2026 年企业级 AI Agent 终极架构蓝图:从聊天机器人到智能自动化的全栈工程化落地
普通的 Chatbot 和企业级 AI Agent,本质上是两个完全不同的物种。聊天机器人的核心能力是 “对话响应”,它的闭环是 “用户提问→LLM 生成回答→返回给用户”,所有能力都围绕着 “对话” 展开;而企业级 AI Agent 的核心能力是 “目标驱动的自主执行”,它的闭环是 “用户给定目标→自主规划拆解任务→调用工具完成执行→校验结果达成目标”,对话只是它的交互方式之一,而非核心。
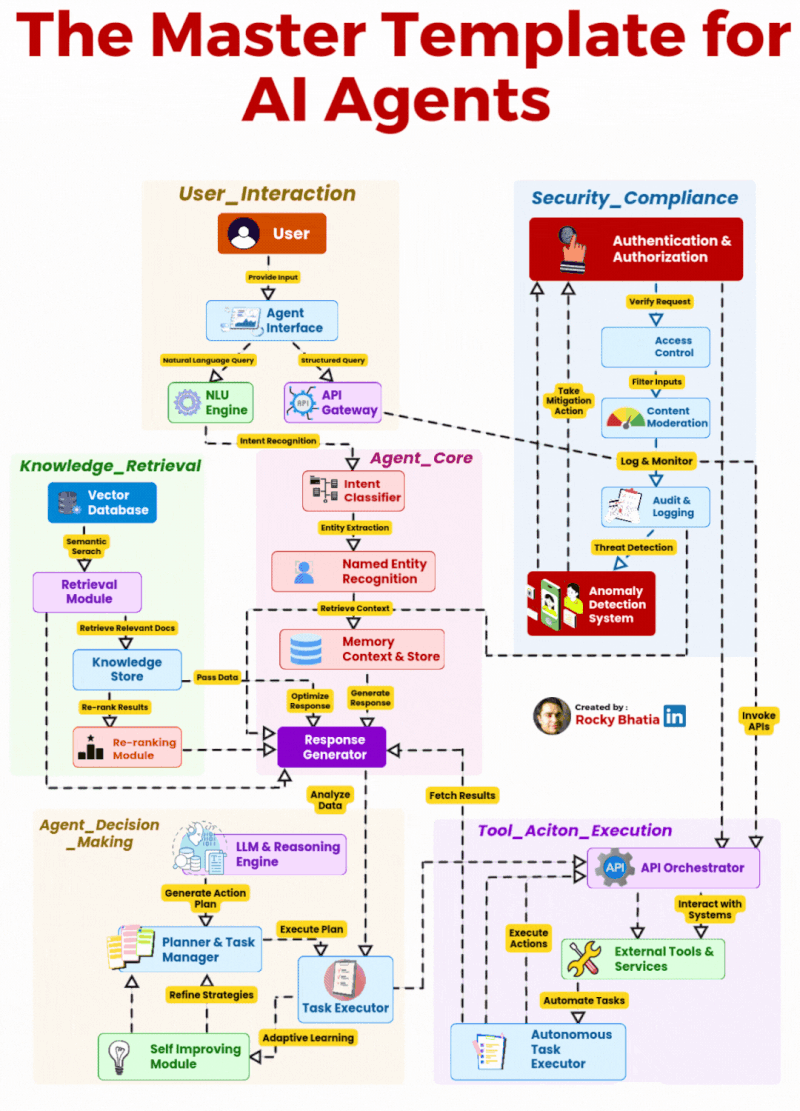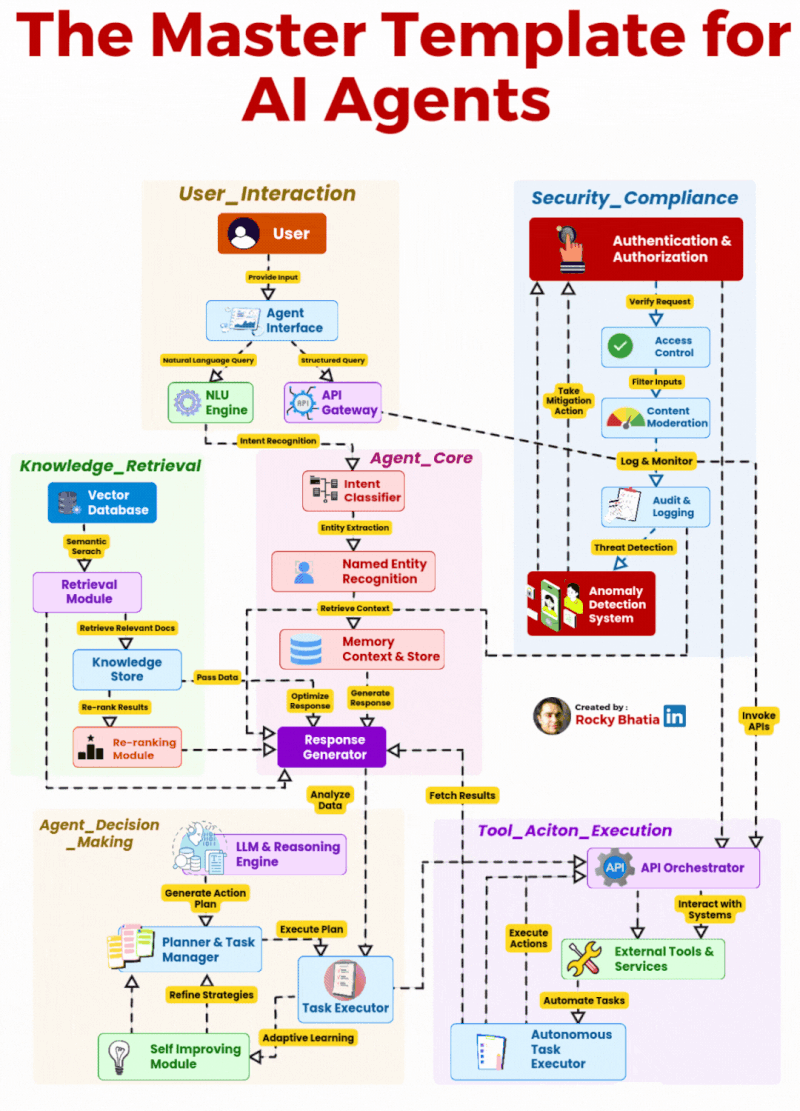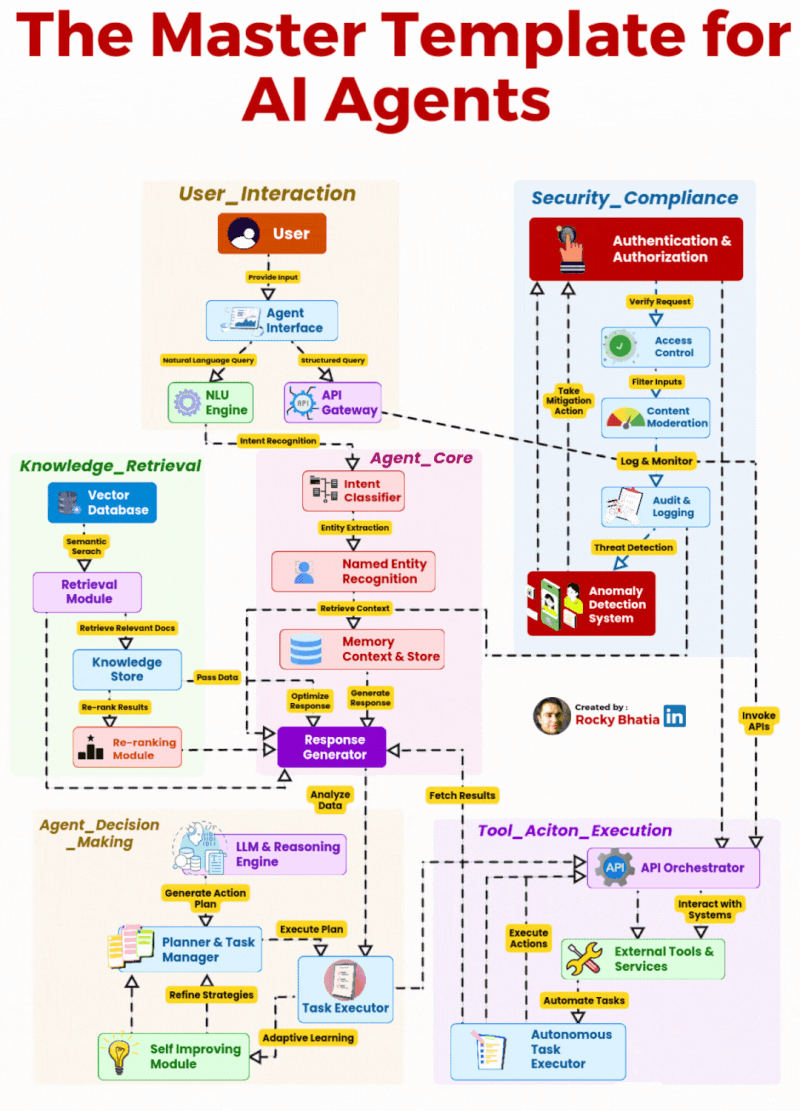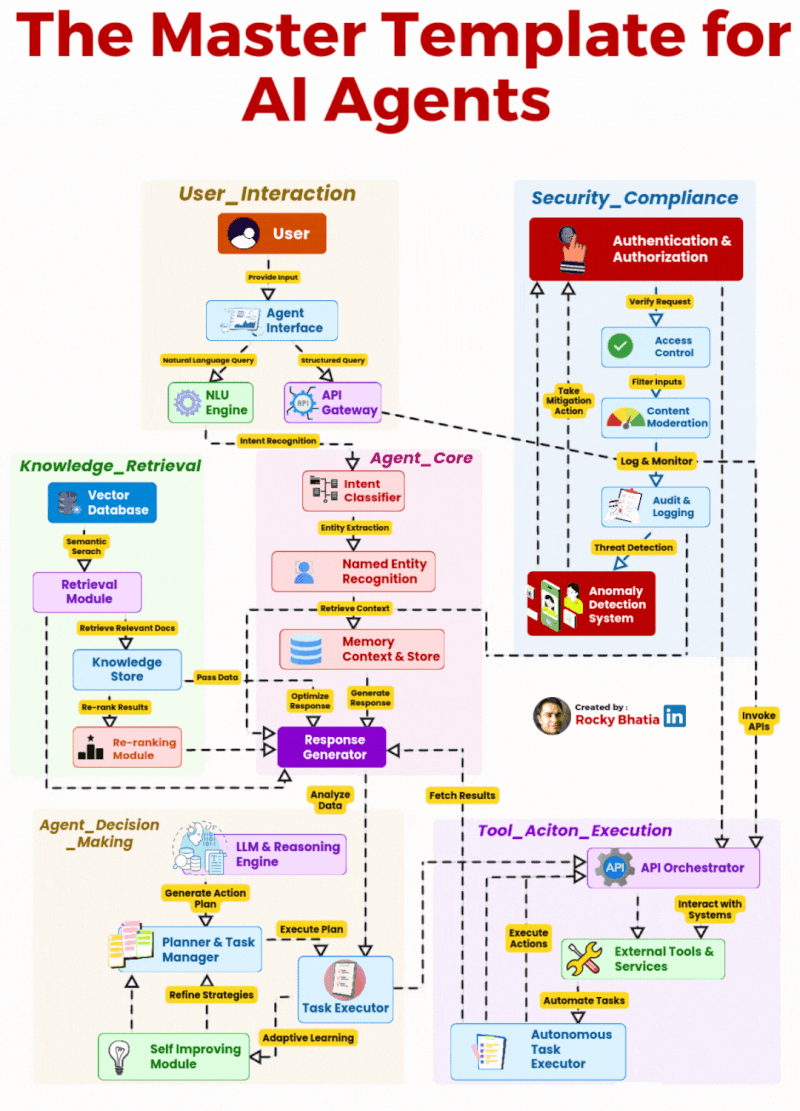
2026 年,AI Agent 已经彻底告别了概念炒作的蛮荒期,全面进入企业级规模化落地的深水区。但行业里始终存在一个致命的认知误区:太多团队把 AI Agent 等同于 “大模型 + 提示词”,觉得只要接入了 GPT、Claude 这类 LLM,就能做出能落地的 Agent。最终的结果往往是:demo 跑得通,一到生产环境就频繁失控、幻觉频发、越权操作、无法处理复杂业务流程,永远停留在玩具阶段。
事实上,AI Agent 的核心从来不是 LLM 本身,而是一套完整的、全链路的编排、推理、执行、安全架构体系。LLM 只是 Agent 的 “大脑皮层”,而一个能真正在企业生产环境中稳定运行的 Agent,需要完整的感官系统、记忆系统、决策系统、执行系统与免疫系统。本文拆解的这套 6 大模块 AI Agent 主模板架构,正是生产级 Agent 的完整工程化蓝图 —— 它覆盖了从用户输入到任务执行、安全管控的端到端全流程,彻底打破了 “Agent 就是聊天机器人” 的认知局限,将 AI Agent 从对话工具,升级为企业智能自动化的核心支柱。
一、重新定义 AI Agent:它不是聊天机器人,是企业智能自动化的全栈系统
在拆解架构之前,我们必须先厘清一个核心认知:普通的 Chatbot 和企业级 AI Agent,本质上是两个完全不同的物种。
聊天机器人的核心能力是 “对话响应”,它的闭环是 “用户提问→LLM 生成回答→返回给用户”,所有能力都围绕着 “对话” 展开;而企业级 AI Agent 的核心能力是 “目标驱动的自主执行”,它的闭环是 “用户给定目标→自主规划拆解任务→调用工具完成执行→校验结果达成目标”,对话只是它的交互方式之一,而非核心。
这也是为什么很多团队的 Agent 永远无法落地:他们只做了对话交互的表层,却没有搭建支撑 Agent 自主执行的完整底层架构。而本文的这套架构蓝图,通过 6 大相互协同的模块,构建了一个完整的、可落地的、安全可控的 Agent 体系,每个模块各司其职,共同实现了 “感知 - 决策 - 执行 - 反馈 - 优化” 的完整智能闭环。
二、AI Agent 架构六大核心模块全拆解
这套架构将企业级 Agent 划分为 6 个相互解耦、又紧密协同的核心模块,从用户交互的入口层,到核心的决策执行层,再到贯穿全链路的安全合规层,形成了一套职责清晰、边界明确的工程化体系。
模块一:User_Interaction(用户交互层)—— Agent 的 “感官系统”,连接用户与核心能力的统一入口
用户交互层是整个 Agent 的 “门面”,也是用户与 Agent 能力交互的唯一入口。它的核心目标,是把不同渠道、不同格式的用户输入,统一转化为 Agent 核心能理解的结构化指令,同时屏蔽底层系统的复杂度,给用户提供极简、一致的交互体验。
核心组件与工作流程
- Agent Interface(统一交互接口):这是用户接触 Agent 的第一触点,它原生支持多渠道的接入能力,包括 WhatsApp/Telegram/ 企业微信 / 飞书等即时通讯渠道、终端 CLI、Web 界面、OpenAPI 等,实现了 “一次开发,多渠道适配”,无论用户从哪个渠道发起请求,都能获得一致的 Agent 能力。
- NLU Engine(自然语言理解引擎):负责处理用户的自然语言输入,完成核心的意图识别、语义理解、歧义消解,把用户模糊的自然语言 query,转化为 Agent 能精准理解的结构化意图。比如用户说 “帮我看看这个客户的合同有没有问题”,NLU 引擎会识别出核心意图是 “合同合规审核”,同时提取出 “客户合同” 这个核心实体。
- API Gateway(API 网关):负责处理结构化的查询与指令请求,实现协议转换、请求路由、流量管控、鉴权预处理,是 Agent 对接企业内部系统、第三方应用的标准化入口,让 Agent 能被其他业务系统直接调用,而非只能通过人工对话触发。
工程落地核心要点
- 输入归一化:无论用户从哪个渠道、以哪种格式输入,都要统一转化为 Agent 核心可处理的标准化结构,避免不同渠道的格式差异影响核心处理逻辑;
- 意图识别的准确率:NLU 引擎的核心是意图分类的精准度,必须针对企业的业务场景做定制化优化,避免意图识别错误导致的执行偏差;
- 交互的低门槛:必须屏蔽底层的技术复杂度,用户只需要用自然语言描述目标,无需关心 Agent 的执行细节,这是 Agent 能被广泛使用的核心。
模块二:Agent_Core(Agent 核心层)—— Agent 的 “中枢神经系统”,全链路的调度与响应生成
Agent 核心层是整个系统的 “交通枢纽”,承接用户交互层的输入,向下调度知识检索、决策执行、工具调用等所有模块,同时负责上下文管理、实体识别与最终响应生成,是整个 Agent 的调度中枢。
核心组件与工作流程
- Intent Classifier(意图分类器):对 NLU 引擎输出的初步意图做精细化分类,匹配对应的处理流程。比如将用户请求分为 “知识问答类”“任务执行类”“闲聊类”“异常请求类”,不同类别的请求分流到不同的模块处理,避免所有请求都走同一套逻辑导致的效率低下与执行错误。
- Named Entity Recognition(命名实体识别,NER):从用户输入与上下文信息中,精准提取核心业务实体,比如人名、企业名、合同编号、时间、地点、产品 ID、系统账号等,为后续的知识检索、工具调用、任务执行提供精准的实体锚点,是 Agent 不 “跑偏” 的核心基础。
- Memory Context & Store(上下文记忆与存储):这是 Agent 的 “短期记忆体”,负责存储当前会话的全量交互历史、任务执行的中间结果、用户的偏好设置、当前任务的状态信息,彻底解决多轮对话、长周期任务中的 “上下文失忆” 问题,保证 Agent 在长任务执行中始终对齐初始目标。
- Response Generator(响应生成器):整合知识检索结果、工具执行结果、上下文信息与用户需求,生成符合格式规范、业务要求、用户预期的最终响应。同时负责优化输出的结构、风格、合规性,避免幻觉与违规内容,保证最终输出的可控性。
工程落地核心要点
- 记忆的精细化管理:必须做好上下文的 Token 管控,通过摘要压缩、非核心信息过滤等方式,避免上下文溢出导致的核心指令丢失,这是长周期任务成功的关键;
- 响应生成的可控性:必须给响应生成器设定明确的边界与格式规范,避免 LLM 自由发挥,保证输出结果完全贴合业务需求;
- 模块解耦:核心层只做调度与整合,不做具体的检索、推理、执行操作,保证架构的可扩展性,后续新增能力无需修改核心层代码。
模块三:Knowledge_Retrieval(知识检索层)—— Agent 的 “长期记忆与知识库”,解决幻觉与知识边界问题
知识检索层是企业级 Agent 的 “长期记忆体”,也是 RAG(检索增强生成)的核心载体。它的核心目标,是为 Agent 提供精准、实时、可靠的企业私有知识,彻底解决大模型的知识截止期、幻觉频发、企业内部知识注入三大核心痛点,是 Agent 能适配企业业务场景的核心基础。
核心组件与工作流程
- Vector Database(向量数据库):存储企业非结构化文档的向量嵌入数据,负责基于语义相似度的快速检索,是整个检索体系的核心底座。它将文档、手册、制度等非结构化内容转化为高维向量,实现毫秒级的语义匹配,找到与用户需求最相关的知识片段。
- Retrieval Module(检索模块):检索能力的执行单元,负责将用户 query、核心实体转化为向量,向向量数据库发起检索请求,同时支持混合检索(向量语义检索 + 关键词精确检索),兼顾语义匹配与实体精确匹配,提升召回率。
- Knowledge Store(知识库):企业的知识资产源头,包括结构化与非结构化的业务数据,比如产品手册、合同模板、公司制度、财务规范、业务数据、API 文档、历史项目案例等,是检索的数据源,也是 Agent 的 “知识弹药库”。
- Re-ranking Module(重排序模块):对初筛的检索结果做精细化的精排与过滤,通过交叉注意力模型、业务规则匹配等方式,过滤掉语义相似但实际无关的内容,将最相关、最核心的知识排在最前面,大幅提升检索的精准度,从根源上减少大模型幻觉。
工程落地核心要点
- 分块策略是检索成功的前提:必须基于文档的语义边界、章节结构做分块,而非固定大小的机械切分,避免分块破坏语义完整性,导致检索结果无效;
- 混合检索是企业级场景的必选项:纯向量检索无法处理精确的实体、编号、日期类查询,必须结合关键词检索,兼顾语义与精度;
- 重排序是提升准确率的关键:初筛解决 “召回” 的问题,重排序解决 “精准” 的问题,企业级场景必须加入重排序环节,才能保证检索结果的可用性。
模块四:Agent_Decision_Making(决策推理层)—— Agent 的 “大脑”,实现从 “响应” 到 “行动” 的跨越
这是 Agent 区别于普通聊天机器人的核心模块,也是整个系统的 “智慧中枢”。它的核心目标,是基于用户的目标,完成逻辑推理、任务规划、执行调度与自我优化,让 Agent 从 “被动响应用户提问”,升级为 “主动完成用户给定的目标”,是实现智能自动化的核心。
核心组件与工作流程
- LLM & Reasoning Engine(大语言模型与推理引擎):决策的核心载体,负责目标理解、逻辑推理、异常分析、结果校验,通过思维链(CoT)、思维树(ToT)、反射(Reflexion)等推理范式,把模糊的大目标拆解为可落地的逻辑步骤,同时对执行结果做合规性、准确性校验。
- Planner & Task Manager(规划器与任务管理器):负责将推理引擎输出的逻辑步骤,转化为可执行的任务计划,拆解为有明确依赖、优先级、时间节点的子任务,同时管理任务的执行状态、进度跟踪、异常重试,是 Agent 任务编排的核心。比如用户要求 “完成月度财务报表生成”,规划器会将其拆解为 “拉取业务数据→数据校验→报表生成→合规校验→同步给负责人”5 个核心子任务,明确每个任务的依赖与执行顺序。
- Task Executor(任务执行器):负责按照任务计划,调度工具执行层的能力,完成每个子任务的执行,同时跟踪每个任务的执行结果,处理执行中的异常、超时、失败重试,将执行结果反馈给推理引擎做校验与下一步决策。
- Self Improving Module(自我优化模块):实现 Agent 的闭环迭代,基于任务执行的结果、用户的反馈、成功 / 失败的案例,自动优化任务规划策略、提示词模板、工具调用逻辑、异常处理机制,让 Agent 越用越好用,执行成功率持续提升。
工程落地核心要点
- 任务拆解的粒度控制:子任务的拆解必须做到 “单一职责、可执行、可校验”,粒度过粗会导致执行失控,粒度过细会导致执行效率低下;
- 异常处理与熔断机制:必须预设任务执行的异常场景,设置重试次数、超时时间、熔断阈值,避免 Agent 陷入无限循环、无限制重试的失控状态;
- 自我优化的边界控制:自我优化必须限定在明确的范围内,禁止 Agent 修改核心执行逻辑、安全规则,避免优化导致的执行失控。
模块五:Tool_Action_Execution(工具执行层)—— Agent 的 “手脚”,实现与真实世界的交互
如果说决策层是 Agent 的大脑,那么工具执行层就是 Agent 的 “手脚”。它的核心目标,是把 Agent 的决策转化为真实世界的动作,打通与外部系统、工具、服务的连接,让 Agent 从 “能说会道” 变成 “能办实事”,是企业级自动化落地的最终载体。
核心组件与工作流程
- API Orchestrator(API 编排器):工具调用的统一中枢,负责管理所有外部 API 与工具的元信息、鉴权信息、调用规范,统一完成参数组装、请求发送、结果解析、错误重试、异常降级,屏蔽不同工具、不同系统的协议差异、格式差异,让上层决策层无需关心工具的底层实现细节。
- External Tools & Services(外部工具与服务):Agent 可调用的外部能力集合,也是 Agent 执行动作的载体,覆盖了企业级场景的全品类需求:
- 数据类工具:数据库、数据仓库、BI 系统;
- 业务系统:CRM、ERP、OA、合同管理系统;
- 沟通工具:企业微信、飞书、邮件、短信;
- 执行类工具:Shell 命令、无头浏览器、文件系统、代码执行环境;
- 第三方服务:地图、天气、合规查询、第三方 API 等。
- Autonomous Task Executor(自主任务执行器):负责无人值守的自动化任务执行,支持定时触发、事件触发、状态触发的自动化任务,比如每日自动生成业务日报、合同到期自动提醒、异常数据自动告警,实现完全脱离人工干预的自主执行,是 Agent 实现企业级自动化的核心能力。
工程落地核心要点
- 工具描述的精准性:工具的功能描述、入参出参定义,直接决定了 LLM 能否正确选择和调用工具,必须清晰、无歧义、贴合业务场景;
- 权限最小化原则:给 Agent 开放的工具权限,必须遵循 “最小可用” 原则,只开放完成任务必须的接口,禁止开放高风险的全量权限,避免越权操作;
- 全链路执行追踪:必须记录每一次工具调用的请求参数、返回结果、执行耗时、异常信息,出现问题时可追溯、可复盘。
模块六:Security_Compliance(安全合规层)—— Agent 的 “免疫系统”,企业级落地的生命线
这是贯穿 Agent 全链路的核心模块,也是个人 demo 与企业级生产系统的核心分界线。很多 Agent demo 无法落地,核心原因就是缺失了这一层 —— 它的核心目标,是实现 Agent 全生命周期的安全管控、合规审计、风险防护,解决企业最关心的权限管控、数据安全、合规审计、恶意攻击防护等核心问题,是 Agent 能在企业环境中稳定运行的生命线。
核心组件与工作流程
- Authentication & Authorization(身份认证与权限管控):安全管控的第一道关口,负责用户的身份校验,确认 “你是谁”;同时基于 RBAC 角色权限模型,做细粒度的权限管控,明确 “你能做什么、不能做什么”,比如普通员工只能调用查询类工具,管理者才能审批操作,严格遵循最小权限原则。
- Access Control(访问控制):基于用户身份与角色,对资源访问、工具调用做实时的过滤与管控,拦截非法的访问请求、越权操作,比如禁止普通员工访问高管的财务数据,禁止非授权用户调用高风险的 Shell 执行工具,从源头规避越权风险。
- Content Moderation(内容审核):负责输入与输出的全链路内容安全,对用户的输入做恶意检测,防范提示词注入、越狱攻击;对 Agent 的输出做合规审核,过滤敏感信息、违规内容、虚假信息,保证 Agent 的输出符合企业规范与监管要求。
- Audit & Logging(审计与日志):全链路记录 Agent 的所有操作,包括用户输入、意图识别、知识检索、工具调用、执行结果、响应输出的全流程信息,不可篡改、可追溯、可复盘,满足金融、政务、医疗等强监管行业的合规审计要求,出现问题时能精准定位根因。
- Anomaly Detection System(异常检测系统):实时监控 Agent 的运行状态与行为,通过规则引擎与机器学习模型,检测异常操作、越权访问、恶意调用、API 成本失控、循环执行等风险,一旦发现异常,立即触发告警、熔断、拦截等 mitigation 动作,避免风险扩大。
工程落地核心要点
- 安全必须前置,而非事后补补丁:安全合规能力必须在架构设计之初就融入全链路,而不是 Agent 开发完成后再打补丁,否则会出现大量的安全漏洞;
- 全链路可审计:企业级 Agent 的每一个操作都必须留下可追溯的日志,这是合规的基本要求,也是出现问题时定位根因的核心依据;
- 提示词注入防护:这是 Agent 最常见的攻击方式,必须在输入层做好检测与过滤,同时通过系统提示词加固、权限最小化等方式,降低注入攻击的风险。
三、端到端闭环:企业级 Agent 的完整执行流程
为了更清晰地展示这套架构的运行逻辑,我们以企业中最常见的「供应商合同审核自动化 Agent」为例,完整走一遍从用户输入到任务完成的全链路闭环:
- 用户交互层:用户在企业微信中给 Agent 发送指令:“帮我审核供应商 A 的这份采购合同,对照公司的采购制度检查合规性,生成审核报告,同步给法务和采购负责人,最后在 OA 里创建审批单”。Agent Interface 接收请求后,NLU Engine 识别出核心意图是 “合同合规审核与流程自动化”,提取出 “供应商 A、采购合同、采购制度、法务、采购负责人、OA 审批单” 等核心实体,将结构化的意图与实体传给 Agent Core。
- Agent Core 层:Intent Classifier 将请求分类为 “任务执行 + 知识检索”,NER 完成实体提取,从记忆库中拉取用户的身份、岗位、权限信息,同时向知识检索层发起 “采购制度、合同审核规范” 的检索请求,向决策层发起任务执行请求。
- 知识检索层:Retrieval Module 将检索 query 向量化,从向量数据库中召回公司的采购管理制度、合同审核标准、供应商准入规则,经过重排序模块精排后,将精准的合规要求传给决策层与响应生成器。
- 决策推理层:LLM 与推理引擎理解用户目标,结合检索到的合规制度,规划出 5 步执行计划:①从合同管理系统读取供应商 A 的合同原文;②对照采购制度完成合规校验,标注风险点;③生成标准化的合同审核报告;④通过飞书将报告同步给法务与采购负责人;⑤在 OA 系统中创建合同审批单。Planner 完成任务拆解与依赖管理后,Task Executor 向工具执行层下发执行指令。
- 工具执行层:API Orchestrator 按照执行计划,依次调用合同管理系统的接口读取合同原文、调用飞书接口发送消息、调用 OA 系统创建审批单,Autonomous Task Executor 完成全流程的任务执行,将每一步的执行结果返回给决策层,推理引擎校验执行结果符合预期后,进入下一步。
- 安全合规层:全流程贯穿安全管控:用户请求先经过身份认证与权限校验,确认用户有合同查看与审批单创建的权限;输入输出经过内容审核,过滤敏感信息;全流程的工具调用、操作行为都被记录到审计日志中;异常检测系统实时监控,没有发现越权操作与异常行为。
- 最终闭环:Agent Core 整合所有执行结果,通过 Response Generator 生成标准化的执行报告,包含合同审核的风险点、同步与审批单创建结果,通过用户交互层返回给用户;同时更新上下文记忆库,自我优化模块基于本次执行的结果,优化后续的合同审核任务拆解逻辑。
四、企业级 AI Agent 落地的核心原则与避坑指南
基于这套架构蓝图,我们总结了 5 个企业级 Agent 落地的核心原则,帮你避开 90% 的团队踩过的坑:
1. 架构必须分层解耦,而非耦合堆砌
这套架构的核心优势,就是每个模块职责单一、边界清晰,层与层之间通过标准化的接口交互。比如更换向量数据库,不会影响 Agent 核心层;更换底层 LLM,不会影响工具执行层;新增一个工具,无需修改决策层的代码。很多团队的 Agent 最终无法维护,就是因为把所有逻辑都耦合在一起,变成了 “屎山代码”,新增一个功能就要推翻重写。
2. 安全合规必须前置,而非事后补救
企业级 Agent 的红线,永远是安全与合规。很多团队先做功能实现,再补安全能力,最终导致 Agent 出现数据泄露、越权操作、合规违规等致命问题,直接被业务部门叫停。这套架构将安全合规层贯穿全链路,从设计之初就把权限管控、审计日志、内容安全、异常检测融入每个环节,这是 Agent 能从 demo 走向生产的核心前提。
3. 记忆体系必须分层设计,避免 “失忆” 与 “溢出”
Agent 的记忆能力,直接决定了长周期任务的成功率。必须做好记忆的分层设计:用上下文记忆库存储短期会话信息,用向量知识库存储长期知识,用执行日志存储任务历史,不同类型的记忆分开管理、按需调用。既避免了上下文溢出导致的核心指令丢失,又能让 Agent 在需要时精准召回相关知识,彻底解决 “失忆” 问题。
4. 必须做可控的自主执行,而非无限制的自治
企业级 Agent 的核心价值是自动化,而非无限制的 “自治”。必须给 Agent 设定明确的执行边界、权限范围、异常熔断规则,高风险操作必须设置人工审批节点,绝对不能让 Agent 拥有无限制的工具调用权限与执行权限。否则,Agent 很容易出现失控操作,给企业带来无法挽回的损失。
5. 可观测性是生产落地的前提
一个无法被监控、无法被追踪的 Agent,绝对不能上生产环境。必须在架构中内置全链路的可观测性能力,包括日志、指标、追踪、告警四大核心能力,实时监控 Agent 的执行成功率、工具调用准确率、响应耗时、API 成本等核心指标,出现问题能快速定位根因,而不是面对一个黑盒,连哪里出错了都不知道。
结语
2026 年,AI Agent 的竞争,早已不是 “用不用更强大的 LLM” 的竞争,而是底层架构设计的竞争。再强大的大模型,没有一套完整、稳定、安全的架构体系支撑,也只能是一个 “只会说话的玩具”,无法为企业创造真正的业务价值。
这套 6 大模块的 AI Agent 架构蓝图,本质上是企业级 Agent 的通用落地模板 —— 它把复杂的智能自动化体系,拆解为职责清晰、可落地、可扩展的模块,帮你彻底跳出 “demo 永远跑不通生产” 的困境。
未来,AI Agent 不会只是企业里的 “聊天助手”,它会成为企业智能自动化的核心支柱,渗透到采购、财务、销售、运营、研发的每一个业务流程里。而能真正驾驭 Agent 的,永远是那些懂业务、懂架构,能把 AI 能力与业务流程深度结合的人。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献82条内容
已为社区贡献82条内容

所有评论(0)