LingBot-World 技术详解与部署指南
蚂蚁集团旗下灵波科技开源世界模型LingBot-World,引发AI领域广泛关注。该模型基于DiT架构,具备超长时序稳定生成、实时交互响应和Zero-shot泛化等核心能力,能模拟符合物理规律的动态场景。技术亮点包括:混合数据引擎融合真实视频与游戏合成数据;三层语义标注体系实现精细训练;三阶段进化训练策略逐步提升性能。与谷歌Genie 3相比,LingBot-World的开源策略推动了行业技术共享
关于UCloud(优刻得)旗下的compshare算力共享平台
UCloud(优刻得)是中国知名的中立云计算服务商,科创板上市,中国云计算第一股。
Compshare GPU算力平台隶属于UCloud,专注于提供高性价4090算力资源,配备独立IP,支持按时、按天、按月灵活计费,支持github、huggingface访问加速。
使用下方链接注册可获得20元算力金,免费体验10小时4090云算力,此外还有5090, 3090和P40,价格每小时只需要8毛,赠送的算礼金够用一整天。
https://www.compshare.cn/?ytag=GPU_lovelyyoshino_Lcsdn_csdn_display
1. 引言:开源世界模型的里程碑时刻
2026年1月29日,蚂蚁集团旗下具身智能公司灵波科技(Robbyant)正式开源了其世界模型 LingBot-World。这一消息发布后迅速登顶全球社交媒体热榜,引发了人工智能领域的广泛关注。与谷歌 DeepMind 的 Genie 3 不同,LingBot-World 选择了完全开源的路线,这一决策直接推动了 Genie 3 宣布即将开源,可以说是以开放姿态倒逼了整个行业的技术共享进程。
LingBot-World 并非孤立的技术发布,而是蚂蚁灵波"具身智能进化周"连续三天发布的三款开源模型之一。在此之前,团队已经开源了负责空间感知的 LingBot-Depth 和负责视觉-语言-动作决策的 LingBot-VLA。三者共同构成了一套完整的具身智能基础设施,覆盖了感知、决策、模拟三大核心环节。
本文将从技术原理、部署流程、代码实践等多个维度,对 LingBot-World 进行系统性的解读,帮助读者全面理解这一开源世界模型的核心价值与实际应用方法。项目主页:https://technology.robbyant.com/lingbot-world,GitHub:https://github.com/Robbyant/lingbot-world-Tech,论文地址:
https://github.com/Robbyant/lingbot-world/blob/main/LingBot_World_paper.pdf

目前相关内容已经在官网中可以直接安装使用了NVIDIA Alpamayo自动生成项目中了。
2. 世界模型:人工智能的认知基石
2.1 什么是世界模型
世界模型(World Model)是一种能够学习并理解物理世界运行规律的人工智能系统。与传统的视频生成模型不同,世界模型不仅追求视觉上的逼真效果,更重要的是要让生成的内容符合真实的物理规律和因果关系。
从认知科学的角度来看,人类大脑内部存在一套关于世界如何运作的"心智模型"。当我们看到一个玻璃杯放在桌边时,即使没有亲眼见过它掉落,我们也能预判如果它被碰到会发生什么。这种预判能力源于我们从无数次生活经验中提取出的物理规律认知。世界模型的目标,就是让人工智能系统也具备类似的能力——不仅能"看到"当前状态,还能"预测"未来变化,并"模拟"不同行为可能带来的后果。
2.2 世界模型与视频生成模型的本质区别
以 OpenAI 的 Sora 为例,它能够生成视觉效果极为逼真的视频,但本质上学到的是"什么样的画面看起来像真实视频",而非"物理世界实际如何运作"。因此在 Sora 生成的视频中,偶尔会出现人物肢体凭空消失、物体穿越墙壁、重力方向突变等违反物理规律的现象。
世界模型则要求更高:一个杯子从桌上掉落,必须沿着抛物线轨迹下落;落地时根据材质决定是碎裂还是弹起;碎片必须向四周飞溅——整个因果链条都要符合物理规律。这种对物理一致性的严格要求,使得世界模型在机器人训练、自动驾驶仿真、游戏开发等领域具有不可替代的价值。
2.3 世界模型的核心技术挑战
构建一个实用的世界模型需要解决三大核心难题:
一致性问题:生成的内容在时间和空间维度上必须保持连贯。当镜头转回之前经过的场景时,建筑、物体的位置和外观应当与之前一致,不能出现"记忆丢失"的情况。
交互性问题:世界模型必须能够响应用户的操作指令。当用户按下前进键时,画面应当相应地向前推进;当用户输入"下雪"的指令时,场景应当逐渐被白雪覆盖。
实时性问题:在交互场景中,用户无法容忍过长的响应延迟。如果按下按键后需要等待数秒才能看到画面变化,用户体验将大打折扣。
3. LingBot-World 核心能力解析
3.1 超长时序稳定生成
传统视频生成模型普遍存在"长时漂移"问题:生成时间越长,画面质量下降越明显,场景一致性也难以维持。LingBot-World 通过多阶段训练和空间记忆机制,实现了近10分钟的连续稳定生成。
以16帧每秒的帧率计算,10分钟意味着9600帧。在生成第9600帧时,模型仍然能够"记住"第1帧时场景的样貌,确保整体的时空一致性。即使镜头移开60秒后再转回来,场景中的物体仍然存在且结构保持一致。这种"空间记忆"能力是 LingBot-World 区别于普通视频生成模型的关键特征。
3.2 实时交互响应
LingBot-World 实现了约16帧每秒的生成吞吐量,端到端交互延迟控制在1秒以内。用户可以通过键盘的 WASD 键控制视角的前进、后退、左移、右移,通过鼠标控制视角的水平和垂直旋转。整个操作过程流畅自然,体验感接近于游玩一款预渲染的3A游戏。
这种实时交互能力的实现,依赖于团队在模型架构和推理优化方面的大量工作,包括因果注意力机制的引入、少步蒸馏技术的应用,以及 FSDP 分布式并行策略的优化。
3.3 Zero-shot 泛化能力
Zero-shot 泛化是指模型在没有见过某个特定场景的情况下,也能够对其进行合理的推理和生成。LingBot-World 展现出了强大的 Zero-shot 能力:用户可以输入任意一张图片作为初始帧,模型就能将其"变活",生成可交互的动态场景。
无论是真实照片、游戏截图还是艺术画作,LingBot-World 都能保持原有的视觉风格,同时实现场景的动态化。这大大降低了实际部署的门槛——不需要为每个应用场景准备大量的训练数据,直接拿一张图片就能开始使用。
3.4 文本驱动的世界事件
除了键盘鼠标控制,LingBot-World 还支持用自然语言触发"世界事件"。用户可以输入类似"让天气变成下雪"、“换成像素艺术风格”、"在天空放一些烟花"这样的指令,模型会相应地改变场景状态。
关键在于,这些变化过程中场景的几何关系保持一致。建筑还是那些建筑,只是上面覆盖了雪;道路还是那些道路,只是渲染风格变了。这说明模型理解了"内容"和"风格"的区别,能够在改变一个的同时保持另一个不变。
4. 技术架构深度解析
4.1 DiT 扩散 Transformer 架构
LingBot-World 的底层架构基于 DiT(Diffusion Transformer)模型构建,这是将扩散模型与 Transformer 架构相结合的技术路线。
扩散模型的核心原理:扩散模型的工作机制可以用一个直观的比喻来理解。想象一杯清水中滴入墨汁,墨汁会逐渐扩散直到整杯水变成均匀的颜色——这是"正向扩散"过程。扩散模型要学习的是"逆向扩散":如何从混乱的噪声中一步步恢复出清晰的图像。在训练阶段,模型学习如何从加噪的图像中预测噪声;在推理阶段,模型从纯噪声开始,逐步去噪生成目标图像。
Transformer 的优势:Transformer 架构的核心是自注意力机制(Self-Attention),它允许模型在处理序列中的每个元素时,同时"关注"到序列中所有其他元素。这种全局感知能力对于视频生成尤为重要,因为视频帧之间存在复杂的时序依赖关系。相比传统的 U-Net 架构,Transformer 在长程建模和可扩展性方面具有明显优势。
DiT 的技术融合:DiT 用 Transformer 替代了传统扩散模型中的 U-Net 骨干网络,在潜在空间中进行降噪操作。这种组合带来了更强的长程建模能力、更好的可扩展性,以及更灵活的条件注入方式。
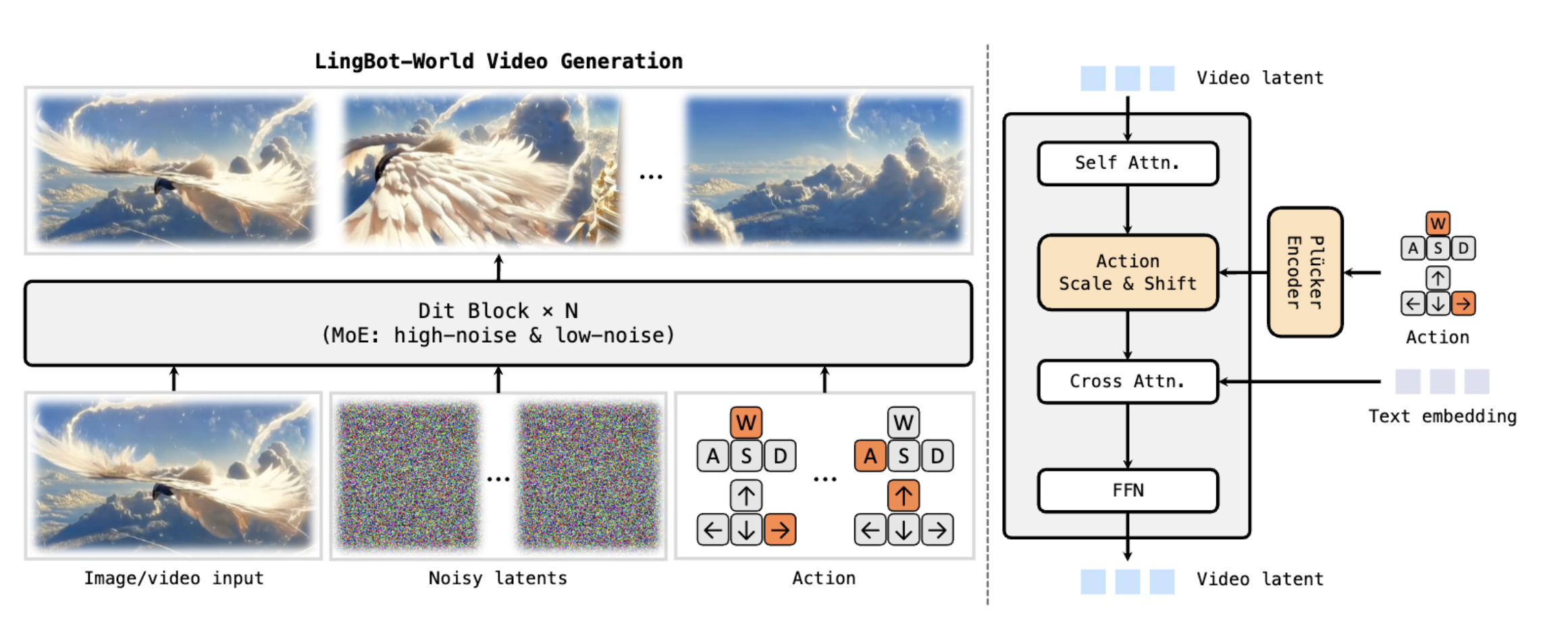
4.2 混合数据引擎
高质量的训练数据是模型性能的基础。LingBot-World 团队构建了一个精心设计的混合数据引擎,融合了真实世界视频和游戏引擎合成数据两大来源。
真实世界视频:团队从互联网收集了海量的真实视频,包括第一人称视角(如运动相机拍摄、行车记录仪)和第三人称视角(如电影、纪录片)。这些视频提供了丰富的视觉多样性和真实的物理运动模式。
游戏引擎合成数据:真实视频的局限在于难以获取精确的元数据,比如相机的确切位置和朝向、用户的操作指令等。为解决这一问题,团队使用虚幻引擎(Unreal Engine)生成了大量合成数据。游戏引擎可以精确记录每一帧的相机位姿、操作指令、物理碰撞信息和语义标签,这些"真值标签"对于让模型学会因果关系至关重要。
混合策略的价值:真实视频提供"长什么样"的知识,合成数据提供"怎么动"的知识。两者互补,形成完整的世界认知体系。
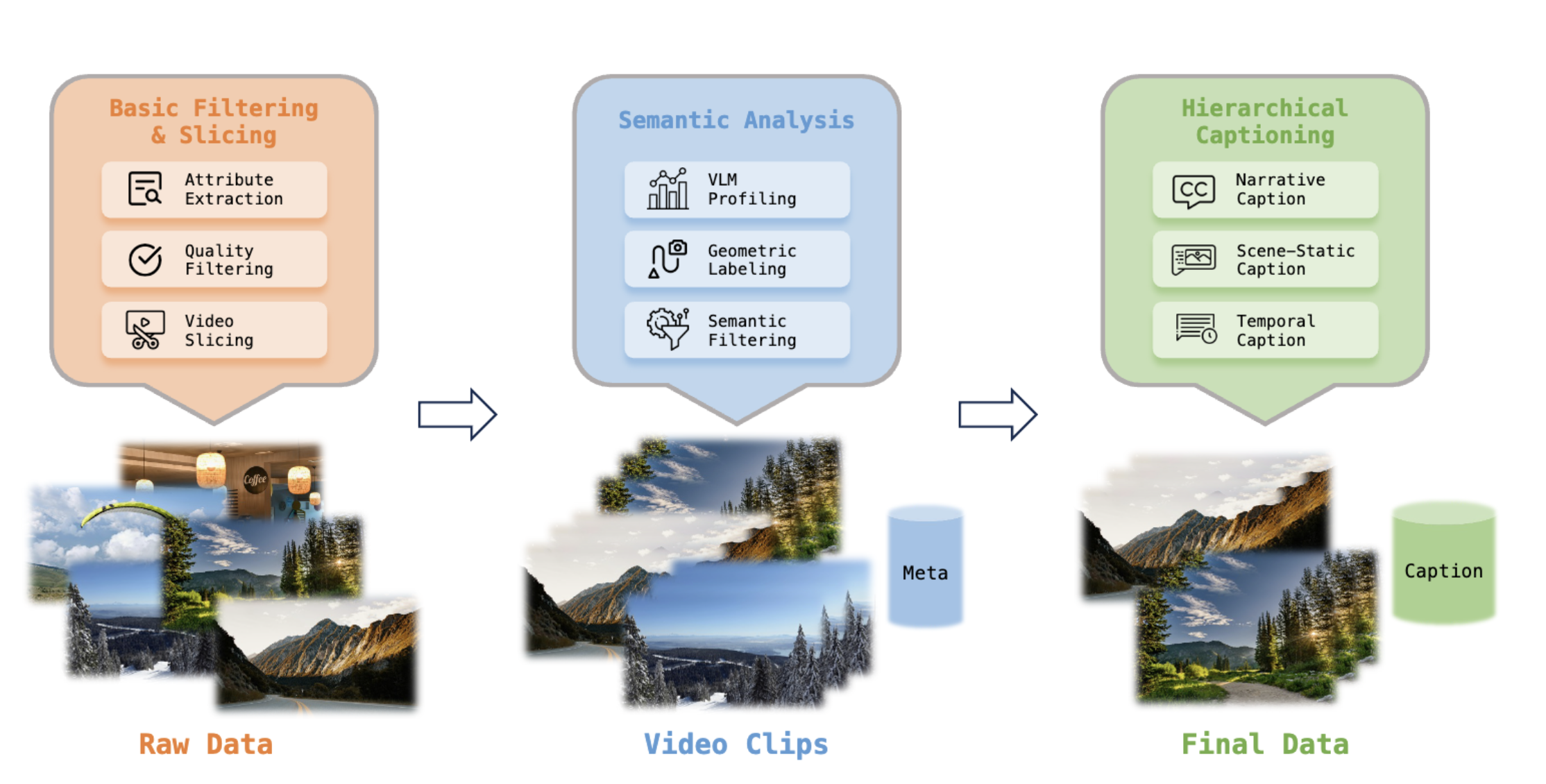
4.3 分层语义标注体系
传统视频数据集通常只有笼统的文字描述,这对于世界模型来说远远不够。LingBot-World 采用了独创的三层语义标注体系:
叙事描述(Narrative Caption):描述视频的整体情节和环境变化,讲述"发生了什么故事"。
静态场景描述(Scene-Static Caption):只描述环境本身,刻意忽略动作。这让模型学会将背景与运动解耦。
密集时序描述(Dense Temporal Caption):精确到秒的动作描述,比如"第5秒向左转,看到了一根柱子"。这种细粒度标注让模型能够精确理解操作与视觉变化之间的对应关系。
4.4 三阶段进化训练策略
LingBot-World 的训练分为三个阶段,每个阶段解决特定的问题:
第一阶段:预训练
目标是让模型获得强大的视觉生成能力。团队基于 Wan2.2 视频生成模型进行初始化,继续用大规模视频数据进行预训练。这一阶段不追求交互能力,只追求"画得好看":纹理细腻、光影自然、物体清晰、运动流畅。
第二阶段:中期训练
目标是让模型理解物理规律和交互逻辑。团队引入了混合专家(Mixture of Experts,MoE)架构,不同的"专家"模块负责不同方面的知识:有的负责全局结构布局,有的负责局部纹理细节,有的负责运动变化预测。
在这个阶段,大量交互数据被注入模型,让它学会因果关系。同时通过渐进式课程学习,模型从短视频逐步扩展到长视频,逐渐涌现出空间记忆能力。
第三阶段:后训练
目标是提升实时性和稳定性。团队通过 FSDP 分布式并行、DeepSpeed Ulysses 长序列优化、模型量化等工程手段提升推理速度,最终达到16帧每秒、1秒以内延迟的实时交互水平。
5. 环境准备与安装指南
5.1 硬件要求
LingBot-World 基于 14B 参数量的 DiT 架构构建,其推理过程涉及 T5-XXL 文本编码器、CLIP 图像编码器、DiT 视频生成主干网络以及 VAE 解码器等多个大型子模块的协同工作,因此对 GPU 显存和计算能力有较高要求。项目默认采用 torchrun 启动多 GPU 分布式推理,通过 FSDP(Fully Sharded Data Parallel)将模型参数分片到多张显卡上,从而突破单卡显存瓶颈。以下是基于项目 requirements.txt 中 torch>=2.4.0 要求和实际测试总结的硬件配置建议:
- GPU:1-2 张 NVIDIA RTX 4090 48GB
- 显存:24-48GB
- 系统内存:64GB 以上
- 存储空间:100GB 以上可用空间
在最低配置下,建议使用 --t5_cpu 参数将 T5 编码器卸载到 CPU 以节省约 8-10GB 显存,同时将 --frame_num 降低至 49(约3秒视频)以控制峰值显存占用。对于显存受限的用户,社区还提供了 4-bit NF4 量化版本模型(详见 6.3 节),可以在保持较好视觉质量的前提下将显存占用降低约 60%-70%。
5.2 软件环境
LingBot-World 的软件依赖链涉及 NVIDIA GPU 驱动、CUDA Toolkit、cuDNN、PyTorch、Flash Attention 等多个层级,各层之间存在严格的版本匹配要求。项目基于 Wan2.2 框架构建,核心推理流程依赖 NCCL 进行多 GPU 通信、依赖 Flash Attention 进行高效注意力计算,这些组件目前仅在 Linux 平台上经过充分测试。建议在部署前通过 nvidia-smi 确认驱动版本,通过 nvcc --version 确认 CUDA Toolkit 版本,确保各层版本相互兼容。Python 3.10 及以上,低于 4.0(项目 pyproject.toml 中明确声明 requires-python = ">=3.10,<4.0"),建议使用 conda 或 venv 创建独立的虚拟环境,避免与系统 Python 或其他项目的依赖产生冲突
5.3 安装步骤
第一步:创建 conda 环境
LingBot-World 的依赖链较为复杂,涉及 PyTorch、Flash Attention、diffusers 等多个对编译环境有特定要求的库。使用 conda 创建隔离环境可以避免系统级 Python 包的版本冲突,同时 conda 能够自动管理 CUDA toolkit 等底层依赖。根据项目 pyproject.toml 的声明,Python 版本必须 >= 3.10 且 < 4.0,推荐使用 3.10 以获得最佳兼容性。
# 创建名为 lingbot 的虚拟环境
conda create -n lingbot python=3.10
conda activate lingbot
第二步:克隆项目代码
项目代码托管在 GitHub 上,克隆后的目录结构包含:generate.py(推理入口脚本)、wan/(核心模型模块,包括 DiT 主干网络、VAE 编解码器、T5 文本编码器等)、examples/(示例输入数据,包含图像和相机位姿文件)、requirements.txt(依赖清单)以及 pyproject.toml(项目元数据配置)。整个代码库基于 Wan2.2 视频生成框架构建,读者可参考 Wan2.2 文档 了解底层架构细节。
git clone https://github.com/robbyant/lingbot-world.git
cd lingbot-world
第三步:安装 PyTorch
项目 requirements.txt 明确要求 torch>=2.4.0 和 torchvision>=0.19.0。PyTorch 2.4 引入了对 FSDP2 和 torch.compile 的重要改进,这些特性直接影响 LingBot-World 的分布式推理性能。由于 PyTorch 的 CUDA 版本需要与系统安装的 NVIDIA 驱动和 CUDA Toolkit 严格匹配,建议先通过 nvidia-smi 确认驱动支持的最高 CUDA 版本,再选择对应的安装命令。如果版本不匹配,运行时会出现 CUDA error: no kernel image is available 等难以排查的错误。
# CUDA 11.8 版本
pip install torch>=2.4.0 torchvision>=0.19.0 torchaudio --index-url https://download.pytorch.org/whl/cu118
# CUDA 12.1 版本(推荐)
pip install torch>=2.4.0 torchvision>=0.19.0 torchaudio --index-url https://download.pytorch.org/whl/cu121
第四步:安装项目依赖
项目根目录下的 requirements.txt 包含了运行 LingBot-World 所需的全部 Python 依赖。这些依赖覆盖了从模型加载(diffusers、transformers)、分布式计算(accelerate)、图像视频处理(opencv-python、imageio)到数值计算(numpy、scipy)的完整工具链。需要特别注意的是,transformers 的版本被限制在 >=4.49.0,<=4.51.3 范围内,这是因为更高版本可能引入不兼容的 API 变更,导致模型加载失败。安装前请确保 PyTorch 已正确安装(第三步),否则部分依赖的编译过程会因找不到 torch 而报错。
pip install -r requirements.txt
项目的核心依赖包括(完整列表参见 requirements.txt):
| 依赖包 | 版本要求 | 用途说明 |
|---|---|---|
| torch | >=2.4.0 | 深度学习框架 |
| torchvision | >=0.19.0 | 视觉处理工具 |
| diffusers | >=0.31.0 | 扩散模型库 |
| transformers | >=4.49.0, <=4.51.3 | Transformer 模型库 |
| accelerate | >=1.1.1 | 分布式训练加速 |
| flash_attn | - | Flash Attention 加速 |
| opencv-python | >=4.9.0.80 | 图像处理 |
| imageio[ffmpeg] | - | 视频读写 |
第五步:安装 Flash Attention
Flash Attention 是 LingBot-World 推理流程中不可或缺的加速组件。在 DiT 模型的自注意力计算中,标准实现的显存占用与序列长度的平方成正比,而 Flash Attention 通过分块计算和 IO 感知的内存访问模式,将显存复杂度降低到线性级别,同时实现了 2-4 倍的计算加速。项目 requirements.txt 中将 flash_attn 列为必需依赖,wan/modules/attention.py 中的注意力模块直接调用了 Flash Attention 的底层接口。由于 Flash Attention 需要从 CUDA 源码编译,必须单独安装且不能使用构建隔离模式:
pip install flash-attn --no-build-isolation
编译过程需要系统中已安装匹配的 CUDA Toolkit(不仅是运行时库,还需要 nvcc 编译器)。常见的编译失败原因包括:CUDA Toolkit 版本与 PyTorch 的 CUDA 版本不一致、系统缺少 ninja 构建工具、或 GCC 版本过高导致兼容性问题。如果编译持续失败,可以尝试从 flash-attn 的 GitHub Releases 页面下载与当前环境匹配的预编译 wheel 包直接安装。

6. 模型下载与配置
6.1 模型版本说明
LingBot-World 采用模块化的模型发布策略,根据不同的控制信号类型和推理速度需求划分为多个版本。从项目 README 的模型下载表可以看到,当前已发布的 Base-Cam 版本以相机位姿(Camera Poses)作为控制信号,用户通过提供 intrinsics.npy(相机内参)和 poses.npy(相机外参变换矩阵)来精确控制每一帧的镜头位置和朝向。这种控制方式特别适合电影级运镜效果的生成,例如环绕拍摄、推拉镜头、航拍俯冲等复杂相机运动。后续计划发布的 Act 版本将支持动作指令控制,面向游戏交互和机器人模拟场景;Fast 版本则专注于低延迟实时交互。
| 模型名称 | 控制信号类型 | 支持分辨率 | 下载渠道 | 适用场景 |
|---|---|---|---|---|
| LingBot-World-Base (Cam) | 相机位姿 | 480P / 720P | HuggingFace / ModelScope | 电影级运镜、虚拟旅游 |
| LingBot-World-Base (Act) | 动作指令 | 待发布 | 待发布 | 游戏交互、机器人模拟 |
| LingBot-World-Fast | - | 待发布 | 待发布 | 低延迟实时交互 |
目前已开放下载的是 Base-Cam 版本,模型权重托管在 HuggingFace(robbyant/lingbot-world-base-cam)和 ModelScope(Robbyant/lingbot-world-base-cam)两个平台上,国内用户建议优先使用 ModelScope 以获得更快的下载速度。
6.2 下载方式
方式一:使用 HuggingFace CLI(国际用户推荐)
HuggingFace 是全球最大的开源模型托管平台,LingBot-World 的官方权重文件托管在 robbyant/lingbot-world-base-cam 仓库下。项目 pyproject.toml 的 [project.optional-dependencies] 中已将 huggingface-hub[cli] 列为开发依赖,说明这是官方推荐的下载方式。--local-dir 参数指定本地存储路径,下载完成后该目录将包含模型权重、配置文件和 tokenizer 等全部推理所需文件,后续推理时通过 --ckpt_dir 参数指向此目录即可。
# 安装 huggingface_hub CLI 工具
pip install "huggingface_hub[cli]"
# 下载 Base-Cam 版本到本地目录
huggingface-cli download robbyant/lingbot-world-base-cam --local-dir ./lingbot-world-base-cam
方式二:使用 ModelScope CLI(国内用户推荐)
ModelScope(魔搭社区)是阿里云提供的国内模型托管平台,LingBot-World 同步发布在 Robbyant/lingbot-world-base-cam 仓库下。对于国内用户而言,ModelScope 的下载速度通常远优于 HuggingFace,且无需配置代理或镜像源。需要注意的是 ModelScope CLI 的本地路径参数使用下划线 --local_dir(而非 HuggingFace 的连字符 --local-dir),两者语法略有差异。
# 安装 modelscope CLI 工具
pip install modelscope
# 下载 Base-Cam 版本到本地目录
modelscope download robbyant/lingbot-world-base-cam --local_dir ./lingbot-world-base-cam
模型文件较大(约数十 GB),下载过程需要稳定的网络连接和足够的磁盘空间。建议使用 tmux 或 screen 等终端复用工具在后台运行下载命令,避免因 SSH 断连导致下载中断。如果下载中途失败,两个 CLI 工具均支持断点续传,重新执行相同命令即可从中断处继续。
6.3 量化版本(显存受限用户)
对于显存不足的用户,社区贡献者提供了基于 NF4(4-bit NormalFloat)量化技术的轻量版本。NF4 量化是 QLoRA 论文中提出的一种信息论最优的 4-bit 数据类型,相比传统的 INT4 量化能够更好地保留模型权重的分布特征。该量化版本将 DiT 主干网络的权重从 FP16/BF16 压缩到 4-bit 精度,显存占用降低约 60%-70%,使得在单张 RTX 4090(48GB)上运行成为可能。正如项目 README 中所注明的,该量化模型仅用于推理,视觉保真度和时序一致性相比全精度模型可能存在轻微下降。
# 下载社区提供的 NF4 量化版本
huggingface-cli download cahlen/lingbot-world-base-cam-nf4 --local_dir ./lingbot-world-base-cam-nf4
使用量化版本时,推理命令与全精度版本完全相同,只需将 --ckpt_dir 指向量化模型的目录即可。建议在正式使用前先用项目自带的 examples/ 示例数据进行测试,对比量化版本与全精度版本的输出质量差异,再决定是否满足实际需求。
7. 推理示例与代码详解
7.1 输入数据准备
在运行推理之前,需要准备输入数据。项目 examples/ 目录下提供了三组完整的示例数据(00/、01/、02/),每组包含 image.jpg(输入图像)、intrinsics.npy(相机内参)、poses.npy(相机位姿)和 prompt.txt(文本提示)四个文件。读者可以直接使用这些示例数据进行首次推理测试,验证环境安装是否正确,再替换为自己的数据。generate.py 的参数解析逻辑(_validate_args 函数)会在未指定 --prompt 或 --image 时自动使用内置的示例数据,因此即使不提供任何输入也能运行默认的演示场景。
必需输入:
- 输入图像:作为视频生成的第一帧,支持 PNG 或 JPG 格式。图像的宽高比将决定输出视频的宽高比,
generate.py会根据--size参数指定的目标面积自动调整实际输出分辨率 - 文本提示(Prompt):描述期望生成的场景内容、视觉风格和动态变化。Prompt 的质量直接影响生成效果,建议参考
generate.py中EXAMPLE_PROMPT字典提供的示例格式,采用详细的电影级场景描述
可选输入:
- 相机控制信号:用于精确控制每一帧的镜头位置和朝向,可通过 ViPE 工具从现有视频中提取
intrinsics.npy:相机内参矩阵,形状为[num_frames, 4],四个值分别对应焦距[fx, fy]和主点坐标[cx, cy]poses.npy:相机外参变换矩阵,形状为[num_frames, 4, 4],每个 4×4 矩阵表示 OpenCV 坐标系下从世界坐标到相机坐标的刚体变换
如果不提供相机控制信号(即省略 --action_path 参数),模型将根据文本提示自主决定镜头运动方式,生成效果仍然可用但缺少精确的运镜控制。
7.2 基础推理命令
LingBot-World 使用 PyTorch 的 torchrun 分布式启动器运行推理,入口脚本为项目根目录下的 generate.py。该脚本内部通过 wan.WanI2V 管道类协调 T5 文本编码、CLIP 图像编码、DiT 视频生成和 VAE 解码等多个阶段的计算流程。--nproc_per_node 指定每个节点使用的 GPU 数量,--ulysses_size 必须与之保持一致以启用 Ulysses 序列并行。--dit_fsdp 和 --t5_fsdp 分别对 DiT 主干网络和 T5 编码器启用 FSDP 参数分片,将模型权重均匀分布到所有 GPU 上。以下是两种常用分辨率的推理命令示例,均使用项目自带的 examples/00/ 示例数据:
480P 分辨率推理(8 GPU):
torchrun --nproc_per_node=4 generate.py --task i2v-A14B --size 480*832 --ckpt_dir lingbot-world-base-cam --image examples/00/image.jpg --action_path examples/00 --dit_fsdp --t5_fsdp --ulysses_size 8 --frame_num 161 --prompt "The video presents a soaring journey through a fantasy jungle. The wind whips past the rider's blue hands gripping the reins, causing the leather straps to vibrate. The ancient gothic castle approaches steadily, its stone details becoming clearer against the backdrop of floating islands and distant waterfalls."
720P 分辨率推理(8 GPU):
torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 720*1280 --ckpt_dir lingbot-world-base-cam --image examples/00/image.jpg --action_path examples/00 --dit_fsdp --t5_fsdp --ulysses_size 8 --frame_num 161 --prompt "The video presents a soaring journey through a fantasy jungle. The wind whips past the rider's blue hands gripping the reins, causing the leather straps to vibrate. The ancient gothic castle approaches steadily, its stone details becoming clearer against the backdrop of floating islands and distant waterfalls."
7.3 核心参数详解
以下是 generate.py 脚本的关键参数说明。这些参数均通过 argparse 定义在 _parse_args() 函数中,部分参数(如 sample_steps、sample_shift、sample_guide_scale)在未指定时会自动从 wan/configs/ 目录下的模型配置文件中读取默认值。_validate_args() 函数会在解析完成后进行合法性校验,包括检查 --size 是否在 SUPPORTED_SIZES 列表中、分布式环境下 ulysses_size 是否等于 world_size 等约束条件:
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
--task |
str | i2v-A14B | 任务类型,i2v 表示图生视频 |
--size |
str | 1280*720 | 输出分辨率,格式为"宽*高" |
--ckpt_dir |
str | 必填 | 模型检查点目录路径 |
--image |
str | 必填 | 输入图像路径 |
--action_path |
str | 可选 | 相机控制信号目录 |
--frame_num |
int | 161 | 生成帧数,需满足 4n+1 |
--prompt |
str | 示例 | 文本描述提示词 |
--dit_fsdp |
flag | False | 对 DiT 启用 FSDP 并行 |
--t5_fsdp |
flag | False | 对 T5 启用 FSDP 并行 |
--t5_cpu |
flag | False | 将 T5 放置于 CPU |
--ulysses_size |
int | 1 | Ulysses 序列并行分片数 |
--base_seed |
int | 42 | 随机种子 |
7.4 核心代码解析
以下代码片段均直接引用自项目 generate.py(源文件第 212-325 行),展示了从分布式环境初始化到视频生成再到结果保存的完整推理流程。读者可对照源文件逐行验证。
分布式环境初始化:
def generate(args):
rank = int(os.getenv("RANK", 0))
world_size = int(os.getenv("WORLD_SIZE", 1))
local_rank = int(os.getenv("LOCAL_RANK", 0))
device = local_rank
if world_size > 1:
torch.cuda.set_device(local_rank)
dist.init_process_group(
backend="nccl",
init_method="env://",
rank=rank,
world_size=world_size)
这段代码(源文件 generate.py:212-236)负责初始化分布式推理环境。torchrun 启动器会自动为每个进程设置 RANK(全局进程编号)、WORLD_SIZE(总进程数)、LOCAL_RANK(本机内进程编号)等环境变量。代码通过读取这些变量确定当前进程的角色和 GPU 设备分配。当 world_size > 1 时,使用 NCCL 后端初始化进程组,NCCL 是 NVIDIA 专为 GPU 间通信优化的集合通信库,支持高效的 AllReduce、AllGather 等操作。单 GPU 模式下则跳过分布式初始化,同时禁止使用 FSDP 和序列并行等分布式特性。
模型管道创建:
wan_i2v = wan.WanI2V(
config=cfg,
checkpoint_dir=args.ckpt_dir,
device_id=device,
rank=rank,
t5_fsdp=args.t5_fsdp,
dit_fsdp=args.dit_fsdp,
use_sp=(args.ulysses_size > 1),
t5_cpu=args.t5_cpu,
convert_model_dtype=args.convert_model_dtype,
)
WanI2V 是图生视频的核心管道类(定义在 wan/image2video.py 中),负责协调 T5-XXL 文本编码器、CLIP 图像编码器、DiT 视频生成主干网络和 VAE 解码器的完整推理流程。构造函数中的 config 参数来自 wan/configs/wan_i2v_A14B.py,包含了模型架构的所有超参数(如注意力头数 num_heads、采样步数 sample_steps、引导尺度 sample_guide_scale 等)。t5_fsdp 和 dit_fsdp 控制是否对对应模块启用 FSDP 参数分片,t5_cpu 则将 T5 编码器完全放置于 CPU 内存以节省 GPU 显存。use_sp 参数启用 Ulysses 序列并行,将长视频序列的注意力计算分片到多个 GPU 上。
视频生成调用:
video = wan_i2v.generate(
args.prompt,
img,
action_path=args.action_path,
max_area=MAX_AREA_CONFIGS[args.size],
frame_num=args.frame_num,
shift=args.sample_shift,
sample_solver=args.sample_solver,
sampling_steps=args.sample_steps,
guide_scale=args.sample_guide_scale,
seed=args.base_seed,
offload_model=args.offload_model)
generate 方法(定义在 wan/image2video.py 中)是实际执行视频生成的核心入口。它接收文本提示 prompt、输入图像 img、相机控制信号路径 action_path 等参数,内部依次完成文本编码、图像编码、噪声初始化、迭代去噪和 VAE 解码等步骤,最终返回形状为 [T, C, H, W] 的视频张量。其中 max_area 由 SIZE_CONFIGS 映射得到,控制输出视频的像素总面积;sample_solver 支持 unipc 和 dpm++ 两种采样器,前者是项目默认选择;guide_scale 控制 Classifier-Free Guidance 的强度,值越大生成结果越贴近文本描述但多样性降低;offload_model 在单 GPU 模式下默认开启,每个子模块前向传播完成后自动卸载到 CPU 以释放显存。
8. 高级用法与优化技巧
8.1 生成更长的视频
LingBot-World 的一大核心优势是支持超长时序视频生成。默认的 frame_num=161 会生成约10秒的视频(16fps)。正如项目 README 中所述:“If you have sufficient CUDA memory, you may increase the frame_num parameter to a value such as 961 to generate a one-minute video at 16 FPS。” 模型通过空间记忆机制在长时序生成中保持场景一致性,即使生成数百帧后镜头转回之前的场景,建筑和物体的位置仍能保持不变。增加帧数会线性增加显存占用和推理耗时,建议在 8×A100 80GB 配置下尝试 961 帧的长视频生成:
# 生成约1分钟视频(961帧 / 16fps ≈ 60秒)
torchrun --nproc_per_node=8 generate.py \
--task i2v-A14B \
--size 480*832 \
--ckpt_dir lingbot-world-base-cam \
--image examples/00/image.jpg \
--dit_fsdp \
--t5_fsdp \
--ulysses_size 8 \
--frame_num 961 \
--prompt "Your scene description here..."
注意:帧数需要满足 4n+1 的格式(如 49、161、321、481、641、801、961 等)。
8.2 显存优化策略
策略一:T5 模型 CPU 卸载
T5-XXL 文本编码器拥有约 110 亿参数,以 FP16 精度加载时占用约 8-10GB 显存。在 generate.py 的推理流程中,T5 仅在最初的文本编码阶段使用一次,之后的整个去噪迭代过程都不再需要它。因此将 T5 放置于 CPU 内存是一种高效的显存优化策略——通过 --t5_cpu 参数启用后,T5 的权重始终驻留在系统内存中,文本编码通过 CPU 完成,虽然这一步的速度会变慢,但释放出的 8-10GB GPU 显存可以用于支持更高分辨率或更多帧数的视频生成:
torchrun --nproc_per_node=8 generate.py \
--task i2v-A14B \
--size 480*832 \
--ckpt_dir lingbot-world-base-cam \
--image examples/00/image.jpg \
--t5_cpu \
--frame_num 161 \
--prompt "Your prompt..."
使用 --t5_cpu 后,文本编码阶段的耗时会增加(CPU 推理速度远低于 GPU),但由于文本编码在整个推理流程中只执行一次,对总体推理时间的影响有限。这一策略特别适合显存紧张但系统内存充裕的场景,是官方 README 中明确推荐的显存优化手段。
策略二:减少 GPU 并行数量
并非所有用户都拥有 8 张 GPU。generate.py 的分布式逻辑(源文件第 212-240 行)支持灵活调整 GPU 数量。关键约束是 --ulysses_size 必须等于 --nproc_per_node(即 GPU 数量),且模型配置中的注意力头数 num_heads 必须能被 ulysses_size 整除。以 4 张 GPU 为例:
# 使用 4 张 GPU
torchrun --nproc_per_node=4 generate.py \
--task i2v-A14B \
--size 480*832 \
--ckpt_dir lingbot-world-base-cam \
--image examples/00/image.jpg \
--dit_fsdp \
--t5_fsdp \
--ulysses_size 4 \
--frame_num 161 \
--prompt "Your prompt..."
注意:ulysses_size 必须与 GPU 数量保持一致,这是 generate.py 中 _validate_args 函数的硬性校验条件(源文件第 239 行:assert args.ulysses_size == world_size)。此外,减少 GPU 数量意味着每张卡需要承载更多的模型参数分片,峰值显存占用会相应增加,可能需要配合 --t5_cpu 或降低 --frame_num 来避免 OOM。
策略三:单 GPU 推理
当仅有一张 GPU 时,需要使用 python 而非 torchrun 启动脚本,同时移除所有分布式相关参数(--dit_fsdp、--t5_fsdp、--ulysses_size)。generate.py 的验证逻辑(源文件第 231-236 行)会在非分布式环境下主动拒绝这些参数。单 GPU 模式下 offload_model 会自动设为 True,即每个子模块前向传播完成后自动卸载到 CPU,以串行方式复用有限的显存空间。强烈建议同时启用 --t5_cpu 并将帧数降低到 49(约3秒视频),以确保在 48GB 显存的 RTX 4090 上不会触发 OOM:
python generate.py \
--task i2v-A14B \
--size 480*832 \
--ckpt_dir lingbot-world-base-cam \
--image examples/00/image.jpg \
--t5_cpu \
--frame_num 49 \
--prompt "Your prompt..."
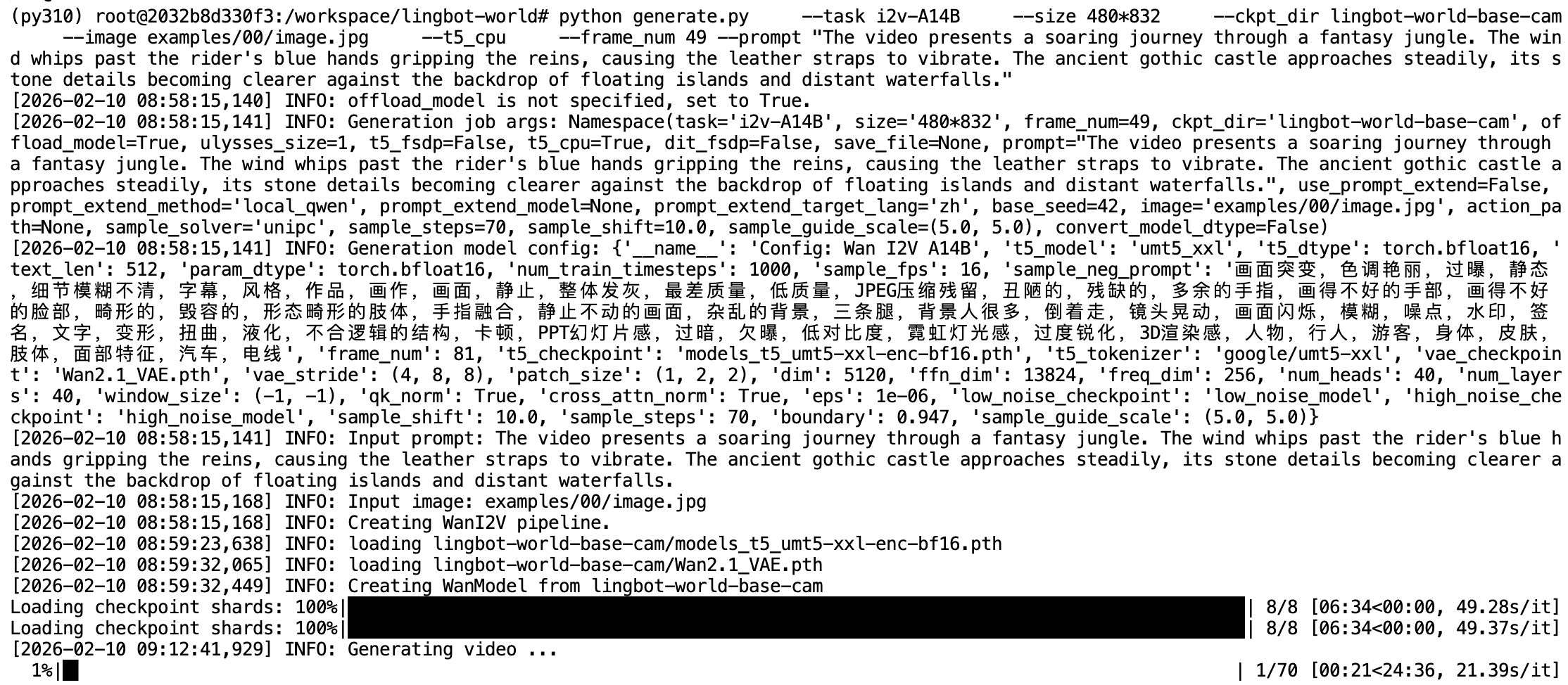
单 GPU 模式下,由于所有模型参数无法通过 FSDP 分片到多张卡上,峰值显存压力完全由一张卡承担。generate.py 中的 offload_model 机制(源文件第 219-220 行)会在单卡时自动启用,每个子模块前向传播完成后将权重卸载到 CPU,以串行复用显存。即便如此,仍建议将 --size 设为 480*832(480P)、--frame_num 设为 49(约3秒视频),并配合 --t5_cpu 使用,以确保在 48GB 显存的消费级显卡上稳定运行。如果使用社区提供的 NF4 量化版本(详见 6.3 节),单卡可尝试更高的帧数。
8.3 Prompt 编写技巧
文本提示(Prompt)的质量直接影响生成效果。LingBot-World 使用 T5-XXL 作为文本编码器,能够理解复杂的长文本描述。从 generate.py 中内置的 EXAMPLE_PROMPT 字典可以看到,官方示例 Prompt 通常长达 200-400 个英文单词,涵盖场景构成、光照条件、镜头运动、材质细节和氛围情绪等多个维度。项目还支持通过 --use_prompt_extend 参数启用 Prompt 扩展功能(基于本地 Qwen 模型或 DashScope API),自动将简短的用户输入扩展为详细的场景描述。以下是编写有效 Prompt 的建议:
结构化描述:按照"视觉风格 + 场景要素 + 动态细节 + 氛围情绪"的结构组织描述。
具体而非抽象:避免使用"漂亮"、“好看"等抽象词汇,改用具体的视觉描述,如"阳光洒在湖面上泛起金色的波光”。
示例对比:
| 质量 | Prompt 示例 |
|---|---|
| 较差 | “一个城市” |
| 一般 | “赛博朋克风格的城市夜景” |
| 较好 | “赛博朋克风格的未来都市夜景,霓虹灯闪烁的高楼大厦,雨后湿润的街道反射着五颜六色的灯光,空中有飞行汽车掠过留下流光尾迹” |
官方示例 Prompt:
The video presents a cinematic, first-person wandering experience through
a hyper-realistic urban environment rendered in a video game engine. It
begins with a static, sun-drenched alley framed by graffiti-laden industrial
walls and overhead power lines, immediately establishing a gritty, lived-in
atmosphere. As the camera pans right and tilts upward, it reveals a sprawling
cityscape dominated by towering skyscrapers and industrial infrastructure,
all bathed in warm, late-afternoon light that casts long shadows and produces
dramatic lens flares.
这个示例展示了高质量 Prompt 的特点:详细的视觉描述、明确的镜头运动、丰富的环境细节。
9. 总结
本文系统介绍了蚂蚁灵波开源的世界模型 LingBot-World,LingBot-World 基于 DiT 扩散 Transformer 架构,通过混合数据引擎(真实视频 + 游戏引擎合成)、分层语义标注、三阶段进化训练等技术手段,实现了高保真、长时序、可交互的世界模拟能力。
10. 参考链接
https://www.fuyuan7.com/post-1410.html
https://www.modelscope.cn/models/Robbyant/lingbot-world-base-cam/summary

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献161条内容
已为社区贡献161条内容

所有评论(0)