小白程序员必备:大模型在医疗领域的实际应用与精准评估教程
本文通过一个试点研究,评估了AI医疗搜索引擎OpenEvidence在复杂医学专科场景中的表现。研究发现,OpenEvidence的两种模式(快速搜索OE和深度咨询DC)的准确率远低于预期,最高仅为41%,且可重复性也有待提高。尽管OpenEvidence在USMLE考试中表现优异,但这一结果与真实临床场景存在差距。研究强调,在临床决策中使用AI工具时必须有专家监督,并建议未来进行更大规模、多维度
本文通过一个试点研究,评估了AI医疗搜索引擎OpenEvidence在复杂医学专科场景中的表现。研究发现,OpenEvidence的两种模式(快速搜索OE和深度咨询DC)的准确率远低于预期,最高仅为41%,且可重复性也有待提高。尽管OpenEvidence在USMLE考试中表现优异,但这一结果与真实临床场景存在差距。研究强调,在临床决策中使用AI工具时必须有专家监督,并建议未来进行更大规模、多维度评估,以提升AI在医疗领域的准确性和可靠性。

The accuracy and repeatability of OpenEvidence on complex medical subspecialty scenarios: a pilot study
摘要
本研究评估了流行的AI医疗搜索引擎OpenEvidence在复杂医学专科场景中的表现。研究团队使用MedXpertQA数据集中的100个医学专科场景,通过两名独立评估者测试了快速搜索(OE)和深度咨询(DC)两种模式。结果显示,DC模式的最高准确率仅为41%,OE模式为34%,远低于预期。可重复性测试显示评估者一致性率分别为77%(OE)和72%(DC)。研究强调在临床决策中使用这些AI工具时必须有专家监督。
阅读原文或https://t.zsxq.com/wy43l获取原文pdf
一、研究背景:AI如何改变医疗信息检索
医疗实践中的信息获取困境
医学实践需要广博的知识、批判性思维和丰富的经验。然而,临床医生经常遇到诊断或治疗方案不确定的情况,需要扩展鉴别诊断范围。这时,获取高质量、最新的信息至关重要。传统教科书往往过时,文献检索可能缓慢且效率低下。
正因如此,UpToDate、DynaMed和Epocrates等在线资源广受欢迎。但UpToDate庞大内容的导航复杂性及其成本一直是挑战。2025年中期,UpToDate推出了支持AI的版本,允许使用自然语言处理进行搜索。
OpenEvidence的诞生与发展
OpenEvidence是医疗领域的另一个重要工具。它由Daniel Nadler博士于2023年作为梅奥诊所平台加速计划的一部分创建。该平台基于循证医学,与《美国医学会杂志》(JAMA)和《新英格兰医学杂志》(NEJM)建立了内容协议,共享全文内容。许多OE和DC的答案包含来自这些资源的图像或表格。OpenEvidence还与Elsevier的ClinicalKey AI合作提供医疗内容。
OpenEvidence的核心特点:
-
双模式搜索系统
:提供快速搜索(OE)和深度咨询(DC)两种模式
-
多平台支持
:基于网页,同时提供iOS和Android应用
-
丰富功能
:创建患者宣传册、生成表格、计算风险评分、创建多选题、起草事先授权信函等
-
卓越表现
:2025年在美国医学执照考试(USMLE)中获得100%的分数
-
广泛使用
:截至2025年7月拥有40万用户,对美国持有NPI编号的医生和部分海外地区免费
技术架构的独特性
根据Nadler博士的说法,OpenEvidence是"专业模型的集合而非单一大型模型",所有模型都专门在同行评审的医学文献上训练,不连接公共互联网。这表明OpenEvidence使用了检索增强生成(RAG)技术。
据一位消息人士称,DC是一个代理AI系统,比OE更强大,但计算需求更高。迄今为止,尚未有研究评估其准确性。
二、研究设计与方法论
MedXpertQA数据集的创新性
标准医学委员会考试题(如USMLE中的题目)已不再足够,因为它们无法全面测试医学推理能力。
2025年,Zuo等人发表了关于MedXpertQA数据集创建的文章。该数据集包含4,460个问题,来自USMLE、COMLEX-USA和17个美国医学专科委员会,涵盖11个身体系统。
数据集的独特设计:
-
语义过滤
:使用概率语义相似性过滤高度相似的问题
-
问题修改
:对问题进行轻微修改,降低LLM在训练中遇到它们的可能性
-
增加难度
:将可能答案扩展到10个选项,使决策更加困难
-
专家审核
:由医生审核问题的准确性和有效性
-
分类细致
:分为"文本"和"多模态"评估,文本类别进一步分为推理和理解场景
在该数据集上测试了12个大型语言模型,在推理数据子集上,GPT-o1的准确率最高为46%,Qwen2.5-32B最低为14%。
本研究的目标与假设
研究目标:
使用MedXpertQA数据集评估OE和DC模型的准确性,将结果与Zuo等人文章中报告的LLM进行比较。此外,由于OE和DC缺乏可重复性数据,两名研究人员将测试相同的医学场景以确保一致性。
研究假设:
研究团队假设OE和DC的准确性会高于先前研究中的LLM表现。
样本设计:
从数据集中随机选择100个基于文本的推理场景作为本试点研究的基础。
三、研究结果:令人深思的发现
整体准确性分析
研究结果显示了出乎意料的表现。两种模式的准确率都相对较低:
按评估者和方法分类的准确率:
-
OE-JJ模式
:34.0%
-
OE-RH模式
:38.0%
-
DC-JJ模式
:38.0%
-
DC-RH模式
:41.0%
DC-RH达到了最高准确率41%,但这一数字仍然远低于临床应用的期望水平。
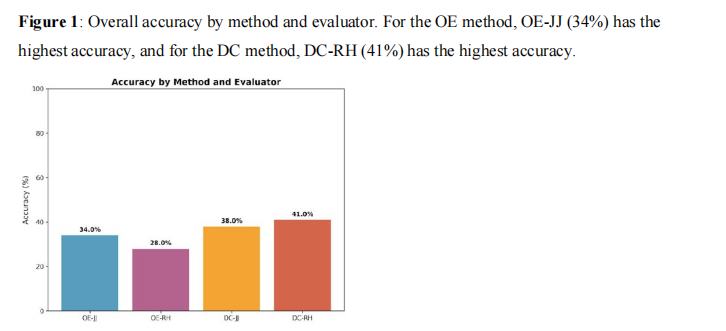
如图1所示,横轴为四种评估组合(OE-JJ, OE-RH, DC-JJ, DC-RH),纵轴为准确率百分比。DC-RH显示最高准确率41%,OE-JJ最低为34%。
按身体系统的详细分析
研究对不同身体系统的准确率进行了细致分析,结果显示各系统间存在显著差异:
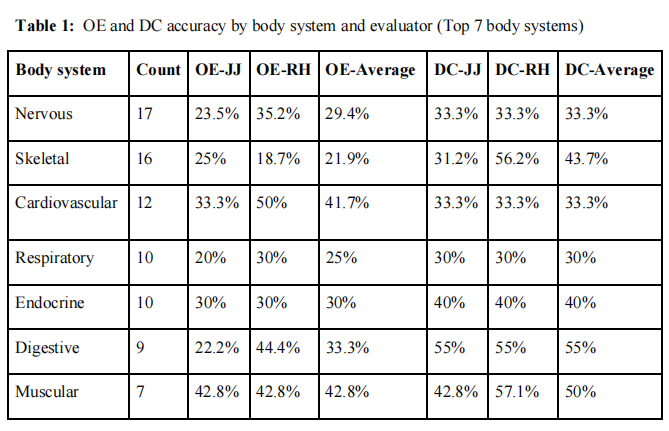
前7个身体系统的表现:
-
消化系统
:DC表现最佳,平均准确率55%
-
肌肉系统
:DC平均准确率50%,两种方法都有良好表现
-
骨骼系统
:DC平均准确率43.7%,但评估者间差异较大(31.2% vs 56.2%)
-
心血管系统
:OE平均准确率41.7%,DC为33.3%
-
内分泌系统
:DC平均准确率40%,两位评估者完全一致
-
神经系统
:两种方法准确率相近,均在30%左右
-
呼吸系统
:两种方法准确率均为30%或以下
关键发现:
- 消化系统和肌肉系统的准确率相对较高
- 某些系统(如骨骼系统)评估者间差异显著
- 没有任何身体系统的准确率超过55%
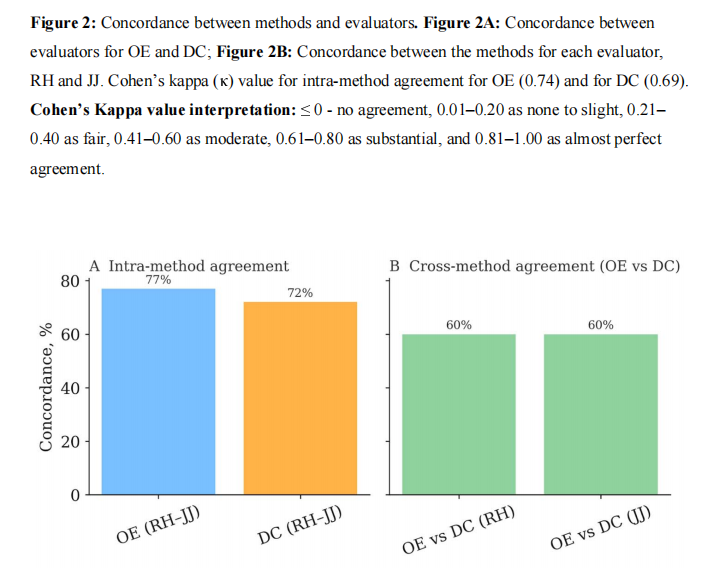
可重复性评估
可重复性测试揭示了另一个重要问题:
-
OE模式
:评估者一致性率为77%
-
DC模式
:评估者一致性率为72%
这些数字低于预期,考虑到临床医生已开始在临床护理点使用这些工具进行临床决策支持,这一发现令人担忧。
四、与既往研究的对比
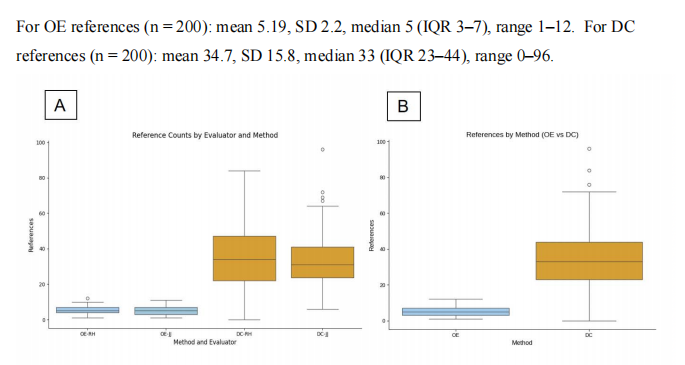
有限的准确性研究
评估OpenEvidence准确性和完整性的研究一直有限:
Hurt等人的研究:
研究了五个常见初级保健医学问题(高血压、高脂血症、2型糖尿病、抑郁症和肥胖)。尽管在清晰度、相关性、支持度和满意度方面得分很高,但对临床决策的影响微乎其微。换句话说,它强化了计划而不是修改计划。
Low等人的比较研究:
比较了OE、ChatRWD和三个LLM在50个开放式临床场景上的表现。九名医生对准确性和相关性进行评分。ChatRWD达到58%,OE为24%,LLM为2-10%。
本研究的独特贡献
本研究是首个系统评估OpenEvidence在复杂医学专科场景中表现的研究,使用了标准化的MedXpertQA数据集,并首次评估了可重复性问题。
研究发现OpenEvidence在该数据集上的表现与公开可用的LLM相似,准确率较低。这与其在USMLE考试中100%的得分形成鲜明对比,提示标准化考试题目与真实复杂临床场景之间存在显著差距。
五、研究局限性与未来方向
当前研究的局限
虽然本研究提供了重要见解,但也存在一些局限性:
-
样本规模
:100个场景的试点研究,需要更大规模验证
-
评估者数量
:仅有两名独立评估者
-
数据集特异性
:仅使用MedXpertQA数据集
-
评估维度
:主要关注准确性,未全面评估临床实用性
未来研究建议
研究团队建议:
-
多样化测试场景
:在开放式问题和复杂场景上测试OE/DC,使用其可能未训练过的资源,如BMJ病例报告
-
扩大样本规模
:进行大规模验证研究
-
多维度评估
:评估准确性、可重复性、临床实用性等多个维度
-
真实世界验证
:在实际临床环境中评估其表现
六、临床应用的启示
关键要点
-
必须有专家监督
:这些发现强调,在临床护理中使用这些工具时必须有专家监督
-
谨慎使用
:不能完全依赖AI工具做出临床决策
-
持续验证
:需要对各种复杂专科医学场景、病例报告和其他医学资源进行进一步的大型研究
对医疗专业人员的建议
尽管OpenEvidence和类似的AI工具在医疗信息检索方面展现出潜力,但本研究结果表明:
-
辅助工具定位
:应将这些工具视为辅助决策工具,而非替代临床判断
-
交叉验证
:重要决策应通过多个来源验证
-
持续学习
:医疗专业人员需要了解这些工具的局限性
-
批判性思维
:保持对AI生成答案的批判性评估
七、结论与展望
核心结论
OpenEvidence在MedXpertQA数据集样本上表现出较低的准确性,与公开可用的LLM类似。该数据集的可重复性率低于预期,考虑到临床医生已开始在临床护理点使用这些工具进行临床决策支持,这令人担忧。
这些发现强调,在临床护理中使用这些工具时必须有专家监督。我们需要进一步的大规模研究来验证它们在各种复杂专科医学场景、病例报告和其他医学资源上的准确性和可重复性。
技术发展方向
未来的AI医疗工具需要:
-
提高复杂推理能力
:增强处理复杂医学场景的能力
-
优化可重复性
:提高不同使用场景下的一致性
-
增强透明度
:让医生了解AI决策的依据
-
持续学习机制
:根据新的医学证据不断更新
对行业的影响
本研究对医疗AI行业具有重要意义:
-
标准化评估
:需要建立更全面的AI医疗工具评估标准
-
监管框架
:可能需要更严格的监管和验证要求
-
临床培训
:医疗专业人员需要接受AI工具使用培训
-
持续研究
:需要更多独立研究评估这些工具的实际效果
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献737条内容
已为社区贡献737条内容

所有评论(0)