多模态-11 Qwen2-VL
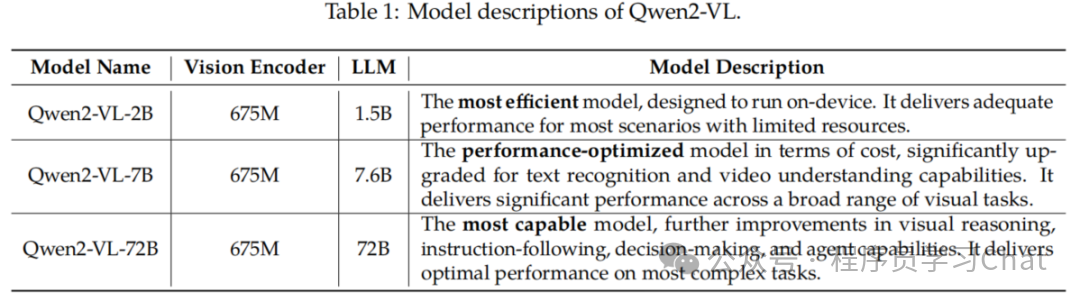
Qwen2-VL是Qwen-VL的升级版多模态模型,主要改进包括:支持任意分辨率图像输入、扩展视频处理能力、增加多语言支持(日语、韩语等8种语言)以及提升视觉任务范围。模型结构由视觉编码器和语言大模型组成,采用2D-RoPE和M-RoPE技术处理时空信息。训练采用三阶段方法,使用包含1.4T token的高质量多模态数据集。Qwen2-VL提供2B、8B和72B三种参数规模版本,适用于不同应用场景
这篇文章介绍千问VL系列多模态模型Qwen2-VL
Transformer介绍可以看:深度学习基础-5 注意力机制和Transformer
多模态基础知识点介绍可以看:多模态-1 基础理论
Qwen-VL介绍可以看:多模态-10 Qwen-VL
需要一些大模型基础理论和训练的知识,可以看:大模型基础理论-BPE/DeepNorm/FlashAttention/GQA/RoPE、大模型训练-流水线并行/张量并行/ZeRO/Prefix/Prompt tunning/LoRA
Qwen2-VL原论文:《Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution》
Qwen2-VL是Qwen-VL的拓展延续,进行了以下改进:
1)动态分辨率:Qwen-VL只支持固定大小的图像输入,Qwen2-VL支持任意大小的图像输入
2)更全面的模态:Qwen-VL主要输入是图文,Qwen2-VL支持处理视频
3)更丰富的数据集:增加视频、Agent调用等多种类型的数据,形成1.4T token的高质量训练集
4)多语言支持:Qwen-VL主要支持中英文,Qwen2-VL拓宽了语言范围,支持日语、韩语、法语、德语、意大利语、俄语、越南语、阿拉伯语等
5)多视觉任务支持:除了支持Qwen-VL的图像理解、问答、Grounding、OCR,还支持视觉Agent、视频理解等任务

Qwen2-VL全面探索了视觉语言大模型的Scaling law,针对不同使用场景发布了不同参数规模的Qwen2-VL版本,包括具有最优效率适合边缘部署的Qwen2-VL-2B、平衡性能和效率的Qwen2-VL-8B、最全面综合能力的Qwen2-VL-72B
一 模型结构
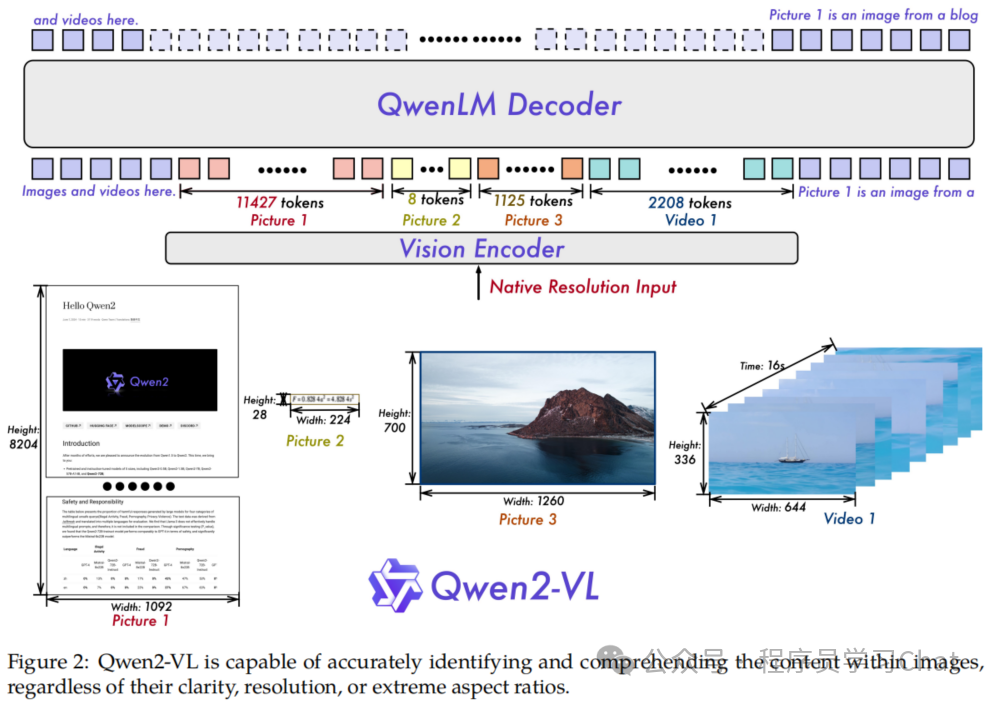





Qwen2-VL要解决的关键问题是突破Qwen-VL的固定图像输入尺寸限制,实现对任意尺寸图像和视频的理解,整体类似Qwen-VL的思路,视觉编码器提取视觉特征,视觉特征融合到语言大模型的token序列中,由语言大模型根据这些序列进行视觉理解与信息生成,但是Qwen2-VL移除了Qwen-VL的adapter组件,只由视觉编码器(Vision Encoder)+语言大模型(LLM,Qwen2-VL使用的语言大模型是Qwen2)组成。
1.1 Naive Dynamic Resolution

注意图像中每个patch的二维坐标不是指的像素坐标h和w,而是patch分块之后的行号和列号,比如一个图像分为了9个patch,每行3个patch,那么第一个patch的h、w为(0,0),第二个是(0,1)......,以此类推。
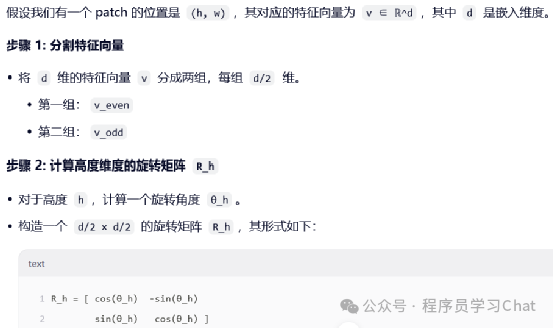
2D-RoPE是RoPE在二维图像上的拓展



举个具体计算例子:
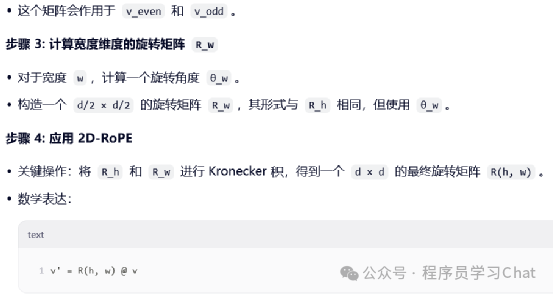
1.2 M-RoPE

具体计算过程如下:



M-RoPE 作用于 LLM 内部注意力计算的 Q、K 向量上,通过逻辑划分嵌入向量的维度,让不同部分携带上 (t, h, w) 的信息。
一个视频输入到Qwen2-VL中,M-RoPE的具体处理过程如下:


1.3 Unified Image and Video Understanding

二 训练




Qwen2-VL采取的也是类似于Qwen-VL的三阶段训练方法:






Qwen2-VL并行训练细节如下:


三 数据集格式
引入[vision_start]、[box_start]、[object_ref_start]、[llm_start]等标记符号区分训练数据的不同部分,原理和Qwen-VL中的标记符号类似,详细介绍可以看:多模态-10 Qwen-VL



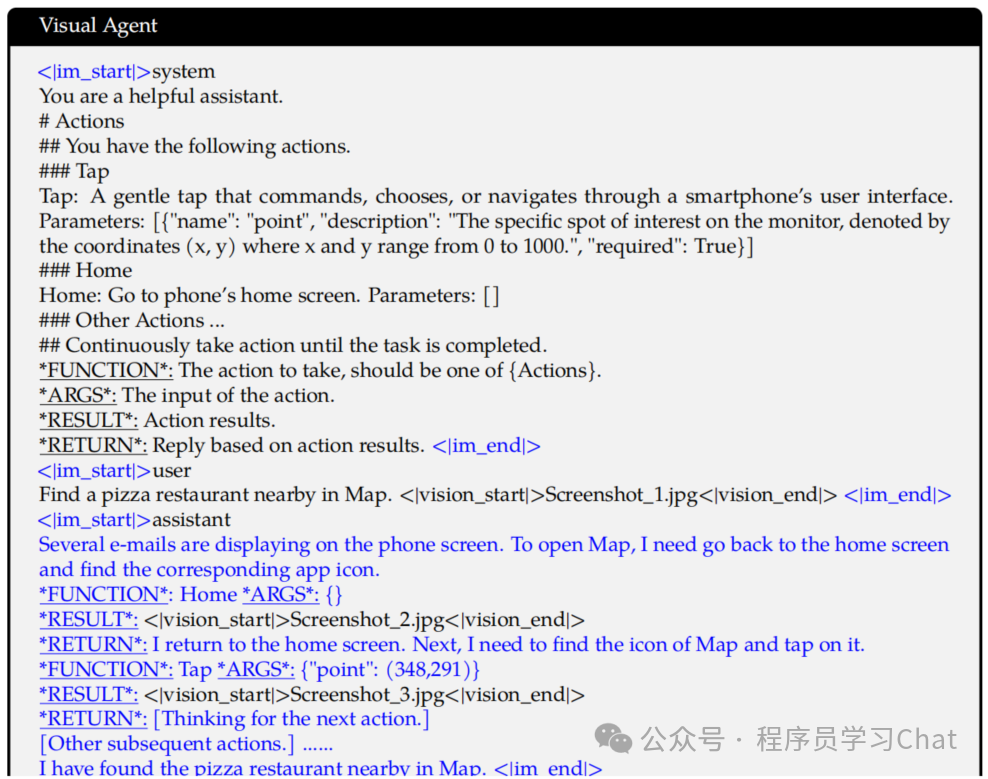
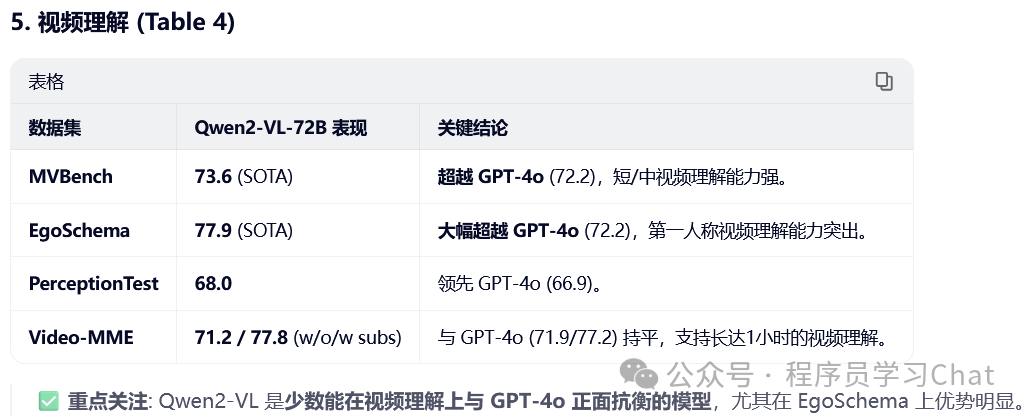
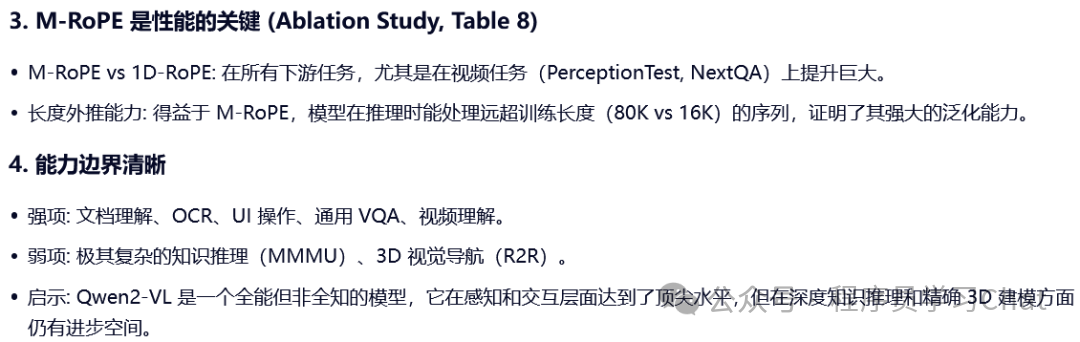
四 实验结果
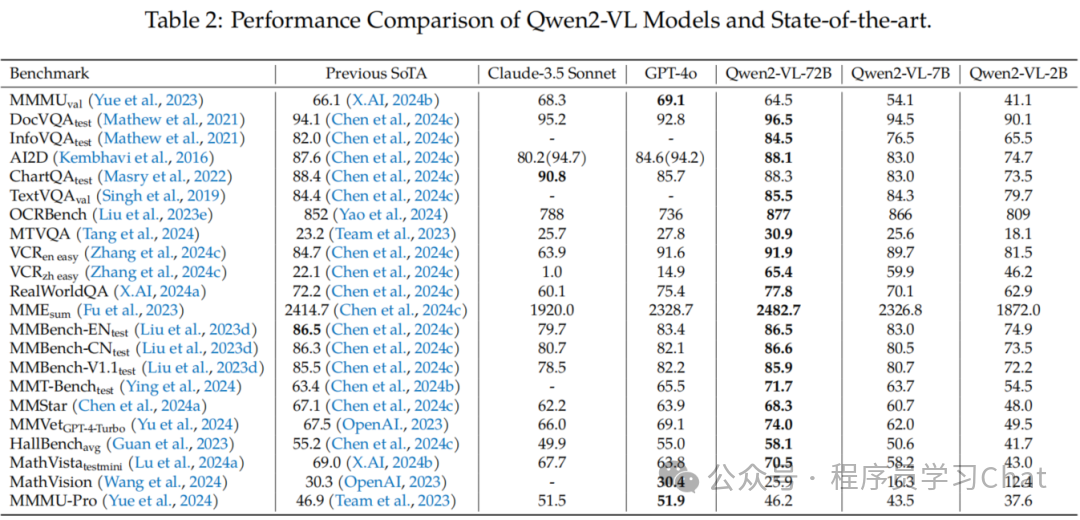


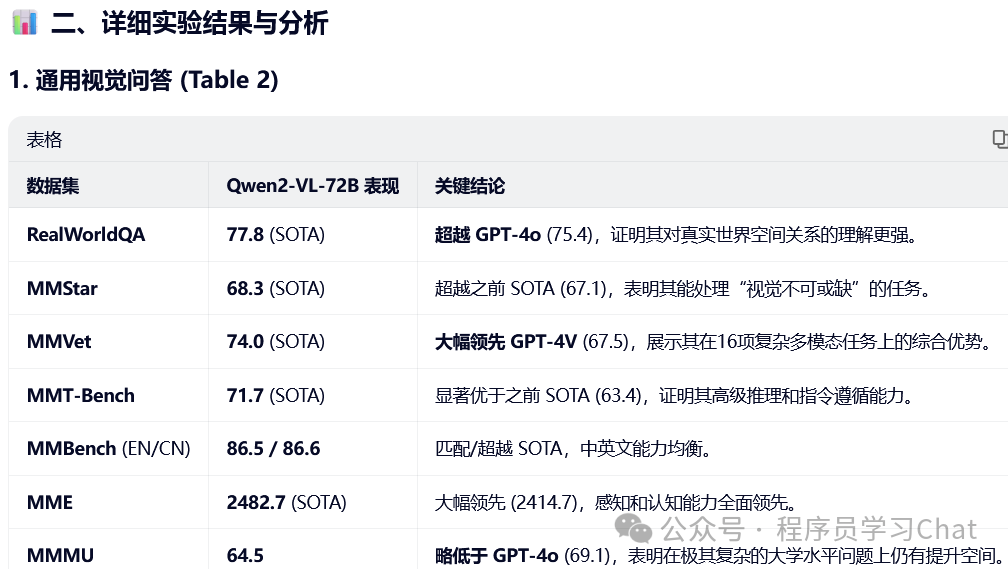
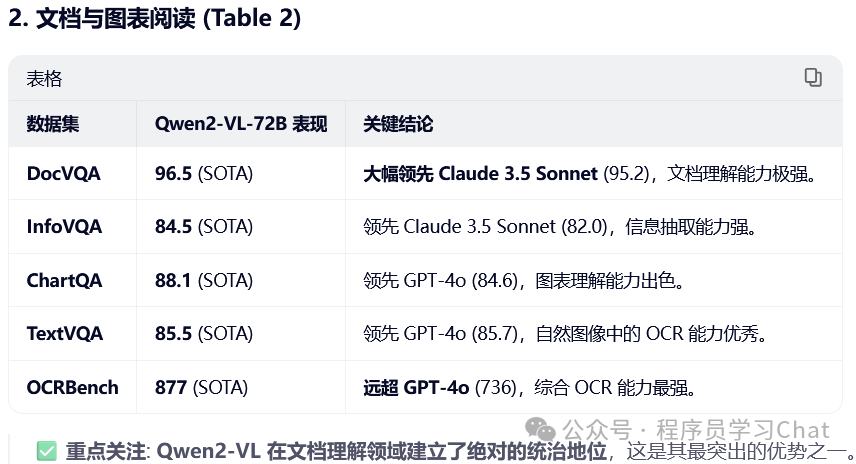





有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)