OpenResearcher:全开源的长周期DeepResearch轨迹生成方案
总结来说,OpenResearcher证明了完全可复现的离线轨迹合成能够作为训练有竞争力的深度研究智能体的坚实基础,不需要依赖专有搜索基础设施。

核心亮点速览
最近整个AI圈都在卷深度研究能力,各种Agent满天飞。这个OpenResearcher项目组直接放了个大招:用GPT-OSS-120B配合离线语料库和检索器,就能零成本合成出100多轮的高质量深度研究轨迹数据。
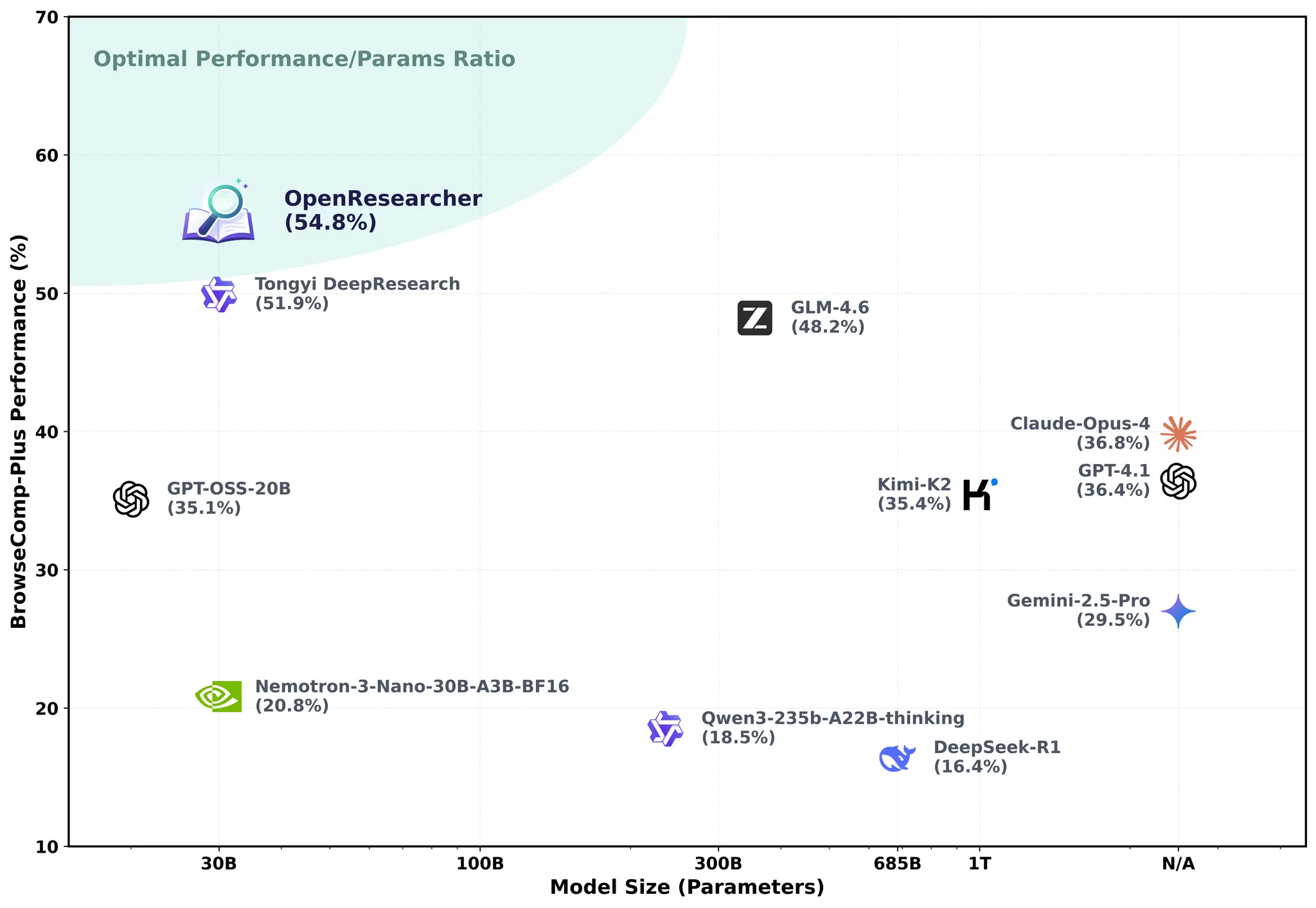
更狠的是,拿这些合成数据去训练Nemotron-3-Nano-30B-A3B-Base,直接把BrowseComp-Plus的准确率从20.8%干到了54.8%。这提升幅度,说实话有点吓人。
传统方案都得靠搜索API,不光贵(每次查询0.001-0.01美元),还有速率限制,结果还不稳定。OpenResearcher这套离线方案把这些问题全解决了:成本低、无限制、完全可复现。
最良心的是,项目组把所有东西都开源了:搜索引擎和语料库、深度研究轨迹数据、训练好的模型、完整代码。真正做到了拿来就能用。
相关资源
- 👨💻 GitHub仓库: https://github.com/TIGER-AI-Lab/OpenResearcher
- 🤗 HuggingFace模型&数据集: https://huggingface.co/collections/TIGER-Lab/openresearcher
- 🚀 在线Demo: https://huggingface.co/spaces/OpenResearcher/OpenResearcher
- 💡 案例展示: https://open-researcher.github.io/OpenResearcher.github.io/
- 🔎 评测日志: https://huggingface.co/datasets/OpenResearcher/OpenResearcher-Eval-Logs/tree/main
开源深度研究Agent的现状困境
自从DeepSeek-R1发布后,整个社区对收集大规模推理模型的长推理轨迹数据热情高涨。OpenThoughts、OpenMathReasoning、OpenCodeReasoning这些项目都在做类似的事情,目标就是通过监督微调来训练中小规模的推理模型。DeepSeek-R1-Distill系列模型就是完全靠海量精心筛选的长推理轨迹做SFT训练出来的,效果确实达到了业界顶尖水平。
最近随着智能体推理技术的兴起,深度研究Agent成了新的技术前沿。这类系统能够迭代搜索、聚合证据、多步推理,是大模型能力的重要突破方向。相应地,包含工具调用(特别是搜索功能)的轨迹数据变得越来越重要。
但实际操作中,搜索功能基本都要依赖商业搜索引擎API(比如Serper)。这些API大规模使用成本高得吓人,而且因为是黑盒实现,根本没法复现结果。更要命的是,经常遇到高延迟、直接失败、返回结果不一致等问题。这就导致想要大规模收集高质量的长周期研究轨迹数据变得特别困难。
从开源生态的角度看,这类轨迹数据还很稀缺。现有的开源系统跟顶级闭源模型比起来差距还是挺明显的。具体来说有这几个问题:
没有长周期轨迹:像Search-R1这种只用维基百科数据,轮次才2-5轮,跟真实的深度研究场景差太远了。
没有离线环境:大部分方案都得依赖实时搜索API,复现成本高,结果还不确定。
发布不完整:没有哪个项目把模型权重、轨迹数据、代码、环境全部一起开源。
看看目前各个项目的发布情况对比:
| 项目 | 模型权重 | 轨迹数据 | 代码 | 环境 |
|---|---|---|---|---|
| Search-R1 | ✅ | ❌ | ✅ | ✅ (维基百科) |
| 通义深度研究 | ❌ | ❌ | ✅ | ❌ (基于API) |
| MiroThinker | ✅ | ✅ | ✅ | ❌ (基于API) |
| OpenResearcher | ✅ | ✅ | ✅ | ✅ |
综合来看,这些限制暴露了智能体推理研究的一个根本瓶颈:怎么才能用低成本、完全可复现的方式来合成高质量的长周期智能体推理轨迹?
为了解决这些问题,OpenResearcher提供了一套完全离线、低成本、可复现的流水线,能够合成100轮以上的长周期深度研究轨迹,包含迭代搜索、证据聚合和多步推理。所有资源都向社区开放。
OpenResearcher轨迹合成全流程
核心思路其实很简单但很有效:用本地搭建的搜索引擎替代那些又贵又不稳定的在线搜索API,同时保持真实网络研究的难度、噪声和不确定性。
下面这张图展示了整个流水线的架构:

问答题目的收集策略
为什么问题选择很关键
要合成有意义的深度研究轨迹,问题本身得够难,不能靠简单检索就能解决。标准的检索benchmark和语料库(比如维基百科、MS MARCO)其实并不适合这个目的。这些数据集有个共同特点:大部分问题2-5步检索就能搞定,信息干净整洁、结构清晰、交叉引用密集,很少出现歧义、矛盾或缺失证据的情况。
真实的深度研究完全不是这么回事。在网络规模的复杂环境下:证据分散在各种异构来源里,说法可能过时或者互相矛盾,推理往往需要跨越很长的依赖链条。
很多这类问题刚看起来挺简单,但随着搜索深入,会逐渐暴露出知识缺口、来源冲突、隐藏依赖等问题。要取得进展,经常得先让问题变得更复杂——通过扩展、重新定义或者分解问题——然后才能最终简化并解决。
虽然检索步数是难度的一个表面指标,但真正驱动难度的是底层复杂性,表现为随着探索深入,搜索和推理的要求越来越高。
这种特征轨迹——问题不断演化、随着深入搜索变得更难、最后才收敛——需要持续的多轮探索和推理。固定的多跳检索流水线根本捕捉不到这种行为,这才是真实深度研究的核心特征。
数据集选择
基于这个考虑,项目组选择了MiroVerse-v0.1数据集的问题,这个数据集需要在异构证据上进行长周期、多跳推理。实测发现,即使是很强的教师模型GPT-OSS-120B,在搜索增强的环境下解决单个问题也经常需要超过100次工具调用。
从完整数据集中随机抽样了10%的问答对,大概6000个实例。
虽然MiroVerse提供了部分轨迹,但这些轨迹不适合直接用来做监督训练,原因有几个:检索到的证据不一定真的支持最终答案,搜索轨迹往往很短、退化或者不一致,工具使用模式在不同数据集间差异很大。
既然目标是合成高质量的长周期研究轨迹,项目组决定从头重新生成所有轨迹,只保留干净的问答对作为起点。
离线搜索引擎的构建
通过在线搜索获取黄金段落
前面说了,重新生成轨迹有个关键前提:相关证据必须是可检索的。
系统失败可能有两个完全不同的原因:一是证据缺失——所需信息压根不在搜索语料库里;二是推理失败——信息存在,但系统没找到或者没用上。
第一种情况特别重要。如果不提前确保语料库覆盖率,很多失败轨迹只是反映证据缺失,而不是检索或推理能力的问题。这种轨迹对训练或评测没什么价值,因为看不出智能体是否真正具备多步搜索和证据综合的能力。
为了确保语料库覆盖,项目组做了一次性的在线引导步骤,为6000个问答对收集黄金段落。
具体流程:
首先是查询构建(面向覆盖率)。用问题加上参考答案来构造搜索查询,确保能检索到黄金段落。
然后在线检索。通过Serper搜索API(https://google.serper.dev/search)获取结果。
接着内容抓取和清洗。用Serper Scrape API(https://scrape.serper.dev)获取页面内容,用标准流程去掉样板文字、导航元素等非核心内容。
最后去重和正文提取。对检索到的文档去重,提取主要文本内容,切分成10000个黄金段落。
特别要说明的是,在后续的轨迹合成中,教师模型是看不到答案的。它必须通过多轮搜索和推理才能得出正确结论。
离线语料库构建
为了模拟真实网络的覆盖范围,体现真实搜索环境的复杂性,项目组从FineWeb采样了1500万份文档(大约10万亿token)。这些文档跟黄金段落合并起来构成离线语料库,其中FineWeb文档(1500万)作为负样本(干扰证据),黄金段落(1万)作为正样本(支持参考答案的证据)。
这个设计受到BrowseComp-Plus的启发,后者也用了本地可复现的检索环境。关键区别在于语料库的策划方式:BrowseComp-Plus会人工验证每个问题都能被语料库回答,而OpenResearcher故意跳过了这个人工验证步骤。
这样做的好处是能够大规模合成数据,代价是引入不完整、有噪声或缺失的证据——这个权衡反而更接近真实的研究场景。
语料库索引
离线语料库中的每份文档都用Qwen3-Embedding-8B做嵌入,然后用FAISS建索引,支持高效的大规模密集检索。推理时,智能体发出自然语言查询,检索器返回排序后的文档——跟网络搜索API的工作方式完全一样。
浏览器工具:从"搜索"到真实浏览
之前的智能体搜索系统(比如Search-R1)把搜索当成单步文档检索操作:发出查询,返回一个或几个文档,直接对检索内容进行推理。
但这个抽象跟人类实际做研究的方式差得太远了。在真实的浏览行为中,搜索只是入口而不是研究过程本身。典型的工作流程应该是这样的:发出一个宽泛的查询来识别候选来源,打开有希望的文档查看完整内容,浏览、滚动、定位跟工作假设相关的特定段落,根据部分证据优化查询并迭代。
把这些不同的认知步骤压缩成单一的"检索-阅读"操作,掩盖了研究过程的本质要素。这会导致推理轨迹很浅、过度依赖片段、面对长文档或有噪声的文档时扩展性差、工具使用行为不切实际。
为了在完全离线的环境下支持长周期深度研究,OpenResearcher明确地对浏览行为建模,而不是把它压缩成单一的搜索原语。目标不是复刻完整的浏览器,而是暴露出最小的操作集合,这些操作对于真实的研究行为既是必要的,又足以支持多步证据发现、验证和综合。
项目组确定了三个这样的原语,分别实现为对应的工具:
- search:根据查询检索候选文档
- open:详细查看某个文档
- find:在文档内定位特定证据
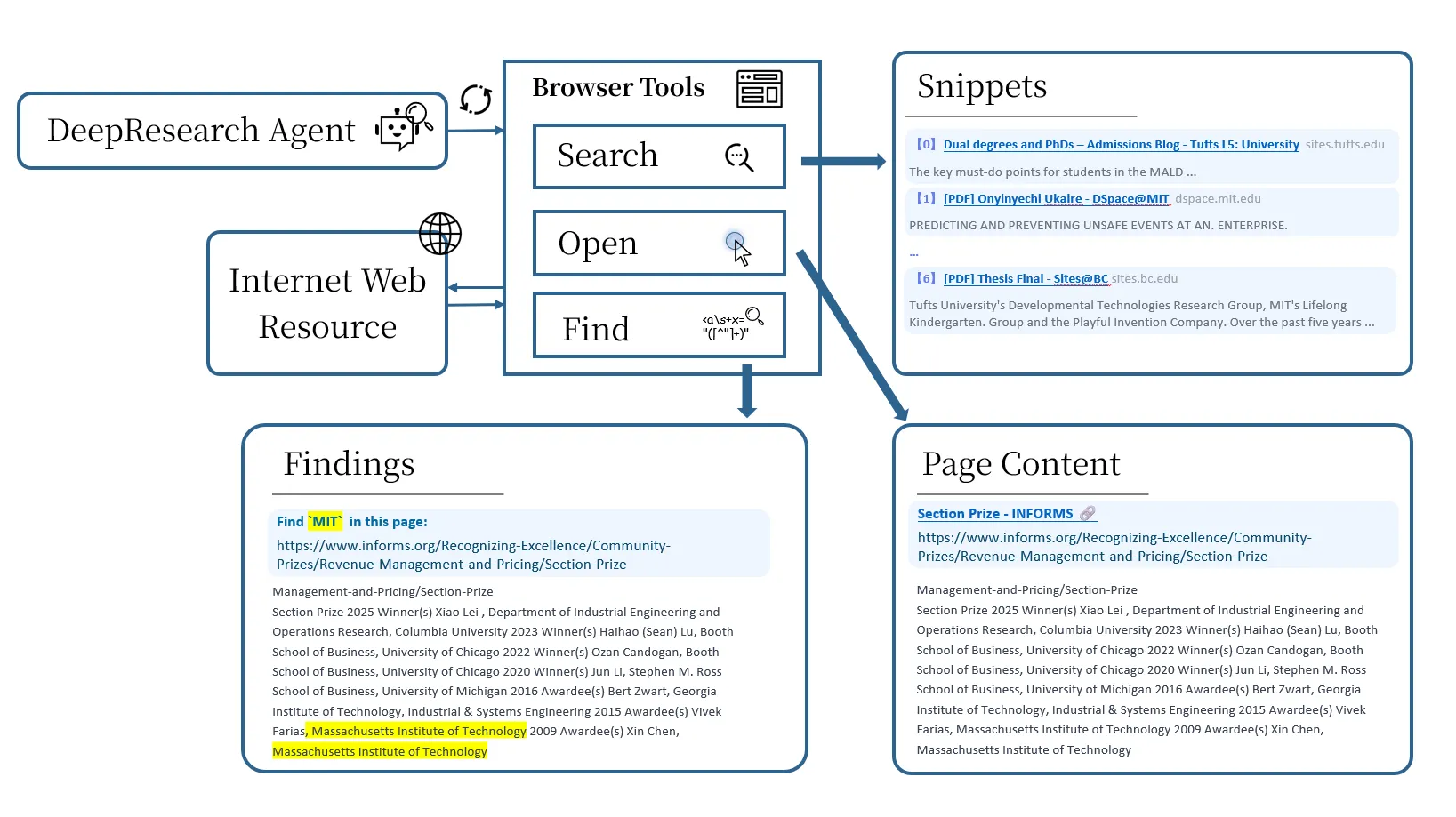
一个自然的问题是:为什么三个工具都需要?
只有search的智能体只能依赖片段,这些片段往往不完整或者有误导性。有search + open还是会强迫模型在上下文窗口内隐式扫描长文档,这种方法效率低、不稳定,而且跟人类浏览行为不一致。有search + open + find才能实现文档导航,支持精确的证据定位和持续的长周期推理。
这三个工具配合起来,能让智能体迭代优化假设、验证主张、导航长文档,方式跟真实的人类浏览行为非常接近。
教师轨迹合成
项目组用GPT-OSS-120B作为教师模型来合成长周期深度研究轨迹。
对每个问答对,生成16条不同随机种子的轨迹,以捕捉多样化的推理路径。合成过程在64块H100 GPU上并行化,每个种子分成8个chunk,由专门的GPU运行GPT-OSS-120B来处理。
整个合成过程大约需要2天,每条轨迹最多需要10分钟,因为教师模型和离线搜索环境之间有大量的多轮交互——这正是想要捕捉的行为。
合成配置参数如下:
| 配置项 | 参数值 |
|---|---|
| 教师模型 | GPT-OSS-120B |
| 检索器 | Qwen3-8B-Embed |
| 最大搜索步数 | 150 |
| 每条轨迹最大token数 | 128K |
| 每次搜索返回文档数 | Top-10 |
| Temperature | 1.0 |
| Top-P | 0.95 |
| 搜索工具 | search, open, find |
轨迹统计分析
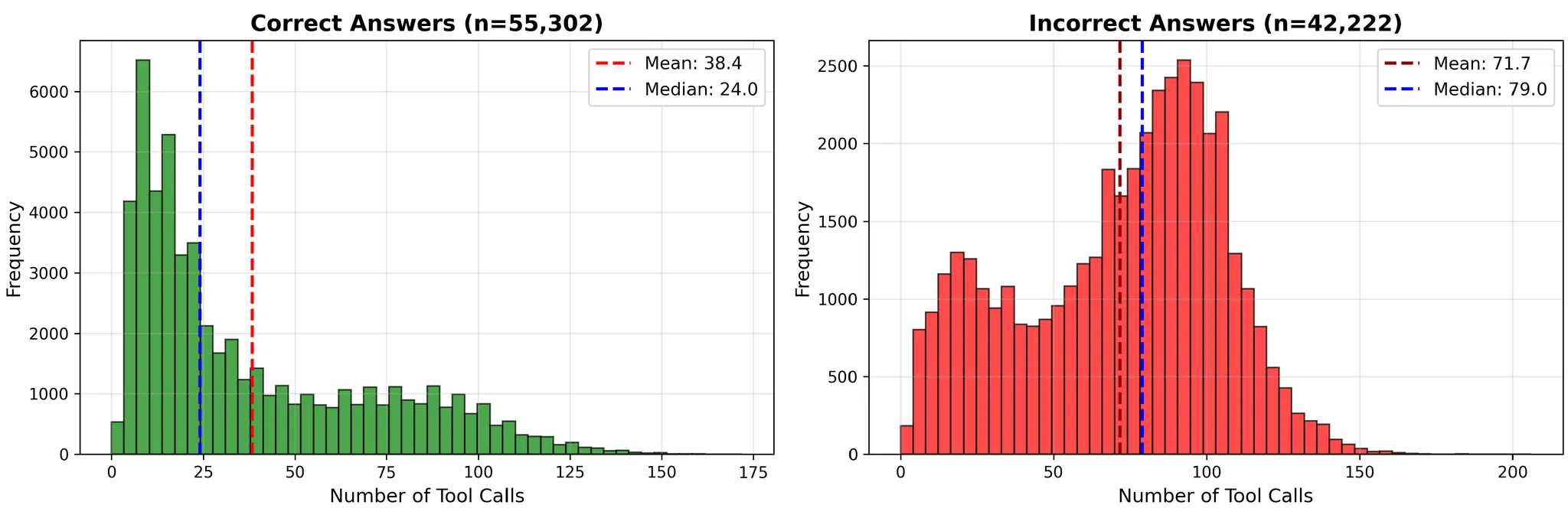
合成完成后总共得到97,632条轨迹,其中55,824条产生了正确的最终答案。采用拒绝采样策略,只保留成功的轨迹用于下游微调。
整体成功率
| 指标 | 成功 | 失败 | 全部 |
|---|---|---|---|
| 数量 | 55,302 | 42,222 | 97,524 |
| 比例 | 56.71% | 43.29% | 100% |
| 平均工具调用次数 | 38.4 | 71.7 | 52.75 |
| 平均搜索次数 | 22.06 | 48.78 | 33.63 |
| 最大工具调用次数 | 172 | 185 | 185 |
| 最大搜索次数 | 109 | 119 | 119 |
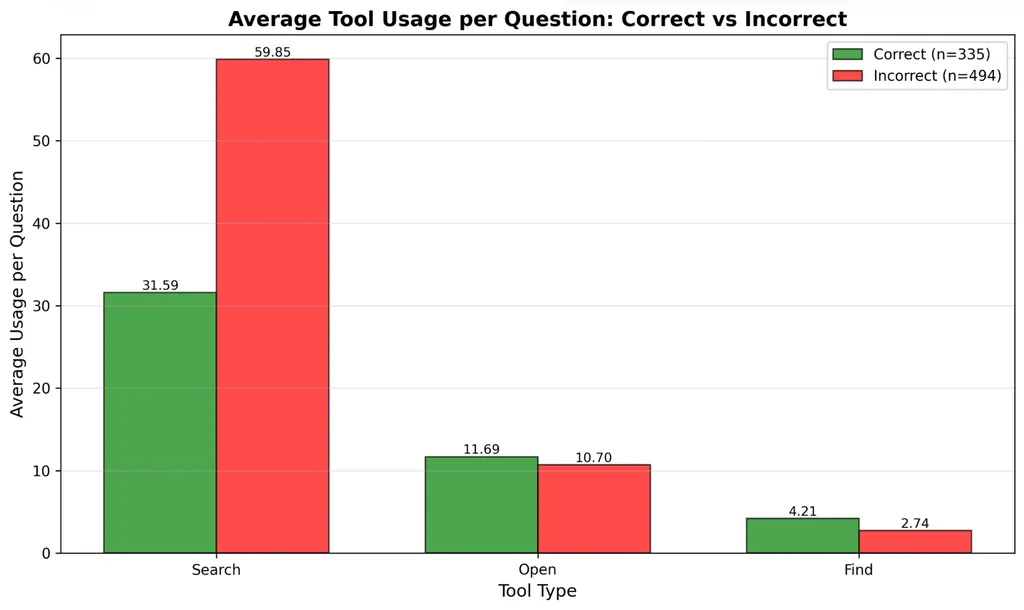
一个关键观察是:正确和错误轨迹在工具使用上差距很大。错误轨迹的工具调用次数几乎是正确轨迹的2倍。这说明失败不是因为探索不够,而可能是搜索效率低或者方向错误。更难的问题可能不只是需要"更多搜索",而是需要更好的搜索策略。
工具调用次数的直方图还揭示了另一个重要特性:成功轨迹的长度分布范围很广。很多正确轨迹在10-40次工具调用内完成,有相当一部分需要100多步,有些甚至达到最大范围(150次以上工具调用)。
这证实了数据集确实包含真正的长周期推理链,而不是简单的检索捷径。
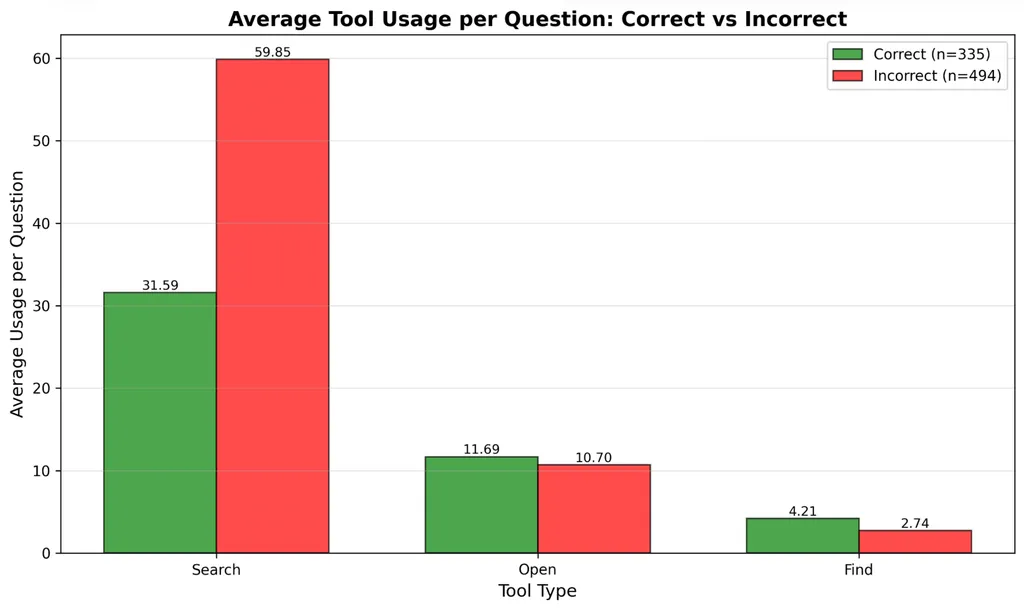
工具调用分布细节
进一步拆分search、open、find三个工具的使用情况会发现:失败轨迹中多出来的工具调用几乎完全来自search,open和find在成功和失败运行之间的分布相似。
这说明:成功轨迹倾向于更早地收敛到相关文档,失败轨迹反复重新构造查询但没有实质性进展,文档级导航(open、find)不是主要瓶颈——查询构造才是。
这跟设计明确的浏览器原语的初衷是一致的:深度研究失败往往源于搜索漂移,而不是缺乏推理能力。
Pass@k分析
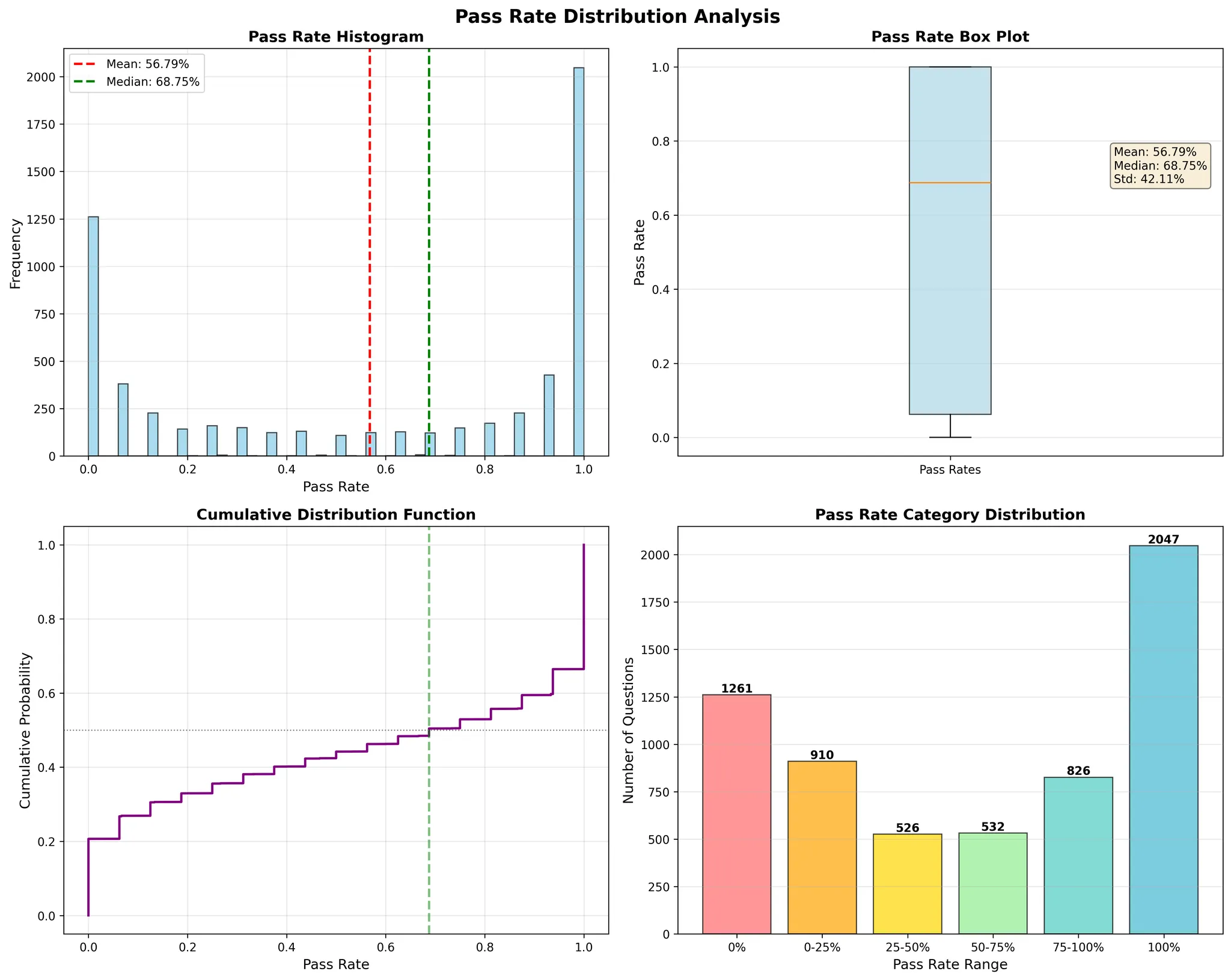
为了衡量解决方案的多样性,在每个问题的16条轨迹上计算pass@k指标。
有两点很突出:pass@1和pass@16之间有巨大差距。两者之间差了20多个百分点,意味着接近80%的问题是可以解决的,但只能沿着特定的推理路径。
问题间的方差很高。通过率分布高度倾斜:有些问题几乎总能解决,有些即使尝试16次也很少解决。
分析每个问题的通过率会发现双峰结构:一大块(超过30%)接近0%通过率(极难问题),另有接近20%的问题达到近100%通过率(稳定可解问题),中间(约45%)的问题较少,代表潜在的改进空间。
这种结构是开放式、网络规模研究任务的典型特征,成功往往取决于发现少数关键事实。
离线语料库的成本节省
采用离线搜索的一个主要动机就是可扩展性。
如果在合成过程中依赖在线搜索API,成本会这样计算:60次工具调用 × 6000个问题 × 16个种子 = 5,760,000次搜索请求。
| API | 每1000次价格 | 预估成本 |
|---|---|---|
| Serper | $1 | $5,760 |
| SerpAPI | $5 | $28,800 |
相比之下,离线检索器的优势是:每次搜索边际成本为0,没有速率限制,完全确定性的行为,完美可复现。
这让大规模、长周期的轨迹合成第一次变得可行,不需要专有基础设施。
实验设置与结果
训练配置
为了验证合成轨迹的有效性,从nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-Base-BF16初始化一个模型,只用正确答案的轨迹进行微调。
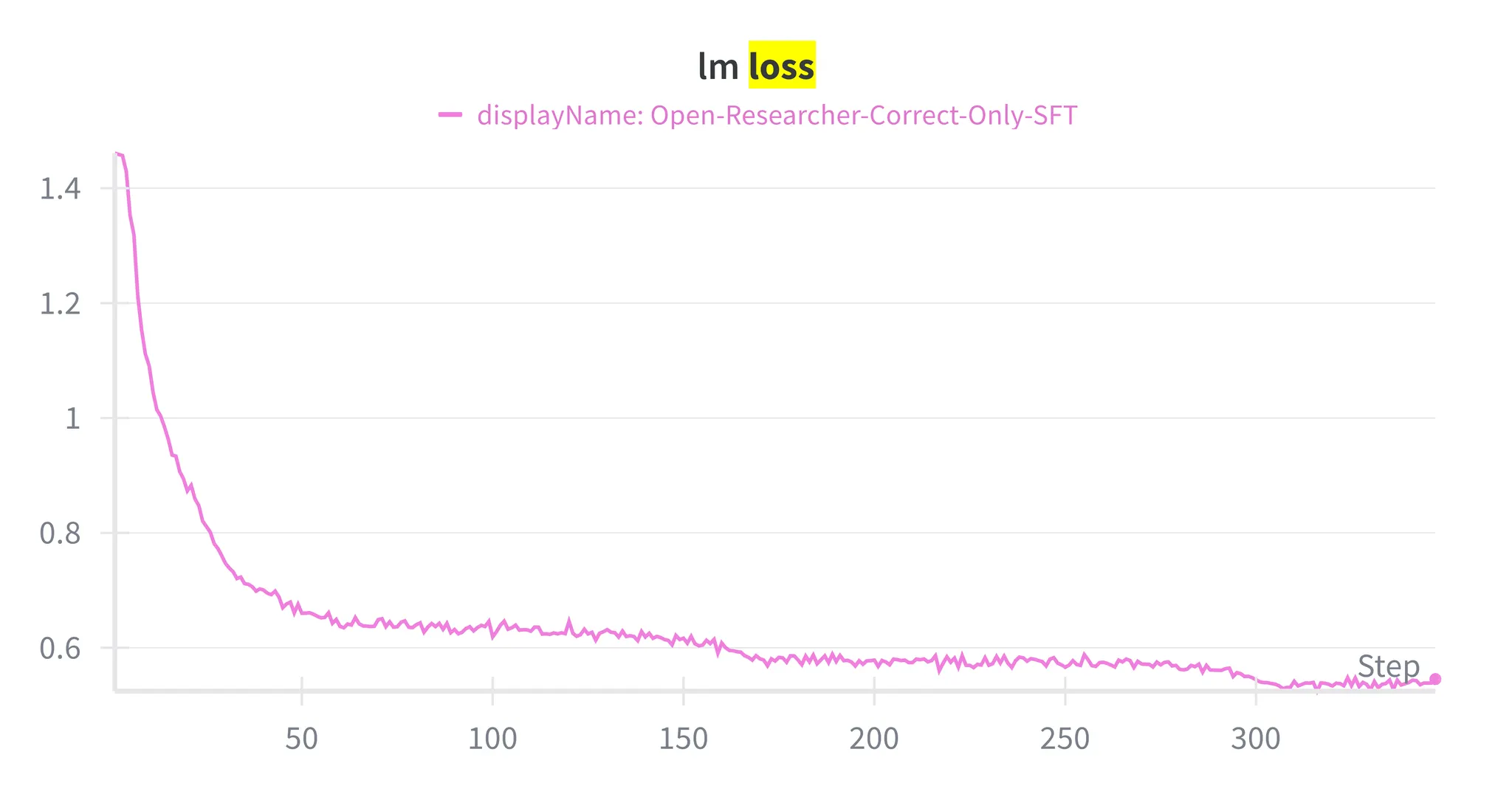
采用Megatron-LM作为监督微调(SFT)代码库。所有实验都在固定和受控的训练配置下进行:在8块H100 GPU上训练8小时,学习率设为5e-5,序列预打包到最大长度256K token,训练347步,全局批大小64。
这个设置让模型能够直接从长周期推理轨迹中学习,包括扩展的工具使用模式和多步证据聚合,没有截断。
评测设置
在几个广泛使用的深度研究benchmark上评测训练好的模型:BrowseComp-Plus、BrowseComp、GAIA、xbench-DeepSearch。
为了确保公平和有意义的比较,遵循BrowseComp-Plus和通义深度研究使用的官方评测协议。
对于搜索后端:BrowseComp-Plus(固定语料库)使用官方发布的语料库加上Qwen3-Embedding-8B的FAISS索引构建离线搜索引擎。所有其他benchmark(实时网络)依赖Serper API:search用Serper Search,open用Serper Scrape(用于完整文档检索)。
这个评测设计能够同时测试:在完全可复现条件下的语料库内推理能力,以及对真实网络搜索环境的泛化能力。
实验结果
BrowseComp-Plus(固定语料库)
BrowseComp-Plus是一个完全离线的benchmark,每个问题都经过人工验证可以被语料库解答,支持确定性和可复现的评测。
| 方法 | 准确率 |
|---|---|
| OpenAI-4.1 | 36.4 |
| Claude-4-Opus-4 | 36.8 |
| Gemini-2.5-Pro | 29.5 |
| Kimi-K2 | 35.4 |
| DeepSeek-R1 | 16.4 |
| Nemotron-3-Nano-30B-A3B | 20.8 |
| GPT-OSS-20B | 35.1 |
| GPT-OSS-120B | 57.0 |
| 通义深度研究 | 51.9 |
| CutBill-30B-A3B-RL | 30.3 |
| OpenResearcher-30B-A3B | 54.8 |
关键观察:OpenResearcher-30B-A3B达到54.8%准确率,超过除GPT-OSS-120B外的所有基线。相比基础的Nemotron-3-Nano-30B-A3B模型(20.8%),绝对提升了34.0个百分点。
这个结果证明,仅靠在合成的长周期轨迹上做监督微调,就足以弥补与前沿规模推理模型的大部分差距。
网络API Benchmark
这些benchmark使用实时网络搜索API,测试对真实搜索环境的泛化能力。
| 方法 | BrowseComp | GAIA | xbench-DeepSearch |
|---|---|---|---|
| OpenAI-o4-mini | 28.3 | 55.8 | 67.0 |
| Claude-4-Sonnet | 12.2 | 68.3 | 64.6 |
| Kimi-K2 (1TB) | 14.1 | 57.7 | 50.0 |
| DeepSeek-V3.1 (685B) | 30.0 | 63.1 | 71.0 |
| ASearcher-Web-QwQ-32B | 5.2 | 52.8 | 42.1 |
| WebDancer-QWQ-32B | 3.8 | 51.5 | 39.0 |
| WebSailor-72B | 12.0 | 55.4 | 55.0 |
| DeepMiner-32B-SFT | 21.2 | 54.4 | 53.0 |
| OpenResearcher-30B-A3B | 30.3 | 64.1 | 65.0 |
关键观察:OpenResearcher-30B-A3B在多个benchmark上达到或超过OpenAI-o4-mini和Claude-4-Sonnet等前沿模型。大幅超越现有的开源深度研究系统(ASearcher、WebDancer、WebSailor、DeepMiner)。值得注意的是,这些提升是在没有用实时网络数据训练的情况下实现的。
案例展示
项目组提供了在线demo供大家体验:https://huggingface.co/spaces/OpenResearcher/OpenResearcher
也有一些预先收集的合成轨迹定性案例:https://open-researcher.github.io/OpenResearcher.github.io/
讨论与分析
实验结果支撑了几个关键结论。
首先,长周期轨迹监督非常有效。在合成轨迹上微调产生了相比基础模型的巨大提升(+34个百分点),即使没有强化学习或人工标注。
其次,更丰富的工具监督很重要。跟很多只暴露单一search工具的先前系统不同,OpenResearcher用结构化的工具集训练:search用于检索候选文档,open用于查看完整文档内容,find用于定位精确证据片段。
这支持了更真实和有效的研究策略:广泛探索、有针对性的深入挖掘、精确的证据支撑。
最后也是最重要的,离线训练能泛化到在线搜索。尽管完全在固定的离线搜索引擎上训练,模型对实时网络环境(Serper API)的迁移效果非常好。这说明学到的核心技能——查询构造、证据聚合、迭代优化、搜索终止——是环境无关的。
总结来说,OpenResearcher证明了完全可复现的离线轨迹合成能够作为训练有竞争力的深度研究智能体的坚实基础,不需要依赖专有搜索基础设施。
参考文献
[1] OpenThoughts: Data Recipes for Reasoning Models
[2] OpenMathReasoning: A Large-scale Math Reasoning Dataset for Training Large Language Models
[3] OpenCodeReasoning: Advancing Data Distillation for Competitive Programming Coding
[4] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
[5] Tongyi DeepResearch Technical Report
[6] MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
[7] Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
[8] Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps
[9] MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
[10] The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
[11] BrowseComp-Plus: A More Fair and Transparent Evaluation Benchmark of Deep-Research Agent
[12] gpt-oss-120b & gpt-oss-20b Model Card

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)