【考研复试·项目实战】基于BART的特定领域文本生成系统:从预训练到推理全流程解析
一、 项目背景与技术选型
1.1 为什么选择 BART?
在文本生成(Seq2Seq)任务中,模型架构决定了效果上限。本项目放弃了 BERT 和 GPT,选择了 BART,原因在于其架构的独特性:
|
模型 |
架构类型 |
优势 |
劣势 |
适用场景 |
|---|---|---|---|---|
|
BERT |
Encoder-only |
理解能力强(双向注意力) |
无法生成文本 |
文本分类、实体识别 |
|
GPT |
Decoder-only |
生成能力强(自回归) |
只能看上文,理解不够深 |
创意写作、对话 |
|
BART |
Encoder-Decoder |
理解+生成 双剑合璧 |
计算量稍大 |
机器翻译、摘要、文本纠错 |
通俗理解:BERT 像个只会做阅读理解的哑巴,GPT 像个只会瞎编故事的话痨,而 BART 既能读懂文章(Encoder),又能把理解的内容写出来(Decoder),是两者的集大成者。
1.2 核心策略:两阶段训练法
为了解决 Domain Shift(领域漂移) 问题(即通用模型看不懂专业术语),我们设计了两步走策略:
-
预训练 (Pre-train):做“完形填空” (MLM)。让模型在无标注的领域数据上跑一遍,通过填补被挖空的词,熟悉专业术语和上下文关系。
-
微调 (Fine-tune):做“模拟考试” (Seq2Seq)。给模型具体的输入和标准答案,教它生成目标文本。
二、 数据工程 (Data Pipeline)
数据处理是项目的基石。我们需要将原始 CSV 转换为模型可读的 Tensor(张量)。
2.1 原始数据清洗 (process_data.py)

图解:这是我们面临的原始数据(以医疗报告为例)。数据通常是非结构化的长文本,包含大量专业术语(如“类圆形低密度影”、“脂肪间隙模糊”)。我们的目标是让模型能够理解并生成这类文本。
这一步进行数据集划分,保证实验的可复现性。
import pandas as pd
# 读取原始数据
train_df = pd.read_csv("data/train.csv", header=None, names=["id", "input", "tgt"])
# 1. 随机采样划分训练集 (90%)
# random_state=0 锁死随机种子,保证每次划分结果一致(复现性关键!)
# 否则每次跑实验数据都不一样,实验结论就没法对比了
train_data = train_df.sample(frac=0.9, random_state=0, axis=0)
# 2. 剩下的作为验证集 (10%)
# isin取反逻辑:凡是不在训练集里的,都归为验证集
val_data = train_df[~train_df.index.isin(train_data.index)]
train_data.to_csv("data/pro_train_data.csv", index=False, header=False)
val_data.to_csv("data/pro_val_data.csv", index=False, header=False)
2.2 数据集构建与 Tokenization (model_utils/data.py)
这是最核心的数据处理类。重点在于特殊 Token 的添加和长度对齐。

图解:在处理特定领域数据时,经常遇到OOV (Out of Vocabulary) 问题,即有些数字或术语在通用词表中不存在。我们在 Tokenization 阶段需要特别注意这些情况,通过拆分 Token 或扩展词表来解决。
针对 OOV 的加字处理方法: 如果发现领域特有的词(例如特定的医疗代码或数字组合)大量出现且被分词器拆得支离破碎(UNK),我们可以“加字”策略:
-
扫描语料:统计训练集中出现频率高但在预训练词表(
vocab.txt)中不存在的词。 -
修改词表:将这些新词手动追加到
vocab.txt文件的末尾,或者使用tokenizer.add_tokens(['新词1', '新词2'])动态添加。 -
调整 Embedding 层:因为词表变大了(例如从 21128 增加到 21130),模型的 Embedding 矩阵(
model.resize_token_embeddings(new_len))也必须随之扩容,新加入的词向量会随机初始化,在后续的训练中学习语义。
核心原理:GPU 进行矩阵运算时,要求一个 Batch 内的所有句子长度必须一致。就像盖房子用的砖头必须一样大。因此我们需要对短句子进行 Padding(补 0),对长句子进行 Truncation(截断)。
class TranslationDataset(Dataset):
def __init__(self, data_file, args):
# 加载分词器 (Tokenizer),它是把文本变数字的翻译官
self.tk = AutoTokenizer.from_pretrained(args.pre_model_path)
# 定义特殊符号 ID:
# [SOS] Start of Sentence (开始)
# [EOS] End of Sentence (结束)
# [PAD] Padding (占位补丁)
self.sos_id = args.sos_id
self.eos_id = args.eos_id
self.pad_id = args.pad_id
def __getitem__(self, idx):
# === 步骤 1: 文本转 ID (Tokenization) ===
# 逻辑:[SOS] + 文本分词转ID + [EOS]
source = (
[self.sos_id]
+ self.tk.convert_tokens_to_ids([x for x in self.samples[idx][1].split()])
+ [self.eos_id]
)
# === 步骤 2: Padding (补齐) ===
# 如果句子短于 input_l,用 0 (pad_id) 在后面补齐
if len(source) < self.input_l:
source.extend([self.pad_id] * (self.input_l - len(source)))
# === 步骤 3: Truncation (截断) ===
# 如果句子太长,直接切片保留前 input_l 个
# 同样的操作也应用于 target (答案)
return np.array(source)[: self.input_l], np.array(target)[: self.output_l]
三、 模型架构设计 (model_utils/models.py)
我们复用了 HuggingFace 的 BartForConditionalGeneration,但重写了 forward 逻辑以支持不同的运行模式。
3.1 掩码生成机制 (build_bart_inputs)
模型在计算注意力(Attention)时,不应该关注 Padding 填充的 0(无意义占位符)。所以我们需要生成一个 Mask(掩码)来告诉模型:“忽略这些 0”。
def build_bart_inputs(self, input, tgt=None):
# input != self.pad_id 生成布尔矩阵
# 有字的地方是 True(1),补 0 的地方是 False(0)
# 模型看到 False 就会绕道走
input_mask = input != self.pad_id
if tgt is None:
return input_mask, None
else:
tgt_mask = tgt != self.tgt_pad_id
return input_mask, tgt_mask
3.2 核心前向传播 (forward)
这是复试重点:如何在一个函数里同时支持“训练”和“推理”?
def forward(self, inputs, tgts=None):
# 1. 生成防干扰掩码
input_mask, tgt_mask = self.build_bart_inputs(inputs, tgts)
# === 模式 A:推理 (Inference) ===
# 场景:没有标准答案 (tgts is None),模型需要自己写文章。
if tgts == None:
return self.model.generate(
inputs,
max_length=self.max_l,
attention_mask=input_mask,
num_beams=self.beam, # 关键技术:Beam Search (束搜索)
no_repeat_ngram_size=self.no_repeat, # 防止复读机现象
decoder_start_token_id=102 # 强制从这个 Token 开始写
)
# === 模式 B:训练 (Training) ===
# 场景:有标准答案,进行并行计算。
outputs = self.model(
input_ids=inputs,
attention_mask=input_mask,
decoder_input_ids=tgts, # Teacher Forcing:把正确答案直接喂给 Decoder
decoder_attention_mask=tgt_mask,
)
# 返回 Logits (未归一化的概率分布),用于后面计算 Loss
return outputs.logits
四、 阶段一:领域预训练 (pretrain.py)
目的:解决 Domain Shift(领域漂移)。让模型适应你的数据领域。
方法:MLM (Masked Language Modeling) —— 完形填空。
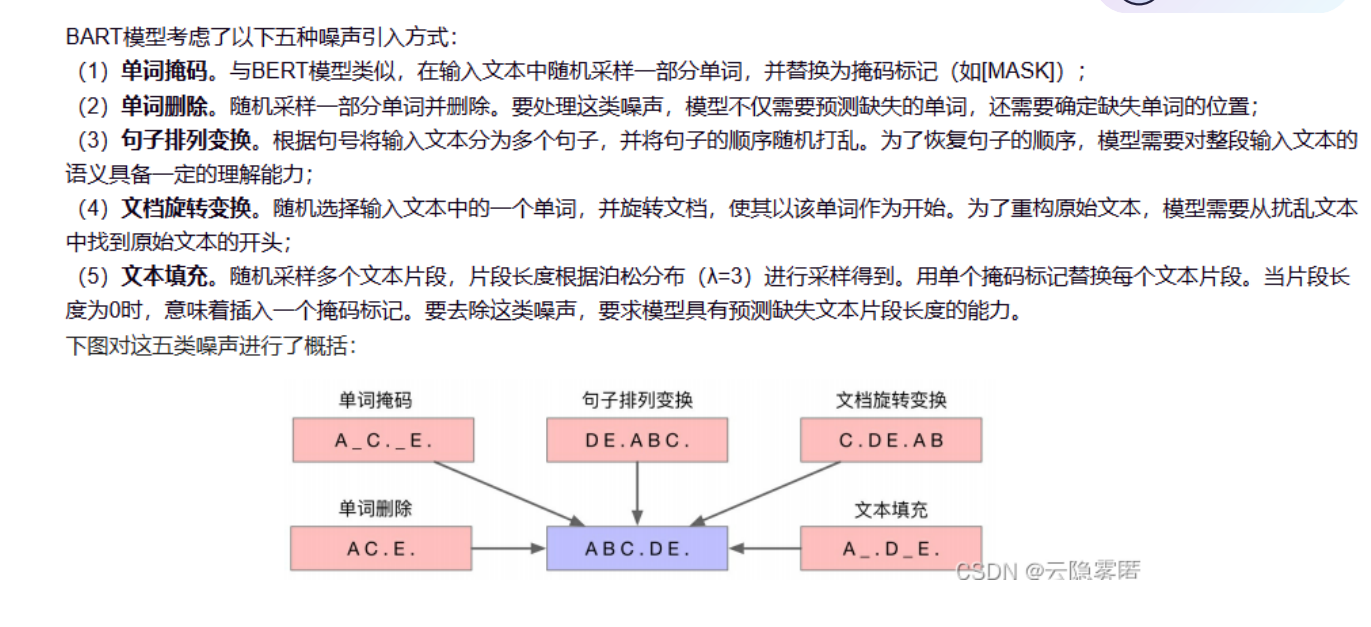
图解:为了让模型更懂语言,BART 采用了多种“破坏数据”的方式来训练:
-
单词掩码 (Masking):挖掉几个词让模型填。
-
句子排列 (Permutation):打乱句子顺序让模型排。
-
文档旋转 (Rotation):改变文章开头。 我们的
pretrain.py主要利用了 单词掩码 策略。
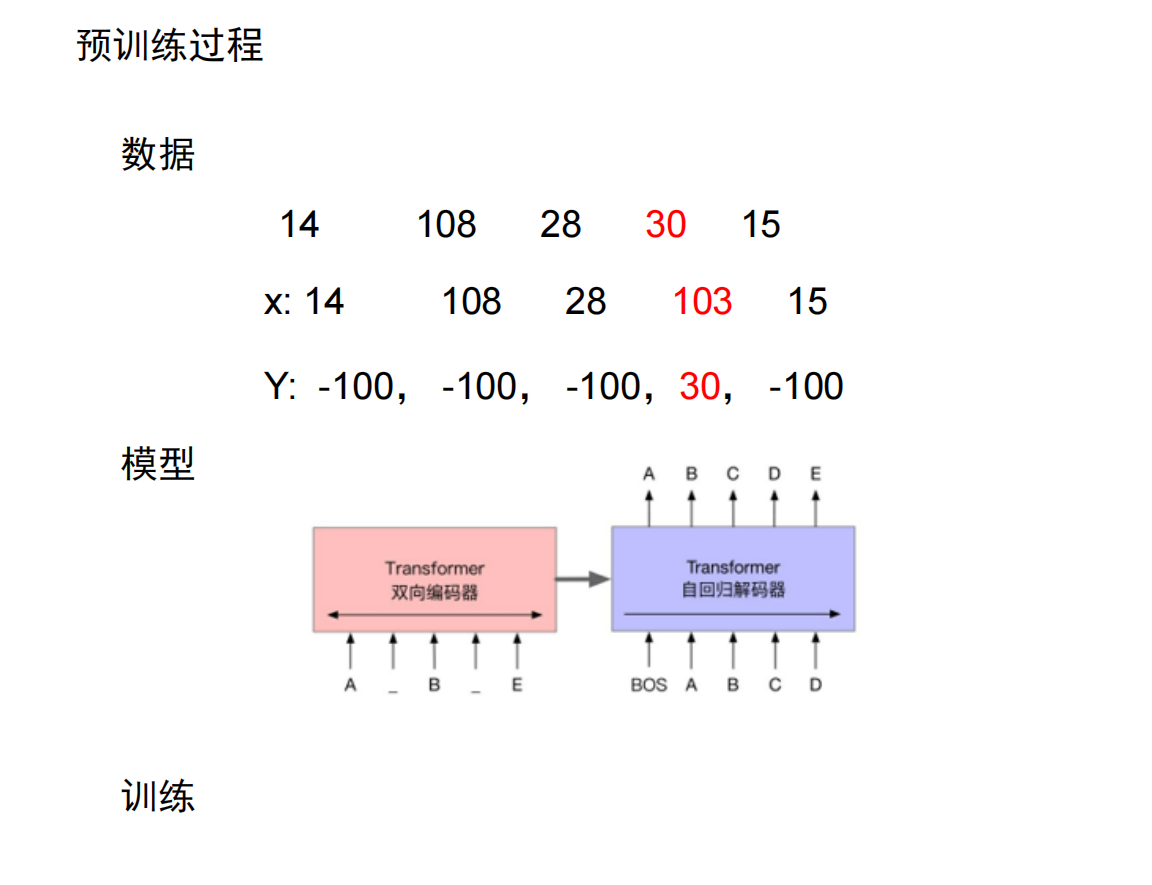
图解:预训练阶段是“自监督”的。输入是损坏的文本(Masked Text),输出是原始文本。模型通过 Encoder 理解上下文,通过 Decoder 还原被 Mask 的内容。
在此阶段,我们使用 AutoModelForMaskedLM。数据加载器会动态地 (Dynamic Masking) 将输入句子中 15% 的词替换为 [MASK],强迫模型根据上下文复原这些词。
# pretrain.py 核心片段
for epoch in range(args.max_epochs):
for batch in train_dataloader:
model.train() # 必须开启!这会启用 Dropout,增加训练难度
# batch 在传入前已经被 collet_fn 随机挖掉了 15% 的词
# model 内部会自动计算预测词和原词之间的 Loss
loss = model(batch)
loss.backward() # 反向传播:找错误原因
optimizer.step() # 优化器:修改参数
# 定期保存 Checkpoint,文件名记录 loss 以便筛选最佳模型
if epoch % 5 == 0:
torch.save(..., f"epoch{epoch}loss{loss:.3f}pre_model.bin")
五、 阶段二:下游微调 (finetine.py)
目的:Seq2Seq 生成任务。教模型“看题写答案”
难点:Loss 计算时的错位对齐。

图解:微调阶段是有监督的。我们输入完整的 Source Text,模型通过 Encoder 编码后,Decoder 结合 Teacher Forcing(输入标准答案的前半部分)来预测下一个词。
意思是:微调就是一场开卷考试。
-
Source Text 是阅读理解题干。
-
Teacher Forcing 是老师在旁边,你每写一个字,老师就悄悄告诉你下一个正确答案的前一个字,让你去猜下一个字。通过这种高强度的“喂饭”式训练,模型能最快地学会标准答案的生成逻辑。
5.1 加载预训练权重
if use_pre:
# 加载阶段一练好的权重,这一步是知识迁移的关键
# 就像把一个已经在医学院读过预科(预训练)的学生领进门
checkpoint = torch.load(args.my_pre_model_path)
model.load_state_dict(checkpoint["model_state_dict"], strict=True)
5.2 训练循环与错位对齐
这是面试官最喜欢问的代码细节:
for source, targets in tqdm(train_dataloader):
# 1. 前向传播:同时传入输入和答案
# pred 的形状是 (batch_size, seq_len, vocab_size)
pred = model(source[:, : args.input_l], targets[:, : args.output_l])
# 2. 计算 CrossEntropy Loss (交叉熵损失)
# === 关键考点:错位对齐 ===
# 为什么要切片?
# pred[:, :-1] : 舍弃最后一个预测(因为后面没答案了,不用对)
# targets[:, 1:] : 舍弃第一个词(因为那是[SOS],不需要预测)
# 效果:用 t 时刻的输出,去对齐 t+1 时刻的输入
loss = CE(pred[:, :-1], targets[:, 1:])
loss.backward()
optimizer.step()
5.3 评估指标
Loss 只能反映概率差距,不能反映句子通顺度。我们使用 CIDEr 分数来评估生成质量,并基于此择优保存模型(Best Model Saving)。
# finetine.py 第 39-41 行
CiderD_scorer = CiderD(df="corpus", sigma=15)
cider_score, cider_scores = CiderD_scorer.compute_score(gts, res)
return cider_score为什么选择 CIDEr?
CIDEr(Consensus-based Image Description Evaluation)指标最初用于图像描述,但非常适合文本生成评估,特别是当我们需要关注**关键词(Key Concepts)**时。
-
基于 TF-IDF:CIDEr 利用 TF-IDF 权重对 n-gram 进行加权。
-
TF(词频):如果一个词在生成句中出现频率高,权重增加。
-
IDF(逆文档频率):如果一个词在整个语料库中很罕见(例如专业术语、特定名词),权重会显著增加;反之,像“的”、“是”这种常用词权重会降低。
-
-
抓重点能力强:相比于 BLEU 或 ROUGE 容易被常用虚词“刷分”,CIDEr 更看重生成结果是否包含了那些信息量大、区分度高的词汇。对于医疗报告或专业领域文本生成,准确生成专业术语(低频词)是核心要求,因此 CIDEr 是比 Loss 更贴合实际应用效果的“指挥棒”。
六、 推理与后处理 (inference.py)
这是模型“毕业”后的实战。在未知的测试集上跑结果。
6.1 核心流程
def inference(args):
# 1. 必须开启 Eval 模式!
# 作用:关闭 Dropout,固定 BN 层统计量
# 如果不写这行,模型每次输出的结果都会不一样,且效果很差
model.eval()
for source in tqdm(test_loader):
# 触发 Beam Search 生成
pred = model(source)
pred = pred.cpu().numpy()
for i in range(pred.shape[0]):
# 2. 数据清洗:pred[i][2:]
# 索引0: [BOS]
# 索引1: decoder_start_token_id (102)
# 这两个是“启动暗号”,必须切掉,才是真正的文本内容
# 就像买新手机要撕掉保护膜一样
result_text = array2str(pred[i][2:], args)
writer.writerow([tot, result_text])
七、 考研复试·地狱级问答 (Q&A)
这一部分是面试的决胜局。我将面试中可能遇到的“深水区”问题整理如下,包含破题思路和满分话术。
第一关:模型理论篇 (Model Architecture)
Q1: 现在的 GPT-4 这么强,BERT 也很经典,为什么你的项目非要选 BART?
满分回答: “老师,选择 BART 是基于我的任务特性(Seq2Seq 生成决定的,它结合了 BERT 和 GPT 的优点:
-
排除 BERT:BERT 是 Encoder-only(仅编码器) 结构,擅长‘理解’(如分类、情感分析),但缺乏解码器,无法直接生成文本。
-
排除 GPT:GPT 是 Decoder-only(仅解码器) 结构,擅长‘自由生成’(如写小说),但它是单向注意力,无法像 Encoder 那样双向、全局地理解输入文本的深层语义。
-
选择 BART:BART 是 Encoder-Decoder 结构。Encoder 负责双向理解输入,Decoder 负责自回归生成。对于‘输入一段话,生成另一段话’这种任务,BART 的架构是最匹配的。”
Q2: 训练时的 Loss 计算 pred[:, :-1] 到底是什么意思?
破题思路:这考的是 Teacher Forcing 的核心逻辑——错位对齐。如果能举出例子,说明你真懂。
满分回答: “这是序列生成任务中标准的错位对齐计算。 假设我们要教模型学会句子 [A, B, C]。
-
输入给 Decoder 的是:
[SOS, A, B](在 t 时刻)。 -
期望模型预测的是:
[A, B, C](在 t+1 时刻)。
在代码中:
-
pred[:, :-1]:舍弃了模型预测的最后一个词(因为后面没答案了)。 -
targets[:, 1:]:舍弃了标准答案的第一个词(因为那是输入的[SOS])。
这样就实现了用‘当前的输入’去预测‘下一个词’,从而计算交叉熵损失。”
第二关:训练策略篇 (Training Strategy)
Q3: 既然 BART 已经是预训练好的,你为什么还要自己写个 pretrain.py?这不是多此一举吗?
破题思路:这道题考的是 Domain Adaptation(领域自适应)。通用模型不懂专业黑话,你需要解释这一步的必要性
满分回答: “这绝对不是多此一举,而是为了解决领域漂移(Domain Shift)的问题。 原始 BART 是在维基百科等通用语料上训练的,它可能不理解我项目数据中的专业术语(如特定竞赛的黑话、医学术语等)。 我在 pretrain.py 中使用 MLM(掩码语言模型) 任务,随机遮盖 15% 的词让模型填空。这一步就像是让一个文科生在做专业翻译前,先背一遍专业词典。实验证明,这一步显著提升了模型在下游任务上的收敛速度和效果。”
Q4: 训练时你用了 Teacher Forcing(给标准答案),但推理时没有答案,这会产生什么问题?
破题思路:这是一个高阶问题,术语叫 Exposure Bias(曝光偏差)。
满分回答: “这会导致曝光偏差(Exposure Bias)。
-
训练时:模型有‘老师’带着,不管上一轮预测对错,下一轮都能看到正确的词,所以路走得很顺。
-
推理时:模型只能靠自己。如果上一轮生成错了,这个错误会累积到下一轮,导致越跑越偏。
我的解决方案:虽然我的代码主要用了 Teacher Forcing,但我通过在推理阶段使用 Beam Search (num_beams=5),同时保留 5 条可能的路径,在一定程度上缓解了单步预测错误带来的崩溃,保证了生成的鲁棒性。”
第三关:工程与优化篇 (Engineering)
Q5: 为什么在 inference.py 最后,你要对结果切片 pred[i][2:]?
破题思路:这考的是你对 Tokenizer 特殊符号的敏感度,体现工程经验。
满分回答: “这是因为 BART 模型的生成序列包含控制信号。
-
索引 0 通常是 BOS (Begin of Sentence),如
<s>。 -
索引 1 是我在
generate函数中显式指定的 Decoder Start Token(代码里设为 102)。
这两个 Token 只是告诉模型‘准备开始’,并不是实际的文本内容。如果不切掉,生成的句子就会带有乱码。所以 [2:] 是为了清洗数据,只保留真正生成的文本。”
Q6: 为什么用 CIDEr 分数来保存模型,而不是 Loss?Loss 越低不是越好吗?
破题思路:考评价指标的区别。Loss 是数学上的最优,CIDEr 是人类感官上的最优。
满分回答: “Loss 低并不完全代表生成质量好。
-
Loss 的局限:CrossEntropy Loss 只是逐词比较概率。有时候模型生成了一句通顺的话,只是换了个同义词,Loss 可能会很高,但其实语义是对的。
-
CIDEr 的优势:CIDEr 基于 TF-IDF,它更关注句子中的关键词(Rare Words)是否被生成出来了,这更符合人类的评判标准。
所以我的策略是:用 Loss 训练参数,用 CIDEr 择优保存。”

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)