斯坦福大学 | CS336 | 从零开始构建语言模型 | Spring 2025 | 笔记 | Assignment 2: DDP Training Implement
斯坦福大学 | CS336 | 从零开始构建语言模型 | Spring 2025 | 笔记 | Assignment 2: DDP Training Implement
目录
-
- 前言
- 1. Problem (distributed_communication_single_node): 5 points
- 2. Problem (naive_ddp): 5 points
- 3. Problem (naive_ddp_benchmarking): 3 points
- 4. Problem (minimal_ddp_flat_benchmarking): 2 points
- 5. Problem (ddp_overlap_individual_parameters): 5 points
- 6. Problem (ddp_overlap_individual_parameters_benchmarking): 1 point
- 7. Problem (ddp_overlap_bucketed): 8 points
- 8. Problem (ddp_bucketed_benchmarking): 3 points
- 9. Problem (communication_accounting): 10 points
- 10. Problem (optimizer_state_sharding): 15 points
- 11. Problem (optimizer_state_sharding_accounting): 5 points
- 结语
- 源码下载链接
- 参考
前言
在上篇文章 斯坦福大学 | CS336 | 从零开始构建语言模型 | Spring 2025 | 笔记 | Assignment 2: DDP Training 中,我们已经了解了 DDP Training 的作业要求,下面我们就一起来看看这些作业该如何实现,本篇文章记录 CS336 作业 Assignment 2: Systems 中的 DDP Training 实现,仅供自己参考😄
Note:博主并未遵循 from-scratch 的宗旨,所有代码几乎均由 ChatGPT 完成
Assignment 2:https://github.com/stanford-cs336/assignment2-systems
reference:https://chatgpt.com/
1. Problem (distributed_communication_single_node): 5 points
编写一个脚本,用于在 单节点多进程(single-node multi-process) 设置下,对 all-reduce 操作的执行时间进行基准测试。上面给出的一个示例代码可以作为一个合理的起点,请在以下配置上进行实验,对比不同设置下的性能表现:
- 后端 + 设备类型:Gloo + CPU,NCCL + GPU
- all-reduce 数据规模:float32 数据张量,大小分别为 1MB、10MB、100MB、1GB
- 进程数量:2、4 或 6 个进程
- 资源限制:最多使用 6 张 GPU,每一次基准测试运行时间应控制在 5 分钟以内
Deliverable:请给出图表和表格,对比上述不同设置下的结果,并附上 2-3 句对实验结果的分析与讨论,说明各个因素(如后端类型、数据规模、进程数)之间是如何相互影响的。
代码实现如下:
import math
import time
import os
import argparse
from multiprocessing import Manager
from pathlib import Path
from typing import Any, Dict, List
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
from cs336_systems.utils import DDPCommRow, DDPCommBenchmarkReporter
def setup(rank: int, world_size: int, backend: str, master_addr: str, master_port: str) -> None:
os.environ["MASTER_ADDR"] = master_addr
os.environ["MASTER_PORT"] = master_port
dist.init_process_group(backend=backend, rank=rank, world_size=world_size)
def cleanup() -> None:
if dist.is_initialized():
dist.destroy_process_group()
def sync_if_cuda(device: torch.device) -> None:
if device.type == "cuda":
torch.cuda.synchronize(device)
def worker(
rank: int,
world_size: int,
backend: str,
size_bytes_list: List[int],
warmup: int,
iters: int,
master_addr: str,
master_port: str,
out_rows_proxy, # Manager().list()
) -> None:
try:
setup(rank, world_size, backend, master_addr, master_port)
use_cuda = (backend == "nccl")
if use_cuda:
assert torch.cuda.is_available(), "CUDA not available but backend=nccl"
assert world_size <= torch.cuda.device_count(), (f"world_size={world_size} > cuda_device_count={torch.cuda.device_count()}")
torch.cuda.set_device(rank)
device = torch.device(f"cuda:{rank}")
else:
device = torch.device("cpu")
dtype = torch.float32
elem_size = torch.tensor([], dtype=dtype).element_size() # 4 bytes
for size_bytes in size_bytes_list:
numel = size_bytes // elem_size
if numel <= 0:
raise ValueError(f"Invalid size_bytes={size_bytes}")
torch.manual_seed(1234 + rank)
x = torch.rand((numel,), device=device, dtype=dtype)
# warmup
for _ in range(warmup):
dist.all_reduce(x, op=dist.ReduceOp.SUM)
sync_if_cuda(device)
# timed
times_ms: List[float] = []
for _ in range(iters):
sync_if_cuda(device)
t0 = time.perf_counter()
dist.all_reduce(x, op=dist.ReduceOp.SUM)
sync_if_cuda(device)
t1 = time.perf_counter()
times_ms.append((t1 - t0) * 1e3)
gathered: List[List[float]] = [None for _ in range(world_size)] # type: ignore
dist.all_gather_object(gathered, times_ms)
if rank == 0:
# per-iter max across ranks ~= synchronized step latency
per_iter_max = [max(gathered[r][i] for r in range(world_size)) for i in range(iters)]
mean = sum(per_iter_max) / len(per_iter_max)
var = sum((t -mean) ** 2 for t in per_iter_max) / max(1, (len(per_iter_max) - 1))
std = math.sqrt(var)
max_ms = max(per_iter_max)
out_rows_proxy.append(
dict(
backend=backend,
device=("cuda" if use_cuda else "cpu"),
world_size=world_size,
op="all_reduce",
size_bytes=size_bytes,
dtype="float32",
warmup_steps=warmup,
measure_steps=iters,
mean_ms=float(mean),
std_ms=float(std),
max_ms=float(max_ms)
)
)
dist.barrier()
finally:
cleanup()
def parse_args() -> argparse.Namespace:
p = argparse.ArgumentParser()
p.add_argument("--backend", type=str, choices=["gloo", "nccl"], required=True)
p.add_argument("--world-size", type=int, default=2)
p.add_argument("--warmup", type=int, default=5)
p.add_argument("--iters", type=int, default=50)
p.add_argument("--master-addr", type=str, default="127.0.0.1")
p.add_argument("--master-port", type=str, default="29501")
p.add_argument("--out-dir", type=str, default="runs/ddp_comm_test")
return p.parse_args()
def main() -> None:
args = parse_args()
# Required sizes: 1MB / 10MB / 100MB / 1GB
size_bytes_list = [
1 * 1024 * 1024,
10 * 1024 * 1024,
100 * 1024 * 1024,
1024 * 1024 * 1024,
]
out_dir = Path(args.out_dir)
reporter = DDPCommBenchmarkReporter(
jsonl_path=out_dir / "metrics.jsonl",
md_path=out_dir / "table.md",
title="#### DDP communication benchmark (op=all_reduce)"
)
with Manager() as manager:
out_rows = manager.list()
mp.spawn(
worker,
args=(
args.world_size,
args.backend,
size_bytes_list,
args.warmup,
args.iters,
args.master_addr,
args.master_port,
out_rows,
),
nprocs=args.world_size,
join=True,
)
# rank0 results were appended into out_rows
rows: List[Dict[str, Any]] = list(out_rows)
for r in rows:
reporter.append(DDPCommRow(**r))
reporter.write_markdown()
print(f"[OK] wrote {len(rows)} rows -> {out_dir/'metrics.jsonl'} and {out_dir/'table.md'}")
if __name__ == "__main__":
main()
运行指令如下:
uv run cs336_systems/ddp/bench_allreduce.py --backend gloo --world-size 2
执行后输出如下:

执行后的结果会保存到对应的 JSON 和 Markdown 文件中
代码实现比较简单,我们来快速分析下:
def main() -> None:
args = parse_args()
# Required sizes: 1MB / 10MB / 100MB / 1GB
size_bytes_list = [
1 * 1024 * 1024,
10 * 1024 * 1024,
100 * 1024 * 1024,
1024 * 1024 * 1024,
]
out_dir = Path(args.out_dir)
reporter = DDPCommBenchmarkReporter(
jsonl_path=out_dir / "metrics.jsonl",
md_path=out_dir / "table.md",
title="#### DDP communication benchmark (op=all_reduce)"
)
main() 主函数入口,负责解析参数(backend/world_size/warmup 等),构造固定的张量大小列表(1MB/10MB/100MB/1GB),然后统一将所有实验结果写入 JSON 文件并渲染成 Markdown
def main() -> None:
...
with Manager() as manager:
out_rows = manager.list()
mp.spawn(
worker,
args=(
args.world_size,
args.backend,
size_bytes_list,
args.warmup,
args.iters,
args.master_addr,
args.master_port,
out_rows,
),
nprocs=args.world_size,
join=True,
)
我们使用 torch.multiprocessing.spawn 来启动 world_size 个进程,每个进程对应一个 rank,统一执行 worker(rank, ...)
def setup(rank: int, world_size: int, backend: str, master_addr: str, master_port: str) -> None:
os.environ["MASTER_ADDR"] = master_addr
os.environ["MASTER_PORT"] = master_port
dist.init_process_group(backend=backend, rank=rank, world_size=world_size)
每个 rank 在 setup() 中设置 MASTER_ADDR/MASTER_PORT,然后调用 dist.init_process_group(...),这里的关键点是:哪怕是单机,也需要一个 master 地址与端口用于 rendezvous,让所有进程能互相发现并建立通信组
def worker(
rank: int,
world_size: int,
backend: str,
size_bytes_list: List[int],
warmup: int,
iters: int,
master_addr: str,
master_port: str,
out_rows_proxy, # Manager().list()
) -> None:
try:
setup(rank, world_size, backend, master_addr, master_port)
use_cuda = (backend == "nccl")
if use_cuda:
assert torch.cuda.is_available(), "CUDA not available but backend=nccl"
assert world_size <= torch.cuda.device_count(), (f"world_size={world_size} > cuda_device_count={torch.cuda.device_count()}")
torch.cuda.set_device(rank)
device = torch.device(f"cuda:{rank}")
else:
device = torch.device("cpu")
...
在 worker() 内部通过 use_cuda = (backend == "nccl") 决定设备类型:
- backend=nccl:要求 CUDA 可用,并用
torch.cuda.set_device(rank),把 rank0 映射到 GPU0、rank1 映射到 GPU1、…,张量x分配在对应 GPU 上 - backend=gloo:直接使用 CPU 张量
def worker(
rank: int,
world_size: int,
backend: str,
size_bytes_list: List[int],
warmup: int,
iters: int,
master_addr: str,
master_port: str,
out_rows_proxy, # Manager().list()
) -> None:
try:
...
dtype = torch.float32
elem_size = torch.tensor([], dtype=dtype).element_size() # 4 bytes
for size_bytes in size_bytes_list:
numel = size_bytes // elem_size
if numel <= 0:
raise ValueError(f"Invalid size_bytes={size_bytes}")
torch.manual_seed(1234 + rank)
x = torch.rand((numel,), device=device, dtype=dtype)
# warmup
for _ in range(warmup):
dist.all_reduce(x, op=dist.ReduceOp.SUM)
sync_if_cuda(device)
# timed
times_ms: List[float] = []
for _ in range(iters):
sync_if_cuda(device)
t0 = time.perf_counter()
dist.all_reduce(x, op=dist.ReduceOp.SUM)
sync_if_cuda(device)
t1 = time.perf_counter()
times_ms.append((t1 - t0) * 1e3)
...
每个 size 都先进行 warmpup 次 all-reduce,然后才开始 iters 次正式测量。值得注意的是,通信操作 dist.all_reduce 在 GPU 上通常是 异步 排队执行的,如果只用 perf_counter() 包住 API 调用而不做同步,就会测到 “发起 kernel 的时间”,而不是 “通信真正完成的时间”。因此我们对 CUDA 场景在计时前后都调用 sync_if_cuda,确保:
- 开始计时前:清空前面残留的异步工作
- 结束计时后:等待本次 all-reduce 真正完成再停止计时
def worker(
rank: int,
world_size: int,
backend: str,
size_bytes_list: List[int],
warmup: int,
iters: int,
master_addr: str,
master_port: str,
out_rows_proxy, # Manager().list()
) -> None:
try:
...
for size_bytes in size_bytes_list:
...
gathered: List[List[float]] = [None for _ in range(world_size)] # type: ignore
dist.all_gather_object(gathered, times_ms)
if rank == 0:
# per-iter max across ranks ~= synchronized step latency
per_iter_max = [max(gathered[r][i] for r in range(world_size)) for i in range(iters)]
mean = sum(per_iter_max) / len(per_iter_max)
var = sum((t -mean) ** 2 for t in per_iter_max) / max(1, (len(per_iter_max) - 1))
std = math.sqrt(var)
max_ms = max(per_iter_max)
out_rows_proxy.append(
dict(
backend=backend,
device=("cuda" if use_cuda else "cpu"),
world_size=world_size,
op="all_reduce",
size_bytes=size_bytes,
dtype="float32",
warmup_steps=warmup,
measure_steps=iters,
mean_ms=float(mean),
std_ms=float(std),
max_ms=float(max_ms)
)
)
dist.barrier()
finally:
cleanup()
每个 rank 都会得到一个长度为 iters 的 time_ms 列表,我们使用 dist.all_gather_object(gathered, times_ms) 把所有 rank 的测量序列收集到 rank0,收集到 gathered 后,rank0 可用做更合理的全局统计,而不是只看某一个 rank 的局部时间
不同设置下的性能表现如下表所示:
| backend | device | world_size | size_bytes | dtype | mean_ms | std_ms | max_ms |
|---|---|---|---|---|---|---|---|
| gloo | cpu | 2 | 1MB | float32 | 1.092 | 0.119 | 1.392 |
| gloo | cpu | 2 | 10MB | float32 | 8.887 | 1.286 | 12.48 |
| gloo | cpu | 2 | 100MB | float32 | 96.094 | 16.275 | 168.011 |
| gloo | cpu | 2 | 1GB | float32 | 1045.36 | 146.876 | 1397.88 |
| gloo | cpu | 4 | 1MB | float32 | 2.37 | 0.317 | 2.901 |
| gloo | cpu | 4 | 10MB | float32 | 13.84 | 1.026 | 16.091 |
| gloo | cpu | 4 | 100MB | float32 | 152.201 | 21.55 | 247.16 |
| gloo | cpu | 4 | 1GB | float32 | 1700.88 | 132.424 | 2084.36 |
| gloo | cpu | 6 | 1MB | float32 | 2.994 | 0.278 | 3.644 |
| gloo | cpu | 6 | 10MB | float32 | 18.043 | 2.819 | 35.083 |
| gloo | cpu | 6 | 100MB | float32 | 208.053 | 29.335 | 320.367 |
| gloo | cpu | 6 | 1GB | float32 | 1941.73 | 190.509 | 2640.62 |
| nccl | cuda | 2 | 1MB | float32 | 0.352 | 0.011 | 0.38 |
| nccl | cuda | 2 | 10MB | float32 | 2.691 | 0.014 | 2.73 |
| nccl | cuda | 2 | 100MB | float32 | 26.344 | 0.058 | 26.461 |
| nccl | cuda | 2 | 1GB | float32 | 268.845 | 0.219 | 269.254 |
| nccl | cuda | 4 | 1MB | float32 | 0.443 | 0.007 | 0.465 |
| nccl | cuda | 4 | 10MB | float32 | 4.632 | 0.03 | 4.695 |
| nccl | cuda | 4 | 100MB | float32 | 45.967 | 0.418 | 47.89 |
| nccl | cuda | 4 | 1GB | float32 | 467.209 | 1.355 | 469.659 |
| nccl | cuda | 6 | 1MB | float32 | 0.599 | 0.418 | 2.668 |
| nccl | cuda | 6 | 10MB | float32 | 4.667 | 0.116 | 5.275 |
| nccl | cuda | 6 | 100MB | float32 | 49.473 | 0.707 | 52.367 |
| nccl | cuda | 6 | 1GB | float32 | 496.886 | 2.252 | 502.676 |
Note:这是博主在六块 RTX2080Ti 上测量得到的结果
博主根据上述表格绘制的对比图如下所示:

从图中我们可以分析得到:
1. 延迟随通信规模的变化趋势
从左侧图的延迟曲线可以观察到,无论在 2、4 还是 6 ranks 下,两种后端的 all-reduce 延迟都随着 tensor size 的增大呈现出近似线性的增长趋势(对数坐标下接近直线),这表明在较大通信规模时,整体延迟主要由 数据搬运与链路带宽 所主导,而非固定调度开销。
相比之下,NCCL + CUDA 在所有 tensor size 下都显著由于 Gloo + CPU,体现了 GPU 直连通信与 NCCL 拓扑感知优化所带来的高效带宽利用。
2. 小张量与大张量下的性能主导因素差异
在 1 MiB 这样的小通信规模下,两种后端的绝对延迟都较低,但此时性能更多受到 通信启动、调度以及软件栈开销 的影响,而非纯带宽限制。因此可以看到,在不同 ranks 设置下,speedup 曲线存在一定波动,并非严格单调。
而随着 tensor size 增大到 100 MiB 与 1 GiB,延迟增长开始稳定受限于带宽瓶颈,此时 NCCL 的优势更加稳定且可预测,这一现象与分布式训练中的实际情况高度一致:梯度规模越大,通信后端与硬件互联能力的重要性就越突出。
3. 不同 ranks 数量下的 NCCL 的加速效果
右侧 speedup 子图展示了 NCCL 相对于 Gloo 的加速比,在 2 ranks 情况下,NCCL 的加速比整体位于 3x~4x 区间,并随着通信规模增大略有提升,这说明在双卡场景下,GPU-GPU 通信已经能够较好地摊薄启动与同步开销。
当 ranks 增加到 4 与 6 时,可以观察到在小张量(1-10 MiB)下加速比有所下降,而在 100 MiB 左右又出现回升趋势,这表明随着参与通信的 rank 数量增加,all-reduce 的通信路径与同步复杂度上升,使得小张量场景更容易被固定开销所主导;但在大张量场景下,NCCL 依然能够通过更高效的带宽利用保存稳定的性能优势。
综合来看,本实验清晰地验证了以下几点结论:
1. NCCL + CUDA 在单节点多卡 all-reduce 场景中显著优于 Gloo + CPU,尤其在中大规模通信下优势明显;
2. 通信规模绝对性能主导因素:小张量受启动与调度开销影响更大,大张量则主要受带宽限制;
3. rank 数量增加会放大小通信地同步开销,但在真实训练常见地大梯度规模下,NCCL 仍能提供稳定且可观地加速效果。
这些结果与分布式深度学习系统中对通信后端的普遍经验基本一致
2. Problem (naive_ddp): 5 points
Deliverable:编写一个脚本,通过在反向传播之后对 各个参数的梯度进行 all-reduce 的方式,朴素地实现分布式数据并行(DDP)训练。为了验证你的 DDP 实现是否正确,请使用该脚本在 随机生成的数据 上训练一个 小型 toy 模型,并验证其训练得到的权重是否与 单进程训练 得到的结果一致。
Note:如果你在编写这个测试时遇到困难,可以参考 tests/test_ddp_individual_parameters.py
代码实现如下:
import argparse
import os
from copy import deepcopy
from typing import Dict, List, Tuple
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
class ToyModel(nn.Module):
def __init__(self, in_features: int, out_features: int):
super().__init__()
self.fc1 = nn.Linear(in_features, 10, bias=False)
self.ln = nn.LayerNorm(10)
self.fc2 = nn.Linear(10, out_features, bias=False)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.ln(x)
x = self.fc2(x)
return x
def setup_process_group(rank: int, world_size: int, backend: str, master_addr: str, master_port: str) -> None:
os.environ["MASTER_ADDR"] = master_addr
os.environ["MASTER_PORT"] = master_port
dist.init_process_group(backend=backend, rank=rank, world_size=world_size)
def cleanup_process_group() -> None:
if dist.is_initialized():
dist.destroy_process_group()
def sync_if_cuda(device: torch.device) -> None:
if device.type == "cuda":
torch.cuda.synchronize(device)
@torch.no_grad()
def broadcast_model_from_rank0(model: nn.Module) -> None:
"""Make all ranks start from identical parameters (rank0 as source)."""
for p in model.parameters():
dist.broadcast(p.data, src=0)
def allreduce_gradients(model: nn.Module) -> None:
"""Naive DDP: all-reduce every parameter's gradient, then average."""
world_size = dist.get_world_size()
for p in model.parameters():
if p.requires_grad and p.grad is not None:
dist.all_reduce(p.grad, op=dist.ReduceOp.SUM)
p.grad.div_(world_size)
def make_random_dataset(
seed: int, n: int, in_dim: int, out_dim: int, device: torch.device
) -> Tuple[torch.Tensor, torch.Tensor]:
"""Generate a fixed random regression dataset (same across ranks)."""
g = torch.Generator(device="cpu")
g.manual_seed(seed)
x = torch.randn(n, in_dim, generator=g)
y = torch.randn(n, out_dim, generator=g)
return x.to(device), y.to(device)
def single_process_train(
model: nn.Module,
x: torch.Tensor,
y: torch.Tensor,
steps: int,
lr: float
) -> nn.Module:
"""Baseline: single process trains on the full dataset each step."""
model = deepcopy(model).to(x.device)
loss_fn = nn.MSELoss()
opt = optim.SGD(model.parameters(), lr=lr)
for _ in range(steps):
opt.zero_grad(set_to_none=True)
out = model(x)
loss = loss_fn(out, y)
loss.backward()
opt.step()
return model
def ddp_worker(
rank: int,
world_size: int,
backend: str,
use_cuda: bool,
master_addr: str,
master_port: str,
seed_model: int,
seed_data: int,
n: int,
in_dim: int,
out_dim: int,
steps: int,
lr: float,
return_dict,
) -> None:
try:
setup_process_group(rank, world_size, backend, master_addr, master_port)
# device mapping: rank -> cuda:rank
if use_cuda:
torch.cuda.set_device(rank)
device = torch.device(f"cuda:{rank}")
else:
device = torch.device("cpu")
# Build model with rank-dependent seed first (to prove broadcast works)
torch.manual_seed(seed_model + rank)
model = ToyModel(in_dim, out_dim).to(device)
# make all ranks start from rank0 params
broadcast_model_from_rank0(model)
dist.barrier()
# Prepare identical random dataset on each rank, then shard it
x_all, y_all = make_random_dataset(seed=seed_data, n=n, in_dim=in_dim, out_dim=out_dim, device=device)
assert n % world_size == 0
local_bs = n // world_size
start = rank * local_bs
x_local = x_all[start : start + local_bs]
y_local = y_all[start : start + local_bs]
loss_fn = nn.MSELoss()
opt = optim.SGD(model.parameters(), lr=lr)
for _ in range(steps):
opt.zero_grad(set_to_none=True)
out = model(x_local)
loss = loss_fn(out, y_local)
loss.backward()
# Key point: After backpropagation, perform an all-reduce operation (and average) on the gradients of each parameter
allreduce_gradients(model)
sync_if_cuda(device)
opt.step()
sync_if_cuda(device)
# Return final weights to rank0 for verification
state = {k: v.detach().cpu() for k, v in model.state_dict().items()}
return_dict[rank] = state
dist.barrier()
finally:
cleanup_process_group()
def compare_state_dicts(a: Dict[str, torch.Tensor], b: Dict[str, torch.Tensor]) -> Tuple[bool, List[str]]:
mismatched = []
for k in a.keys():
if not torch.allclose(a[k], b[k]):
mismatched.append(k)
return (len(mismatched) == 0), mismatched
def main() -> None:
p = argparse.ArgumentParser()
p.add_argument("--world-size", type=int, default=2)
p.add_argument("--backend", type=str, default="nccl", choices=["nccl", "gloo"])
p.add_argument("--master-addr", type=str, default="127.0.0.1")
p.add_argument("--master-port", type=str, default="29510")
p.add_argument("--seed-model", type=int, default=0)
p.add_argument("--seed-data", type=int, default=123)
p.add_argument("--n", type=int, default=64)
p.add_argument("--in-dim", type=int, default=16)
p.add_argument("--out-dim", type=int, default=8)
p.add_argument("--steps", type=int, default=20)
p.add_argument("--lr", type=float, default=0.1)
args = p.parse_args()
# Device device/backend
use_cuda = torch.cuda.is_available() and args.backend == "nccl"
if args.backend == "nccl" and not torch.cuda.is_available():
raise RuntimeError("backend=nccl requires CUDA, but CUDA is not available.")
if use_cuda and args.world_size > torch.cuda.device_count():
raise RuntimeError(f"world_size={args.world_size} > cuda_device_count={torch.cuda.device_count()}")
# Build rank0 baseline model + baseline dataset on rank0 device
torch.manual_seed(args.seed_model + 0)
baseline_device = torch.device("cuda:0") if use_cuda else torch.device("cpu")
baseline_model = ToyModel(args.in_dim, args.out_dim).to(baseline_device)
x_full, y_full = make_random_dataset(args.seed_data, args.n, args.in_dim, args.out_dim, baseline_device)
baseline_trained = single_process_train(
model=baseline_model,
x=x_full,
y=y_full,
steps=args.steps,
lr=args.lr
)
baseline_state = {k: v.detach().cpu() for k, v in baseline_trained.state_dict().items()}
# Run naive DDP
manager = mp.Manager()
return_dict = manager.dict()
mp.spawn(
ddp_worker,
args=(
args.world_size,
args.backend,
use_cuda,
args.master_addr,
args.master_port,
args.seed_model,
args.seed_data,
args.n,
args.in_dim,
args.out_dim,
args.steps,
args.lr,
return_dict,
),
nprocs=args.world_size,
join=True,
)
# Verify: all ranks match baseline
ok_all = True
for r in range(args.world_size):
ddp_state = return_dict[r]
ok, mismateched = compare_state_dicts(baseline_state, ddp_state)
if not ok:
ok_all = False
print(f"[FALL] rank {r} differs from single-process baseline. mismatched keys: {mismateched}")
else:
print(f"[OK] rank {r} matches single-process baseline exactly.")
if ok_all:
print("\nNaive DDP correctness check passed: DDP weights == single-process weights.")
else:
raise SystemExit("\nNaive DDP correctness check failed.")
if __name__ == "__main__":
main()
Note:ToyModel 的定义来自之前 Mix Precision 作业
运行指令如下:
uv run cs336_systems/ddp/naive_ddp.py
执行后输出如下:

上述代码用最直接的方式复现了 DDP 的核心语义:每个 rank 在不同数据子集上计算局部梯度,然后在反向传播之后对每个参数梯度执行 all-reduce(求和并取平均),最后再进行 optimizer step,通过将最终权重与 “单进程在全量数据上训练” 的结果逐参数对比来验证朴素 DDP 的正确性
我们来重点看下 ddp_worker 函数中实现的内容:
def ddp_worker(
rank: int,
world_size: int,
backend: str,
use_cuda: bool,
master_addr: str,
master_port: str,
seed_model: int,
seed_data: int,
n: int,
in_dim: int,
out_dim: int,
steps: int,
lr: float,
return_dict,
) -> None:
try:
setup_process_group(rank, world_size, backend, master_addr, master_port)
# device mapping: rank -> cuda:rank
if use_cuda:
torch.cuda.set_device(rank)
device = torch.device(f"cuda:{rank}")
else:
device = torch.device("cpu")
# Build model with rank-dependent seed first (to prove broadcast works)
torch.manual_seed(seed_model + rank)
model = ToyModel(in_dim, out_dim).to(device)
# make all ranks start from rank0 params
broadcast_model_from_rank0(model)
dist.barrier()
...
为了验证 “朴素 DDP 能与单进程一致的权重”,所有 rank 必须从完全相同的初始参数开始。我们刻意先用 torch.manual_seed(seed_model + rank) 让每个初始参数不同,然后调用 dist.broadcast(p.data, src=0) 把 rank0 的参数广播到所有 rank,实现 “rank0 参数作为权威源” 的对齐
# Prepare identical random dataset on each rank, then shard it
x_all, y_all = make_random_dataset(seed=seed_data, n=n, in_dim=in_dim, out_dim=out_dim, device=device)
assert n % world_size == 0
local_bs = n // world_size
start = rank * local_bs
x_local = x_all[start : start + local_bs]
y_local = y_all[start : start + local_bs]
我们用固定 seed 生成随机数据 (x_all, y_all),并在每个 rank 上生成同一份数据池,随后通过索引切片划分为不重叠子集,以此来模拟真实数据并行训练中 “每个 worker 处理不同 mini-batch 子集” 的做法
def allreduce_gradients(model: nn.Module) -> None:
"""Naive DDP: all-reduce every parameter's gradient, then average."""
world_size = dist.get_world_size()
for p in model.parameters():
if p.requires_grad and p.grad is not None:
dist.all_reduce(p.grad, op=dist.ReduceOp.SUM)
p.grad.div_(world_size)
for _ in range(steps):
opt.zero_grad(set_to_none=True)
out = model(x_local)
loss = loss_fn(out, y_local)
loss.backward()
# Key point: After backpropagation, perform an all-reduce operation (and average) on the gradients of each parameter
allreduce_gradients(model)
sync_if_cuda(device)
opt.step()
sync_if_cuda(device)
# Return final weights to rank0 for verification
state = {k: v.detach().cpu() for k, v in model.state_dict().items()}
return_dict[rank] = state
dist.barrier()
该函数的核心在 allreduce_gradients(model):它遍历模型每个参数,对 param.grad 执行:
1. dist.all_reduce(grad, SUM):把所有 rank 的局部梯度求和
2. grad /= world_size:转为平均梯度
这一步实现了数据上的等价关系:
∇ θ = 1 R ∑ r = 1 R ∇ θ r \nabla \theta = \frac{1}{R}\sum_{r=1}^R \nabla \theta_r ∇θ=R1r=1∑R∇θr
其中 ∇ θ r \nabla \theta_r ∇θr 是 rank r 在其本地数据子集上计算得到的梯度。由于均方误差损失(MSELoss)是对样本平均的形式,且各 rank 子集不重叠,最终平均梯度与单进程在全量 batch 上计算得到的梯度一致。因此,在相同学习率与优化器参数下,optimizer step 的更新方向和步长都与单进程完全相同,从而权重可以严格对齐。
这也解释了为什么我们这里的实现被称为 “naive”:它对每个参数逐个执行 all-reduce,每个 bucket、没有通信/计算重叠,但语义上已经是正确的 DDP。
3. Problem (naive_ddp_benchmarking): 3 points
在这种 朴素(naïve)的 DDP 实现 中,每一次反向传播结束后,都会对 每一个参数的梯度在各个 rank 之间单独执行 all-reduce 操作。为了更好地理解数据并行训练所带来的 通信开销,请编写一个脚本,对你之前实现的语言模型在使用这种朴素 DDP 方案训练时的性能进行基准测试,你需要:
- 测量 每一步训练的总耗时
- 测量其中 用于梯度通信的时间占比
请在 单节点环境(1 个节点 x 2 块 GPU) 下进行测量,并使用 §1.1.2 中描述的 XL 模型规模(Table 1)作为测试对象

Deliverable:请给出你基准测试的设置说明,并报告在每种设置下的单次训练迭代耗时以及用于梯度通信的时间。
代码实现如下:
import argparse
import os
import math
import time
from multiprocessing import Manager
from pathlib import Path
from typing import List, Tuple
import torch
import torch.nn as nn
import torch.distributed as dist
import torch.multiprocessing as mp
from cs336_systems.ddp.naive_ddp import broadcast_model_from_rank0, allreduce_gradients
from cs336_basics.transformer_lm import TransformerLM
from cs336_basics.optimizer import AdamW
from cs336_basics.nn_utils import cross_entropy_from_logits
from cs336_systems.utils import NaiveDDPBenchRow, NaiveDDPBenchmarkReporter
def setup(rank: int, world_size: int, backend: str, master_addr: str, master_port: str) -> None:
os.environ["MASTER_ADDR"] = master_addr
os.environ["MASTER_PORT"] = master_port
dist.init_process_group(backend=backend, rank=rank, world_size=world_size)
def cleanup() -> None:
if dist.is_initialized():
dist.destroy_process_group()
def sync_if_cuda(device: torch.device) -> None:
if device.type == "cuda":
torch.cuda.synchronize(device)
def build_xl_model(device: torch.device, dtype: torch.dtype) -> nn.Module:
return TransformerLM(
vocab_size=10000,
context_length=128,
d_model=768,
num_layers=16,
num_heads=12,
d_ff=3200,
rope_theta=10000.0,
max_seq_len=128,
eps=1e-5,
device=device,
dtype=dtype,
)
def make_fake_batch(global_bs: int, ctx: int, vocab_size: int, device: torch.device):
g = torch.Generator(device="cpu")
g.manual_seed(123)
tokens = torch.randint(0, vocab_size, (global_bs, ctx + 1), generator=g, dtype=torch.long)
x = tokens[:, :-1].to(device)
y = tokens[:, 1:].to(device)
return x, y
def worker(
rank: int,
world_size: int,
backend: str,
master_addr: str,
master_port: str,
model_size: str,
vocab_size: int,
global_batch_size: int,
context_length: int,
warmup_steps: int,
measure_steps: int,
out_proxy,
) -> None:
try:
setup(rank, world_size, backend, master_addr, master_port)
assert world_size == 2, "This benchmark is standardized to 2 GPUs for the assignment."
assert backend == "nccl", "This benchmark is intended for NCCL + CUDA (1 node x 2 GPU)."
torch.cuda.set_device(rank)
device = torch.device(f"cuda:{rank}")
dtype = torch.float32
# Build model and ensure identical init
model = build_xl_model(device=device, dtype=dtype)
broadcast_model_from_rank0(model)
dist.barrier()
# Fake batch (global) then shard into micro-batch
x, y = make_fake_batch(global_batch_size, context_length, vocab_size, device=device)
assert global_batch_size % world_size == 0
micro_bs = global_batch_size // world_size
x_local = x[rank * micro_bs : (rank + 1) * micro_bs]
y_local = y[rank * micro_bs : (rank + 1) * micro_bs]
# Loss/optimizer
loss_fn = cross_entropy_from_logits
opt = AdamW(model.parameters())
def run_one_step() -> Tuple[float, float]:
"""
Returns: (step_ms, comm_ms)
step_ms: forward->backward->allreduce grads->opt.step
comm_ms: only time inside allreduce_gradients(model)
"""
opt.zero_grad(set_to_none=True)
sync_if_cuda(device)
t0 = time.perf_counter()
# --- forward/backward (placeholder) ---
logits = model(x_local) # [micro_bs, S, V]
loss = loss_fn(logits, y_local)
loss.backward()
# --- communication timing (naive per-parameter all-reduce) ---
sync_if_cuda(device)
c0 = time.perf_counter()
allreduce_gradients(model)
sync_if_cuda(device)
c1 = time.perf_counter()
opt.step()
sync_if_cuda(device)
t1 = time.perf_counter()
return (t1 - t0) * 1e3, (c1 - c0) * 1e3
# warmup
for _ in range(warmup_steps):
run_one_step()
dist.barrier()
# measure
step_times: List[float] = []
comm_times: List[float] = []
for _ in range(measure_steps):
s_ms, c_ms = run_one_step()
step_times.append(s_ms)
comm_times.append(c_ms)
# gather per-rank times
gathered_steps: List[List[float]] = [None for _ in range(world_size)] # type: ignore
gathered_comms: List[List[float]] = [None for _ in range(world_size)] # type: ignore
dist.all_gather_object(gathered_steps, step_times)
dist.all_gather_object(gathered_comms, comm_times)
if rank == 0:
# use per-iter max across ranks as synchronized step/comm time
step_max = [max(gathered_steps[r][i] for r in range(world_size)) for i in range(measure_steps)]
comm_max = [max(gathered_comms[r][i] for r in range(world_size)) for i in range(measure_steps)]
def mean_std(xs: List[float]) -> Tuple[float, float]:
m = sum(xs) / len(xs)
if len(xs) <= 1:
return m, 0.0
var = sum((x - m) ** 2 for x in xs) / (len(xs) - 1)
return m, math.sqrt(var)
step_mean, step_std = mean_std(step_max)
comm_mean, comm_std = mean_std(comm_max)
comm_pct = (comm_mean / step_mean) * 100.0 if step_mean > 0 else 0.0
out_proxy.append(
dict(
model_size=model_size,
backend=backend,
device="cuda",
world_size=world_size,
dtype="fp32",
global_batch_size=global_batch_size,
micro_batch_size=micro_bs,
context_length=context_length,
warmup_steps=warmup_steps,
measure_steps=measure_steps,
step_mean_ms=step_mean,
step_std_ms=step_std,
comm_mean_ms=comm_mean,
comm_std_ms=comm_std,
comm_pct_mean=comm_pct,
)
)
dist.barrier()
finally:
cleanup()
def main() -> None:
p = argparse.ArgumentParser()
p.add_argument("--model-size", type=str, default="xl")
p.add_argument("--vocab-size", type=int, default=10000)
p.add_argument("--global-batch-size", type=int, default=32)
p.add_argument("--context-length", type=int, default=128)
p.add_argument("--warmup-steps", type=int, default=5)
p.add_argument("--measure-steps", type=int, default=20)
p.add_argument("--backend", type=str, default="nccl", choices=["nccl"])
p.add_argument("--world-size", type=int, default=2)
p.add_argument("--master-addr", type=str, default="127.0.0.1")
p.add_argument("--master-port", type=str, default="29530")
p.add_argument("--out-dir", type=str, default="runs/naive_ddp_bench")
args = p.parse_args()
# standardized: 1 node x 2 GPU
assert args.world_size == 2, "Use 2 GPUs for consistency with later problems."
out_dir = Path(args.out_dir)
reporter = NaiveDDPBenchmarkReporter(
jsonl_path=out_dir / "metrics.jsonl",
md_path=out_dir / "table.md",
title="#### Naive DDP benchmarking (XL, 1 node x 2 GPU)",
)
with Manager() as manager:
out_rows = manager.list()
mp.spawn(
worker,
args=(
args.world_size,
args.backend,
args.master_addr,
args.master_port,
args.model_size,
args.vocab_size,
args.global_batch_size,
args.context_length,
args.warmup_steps,
args.measure_steps,
out_rows,
),
nprocs=args.world_size,
join=True,
)
rows = list(out_rows)
for r in rows:
reporter.append(NaiveDDPBenchRow(**r))
reporter.write_markdown()
print(f"[OK] wrote {len(rows)} rows to {out_dir/'metrics.jsonl'} and {out_dir/'table.md'}")
if __name__ == "__main__":
main()
运行指令如下:
uv run cs336_systems/ddp/bench_naive_ddp.py
执行后输出如下:

Note:由于硬件资源的限制,博主并没有采用 §1.1.2 中描述的 XL 模型规模进行实验,而是进行了适当的缩放。
代码实现较简单,主要是在 单节点 2 GPU 环境下,对之前实现的朴素 DDP 训练的性能进行基准测试,脚本的整体流程是:
1. mp.spawn 启动 world_size=2 个进程(每个进程一个 rank)
2. 每个 rank 初始化 NCCL 进程组,并绑定到 cuda:rank
3. 构建模型并确保所有 rank 起点参数一致
4. 生成一批固定随机 token 数据并在 rank 间切分(数据并行)
5. 在每个 step 内测量两类时间:
- step 总耗时(forward + backward + grad sync + step)
- 通信耗时(仅梯度 all-reduce 部分)
6. 将每个 rank 的时间序列收集到 rank0 做统计,并通过 reporter 输出到对应的 JSON 文件并渲染成 Markdown
结果如下表所示:
| model_size | backend | device | world_size | dtype | global_batch_size | micro_batch_size | context_length | warmup_steps | measure_steps | step_mean_ms | step_std_ms | comm_mean_ms | comm_std_ms | comm_pct_mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| xl | nccl | cuda | 2 | fp32 | 32 | 16 | 128 | 5 | 20 | 462.374 | 1.726 | 197.793 | 1.906 | 42.778 |
在当前实验配置下(global-batch size=32,每个 rank 的 micro-batch size=16,context length=128,FP32 精度),一次完整训练 step 的平均耗时约为 462 ms。其中,梯度同步(即所有参数梯度的 all-reduce)平均耗时约为 198 ms,约占单步训练总时间的 43%。此外,无论是 step 总耗时还是通信耗时,其标准差都维持在 2 ms 左右,表明测量结果稳定、抖动较小,通信开销具有明显的系统特征。
如此高的通信占比,直接源于朴素 DDP 的实现方式。在该实现中,每一个参数张量在反向传播结束后都会触发一次独立的 all-reduce 操作。对于 Transformer 模型而言,其参数数量和参数张量数量都非常可观,这意味着一次训练 step 中会产生大量的小规模通信调用。即使在单节点环境下使用 NCCL 和高速 GPU 互联,这些频繁的通信调用仍然会带来显著的启动和同步开销,从而使梯度通信成为训练过程中的主要性能瓶颈之一。
该实验结果清楚地揭示了朴素 DDP 的核心局限性:虽然其在数学意义上与单进程训练完全等价,且实现简单直观,但其通信策略在性能上是低效的。这也直接说明了后续更高效的 DDP 实现(例如通过梯度分桶、减少 all-reduce 次数以及将通信与反向计算进行重叠)存在的必要性和优化空间。
4. Problem (minimal_ddp_flat_benchmarking): 2 points
修改你的最小化 DDP 实现,使其在通信阶段对 所有参数的梯度先进行展平并合并成一个张量,然后只进行 一次 batched all-reduce 通信。请将该实现的性能与之前的最小 DDP 实现进行对比,后者是在相同实验条件下 (1 个节点 x 2 块 GPU,XL 模型规模,§1.1.2 中描述的设置)对每个参数张量分别执行一次 all-reduce
Deliverable:报告每次训练迭代的耗时以及分布式数据并行训练中用于梯度通信的时间,并用 1-2 句话简要对比说明使用单次合并 all-reduce 通信与逐参数通信在性能上的差异。
代码实现如下:
import argparse
import math
import time
from multiprocessing import Manager
from pathlib import Path
from typing import List, Tuple
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
from torch._utils import _flatten_dense_tensors, _unflatten_dense_tensors
from cs336_basics.optimizer import AdamW
from cs336_basics.nn_utils import cross_entropy_from_logits
from cs336_systems.ddp.naive_ddp import broadcast_model_from_rank0, allreduce_gradients
from cs336_systems.utils import MinimalDDPFlatBenchRow, MinimalDDPFlatBenchmarkReporter
from cs336_systems.ddp.bench_naive_ddp import setup, cleanup, sync_if_cuda, build_xl_model, make_fake_batch
def allreduce_flat(model: nn.Module) -> None:
"""
Flatten all grads into a single buffer -> one all_reduce -> unflatten -> copy back.
Includes the flatten/unflatten overhead inside comm time (fair, end-to-end comm phase).
"""
ws = dist.get_world_size()
grads = []
params = []
for p in model.parameters():
if p.requires_grad and p.grad is not None:
grads.append(p.grad)
params.append(p)
if not grads:
return
flat = _flatten_dense_tensors(grads)
dist.all_reduce(flat, op=dist.ReduceOp.SUM)
flat.div_(ws)
new_grads = _unflatten_dense_tensors(flat, grads)
for p, g in zip(params, new_grads):
p.grad.copy_(g)
def worker(
rank: int,
world_size: int,
backend: str,
master_addr: str,
master_port: str,
global_batch_size: int,
context_length: int,
warmup_steps: int,
measure_steps: int,
out_proxy,
) -> None:
try:
setup(rank, world_size, backend, master_addr, master_port)
assert world_size == 2, "Standardized to 2 GPUs."
assert backend == "nccl", "Intended for NCCL + CUDA."
torch.cuda.set_device(rank)
device = torch.device(f"cuda:{rank}")
dtype = torch.float32
model = build_xl_model(device=device, dtype=dtype)
broadcast_model_from_rank0(model)
dist.barrier()
x, y = make_fake_batch(global_batch_size, context_length, 10000, device=device)
micro_bs = global_batch_size // world_size
x_local = x[rank * micro_bs : (rank + 1) * micro_bs]
y_local = y[rank * micro_bs : (rank + 1) * micro_bs]
loss_fn = cross_entropy_from_logits
opt = AdamW(model.parameters())
def run_one_step(sync_fn) -> Tuple[float, float]:
opt.zero_grad(set_to_none=True)
sync_if_cuda(device)
t0 = time.perf_counter()
logits = model(x_local)
loss = loss_fn(logits, y_local)
loss.backward()
sync_if_cuda(device)
c0 = time.perf_counter()
sync_fn(model)
sync_if_cuda(device)
c1 = time.perf_counter()
opt.step()
sync_if_cuda(device)
t1 = time.perf_counter()
return (t1 - t0) * 1e3, (c1 - c0) * 1e3
def bench_variant(variant: str, sync_fn):
# warmup
for _ in range(warmup_steps):
run_one_step(sync_fn)
dist.barrier()
# measure
step_times: List[float] = []
comm_times: List[float] = []
for _ in range(measure_steps):
s, c = run_one_step(sync_fn)
step_times.append(s)
comm_times.append(c)
gathered_steps: List[List[float]] = [None for _ in range(world_size)] # type: ignore
gathered_comms: List[List[float]] = [None for _ in range(world_size)] # type: ignore
dist.all_gather_object(gathered_steps, step_times)
dist.all_gather_object(gathered_comms, comm_times)
if rank == 0:
step_max = [max(gathered_steps[r][i] for r in range(world_size)) for i in range(measure_steps)]
comm_max = [max(gathered_comms[r][i] for r in range(world_size)) for i in range(measure_steps)]
def mean_std(xs: List[float]) -> Tuple[float, float]:
m = sum(xs) / len(xs)
if len(xs) <= 1:
return m, 0.0
var = sum((x - m) ** 2 for x in xs) / (len(xs) - 1)
return m, math.sqrt(var)
step_mean, step_std = mean_std(step_max)
comm_mean, comm_std = mean_std(comm_max)
comm_pct = (comm_mean / step_mean) * 100.0 if step_mean > 0 else 0.0
out_proxy.append(
dict(
variant=variant,
model_size="xl",
backend=backend,
device="cuda",
world_size=world_size,
dtype="fp32",
global_batch_size=global_batch_size,
micro_batch_size=micro_bs,
context_length=context_length,
warmup_steps=warmup_steps,
measure_steps=measure_steps,
step_mean_ms=step_mean,
step_std_ms=step_std,
comm_mean_ms=comm_mean,
comm_std_ms=comm_std,
comm_pct_mean=comm_pct,
)
)
dist.barrier()
# Run both variants back-to-back under identical conditions
bench_variant("per_param", allreduce_gradients)
bench_variant("flat", allreduce_flat)
finally:
cleanup()
def main() -> None:
p = argparse.ArgumentParser()
p.add_argument("--global-batch-size", type=int, default=32)
p.add_argument("--context-length", type=int, default=128)
p.add_argument("--warmup-steps", type=int, default=5)
p.add_argument("--measure-steps", type=int, default=20)
p.add_argument("--backend", type=str, default="nccl", choices=["nccl"])
p.add_argument("--world-size", type=int, default=2)
p.add_argument("--master-addr", type=str, default="127.0.0.1")
p.add_argument("--master-port", type=str, default="29540")
p.add_argument("--out-dir", type=str, default="runs/minimal_ddp_flat")
args = p.parse_args()
out_dir = Path(args.out_dir)
reporter = MinimalDDPFlatBenchmarkReporter(
jsonl_path=out_dir / "metrics.jsonl",
md_path=out_dir / "table.md",
title="#### Minimal DDP flat benchmarking (per-parameter vs flat)",
)
with Manager() as manager:
out_rows = manager.list()
mp.spawn(
worker,
args=(
args.world_size,
args.backend,
args.master_addr,
args.master_port,
args.global_batch_size,
args.context_length,
args.warmup_steps,
args.measure_steps,
out_rows,
),
nprocs=args.world_size,
join=True,
)
for r in list(out_rows):
reporter.append(MinimalDDPFlatBenchRow(**r))
reporter.write_markdown()
print(f"[OK] wrote results to {out_dir/'metrics.jsonl'} and {out_dir/'table.md'}")
if __name__ == "__main__":
main()
运行指令如下:
uv run cs336_systems/ddp/bench_minimal_ddp_flat.py
执行后输出如下:

上述代码在完全相同的训练设置下,对两种 DDP 梯度同步方式进行了性能对比:
- per_param(naive):对每个参数的
grad单独执行一次all_reduce - flat(batched):将所有参数梯度展平拼接为一个大张量,只执行 一次
all_reduce,再还原回各个参数的梯度张量
我们重点来看下 flat 下的 all-reduce 具体代码是如何实现的:
def allreduce_flat(model: nn.Module) -> None:
"""
Flatten all grads into a single buffer -> one all_reduce -> unflatten -> copy back.
Includes the flatten/unflatten overhead inside comm time (fair, end-to-end comm phase).
"""
ws = dist.get_world_size()
grads = []
params = []
for p in model.parameters():
if p.requires_grad and p.grad is not None:
grads.append(p.grad)
params.append(p)
if not grads:
return
flat = _flatten_dense_tensors(grads)
dist.all_reduce(flat, op=dist.ReduceOp.SUM)
flat.div_(ws)
new_grads = _unflatten_dense_tensors(flat, grads)
for p, g in zip(params, new_grads):
p.grad.copy_(g)
1. 收集所有需要同步的梯度张量
for p in model.parameters():
if p.requires_grad and p.grad is not None:
grads.append(p.grad)
params.append(p)
2. 展平并拼接(flatten + concat)成一个连续大 buffer
flat = _flatten_dense_tensors(grads)
这里我们使用了作业提示的工具函数 _flatten_dense_tensors,这一步把多个 dense grad tensor 组织成一个 contiguous 1D tensor,避免手工 torch.cat 的繁琐与潜在碎片
4. 还原回原始形状,并写回每个参数的 grad
new_grads = _unflatten_dense_tensors(flat, grads)
for p, g in zip(params, new_grads):
p.grad.copy_(g)
这一步是关键:_unflatten_dense_tensors 能根据原始 grad 的 shape 信息,把扁平向量切回对应分片,然后 copy_ 回 p.grad,保存后续 optimizer 看见的梯度与 naive DDP 完全一致
因此,flat 版本的通信调用次数从 “参数张量数” 降为 1,理论上能显著减少通信启动开销、提示通信效率。
结果如下表所示:
| variant | model_size | backend | device | world_size | dtype | global_batch_size | micro_batch_size | context_length | warmup_steps | measure_steps | step_mean_ms | step_std_ms | comm_mean_ms | comm_std_ms | comm_pct_mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| per_param | xl | nccl | cuda | 2 | fp32 | 32 | 16 | 128 | 5 | 20 | 463.725 | 1.241 | 196.602 | 1.362 | 42.396 |
| flat | xl | nccl | cuda | 2 | fp32 | 32 | 16 | 128 | 5 | 20 | 450.054 | 1.388 | 180.638 | 0.481 | 40.137 |

从上表我们可以看出,再逐参数 all-reduce(per_param)实现中,每个训练 step 的平均耗时约为 463.7 ms,采用梯度合并的 flat 实现后,单步训练的平均耗时下降至 450.1 ms,整体 step 时间减少了约 13.7 ms(≈3%)。
这一结果表明,即使不改变模型结构、不引入通信与计算重叠,仅通过减少通信调用次数,也能对整体训练性能产生可观的正向影响。
从梯度通信阶段的耗时来看,差异更加明显:
- per_param:梯度通信平均耗时约为 196.6 ms,占单步训练时间的 42.4%
- flat:梯度通信平均耗时下降至 180.6 ms,通信占比降低到 40.1%
也就是说,通过将所有参数梯度合并为一次 batched all-reduce,通信时间减少了约 16 ms(≈8%),并且通信在训练 step 中所占比例也出现了明显下降
需要注意的是,在 flat 实现中,这里的通信时间不仅包含一次 all-reduce 本身,还包括梯度的 flatten / unflatten 以及拷贝回参数张量的开销。即便如此,其整体通信成本仍显著低于逐参数 all-reduce 的实现,说明减少通信调用次数所节省的启动与同步开销,远大于额外的内存整理成本。
5. Problem (ddp_overlap_individual_parameters): 5 points
请实现一个 Python 类,用于处理 分布式数据并行(Distributed Data Parallel, DDP)训练,该类需要封装任意一个 PyTorch 的 nn.Module,并在训练开始前负责 广播模型权重(从而保证所有 rank 拥有相同的初始函数),以及在训练过程中 发起梯度平均所需的通信操作
我们建议你实现如下的公共接口:
__init__(self, module: torch.nn.Module):给定一个已经实例化的 PyTorchnn.Module,构造一个 DDP 容器,用于在不同 rank 之间处理梯度同步forward(self, *inputs, **kwargs):使用给定的位置参数和关键字参数,调用被封装模块的forward()方法finish_gradient_synchronization(self):当该函数被调用时,应等待所有 异步通信操作 完成,以确保梯度相关的通信已经正确地排队到 GPU 上
为了使用这个类进行分布式训练,我们会将一个模块传入该类进行封装,然后在调用 optimizer.step() 之前,显式调用一次 finish_gradient_synchronization(self) 以确保 依赖梯度的优化器更新操作 能够正确地被调度执行,使用示例如下:
model = ToyModel().to(device)
ddp_model = DDP(model)
for _ in range(train_steps):
x, y = get_batch()
logits = ddp_model(x)
loss = loss_fn(logits, y)
loss.backward()
ddp_model.finish_gradient_synchronization()
optimizer.step()
Deliverable:请实现一个用于分布式数据并行训练的 容器类,该类应当能够 将梯度通信与反向传播计算进行重叠(overlap),以减少通信带来的训练开销。为了测试你的 DDP 实现,你需要首先实现 [adapters.get_ddp_individual_parameters] 和 [adapters.ddp_individual_parameters_on_after_backward](该项为可选,取决于你的实现是否需要),然后运行测试:
uv run pytest tests/test_ddp_individual_parameters.py
我们建议你多次运行测试(例如 5 次),以确保实现具有足够的稳定性并能够可靠通过。
代码实现如下:
from typing import List
import torch
import torch.distributed as dist
class DDPIndividualParameters(torch.nn.Module):
"""
Overlap DDP (individual parameter gradients):
- __init__: broadcast parameters from rank0, then register post-accumulate grad hooks
- backward: as each parameter's grad becomes ready, launch async all_reduce(grad)
- finish_gradient_synchronization: wait all handles, then average grads
"""
def __init__(self, module: torch.nn.Module):
super().__init__()
if not dist.is_initialized():
raise RuntimeError("Process group not initialized; call dist.init_process_group first.")
self.module = module
self.world_size = dist.get_world_size()
# Handles returned by async all_reduce
self._handles: List[dist.Work] = []
# Grads that correspond to handles
self._grads: List[torch.Tensor] = []
# Make sure all ranks start from the same weights
self._broadcast_from_rank0()
# Register hooks to overlap comm with backprop compute
self._register_grad_ready_hooks()
def forward(self, *inputs, **kwargs):
return self.module(*inputs, **kwargs)
@torch.no_grad()
def _broadcast_from_rank0(self) -> None:
# Broadcast parameters
for p in self.module.parameters():
dist.broadcast(p.data, src=0)
# Also broadcast buffers (safe default for general modules)
for b in self.module.buffers():
if b is not None and torch.is_tensor(b):
dist.broadcast(b, src=0)
def _register_grad_ready_hooks(self) -> None:
"""
Use register_post_accumulate_grad_hook if available (preferred),
otherwise fail back to register_hook.
"""
for p in self.module.parameters():
if not p.requires_grad:
continue
# Capture parameter with a factory to avoid late-binding closure bug
def _make_hook(param: torch.Tensor):
# Preferred API (fires after grad accumulation)
if hasattr(param, "register_post_accumulate_grad_hook"):
def _hook(_):
g = param.grad
if g is None:
return
h = dist.all_reduce(g, op=dist.ReduceOp.SUM, async_op=True)
self._handles.append(h)
self._grads.append(g)
return _hook, "post_accumulate"
else:
# Fallback: register_hook receives grad tensor
def _hook(grad: torch.Tensor):
h = dist.all_reduce(grad, op=dist.ReduceOp.SUM, async_op=True)
self._handles.append(h)
self._grads.append(grad)
return grad
return _hook, "hook"
hook_fn, kind = _make_hook(p)
if kind == "post_accumulate":
p.register_post_accumulate_grad_hook(hook_fn)
else:
p.register_hook(hook_fn)
def finish_gradient_synchronization(self) -> None:
"""
Must be called after loss.backward() and before optimizer.step().
Ensures all async all_reduce ops are completed/queued, then averages grads.
"""
# Wait all outstanding async ops
for h in self._handles:
h.wait()
# Average grads after reduction finished (avoid racing async ops)
if self.world_size > 1:
for g in self._grads:
g.div_(self.world_size)
# Clear for next iteration
self._handles.clear()
self._grads.clear()
测试适配器 [adapters.get_ddp_individual_parameters] 和 [adapters.ddp_individual_parameters_on_after_backward] 的实现如下:
def get_ddp_individual_parameters(module: torch.nn.Module) -> torch.nn.Module:
"""
Returns a torch.nn.Module container that handles
parameter broadcasting and gradient synchronization for
distributed data parallel training.
This container should overlaps communication with backprop computation
by asynchronously communicating gradients as they are ready
in the backward pass. The gradient for each parameter tensor
is individually communicated.
Args:
module: torch.nn.Module
Underlying model to wrap with DDP.
Returns:
Instance of a DDP class.
"""
# For example: return DDPIndividualParameters(module)
from cs336_systems.ddp.ddp_overlap_individual_parameters import DDPIndividualParameters
return DDPIndividualParameters(module)
def ddp_individual_parameters_on_after_backward(ddp_model: torch.nn.Module, optimizer: torch.optim.Optimizer):
"""
Code to run after the backward pass is completed, but before we take
an optimizer step.
Args:
ddp_model: torch.nn.Module
DDP-wrapped model.
optimizer: torch.optim.Optimizer
Optimizer being used with the DDP-wrapped model.
"""
# For example: ddp_model.finish_gradient_synchronization()
ddp_model.finish_gradient_synchronization()
执行 uv run pytest tests/test_ddp_individual_parameters.py 后输出如下:

上述代码实现了一个用于分布式数据并行训练的容器类 DDPIndividualParameters,其目标是在保持 DDP 数值语义正确(梯度平均、与单进程一致)的前提下,将 梯度通信与反向传播计算重叠(overlap),从而降低通信在每步训练中的 “暴露时间”。与 naive DDP(在 backward 完成后再串行 all-reduce 所有参数梯度)相比,本实现的关键差异在于:通信在反向传播过程中按参数粒度尽早启动,并以异步方式发起。
下面我们简单来看下代码是如何实现的:
1) 初始阶段:广播模型权重,保证所有 rank 起点一致
class DDPIndividualParameters(torch.nn.Module):
"""
Overlap DDP (individual parameter gradients):
- __init__: broadcast parameters from rank0, then register post-accumulate grad hooks
- backward: as each parameter's grad becomes ready, launch async all_reduce(grad)
- finish_gradient_synchronization: wait all handles, then average grads
"""
def __init__(self, module: torch.nn.Module):
super().__init__()
if not dist.is_initialized():
raise RuntimeError("Process group not initialized; call dist.init_process_group first.")
self.module = module
self.world_size = dist.get_world_size()
# Handles returned by async all_reduce
self._handles: List[dist.Work] = []
# Grads that correspond to handles
self._grads: List[torch.Tensor] = []
# Make sure all ranks start from the same weights
self._broadcast_from_rank0()
# Register hooks to overlap comm with backprop compute
self._register_grad_ready_hooks()
@torch.no_grad()
def _broadcast_from_rank0(self) -> None:
# Broadcast parameters
for p in self.module.parameters():
dist.broadcast(p.data, src=0)
# Also broadcast buffers (safe default for general modules)
for b in self.module.buffers():
if b is not None and torch.is_tensor(b):
dist.broadcast(b, src=0)
在初始化中,容器首先检查分布式进程组是否已初始化(dist.is_initialized()),随着执行 _broadcast_from_rank0():
- 对所有
module.parameters()的param.data调用dist.broadcast(..., src=0) - 同时对
module.buffers()也进行广播(更通用,避免 buffer 在 rank 间不一致)
这一步保证了所有 rank 在训练开始前具有完全相同的模型状态,从而使后续的 “梯度平均更新” 在数学意义上等价于单进程基线训练。
2) 核心机制:利用 backward hook 捕获 “梯度就绪” 时刻
def _register_grad_ready_hooks(self) -> None:
"""
Use register_post_accumulate_grad_hook if available (preferred),
otherwise fail back to register_hook.
"""
for p in self.module.parameters():
if not p.requires_grad:
continue
# Capture parameter with a factory to avoid late-binding closure bug
def _make_hook(param: torch.Tensor):
# Preferred API (fires after grad accumulation)
if hasattr(param, "register_post_accumulate_grad_hook"):
def _hook(_):
g = param.grad
if g is None:
return
h = dist.all_reduce(g, op=dist.ReduceOp.SUM, async_op=True)
self._handles.append(h)
self._grads.append(g)
return _hook, "post_accumulate"
else:
# Fallback: register_hook receives grad tensor
def _hook(grad: torch.Tensor):
h = dist.all_reduce(grad, op=dist.ReduceOp.SUM, async_op=True)
self._handles.append(h)
self._grads.append(grad)
return grad
return _hook, "hook"
hook_fn, kind = _make_hook(p)
if kind == "post_accumulate":
p.register_post_accumulate_grad_hook(hook_fn)
else:
p.register_hook(hook_fn)
为了在梯度一生成就立刻触发通信,容器在 _register_grad_ready_hooks() 中为每个梯度参数注册 hook。实现优先使用作业推荐的 register_post_accumulate_grad_hook,其语义是当该参数在反向传播中完成梯度累积后立即触发回调,此时 param.grad 已经处于 “就绪(ready)” 状态,非常适合第一时间启动通信。
为了兼容不同版本,代码还提供了降级路径:使用 param.register_hook(收到的参数是 grad tensor)。此外实现采用 _make_hook(param) 的工厂函数形式,避免 Python 闭包的 “循环变量晚绑定” 问题,确保每个 hook 绑定的是正确的参数张量。
3) 异步 all-reduce:让通信与后续反向计算重叠执行
def _hook(_):
g = param.grad
if g is None:
return
h = dist.all_reduce(g, op=dist.ReduceOp.SUM, async_op=True)
self._handles.append(h)
self._grads.append(g)
hook 的内部逻辑是本实现的核心:
1. 取到该参数的梯度张量 g
2. 立刻调用 dist.all_reduce(..., async_op=True) 返回一个通信句柄 h
3. 将 h 与对应的 grad g 记录到容器内部列表中
关键点在于 async_op=True:这会使 all-reduce 调用 不阻塞当前 Python 执行流,从而允许 autograd 在继续计算后续层梯度的同时,已就绪的梯度开始执行通信/排队通信操作。即:
- 反向传播计算(backward compute)
- 梯度同步通信(all-reduce)
在时间轴上尽可能交叠,从而减少 “把通信完整暴露在 step 末尾” 的开销。
4) 在 step 前统一等待并做梯度平均
def finish_gradient_synchronization(self) -> None:
"""
Must be called after loss.backward() and before optimizer.step().
Ensures all async all_reduce ops are completed/queued, then averages grads.
"""
# Wait all outstanding async ops
for h in self._handles:
h.wait()
# Average grads after reduction finished (avoid racing async ops)
if self.world_size > 1:
for g in self._grads:
g.div_(self.world_size)
# Clear for next iteration
self._handles.clear()
self._grads.clear()
虽然通信被分散到 backward 过程中异步启动,但在调用 optimizer.step() 前,仍需确保:
- 所有梯度 all-reduce 已完成
- 梯度被正确地平均
因此容器提供 finish_gradient_synchronization(),训练循环在 loss.backward() 之后显式调用:
1. 对所有 handle 执行 handle.wait():这一步确保异步通信完成/排队完成,从而使后续依赖梯度结果的 optimizer step 是安全的
2. 对所有记录的 grad 执行:grad.div_(world_size),因为 all-reduce 做的是 SUM,需要除以 world_size 得到 “平均梯度”,保持与单进程训练一致的更新幅度
3. 清空 _handles 和 _grads:防止跨 step 混入旧的 handle,保证每轮迭代的通信状态独立。
6. Problem (ddp_overlap_individual_parameters_benchmarking): 1 point
(a) 请对你的 DDP 实现进行性能基准测试,评估在 将反向传播计算与单个参数梯度的通信进行重叠(overlap) 时的训练性能,并将其与此前学习过的两组设置进行对比:
- 最小化 DDP 实现:对每个参数张量分别执行一次 all-reduce
- 批量通信实现:将所有参数张量拼接后执行一次 all-reduce
所有对比应在 相同的实验设置 下完成:1 个节点、2 块 GPU 以及 §1.1.2 中描述的 XL 模型规模
Deliverable:给出在 “反向传播与单参数梯度通信重叠” 条件下,每一次训练迭代的耗时,并用 1-2 句话对比并总结不同实现之间的性能差异。
代码实现如下:
import argparse
import math
import time
from multiprocessing import Manager
from pathlib import Path
from typing import List, Tuple
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
from cs336_basics.optimizer import AdamW
from cs336_basics.nn_utils import cross_entropy_from_logits
from cs336_systems.ddp.bench_naive_ddp import setup, cleanup, sync_if_cuda, build_xl_model, make_fake_batch
from cs336_systems.ddp.ddp_overlap_individual_parameters import DDPIndividualParameters
from cs336_systems.utils import MinimalDDPFlatBenchRow, MinimalDDPFlatBenchmarkReporter
def worker(
rank: int,
world_size: int,
backend: str,
master_addr: str,
master_port: str,
global_batch_size: int,
context_length: int,
warmup_steps: int,
measure_steps: int,
out_proxy,
) -> None:
try:
setup(rank, world_size, backend, master_addr, master_port)
assert world_size == 2, "Standardized to 2 GPUs."
assert backend == "nccl", "Intended for NCCL + CUDA."
torch.cuda.set_device(rank)
device = torch.device(f"cuda:{rank}")
dtype = torch.float32
# base model
model = build_xl_model(device=device, dtype=dtype)
# wrap with overlap-ddp container
ddp_model = DDPIndividualParameters(model)
x, y = make_fake_batch(global_batch_size, context_length, 10000, device=device)
micro_bs = global_batch_size // world_size
x_local = x[rank * micro_bs : (rank + 1) * micro_bs]
y_local = y[rank * micro_bs : (rank + 1) * micro_bs]
loss_fn = cross_entropy_from_logits
opt = AdamW(ddp_model.parameters()) # optimizer sees same params
def run_one_step() -> Tuple[float, float]:
opt.zero_grad(set_to_none=True)
sync_if_cuda(device)
t0 = time.perf_counter()
logits = ddp_model(x_local)
loss = loss_fn(logits, y_local)
loss.backward()
sync_if_cuda(device)
c0 = time.perf_counter()
ddp_model.finish_gradient_synchronization()
sync_if_cuda(device)
c1 = time.perf_counter()
opt.step()
sync_if_cuda(device)
t1 = time.perf_counter()
return (t1 - t0) * 1e3, (c1 - c0) * 1e3
# warmup
for _ in range(warmup_steps):
run_one_step()
dist.barrier()
# measure
step_times: List[float] = []
comm_times: List[float] = []
for _ in range(measure_steps):
s, c = run_one_step()
step_times.append(s)
comm_times.append\(c\)
gathered_steps: List[List[float]] = [None for _ in range(world_size)] # type: ignore
gathered_comms: List[List[float]] = [None for _ in range(world_size)] # type: ignore
dist.all_gather_object(gathered_steps, step_times)
dist.all_gather_object(gathered_comms, comm_times)
if rank == 0:
step_max = [max(gathered_steps[r][i] for r in range(world_size)) for i in range(measure_steps)]
comm_max = [max(gathered_comms[r][i] for r in range(world_size)) for i in range(measure_steps)]
def mean_std(xs: List[float]) -> Tuple[float, float]:
m = sum(xs) / len(xs)
if len(xs) <= 1:
return m, 0.0
var = sum((x - m) ** 2 for x in xs) / (len(xs) - 1)
return m, math.sqrt(var)
step_mean, step_std = mean_std(step_max)
comm_mean, comm_std = mean_std(comm_max)
comm_pct = (comm_mean / step_mean) * 100.0 if step_mean > 0 else 0.0
out_proxy.append(
dict(
variant="overlap",
model_size="xl",
backend=backend,
device="cuda",
world_size=world_size,
dtype="fp32",
global_batch_size=global_batch_size,
micro_batch_size=micro_bs,
context_length=context_length,
warmup_steps=warmup_steps,
measure_steps=measure_steps,
step_mean_ms=step_mean,
step_std_ms=step_std,
comm_mean_ms=comm_mean,
comm_std_ms=comm_std,
comm_pct_mean=comm_pct,
)
)
dist.barrier()
finally:
cleanup()
def main() -> None:
p = argparse.ArgumentParser()
p.add_argument("--global-batch-size", type=int, default=32)
p.add_argument("--context-length", type=int, default=128)
p.add_argument("--warmup-steps", type=int, default=5)
p.add_argument("--measure-steps", type=int, default=20)
p.add_argument("--backend", type=str, default="nccl", choices=["nccl"])
p.add_argument("--world-size", type=int, default=2)
p.add_argument("--master-addr", type=str, default="127.0.0.1")
p.add_argument("--master-port", type=str, default="29540")
p.add_argument("--out-dir", type=str, default="runs/ddp_compare_xl")
args = p.parse_args()
out_dir = Path(args.out_dir)
reporter = MinimalDDPFlatBenchmarkReporter(
jsonl_path=out_dir / "metrics.jsonl",
md_path=out_dir / "table.md",
title="#### DDP benchmarking: per-parameter vs flat vs overlap",
)
with Manager() as manager:
out_rows = manager.list()
mp.spawn(
worker,
args=(
args.world_size,
args.backend,
args.master_addr,
args.master_port,
args.global_batch_size,
args.context_length,
args.warmup_steps,
args.measure_steps,
out_rows,
),
nprocs=args.world_size,
join=True,
)
for r in list(out_rows):
reporter.append(MinimalDDPFlatBenchRow(**r))
reporter.write_markdown()
print(f"[OK] wrote results to {out_dir/'metrics.jsonl'} and {out_dir/'table.md'}")
if __name__ == "__main__":
main()
代码实现比较简单,与之前的 bench_minimal_ddp_flat.py 基准测试脚本保持一致,主要差异是把之前的 sync_fn(model) 换成一个 “overlap DDP 容器” 的行为:
- backward 过程中:grad ready 触发
async all_reduce - step 前:
finish_gradient_synchronization()统一wait并grad /= world_size
运行指令如下:
uv run cs336_systems/ddp/bench_ddp_overlap_individual_parameters.py
执行后输出如下:

结果如下表所示:
| variant | model_size | backend | device | world_size | dtype | global_batch_size | micro_batch_size | context_length | warmup_steps | measure_steps | step_mean_ms | step_std_ms | comm_mean_ms | comm_std_ms | comm_pct_mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| per_param | xl | nccl | cuda | 2 | fp32 | 32 | 16 | 128 | 5 | 20 | 463.725 | 1.241 | 196.602 | 1.362 | 42.396 |
| flat | xl | nccl | cuda | 2 | fp32 | 32 | 16 | 128 | 5 | 20 | 450.054 | 1.388 | 180.638 | 0.481 | 40.137 |
| overlap | xl | nccl | cuda | 2 | fp32 | 32 | 16 | 128 | 5 | 20 | 366.605 | 1.472 | 3.662 | 1.091 | 0.999 |

从整体训练 step 的平均耗时来看,三种实现呈现出明显的性能差异:
- per_parameter:约 463.7 ms / step
- flat:约 450.1 ms / step(相较 per_parameter 减少约 13.7 ms,≈3%)
- overlap:约 366.6 ms / step(相较 per_parameter 减少约 97.1 ms,≈21%)
可以看到,flat 通过减少通信调用次数带来了一定收益,而 overlap 实现则显著降低了单步训练时间,带来的整体加速效果远超前两种实现。
梯度通信阶段的对比更加直观地反映了三种策略的差异:
- per_parameter:
- 通信耗时约 196.6 ms / step
- 通信占比约 42.4%
- flat:
- 通信耗时约 180.6 ms / step
- 通信占比约 40.1%
- overlap:
- 在 step 末尾显式等待的通信时间仅约 3.7 ms / step
- 通信占比降至 约 1.0%
需要注意的是,在 overlap 实现中,comm_mean_ms 仅统计了在 finish_gradient_synchronization() 中 尚未被隐藏、必须显式等待的通信时间。大部分梯度通信已经在反向传播过程中与后续层的梯度计算成功重叠,因此不再体现在 step 末尾的等待时间中,这正是 overlap 设计的核心收益所在。
总的来说,在相同的 1 node x 2 GPU、XL 模型配置下,将反向传播计算与单参数梯度通信进行重叠(overlap)可以将单步训练时间降低约 21%,并将通信在训练 step 中的显式占比约 40% 降至 1% 左右。相比逐参数和 batched all-reduce,overlap 的主要优势在于成功将大部分梯度通信隐藏在反向传播计算过程中,从而显著降低通信对训练性能的影响。
(b) 请在你的基准测试代码中(同样使用 1 节点、2 GPU、XL 模型规模),引入 Nisight profiler,对以下两种实现进行对比分析:
- 初始的 DDP 实现
- 当前这种将反向计算与通信进行重叠的 DDP 实现
通过 可视化方式 对比两条执行轨迹,并提供 profiler 截图,清楚展示其中一种实现能够将计算与通信重叠,而另一种不能
Deliverable:提交两张 profiler 截图,一张来自初始 DDP 实现,一张来自支持计算与通信重叠的 DDP 实现,截图应能够直观展示通信操作是否与反向传播过程发生了重叠。
修改代码如下:
def nvtx_range(msg: str):
if not use_nvtx:
return nullcontext()
if profile and rank != profile_rank:
return nullcontext()
return torch.cuda.nvtx.range(msg)
def run_one_step() -> Tuple[float, float]:
opt.zero_grad(set_to_none=True)
sync_if_cuda(device)
t0 = time.perf_counter()
with nvtx_range("fwd"):
logits = ddp_model(x_local)
with nvtx_range("loss"):
loss = loss_fn(logits, y_local)
with nvtx_range("bwd"):
loss.backward()
sync_if_cuda(device)
c0 = time.perf_counter()
with nvtx_range("finish_grad_sync"):
ddp_model.finish_gradient_synchronization()
sync_if_cuda(device)
c1 = time.perf_counter()
with nvtx_range("opt_step"):
opt.step()
sync_if_cuda(device)
t1 = time.perf_counter()
return (t1 - t0) * 1e3, (c1 - c0) * 1e3
# profiling
if profile:
dist.barrier()
for i in range(profile_steps):
# outer range per iteration
if use_nvtx and rank == profile_rank:
torch.cuda.nvtx.range_push(f"profile_iter_{i}")
run_one_step()
if use_nvtx and rank == profile_rank:
torch.cuda.nvtx.range_pop()
dist.barrier()
return
主要是在 worker 函数中加入 Nsight profiler 相关的功能
profile 脚本如下:
#!/usr/bin/env bash
set -euo pipefail
OUTDIR="runs/ddp_compare_xl"
GBS=32
CTX=128
WARMUP=2
MEASURE=10
PROFILE_STEPS=3
PROFILE_RANK=0
mkdir -p runs
echo "[1/2] Profiling INITIAL (naive per-parameter, no overlap)"
nsys profile -o runs/nsys_initial \
--trace=cuda,nvtx \
--force-overwrite true \
--cpuctxsw=none --sample=none \
uv run python cs336_systems/ddp/bench_naive_ddp.py \
--model-size xl \
--global-batch-size ${GBS} --context-length ${CTX} \
--warmup-steps ${WARMUP} --measure-steps ${MEASURE} \
--backend nccl --world-size 2 --master-addr 127.0.0.1 --master-port 29530 \
--profile --profile-rank ${PROFILE_RANK} --profile-steps ${PROFILE_STEPS} \
--nvtx \
--out-dir ${OUTDIR}
echo "[2/2] Profiling OVERLAP (individual params, async all-reduce)"
nsys profile -o runs/nsys_overlap \
--trace=cuda,nvtx \
--force-overwrite true \
--cpuctxsw=none --sample=none \
uv run python cs336_systems/ddp/bench_ddp_overlap_individual_parameters.py \
--global-batch-size ${GBS} --context-length ${CTX} \
--warmup-steps ${WARMUP} --measure-steps ${MEASURE} \
--backend nccl --world-size 2 --master-addr 127.0.0.1 --master-port 29540 \
--profile --profile-rank ${PROFILE_RANK} --profile-steps ${PROFILE_STEPS} \
--nvtx \
--out-dir ${OUTDIR}
echo "[OK] Done. Open runs/nsys_initial.nsys-rep and runs/nsys_overlap.nsys-rep"
执行该脚本(bash scripts/profile_nsys_ddp.sh)后输出如下:

可以看到 runs 文件夹下成功生成了两个 .nsys-rep 的文件,我们可以使用 Nsight System 工具来查看这些文件
Nsight Systems 分析结果如下图所示:


在初始的 DDP 实现中(第一张图所示),梯度通信在反向传播完全结束之后统一执行,可以清楚地看到 allreduce_grads 阶段严格位于 bwd 之后,并伴随一次显式地 cudaDeviceSynchronize,因此通信开销完整地落在训练关键路径上。
相比之下,在支持计算与通信重叠的 DDP 实现中(第二张图所示),反向传播结束后不再出现一个集中的梯度 all-reduce 阶段。绝大部分梯度通信已在反向传播过程中以异步方式完成,使得在 bwd 结束后只需极短的 finish_grad_sync 即可进入 opt_step。这表明梯度通信被成功地与反向计算过程重叠(少了一次 cudaDeviceSynchronize),从而有效缩短了每次训练迭代的关键路径。
7. Problem (ddp_overlap_bucketed): 8 points
实现一个用于 分布式数据并行训练 的 Python 类,通过 梯度分桶(gradient bucketing)来提升通信效率。该类需要封装任意一个输入的 PyTorch nn.Module,并在训练开始前负责广播模型权重(确保所有 rank 拥有相同的初始参数),同时以 分桶的方式 发起梯度平均的通信操作
我们推荐使用如下公共接口:
def __init__(self, module: torch.nn.Module, bucket_size_mb: float):给定一个已经实例化的 PyTorchnn.Module作为并行对象,构造一个 DDP 容器,用于在各个 rank 之间进行梯度同步。梯度同步应当以 bucket 的形式进行,每个 bucket 中包含的参数总大小不超过bucket_size_mb(以 MB 计)def forward(self, *inputs, **kwargs):使用给定的位置参数和关键字参数,调用被封装模型的forward()方法def finish_gradient_synchronization(self):当该函数被调用时,应等待所有 异步通信操作 在 GPU 上完成排队(queued)
除了新增的 bucket_size_mb 初始化参数之外,该公共接口与之前实现的、对每个参数单独通信的 DDP 实现是保持一致的。我们建议按照 model.parameters() 的 逆序 将参数分配到各个 bucket 中,因为在反向传播中,梯度大致会按照这个顺序逐步就绪
Deliverable:实现一个用于分布式数据并行训练的容器类,该类需要在反向传播计算过程中重叠梯度通信与计算,并且梯度通信必须采用 bucket 化的方式,以减少总体通信调度的次数。为了测试你的实现,请完成以下适配器函数:
- [adapters.get_ddp_bucketed]
- [adapters.ddp_bucketed_on_after_backward](该项为可选,取决于你的实现是否需要)
- [adapters.ddp_bucketed_on_train_batch_start](该项为可选,取决于你的实现是否需要)
然后,通过运行以下命令执行测试:
uv run pytest tests/test_ddp.py
我们建议你多次运行测试(例如 5 次),以确保实现具有足够的稳定性并能够可靠通过。
代码实现如下:
from dataclasses import dataclass
from typing import Dict, List, Optional, Tuple
import torch
import torch.distributed as dist
@dataclass
class _ParamSlice:
bucket_id: int
offset: int
numel: int
shape: torch.Size
dtype: torch.dtype
device: torch.device
class DDPBucketed(torch.nn.Module):
"""
Bucketed + Overlap DDP:
- Broadcast params/buffers from rank0 on init.
- Bucket parameters (reverse order) by size <= bucket_size_mb
- For each param, register post-accumulate hook:
* copy grad into bucket flat buffer slice
* replace param.grad with view into bucket buffer slice
* when a bucket is fully ready, launch async all_reduce on bucket flat buffer
- finish_gradient_synchronization(): wait all bucket handles and divide by world_size
"""
def __init__(self, module: torch.nn.Module, bucket_size_mb: float):
super().__init__()
if not dist.is_initialized():
raise RuntimeError("Process group not initialized.")
self.module = module
self.world_size = dist.get_world_size()
self.bucket_size_bytes = int(bucket_size_mb * 1024 * 1024)
if self.bucket_size_bytes <= 0:
raise ValueError("bucket_size_mb must be > 0")
# Buckets: list of flat buffers + param ids in each bucket
self._bucket_params: List[List[torch.nn.Parameter]] = []
self._bucket_flats: List[Optional[torch.Tensor]] = [] # allocated lazily (first backward)
self._bucket_handles: List[Optional[dist.Work]] = []
self._bucket_pending: List[int] = []
self._bucket_ready: List[List[bool]] = [] # per-bucket per-param ready flags
self._pindex: Dict[int, Tuple[int, int]] = {} # param_id -> (bucket_id, index_in_bucket)
# Mapping id(param) -> slice info
self._pslice: Dict[int, _ParamSlice] = {}
# 1) Broadcast initial states
self._broadcast_from_rank0()
# 2) Build buckets (reverse order)
self._build_buckets()
# 3) Register hooks
self._register_hooks()
# 4) Initialize per-step state
self.on_train_batch_start()
def forward(self, *inputs, **kwargs):
return self.module(*inputs, **kwargs)
@torch.no_grad()
def _broadcast_from_rank0(self) -> None:
for p in self.module.parameters():
dist.broadcast(p.data, src=0)
for b in self.module.buffers():
if b is not None and torch.is_tensor(b):
dist.broadcast(b, src=0)
def _build_buckets(self) -> None:
params = [p for p in self.module.parameters() if p.requires_grad]
# reverse order suggested by prompt
params_rev = list(reversed(params))
buckets: List[List[torch.nn.Parameter]] = []
cur: List[torch.nn.Parameter] = []
cur_bytes = 0
def p_bytes(p: torch.nn.Parameter) -> int:
# element_size may depend on dtype
return p.numel() * p.element_size()
for p in params_rev:
pb = p_bytes(p)
# If adding p would exceed bucket limit, start a new bucket (if current not empty)
if cur and (cur_bytes + pb > self.bucket_size_bytes):
buckets.append(cur)
cur = []
cur_bytes = 0
cur.append(p)
cur_bytes += pb
if cur:
buckets.append(cur)
self._bucket_params = buckets
self._pindex.clear()
self._bucket_flats = [None for _ in buckets]
self._bucket_handles = [None for _ in buckets]
# Precompute slices (offset in elements, not bytes) per param
for b_id, bps in enumerate(self._bucket_params):
offset = 0
for i, p in enumerate(bps):
self._pindex[id(p)] = (b_id, i)
pid = id(p)
self._pslice[pid] = _ParamSlice(
bucket_id=b_id,
offset=offset,
numel=p.numel(),
shape=p.shape,
dtype=p.dtype,
device=p.device,
)
offset += p.numel()
def _ensure_bucket_flat(self, bucket_id: int, ref_grad: torch.Tensor) -> None:
"""
Allocate bucket flat buffer on first use, using grad's dtype/device
"""
if self._bucket_flats[bucket_id] is not None:
return
# total numel in this bucket
total = 0
for p in self._bucket_params[bucket_id]:
total += p.numel()
self._bucket_flats[bucket_id] = torch.empty(
(total,),
device=ref_grad.device,
dtype=ref_grad.dtype,
)
def _register_hooks(self) -> None:
for p in self.module.parameters():
if not p.requires_grad:
continue
pid = id(p)
if pid not in self._pslice:
continue
def _make_hook(param: torch.nn.Parameter):
param_id = id(param)
def _hook(_):
g = param.grad
if g is None:
return
sl = self._pslice[param_id]
b_id = sl.bucket_id
# Allocate bucket flat on first ready grad
self._ensure_bucket_flat(b_id, g)
flat = self._bucket_flats[b_id]
assert flat is not None
# View into flat slice
start = sl.offset
end = start + sl.numel
view = flat[start:end].view(sl.shape)
# Copy grad into bucket storage and redirect param.grad to this view
view.copy_(g)
param.grad = view # optimizer will read from bucket storage
# Mark ready
_, idx_in_bucket = self._pindex[param_id]
if not self._bucket_ready[b_id][idx_in_bucket]:
self._bucket_ready[b_id][idx_in_bucket] = True
self._bucket_pending[b_id] -= 1
# If bucket fully ready, launch async all-reduce now (overlap!)
if self._bucket_pending[b_id] == 0 and self._bucket_handles[b_id] is None:
h = dist.all_reduce(flat, op=dist.ReduceOp.SUM, async_op=True)
self._bucket_handles[b_id] = h
return _hook
# Preferred API
if hasattr(p, "register_post_accumulate_grad_hook"):
p.register_post_accumulate_grad_hook(_make_hook(p))
else:
# Fallback: grad hook receives grad tensor
def _fallback_hook(grad: torch.Tensor, param=p):
# emulate post-accumulate behavior
if grad is None:
return grad
# temporarily set param.grad to grad then call the same logic
param.grad = grad
_make_hook(param)(None)
return param.grad
p.register_hook(_fallback_hook)
def on_train_batch_start(self) -> None:
"""
Optional hook: reset per-step state.
"""
self._bucket_handles = [None for _ in self._bucket_params]
self._bucket_pending = [len(bps) for bps in self._bucket_params]
self._bucket_ready = [[False for _ in bps] for bps in self._bucket_params]
def on_after_backward(self) -> None:
"""
Optional hook: ensure buckets don't get stuck if some params have None grads.
"""
# Fill missing grads as zeros into bucket flats
for b_id, bps in enumerate(self._bucket_params):
if self._bucket_flats[b_id] is None:
# allocate based on first param
p0 = bps[0]
self._bucket_flats[b_id] = torch.zeros(
(sum(p.numel() for p in bps),),
device=p0.device,
dtype=p0.dtype,
)
flat = self._bucket_flats[b_id]
assert flat is not None
for i, p in enumerate(bps):
if self._bucket_ready[b_id][i]:
continue
# If grad is None, set zeros view and mark ready
sl = self._pslice[id(p)]
start = sl.offset
end = start + sl.numel
view = flat[start:end].view(sl.shape)
if p.grad is None:
view.zero_()
p.grad = view
else:
view.copy_(p.grad)
p.grad = view
self._bucket_ready[b_id][i] = True
self._bucket_pending[b_id] -= 1
# Launch if now ready and not launched
if self._bucket_pending[b_id] == 0 and self._bucket_handles[b_id] is None:
self._bucket_handles[b_id] = dist.all_reduce(flat, op=dist.ReduceOp.SUM, async_op=True)
def finish_gradient_synchronization(self) -> None:
"""
Wait for all async all-reduce ops to be queued/completed, then average grads.
Must be called after backward (or after on_after_backward) and before optimizer.step().
"""
# Ensure buckets won't deadlock due to None grads (safe default)
self.on_after_backward()
# Wait all handles
for h in self._bucket_handles:
if h is not None:
h.wait()
# Average
if self.world_size > 1:
for flat in self._bucket_flats:
if flat is not None:
flat.div_(self.world_size)
self.on_train_batch_start()
测试适配器的实现如下:
def get_ddp_bucketed(module: torch.nn.Module, bucket_size_mb: float) -> torch.nn.Module:
"""
Returns a torch.nn.Module container that handles
parameter broadcasting and gradient synchronization for
distributed data parallel training.
This container should overlaps communication with backprop computation
by asynchronously communicating buckets of gradients as they are ready
in the backward pass.
Args:
module: torch.nn.Module
Underlying model to wrap with DDP.
bucket_size_mb: The bucket size, in megabytes. If None, use a single
bucket of unbounded size.
Returns:
Instance of a DDP class.
"""
from cs336_systems.ddp.ddp_overlap_bucketed import DDPBucketed
return DDPBucketed(module, bucket_size_mb)
def ddp_bucketed_on_after_backward(ddp_model: torch.nn.Module, optimizer: torch.optim.Optimizer):
"""
Code to run after the backward pass is completed, but before we take
an optimizer step.
Args:
ddp_model: torch.nn.Module
DDP-wrapped model.
optimizer: torch.optim.Optimizer
Optimizer being used with the DDP-wrapped model.
"""
# For example: ddp_model.finish_gradient_synchronization()
if hasattr(ddp_model, "finish_gradient_synchronization"):
ddp_model.finish_gradient_synchronization()
elif hasattr(ddp_model, "on_after_backward"):
ddp_model.on_after_backward()
def ddp_bucketed_on_train_batch_start(ddp_model: torch.nn.Module, optimizer: torch.optim.Optimizer):
"""
Code to run at the very start of the training step.
Args:
ddp_model: torch.nn.Module
DDP-wrapped model.
optimizer: torch.optim.Optimizer
Optimizer being used with the DDP-wrapped model.
"""
if hasattr(ddp_model, "on_train_batch_start"):
ddp_model.on_train_batch_start()
执行 uv run pytest tests/test_ddp.py 后输出如下:

DDPBucketed 类的目标是同时解决两件事:
1. 减少通信调用次数:不再为每个参数单独 all-reduce,而是把多个参数的梯度合并成若干个 bucket,每个 bucket 对应一个 all-reduce
2. 把通信和反向计算重叠:不像 “flat 一大桶” 必须等整个 backward 完才通信,而是 当某个 bucket 内的所有梯度都就绪时立即异步 all-reduce,从而将通信隐藏在后续层的反向计算之下
下面我们来看下代码实现,重点分析下 Bucket 是如何实现的:
1) 定义 bucket 工作的 “索引表”
@dataclass
class _ParamSlice:
bucket_id: int
offset: int
numel: int
shape: torch.Size
dtype: torch.dtype
device: torch.device
_ParamSlice 给 每个参数 记录了一条 “定位信息”:
- 这个参数属于哪个 bucket(
bucket_id) - 在 bucket 的 flat 1D buffer 里从哪个元素位置开始(
offset) - 这个参数占多少元素(
numel) - 原始形状(
shape),用于把 flat 切片.view(shape)还原 - dtype/device
bucket 的本质是 “把很多梯度拼到一块连续内存里”,而 _ParamSlice 就是每个参数在这块内存里的地址映射表
2) 初始化:广播 + 构建 buckets + 注册 hooks + 初始化 per-step 计数器
def __init__(self, module: torch.nn.Module, bucket_size_mb: float):
super().__init__()
if not dist.is_initialized():
raise RuntimeError("Process group not initialized.")
self.module = module
self.world_size = dist.get_world_size()
self.bucket_size_bytes = int(bucket_size_mb * 1024 * 1024)
if self.bucket_size_bytes <= 0:
raise ValueError("bucket_size_mb must be > 0")
# Buckets: list of flat buffers + param ids in each bucket
self._bucket_params: List[List[torch.nn.Parameter]] = []
self._bucket_flats: List[Optional[torch.Tensor]] = [] # allocated lazily (first backward)
self._bucket_handles: List[Optional[dist.Work]] = []
self._bucket_pending: List[int] = []
self._bucket_ready: List[List[bool]] = [] # per-bucket per-param ready flags
self._pindex: Dict[int, Tuple[int, int]] = {} # param_id -> (bucket_id, index_in_bucket)
# Mapping id(param) -> slice info
self._pslice: Dict[int, _ParamSlice] = {}
# 1) Broadcast initial states
self._broadcast_from_rank0()
# 2) Build buckets (reverse order)
self._build_buckets()
# 3) Register hooks
self._register_hooks()
# 4) Initialize per-step state
self.on_train_batch_start()
我们先看下初始化里创建的 bucket 体系的 “数据结构全家桶” 都各自代表什么含义:
self._bucket_params:每个 bucket 对应一个参数列表(bucket 的 “成员名单”);self._bucket_flats:每个 bucket 对应一个 1D flat tensor(bucket 的 “真实存储”);注意,它一开始是 None,“lazy allocate”,第一次有梯度 ready 才分配self._bucket_handles:每个 bucket 一旦发起dist.all_reduce(..., async_op=True)会得到一个 handle(句柄)放这里,之后finish_gradient_synchronization()会wait()它;self._bucket_pending:每个 bucket 还差多少参数 grad 没 ready,当它减到 0,就触发这个 bucket 的 all_reduce;self._bucket_ready:每个 bucket 内每个参数的 ready flag(避免重复减 pending);self._pindex:hook 里 O(1) 找到某个参数在 bucket 内的序号;self._pslice:切片映射表,决定 param.grad 应该写到 flat 的哪段。
真正的 bucket 就是 _bucket_params + _bucket_flats + _pslice 三者配合,其中 _bucket_flats 是通信对象。
2.1 广播初始权重
@torch.no_grad()
def _broadcast_from_rank0(self) -> None:
for p in self.module.parameters():
dist.broadcast(p.data, src=0)
for b in self.module.buffers():
if b is not None and torch.is_tensor(b):
dist.broadcast(b, src=0)
构造时首先调用 _broadcast_from_rank0 对所有参数 p.data 以及模型的 buffers 执行 dist.broadcast(..., src=0),这样确保每个 rank 在进行训练前拥有一致的初始状态。
2.2 构建 buckets(按参数逆序 + 尺寸上限)
def _build_buckets(self) -> None:
params = [p for p in self.module.parameters() if p.requires_grad]
# reverse order suggested by prompt
params_rev = list(reversed(params))
buckets: List[List[torch.nn.Parameter]] = []
cur: List[torch.nn.Parameter] = []
cur_bytes = 0
def p_bytes(p: torch.nn.Parameter) -> int:
# element_size may depend on dtype
return p.numel() * p.element_size()
for p in params_rev:
pb = p_bytes(p)
# If adding p would exceed bucket limit, start a new bucket (if current not empty)
if cur and (cur_bytes + pb > self.bucket_size_bytes):
buckets.append(cur)
cur = []
cur_bytes = 0
cur.append(p)
cur_bytes += pb
if cur:
buckets.append(cur)
self._bucket_params = buckets
self._pindex.clear()
self._bucket_flats = [None for _ in buckets]
self._bucket_handles = [None for _ in buckets]
# Precompute slices (offset in elements, not bytes) per param
for b_id, bps in enumerate(self._bucket_params):
offset = 0
for i, p in enumerate(bps):
self._pindex[id(p)] = (b_id, i)
pid = id(p)
self._pslice[pid] = _ParamSlice(
bucket_id=b_id,
offset=offset,
numel=p.numel(),
shape=p.shape,
dtype=p.dtype,
device=p.device,
)
offset += p.numel()
_build_buckets() 只挑选 requires_grad 的参数,并按 model.parameters() 的 逆序 进行分组,分组策略是:向当前 bucket 追加参数,直到追加后超过 bucket_size_mb 对应的字节上限就封口开新 bucket。接着为每个参数计算它在 bucket flat 里的 offset(按元素)
2.3 注册 hooks(核心)
def _register_hooks(self) -> None:
for p in self.module.parameters():
if not p.requires_grad:
continue
pid = id(p)
if pid not in self._pslice:
continue
def _make_hook(param: torch.nn.Parameter):
param_id = id(param)
def _hook(_):
g = param.grad
if g is None:
return
sl = self._pslice[param_id]
b_id = sl.bucket_id
# Allocate bucket flat on first ready grad
self._ensure_bucket_flat(b_id, g)
flat = self._bucket_flats[b_id]
assert flat is not None
# View into flat slice
start = sl.offset
end = start + sl.numel
view = flat[start:end].view(sl.shape)
# Copy grad into bucket storage and redirect param.grad to this view
view.copy_(g)
param.grad = view # optimizer will read from bucket storage
# Mark ready
_, idx_in_bucket = self._pindex[param_id]
if not self._bucket_ready[b_id][idx_in_bucket]:
self._bucket_ready[b_id][idx_in_bucket] = True
self._bucket_pending[b_id] -= 1
# If bucket fully ready, launch async all-reduce now (overlap!)
if self._bucket_pending[b_id] == 0 and self._bucket_handles[b_id] is None:
h = dist.all_reduce(flat, op=dist.ReduceOp.SUM, async_op=True)
self._bucket_handles[b_id] = h
return _hook
# Preferred API
if hasattr(p, "register_post_accumulate_grad_hook"):
p.register_post_accumulate_grad_hook(_make_hook(p))
else:
# Fallback: grad hook receives grad tensor
def _fallback_hook(grad: torch.Tensor, param=p):
# emulate post-accumulate behavior
if grad is None:
return grad
# temporarily set param.grad to grad then call the same logic
param.grad = grad
_make_hook(param)(None)
return param.grad
p.register_hook(_fallback_hook)
_register_hooks() 为每个可训练参数注册反向 hook(优先使用 register_post_accumulate_grad_hook,否则 fallback 到 register_hook)。当某个参数的梯度在反向传播中就绪时,hook 主要做三步:
1. 定位参数属于哪个 bucket、对应 flat buffer 的哪段切片(使用 _ParamSlice 中的 offset/numel)
2. 把当前 param.grad copy 进 bucket flat 的切片,并将 param.grad 重定向为这段切片的 view。这样后续对 bucket flat 的归一化操作会自动反映到各个参数的 grad 上
Note:flat buffer 并不会在初始化阶段立刻分配,而是采用 lazy allocate(_ensure_bucket_flat()):当该 bucket 中第一次出现梯度 ready 时,才依据该 bucket 的总 numel 分配 torch.empty(total_numel)
3. 维护 bucket 的 pending 计数,当一个 bucket 内所有参数都已 ready(pending == 0)时,立刻对该 bucket flat 发起 dist.all_reduce(flat, async_op=True) 把通信排队到 GPU 上,从而与后续仍在进行的反向计算形成重叠
这种设计实现了作业要求的两个目标:
- bucket 化:一次通信同步多个参数梯度,减少 all-reduce 调度次数
- overlap:无需等 backward 全部结束,bucket 一凑齐就启动异步通信
2.4 初始化 per-step 计数器
def on_train_batch_start(self) -> None:
"""
Optional hook: reset per-step state.
"""
self._bucket_handles = [None for _ in self._bucket_params]
self._bucket_pending = [len(bps) for bps in self._bucket_params]
self._bucket_ready = [[False for _ in bps] for bps in self._bucket_params]
3) None grad 处理
def on_after_backward(self) -> None:
"""
Optional hook: ensure buckets don't get stuck if some params have None grads.
"""
# Fill missing grads as zeros into bucket flats
for b_id, bps in enumerate(self._bucket_params):
if self._bucket_flats[b_id] is None:
# allocate based on first param
p0 = bps[0]
self._bucket_flats[b_id] = torch.zeros(
(sum(p.numel() for p in bps),),
device=p0.device,
dtype=p0.dtype,
)
flat = self._bucket_flats[b_id]
assert flat is not None
for i, p in enumerate(bps):
if self._bucket_ready[b_id][i]:
continue
# If grad is None, set zeros view and mark ready
sl = self._pslice[id(p)]
start = sl.offset
end = start + sl.numel
view = flat[start:end].view(sl.shape)
if p.grad is None:
view.zero_()
p.grad = view
else:
view.copy_(p.grad)
p.grad = view
self._bucket_ready[b_id][i] = True
self._bucket_pending[b_id] -= 1
# Launch if now ready and not launched
if self._bucket_pending[b_id] == 0 and self._bucket_handles[b_id] is None:
self._bucket_handles[b_id] = dist.all_reduce(flat, op=dist.ReduceOp.SUM, async_op=True)
实际训练中,某些参数在某次迭代可能出现 grad is None(例如条件分支或未参与计算图),如果仅依赖 hook,这些参数永远不会触发 ready 标记,导致所在 bucket 的 pending 无法归零,从而 bucket all-reduce 永远不触发。
因此我们在实现中提供了 on_after_backward() 作为兜底:遍历每个 bucket,把尚未 ready 的参数补齐到 flat buffer 中 — 若 grad is None 写入 0;否则执行同样的 copy + 重定向,并更新 pending,必要时在此阶段补发 all-reduce。
该函数在 finish_gradient_synchronization() 开头被调用,保证任何情况下所有 bucket 都能进入可等待状态。
4) 同步
def finish_gradient_synchronization(self) -> None:
"""
Wait for all async all-reduce ops to be queued/completed, then average grads.
Must be called after backward (or after on_after_backward) and before optimizer.step().
"""
# Ensure buckets won't deadlock due to None grads (safe default)
self.on_after_backward()
# Wait all handles
for h in self._bucket_handles:
if h is not None:
h.wait()
# Average
if self.world_size > 1:
for flat in self._bucket_flats:
if flat is not None:
flat.div_(self.world_size)
self.on_train_batch_start()
finish_gradient_synchronization() 对外体现为 ”训练一步结束前的同步点“,主要职责是:
1. 调用 on_after_backward(),确保所有 bucket 都已发起或补发通信;
2. 对每个 bucket 的异步 handle 执行 wait(),保证梯度同步完成;
3. 由于 all-reduce 默认是 SUM,对每个 bucket flat 执行 div_(world_size) 得到平均梯度;
4. 最后重载 per-step 状态(handles/pending/ready),进入下一迭代。
8. Problem (ddp_bucketed_benchmarking): 3 points
(a) 在与前面实验相同的配置下(1 个节点、2 块 GPU、XL 模型规模),对你实现的 分桶(bucketed)DDP 版本进行性能基准测试,改变 最大 bucket 大小(例如:1、10、100、1000 MB),将这些结果与 未使用分桶机制 的实验结果进行比较 — 你的实验结果是否符合你的预期?如果不符合,原因可能是什么?你可能需要使用 PyTorch profiler 来更深入地理解通信调用是如何被调度和执行的。另外,你认为需要对实验设置做出哪些改变才能使结果更符合你的预期?
Deliverable:给出不同 bucket 大小下,每次训练迭代的测量时间,并用 3-4 句话对实验结果、你的预期以及任何不一致的现象的潜在原因进行说明。
代码实现如下:
import argparse
import math
import time
from multiprocessing import Manager
from pathlib import Path
from typing import List, Tuple, Optional
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
from cs336_basics.optimizer import AdamW
from cs336_basics.nn_utils import cross_entropy_from_logits
from cs336_systems.ddp.bench_naive_ddp import setup, cleanup, sync_if_cuda, build_xl_model, make_fake_batch
from cs336_systems.ddp.ddp_overlap_individual_parameters import DDPIndividualParameters
from cs336_systems.ddp.ddp_overlap_bucketed import DDPBucketed
from cs336_systems.utils import MinimalDDPFlatBenchRow, MinimalDDPFlatBenchmarkReporter
def worker(
rank: int,
world_size: int,
backend: str,
master_addr: str,
master_port: str,
global_batch_size: int,
context_length: int,
warmup_steps: int,
measure_steps: int,
bucket_sizes_mb: List[float],
out_proxy,
) -> None:
try:
setup(rank, world_size, backend, master_addr, master_port)
assert world_size == 2, "Standardized to 2 GPUs for this assignment."
assert backend == "nccl", "Intended for NCCL + CUDA."
torch.cuda.set_device(rank)
device = torch.device(f"cuda:{rank}")
dtype = torch.float32 # keep consistent with your overlap benchmark
# Prepare fixed fake batch (same across variants for fairness)
x, y = make_fake_batch(global_batch_size, context_length, 10000, device=device)
micro_bs = global_batch_size // world_size
x_local = x[rank * micro_bs : (rank + 1) * micro_bs]
y_local = y[rank * micro_bs : (rank + 1) * micro_bs]
loss_fn = cross_entropy_from_logits
def run_variant(variant: str, bucket_mb: Optional[float]) -> None:
# Fresh model per variant to avoid cross-contamination
model = build_xl_model(device=device, dtype=dtype)
if variant == "overlap":
ddp_model = DDPIndividualParameters(model)
elif variant == "bucketed":
assert bucket_mb is not None
ddp_model = DDPBucketed(model, bucket_size_mb=float(bucket_mb))
else:
raise ValueError(f"unknown variant: {variant}")
opt = AdamW(ddp_model.parameters())
def run_one_step() -> Tuple[float, float]:
opt.zero_grad(set_to_none=True)
sync_if_cuda(device)
t0 = time.perf_counter()
logits = ddp_model(x_local)
loss = loss_fn(logits, y_local)
loss.backward()
sync_if_cuda(device)
c0 = time.perf_counter()
# measure "communication tail" after backward
ddp_model.finish_gradient_synchronization()
sync_if_cuda(device)
c1 = time.perf_counter()
opt.step()
sync_if_cuda(device)
t1 = time.perf_counter()
return (t1 - t0) * 1e3, (c1 - c0) * 1e3
# ---------- warmup ----------
for _ in range(warmup_steps):
run_one_step()
dist.barrier()
# ---------- measure ----------
step_times: List[float] = []
comm_times: List[float] = []
for _ in range(measure_steps):
s, c = run_one_step()
step_times.append(s)
comm_times.append(c)
gathered_steps: List[List[float]] = [None for _ in range(world_size)] # type: ignore
gathered_comms: List[List[float]] = [None for _ in range(world_size)] # type: ignore
dist.all_gather_object(gathered_steps, step_times)
dist.all_gather_object(gathered_comms, comm_times)
if rank == 0:
# distributed iteration time is governed by the slowest rank
step_max = [max(gathered_steps[r][i] for r in range(world_size)) for i in range(measure_steps)]
comm_max = [max(gathered_comms[r][i] for r in range(world_size)) for i in range(measure_steps)]
def mean_std(xs: List[float]) -> Tuple[float, float]:
m = sum(xs) / len(xs)
if len(xs) <= 1:
return m, 0.0
var = sum((x - m) ** 2 for x in xs) / (len(xs) - 1)
return m, math.sqrt(var)
step_mean, step_std = mean_std(step_max)
comm_mean, comm_std = mean_std(comm_max)
comm_pct = (comm_mean / step_mean) * 100.0 if step_mean > 0 else 0.0
# encode bucket size into variant string to avoid changing utils.py schema
if variant == "bucketed":
variant_name = f"bucketed_{int(bucket_mb)}mb"
else:
variant_name = "overlap"
out_proxy.append(
dict(
variant=variant_name,
model_size="xl",
backend=backend,
device="cuda",
world_size=world_size,
dtype="fp32",
global_batch_size=global_batch_size,
micro_batch_size=micro_bs,
context_length=context_length,
warmup_steps=warmup_steps,
measure_steps=measure_steps,
step_mean_ms=step_mean,
step_std_ms=step_std,
comm_mean_ms=comm_mean,
comm_std_ms=comm_std,
comm_pct_mean=comm_pct,
)
)
dist.barrier()
# ---- Run baseline + bucket sweeps ----
run_variant("overlap", None)
for b in bucket_sizes_mb:
run_variant("bucketed", float(b))
finally:
cleanup()
def main() -> None:
p = argparse.ArgumentParser()
p.add_argument("--global-batch-size", type=int, default=32)
p.add_argument("--context-length", type=int, default=128)
p.add_argument("--warmup-steps", type=int, default=5)
p.add_argument("--measure-steps", type=int, default=20)
p.add_argument("--bucket-sizes-mb", type=float, nargs="+", default=[1, 10, 100, 1000])
p.add_argument("--backend", type=str, default="nccl", choices=["nccl"])
p.add_argument("--world-size", type=int, default=2)
p.add_argument("--master-addr", type=str, default="127.0.0.1")
p.add_argument("--master-port", type=str, default="29560")
p.add_argument("--out-dir", type=str, default="runs/ddp_bucketed_xl")
args = p.parse_args()
out_dir = Path(args.out_dir)
reporter = MinimalDDPFlatBenchmarkReporter(
jsonl_path=out_dir / "metrics.jsonl",
md_path=out_dir / "table.md",
title="#### DDP bucketed benchmarking: overlap vs bucketed (sweep bucket sizes)",
)
with Manager() as manager:
out_rows = manager.list()
mp.spawn(
worker,
args=(
args.world_size,
args.backend,
args.master_addr,
args.master_port,
args.global_batch_size,
args.context_length,
args.warmup_steps,
args.measure_steps,
args.bucket_sizes_mb,
out_rows,
),
nprocs=args.world_size,
join=True,
)
for r in list(out_rows):
reporter.append(MinimalDDPFlatBenchRow(**r))
reporter.write_markdown()
print(f"[OK] wrote results to {out_dir/'metrics.jsonl'} and {out_dir/'table.md'}")
if __name__ == "__main__":
main()
代码主要对比的是不进行 bucket 时 overlap 的 DDP 实现(即 DDPIndividualParameters)
运行指令如下:
uv run cs336_systems/ddp/bench_ddp_bucketed.py
执行后输出如下:

结果如下表所示:
| variant | model_size | backend | device | world_size | dtype | global_batch_size | micro_batch_size | context_length | warmup_steps | measure_steps | step_mean_ms | step_std_ms | comm_mean_ms | comm_std_ms | comm_pct_mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| overlap | xl | nccl | cuda | 2 | fp32 | 16 | 8 | 128 | 5 | 20 | 312.652 | 9.39 | 4.078 | 0.772 | 1.304 |
| bucketed_1mb | xl | nccl | cuda | 2 | fp32 | 16 | 8 | 128 | 5 | 20 | 322.168 | 14.029 | 5.001 | 1.549 | 1.552 |
| bucketed_10mb | xl | nccl | cuda | 2 | fp32 | 16 | 8 | 128 | 5 | 20 | 310.324 | 5.327 | 3.264 | 0.075 | 1.052 |
| bucketed_100mb | xl | nccl | cuda | 2 | fp32 | 16 | 8 | 128 | 5 | 20 | 298.947 | 3.922 | 2.801 | 0.038 | 0.937 |
| bucketed_1000mb | xl | nccl | cuda | 2 | fp32 | 16 | 8 | 128 | 5 | 20 | 354.389 | 4.205 | 2.935 | 0.668 | 0.828 |

Note:由于硬件显存的限制,博主本次实验设置的 global batch size = 16
实验结果显示,不同 bucket 大小对每次训练迭代的耗时具有显著影响。具体而言,分桶的 overlap DDP 实现每次迭代的平均耗时约为 312.7 ms;当 bucket size 设置为 1 MB 时,迭代时间上升至 322.2 ms;当 bucket size 增大至 10 MB 和 100 MB 时,迭代时间分别下降至 310.3 ms 和 298.9 ms,其中 100 MB 配置取得了最佳性能;而当 bucket size 进一步增大至 1000 MB 时,迭代时间反而显著上升至 354.4 ms。
总体来看,实验结果与预期基本一致:过小的 bucket 会由于 all-reduce 调用次数过多而放大通信调度开销,而过大的 bucket 则会推迟通信启动时机,消弱梯度通信与反向传播之间的重叠效果。中等大小的 bucket(如 10-100 MB)在减少通信调用次数与保留 overlap 能力之间取得了较好的平衡,从而实现了最低的迭代时间。
值得注意的是,在本实验设置下,梯度通信仅占总迭代时间的约 1% 左右,因此 bucket size 对整体性能影响幅度有限。若希望进一步放大 bucket 化策略的收益,可以考虑增大模型规模、序列长度或 world size,从而提升通信在训练关键路径中的占比。
(b) 假设计算一个 bucket 中梯度所需的时间与通信该梯度 bucket 所需的时间是 相同的,在此假设下,写出一个公式用来建模 DDP 的通信开销(即反向传播结束后所额外花费的时间)作为以下变量的函数:
- s s s:模型参数的总大小(字节数)
- w w w:all-reduce 算法的带宽,定义为每个 rank 传输的数据量除以完成一次 all-reduce 所需的时间
- o o o:每一次通信调用所带来的固定开销(秒)
- n b n_b nb:bucket 的数量
在此基础上,再推导出一个公式,用于给出 使 DDP 通信开销最小化的最优 bucket 大小
Deliverable:一个用于建模 DDP 通信开销的公式以及一个用于计算最优 bucket 大小的公式。
通信开销建模推导如下:
设模型参数(梯度)总大小为 s s s(bytes),分成 n b n_b nb 各 bucket,则每个 bucket 的大小为:
b = s n b b = \frac{s}{n_b} b=nbs
一次 bucket 的 all-reduce 时间可分为两部分:
- 带宽项:传输规模为 b b b,按题意用 all-reduce 带宽 w w w(bytes/s)刻画,则耗时 b w \frac{b}{w} wb
- 固定调用开销:每次通信调用带来固定开销 o o o
因此每个 bucket 的通信耗时可写为:
T comm ( b ) = b w + o T_{\text{comm}}(b) = \frac{b}{w} + o Tcomm(b)=wb+o
题目给的关键假设是:计算一个 bucket 梯度所需的时间 = 通信这个 bucket 所需的时间(带宽项)。在这种 “理想平衡流水线” 下,带宽项 b w \frac{b}{w} wb 可以与反向传播计算实现最大程度重叠:除了最后一个 bucket 的通信 “排空(drain)” 之外,其余 bucket 的带宽项基本都被后续计算隐藏掉;但每次通信调用的固定开销 o o o 会随着 bucket 数量线性累积(可理解为每次发起通信的不可忽略调度成本)。
因此,反向传播结束后额外付出的 DDP 通信开销(尾部开销) 可以用下面的模型刻画为:
T overhead ( n b ) = s n b w ⏟ 最后一个 bucket 的带宽排空 + n b o ⏟ 共 n b 次通信调用的固定开销 T_{\text{overhead}}(n_b)=\underbrace{\frac{s}{n_bw}}_{\text{最后一个 bucket 的带宽排空}}+\underbrace{n_bo}_{\text{共 }n_b\text{ 次通信调用的固定开销}} Toverhead(nb)=最后一个 bucket 的带宽排空 nbws+共 nb 次通信调用的固定开销 nbo
上式也直观体现了 bucket 的两种极端:
- n b n_b nb 很大(bucket 很小)时, n b o n_bo nbo 主导,调用开销爆炸;
- n b n_b nb 很小(bucket 很大)时, s n b w \frac{s}{n_bw} nbws 主导,最后排空时间变大(overlap 变差)。
使通信开销最小的最优 bucket 大小推导如下:
对 T overhead ( n b ) = s n b w + n b o T_{\text{overhead}}(n_b)=\frac{s}{n_bw}+n_bo Toverhead(nb)=nbws+nbo 关于 n b n_b nb 求极小值:
d T d n b = − s w n b 2 + o \frac{dT}{dn_b}=-\frac{s}{wn_b^2}+o dnbdT=−wnb2s+o
令导数为 0:
− s w n b 2 + o = 0 ⇒ n b ⋆ = s w o -\frac{s}{wn_b^2}+o=0 \quad\Rightarrow\quad n_b^{\star}=\sqrt{\frac{s}{wo}} −wnb2s+o=0⇒nb⋆=wos
于是最优 bucket 大小 b ⋆ b^{\star} b⋆ 为:
b ⋆ = s n b ⋆ = s s w o = s w o b^\star=\frac{s}{n_b^{\star}} =\frac{s}{\sqrt{\frac{s}{w o}}} =\sqrt{swo} b⋆=nb⋆s=woss=swo
9. Problem (communication_accounting): 10 points
考虑一个新的模型配置 XXL,其参数为:
- d model = 16384 d_{\text{model}}=16384 dmodel=16384
- d ff = 53248 d_{\text{ff}}=53248 dff=53248
- num_blocks = 126 \text{num\_blocks}=126 num_blocks=126
由于该模型规模极大,绝大多数 FLOPs 都来自前馈网络(FFN),因此我们做出一些简化假设:
- 忽略注意力层、输入嵌入层以及输出线性层
- 假设每个 FFN 仅由 两个线性层 组成(忽略激活函数):
- 第一层输入维度为 d model d_{\text{model}} dmodel,输出维度为 d ff d_{\text{ff}} dff
- 第二层输入维度为 d ff d_{\text{ff}} dff,输出维度为 d model d_{\text{model}} dmodel
- 模型由 num_blocks 个这样的 FFN block 组成
- 不使用 activation checkpointing
- 激活值与梯度通信使用 BF16
- 累积梯度、主权重(master weights)以及优化器状态使用 FP32
(a) 在 单个设备 上,以 FP32 精度存储 主模型权重、累积梯度、优化器状态 需要多少显存?同时回答反向传播阶段(这些张量使用 BF16)能节省多少显存?这些显存需求相当于多少张 H100 80GB GPU 的容量?
Deliverable:给出你的计算过程,并用一句话总结结论。
1) 参数量(只计 FFN 两个线性层、忽略 bias)
每个 FFN block 有两层线性层:
- W 1 ∈ R d ff × d model W_1 \in \mathbb{R}^{d_{\text{ff}}\times d_{\text{model}}} W1∈Rdff×dmodel
- W 2 ∈ R d model × d ff W_2 \in \mathbb{R}^{d_{\text{model}}\times d_{\text{ff}}} W2∈Rdmodel×dff
因此每个 block 的参数量:
P block = d ff d model + d model d ff = 2 d model d ff P_{\text{block}} = d_{\text{ff}}d_{\text{model}} + d_{\text{model}}d_{\text{ff}} = 2d_{\text{model}}d_{\text{ff}} Pblock=dffdmodel+dmodeldff=2dmodeldff
代入 d model = 16384 , d ff = 53248 d_{\text{model}}=16384,\ d_{\text{ff}}=53248 dmodel=16384, dff=53248:
d model d ff = 16384 × 53248 = 872,415,232 P block = 2 × 872,415,232 = 1,744,830,464 d_{\text{model}}d_{\text{ff}}=16384\times 53248=872{,}415{,}232 \\ P_{\text{block}}=2\times 872{,}415{,}232=1{,}744{,}830{,}464 dmodeldff=16384×53248=872,415,232Pblock=2×872,415,232=1,744,830,464
总 block 数 = 126 =126 =126,总参数量:
P = 126 × 1,744,830,464 = 219,848,638,464 params ≈ 2.198 × 10 11 P = 126\times 1{,}744{,}830{,}464=219{,}848{,}638{,}464\ \text{params}\approx 2.198\times 10^{11} P=126×1,744,830,464=219,848,638,464 params≈2.198×1011
2) FP32 下主权重、累积梯度、优化器状态显存
题目要求在单设备以 FP32 存储:
- 主权重(master weights):每参数 4B
- 累积梯度(accumulated grads):每参数 4B
- 优化器状态:这里按 Adam 计( m , v m,v m,v 两个 FP32 状态),每参数 2 × 4 = 8 B 2 \times 4 = 8B 2×4=8B
于是每个参数总 FP32 持久开销:
4 + 4 + 8 = 16 bytes/param 4 + 4 + 8 = 16\ \text{bytes/param} 4+4+8=16 bytes/param
总显存(字节):
M FP32 = 16 P = 16 × 219,848,638,464 = 3,517,578,215,424 bytes M_{\text{FP32}} = 16P = 16\times 219{,}848{,}638{,}464 = 3{,}517{,}578{,}215{,}424\ \text{bytes} MFP32=16P=16×219,848,638,464=3,517,578,215,424 bytes
换算成 GiB( 1 GiB = 2 30 bytes 1\ \text{GiB}=2^{30}\ \text{bytes} 1 GiB=230 bytes):
M FP32 = 3,517,578,215,424 2 30 = 3276 GiB ≈ 3.52 TB M_{\text{FP32}}=\frac{3{,}517{,}578{,}215{,}424}{2^{30}}=3276\ \text{GiB}\approx 3.52\ \text{TB} MFP32=2303,517,578,215,424=3276 GiB≈3.52 TB
3) 反向传播阶段改用 BF16 能节省多少?相当于多少张 H100 80GB?
若将上述三类张量都从 FP32 改为 BF16(2B/param),则显存能节省约 3,276 GB / 2 ≈ 1,638 GB 3{,}276 \ \text{GB}/2\approx1{,}638\ \text{GB} 3,276 GB/2≈1,638 GB,这些显存相当于 1,638 GB / 80 ≈ 21.98 1{,}638\ \text{GB} / 80 \approx 21.98 1,638 GB/80≈21.98 约 22 张 H100 80GB
结论
仅 FFN(126 个 block、两层线性)在单卡上用 FP32 存主权重+累积梯度+Adam 优化器状态需要约 3276 GiB 显存;若这些张量在反向传播阶段改用 BF16,则显存需求减半,能节省 1638 GiB 显存,相当于 22 张 H100 80GB。
(b) 现在假设主权重、优化器状态、梯度以及一半的激活值(在实践中通常是每隔一层)被分片(shard)到 N FSDP N_{\text{FSDP}} NFSDP 个设备上,请写成 说明每个设备所需显存 的表达式,同时计算 N FSDP N_{\text{FSDP}} NFSDP 至少需要取多少才能使每个设备的总显存消耗 小于 1 个 v5p TPU(每设备 95GB)
Deliverable:你的计算过程加一句话总结。
先复用 (a) 的结论:仅 FFN 的总参数量:
P = 2 ⋅ d model ⋅ d ff ⋅ num_blocks P = 2\cdot d_{\text{model}}\cdot d_{\text{ff}}\cdot \text{num\_blocks} P=2⋅dmodel⋅dff⋅num_blocks
在本题配置下 P ≈ 2.198 × 10 11 P\approx 2.198\times 10^{11} P≈2.198×1011(我们在 (a) 中已经算出)。
1) 被 FSDP 分片的 “持久张量”(FP32)
题目说 主权重、优化器状态、梯度 都被分片到 N FSDP N_{\text{FSDP}} NFSDP 个设备上,并且使用 FP32,那么这部分总字节数为:
S state = ( 4 + 4 + 8 ) P = 16 P bytes S_{\text{state}} = (4+4+8)P = 16P\ \text{bytes} Sstate=(4+4+8)P=16P bytes
分片后每设备承担:
S state N FSDP \frac{S_{\text{state}}}{N_{\text{FSDP}}} NFSDPSstate
2) 激活(FP16),其中 “一半分片,一半不分片”
题目说 一半的激活值(通常每隔一层)被分片到 N FSDP N_{\text{FSDP}} NFSDP 个设备,这等价于激活张量 A act A_{\text{act}} Aact 中:
- 一半仍然在每张卡上 完整保留: 1 2 A act \frac{1}{2}A_{\text{act}} 21Aact
- 另一半在 FSDP 维度上 均匀分片: 1 2 A act / N FSDP \frac{1}{2}A_{\text{act}}/N_{\text{FSDP}} 21Aact/NFSDP
因此激活部分的每设备显存是:
1 2 A act + 1 2 A act N FSDP \frac{1}{2}A_{\text{act}} + \frac{1}{2}\frac{A_{\text{act}}}{N_{\text{FSDP}}} 21Aact+21NFSDPAact
Note:这里的 A act A_{\text{act}} Aact 需要我们指定 “每设备一次 step 的 token 数”(= 每设备 batch size x 序列长度),才能得到具体数值
3) 合并得到每设备总显存公式
M per-device ( N FSDP ) = 16 P N FSDP ⏟ FP32: master+grad+Adam states + 1 2 A act ⏟ BF16: 不分片那一半激活 + 1 2 A act N FSDP ⏟ BF16: 分片那一半激活 M_{\text{per-device}}(N_{\text{FSDP}})=\underbrace{\frac{16P}{N_{\text{FSDP}}}}_{\text{FP32: master+grad+Adam states}}+\underbrace{\frac{1}{2}A_{\text{act}}}_{\text{BF16: 不分片那一半激活}}+\underbrace{\frac{1}{2}\frac{A_{\text{act}}}{N_{\text{FSDP}}}}_{\text{BF16: 分片那一半激活}} Mper-device(NFSDP)=FP32: master+grad+Adam states NFSDP16P+BF16: 不分片那一半激活 21Aact+BF16: 分片那一半激活 21NFSDPAact
等价为如下形式:
M per-device = 16 P + 1 2 A act N FSDP + 1 2 A act M_{\text{per-device}}=\frac{16P+\tfrac12 A_{\text{act}}}{N_{\text{FSDP}}} + \tfrac12 A_{\text{act}} Mper-device=NFSDP16P+21Aact+21Aact
4. 求 N F S D P N_{FSDP} NFSDP 的最小值(使每设备 < 95GB)
要求:
16 P + 1 2 A act N FSDP + 1 2 A act < 95 GB \frac{16P+\tfrac12 A_{\text{act}}}{N_{\text{FSDP}}} + \tfrac12 A_{\text{act}} < 95\ \text{GB} NFSDP16P+21Aact+21Aact<95 GB
解得:
N FSDP > 16 P + 1 2 A act 95 − 1 2 A act N_{\text{FSDP}}>\frac{16P+\tfrac12 A_{\text{act}}}{95-\tfrac12 A_{\text{act}}} NFSDP>95−21Aact16P+21Aact
因此最小整数解:
N FSDP,min = ⌈ 16 P + 1 2 A act 95 − 1 2 A act ⌉ N_{\text{FSDP,min}}=\left\lceil\frac{16P+\tfrac12 A_{\text{act}}}{95-\tfrac12 A_{\text{act}}}\right\rceil NFSDP,min=⌈95−21Aact16P+21Aact⌉
结论
把 FP32 的主权重+梯度+Adam 状态 和 BF16 激活(其中一半分片)一起考虑时,每设备显存为 M = 16 P + 1 2 A act N FSDP + 1 2 A act \displaystyle M=\frac{16P+\tfrac12A_{\text{act}}}{N_{\text{FSDP}}}+\tfrac12A_{\text{act}} M=NFSDP16P+21Aact+21Aact,因此最小分片数 N FSDP,min = ⌈ 16 P + 1 2 A act 95 − 1 2 A act ⌉ N_{\text{FSDP,min}}=\left\lceil\frac{16P+\tfrac12 A_{\text{act}}}{95-\tfrac12 A_{\text{act}}}\right\rceil NFSDP,min=⌈95−21Aact16P+21Aact⌉,在忽略激活得情况下 至少约 38 张设备 才能把持久状态压到 95GB/卡 以下。
(c) 给定 TPU v5p 的硬件参数(来自《TPU Scaling Book》):
- 通信带宽: W ici = 2.9 × 10 10 W_{\text{ici}}=2.9\times 10^{10} Wici=2.9×1010
- 计算吞吐: C = 4.6 × 10 14 FLOPs/s C=4.6 \times 10^{14} \text{ FLOPs/s} C=4.6×1014 FLOPs/s
并采用以下并行配置(同样遵循《TPU Scaling Book》的记号):
- 设备 mesh: M X = 2 , M Y = 1 ( 2D mesh ) M_X = 2, \ M_Y=1 \ \ (\text{2D mesh}) MX=2, MY=1 (2D mesh)
- FSDP 维度: X = 16 X=16 X=16
- TP(Tensor Parallel)维度: Y = 4 Y=4 Y=4
请回答在该设置下,每个设备对应的 batch size 是多少时恰好是 compute-bound?此时的 总体 batch size 是多少?
Deliverable:给出你的计算过程,并用一句话总结结论。
1) 总设备数与 DP 倍数
- 模型并行组大小为: X ⋅ Y = 16 ⋅ 4 = 64 X\cdot Y = 16\cdot 4=64 X⋅Y=16⋅4=64
- 总设备数为: ( M X ⋅ X ) ⋅ ( M Y ⋅ Y ) = 2 ⋅ 16 ⋅ 1 ⋅ 4 = 128 (M_X\cdot X)\cdot (M_Y\cdot Y)=2\cdot16\cdot1\cdot4=128 (MX⋅X)⋅(MY⋅Y)=2⋅16⋅1⋅4=128
- 数据并行数为: N DP = 128 64 = M X M Y = 2 N_{\text{DP}}=\frac{128}{64}=M_XM_Y=2 NDP=64128=MXMY=2
2) 每设备的计算量(FLOPs)
对于一个线性层 X W XW XW 来说:
- forward matmul: 2 B T d in d out 2BTd_{\text{in}}d_{\text{out}} 2BTdindout
- backward( d X dX dX 与 d W dW dW):各一个同规模 matmul
所有 linear 的总 FLOPs 约为 6 B T d in d out 6BTd_{\text{in}}d_{\text{out}} 6BTdindout
每个 block 有两层,因此每个 block 的训练 FLOPs:
F block ≈ 6 B T d model d ff + 6 B T d ff d model = 12 B T d model d ff F_{\text{block}} \approx 6BTd_{\text{model}}d_{\text{ff}} + 6BTd_{\text{ff}}d_{\text{model}}=12BTd_{\text{model}}d_{\text{ff}} Fblock≈6BTdmodeldff+6BTdffdmodel=12BTdmodeldff
TP 维度 Y = 4 Y=4 Y=4 会把这两层 matmul 的计算按权重分片分摊到 4 个 rank 上,因此每设备 FLOPs 再除以 Y Y Y:
F dev ≈ 12 B T d model d ff ⋅ num_blocks Y F_{\text{dev}} \approx \frac{12BTd_{\text{model}}d_{\text{ff}}\cdot \text{num\_blocks}}{Y} Fdev≈Y12BTdmodeldff⋅num_blocks
令 B dev B_{\text{dev}} Bdev 表示 “每设备每 step 的 token 数”(也就是上式的 B T BT BT),代入相关数值有:
F dev ≈ 3.296 × 10 11 ⏟ FLOPs per token per device ⋅ B dev F_{\text{dev}} \approx \underbrace{3.296\times 10^{11}}_{\text{FLOPs per token per device}}\cdot B_{\text{dev}} Fdev≈FLOPs per token per device 3.296×1011⋅Bdev
因此每设备 compute time:
t comp ( B dev ) = F dev C ≈ 3.296 × 10 11 4.6 × 10 14 B dev ≈ 7.169 × 10 − 4 B dev s t_{\text{comp}}(B_{\text{dev}})=\frac{F_{\text{dev}}}{C}\approx \frac{3.296\times 10^{11}}{4.6\times 10^{14}}B_{\text{dev}}\approx 7.169\times 10^{-4}B_{\text{dev}}\ \text{s} tcomp(Bdev)=CFdev≈4.6×10143.296×1011Bdev≈7.169×10−4Bdev s
3) 每设备的通信量(bytes)
这里主要有两类通信(都走 ICI),并且假定激活与梯度通信用 BF16:
(i) FSDP:每个 block 的权重 all-gather + 梯度 reduce-scatter(与 batch 无关)
每个 block 的参数量是 2 d model d ff 2d_{\text{model}}d_{\text{ff}} 2dmodeldff,通信用 BF16(2 bytes),所以该 block 权重(BF16)大小:
S W = 2 d model d ff ⋅ 2 = 4 d model d ff bytes S_W = 2d_{\text{model}}d_{\text{ff}}\cdot 2 = 4d_{\text{model}}d_{\text{ff}}\ \text{bytes} SW=2dmodeldff⋅2=4dmodeldff bytes
TP=4 下,每个设备只需要该 block 的 1 / Y 1/Y 1/Y 权重分片的 “全量”,因此 all-gather 的目标大小是 S W / Y S_W/Y SW/Y,此外一个 all-gather / reduce-scatter 的每设备通行量还需近似带上 ( X − 1 ) / X (X-1)/X (X−1)/X 系数:
bytes FSDP per block ≈ 2 ⋅ X − 1 X ⋅ S W Y \text{bytes}_{\text{FSDP per block}}\approx 2\cdot \frac{X-1}{X}\cdot \frac{S_W}{Y} bytesFSDP per block≈2⋅XX−1⋅YSW
乘以 126 个 blocks:
bytes FSDP ≈ 2 ⋅ 15 16 ⋅ 4 d model d ff 4 ⋅ 126 = 2 ⋅ 15 16 ⋅ d model d ff ⋅ 126 \text{bytes}_{\text{FSDP}}\approx 2\cdot \frac{15}{16}\cdot \frac{4d_{\text{model}}d_{\text{ff}}}{4}\cdot 126= 2\cdot\frac{15}{16}\cdot d_{\text{model}}d_{\text{ff}}\cdot 126 bytesFSDP≈2⋅1615⋅44dmodeldff⋅126=2⋅1615⋅dmodeldff⋅126
代入数值得到:
bytes FSDP ≈ 2.061 × 10 11 bytes , t FSDP = bytes FSDP W ici ≈ 2.061 × 10 11 2.9 × 10 10 ≈ 7.107 s \text{bytes}_{\text{FSDP}} \approx 2.061\times 10^{11}\ \text{bytes}, \quad t_{\text{FSDP}}=\frac{\text{bytes}_{\text{FSDP}}}{W_{\text{ici}}} \approx \frac{2.061\times10^{11}}{2.9\times10^{10}} \approx 7.107\ \text{s} bytesFSDP≈2.061×1011 bytes,tFSDP=WicibytesFSDP≈2.9×10102.061×1011≈7.107 s
(ii) TP:MLP 内部的张量并行 all-reduce(与 batch 成正比)
在常见的 MLP 张量并行划分(第一层 column-parallel、第二层 row-parallel)中,每个 block 至少会引入一次沿 TP 组的 all-reduce。为了建模 “compute-bound 临界点”,我们用一个简化但常用的近似:每个 block 有约 2 次 all-reduce 规模为 B dev ⋅ d model B_{\text{dev}}\cdot d_{\text{model}} Bdev⋅dmodel 的 BF16 张量(一次 forward / 一次 backward 的关键依赖)。
于是:
bytes TP per block ≈ 2 ⋅ Y − 1 Y ⋅ ( B dev ⋅ d model ⋅ 2 ) \text{bytes}_{\text{TP per block}}\approx 2\cdot \frac{Y-1}{Y}\cdot (B_{\text{dev}}\cdot d_{\text{model}}\cdot 2) bytesTP per block≈2⋅YY−1⋅(Bdev⋅dmodel⋅2)
乘上 126 blocks:
bytes TP ≈ 2 ⋅ 3 4 ⋅ ( B dev ⋅ d model ⋅ 2 ) ⋅ 126 \text{bytes}_{\text{TP}}\approx 2\cdot \frac{3}{4}\cdot (B_{\text{dev}}\cdot d_{\text{model}}\cdot 2)\cdot 126 bytesTP≈2⋅43⋅(Bdev⋅dmodel⋅2)⋅126
换成时间:
t TP ( B dev ) = bytes TP W ici ≈ 2.136 × 10 − 4 B dev s t_{\text{TP}}(B_{\text{dev}})=\frac{\text{bytes}_{\text{TP}}}{W_{\text{ici}}}\approx 2.136\times 10^{-4}B_{\text{dev}}\ \text{s} tTP(Bdev)=WicibytesTP≈2.136×10−4Bdev s
总通信时间:
t comm ( B dev ) = t FSDP + t TP ( B dev ) ≈ 7.107 + 2.136 × 10 − 4 B dev s t_{\text{comm}}(B_{\text{dev}})=t_{\text{FSDP}}+t_{\text{TP}}(B_{\text{dev}}) \approx 7.107 + 2.136\times 10^{-4}B_{\text{dev}}\ \text{s} tcomm(Bdev)=tFSDP+tTP(Bdev)≈7.107+2.136×10−4Bdev s
4) compute-bound 临界点:令计算时间 = 通信时间
compute-bound 的临界点可取:
t comp ( B dev ) = t comm ( B dev ) t_{\text{comp}}(B_{\text{dev}})=t_{\text{comm}}(B_{\text{dev}}) tcomp(Bdev)=tcomm(Bdev)
代入上面的线性模型:
7.169 × 10 − 4 B dev = 7.107 + 2.136 × 10 − 4 B dev 7.169\times 10^{-4}B_{\text{dev}}=7.107 + 2.136\times 10^{-4}B_{\text{dev}} 7.169×10−4Bdev=7.107+2.136×10−4Bdev
移项得:
( 7.169 − 2.136 ) × 10 − 4 B dev = 7.107 ⇒ 5.033 × 10 − 4 B dev = 7.107 ⇒ B dev ≈ 1.412 × 10 4 (7.169-2.136)\times 10^{-4}B_{\text{dev}}=7.107\Rightarrow 5.033\times 10^{-4}B_{\text{dev}}=7.107 \Rightarrow B_{\text{dev}}\approx 1.412\times 10^{4} (7.169−2.136)×10−4Bdev=7.107⇒5.033×10−4Bdev=7.107⇒Bdev≈1.412×104
结论:每设备约需要 B dev ≈ 14,120 B_{\text{dev}}\approx 14{,}120 Bdev≈14,120 个 token/step 才刚好 compute-bound。
由于 N DP = 2 N_{\text{DP}}=2 NDP=2,总体 batch size(总 token 数)为:
B global = N DP ⋅ B dev ≈ 2 ⋅ 14120 ≈ 28,240 tokens/step . B_{\text{global}} = N_{\text{DP}}\cdot B_{\text{dev}}\approx 2\cdot 14120\approx 28{,}240\ \text{tokens/step}. Bglobal=NDP⋅Bdev≈2⋅14120≈28,240 tokens/step.
结论
在 X = 16 X=16 X=16 的 FSDP 与 Y = 4 Y=4 Y=4 的 TP 配置下,FSDP 的权重 all-gather/grad reduce-scatter 带来约 7.1s 的常数通信成本,因此要让训练进入 compute-bound,每张 TPU v5p 需要约 14k tokens/step,对应总体 batch size 约 28k tokens/step(DP=2)。
(d) 在实际训练中,我们希望 总体 batch size 尽可能小,同时始终充分利用计算资源(即避免进入通信瓶颈状态),请回答我们还有哪些技术手段可以在 保持高吞吐率 的同时 降低 batch size 呢?
Deliverable:一句话回答,并用文献引用和公式支持你的论述。
通过 梯度累积(gradient accumulation)或梯度压缩(gradient compression) 等技术可以在保持高吞吐率的同时降低 batch size。梯度累积将 K K K 个微批次(micro-batch)的梯度在本地累积后再进行一次通信,使得通信频率降低为原来的 1 / K 1/K 1/K,从而需满足 K ⋅ T comp ( B ) ≥ T comm ( B ) K \cdot T_{\text{comp}}(B) \geq T_{\text{comm}}(B) K⋅Tcomp(B)≥Tcomm(B) 即可在较小 batch size 下隐藏梯度开销;而梯度压缩(如量化或低秩近似)则通过将通信数据量从 S S S 降低为 α S \alpha S αS( α < 1 \alpha < 1 α<1),直接减少 T comm = α S / W T_{\text{comm}}=\alpha S / W Tcomm=αS/W。
相关分析可参考《TPU Scaling Book》第 5 章关于通信–计算平衡的讨论,以及 Seide et al.《1-bit SGD》、Vogels et al.《PowerSGD》等工作。
10. Problem (optimizer_state_sharding): 15 points
实现一个用于 优化器状态分片(optimizer state sharding)的 Python 类,该类需要封装任意输入的 PyTorch nn.Module,并在每一次优化器 step 之后 负责同步更新后的参数
我们推荐使用如下公共接口:
def __init__(self, params, optimizer_cls: Type[Optimizer], **kwargs):初始化分片后的优化器状态。其中:params:需要被优化的参数集合(或者参数组,如果用户希望对模型的不同部分使用不同的超参数,例如不同的学习率),这些参数将会在所有 rank 之间进行分片optimizer_cls:要被封装的优化器类型,例如optim.AdamW- 其余的关键字参数会被直接传递给
optimizer_cls的构造函数,请确保在该方法中调用torch.optim.Optimizer的父类构造函数
def step(self, closure, **kwargs):使用给定的closure和关键字参数调用被封装优化器的step方法,在参数更新完成之后,需要与其他 rank 进行同步def add_param_group(self, param_group: dict[str, Any]):向分片优化器中添加一个新的参数组。该方法会在分片优化器构造过程中,由父类构造函数调用,在训练过程中也可能被调用(例如模型逐层解冻时),因此,该方法需要能够处理 将模型参数分配到不同 rank 上 的逻辑
Deliverable:实现一个用于处理优化器状态分片的容器类,为了测试你的分片优化器实现,请先实现测试适配器 [adapters.adapters.get_sharded_optimizer],然后运行以下测试命令:
uv run pytest tests/test_sharded_optimizer.py
我们建议你多次运行测试(例如 5 次),以确保实现具有足够的稳定性并能够可靠通过。
代码实现如下:
from typing import Any, Dict, Iterable, List, Type, Union
import torch
import torch.distributed as dist
from torch.optim import Optimizer
ParamGroup = Dict[str, Any]
ParamsLike = Union[Iterable[torch.nn.Parameter], Iterable[ParamGroup]]
def _dist_info() -> tuple[int, int]:
"""Return (rank, world_size). If dist not initialized, treat as single-process."""
if dist.is_available() and dist.is_initialized():
return dist.get_rank(), dist.get_world_size()
return 0, 1
def _normalize_param_groups(params: ParamsLike) -> List[ParamGroup]:
"""
Normalize `params` into a list of param group dicts.
Mirrors torch.optim behavior: either an iterable of Parameters or an iterable of dicts.
"""
if isinstance(params, (list, tuple)) and len(params) > 0 and isinstance(params[0], dict):
# Already param groups
return [dict(g) for g in params] # shallow copy
# Otherwise: treat as flat iterable of parameters
return [{"params": list(params)}]
class SharedOptimizer(Optimizer):
"""
Optimizer state sharding
- shard parameters across ranks
- each rank only maintains optimizer state for its shard
- after local step, broadcast updated parameters from their owning rank
Sharding rule: global_param_index % world_size == owning_rank
Global index is defined by first-seen order across param groups
"""
def __init__(self, params: ParamsLike, optimizer_cls: Type[Optimizer], **kwargs):
self.rank, self.world_size = _dist_info()
self._optimizer_cls = optimizer_cls
self._optimizer_kwargs = dict(kwargs)
# Full (unshared) param groups
normalized_groups = _normalize_param_groups(params)
# Track unique params in a stable global order
self._global_params: List[torch.nn.Parameter] = []
self._param_to_gidx: Dict[torch.nn.Parameter, int] = {}
# Local (shared) param groups used to construct the *real* optimizer on this rank
self._local_param_groups: List[ParamGroup] = []
# IMPORTANT: call parent ctor
super().__init__(normalized_groups, defaults=dict(kwargs))
# Construct the local optimizer that only sees local params
self._local_optimizer: Optimizer = self._optimizer_cls(self._local_param_groups, **self._optimizer_kwargs)
def add_param_group(self, param_group: ParamGroup) -> None:
"""
1) register the full param group into self.param_groups
2) create a filtered local param group (only params owned by this rank) for local optimizer
"""
# --- normalize and validate group
if "params" not in param_group:
raise ValueError("param_group must have a 'params' key")
params = param_group["params"]
if isinstance(params, torch.Tensor):
raise TypeError("param_group['params'] must be an iterable of Parameters, not a Tensor")
params_list = list(params)
# Register full group into this Optimizer
full_group = dict(param_group)
full_group["params"] = params_list
# Use base class machinery to keep invariants
super().add_param_group(full_group)
# --- update global param ordering / indexing
for p in params_list:
if not isinstance(p, torch.nn.Parameter):
raise TypeError(f"Expected torch.nn.Parameter, got {type(p)}")
if p not in self._param_to_gidx:
self._param_to_gidx[p] = len(self._global_params)
self._global_params.append(p)
# --- build local (sharded) group with same hyperparams, but only owned params
local_params: List[torch.nn.Parameter] = []
seen_local: set[torch.nn.Parameter] = set()
for p in params_list:
gidx = self._param_to_gidx[p]
owner = gidx % self.world_size
if owner == self.rank and p not in seen_local:
local_params.append(p)
seen_local.add(p)
local_group = {k: v for k, v in param_group.items() if k != "params"}
local_group["params"] = local_params
self._local_param_groups.append(local_group)
# If local optimizer already exists, update it too
if hasattr(self, "_local_optimizer"):
# torch optimizers support add_param_group
self._local_optimizer.add_param_group(local_group)
@torch.no_grad()
def _broadcast_updated_parameters(self) -> None:
"""Broadcast each parameter tensor from its owning rank to all ranks."""
if self.world_size == 1:
return
# Deterministic order matters for debug/repor, but broadcast itself is per-tensor collective.
for p in self._global_params:
owner = self._param_to_gidx[p] % self.world_size
dist.broadcast(p.data, src=owner)
def step(self, closure=None, **kwargs):
"""
1) run closure (if provided) to compute loss
2) local optimizer step (updates only owned params)
3) broadcast update params from owners
"""
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
# Call local optimizer step
if closure is not None:
try:
self._local_optimizer.step(closure=closure, **kwargs)
except TypeError:
self._local_optimizer.step(**kwargs)
else:
self._local_optimizer.step(**kwargs)
# Sync parameters across ranks
self._broadcast_updated_parameters()
if self.world_size > 1:
dist.barrier()
return loss
def zero_grad(self, set_to_none: bool = True) -> None:
"""
Important: must clear grads for *all* parameters (not only local shard),
otherwise behavior diverges from baseline optimizer in tests.
"""
seen: set[torch.nn.Parameter] = set()
for group in self.param_groups:
for p in group["params"]:
if p in seen:
continue
seen.add(p)
if p.grad is None:
continue
if set_to_none:
p.grad = None
else:
p.grad.detach_()
p.grad.zero_()
def state_dict(self) -> Dict[str, Any]:
"""
Return local optimizer state + metadata.
"""
return {
"rank": self.rank,
"world_size": self.world_size,
"local_optimizer": self._local_optimizer.state_dict(),
}
def load_state_dict(self, state_dict: Dict[str, Any]) -> None:
if "local_optimizer" in state_dict:
self._local_optimizer.load_state_dict(state_dict["local_optimizer"])
else:
raise ValueError("Missing 'local_optimizer' in state_dict")
测试适配器 [adapters.adapters.get_sharded_optimizer] 的实现如下:
def get_sharded_optimizer(params, optimizer_cls: Type[torch.optim.Optimizer], **kwargs) -> torch.optim.Optimizer:
"""
Returns a torch.optim.Optimizer that handles optimizer state sharding
of the given optimizer_cls on the provided parameters.
Arguments:
params (``Iterable``): an ``Iterable`` of :class:`torch.Tensor` s
or :class:`dict` s giving all parameters, which will be sharded
across ranks.
optimizer_class (:class:`torch.nn.Optimizer`): the class of the local
optimizer.
Keyword arguments:
kwargs: keyword arguments to be forwarded to the optimizer constructor.
Returns:
Instance of sharded optimizer.
"""
from cs336_systems.ddp.shared_optimizer import SharedOptimizer
return SharedOptimizer(params, optimizer_cls, **kwargs)
执行 uv run pytest tests/test_sharded_optimizer.py 后输出如下:

SharedOptimizer 类实现的目标是:把优化器状态(optimizer state)按 rank 分片,从而避免在数据并行(DP)训练中每个 rank 都保存一份完整 AdamW 状态带来的显存冗余。它的核心策略非常直接:
1. 参数分片(shard parameters):把模型的参数按照一个确定性的规则分配给不同 rank;
2. 状态分片(shard optimizer states):每个 rank 只为 “自己负责的那部分参数” 创建真实的 optimizer_cls(例如 AdamW),因此只维护这部分参数的一阶/二阶动量等状态;
3. 参数同步(sync updated weights):每次 step() 之后,由 “参数所有者 rank” 把更新后的参数广播(broadcast)给所有 rank,确保所有进程的模型权重在每次优化器更新后仍保持一致。
这样做的关键收益是:optimizer state 的显存近似降低到原来的 1 / world_size 1/\text{world\_size} 1/world_size(在参数规模很大、Adam 状态占用显存显著时收益尤为明显),同时保存与普通 DDP 训练相同的 “每步后所有 rank 权重完全一致” 的语义。
下面我们来简单分析下代码的实现:
1) 初始化:先走父类构造,在构造 local optimizer
class SharedOptimizer(Optimizer):
def __init__(self, params, optimizer_cls, **kwargs):
self.rank, self.world_size = _dist_info()
self._optimizer_cls = optimizer_cls
self._optimizer_kwargs = dict(kwargs)
normalized_groups = _normalize_param_groups(params)
self._global_params = []
self._param_to_gidx = {}
self._local_param_groups = []
# IMPORTANT: call parent ctor
super().__init__(normalized_groups, defaults=dict(kwargs))
# Construct the local optimizer that only sees local params
self._local_optimizer = self._optimizer_cls(self._local_param_groups, **self._optimizer_kwargs)
初始化的流程如下:
1. 先读分布式信息:rank/world_size
2. 把传入的 params 规范化成 param groups(_normalize_param_groups)
3. 调用 super().__init__(...) 父类构造函数来注册全局参数组,再用 _local_param_groups 去创建 self._local_optimizer 保证 local optimizer 只包含本 rank 的参数 shard,从而实现 “状态只在 shard 上建立”。
2) 核心:参数分片 + 本地 group 构造(add_param_group)
2.1 注册全量 group
def add_param_group(self, param_group):
...
params_list = list(params)
full_group = dict(param_group)
full_group["params"] = params_list
super().add_param_group(full_group)
这里先把 “全量参数组” 交给 super().add_param_group,确保 self.param_groups 与普通 PyTorch optimizer 的行为一致(例如学习率等超参的组织方式、去重检查等都沿用父类实现)。
2.2 建立稳定的全局参数顺序(global index)
for p in params_list:
if p not in self._param_to_gidx:
self._param_to_gidx[p] = len(self._global_params)
self._global_params.append(p)
gidx(全局参数序号)按 “首次出现顺序” 分配,保证在所有 rank 上一致。这个稳定顺序对后续同步很关键:所有 rank 会以同样顺序遍历 _global_params,因此 collective 的调用顺序一致,不会出现 rank 间次序不匹配。
2.3 按 gidx % world_size 分配 owner(分片规则)并构造本地 group
local_params = []
seen_local = set()
for p in params_list:
gidx = self._param_to_gidx[p]
owner = gidx % self.world_size
if owner == self.rank and p not in seen_local:
local_params.append(p)
seen_local.add(p)
local_group = {k: v for k, v in param_group.items() if k != "params"}
local_group["params"] = local_params
self._local_param_groups.append(local_group)
这是 state sharding 的 “真正发生之处”,分片规则是 owner = gidx % self.world_size,只有 owner == rank 的参数会进入 local_params,local_group 保留原 group 的超参(lr、weight_decay 等),只是把 params 替换成过滤后的 shard 参数
最终 self._local_param_groups 是给 self._local_optimizer 使用的,所以 local optimizer 只会为这些 shard 参数创建/维护状态。
2.4 支持训练中动态 add groud(如逐层解冻)
if hasattr(self, "_local_optimizer"):
self._local_optimizer.add_param_group(local_group)
3) step():只更新本地 shard,然后广播同步全量参数
@torch.no_grad()
def _broadcast_updated_parameters(self):
if self.world_size == 1:
return
for p in self._global_params:
owner = self._param_to_gidx[p] % self.world_size
dist.broadcast(p.data, src=owner)
def step(self, closure=None, **kwargs):
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
# local optimizer step (updates only owned params)
...
self._local_optimizer.step(...)
# Sync parameters across ranks
self._broadcast_updated_parameters()
if self.world_size > 1:
dist.barrier()
return loss
我们通过 self._local_optimizer.step() 只会更新本 rank 负责的参数(因为 local optimizer 的 param_groups 只包含 shard),更新后调用 _broadcast_updated_parameters(),对应每个参数 p,计算它的 owner rank,然后执行 dist.broadcast(...)
这样做后 每个参数都由其 owner rank 发出 “权威版本” 广播到所有 rank,因此 step 后所有 rank 参数完全一致。dist.barrier() 用作强同步点,让所有 rank 在进入下一轮迭代前都完成广播。
4) 梯度清零:清 “全量参数” 而不是只清 shard
def zero_grad(self, set_to_none: bool = True):
seen = set()
for group in self.param_groups:
for p in group["params"]:
if p in seen:
continue
seen.add(p)
if p.grad is None:
continue
if set_to_none:
p.grad = None
else:
p.grad.detach_()
p.grad.zero_()
尽管优化器状态是分片的,但 梯度的产生(反向传播)在每个 rank 上都会为全模型参数产生/累积 p.grad。如果你只清 shard 参数,非 shard 参数可能残留旧梯度,从而让行为与 baseline optimizer 不一致,所以这里遍历的是 self.param_groups(全量组),并用 seen 去重。
5) 优化器状态保存
def state_dict(self):
return {
"rank": self.rank,
"world_size": self.world_size,
"local_optimizer": self._local_optimizer.state_dict(),
}
def load_state_dict(self, state_dict):
if "local_optimizer" in state_dict:
self._local_optimizer.load_state_dict(state_dict["local_optimizer"])
else:
raise ValueError(...)
因为我们的目标就是 “优化器状态分片”,所以每个 rank 的 state_dict 只包含本 rank shard 的状态,恢复时也只需恢复本地 optimizer 的 state。
该实现通过重写 add_param_group 在父类构造期间同时维护 “全局参数顺序” 和 “本地 shard 参数组”,并在每个 rank 上仅为 shard 参数构造真实 optimizer,从而自然实现 optimizer state sharding。step() 只更新本地 shard 参数,随后对所有参数按 owner rank 逐个 broadcast 以同步更新后的权重,保证各 rank 在每次 step 后保持一致。
11. Problem (optimizer_state_sharding_accounting): 5 points
现在我们已经实现了优化器状态分片(optimizer state sharding),接下来分析它在训练过程中对 峰值显存占用以及运行时开销 的影响
(a) 编写一个脚本,对比 使用与不使用优化器状态分片 时训练语言模型的 峰值显存占用。请在标准配置下进行测试(1 个节点、2 块 GPU、XL 模型规模),并分别报告在 模型初始化完成后、执行 optimizer step 之前以及执行 optimizer step 之后 这三个时刻的峰值显存占用,结果是否与你的预期一致?请进一步拆解每种设置下的显存使用情况,例如:参数占用多少显存、优化器占用多少显存等
Deliverable:用 2-3 句话总结峰值显存占用的结果,并说明显存在不同模型组件和优化器组件之间是如何分配的。
代码实现如下:
import argparse
from multiprocessing import Manager
from pathlib import Path
from typing import Dict, List, Tuple
import statistics
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
from cs336_basics.optimizer import AdamW
from cs336_basics.nn_utils import cross_entropy_from_logits
from cs336_systems.ddp.bench_naive_ddp import setup, cleanup, sync_if_cuda, build_xl_model, make_fake_batch
from cs336_systems.ddp.ddp_overlap_bucketed import DDPBucketed
from cs336_systems.utils import OptimShardMemRow, OptimShardTimeRow, OptimShardMemReporter, OptimShardTimeReporter
def tensor_bytes(t: torch.Tensor) -> int:
return t.numel() * t.element_size()
def module_param_bytes(module: torch.nn.Module) -> int:
seen = set()
total = 0
for p in module.parameters():
if p in seen:
continue
seen.add(p)
total += p.numel() * p.element_size()
return total
def module_grad_bytes(module: torch.nn.Module) -> int:
seen = set()
total = 0
for p in module.parameters():
if p in seen:
continue
seen.add(p)
if p.grad is not None:
total += tensor_bytes(p.grad)
return total
def optimizer_state_bytes(optim) -> int:
"""
Count the visible tensor bytes in optimizer.state.
"""
state = getattr(optim, "state", None)
if state is None:
return 0
total = 0
for _, st in state.items():
if isinstance(st, dict):
for _, v in st.items():
if torch.is_tensor(v):
total += tensor_bytes(v)
return total
def max_memory_mb() -> float:
# max_memory_allocated 是 bytes
return float(torch.cuda.max_memory_allocated()) / (1024**2)
def worker(
rank: int,
world_size: int,
backend: str,
master_addr: str,
master_port: str,
global_batch_size: int,
context_length: int,
bucket_size_mb: float,
dtype_str: str,
mode: str,
warmup_steps: int,
measure_steps: int,
out_proxy,
) -> None:
try:
setup(rank, world_size, backend, master_addr, master_port)
assert world_size == 2, "Standardized to 2 GPUs for this assignment."
assert backend == "nccl", "Intended for NCCL + CUDA."
torch.cuda.set_device(rank)
device = torch.device(f"cuda:{rank}")
if dtype_str == "fp32":
dtype = torch.float32
elif dtype_str == "bf16":
dtype = torch.bfloat16
else:
raise ValueError(f"unsupported dtype: {dtype_str}")
# same fake batch across variants
x, y = make_fake_batch(global_batch_size, context_length, 10000, device=device)
micro_bs = global_batch_size // world_size
x_local = x[rank * micro_bs : (rank + 1) * micro_bs]
y_local = y[rank * micro_bs : (rank + 1) * micro_bs]
loss_fn = cross_entropy_from_logits
def time_one_iter_ms(fn):
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
sync_if_cuda(device)
start.record()
fn()
end.record()
sync_if_cuda(device)
return float(start.elapsed_time(end))
def run_variant(variant: str) -> Dict[str, float]:
# ---- init model & ddp wrapper ----
model = build_xl_model(device=device, dtype=dtype)
ddp_model = DDPBucketed(model, bucket_size_mb=bucket_size_mb)
# ---- build optimizer ----
if variant == "baseline":
opt = AdamW(ddp_model.parameters())
local_opt_for_state = opt
elif variant == "sharded":
from cs336_systems.ddp.shared_optimizer import SharedOptimizer
opt = SharedOptimizer(ddp_model.parameters(), AdamW)
local_opt_for_state = opt._local_optimizer # type: ignore[attr-defined]
else:
raise ValueError(variant)
def one_iter():
opt.zero_grad(set_to_none=True)
logits = ddp_model(x_local)
loss = loss_fn(logits, y_local)
loss.backward()
ddp_model.finish_gradient_synchronization()
opt.step()
if mode == "time":
# warmup
for _ in range(warmup_steps):
one_iter()
# measure
times = [time_one_iter_ms(one_iter) for _ in range(measure_steps)]
return dict(
step_mean_ms=statistics.mean(times),
step_std_ms=statistics.pstdev(times),
)
# ---- record after init peak ----
sync_if_cuda(device)
torch.cuda.reset_peak_memory_stats(device)
sync_if_cuda(device)
peak_after_init = max_memory_mb()
# ---- forward/backward (before step) ----
opt.zero_grad(set_to_none=True)
sync_if_cuda(device)
torch.cuda.reset_peak_memory_stats(device)
logits = ddp_model(x_local)
loss = loss_fn(logits, y_local)
loss.backward()
ddp_model.finish_gradient_synchronization()
sync_if_cuda(device)
peak_before_step = max_memory_mb()
# ---- optimizer step (after step) ----
sync_if_cuda(device)
torch.cuda.reset_peak_memory_stats(device)
opt.step()
sync_if_cuda(device)
peak_after_step = max_memory_mb()
# ---- estimates ----
param_mb = module_param_bytes(ddp_model) / (1024**2)
grad_mb = module_grad_bytes(ddp_model) / (1024**2)
optim_mb = optimizer_state_bytes(local_opt_for_state) / (1024**2)
return dict(
peak_after_init_mb=peak_after_init,
peak_before_step_mb=peak_before_step,
peak_after_step_mb=peak_after_step,
param_mb=param_mb,
grad_mb=grad_mb,
optim_state_mb=optim_mb,
)
res_baseline = run_variant("baseline")
dist.barrier()
res_sharded = run_variant("sharded")
dist.barrier()
gathered: List[Tuple[Dict[str, float], Dict[str, float]]] = [None for _ in range(world_size)] # type: ignore
dist.all_gather_object(gathered, (res_baseline, res_sharded))
if rank == 0:
def reduce_max(key: str, which: int) -> float:
# which: 0 baseline, 1 sharded
vals = []
for r in range(world_size):
vals.append(gathered[r][which][key])
return max(vals)
common = dict(
model_size="xl",
backend=backend,
device="cuda",
world_size=world_size,
dtype=dtype_str,
global_batch_size=global_batch_size,
micro_batch_size=micro_bs,
context_length=context_length,
)
def reduce_max(key: str, which: int) -> float:
vals = [gathered[r][which][key] for r in range(world_size)]
return max(vals)
if mode == "mem":
out_proxy.append({
**common,
"variant": "baseline",
"peak_after_init_mb": reduce_max("peak_after_init_mb", 0),
"peak_before_step_mb": reduce_max("peak_before_step_mb", 0),
"peak_after_step_mb": reduce_max("peak_after_step_mb", 0),
"param_mb": reduce_max("param_mb", 0),
"grad_mb": reduce_max("grad_mb", 0),
"optim_state_mb": reduce_max("optim_state_mb", 0),
})
out_proxy.append({
**common,
"variant": "sharded",
"peak_after_init_mb": reduce_max("peak_after_init_mb", 1),
"peak_before_step_mb": reduce_max("peak_before_step_mb", 1),
"peak_after_step_mb": reduce_max("peak_after_step_mb", 1),
"param_mb": reduce_max("param_mb", 1),
"grad_mb": reduce_max("grad_mb", 1),
"optim_state_mb": reduce_max("optim_state_mb", 1),
})
else:
out_proxy.append({
**common,
"variant": "baseline",
"warmup_steps": warmup_steps,
"measure_steps": measure_steps,
"step_mean_ms": reduce_max("step_mean_ms", 0),
"step_std_ms": reduce_max("step_std_ms", 0),
})
out_proxy.append({
**common,
"variant": "sharded",
"warmup_steps": warmup_steps,
"measure_steps": measure_steps,
"step_mean_ms": reduce_max("step_mean_ms", 1),
"step_std_ms": reduce_max("step_std_ms", 1),
})
dist.barrier()
finally:
cleanup()
def main() -> None:
p = argparse.ArgumentParser()
p.add_argument("--global-batch-size", type=int, default=32)
p.add_argument("--context-length", type=int, default=128)
p.add_argument("--bucket-size-mb", type=float, default=100.0)
p.add_argument("--dtype", type=str, default="fp32", choices=["fp32", "bf16"])
p.add_argument("--mode", type=str, default="mem", choices=["mem", "time"])
p.add_argument("--warmup-steps", type=int, default=5)
p.add_argument("--measure-steps", type=int, default=20)
p.add_argument("--backend", type=str, default="nccl", choices=["nccl"])
p.add_argument("--world-size", type=int, default=2)
p.add_argument("--master-addr", type=str, default="127.0.0.1")
p.add_argument("--master-port", type=str, default="29570")
p.add_argument("--out-dir", type=str, default="")
args = p.parse_args()
if args.out_dir.strip():
out_dir = Path(args.out_dir)
else:
out_dir = Path("runs/optim_state_sharding_xl_mem" if args.mode == "mem"
else "runs/optim_state_sharding_xl_time")
out_dir.mkdir(parents=True, exist_ok=True)
if args.mode == "mem":
reporter = OptimShardMemReporter(
jsonl_path=out_dir / "metrics.jsonl",
md_path=out_dir / "table.md",
title="#### Optimizer state sharding accounting (XL, 1 node x 2 GPU): peak memory at key timestamps",
)
else:
reporter = OptimShardTimeReporter(
jsonl_path=out_dir / "metrics.jsonl",
md_path=out_dir / "table.md",
title="#### Optimizer state sharding accounting (XL, 1 node x 2 GPU): iteration time",
)
with Manager() as manager:
out_rows = manager.list()
mp.spawn(
worker,
args=(
args.world_size,
args.backend,
args.master_addr,
args.master_port,
args.global_batch_size,
args.context_length,
args.bucket_size_mb,
args.dtype,
args.mode,
args.warmup_steps,
args.measure_steps,
out_rows,
),
nprocs=args.world_size,
join=True,
)
for r in list(out_rows):
if args.mode == "mem":
reporter.append(OptimShardMemRow(**r))
else:
reporter.append(OptimShardTimeRow(**r))
reporter.write_markdown()
print(f"[OK] wrote results to {out_dir/'metrics.jsonl'} and {out_dir/'table.md'}")
if __name__ == "__main__":
main()
代码主要对比的是 bucket ddp 的实现下对比使用与不使用优化器状态分片的性能
运行指令如下:
uv run cs336_systems/ddp/bench_optimizer_state_sharding_accounting.py --mode mem
执行后输出如下:

结果如下表所示:
| variant | model_size | dtype | world_size | global_batch_size | micro_batch_size | context_length | peak_after_init_mb | peak_before_step_mb | peak_after_step_mb | param_mb | grad_mb | optim_state_mb |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| baseline | xl | fp32 | 2 | 32 | 16 | 128 | 654.659 | 4786.07 | 2764.18 | 652.69 | 652.69 | 1305.38 |
| sharded | xl | fp32 | 2 | 32 | 16 | 128 | 1998.94 | 6112.23 | 3487.62 | 652.69 | 652.69 | 711.281 |

实验结果显示,优化器状态分片显著降低了每个 rank 上优化器状态(optimizer state)的显存占用,其大小约为未分片版本的 1 / world_size 1/\text{world\_size} 1/world_size,这与理论预期一致。同时,模型参数与梯度的显存占用在两种设置下基本相同,符合仅对优化器状态进行分片的设计目标。
需要注意的是,在 optimizer step 阶段,分片版本由于需要额外执行参数广播操作,引入了短暂的通信缓冲区和同步开销,因此在该阶段观测到的峰值显存占用可能略高于未分片版本,这一阶段性峰值并不反映稳态显存占用情况,也不影响优化器状态分片在长期显存节省方面的有效性。
(b) 优化器状态分片会如何影响速度?在标准配置(1 个节点、2 块 GPU、XL 模型规模)下,分别测量 使用和不使用优化器状态分片 时,每个训练 iteration 所需的时间
Deliverable:用 2-3 句话给出你的计时结果。
运行指令如下:
uv run cs336_systems/ddp/bench_optimizer_state_sharding_accounting.py --mode time
执行后输出如下:

结果如下表所示:
| variant | model_size | dtype | world_size | global_batch_size | micro_batch_size | context_length | warmup_steps | measure_steps | step_mean_ms | step_std_ms |
|---|---|---|---|---|---|---|---|---|---|---|
| baseline | xl | fp32 | 2 | 32 | 16 | 128 | 5 | 20 | 365.941 | 1.96 |
| sharded | xl | fp32 | 2 | 32 | 16 | 128 | 5 | 20 | 450.298 | 2.199 |

从上面的结果中我们可以看到,在标准配置下,baseline(未分片)训练迭代时间约为 365.94±1.96 ms/step,而使用优化器状态分片(sharded)后迭代时间上升到约 450.30±2.20 ms/steps(约 +84ms, +23%)。
这一变慢符合预期:我们的分片优化器每步只在本地更新部分参数后,还需要将更新后的参数在各 rank 间同步,当前实现采用 “逐参数张量 broadcast + barrier” 的方式,会引入大量小规模通信调用的调度开销,从而显著拉长 optimizer().step 阶段的总耗时。总体而言,该方法在降低每 rank 优化器状态显存的同时,以额外的参数同步通信开销为代价,导致吞吐下降。
值得注意的是,如果我们想让 sharded 的训练 iteration 时间减少,一个直接的工程改进是:把需要同步的参数按 bucket flatten 后再通信(把 “很多次小 broadcast” 变成 “少数几次大通信”),从而显著降低 per-call 的固定开销,这也更接近真实系统里 ZeRO-1 的通信编排方式。
(c) 我们实现的优化器状态分片方法与 ZeRO stage 1(在 [Rajbhandari+ 2020] 描述的 ZeRO-DP P o s P_{os} Pos)有何不同?请总结两者的差异,尤其是与 显存占用和通信量 相关的不同点
Deliverable:用 2-3 句话进行总结说明。
我们实现的优化器状态分片方法与 ZeRO stage 1(ZeRO-DP P o s P_{os} Pos)在显存节省目标上是相同的,均通过在不同 rank 之间分片优化器状态来将每个 rank 的优化器显存占用降低至约 1 / world_size 1/\text{world\_size} 1/world_size。
但二者在通信方式上存在显著差异:ZeRO stage 1 在参数更新阶段通过高效的 collective 通信(如 reduce-scatter / all-gather)同步参数更新,通信次数较少且以大张量为主;而我们的简化实现采用逐参数的 broadcast 同步更新参数,引入了更多小规模通信调用,从而带来更高的通信调度开销。
因而,尽管两者在显存占用上效果相近,ZeRO stage 1 在通信效率和整体训练性能上更为优越。
OK,以上就是本次 DDP Training 作业的全部实现了
结语
在本篇文章中,我们从零实现并逐步演进了 CS336 Assignment 2 中完整的 DDP Training 体系,并通过系统性的 benchmark 和 Nsight Systems profiler 验证了各类设计在真实性能上的差异。实现路径从最朴素的 per-parameter all-reduce 出发,依次引入梯度展平(flat)、计算与通信重叠(overlap),最终过渡到兼顾通信粒度与调度时机的 bucketed overlap DDP
实验结果清楚地表明,朴素 DDP 虽然在数学语义上与单进程训练严格等价,但其通信策略在工程上是低效的:大量小规模 all-reduce 使梯度同步成为训练 step 中的主要瓶颈。通过梯度展平减少通信调用次数,可以在不改变训练流程的前提下带来稳定但有限的性能收益;而将梯度通信与反向传播计算进行重叠,则能够显著缩短训练关键路径,使大部分通信开销被隐藏在 backward 过程中;进一步地,bucket 化策略在 flat 与 overlap 之间取得了更合理的平衡:既避免了 per-parameter 方案中过多的通信启动开销,又不必等待整个 backward 完成后再统一通信,从而在保持良好重叠效果的同时提升了通信调度效率
在此基础上,我们进一步实现并分析了 optimizer state sharding,将优化器状态按参数维度分片分布到不同 rank 上,仅在每一步参数更新完成后进行必要的同步。相比标准 DDP 中每个 rank 都完整维护一份优化器状态的做法,该策略显著降低了优化器相关的显存冗余,使训练可扩展性从 “参数显存受限” 进一步推进到 “通信与调度受限”
在 DDP 的通信优化这条主线上,通过一系列实现与对比我们可以看到:DDP 的性能并非由单一因素决定,而是通信粒度、通信时机与计算结构共同作用的结果。这也解释了为什么真实系统(如 PyTorch DDP、FSDP 以及 ZeRO 系列方案)普遍采用 bucket + overlap 的设计范式:它不是理论上的最简形式,却是在工程实践中最稳健、最具性价比的选择;而像 optimizer state sharding 这类方法,则进一步把优化目标从 “时间” 扩展到 “显存冗余”,为更大规模训练铺路
至此,我们完成了 Assignment 2: Systems 中要求的所有作业,下篇文章开始我们将进入 Assignment 3: Scaling 的实现,敬请期待🤗
源码下载链接
参考

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

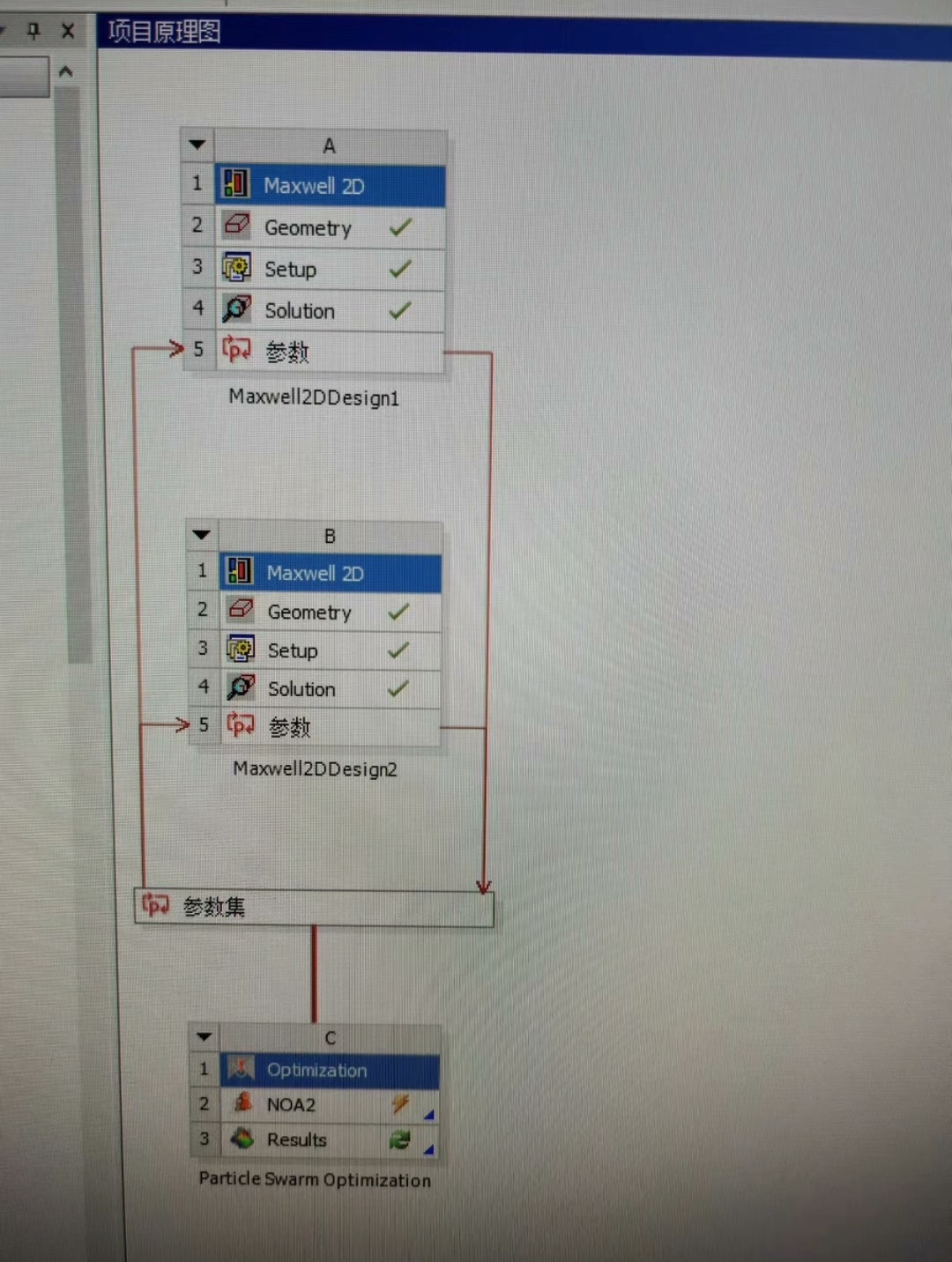
 7
7 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)