大模型代理推理完全指南:从被动预测到主动行动的范式转变
本文探讨了大语言模型从静态推理向代理推理的范式转变,提出Agentic Reasoning三大层级:基础能力、自我进化和群体智能。分析了In-context和Post-training两条技术路线,介绍了Agent在科学发现、编程等领域的应用,指出未来AI竞争力在于构建强大的Agentic Loop——让AI能在环境中生存、记忆、反思和协作的系统设计。
如果在 2023 年,我们还在为 ChatGPT 能写出一首打油诗而惊叹,那么到了 2026 年的今天,单纯的“文本生成”已经无法满足我们对 AGI 的胃口了。我们痛苦地发现:即便模型参数大到离谱,它依然是一个“被动”的预言家——它只能根据你给的 Prompt 算概率,却无法像人一样去“试错”、去“查证”、去“反思”。

- 论文:Agentic Reasoning for Large Language Models
- 链接:https://arxiv.org/pdf/2601.12538
今天我们要拆解的这篇论文 《Agentic Reasoning for Large Language Models》 ,与其说是一篇综述,不如说是给所有做 Agent 的人发的一张“藏宝图”。它不仅仅总结了过去几年的技术,更重要的是,它正式宣告了 LLM 从“Static Reasoning”(静态推理)向 “Agentic Reasoning”(代理推理)的范式转移。
这不是简单的“加个插件”那么简单,这是一次对智能本质的重新建模。
认知的跃迁:从“大脑缸中之脑”到“具身行动者”
这篇论文最核心的洞察在于:Reasoning(推理)不应该只是发生在 Transformer 内部的矩阵乘法,而应该是一个物理过程。
让我们看一张图:
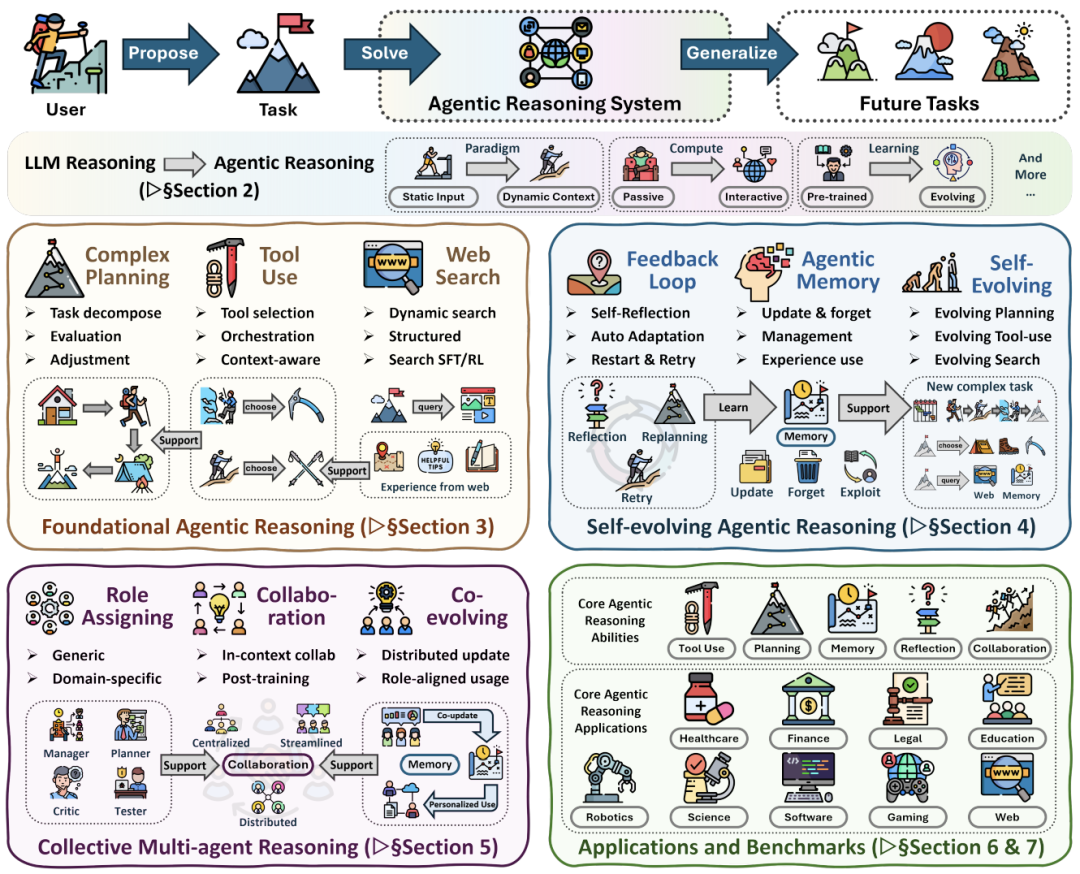
- 传统 LLM Reasoning:
Input -> Internal Compute -> Output。这是一次性的,像是在闭卷考试。 - Agentic Reasoning:
Observation -> Plan -> Act -> Feedback -> Memory -> Refine。这是一个闭环,像是在做科学实验。
作者非常敏锐地指出,这种转变在数学上其实是将 LLM 放入了一个 POMDP(部分可观测马尔可夫决策过程) 中。这不仅是数学游戏,它深刻地改变了我们训练和使用模型的方式。
那个打破僵局的公式
论文中给出了一个非常漂亮的分解公式,将“思考”与“行动”在数学上解耦了:
- (Internal Thought): 这是模型的“内心戏”,比如 CoT(思维链)或者潜在的规划。这部分是不可见的、纯计算的。
- (External Action): 这是模型对世界产生的影响,比如调用 API、写文件、移动机器人手臂。
- : 历史上下文。
Why it matters?以前我们训练模型,是希望它直接输出(比如直接写出代码)。现在我们意识到,必须显式地建模(先想好架构,再写代码)。这种“Think before you Act” 的数学表达,正是最近 DeepSeek-R1 等 Reasoning 模型大火的理论根基。
进化的三重奏:Agentic Reasoning 的完整版图
论文没有堆砌算法,而是构建了一个名为“三维互补”的宏大框架。这非常有意思,它把 Agent 的能力分成了三个层级,像极了生物进化的过程。
1. Foundational(基石):单兵作战的能力
这是 Agent 的基本功,类似于人类学会使用工具。论文将其细分为三个核心要素:
- Planning(规划): 不是简单的“一步步来”,而是引入了搜索算法。论文特别提到了从简单的 Chain-of-Thought 到复杂的 MCTS (蒙特卡洛树搜索) 的演变 。现在的 Agent 在回答问题前,会在脑子里“模拟”无数种可能,就像下围棋一样。
- Tool Use(工具): 关键点在于从“模仿”(SFT)到“精通”(RL)。早期的 Toolformer 只是在模仿人类调用 API,而现在的 Agent 通过 RL 学习何时调用工具、如何处理报错 。
- Search(搜索): 这超越了传统的 RAG。Agentic Search 是动态的——Agent 自己决定“我要不要查资料”、“查到的够不够”、“要不要换个关键词再查一次” 。
2. Self-Evolving(进化):从经验中学习
这一点最让我兴奋。目前的绝大多数 Agent 都是“失忆”的——你在这就聊得火热,换个 Session 它就不认识你了。但 Self-Evolving Agent 引入了两个关键机制:
- Feedback (反馈循环): 不仅仅是人类给点赞,而是包括 Reflective Feedback(自我反思,如 Reflexion)和 Validator-Driven Feedback(比如代码跑不通报错了,Agent 自动看懂报错并重写) 。
- Agentic Memory (动态记忆): 记忆不再是简单的 Vector DB 检索。论文提出了 Memory-as-Action 的概念 ——Agent 会主动决定“这句话很重要,我要写进长期记忆”或者“这个策略过时了,我要忘掉它”。这意味着模型在不更新参数的情况下,随着使用变得越来越“聪明”。
3. Collective(协作):群体智能的涌现
当单体智能遇到瓶颈时,大自然给出的答案是“群体”。论文详细探讨了从静态角色扮演(如 CAMEL, AutoGen)到动态共同进化(Multi-Agent Co-Evolution)的跨越 。 最精彩的部分在于**“协作即推理” (Collaboration as Reasoning)** 的观点:一个 Agent 的输出(Action)成为了另一个 Agent 的输入(Prompt),这种通过 Communication 传递的信息流,本质上是一个分布式的推理过程 。
In-context vs. Post-training:两条路线之争
在如何实现上述能力时,论文犀利地指出了当前的两大技术流派:
- 派系一:In-context Reasoning (推理时编排)
- 做法: 也就是 Prompt Engineering 的极致。通过复杂的 Prompt 流程(如 ReAct, Plan-and-Solve)来激发模型的潜能。
- 优点: 灵活,不需要训练,即插即用。
- 缺点: 受到 Context Window 限制,且推理成本极高(Token 燃烧机) 。
- 派系二:Post-training Reasoning (训练后内化)
- 做法: 通过 SFT 和 RL(特别是像 GRPO 这样的算法)将推理模式“烧录”进模型参数里 。
- 核心洞察: 就像 DeepSeek-R1 做的那样,让模型内化“搜索”和“反思”的过程。论文提到,未来的趋势一定是 System 2 的能力逐渐被蒸馏进 System 1 的直觉中。
实验与应用:不只是纸上谈兵
这篇 Survey 的扎实之处在于它涵盖了大量垂直领域的落地情况。
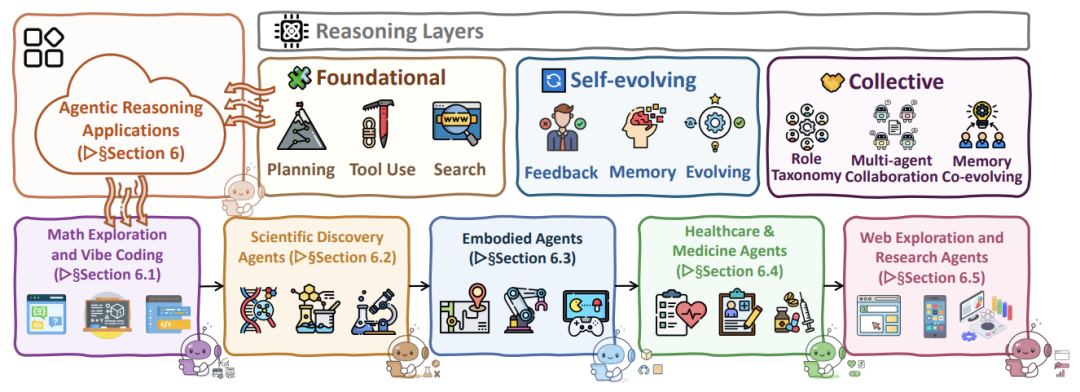
- 上图展示了应用版图,特别值得关注的是 Scientific Discovery(科学发现) 。
- 例如 AI Scientist 这样的系统,已经不仅仅是辅助查资料,而是能独立提出假设、设计实验、编写代码验证、甚至撰写论文。在这里,Agent 实际上是在遍历一个巨大的“科学假设空间”。
- **Math & Coding:**这里的 Agent 已经不仅是做题家,而是探险家。通过 Self-Correction 和 Execution Feedback,Agent 可以在写代码时自己写单元测试来验证自己的逻辑 。
局限与未来:你的 Agent 还缺什么?
文章最后 提出的 Open Problems 非常值得深思,这里挑两个最痛的:
- World Models (世界模型) 的缺失: 目前的 Agent 很多时候是在“瞎猜”行动后的结果。如果 Agent 脑子里有一个 World Model,能模拟“如果我删了这个文件会发生什么”,它的规划能力将会有质的飞跃。
- Latent Agentic Reasoning (隐式推理): 现在的 CoT 都是自然语言,这其实效率很低。未来,模型可能会在高维向量空间里直接进行“纯思维”的规划,而不需要把每一步都翻译成人类语言。
总结
这篇 Agentic Reasoning 的论文告诉我们,我们正处在 AI 发展的十字路口:我们不再仅仅是在训练“模型”,我们是在设计“系统”。
未来的 AI 护城河,可能不在于你有一个多大的 Base Model,而在于你构建了多强大的 Agentic Loop——你的 Agent 能否在环境中生存、记忆、反思,并与他人协作。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
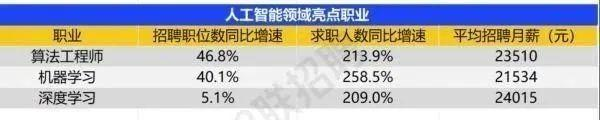
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献537条内容
已为社区贡献537条内容

所有评论(0)