代码命名质量的数学本质与AI生成影响:多理论视角分析
对于AI生成,实际生成依赖为:P(C|N, X) = Σ_I P(C|I, N, X)P(I|N, X)假设2 (命名信息载体性):命名是意图传递的载体之一,承载部分语义信息,但其信息量随命名质量而变化。假设3 (语义关联可度量性):在特定训练数据和模型架构下,命名与目标意图之间可能存在可度量的关联性。联合分布:P(I, N, X, C) = P(I)P(N, X|I)P(C|I, N, X)随机
- 基本假设与定义
1.1 理论假设
假设1 (信息传递约束性):在现实开发场景中,AI代码生成通常基于有限提示推断开发者意图,提示信息的充分性影响推断的准确性。
假设2 (命名信息载体性):命名是意图传递的载体之一,承载部分语义信息,但其信息量随命名质量而变化。
假设3 (语义关联可度量性):在特定训练数据和模型架构下,命名与目标意图之间可能存在可度量的关联性。
假设4 (AI模型行为模式):给定相同输入,同一AI模型倾向于产生相似输出,但存在一定随机性。
1.2 形式化框架
设:
意图空间 I ⊆ S,其中S为所有可能编程意图的集合
命名空间 N ⊆ T,其中T为所有有效标识符的集合
代码空间 C ⊆ P,其中P为所有有效程序的集合
AI生成过程:f: N × X → C,其中X表示其他输入信息(注释、上下文等)
正确性评估:R: I × C → [0,1],表示代码符合意图的程度
- 信息论视角分析
2.1 信息传递的约束条件
根据香农信息论的基本原理:
事件x的自信息:I(x) = -log₂P(x)
随机变量X的熵:H(X) = E[I(X)] = -Σ P(x)log₂P(x)
条件熵:H(Y|X) = Σ P(x)H(Y|X=x)
2.2 命名作为信息通道之一
令I为意图随机变量,N为命名随机变量,X为其他输入信息。
考虑信息传递链:I → (N, X) → C
根据数据处理不等式的一般形式: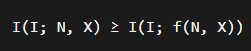
当f为确定性函数时成立。
2.3 命名质量的相对信息度量
在给定其他输入X的条件下,可定义命名的相对信息贡献:
此度量满足:
0 ≤ Q(n|x) ≤ 1
Q(n|x)=1 表示命名n完全确定了意图(给定x)
Q(n|x)=0 表示命名n不提供额外意图信息(给定x)
注意:实际中命名很少完全确定意图,Q(n|x)通常处于中间值。
- 概率图模型分析
3.1 贝叶斯网络结构
考虑更现实的网络结构:I → (N, X) → C
联合分布:P(I, N, X, C) = P(I)P(N, X|I)P(C|I, N, X)
对于AI生成,实际生成依赖为:P(C|N, X) = Σ_I P(C|I, N, X)P(I|N, X)
3.2 条件概率的关联性
命题:在给定其他输入X的条件下,当P(i|n₁, x) > P(i|n₂, x)时,AI可能更倾向于生成针对意图i的代码,但这一关联受限于:
AI模型的实际训练目标
P(C正确|i, n, x)可能随n变化
模型可能具有补偿机制,通过x弥补n的信息不足
因此,清晰命名与正确代码生成之间存在统计关联性,而非确定性关系。
- 向量空间表示分析
4.1 嵌入空间的统计性质
现代AI模型常将文本映射到高维空间S^{d-1} ⊆ ℝ^d。
语义相似度常使用余弦相似度: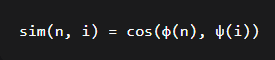
其中φ, ψ为嵌入函数。
4.2 清晰命名的统计趋势
基于训练过程的统计观察:
训练目标通常使相关(命名,意图)对具有较高相似度
清晰命名与目标意图的共现频率较高,可能导致嵌入向量在统计上更接近
模糊命名与多个意图的共现可能导致其嵌入向量位于这些意图向量的中间区域
注意:这一趋势取决于训练数据的分布,存在例外情况。
4.3 相似性检索视角
考虑最近邻检索:根据命名嵌入查找相似训练样本。
清晰命名的最近邻中,与目标意图相关的样本比例在统计上可能更高:
对于训练良好的模型,清晰命名的一致性期望值通常高于模糊命名。
- 搜索过程复杂度分析
5.1 程序空间的规模估计
考虑有限长度程序集合:
词汇表大小 V ≈ 10^4
平均程序长度 L ≈ 100 tokens
程序空间基数上限:|C| ≤ V^L ≈ 10^400
5.2 约束条件的筛选效应
命题:命名提供的语义信息可能减少AI需要搜索的空间。
设:
无约束时搜索空间大小:S₀ = |C|
意图I约束后:S₁ = |C_I| = α₁·S₀, α₁ < 1
命名N进一步约束:S₂ = |C_{I,N}| = α₂·S₁, α₂ ≤ 1
在理想情况下,清晰命名可能显著减小α₂,但实际效果取决于:
AI模型利用命名信息的能力
其他约束条件的存在
模型先验知识的补偿作用
5.3 决策过程复杂度
将生成过程建模为近似搜索,清晰命名可能:
减少达到满意解所需的迭代次数
提高初始生成的质量
降低细化修改的需求
但这些效益存在边际递减规律。
- 因果关联分析
6.1 因果图结构
综合理论分析
多视角关联性总结
从上述理论视角分析,发现以下统计趋势和条件关系:
信息传递角度:在控制其他输入条件下,高质量命名通常传递更多意图信息
概率推断角度:清晰命名常使后验分布更集中于目标意图
向量空间角度:在训练良好的模型中,清晰命名倾向于靠近目标意图向量
搜索过程角度:清晰命名可能减少有效搜索空间
因果分析角度:命名质量可能对生成质量产生非零影响,但混杂因素复杂
理论贡献与边界
理论框架价值
本研究提供了:
多视角分析框架:从多个理论角度分析命名质量的影响机制
条件性结论:明确理论关联的应用条件和边界
实践启示基础:为开发实践提供理论依据而非绝对规则
10.2 研究局限性
需要注意:
理论假设的简化:实际开发环境比理论模型复杂
AI技术的快速发展:新型AI能力可能改变现有关系
任务类型的差异性:不同编程任务对命名的敏感性不同
开发者因素的复杂性:个人习惯和经验的影响难以完全建模
未来研究方向
实证研究设计:在控制条件下检验理论预测
交互机制探索:研究命名与其他输入信息的互补关系
动态策略优化:开发自适应命名策略的智能辅助工具
结论
通过多理论视角分析,我们发现代码命名质量与AI生成效果之间存在条件性关联而非绝对因果关系。高质量命名在多数情况下可能:
提高意图信息传递效率
改善AI的意图推断准确性
优化生成过程的搜索效率
在统计上提高期望代码质量
然而,这些影响受多种因素调节,包括:
AI模型的具体能力
其他输入信息的充分性
任务复杂度和类型
开发者技能和经验
在AI辅助编程实践中,适度优化命名质量通常具有正期望价值,但最优投入水平需根据具体上下文动态调整。这一平衡视角为开发者提供了更实用、更灵活的指导原则,避免了绝对化建议可能导致的过度优化或忽视。
理论分析的价值不在于提供确定性的绝对法则,而在于揭示潜在机制、识别关键因素,并为实证研究和实践优化提供概念框架。在快速发展的AI编程时代,保持理论开放性和实践灵活性同样重要。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)