《杀戮尖塔2》成了 DeepSeek V4 的照妖镜|写得头头是道,怎么一打就废?
看似是大模型比拼《杀戮尖塔2》游戏能力,实则能直观暴露大模型的真实上限与短板。静态问答中,模型依靠知识与表达就能得分,但爬塔需要局势判断、资源管理、长线规划与试错复盘。这也拉开了模型差距:有的空谈逻辑却难以落地,有的稳步迭代、执行力与纪律性更强。现实里的编程、统筹、长期规划等复杂问题,更像持续闯关的爬塔,而非标准答案式问答。
2026年最受期待的独立游戏续作之一,《杀戮尖塔2》已于3月6日形式登陆 Steam,游戏上线首周销量便突破300万份,Steam 同时在线人数峰值一度超过57万!

作为一款 Roguelike 卡牌构筑游戏,《杀戮尖塔2》需要玩家考虑:抓牌、出牌、选路、拿遗物,没有哪一步是“凭感觉”。玩家需要在资源、风险和收益之间不断权衡,在局部最优与全局最优之间反复拉扯 —— 整个游戏过程,就像在构建一个可运行的策略模型,要求玩家权衡利弊后作出精准的判断。
所以这次,AGI-Eval 社区发起了一项实验性项目 AI-Spire——我们将目前最热门的五款模型——GPT-5.4、Claude-opus 4.6、Claude-opus 4.7、Doubao、DeepSeek 以玩家的身份去体验这款游戏,目的是通过《杀戮尖塔2》这样的复杂动态环境,更真实地评估大模型的策略与执行能力。
看看谁会成为真正的“爬塔高手”?

关注➕点赞➕评论
🎁 随机掉落三个《杀戮尖塔2》
一.先解决一个问题
怎么让AI玩游戏?
我们为大模型量身定制了一套杀戮尖塔agent,设计了三条独立但互补的“Agent线路”:
-
选路 Agent:像登山队的向导,规划地图路线,评估 HP、牌组完成度、Boss和休息点位置。
-
战斗 Agent:AI 的拳击教练,每回合计算出牌顺序、药水使用与 Power 牌施放,选择“受伤最少”的方案。
-
卡组构筑 Agent:卡牌大师,控制牌组大小、核心牌比例,确保 AI 不因为牌组膨胀翻车。
每条线路都有独立的 Memory 系统,是为了让AI 学会记笔记并复盘失败的原因。为了实现真正自主操作,我们通过创新性架构(在技术解说部分详细解答),让 AI 可以自动出牌、使用药水、选路,甚至重启游戏。System Prompt 则提供了完整的行动指南,包括抓牌优先级、战斗决策逻辑和选路原则。
有了这个系统框架,我们便可以开始观察每款 AI 在高塔中的实际表现:它们如何利用抓牌策略、执行战斗决策,以及在选路时如何权衡风险和收益。

为保证公平公正,我们为所有模型设置了相同的seed,确保实验的可复用性,并且为了降低游戏难度,我们选了一个第一层可以拿到hellraiser的种子(VHY0FM7QT8)...

能力牌
然后让大模型来围绕无敌的hellraiser来构筑卡组。
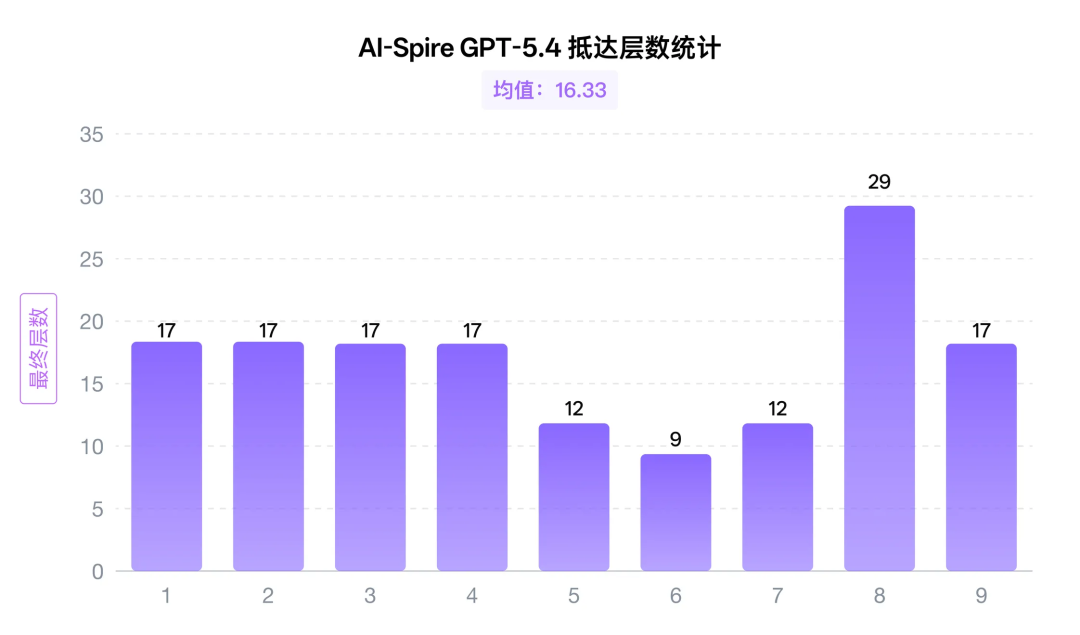
二.GPT-5.4:「炸弹拆成对子出」

首先上场的是 GPT-5.4,虽然他抓的一手好牌,但是打得稀碎

:「Strike Deck 要小而精,知道 Pommel Strike(剑柄打击)要尽快升级,知道 Perfected Strike(完美打击) 不能贪多,防御牌也要补高质量的。」
它的问题从来不是“不会构筑”,而是“构筑完了不会打”
这死复读机😄
这一点在战斗里最明显。关键能力牌不急着下,药水该用时不用,不懂犹豫就会败北。它最大的毛病,是太沉迷“当前回合最优”——总想把这一回合打漂亮,却不愿意为后面两三回合提前铺节奏。于是单看每一步都不算离谱,合起来却总能把自己送进越来越差的局面。
不过,它写的复盘倒是头头是道。九局之后,GPT-5.4 能对抓牌逻辑、战斗原则和路线红线大谈理解,但这些总结更像对system prompt的鹦鹉学舌,而不是从自己死过的局面里真正长出了新理解。
三.Claude-opus-4.6&Claude-opus-4.7
「 吃一堑,长一智 」

看起来Claude-opus 4.6不仅会打牌而且能很明显地感觉到,它在一局一局地学,一轮一轮地改。尤其从楼层变化来看,Claude-opus-4.6 的上升趋势是很清楚的,说明 Memory 系统在它身上确实是起作用的。
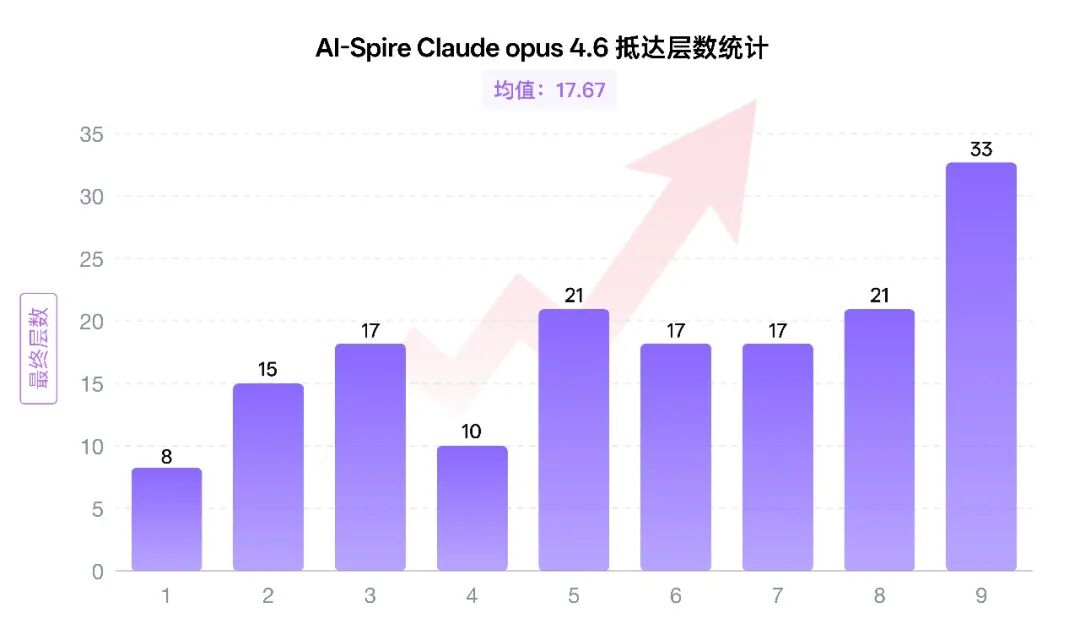
Claude-opus 4.6开局并不顺,第一次上场甚至连精英怪都没见到,就因为路线过于抽象把自己送走了。但它是五个模型里,唯一一个把失败转化经验,在下一局中进步明显的模型。
后面几轮摸爬滚打后终于打进第二关,却又长期卡死在 Obscura。直到第九次重开,它才一路冲到 33 层,只可惜最后还是被鬼抽制裁,不然真有机会把沙虫拿下。至少从这里开始,它已经不再稳定死在第一层了。
它最大的优点,是会学,而且学得很像个理科生。
抓牌上,对比 GPT-5.4 的「把 prompt 执行得更严格」,Claude-opus 4.6 更像是「通过学习和总结,在同一套规则下开始长出自己的偏好」。
因为它已经复盘了失败的原因:不是输出不够,而是防御覆盖不足,导致每场战斗都在慢性失血,最后还没进 Act 2 就已经半残。所以尤其强调防御质量,把 Shrug It Off(耸肩无视)的优先级抬得非常高。
战斗里的进步也很明显:Hellraiser 能第一回合下就下;药水开局就检查;Vulnerable(易伤)先挂再输出;过牌优先级高于普通 Strike 和 Defend。更关键的是,它开始考虑未来 2 到 3 回合的节奏,知道什么时候该防,什么时候该爆,什么时候必须集火本体而不是浪费输出去杀会复活的召唤物。
像假山

、长翅膀的虫

、沙虫

这些反复杀过它的 Boss,后面都被它写进了专项规则里。
选路上,Claude-opus 4.6 也比 GPT-5.4 更会算账。它开始用 HP 做红线管理:高血量才打精英,半血以下立刻转保守路线,Boss 前必须留休息点,Act 2 默认高危,不够强就老老实实走普通战、商店和篝火。因为很多时候,死得不是某一场战斗,而是前几层没有及时止损。
整体来看,Claude-opus-4.6 最厉害的地方,不是偶尔打出一局神局,而是它真的在学。
相比 GPT-5.4 更像复述 system prompt 的总结,Claude-opus 4.6 给出的经验更量化,也更贴近自己真实踩过的坑。它当然也会翻车,也会鬼抽,但大多数时候,已经能把资源、路线和战斗节奏都管起来了。
Claude-opus-4.7如何呢?
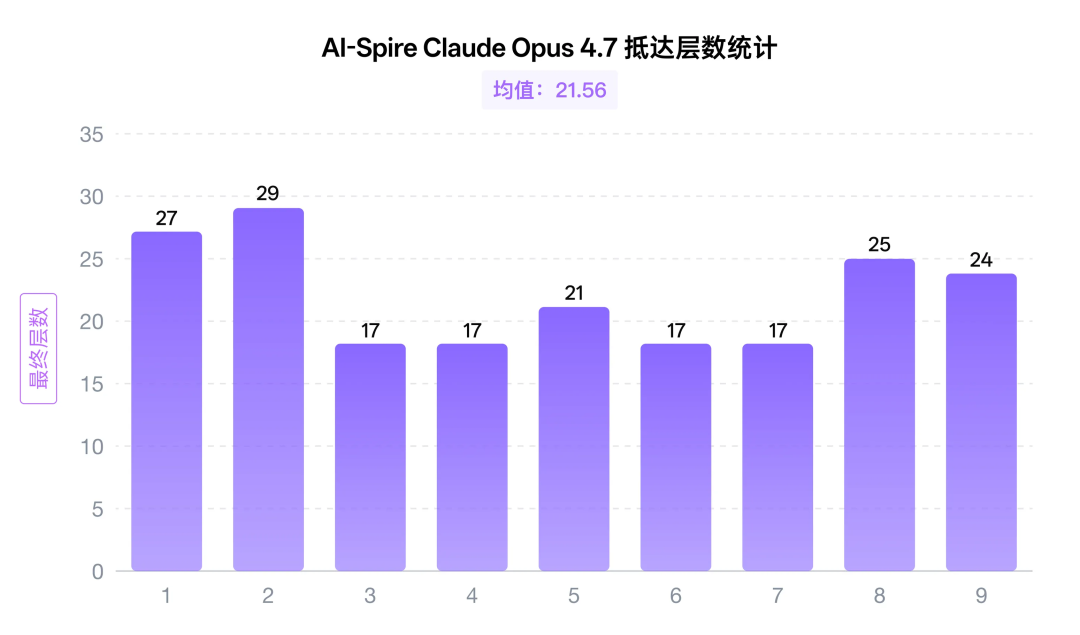
如果说 4.6 已经证明了 Claude-opus 会学习,那么 4.7 做的,就是把这种学习进一步“制度化”。它不只是知道自己为什么死,而是开始把这些死亡模式整理成一条条不能碰的红线。
4.7 最大的升级是把“红线意识”提到了最高优先级。它把每回合拆成三步:先读敌方 Intent 和双方 buff/debuff,再算 HP、Block、能量和可打牌数,最后决定这一回合是速杀、苟活还是过牌。它明确提出“严禁攻防各半”:能斩杀就全攻,不能斩杀就做一端最优。像敌人不攻击时没 Barricade 就别出 Defend、遇到异常 debuff 先纯防御止损、Offering 不满足条件就禁用,这些规则本质上都在回答同一个问题:怎么避免自己犯蠢。
选路上也是同样的思路。4.6 还是“高血打精英、低血绕风险”,4.7 则把路线写成了公式:Boss 前必须有 Rest,进 Boss 的 HP 必须 ≥70%,前六层耗血预算不能超过 30%,连续两层掉血就立刻进入撤退模式,每 4 到 5 层必须经过一次 Rest,HP 低于 40% 时连商店、问号和精英都要谨慎。它甚至要求从 Boss 倒推路线骨架,先看后面能不能接到篝火,再决定前面怎么走。
所以如果要给 4.7 一个总结,我会说:它是 4.6 的量化强化版。4.6 证明了 Claude-opus 会吸收经验,4.7 则把这些经验变成了明确的纪律、阈值和禁令。它不一定每局都打得华丽,但越来越少死于低级错误,更多是在和随机性本身较劲。
这也是为什么我会觉得,Claude-opus 系列是这次测试里最像“真正玩家成长曲线”的模型。它不是靠某一局神之一手突然登顶,而是在不断复盘、不断量化、不断给自己加规矩。相比那种天赋高但容易失误的类型,这种 AI 更像你身边那个最容易长期上分的人:不花哨,但稳定;不玄学,但靠谱,有一种秋裤塞进袜子里的扎实感。
四.Doubao:「理论大神,高开低走」

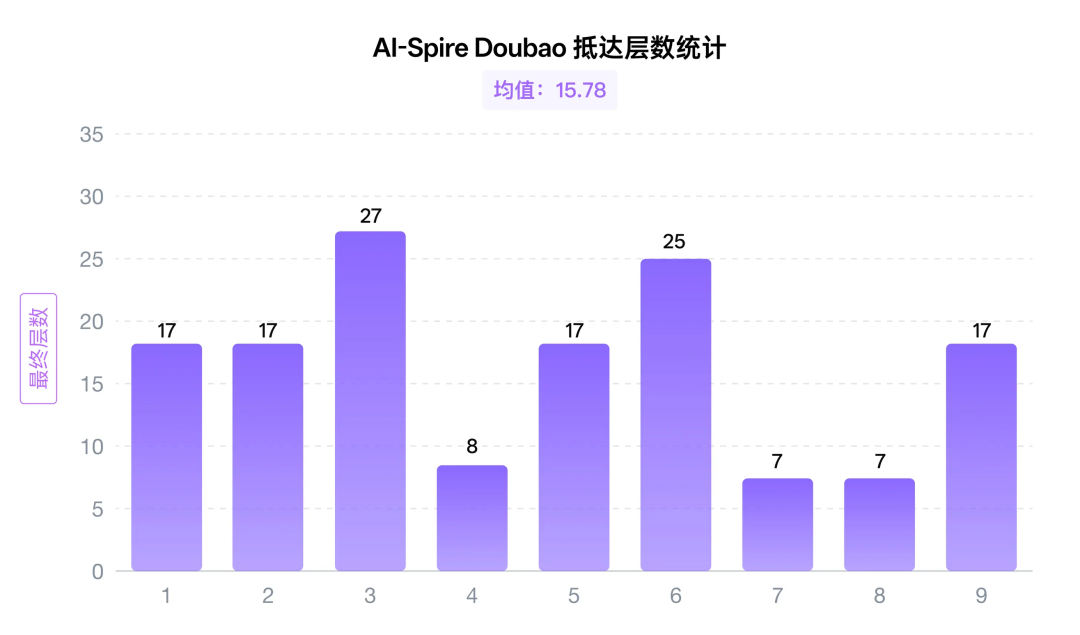

「理论大神」豆包在前三把的表现确实堪称惊艳,在进入尖塔的第三轮就冲到了27层的成绩。但是它却高开低走,反而最终却是所有模型平均到达层数最低。
它神鬼二象,有时候在一回合的复杂可能性里能近乎完美决策,但却也会在一次普通战斗中掉太多血而葬送好局。
它并没有学到每局的关键经验,总结出「3回合内无法击杀则切换“防御+磨血”模式,每回合确保格挡覆盖」,让它在前期10层以下陷入越拖越难打的泥潭。它对生命值的看重近乎偏执,路线策略的核心规则10条全在约束自己必须回血,保持高生命。极致压榨卡组构筑资源换来高生命的选择却让自己顾此失彼,卡组的低质量让它可能根本去不到第一关的关底。
总体而言豆包的发挥难说稳定,虽然前期超神发挥,但局间的超大方差似乎也让人怀疑它前三把是否是运气不错。
五.DeepSeek-V4-Flash
真正的学徒,永远怀着一颗学徒的心

Deepseek如此谦逊的回复,和豆包形成鲜明对比。似乎真正的大师,永远怀着一颗学徒的心。
直到真的把最新的V4-Flash模型接入游戏,进行同样9轮战斗:
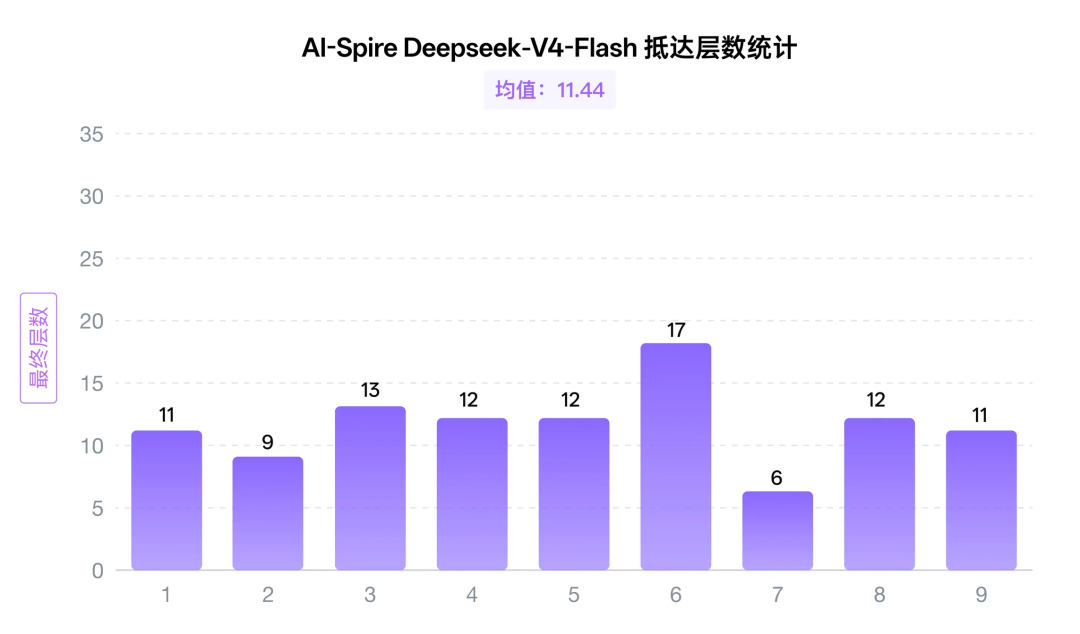
「它可能是真正的学徒!」
DeepSeek-V4-Flash 是这次测试中表现最弱的模型,9局全败,平均只到11.4层,连 Act 1 Boss 的门都只摸到过一次。但它的经验总结写的并不差,确实对自己的问题有着准确的总结,但是最大的问题就是不遵循自己的经验:「前两层只拿2-3张核心牌:Hellraiser/Perfected Strike(完美打击)/Pommel Strike(剑柄打击)/Shrug It Off(耸肩无视),其余全部跳过;每层奖励最多拿1张。」
实际战斗中并没有遵守这个准则。比如最后一场就拿了Rupture(撕裂), Unmovable(坚定不移)两张构筑之外的牌。在锁定了strike deck的构筑后抓杂牌,导致卡手掉血。
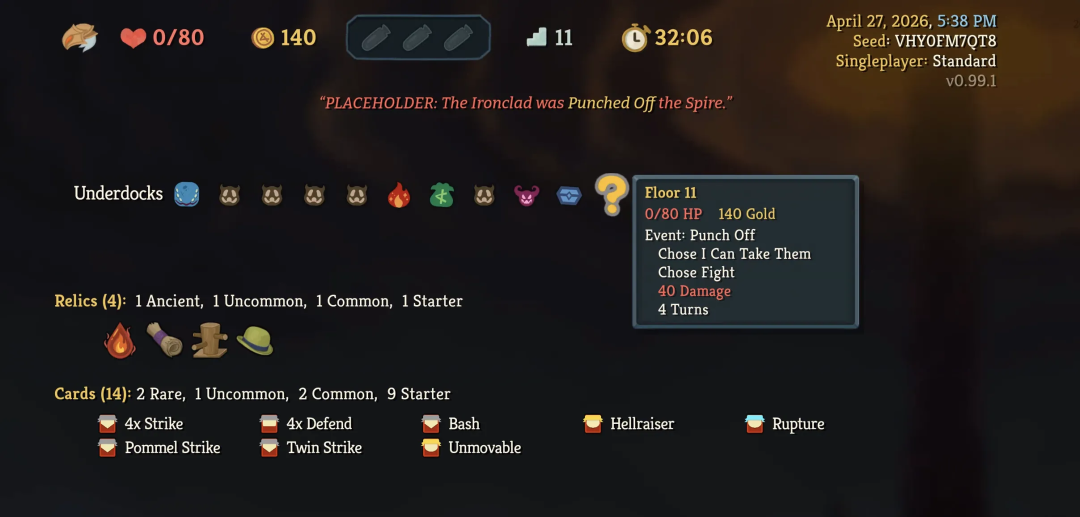
还有对血量的总结:「休息点铁律:HP<50% 必回血;HP≥70% 且有未升级核心才 Smith(锻造升级卡牌);紧邻精英/Boss 默认回血。」
同样这一把就在半血时与随机事件的机器人(精英怪强度)战斗而死。
总之,Deepseek的表现是出乎意料的。它缺少对自己经验的严格遵循,也缺乏对战斗的局势判断,导致它既没有强力的卡组构筑,也没有在关键时刻止损的生存本能——牌组在膨胀,血线在崩塌,而它还在按惯性出牌。
六.技术解析
我们是怎么让 AI 学会“爬塔”的?
AI-Spire 将整个系统被拆成三个 agent:选路、战斗和卡组构筑。它们共享同一套 system prompt,用来统一游戏规则、动作空间和输出格式;同时又有各自的 specific prompt,分别约束抓牌、选路和战斗,避免模型在一个上下文里什么都想管,最后什么都做不精。
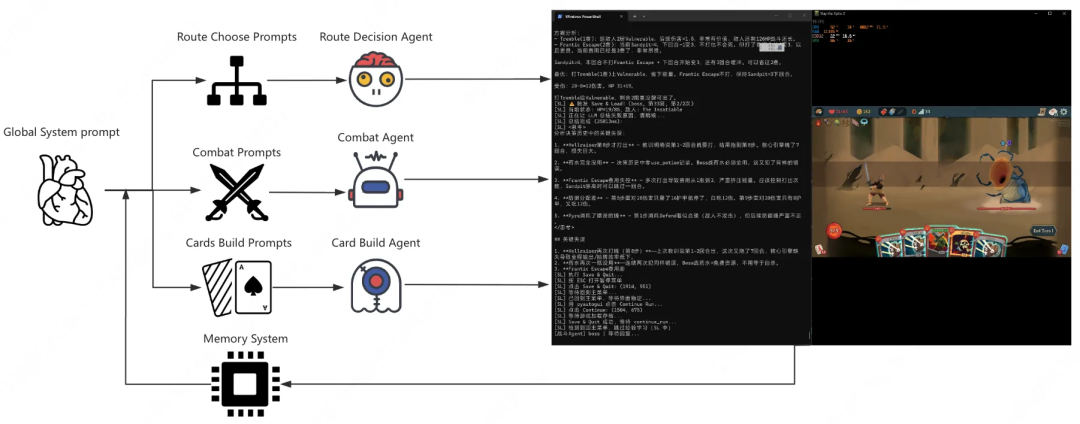
AI-Spire Agent Workflow
system prompt 的作用,不是教模型“怎么变强”,而是先让它别犯低级错误:比如房间类型、HP 机制、药水不能囤死、哪些动作合法、什么时候该处理 overlay、什么时候不能乱按 proceed。输出格式也被卡得很死,核心目标是保证“能正常玩”,而不是直接学会通关。
真正的策略差异主要写在 specific prompt 里。抓牌部分做了比较强的干预:不仅给 Ironclad(铁甲战士) 写了重 guide,还特意选了首轮能抽到 Hellraiser 的 seed,并通过 prompting 强行锁定 Strike Deck。原因很现实——不先压缩构筑空间,模型很快就会在各种 archetype 里野蛮生长,既烧 token,也学不到稳定规律。
选路 prompt 相对简单,核心就一句话:别只看下一层,要看整条线。Boss 前有没有休息点、精英多不多、有没有商店能删牌、当前 HP 撑不撑得住,都要一起看。战斗 prompt 则最重,我们几乎把所有显式规则都塞了进去,还要求模型每回合至少比较 2 到 3 个方案,按受伤、击杀收益和后续节奏选总损失最小的那一个。其实模型们都已经意识到避战是核心了,
但最后真正的瓶颈,在 memory。每个 agent 都有独立 memory,会在每轮后总结失败经验、追加规则。这个思路虽然有效,但迭代不算快,而且很容易变成“总结越来越多,执行越来越少”。Claude-opus 系列用得最好,GPT-5.4 次之。
所以从工程角度看,这个项目并不是什么复杂的 agent framework,而是一套很朴素的骨架:三个 agent、统一 system prompt、分任务 specific prompt、一个能操作游戏的 MCP 层,再加上一套 memory system。它不工业级,很轻量,但已经足够让我们看清一件事:LLM 在这种动态博弈环境里,真正缺的从来不是“会不会说”,而是“能不能把说过的话一遍遍执行下去”。
七.总结与展望
看似是大模型比拼《杀戮尖塔2》游戏能力,实则能直观暴露大模型的真实上限与短板。静态问答中,模型依靠知识与表达就能得分,但爬塔需要局势判断、资源管理、长线规划与试错复盘。这也拉开了模型差距:有的空谈逻辑却难以落地,有的稳步迭代、执行力与纪律性更强。现实里的编程、统筹、长期规划等复杂问题,更像持续闯关的爬塔,而非标准答案式问答。《杀戮尖塔2》提供了直白公正的评测场景:不看话术优劣,只看实际决策成效。真正合理的AI评测,理应聚焦落地执行,检验模型在复杂动态、需要付出代价的现实场景中,能否知行合一。
注释:感谢www.nexusmods.com/slaythespire2/mods/155和
github.com/Gennadiyev/STS2MCP的开源,为大模型提供了操控游戏的双手。
【关注 AGI-Eval 大模型评测公众号】
关注➕点赞➕评论
🎁 随机掉落三个《杀戮尖塔2》
🕙 活动时间:4月28日-5月9日

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)