GPT-5.3-Codex 登场:比 5.2 更快 25%
如果把写代码比作开车,那过去很多“AI 编程助手”更像:你把目的地一口气说完,它闷头把方向盘打到底——中途你想改路线?对不起,它要么装没听见,要么直接“重新规划(并把你刚才说的忘了)”。🙃而的核心变化,就是把 Codex 从“会写代码的工具”往“能在电脑上持续做事的同事”推了一大步:更能扛长任务、更会用工具、更像人在协作,而且。
如果把写代码比作开车,那过去很多“AI 编程助手”更像:你把目的地一口气说完,它闷头把方向盘打到底——中途你想改路线?对不起,它要么装没听见,要么直接“重新规划(并把你刚才说的忘了)”。🙃
而 GPT-5.3-Codex 的核心变化,就是把 Codex 从“会写代码的工具”往“能在电脑上持续做事的同事”推了一大步:更能扛长任务、更会用工具、更像人在协作,而且 整体速度还提升了 25%。

1)强强联合跑得更快
GPT-5.3-Codex 被定位为“目前最强的 agentic coding 模型”,它把两条能力线合流了:
- 继承 GPT-5.2-Codex 的前沿编程能力
- 叠加 GPT-5.2 的推理与专业知识能力
并且在 Codex 场景下 加速 25%,更适合研究+工具调用+复杂执行的长流程任务。
更“离谱但合理”的一句是:这次模型还是第一个在研发过程中“帮忙造自己”的版本——早期模型被用来协助调试训练、管部署、诊断评测与结果分析。
(翻译成人话:研发团队已经开始被自家模型“反向加班”了😅)

2)四个基准
OpenAI 把 GPT-5.3-Codex 的“能打”主要落在四个评测维度上:SWE-Bench Pro、Terminal-Bench、OSWorld、GDPval。
2.1 写代码:SWE-Bench Pro 刷到行业新高
SWE-Bench Pro 更偏真实工程,更“抗投喂”,而且覆盖多语言(不像 SWE-bench Verified 主要测 Python)。GPT-5.3-Codex 在这上面拿到 SOTA。
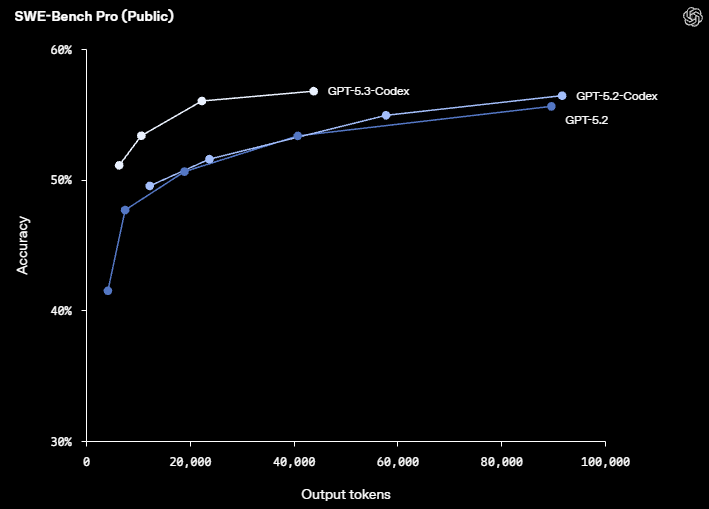
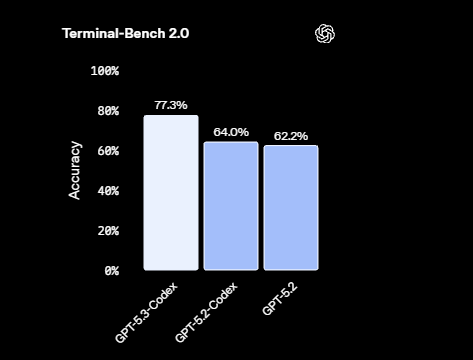
2.2 终端能力:Terminal-Bench 2.0 直接拉开差距
对“能跑命令、会看输出、能修到测试过”为核心的编码代理来说,终端能力几乎等于执行力。GPT-5.3-Codex 在 Terminal-Bench 2.0 上也明显领先,并且强调“用更少 token 做更多事”。
2.3 会用电脑:OSWorld-Verified 进步幅度更直观
OSWorld 是“在桌面环境里完成生产力任务”的评测,需要视觉与操作的组合能力。文中提到 OSWorld-Verified 里人类大概 ~72%,而 GPT-5.3-Codex 相比之前的 GPT 系列显著更强。
2.4 真实职业工作:GDPval 继续保持强势
GDPval 是 OpenAI 2025 年发布的“职业知识工作评测”,覆盖 44 种职业任务(做表格、做演示、写方案等)。GPT-5.3-Codex 在 GDPval 上与 GPT-5.2 表现匹配。
3)最像“同事”的升级
以前的代理体验,经常像“把需求扔进黑盒”:你只能等它吐一个最终结果,然后祈祷别偏题。
GPT-5.3-Codex 主打的交互变化是:
- 更频繁的进度更新(关键决策、进展可见)
- 工作过程中可被“steer”(你可以中途提问、讨论方案、纠偏)
- 不中断上下文(不会因为你插话就失忆)
这对真实工程特别重要:复杂任务不是一次性写完,而是“边做边发现、边改边收敛”。一个能被监督、能被纠偏、还能保持上下文的代理,才更像团队里能长期合作的“靠谱人”。
4)Web 开发:从“能做页面”到“默认更像上线版”
文章里拿了一个很具体的对比:同样是“做一个 SaaS 风 landing page”,GPT-5.3-Codex 会默认补齐更多“产品级细节”,比如:
- 年付价格展示会更像真实商业产品的“折算月价”,折扣表达更自然
- 自动轮播的 testimonial 会给多条不同用户引用,而不是敷衍一条
- 对“简单或不充分的提示词”会给出更合理的默认功能与结构
这类提升的意义是:你不再需要把“常识型产品细节”写成 100 条 checklist,模型会更主动把页面往“能投产”的方向推。
5)一个截图,说明它不止会写代码:它还能产出职业级工件
下面这张来自官方示例的输出截图(金融顾问做 10 页内部培训 PPT)很好地传递了信号:GPT-5.3-Codex 的定位并不只是在 IDE 里敲补丁,而是能把“专业知识工作”也接过去做。
6)安全与网络安全:能力更强,所以防护也更“重装”
文章里明确说:GPT-5.3-Codex 是第一个在“Preparedness Framework(准备框架)”下被归类为网络安全任务 “High capability” 的模型,并且也是第一个被直接训练来识别软件漏洞的版本。
这类表述通常意味着两件事同时发生:
1)模型在安全相关任务上确实更强(对防守方是好事)
2)因为双用途风险更高,部署会更谨慎、更强调监测、访问控制与执行管道(对生态是必要的“刹车系统”)
同时,他们还提到:在生态侧会推进更多防护与合作,包括 Trusted Access for Cyber 试点、以及与开源维护者合作做代码库扫描等。
7)最直观的“成绩单”:5.3 在几个关键项上确实全面抬升
官方附录给了同一推理强度(xhigh)下的对比数据:
| Metric | GPT-5.3-Codex (xhigh) | GPT-5.2-Codex (xhigh) | GPT-5.2 (xhigh) |
|---|---|---|---|
| SWE-Bench Pro (Public) | 56.8% | 56.4% | 55.6% |
| Terminal-Bench 2.0 | 77.3% | 64.0% | 62.2% |
| OSWorld-Verified | 64.7% | 38.2% | 37.9% |
| GDPval (wins or ties) | 70.9% | — | 70.9% (high) |
| Cybersecurity CTF Challenges | 77.6% | 67.4% | 67.7% |
| SWE-Lancer IC Diamond | 81.4% | 76.0% | 74.6% |
有意思的是:SWE-Bench Pro 的提升是“细微但领先”,但 Terminal-Bench 与 OSWorld 的跃迁更夸张——这也符合它“更像电脑上的通用代理”的叙事:不只是写代码更强,而是执行链路更完整。
8)可用性:哪里能用?API 呢?
目前它已经覆盖 Codex 的主要入口:App、CLI、IDE 扩展、Web,并且属于付费 ChatGPT 计划可用;API 方面则是“正在安全推进”。
结尾:从“写得对”到“做得完”,这才是代理真正的分水岭
很多人对编程模型的期待,早就不是“给我生成一段代码”,而是:
- 能读懂工程上下文
- 能跑工具、能看结果
- 能迭代修到通过
- 还能接受人类随时插话纠偏
- 最后交付一个可审查、可落地的成果
GPT-5.3-Codex 这一波更新,最本质的变化其实是:Codex 正在从“编码代理”升级为“电脑上的通用协作体”。
它会写、会跑、会做表、会做 PPT、会追进度、还能被你实时指挥——这才更像团队里那个让人放心把活交出去的同事:不神神叨叨、不给惊喜吓人、能把事情做完✅
喜欢就奖励一个“👍”和“在看”呗~


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)