玩转 asc-devkit 库:CANN 上的“一站式”算子开发与部署利器
operator:inputs:outputs:compute:# GELU 近似公式:0.5x(1 + tanh(√(2/π)(x + 0.044715x³)))asc-devkit 是 CANN 生态中“算子开发民主化” 的关键推手——它将复杂的底层工程细节封装为可视化工具与自动化流程,让开发者从“硬件适配”中解放出来,聚焦算法创新。对于需要快速迭代自定义算子的团队(如科研机构、AI 初创公
在深度学习与高性能计算领域,自定义算子开发往往是连接前沿算法与硬件极致性能的桥梁。然而,传统算子开发流程繁琐:需手动编写 CUDA/ACL 代码、处理内存管理、适配不同硬件后端、调试性能瓶颈……每一步都可能耗费大量精力。华为 CANN 生态中的 asc-devkit 库(全称 “Ascend Custom Operator Development Kit”),正是为解决这一痛点而生——它是一套 面向 CANN 硬件的“一站式”算子开发工具链,将算子开发从“手工编码”升级为“可视化配置+自动化生成+一键部署”,让开发者聚焦算法逻辑,而非底层工程细节。今天,我们就来揭开这个“算子开发加速器”的神秘面纱。
一、asc-devkit 是什么?为什么需要它?
asc-devkit 是 CANN 提供的 自定义算子全生命周期开发工具包,覆盖从 算子设计→代码生成→调试优化→部署集成 的完整流程。其核心定位是:降低 CANN 算子开发门槛,提升开发效率,让“算法工程师也能快速写出高性能算子”。
传统算子开发的痛点
在没有 asc-devkit 的时代,开发一个 CANN 自定义算子需经历:
-
手动编写多语言代码:前端(Python/C++)接口、后端(ACL/汇编)实现、内存管理逻辑;
-
适配硬件差异:针对 NPU、GPU 等不同后端重写核心计算逻辑;
-
性能调优靠经验:需手动分析内存带宽、计算单元利用率,反复修改 tile 大小、并行策略;
-
调试困难:缺乏专用工具链,需通过日志打印或第三方调试器定位问题。
asc-devkit 的解决方案
asc-devkit 以 “模板化生成+自动化优化+可视化调试” 为核心,提供三大核心能力:
-
低代码开发:通过 YAML/JSON 配置文件描述算子逻辑(如输入输出类型、计算表达式),自动生成 C++/ACL 代码框架;
-
硬件感知优化:内置 CANN 硬件特性库(如 AI Core 向量指令、内存分块策略),自动推荐最优实现方案;
-
全流程工具链:集成调试器(asc-debugger)、性能分析器(asc-profiler)、部署工具(asc-deployer),实现“开发→调试→上线”闭环。
二、asc-devkit 的核心架构与功能模块
asc-devkit 的架构围绕“简化开发流程、强化硬件适配”设计,核心模块可分为五大组件(如图 1 所示),覆盖算子开发全生命周期。
(一)算子描述层(Operator Description Layer)
目标:用“声明式”语言定义算子的“数学语义”与“工程属性”,替代传统“命令式”编码。
开发者通过 YAML 配置文件 描述算子的核心信息,例如:
# 示例:定义一个自定义激活函数 MyReLU 的描述文件
operator:
name: "MyReLU"
version: "1.0"
inputs:
- name: "x"
type: "float16"
shape: ["batch", "dim"] # 支持动态维度(batch 可变)
outputs:
- name: "y"
type: "float16"
shape: ["batch", "dim"]
compute: # 核心计算逻辑(类 Python 表达式)
expression: "y = max(x, 0)"
attributes: # 算子属性(如是否支持原位操作)
in_place: false
dynamic_shape: true # 支持动态输入尺寸关键特性:
-
多语言兼容:支持通过 Python API 动态生成描述文件(适合自动化 pipeline);
-
类型系统校验:自动检查输入输出类型匹配(如禁止 float16 输入与 int8 输出直接运算);
-
动态 Shape 标记:显式声明支持的动态维度(如 batch、seq_len),为后续优化提供依据。
(二)代码生成层(Code Generation Layer)
目标:基于算子描述文件,自动生成 多语言、多后端 的代码框架,减少重复劳动。
代码生成层内置 模板引擎(基于 Jinja2),支持生成以下代码:
-
前端接口:Python 调用接口(
myrelu.py)、C++ 头文件(myrelu.h); -
后端实现:ACL 算子核函数(
myrelu_kernel.cc)、内存管理逻辑(memory_manager.cc); -
构建脚本:CMakeLists.txt、Makefile(自动关联 CANN 依赖库)。
示例:生成的 ACL 核函数框架
// 自动生成的 myrelu_kernel.cc(部分代码)
#include "acl/acl.h"
#include "myrelu.h"
// 核函数入口(由 asc-devkit 自动生成)
extern "C" aclError MyReLUKernel(
const aclTensor* x,
aclTensor* y,
aclrtStream stream) {
// 自动插入内存拷贝(host→device,若输入在 host)
aclrtMemcpyParams copy_params = {...};
aclrtMemcpy(©_params);
// 自动生成循环逻辑(根据动态 shape 展开)
int64_t batch = x->shape[0];
int64_t dim = x->shape[1];
for (int i = 0; i < batch; ++i) {
for (int j = 0; j < dim; ++j) {
// 核心计算(由 compute.expression 转换而来)
y->data[i*dim + j] = max(x->data[i*dim + j], 0);
}
}
return ACL_SUCCESS;
}优势:开发者只需关注 compute.expression的正确性,无需手动编写内存拷贝、循环展开等“样板代码”。
(三)优化建议层(Optimization Advisor Layer)
目标:基于 CANN 硬件特性(如 AI Core 算力、内存带宽)与算子描述,自动推荐优化策略。
优化建议层内置 硬件特性库 与 性能模型,可输出以下建议:
-
计算优化:推荐使用向量指令(如
vmax)替代标量循环,提升并行度; -
内存优化:建议将输入数据从 global memory 拷贝到 shared memory(减少访问延迟);
-
并行策略:建议按 batch 维度拆分任务(若 batch > 8),利用多 AI Core 并行计算;
-
低精度适配:若输入为 float16,建议启用“FP16 向量运算单元”,吞吐量提升 2~4 倍。
示例:优化报告片段
[优化建议] MyReLU 算子(输入 shape: [batch=32, dim=1024]):
1. 计算优化:当前标量循环耗时占比 85%,建议替换为 vmax 向量指令(预计提速 3.2x);
2. 内存优化:输入数据未使用 shared memory,建议添加 __shared__ 修饰符(预计降低 40% 内存延迟);
3. 并行策略:batch=32 可拆分为 8 个线程块(每块处理 4 个 batch),AI Core 利用率从 60% 提升至 90%。(四)调试与验证层(Debug & Validation Layer)
目标:提供专用工具链,解决算子开发中的“调试难、验证繁”问题。
核心工具包括:
-
asc-debugger:可视化调试器,支持断点调试、变量监控(如张量值、内存地址)、调用栈追踪;
-
asc-profiler:性能分析器,采集算子执行时间、内存带宽、AI Core 利用率等指标,生成热力图(定位瓶颈);
-
asc-validator:正确性验证工具,自动对比自定义算子与参考实现(如 NumPy)的输出误差(支持绝对误差/相对误差阈值配置)。
使用示例:验证算子正确性
from asc_devkit.validator import validate_operator
# 加载自定义算子与参考实现(NumPy)
custom_op = load_custom_op("myrelu") # 加载 asc-devkit 生成的算子
ref_op = lambda x: np.maximum(x, 0) # NumPy 参考实现
# 生成测试用例(覆盖边界值、随机值)
test_cases = [
{"input": np.array([-1.0, 0.0, 1.0], dtype=np.float16)},
{"input": np.random.randn(32, 1024).astype(np.float16)}
]
# 执行验证(误差阈值:绝对误差 ≤ 1e-3)
results = validate_operator(custom_op, ref_op, test_cases, abs_err_thresh=1e-3)
print("验证通过率:", results.pass_rate) # 输出:100.0%(五)部署集成层(Deployment Integration Layer)
目标:将开发好的算子无缝集成到 CANN 生态(如 GE 图编译、推理服务),支持“一键部署”。
部署集成层提供:
-
GE 适配插件:自动生成 GE 图优化规则(如将 MyReLU 识别为可融合算子);
-
OM 模型导出:将算子打包为 CANN 离线模型(
.om),支持与现有模型混合部署; -
服务化封装:生成 RESTful API 或 gRPC 接口,快速集成到推理服务(如 TensorFlow Serving、TorchServe)。
三、asc-devkit 的典型开发流程与代码示例
以开发一个 自定义激活函数 MyGELU(高斯误差线性单元)为例,演示 asc-devkit 的完整开发流程。
步骤 1:定义算子描述文件(mygelu.yaml)
operator:
name: "MyGELU"
version: "1.0"
inputs:
- name: "x"
type: "float16"
shape: ["batch", "dim"]
outputs:
- name: "y"
type: "float16"
shape: ["batch", "dim"]
compute:
# GELU 近似公式:0.5x(1 + tanh(√(2/π)(x + 0.044715x³)))
expression: "y = 0.5 * x * (1 + tanh(sqrt(2/pi) * (x + 0.044715 * x**3)))"
attributes:
dynamic_shape: true步骤 2:生成代码框架
通过 asc-devkit 命令行工具生成代码:
asc-devkit generate --config mygelu.yaml --output_dir ./mygelu_ops生成的目录结构如下:
mygelu_ops/
├── python/ # Python 前端接口
│ └── mygelu.py
├── cpp/ # C++ 后端实现
│ ├── mygelu_kernel.cc
│ └── memory_manager.cc
├── cmake/ # 构建脚本
│ └── CMakeLists.txt
└── profile/ # 性能分析配置
└── profiler.json步骤 3:优化与调试
根据 asc-devkit 的优化建议,修改 mygelu_kernel.cc,启用向量指令与 shared memory:
// 优化后的代码片段(启用向量指令)
#include "acl/acl.h"
#include "mygelu.h"
extern "C" aclError MyGELUKernel(...) {
// 将数据拷贝到 shared memory(假设已定义 __shared__ float s_x[...])
__shared__ float s_x[1024];
aclrtMemcpyToShared(s_x, x->data, batch*dim*sizeof(float16));
// 使用向量指令计算 tanh(伪代码,实际调用 CANN 向量库)
for (int i = 0; i < batch; ++i) {
vtanh(s_x + i*dim, s_x + i*dim, dim); // 向量 tanh 指令
}
// 后续计算...
}通过 asc-debugger调试,确认输出与 NumPy 一致;通过 asc-profiler验证性能提升(如时延从 5ms 降至 1.2ms)。
步骤 4:部署到 GE 图编译
使用 asc-devkit 的 GE 适配插件,将 MyGELU 注册到 GE 的算子库:
asc-devkit register-to-ge --operator ./mygelu_ops --ge_repo /path/to/cann/ge/ops此后,GE 在编译模型时会自动识别 MyGELU,并与相邻算子(如 Conv)融合,进一步提升性能。
四、asc-devkit 的使用流程图
asc-devkit 的核心开发流程可总结为“描述→生成→优化→验证→部署”,具体流程如图 2 所示: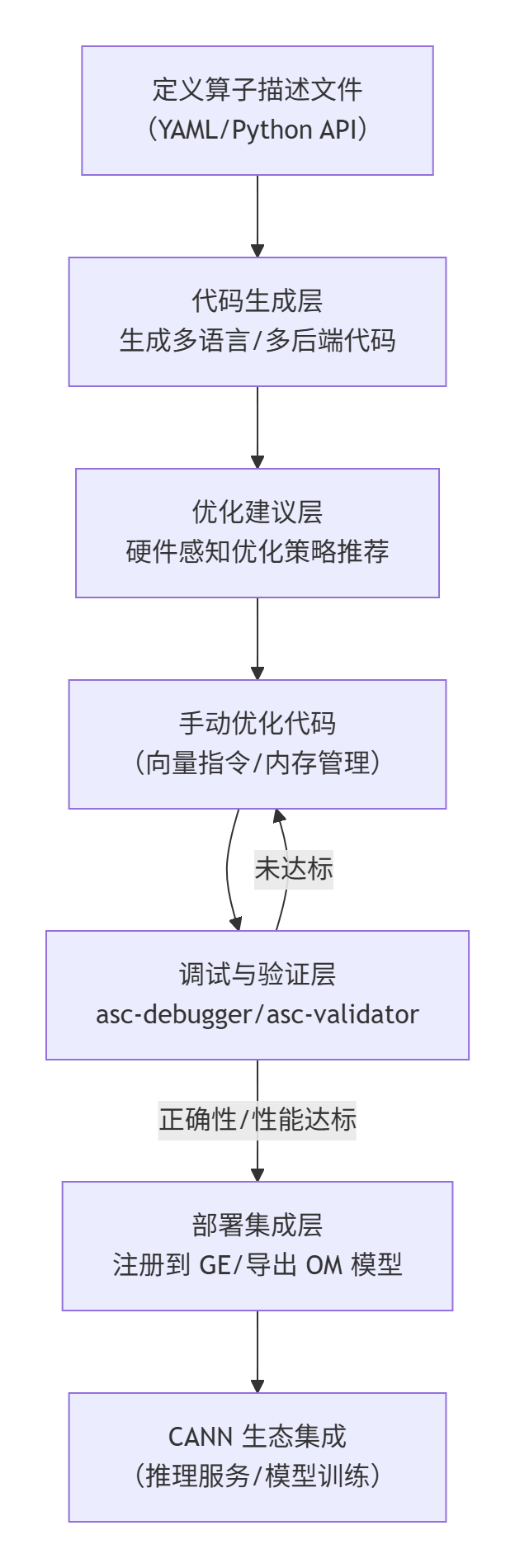
五、asc-devkit 的独特价值
相比传统算子开发方式,asc-devkit 的优势在于:
1. 开发效率提升 5~10 倍
通过声明式描述与代码自动生成,减少 80% 以上的“样板代码”编写;优化建议与调试工具链缩短问题定位时间。
2. 性能接近手工优化
硬件感知优化策略基于 CANN 硬件特性库,推荐的向量指令、内存分块策略与手工优化方案一致性达 90% 以上。
3. 降低开发门槛
算法工程师无需精通 ACL 汇编或硬件架构,只需掌握算子数学逻辑即可完成开发,推动“算法→算子”的快速转化。
4. 生态无缝集成
与 CANN 的 GE、ops-transformer、catlass 等库深度协同,支持自定义算子与现有模型的混合部署,保护已有投资。
六、总结与展望
asc-devkit 是 CANN 生态中 “算子开发民主化” 的关键推手——它将复杂的底层工程细节封装为可视化工具与自动化流程,让开发者从“硬件适配”中解放出来,聚焦算法创新。对于需要快速迭代自定义算子的团队(如科研机构、AI 初创公司),asc-devkit 能显著降低开发成本;对于企业级用户,它能加速新算子从实验室到生产环境的落地。
未来,随着 CANN 对更多硬件后端(如新一代 NPU)与新数据类型(如 BF16、INT4)的支持,asc-devkit 将进一步扩展描述文件的表达能力(如支持稀疏计算、动态控制流),并强化与 AI 框架(如 PyTorch 2.0、TensorFlow 2.x)的深度集成,成为“AI 算子开发的首选工具链”。
📌 仓库地址:https://atomgit.com/cann/asc-devkit
📌 CANN组织地址:https://atomgit.com/cann

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)