Hadoop Yarn资源调度框架详解
Yarn是Hadoop的核心资源管理组件,负责集群资源分配和任务调度。摘要从三个方面介绍Yarn:1)基础架构由ResourceManager(全局资源管理)和NodeManager(节点执行)组成;2)核心调度算法包括FIFO、Capacity(按队列容量分配)和Fair(公平分配)三种策略;3)生产优化方案涉及ResourceManager高可用(基于ZK实现)、多队列管理(支持按用户/任务类
一、Yarn介绍
1、Yarn简介
Yarn是Hadoop中用来管理系统资源的重要组件。官网上对于Yarn设计思想的描述,是将资源管理功能和作业调度监控的功能拆分成不同节点上的守护进程,以提高集群内的整体资源利用率。这个说法过于正统,其实对于Yarn,我们现在应该已经不是很陌生了。Hadoop的整体目的是管理成千上万个服务器组成的大型计算机集群。在这样的集群中要进行高效的数据计算,就需要有一个组件对集群资源进行整体分配。这里所说的集群资源,主要包括CPU核心数、内存、硬盘、网络这四种资源。而通过Yarn,就可以对集群的资源进行整体管理,当需要执行计算任务时,以任务为单位分配集群资源,而计算任务执行完成后,又可以回收集群资源。同时Yarn也提供了集群资源的整体监控。
Yarn最初的设计目的,主要就是为了辅助执行MapReduce计算任务。不过时至今日,Yarn已经演进成了一个相对完善的集群资源管理工具。在Yarn中不光可以执行MapReduce任务,还可以用来执行一些其他的计算任务,比如Spark、Flink等。一个简单的比喻,Yarn就好比我们经常使用的VMare软件,而MapReduce、Spark、Flink这些计算任务就相当于是在VMare上运行的一个个应用程序(虚拟操作系统)。在创建虚拟机时,可以给每个虚拟机分配各种资源,销毁虚拟机时,又可以回收各种资源。
之前在跟踪MapReduce计算任务时已经提到,Hadoop在执行MapReduce计算任务时(
job.waitForCompletion方法)会根据执行计划创建不同的任务执行者。本地执行创建一个LocalJobRunner,而集群执行则创建一个YarnRunner。这个YarnRunner就是与Yarn进行交互的类。
2、Yarn整体架构
Yarn框架整体由ResourceManager和NodeManager两个组件组成。其中,ResourceManager是集群中拥有最高权限的全局管理者。负责响应客户端的请求,并对资源进行分配。NodeManager则是部署在每个计算节点上的一个计算框架,可以认为是集群中的打工者。负责执行所有的Container,收集具体的资源使用情况并报告给ResourceManager。
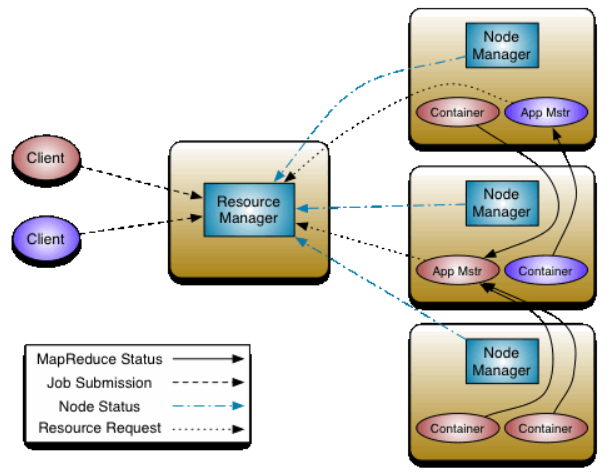
在Yarn集群启动后,ResourceManager和NodeManager都将作为一个守护进程,在对应的服务器上执行。而在讨论Yarn的逻辑结构时,我们又可以划分为几个重要的功能组件。
-
ResourceManager有两个重要的功能组件:
Scheduler和ApplicationsManager。-
Scheduler组件主要负责对集群资源进行划分,也就是决定各个计算任务的执行顺序,根据执行顺序决定资源如何分配。当前版本主要包含三种分配机制,FIFO(谁先申请谁执行),CapacityScheduler(容量策略),FairScheduler(公平策略)。后续会详细分析这三种机制。 -
ApplicationsManager主要负责接收分配的作业任务,启动对应的ApplicaitonMaster。并在出现故障时,重新启动ApplicationMaster。
-
-
NodeManager也有两个重要的功能组件:
AppMaster和Container。-
AppMaster简称AM,是NodeManager中执行具体任务的管理者,负责为应用程序申请资源并分配给内部的任务。同时,也负责跟踪任务的状态并监听任务的执行进度。 -
Container是Yarn中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。任务最终是在Container中执行。
-
3、Yarn基础操作
Yarn提供了一个UI管理页面,默认访问ResourceManager所在服务器的8088端口,可以访问到Yarn的监控页面。
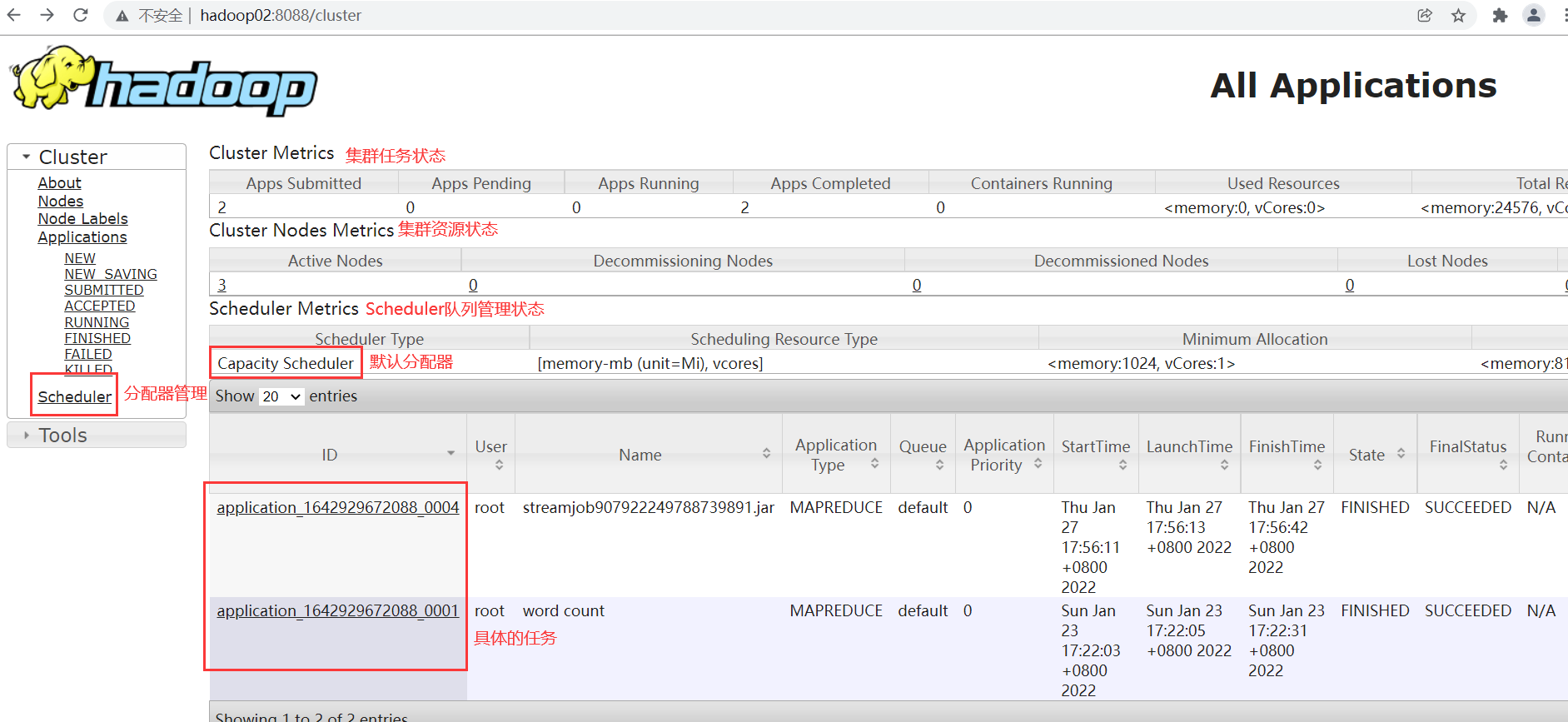
大部分的日常监控需求,例如监控任务进度,查看任务日志,查看参数配置等,在这个UI界面都可以完成。另外,Yarn也提供了一系列指令,可以来查看集群中的任务状态。最为常用的几个指令需要熟悉一下。
bash
yarn application -list #查看当前正在执行的任务 yarn application -list -appStates ALL #查看所有任务 yarn application -list -appId appId #查看某一个任务的详情 yarn application -kill appId #强行关闭一个任务 yarn application -stop [appName+appType | appId] #停止一个任务 yarn application -start appName #继续启动一个任务
Yarn还提供了非常丰富的管理指令,例如管理队列、健康检查、调整配置等。具体可以查看官方手册:https://hadoop.apache.org/docs/r3.2.2/hadoop-yarn/hadoop-yarn-site/YarnCommands.html
同时,Yarn还提供了一套Rest API,可以快速了解集群的运行状态。例如:
bash
http://hadoop02:8088/ws/v1/cluster/apps/ #查看集群所有应用信息 http://hadoop02:8088/ws/v1/cluster/apps/application_1642929672088_0004 #查看某一个应用的信息 http://hadoop02:8088/ws/v1/cluster/metrics #查看集群矩阵信息 http://hadoop02:8088/ws/v1/cluster/scheduler #查看Scheduler组件状态。 http://[NN Ip]:[port]/ws/v1/node #查看NodeManager的状态,需要在任务执行期间。IP和Port从监控页面获取
与其他组件类似,Yarn的Rest API还提供了任务管理的功能。例如直接创建Container、提交任务等。不过通常用得比较少,所以大致了解一下即可。具体参见官方手册:https://hadoop.apache.org/docs/r3.2.2/hadoop-yarn/hadoop-yarn-site/yarn-service/YarnServiceAPI.html
二、Yarn核心机制
1、Yarn整体工作流程
对于一个典型的MapReduce计算任务,Yarn集群的执行机制大概如下图:
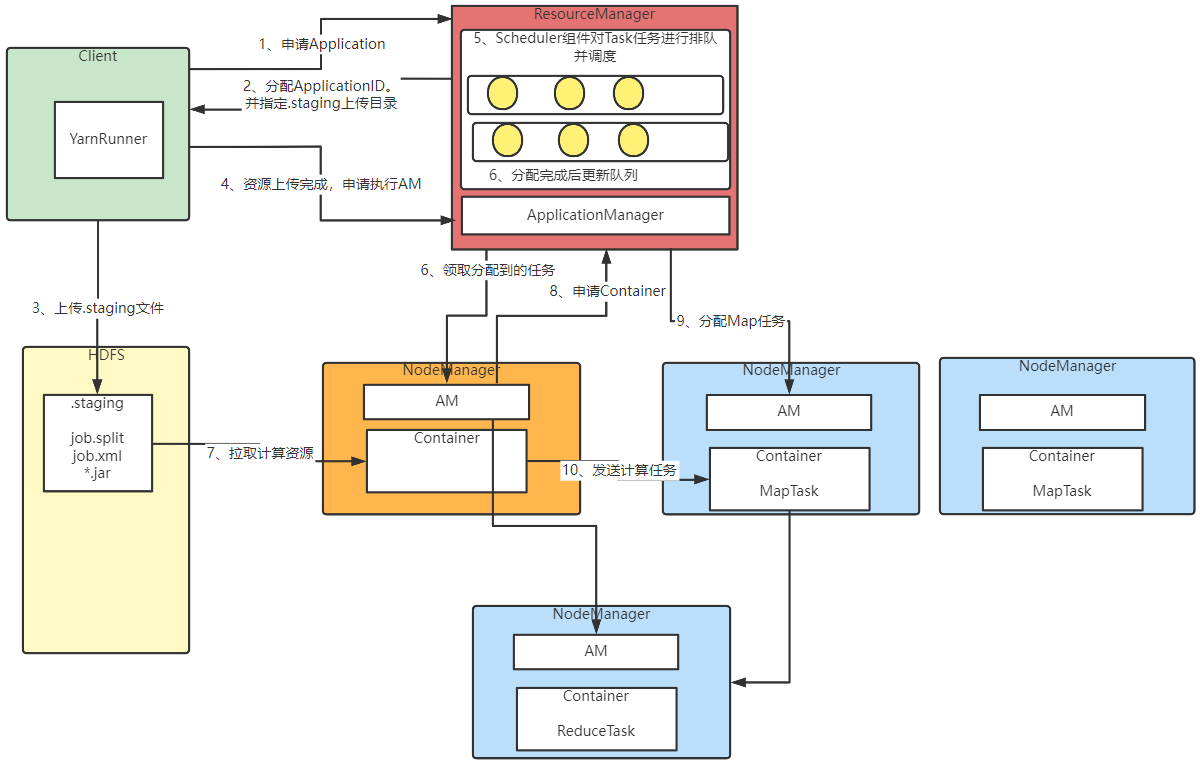
在图中第6步,ResourceManager的ApplicationManager负责通知第一个处理任务的NodeManager,并启动对应的ApplicationMaster。后续的计算任务,就交由该NodeManager上的AM来协调了。ResourceManager只负责资源调度,不参与具体的计算过程。
可以看到,在ResourceManager中,会维护一系列的任务队列Queue,这些任务队列可以在监控页面查看到。
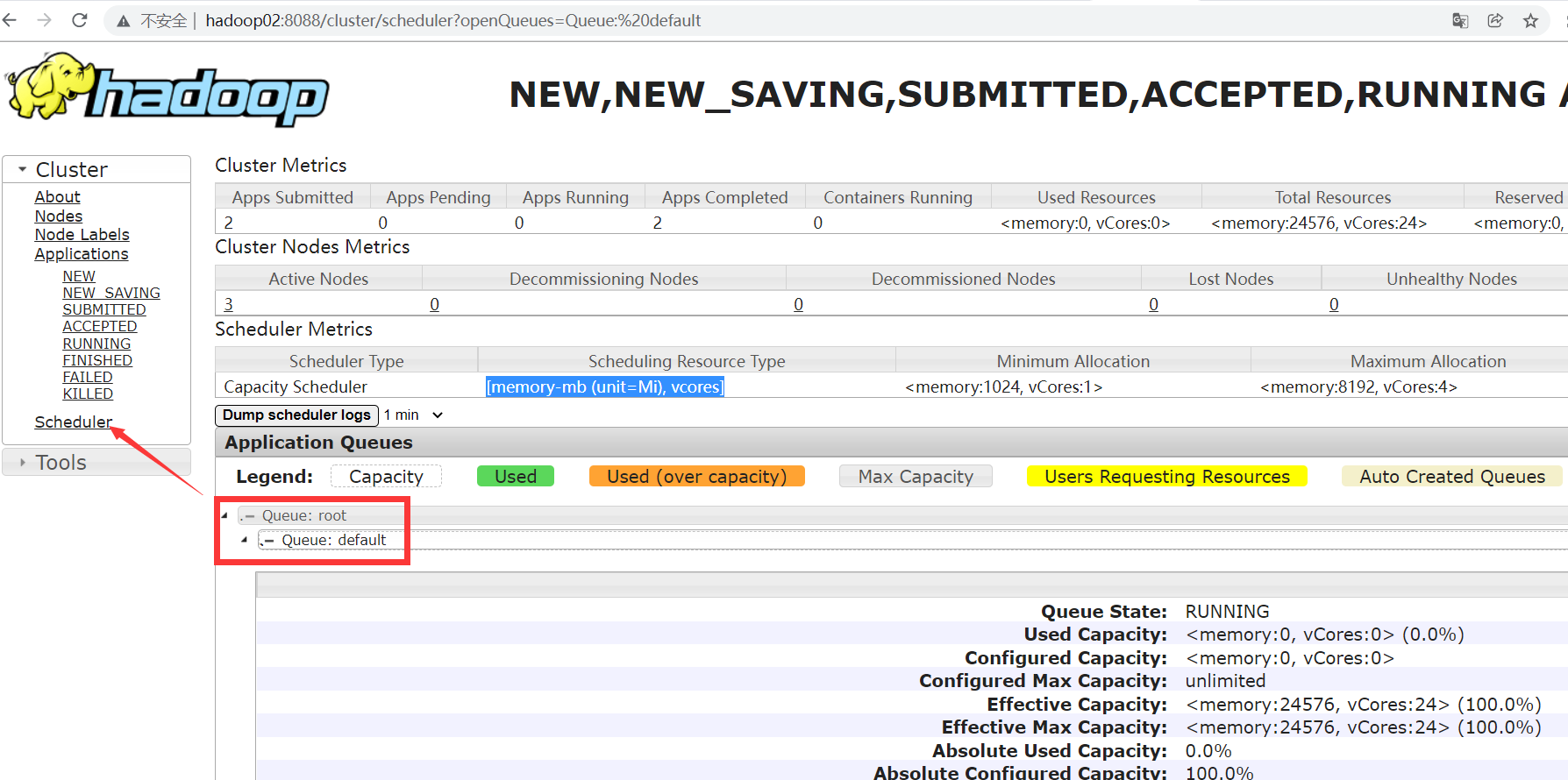
客户端提交过来的计算任务(例如MapReduce中的MapTask和ReduceTask),ResourceManager都会保存到这些队列当中(后续会有演示如何自定义队列)。接下来,ResourceManager就会交由Scheduler组件来对排队的任务进行分配,同时决定如何给不同的计算任务分配计算资源。
很显然,对于一个繁忙的大型Yarn集群,ResourceManager在任务排队这块成了一个单点的性能瓶颈,而调度器的性能就极大程度上影响到了整个集群的工作效率。接下来我们就来重点理解一下Scheduler组件进行任务调度的核心算法。
2、Yarn的核心调度算法
目前,Hadoop有两种作业调度器,容量调度器(Capacity Scheduler)和公平调度器(Fair Scheduler)。Apache版本的Hadoop默认选择的是容量调度器,而CDH版本的Hadoop默认选择的是公平调度器。
配置调度器可以在yarn-site.xml中进行配置。默认的配置如下:
xml
<property> <description>The class to use as the resource scheduler.</description> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> </property>
如果要选择公平调度器,可以将属性配置为org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler。
那这两种调度器应该要如何选择呢?下面就来理解下这些调度器的底层原理。
1)FifoScheduler 先进先出调度器
实际上,如果使用CDH搭建Hadoop集群,可以看到Yarn有三种可选的Scheduler,还有一种是org.apache.hadoop.yarn.server.resourcemanager.scheduler.fifo.FifoScheduler。
这种调度器的工作机制比较简单,就是把任务按照提交的顺序排成一个队列,然后按照FIFO先进先出的顺序,以此执行。而在进行资源分配时,也是先给队列中头部的任务分配资源,资源满足后,就开始执行头部任务。等头部任务的执行完成后,再给下一个任务分配资源。
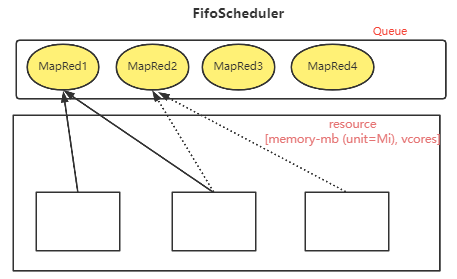
这种调度器的实现较为简单,因此也不需要太多的配置参数。但是他的并发性能非常低。大任务执行期间也会导致其他任务被阻塞。整个集群的并发性能几乎没有,这在大规模的共享集群中是无法接受的。所以,一般集群部署的Hadoop都不会选择FifoScheduler。
而后续的CapacityScheduler和FairScheduler都允许任务在提交的同时就获得一定的系统资源,可以并发的执行。
2)CapacityScheduler容量调度器
这是Apache版本的Hadoop默认的调度器。在${HADOOP_HOME}/etc/hadoop目录下,默认提供了一个capacity-scheduler.xml配置文件,里面有相关的配置参数。
容量调度器对于任务队列的管理,有以下几个特性。
1> 按容量分配队列
容量调度器允许创建多个队列,并给每个队列分配一个默认的容量上限。
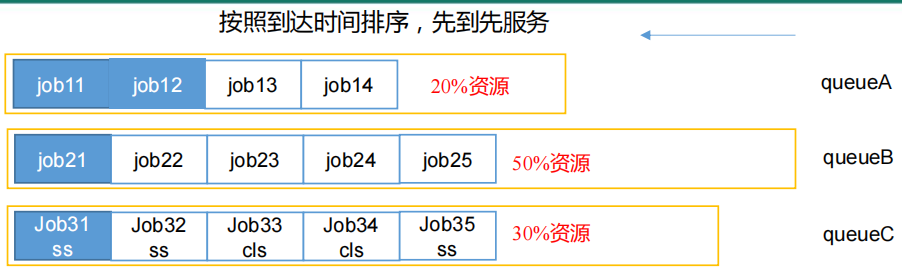
默认只创建一个default队列,占用 100%100% 的资源。可以在配置文件中自行分配队列。
在每个队列内部,按照FIFO的方式进行调度。也就是说,Apache版本Hadoop默认提供的配置文件就是一个CapacityScheduler实现的FifoScheduler。

但是在这里要注意下,虽然给每个队列配置了容量的百分比,但是这个百分比并不是绝对的。容量调度器允许队列之间灵活的借调计算资源。例如对于QueueA,QueueB,QueueC三个队列,如果QueueA的任务比较多,容量不够,而QueueB的任务比较少,容量有空余时,容量调度器允许QueueA临时借调QueueB的部分计算资源,等待QueueA的容量空闲时再归还。
当然,这种临时借调也不会是无限制的。所以还增加了一个配置项,用来控制每个队列最大的容量占比。
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>100</value>
<description>
The maximum capacity of the default queue.
</description>
</property>
2> 多用户共享集群资源
容量调度器允许多个用户提交任务,并且针对提交任务的用户,可以进行队列管理。这里用户的概念跟HDFS中的多用户是相对应的。例如,可以配置ss用户和cls用户提交的任务都分配到queueC队列上。
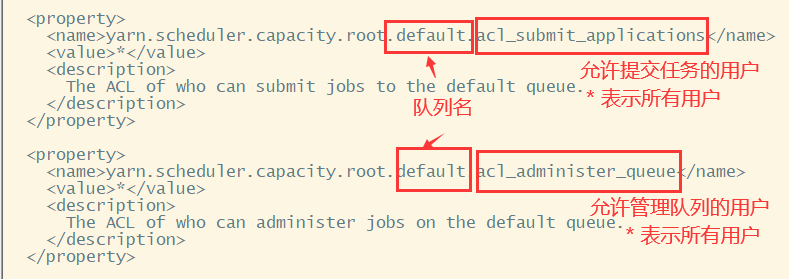
接下来,可以配置一个用户与队列的对应关系,给每个用户指定提交的任务队列。
<property>
<name>yarn.scheduler.capacity.queue-mappings</name>
<value></value> <!-- 例如: u:root:default -->
<description>
A list of mappings that will be used to assign jobs to queues
The syntax for this list is [u|g]:[name]:[queue_name][,next mapping]*
Typically this list will be used to map users to queues,
for example, u:%user:%user maps all users to queues with the same
name
as the user.
</description>
</property>
当然,既然允许多用户提交任务,那也就必须对用户提交的任务增加限制,不能让一个用户无限制的提交任务占用大量的计算资源。
<property>
<name>yarn.scheduler.capacity.root.default.user-limit-factor</name>
<value>1</value>
<description>
Default queue user limit a percentage from 0.0 to 1.0.
</description>
</property>
使用容量调度器的优点,一是增加了多个队列后,多个队列的任务可以并行执行。二是可以将占用资源较多的大任务和占用资源较少的小任务分开管理。这样可以提高计算资源的回收速度。实际上,在容量调度器的算法底层,在不设定任务优先级的情况下,也是尽量优先保证小任务的执行,并且分配的计算资源也尽量集中(按节点距离)。这样可以提高计算资源的回收效率。三是基于多用户的管理也比较适合管理接入应用用户比较多的企业级的统一平台。因此容量调度器已经能够很好的管理大型的共享集群。
容量调度器也有一个比较明显的缺点。预先维护多个任务队列需要消耗一定的集群资源,并且分配任务时,需要根据任务情况进行资源调度,这会导致大任务的执行时间会落后于FIFO调度器的时间。这在计算频率很高,计算任务也很大的大压力集群下,性能还是会有所下降。
3)FairScheduler公平调度器
公平调度器是由Facebook开发的一个多用户调度机制。他也是一个多队列的用户调度器,队列之间依然可以进行资源隔离。而他与容量调度器最明显的区别在于,容量调度器需要根据任务占用的计算资源灵活调度资源,而公平调度器则是所有任务公平对待,一视同仁。只要接收到任务,不管任务所需资源多少,都按照统一的规则,公平分配资源。这样可以减少容器调度器进行资源调度时的时间消耗。
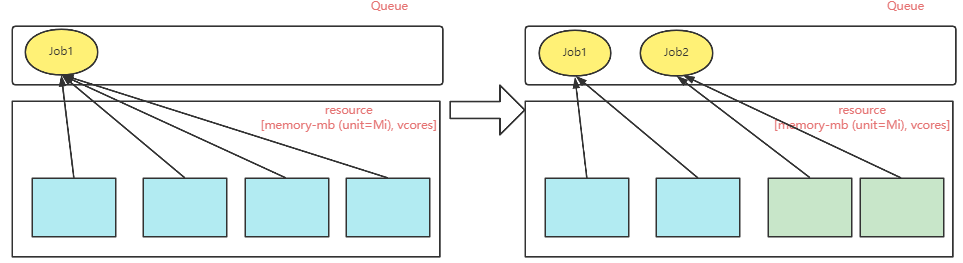
公平调度器的执行方式是这样的:
-
同一个队列上的所有任务共享集群资源,不预先抢占资源。当集群中只有一个任务时,就会占用整个队列的资源。
-
当队列中新增了任务后,就会按照任务个数,平均的调整计算资源分配。例如,队列中有两个任务,那就每个任务占用一半的计算资源,三个任务,就每个任务占据1/3的计算资源。这样每个任务都可以公平的获得一部分的计算资源,不会出现一个大任务把资源全部抢占完的情况。
-
具体到任务执行时,这样平均分配计算资源的方式,肯定不可能正好满足所有任务的需求。对于这些不满足需求的任务,调度器首先会在队列之间进行资源借调,如果借调不满足的话,调度器会计算每个任务已分配的计算资源与需要的计算资源之间的差额,优先选择差额较小的任务分配资源并执行。而对于超额的任务,调度器会采用先等待再回收的策略。即先等待一段时间,看是否有归还出来的计算资源。如果资源长期得不到满足,那么调度器就会在超额的计算任务中杀死一部分任务,释放资源,尽量让其他任务先满足需求执行起来。
关于FairScheduler的使用配置,由于Apache版本的Hadoop并不作为默认调度器,所以也就没有提供默认的配置文件。手动配置会比较繁琐。通常都是结合CDH来进行配置。我们这里就不做过多演示了,有兴趣的话,可以参考下官方的指导手册:https://hadoop.apache.org/docs/r3.2.2/hadoop-yarn/hadoop-yarn-site/FairScheduler.html
4)CapacityScheduler和FairScheduler的区别
FairScheduler相比CapacityScheduler,还是体现出了一些优点:
-
资源共享更灵活。FairScheduler在队列管理时,支持更多的管理策略。在FIFO的基础上,还支持Fair和DRF策略。默认使用的是Fair策略,一种基于最大最小公平算法实现的资源多路复用方式。而DRF全称为Dominant Resource Fairness。他是一种综合的分配方案。我们之前所说的计算资源,通常更多都是根据内存进行分配(因为CPU核心数的竞争压力相对比较小),Yarn默认也是按照内存来进行分配。而DRF可以根据多个指标定制更复杂的分配策略。
-
负载均衡。FairScheduler提供了一个基于任务数的复杂均衡策略,可以尽可能的将任务均匀的分配到集群中的各个节点上。此外,管理员也可以根据自己的需求灵活定制负载均衡策略。
-
提高小计算任务的响应时间。由于采用的公平算法,小任务可以更快速的获取资源并快速完成。
综合比较这两种调度器,FairScheduler的并发能力会更高,但是相应的,配置也会更繁琐,对运维的要求更高。所以,在一些节点非常多,计算任务也非常大的大型Hadoop集群中,可以选择采用FairScheduler。而对于一般场景下的Hadoop集群,则使用CapacityScheduler比较合适。
三、生产优化
1、ResourceManager高可用
资源管理器在Yarn集群中的作用,类似于NameNode在HDFS集群中的作用,也同样有单点崩溃的风险。而在Hadoop2.4版本以前,Hadoop并没有提供官方的ResourceManager高可用功能,企业只能依靠CDH或者其他一些运维手段去实现ResourceManager的高可用。而在当前版本下,Hadoop提供了ResourceManager的高可用功能。
其基础思想是通过Zookeeper来维护一对ResourceManager节点,这一对ResourceManager节点分别处于Active和Standby状态。Standby状态的RM节点作为备份节点,提供HA功能。在这个HA集群中,Zookeeper即负责进行主节点选举,同时也负责保存RM的一些状态信息。而这,即是一个便利,同时也是一种风险,需要均衡考虑。
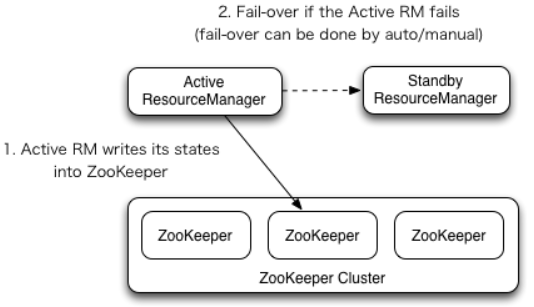
关于RM的状态信息,Hadoop也提供了多种实现机制,由参数
yarn.resourcemanager.store.class指定。默认选项是org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore,基于HDFS或者本地文件系统实现状态共享。另外还有两个可选机制:org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore,基于ZK实现状态共享。以及org.apache.hadoop.yarn.server.resourcemanager.recovery.LeveldbRMStateStore基于LevelDB实现状态共享。详细配置信息请参见官方手册:https://hadoop.apache.org/docs/r3.2.2/hadoop-yarn/hadoop-yarn-site/ResourceManagerRestart.html
而在这几种状态实现机制中,Leveldb方式太重了,一般只有少数大型企业会采用。而FileSystemRMStateStore基于文件的保存方式,由于IO的限制,写入的速率不可能太频繁,因此在HA场景下,很难保证数据不丢失。所以,官方建议还是使用ZKRMStateStore实现。
关于RM的HA机制,相关的参数非常多,具体可以到yarn-default.xml中去查看。这里列出几个比较重要的配置方式。
| Configuration Properties | Description |
|---|---|
hadoop.zk.address |
Address of the ZK-quorum. Used both for the state-store and embedded leader-election. |
yarn.resourcemanager.ha.enabled |
Enable RM HA. |
yarn.resourcemanager.ha.rm-ids |
List of logical IDs for the RMs. e.g., "rm1,rm2". |
yarn.resourcemanager.hostname.rm-id |
For each rm-id, specify the hostname the RM corresponds to. Alternately, one could set each of the RM's service addresses. |
yarn.resourcemanager.address.rm-id |
For each rm-id, specify hostport for clients to submit jobs. If set, overrides the hostname set in yarn.resourcemanager.hostname.rm-id. |
yarn.resourcemanager.scheduler.address.rm-id |
For each rm-id, specify scheduler hostport for ApplicationMasters to obtain resources. If set, overrides the hostname set in yarn.resourcemanager.hostname.rm-id. |
yarn.resourcemanager.resource-tracker.address.rm-id |
For each rm-id, specify hostport for NodeManagers to connect. If set, overrides the hostname set in yarn.resourcemanager.hostname.rm-id. |
yarn.resourcemanager.admin.address.rm-id |
For each rm-id, specify hostport for administrative commands. If set, overrides the hostname set in yarn.resourcemanager.hostname.rm-id. |
yarn.resourcemanager.webapp.address.rm-id |
For each rm-id, specify host:port of the RM web application corresponds to. You do not need this if you set yarn.http.policy to HTTPS_ONLY. If set, overrides the hostname set in yarn.resourcemanager.hostname.rm-id. |
yarn.resourcemanager.webapp.https.address.rm-id |
For each rm-id, specify host:port of the RM https web application corresponds to. You do not need this if you set yarn.http.policy to HTTP_ONLY. If set, overrides the hostname set in yarn.resourcemanager.hostname.rm-id. |
yarn.resourcemanager.ha.id |
Identifies the RM in the ensemble. This is optional; however, if set, admins have to ensure that all the RMs have their own IDs in the config. |
yarn.resourcemanager.ha.automatic-failover.enabled |
Enable automatic failover; By default, it is enabled only when HA is enabled. |
yarn.resourcemanager.ha.automatic-failover.embedded |
Use embedded leader-elector to pick the Active RM, when automatic failover is enabled. By default, it is enabled only when HA is enabled. |
yarn.resourcemanager.cluster-id |
Identifies the cluster. Used by the elector to ensure an RM doesn't take over as Active for another cluster. |
yarn.client.failover-proxy-provider |
The class to be used by Clients, AMs and NMs to failover to the Active RM. |
yarn.client.failover-max-attempts |
The max number of times FailoverProxyProvider should attempt failover. |
yarn.client.failover-sleep-base-ms |
The sleep base (in milliseconds) to be used for calculating the exponential delay between failovers. |
yarn.client.failover-sleep-max-ms |
The maximum sleep time (in milliseconds) between failovers. |
yarn.client.failover-retries |
The number of retries per attempt to connect to a ResourceManager. |
yarn.client.failover-retries-on-socket-timeouts |
The number of retries per attempt to connect to a ResourceManager on socket timeouts. |
例如,我们在hadoop01,hadoop02,hadoop03三台服务器上部署了Zookeeper服务后,可以修改Hadoop的yarn-site.xml文件,修改如下配置片段:
xml
<property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>mycluster</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1, rm2, rm3</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop01</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop02</value> </property> <property> <name>yarn.resourcemanager.hostname.rm3</name> <value>hadoop03</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>hadoop01:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>hadoop02:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm3</name> <value>hadoop03:8088</value> </property> <property> <name>hadoop.zk.address</name> <value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value> </property>
然后需要重启yarn集群,可以在hadoop01和hadoop02两台机器上看到ResourceManager进程。
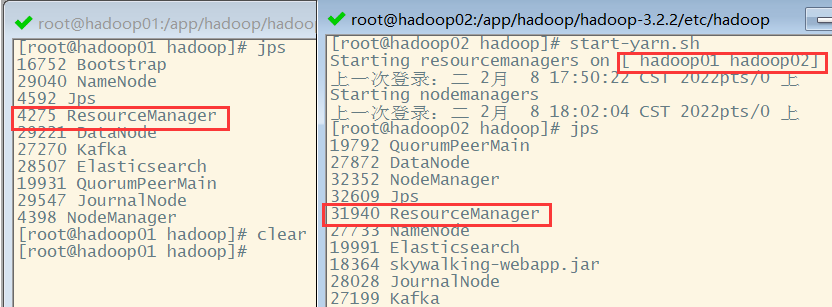
接下来,可以访问RM管理页面的isActive端口,获取节点状态。例如http://hadoop01:8088/isActive。如果当前节点是active状态,会返回一个字符i am active。如果当前节点是standby状态,则会返回一个405的错误页面。
可以使用yarn rmadmin指令查看两个RM节点的状态。可以看到,Yarn基于ZK 选择出了一个active状态的主节点。
另外,也可以使用yarn rmadmin -transitionToStandby rm1和yarn rmadmin -transitionToActive rm1指令手动切换RM的节点状态。基础的管理方式跟HDFS的高可用是差不多的。
这时,如果访问Standby的RM节点的8088管理页面,http://hadoop01:8088/,会自动跳转到active状态的RM节点的管理页面。对Standby状态的RM节点的RestAPI的访问也都会自动转到Active状态的主RM上。
2、多队列任务管理
需求描述:在Yarn中新增加一个dev队列,用于开发测试的任务计算。
配置队列:这里就使用默认的CapacitvScheduler来进行配置。直接修改capacity-scheduler.xml,增加dev队列配置。
xml
<configuration>
<!-- 原有配置省略 -->
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,dev</value><!-- 指定队列,队列可以有多个层级 -->
<description>
The queues at the this level (root is the root queue).
</description>
</property>
<!-- default queue -->
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>60</value> <!-- 调整容量 -->
<description>Default queue target capacity.</description>
</property>
<!-- dev queue -->
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>40</value>
</property>
<!-- 其他配置省略,参照原有的default队列配置即可 -->
</configuration>
配置文件修改完成后,分发到集群中所有节点上。接下来要让配置信息生效。当然可以重启Yarn集群,但是对于queue相关的配置,Yarn提供了实时加载的指令:yarn rmadmin -refreshQueues。
注意:在HA集群下,客户端会以轮询的方式访问多个节点。这就相当于配置信息会在一次请求中被重复更新了。需要确保所有RM节点配置一致。
修改完成后,在Yarn的监控页面就能看到新增加的队列。
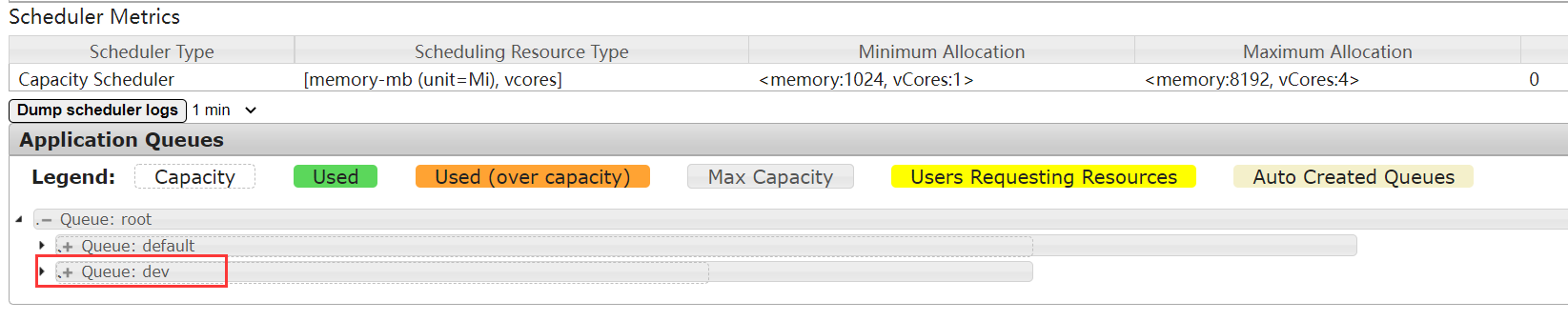
接下来,就可以尝试往dev队列中提交一个WordCount计算任务。
bash
hadoop jar /app/hadoop/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount -Dmapreduce.job.queueName=dev /input2 /output2
任务执行过程中,也可以从Yarn监控页面跟踪到队列的使用情况。
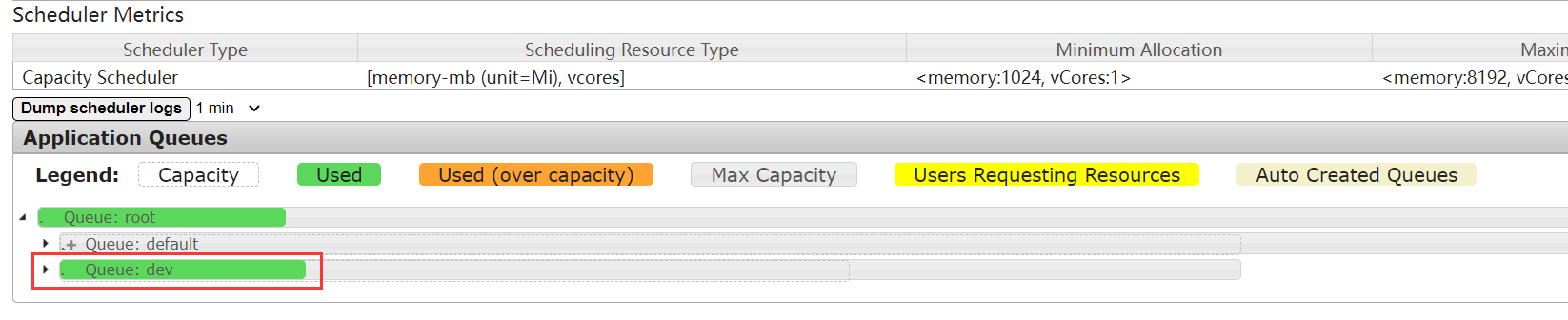
这样就完成了一个简单的多队列管理。在我们这个实验过程中,通过提交任务时配置mapreduce.job.queueName属性的方式来指定提交队列,这样还是比较麻烦的。实际上,对于自定义的MapReduce计算任务,这个属性放到Driver类中更为常见。另外,其实企业中更建议的队列管理方式还是按照用户进行管理。
3、使用GPU加速计算
这是Hadoop3.x版本提供的新的功能支持。如果你的服务器配置了Nvidia系列的显卡,那么可以考虑使用GPU加速计算。一般情况下,对计算性能的提升还是比较明显的。具体配置参见官方手册:https://hadoop.apache.org/docs/r3.2.2/hadoop-yarn/hadoop-yarn-site/UsingGpus.html
使用GPU来加速计算,这在大数据领域是非常常见的一种手段,尤其比较复杂的机器学习、神经网络等大型计算任务,更是离不开GPU的支持。如果你的Hadoop集群对计算性能的要求确实比较高,预算又比较充足的话,给服务器添加显卡会是一个不错的选择。
四、Hadoop总结
Hadoop可以说是一个划时代的产品,可以说正是Hadoop产品开创了互联网开源的大数据时代。但是时至今日,Hadoop已经不光只是一个大数据产品,更代表了一系列的生态。他承载的不光是自己的HDFS、Yarn等工具,更是Spark、Hive、HBase、Flink等非常多的大型框架。同时,他也成了大数据时代的一个标准,所有大数据相关的产品,像Clickhouse,ES等都必须要考虑如何跟Hadoop对接。甚至包括Hadoop本身,也在不断的对接其他的生态产品。
所以对于大数据产品,一定不能只是作为单独的组件来学习,要学会把问题放在整个大数据生态圈中来考虑。对于Hadoop,你需要更深入的学习其中的细节,更需要学会抽象总结出自己的问题。并将这些问题,带到后续大数据组件的学习过程当中。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)