大模型落地全景指南:从技术实践到企业价值创造
《大模型落地全景指南》系统阐述了从技术到业务的大模型应用路径。文章聚焦四大核心支柱:微调技术(含LoRA高效微调方法)、提示词工程、多模态融合及企业级解决方案,通过技术原理、代码实现和行业案例,详细解析各环节实施要点。特别强调企业落地需构建数据治理-模型训练-应用开发-安全审计全流程体系,并针对数据质量、计算成本等挑战提出应对策略。指出大模型落地的本质是技术适配业务,建议企业提前布局数据治理和人才
大模型落地全景指南:从技术实践到企业价值创造
大模型落地已从概念验证进入规模化应用阶段,微调、提示词工程、多模态融合和企业级解决方案构成四大核心支柱。本文通过技术解析、代码实现、流程图解和实战案例,系统拆解落地路径,帮助企业跨越技术鸿沟,实现从模型能力到业务价值的转化。
一、大模型微调:定制化能力的技术基石
大模型微调通过在特定领域数据上持续训练,使通用模型适配垂直场景。按调整范围可分为全参数微调(Full Fine-tuning)和参数高效微调(PEFT),后者以LoRA(Low-Rank Adaptation)为代表,仅更新少量参数即可达到接近全量微调的效果。
技术原理:LoRA通过冻结预训练模型权重,在Transformer的注意力层注入可训练的低秩矩阵,将权重更新量从数十亿降低至百万级。以LLaMA-7B为例,LoRA微调仅需200M参数量即可适配医疗、法律等专业领域。
代码实现(基于Hugging Face PEFT):
from peft import LoraConfig, get_peft_model from transformers import AutoModelForCausalLM, AutoTokenizer # 加载基础模型 model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf") tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf") # 配置LoRA参数 lora_config = LoraConfig( r=16, # 低秩矩阵维度 lora_alpha=32, target_modules=["q_proj", "v_proj"], # 目标注意力层 lora_dropout=0.05, bias="none", task_type="CAUSAL_LM" ) # 注入LoRA适配器 model = get_peft_model(model, lora_config) model.print_trainable_parameters() # 输出可训练参数占比:仅0.19% # 训练代码(示例) from transformers import TrainingArguments, Trainer training_args = TrainingArguments( per_device_train_batch_size=4, gradient_accumulation_steps=4, learning_rate=2e-4, num_train_epochs=3, output_dir="./legal-lora-llama" ) trainer = Trainer(model=model, args=training_args, train_dataset=legal_dataset) trainer.train()
微调决策指南:
| 场景 | 全参数微调 | LoRA微调 |
|---|---|---|
| 数据规模 | 10万+样本 | 1千-10万样本 |
| 计算资源 | 8×A100 (100G)以上 | 单张A100即可 |
| 适用场景 | 领域深度适配 | 快速原型验证、轻量级定制 |
| 典型案例 | 行业大模型(如医疗GPT) | 企业客服机器人 |
流程图(Mermaid格式):
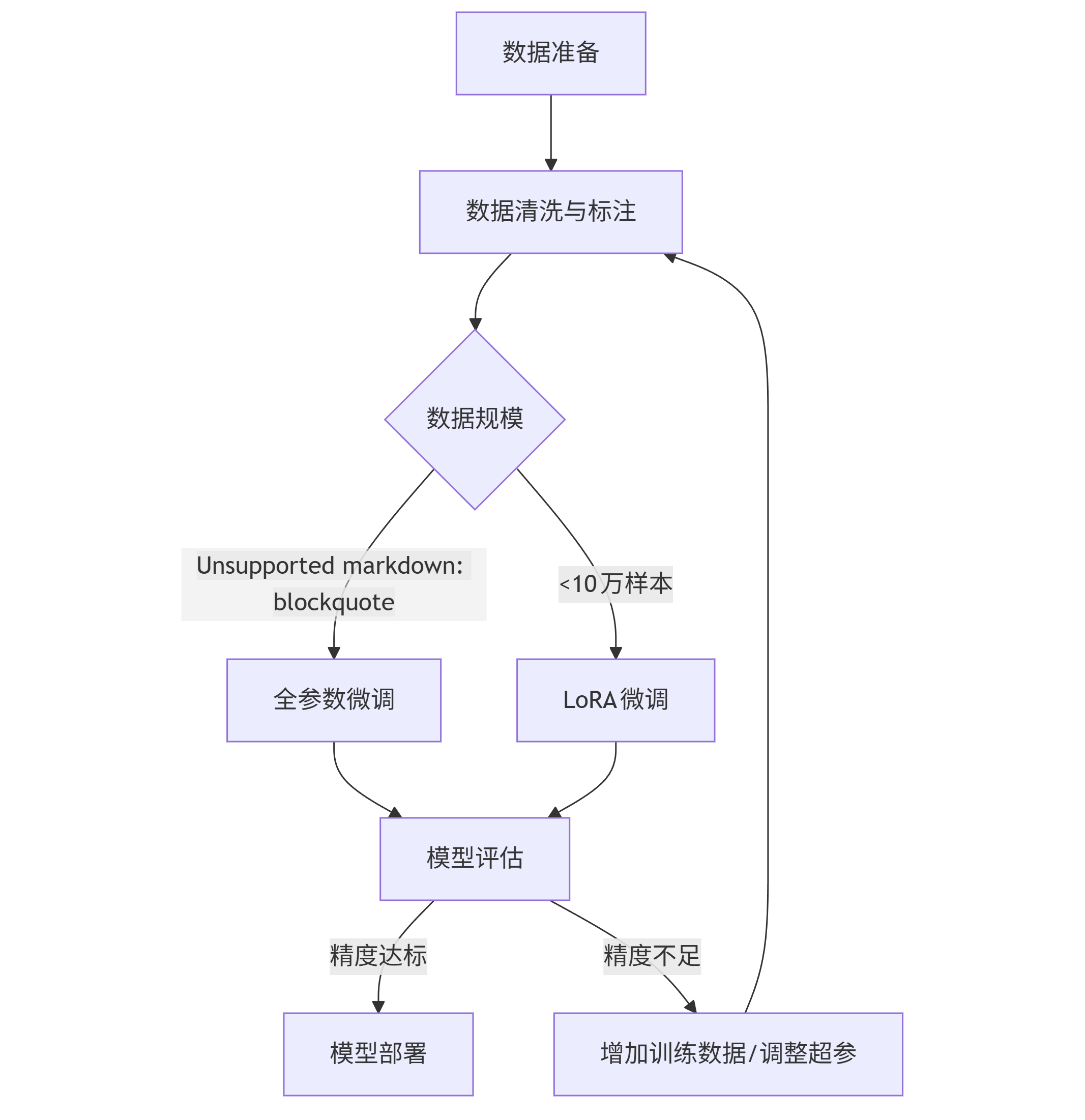
graph TD A[数据准备] --> B[数据清洗与标注] B --> C{数据规模} C -->|>10万样本| D[全参数微调] C -->|<10万样本| E[LoRA微调] D --> F[模型评估] E --> F F -->|精度达标| G[模型部署] F -->|精度不足| H[增加训练数据/调整超参] H --> B
二、提示词工程:零代码解锁模型能力
提示词工程(Prompt Engineering)通过设计输入文本引导模型输出预期结果,是成本最低的落地方式。核心技巧包括指令明确化、思维链(Chain-of-Thought) 和少样本学习(Few-Shot Learning)。
基础提示模板:
任务:{任务描述}
输入:{具体内容}
要求:{输出格式、长度、风格等约束}
示例:{参考案例,可选}
进阶技巧实战:
- 思维链提示(适用于复杂推理):
问题:某商店3件T恤120元,买5件送1件,买12件需支付多少元? 解答步骤: 1. 先计算单件T恤价格:120元 ÷ 3件 = 40元/件 2. 买5件送1件,即6件实际支付5件费用:5×40=200元 3. 12件包含2个6件,总费用:2×200=400元 答案:400元
- 角色代入法(提升专业度):
假设你是资深产品经理,分析以下需求并输出PRD大纲: 用户需求:开发一款支持语音控制的智能台灯,可调节亮度和色温。 PRD大纲应包含:功能模块、交互流程、非功能需求。
- 提示词评估指标:
| 指标 | 描述 | 优化方法 |
|--------------|-------------------------------|---------------------------|
| 指令遵循度 | 模型是否按要求完成任务 | 增加约束词(“必须”“严格”)|
| 输出相关性 | 回答与问题的关联程度 | 明确限定输出范围 |
| 幻觉率 | 生成虚假信息的比例 | 加入事实核查提示 |
工具推荐:
- PromptBase:提示词交易平台,提供行业优质模板
- LangChain:支持提示词模板管理和复杂流程编排
- PromptPerfect:自动优化提示词的AI工具
三、多模态应用:打破数据形式边界
多模态大模型(如GPT-4V、Gemini)可处理文本、图像、音频等多类型输入,典型应用包括视觉问答(VQA)、图文生成和跨模态检索。
技术架构:
图片
(注:实际部署时需替换为真实架构图,如CLIP的双编码器结构)
代码实现(基于GPT-4V API):
import base64 import requests # 图像转Base64 def image_to_base64(image_path): with open(image_path, "rb") as f: return base64.b64encode(f.read()).decode('utf-8') # 调用GPT-4V API进行视觉问答 api_key = "your-api-key" headers = {"Content-Type": "application/json", "Authorization": f"Bearer {api_key}"} image_b64 = image_to_base64("product.jpg") payload = { "model": "gpt-4-vision-preview", "messages": [{"role": "user", "content": [ {"type": "text", "text": "分析这张商品图片,提取产品名称、价格和促销信息"}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_b64}"}} ]}], "max_tokens": 300 } response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload) print(response.json()["choices"][0]["message"]["content"])
行业应用案例:
- 电商:图像搜索(拍图找商品)、自动生成商品描述
- 医疗:医学影像分析(X光片+报告生成)
- 教育:图文结合的智能辅导(如数学公式识别+解题)
四、企业级解决方案:从技术到业务的闭环
企业落地大模型需构建数据治理-模型训练-应用开发-安全审计全流程体系。以金融客服场景为例,完整方案包含以下模块:
1. 数据层
- 客户对话日志脱敏(去除身份证、银行卡号等敏感信息)
- 知识库构建(产品手册、政策文档向量化存储)
- 示例:使用LangChain实现文档向量化
from langchain.document_loaders import PyPDFLoader from langchain.embeddings import HuggingFaceEmbeddings from langchain.vectorstores import Chroma # 加载文档并分割 loader = PyPDFLoader("financial_product_manual.pdf") documents = loader.load_and_split() # 生成嵌入向量并存储 embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2") db = Chroma.from_documents(documents, embeddings, persist_directory="./financial_db") db.persist()
2. 模型层
- 基础模型:GPT-4/通义千问(通用能力)+ LoRA微调(金融术语适配)
- 部署方案:采用阿里云PAI-EAS或AWS SageMaker,支持弹性扩缩容
3. 应用层
- 功能:智能问答、投诉自动分类、工单生成
- 界面:集成至企业现有IM系统(如钉钉、企业微信)
4. 安全层
- 内容过滤:检测并拦截违规提问(如“如何洗钱”)
- 数据隔离:不同部门模型独立部署,防止信息泄露
- 审计日志:记录所有交互数据,满足合规要求
效果评估:
某银行客服场景落地后,问题解决率提升40%,人工转接率下降25%,年节省人力成本超300万元。
五、落地挑战与应对策略
- 数据质量:80%的模型性能问题源于数据。解决方案:构建数据清洗 pipeline,采用主动学习筛选高价值样本。
- 计算成本:7B模型单次微调成本约5000元,175B模型则需数十万元。建议:优先尝试PEFT方法,或采用模型蒸馏压缩模型。
- 伦理风险:生成内容可能包含偏见或错误信息。措施:引入人类反馈强化学习(RLHF),建立人工审核机制。
结语:大模型落地的本质是“技术适配业务”
从微调优化参数到提示词引导输出,从单模态文本到多模态交互,大模型落地的核心不是追求最先进的技术,而是找到业务痛点与模型能力的最佳结合点。未来,随着模型效率提升和成本降低,中小企业将迎来普惠AI时代。企业应现在就着手数据治理和人才培养,避免在AI浪潮中掉队。
思考问题:当大模型能自动生成代码和设计方案时,人类开发者的核心竞争力将转向何处?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献321条内容
已为社区贡献321条内容

所有评论(0)