多智能体架构完全指南:从单一智能体到提升90.2%性能的架构设计
本文详细解析了大模型应用中的多智能体架构选择策略,介绍了四种核心模式:子智能体、技能、交接和路由器,分别适用于不同场景。研究显示,恰当的多智能体架构可提升90.2%性能。文章通过对比各架构在分布式开发、并行化、多跳交互和直接用户交互方面的表现,帮助开发者根据需求选择最优架构。建议从单一智能体开始,仅在遇到上下文管理和分布式开发限制时才升级到多智能体系统。
许多智能体任务其实用一个设计良好的单一智能体就能搞定。建议从这里开始——单智能体更简单,更容易理解和调试。但随着应用规模的扩大,团队会面临一个常见挑战:他们想把各种分散的智能体能力整合到一个统一的界面中。随着需要整合的功能越来越多,两个主要限制就会浮现:
上下文管理:每个能力所需的专业知识很难舒服地塞进一个提示词里。如果上下文窗口无限大且延迟为零,当然可以预先包含所有相关信息。但实际上,需要一些策略来在智能体工作时有选择性地提供信息。
分布式开发:不同团队独立开发和维护各自的功能,有明确的边界和所有权。单一的巨型智能体提示词在跨团队管理时会变得非常困难。
当需要管理大量领域知识、跨团队协作或处理真正复杂的任务时,这些限制就变得至关重要。在这些情况下,多智能体架构才会成为正确的选择。
最近的研究表明,多智能体系统在这些场景下表现更好。在Anthropic的多智能体研究系统中,使用Claude Opus 4作为主智能体、Claude Sonnet 4作为子智能体的多智能体架构,在内部研究评估中比单一的Claude Opus 4智能体表现好了90.2%。这种架构能够将工作分配给拥有独立上下文窗口的智能体,实现了单一智能体无法达到的并行推理能力。
多智能体架构
四种架构模式构成了大多数多智能体应用的基础:子智能体(Subagents)、技能(Skills)、交接(Handoffs)和路由器(Router)。每种模式在任务协调、状态管理和顺序解锁方面采用不同的方法。下面概述了一个框架,帮助选择最能解决关键限制的架构。
子智能体:集中式编排
在子智能体模式中,一个监督智能体通过将专门的子智能体作为工具来调用,从而协调它们。主智能体维护对话上下文,而子智能体保持无状态,提供强大的上下文隔离。
工作原理:主智能体决定调用哪些子智能体、提供什么输入以及如何组合结果。子智能体不记得过去的交互。这种架构提供集中控制,所有路由都通过主智能体,可以并行调用多个子智能体。
最适合:具有多个不同领域的应用,需要集中的工作流控制,且子智能体不需要直接与用户对话。例如协调日历、邮件和CRM操作的个人助理,或委托给专业领域专家的研究系统。
核心权衡:每次交互都会增加一次额外的模型调用,因为结果必须通过主智能体回流。这种开销提供了集中控制和上下文隔离,但代价是延迟和token消耗。
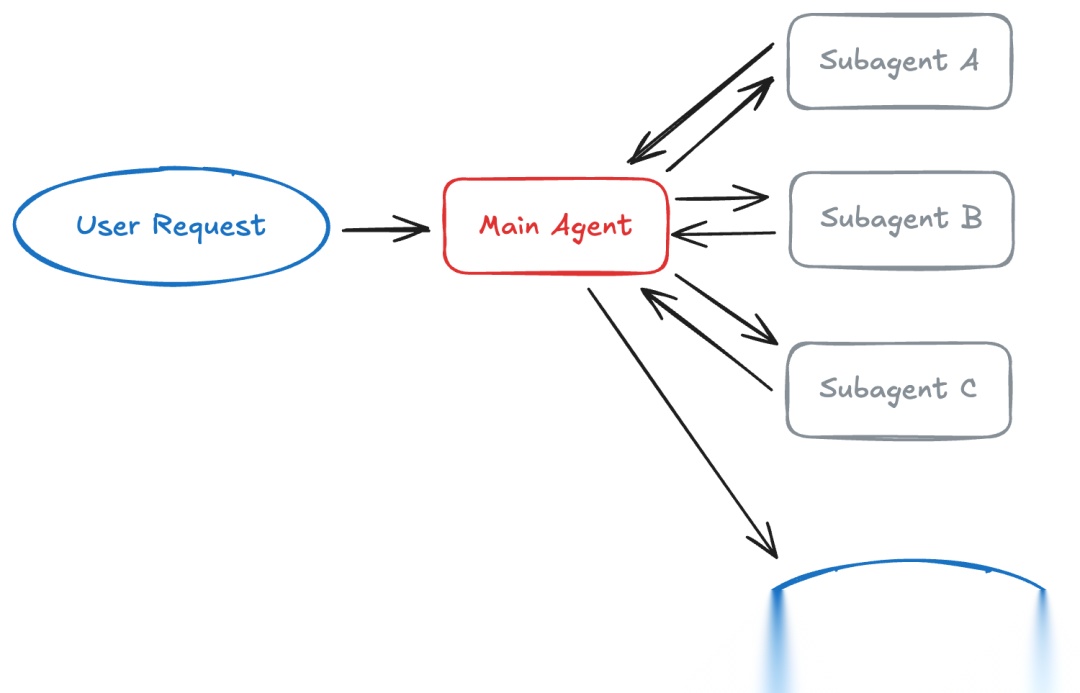
对于想要用最少设置实现这种模式的开发者,Deep Agents提供了开箱即用的实现,只需几行代码就能添加子智能体。
了解更多:子智能体文档 | 教程:用子智能体构建个人助理
技能:渐进式披露
在技能模式中,智能体按需加载专门的提示词和知识。可以把它理解为智能体能力的渐进式披露。
虽然技能架构从技术上讲使用的是单一智能体,但它通过让智能体动态采用专门的角色,具有了多智能体系统的特征。这种方法提供了与多智能体模式类似的好处——比如分布式开发和细粒度的上下文控制——但通过更轻量级的、提示词驱动的方法,而不是管理多个智能体实例。所以,虽然可能有争议,但可以将技能视为一种准多智能体架构。
工作原理:技能主要是提示词驱动的专业化模块,打包为包含指令、脚本和资源的目录。启动时,智能体只知道技能的名称和描述。当某个技能变得相关时,智能体才会加载其完整上下文。技能中的附加文件提供了第三级详细信息,智能体只在需要时才会发现。
最适合:具有许多可能专业化方向的单一智能体,不需要在能力之间强制执行约束的情况,或者不同团队维护不同技能的团队分布场景。常见例子包括编码智能体或创意助手。
核心权衡:随着技能的加载,上下文会在对话历史中积累,这可能导致后续调用时token膨胀。但这种模式提供了简单性,并且在整个过程中保持直接的用户交互。
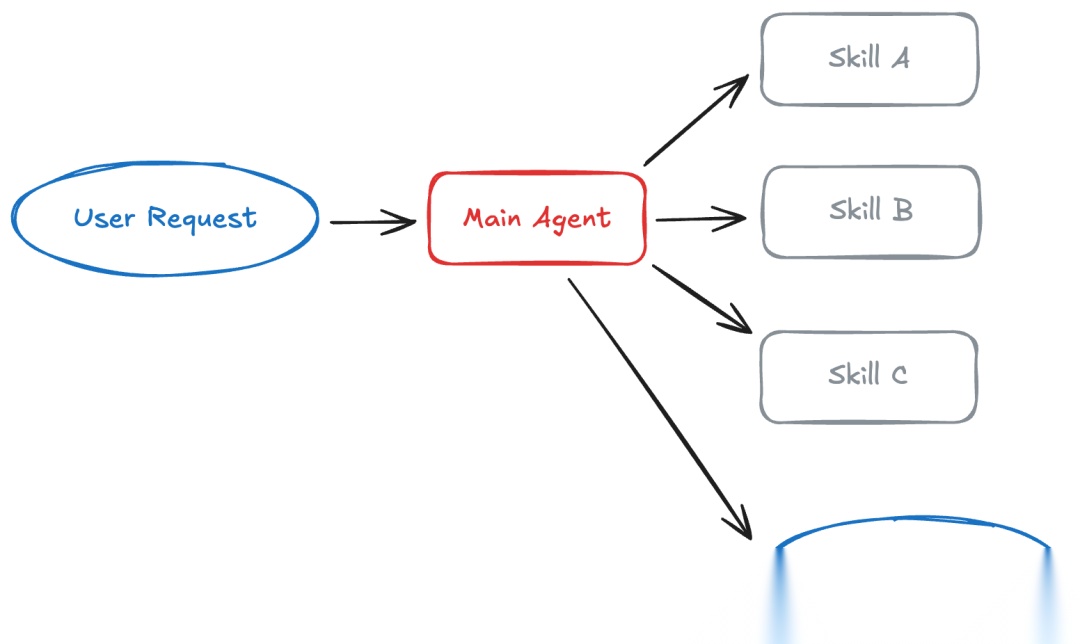
了解更多:技能文档 | 教程:用按需技能构建SQL助手
交接:状态驱动的转换
在交接模式中,活动智能体根据对话上下文动态变化。每个智能体都能通过工具调用转移到其他智能体。
工作原理:当智能体调用交接工具时,它会更新状态,从而决定下一个要激活的智能体。这可能意味着切换到不同的智能体,或改变当前智能体的系统提示词和可用工具。状态在对话轮次之间持续存在,支持顺序工作流。
最适合:分阶段收集信息的客户支持流程、多阶段对话体验,或任何需要顺序约束的场景(只有满足前提条件后能力才会解锁)。
核心权衡:比其他模式更有状态,需要仔细的状态管理。但这使得流畅的多轮对话成为可能,上下文在阶段之间自然地延续。
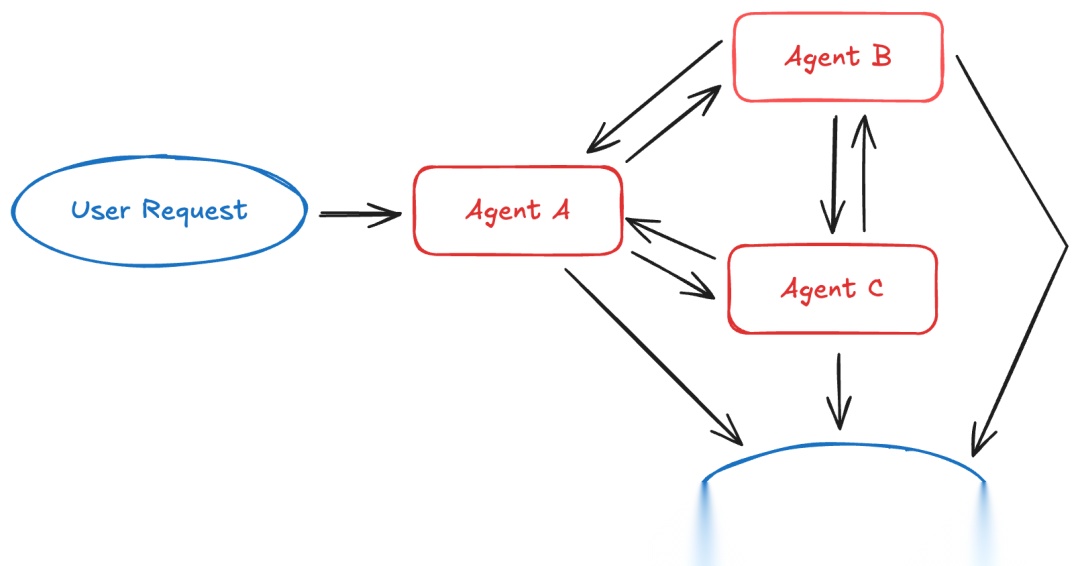
了解更多:交接文档 | 教程:用交接构建客户支持
路由器:并行分发和综合
在路由器模式中,路由步骤对输入进行分类并将其定向到专门的智能体,并行执行查询并综合结果。
工作原理:路由器分解查询,并行调用零个或多个专门的智能体,然后将结果综合成一个连贯的响应。路由器通常是无状态的,独立处理每个请求。
最适合:具有不同垂直领域(独立知识域)的应用,需要跨多个来源并行查询的场景,或需要综合多个智能体结果的情况。例子包括企业知识库和多垂直领域的客户支持助手。
核心权衡:无状态设计意味着每个请求的性能一致,但如果需要对话历史,会有重复的路由开销。可以通过将路由器作为工具包装在有状态的对话智能体中来缓解。
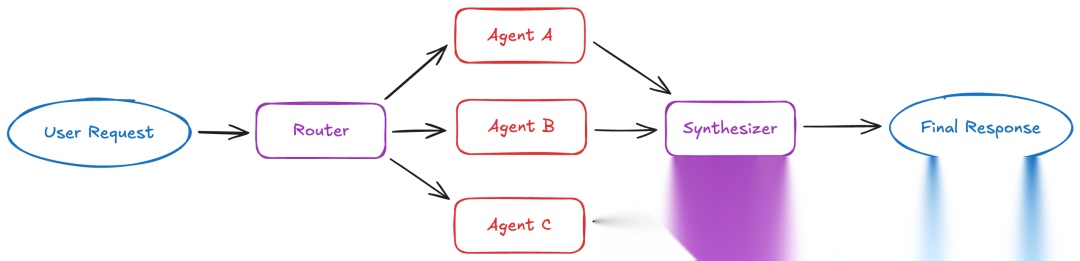
了解更多:路由器文档 | 教程:用路由构建多源知识库
将需求与模式匹配
在实现多智能体系统之前,考虑需求是否与这四种模式之一对齐:
| 需求 | 模式 |
|---|---|
| 多个不同领域(日历、邮件、CRM),需要并行执行 | 子智能体 |
| 单一智能体有许多可能的专业化方向,轻量级组合 | 技能 |
| 具有状态转换的顺序工作流,智能体在整个过程中与用户对话 | 交接 |
| 不同的垂直领域,并行查询多个来源并综合结果 | 路由器 |
下表显示了每种模式如何支持常见的多智能体需求:
| 模式 | 分布式开发 | 并行化 | 多跳 | 直接用户交互 |
|---|---|---|---|---|
| 子智能体 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐ |
| 技能 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 交接 | — | — | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 路由器 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | — | ⭐⭐⭐ |
- 分布式开发:不同团队能否独立维护组件?
- 并行化:多个智能体能否并发执行?
- 多跳:模式是否支持串行调用多个子智能体?
- 直接用户交互:子智能体能否直接与用户对话?
性能特征
架构选择直接影响延迟、成本和用户体验。分析了三个代表性场景,以了解不同模式在真实条件下的表现。
注意,可以在新的多智能体性能文档中找到完整的性能细分(包含每种架构的mermaid图表)。
场景1:单次请求
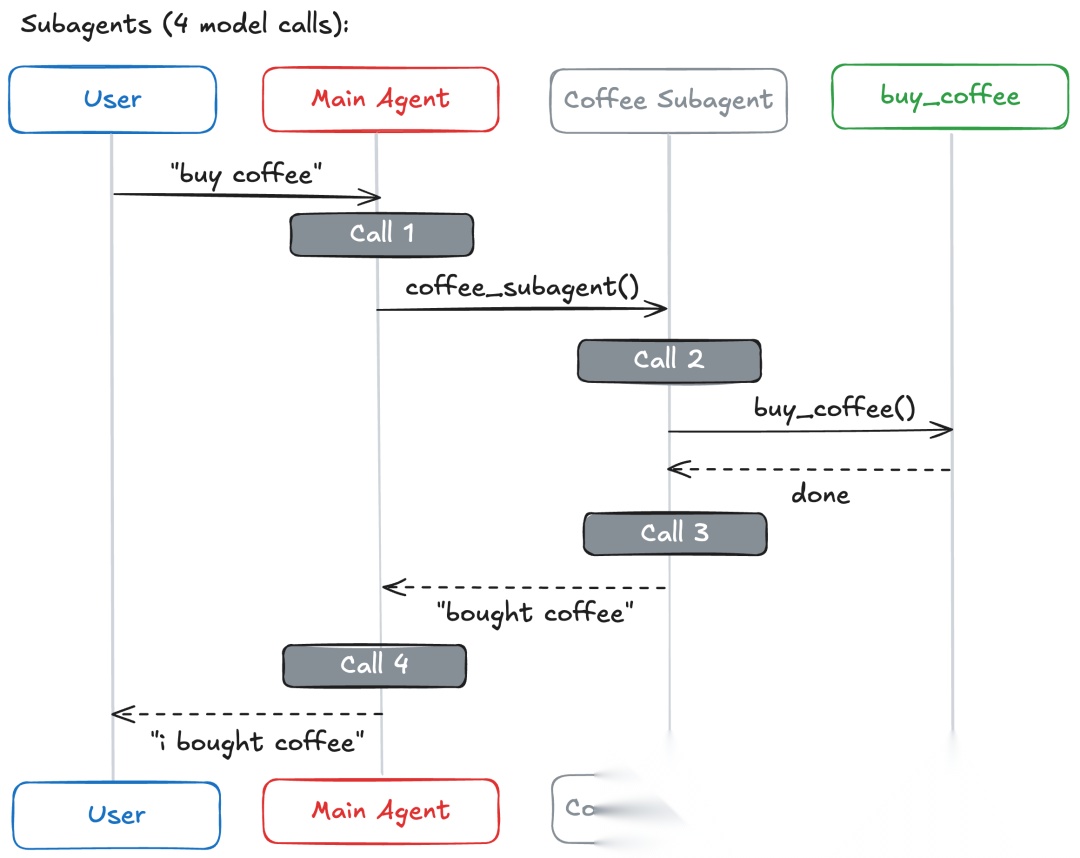
用户发出单个请求:“买咖啡”。专门的智能体可以调用buy_coffee工具。
| 模式 | 模型调用次数 | 备注 |
|---|---|---|
| 子智能体 | 4 | 结果通过主智能体回流 |
| 技能 | 3 | 直接执行 |
| 交接 | 3 | 直接执行 |
| 路由器 | 3 | 直接执行 |
关键洞察:对于单个任务,交接、技能和路由器最高效(各3次调用)。子智能体增加了一次额外调用,因为结果通过主智能体回流。这种开销提供了集中控制,如下所示。
场景2:重复请求
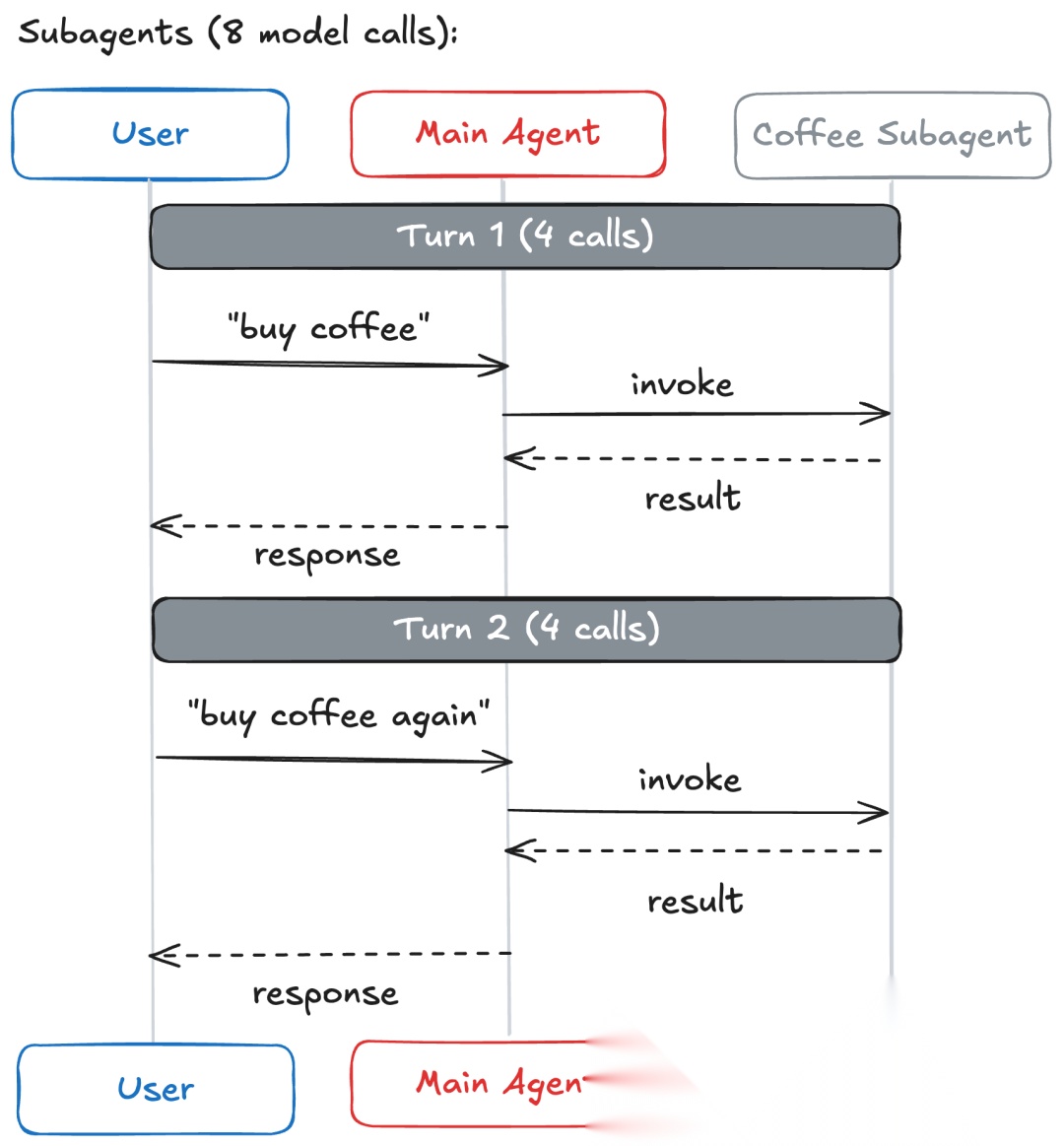
用户在对话中两次发出相同请求:
- 第1轮:“买咖啡”
- 第2轮:“再买一杯咖啡”
| 模式 | 第2轮调用 | 总调用 | 效率提升 |
|---|---|---|---|
| 子智能体 | 4 | 8 | — |
| 技能 | 2 | 5 | 40% |
| 交接 | 2 | 5 | 40% |
| 路由器 | 3 | 6 | 25% |
关键洞察:有状态的模式(交接、技能)通过维护上下文,在重复请求时节省了40-50%的调用。子智能体通过无状态设计保持每个请求的成本一致,以重复的模型调用为代价提供强大的上下文隔离。
场景3:多领域查询
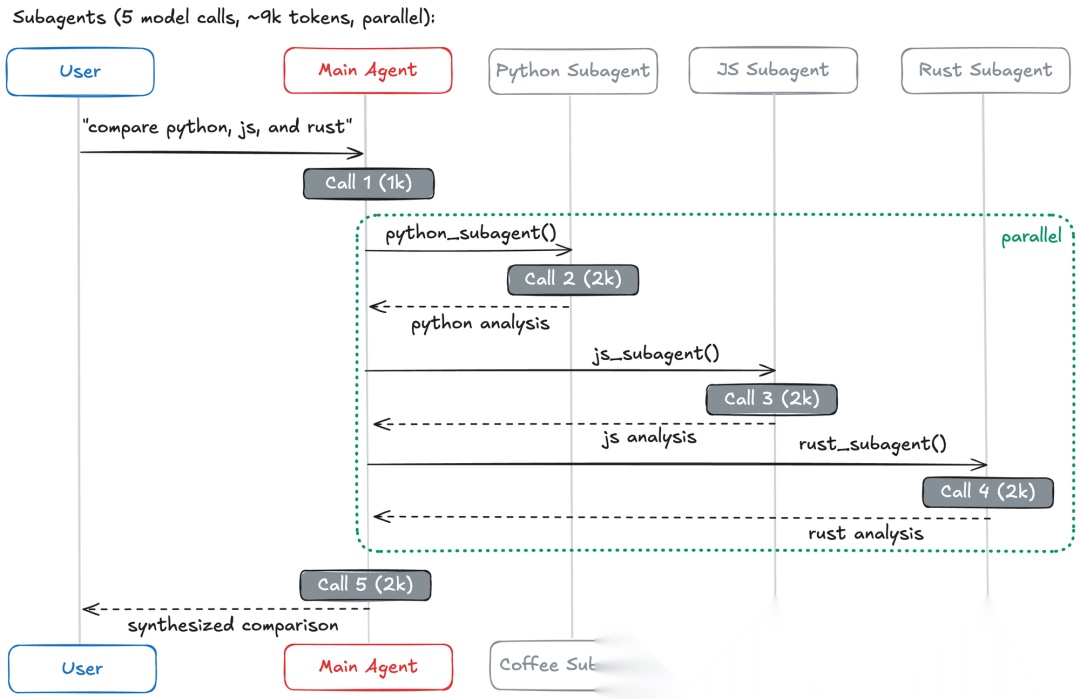
用户问:“比较Python、JavaScript和Rust用于Web开发。” 每个语言智能体包含大约2000个token的文档。所有模式都可以进行并行工具调用。
| 模式 | 模型调用 | 总token数 | 备注 |
|---|---|---|---|
| 子智能体 | 5 | ~9K | 每个子智能体独立工作 |
| 技能 | 3 | ~15K | 上下文积累 |
| 交接 | 7+ | ~14K+ | 需要顺序执行 |
| 路由器 | 5 | ~9K | 并行执行 |
关键洞察:对于多领域任务,具有并行执行能力的模式(子智能体、路由器)最高效。技能的调用次数较少,但由于上下文积累导致token使用量高。交接必须顺序执行,无法利用并行工具调用同时咨询多个领域。
在这个场景中,由于上下文隔离,子智能体处理的token总量比技能少67%。每个子智能体只处理相关上下文,避免了将多个技能加载到单个对话中时积累的token膨胀。
性能总结
最优模式取决于工作负载特征:
| 模式 | 单次请求 | 重复请求 | 并行执行 | 大上下文领域 |
|---|---|---|---|---|
| 子智能体 | — | — | ✅ | ✅ |
| 技能 | ✅ | ✅ | — | — |
| 交接 | ✅ | ✅ | — | — |
| 路由器 | ✅ | — | ✅ | ✅ |
如何开始
下面是Langchain的Deep Agents
多智能体系统协调专门的组件来处理复杂的工作流。当确实需要多智能体能力时,将需求与上述决策框架匹配。对于想要快速开始的团队,Deep Agents提供了开箱即用的实现,结合子智能体和技能来进行复杂的任务规划。
不过在许多情况下,更简单的架构往往就足够了。从单一智能体和良好的提示词工程开始。在添加智能体之前先添加工具。只有在遇到明确限制时才升级到多智能体模式。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献537条内容
已为社区贡献537条内容

所有评论(0)