Token使用量降低30%,以「阿凡达」为灵感的异构智能体框架Eywa,高效结合语言模型与领域专用基础模型
过去几年,AI 行业的主线几乎始终围绕「大模型」展开——更大的参数量,更长的上下文,更强的推理能力,整个行业都在试图构建「一个能够解决所有问题的通用模型」。但 Eywa 所代表的方向说明:「模态原生协作(modality-native collaboration)」能够有效增强多智能体系统在科学场景中的能力,并为未来异构基础模型协同推理提供了一条新的发展路径。换言之,未来真正重要的,并不是「一个万
过去几年,Agentic AI(智能体 AI)几乎成为人工智能领域最重要的演进方向之一。从自动编程、知识检索到任务规划,大语言模型(LLM)正从「聊天机器人」逐渐演化为具备自主推理、行动与协作能力的智能体系统。但一个越来越明显的问题也正在浮现——几乎所有主流智能体系统,本质上仍是「语言中心化」的系统。无论是任务规划、工具调用,还是智能体之间的协作,它们都建立在自然语言这一统一接口之上。
在互联网问答、办公自动化等场景中,这一范式运转良好。但当 AI 开始真正进入科学研究领域时,问题迅速暴露。因为科学世界并不天然属于语言。时间序列、材料晶体结构、蛋白质序列、气象网格、遥感观测数据……这些数据往往高度结构化,甚至根本无法被有效「文本化」。将它们强行转译为自然语言,不仅会损失信息,还会让大模型陷入极高的 token 消耗与推理冗余。
在此背景下,来自伊利诺伊大学香槟分校(UIUC)的研究团队提出了一个用于连接语言智能体与领域专用基础模型的异构智能体框架 Eywa。研究人员通过将领域专用基础模型与语言模型结合,构建出一种新的 EywaAgent,这种设计使语言智能体能够引导基础模型在其专业任务上的推理、规划与决策过程。
研究人员在涵盖物理科学、生命科学以及社会科学的多个领域对 Eywa 进行系统评估,结果表明,相较于仅依赖语言模型的基线系统,Eywa 在「效用—成本」权衡方面实现了持续提升——与 Single-LLM-Agent 基线相比,EywaAgent 在物理、生命与社会科学任务上的平均效用提升约 7%,Token 使用量降低约 30%,执行时间缩短约 10%。 类似地,在多智能体场景中,EywaMAS 同样实现了效用提升,同时降低了 Token 消耗与运行时间。
相关研究成果以「Heterogeneous Scientific Foundation Model Collaboration」为题,已发布预印本于 arXiv。
研究亮点:
* 在涉及结构化数据与领域专用数据的任务中,Eywa 能够有效提升系统性能
* 通过与专用基础模型的有效协作,Eywa 减少了对基于语言推理的依赖
* Eywa 可扩展到多智能体场景中:在 EywaMAS 中,EywaAgent 可以替代传统多智能体系统中的语言智能体;在 EywaOrchestra 中,一个 planner 能够动态协调语言智能体与 EywaAgent 共同解决复杂任务

查看论文:
https://hyper.ai/papers/2604.27351
EywaBench:「多任务、多领域、多模态」的科学评测体系
在提出模型框架之前,研究团队首先指出了当前科学 AI Benchmark 的一个长期存在的问题:即当前的大多数科学基准测试通常要么只覆盖单一任务类型,要么仅聚焦单一领域,要么只支持一种数据格式,因此往往无法完整反映科学智能体系统(scientific agentic systems)真正所需的能力。
研究团队特别指出,当前 benchmark 对两类核心模态长期缺乏充分评估:第一类是时间序列(Time Series),第二类是表格数据(Tabular Data),而恰恰是这两类数据,构成了现实世界科学计算与工业系统的核心基础。为此,论文提出了一个新的评测框架:EywaBench,一个面向异构模态、多任务、多领域科学推理的可扩展 benchmark。
EywaBench 基于多个已有数据集构建,包括但不限于:
* DeepPrinciple
* MMLU-Pro
* fev-bench
* TabArena
EywaBench 具有多任务、多领域覆盖能力,包含自然语言(natural language) 、时间序列(time series) 、表格数据(tabular data) 这三类核心数据模态任务。所有任务被组织为三个科学领域:第一类是物理科学(Physical Science),包括材料、能源与航天等方向;第二类是生命科学(Life Science),包括生物、临床与药物研发;第三类则是社会科学(Social Science),涵盖经济、商业与基础设施等场景。
更关键的是,EywaBench 本身具备可扩展性,研究团队可以通过增加新的时间窗口、变量组合与上下文配置,不断扩充任务规模;也可以接入新的时间序列数据集与表格数据集,扩展新的科学领域。
Eywa:连接语言智能体与领域专用基础模型
Eywa 最核心的灵感来自电影《阿凡达》中的「神经连接(Tsaheylu)」。在潘多拉星球中,Na’vi 可以通过神经连接与飞龙、战马等不同物种建立直接协同关系,从而让不同生物形成统一行动能力。
研究团队认为,当下的 Agentic Systems 也面临类似问题。LLM 拥有高层推理与规划能力,但不擅长处理原生科学数据;领域基础模型拥有强专业能力,却无法进行复杂任务推理。于是,论文提出了 FM–LLM 「Tsaheylu」 接口,其本质,是在语言模型与领域基础模型之间建立一个双向通信机制,如下图所示:
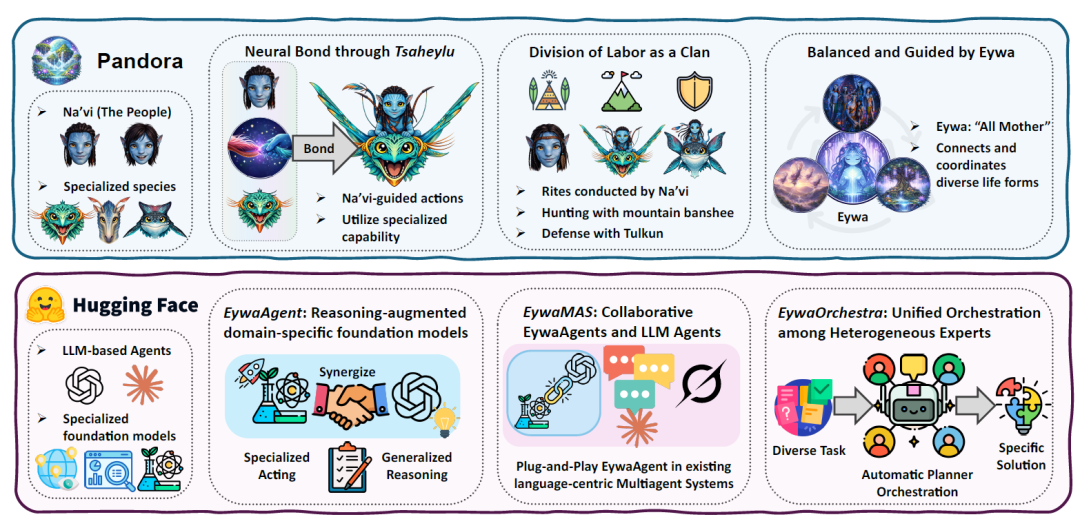
《阿凡达》潘多拉生态系统与 Agentic AI 生态系统之间的类比
第一步:构建 EywaAgent
迈向 Eywa 智能体框架的第一步,是提出 EywaAgent——一种统一抽象框架,通过为基础模型增加基于语言的推理接口,使其能够参与智能体系统中的高级推理过程,其核心思想是在执行高层规划与控制的语言模型,与提供专业能力的领域专用基础模型之间,建立一种强连接(strong bond)。
EywaAgent 通过名为 FM-LLM 「Tsaheylu」 链的双向通信接口,将基于语言的推理与领域特定计算相结合。该链接使语言模型能够正确配置并调用基础模型进行专用计算,同时将输出无缝重新整合至推理流程中。
Tsaheylu 接口被形式化为一对函数:查询编译器 ϕk 负责将任务状态翻译为基础模型的结构性调用,响应适配器 ψk 负责将基础模型的输出转换为兼容语言的表示。此通信流水线使 Agent 能够动态决定在内部执行计算还是将其委托给基础模型,从而在通用推理与专用执行之间灵活适应。
第二步:扩展到 Eywa 智能体系统
在将 EywaAgent 定义为一种可插拔(plug-and-play)的智能体基础模块之后,研究团队进一步将这一范式扩展到多智能体场景,以支持更加复杂、更加异构的协同合作。为此,论文提出了两个互补的系统级抽象:
EywaMAS
将 EywaAgent 扩展到分布式多智能体环境,使多个专业化智能体能够进行交互与协作。EywaMAS 的通信与状态更新动态遵循标准多 Agent 系统模型,其中 Agent 根据接收到的信息更新状态并生成消息,交互由通信拓扑控制。该方法支持在不同语言模型、基础模型及 Agent 类型之间进行灵活组合。
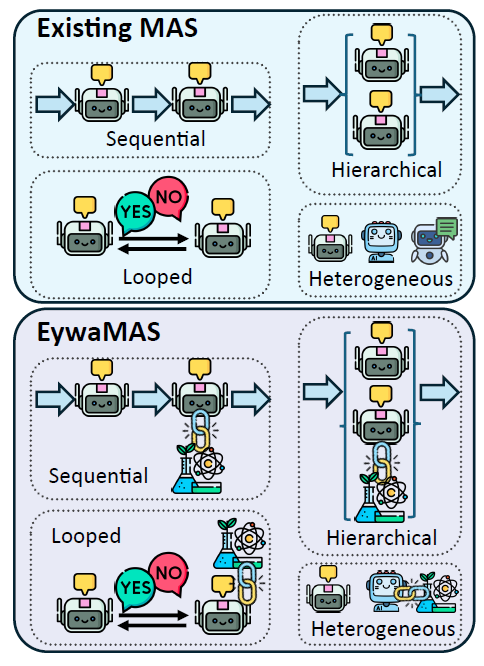
EywaMAS 对现有多智能体系统的扩展
EywaOrchestra
为应对多样化现实任务对 Agent 与拓扑不同配置的需求,框架引入了 EywaOrchestra,一种动态编排系统。EywaOrchestra 充当指挥器角色,根据输入任务动态实例化异构多 Agent 系统,通过选择适当的语言模型、基础模型及通信拓扑来实现。这种自适应编排使系统突破静态设计限制,利用模型适应性与结构适应性为每项任务选择最优配置。
Eywa 在「效用—成本」权衡方面实现持续提升
研究团队在统一实验协议下,对所有方法进行了 EywaBench 测试。下表展示了所有方法在 EywaBench 科学任务中的整体表现,实验结果揭示了几个关键结论:
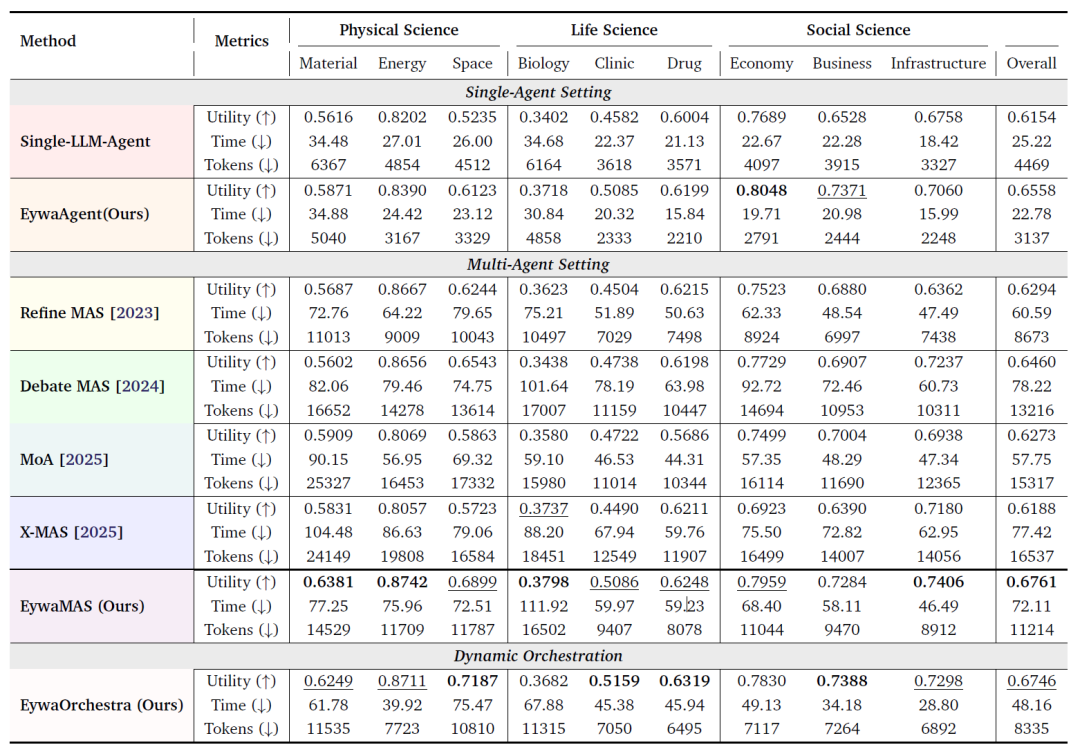
EywaBench 科学任务中的整体性能对比
备注:表格从三个维度对所有方法进行了比较:utility(↑ 越高越好),inference time(↓ 越低越好),token consumption(↓ 越低越好)。其中最优结果使用粗体标注,次优结果使用下划线标注。
首先,EywaAgent 在相同 backbone 条件下,同时提升了系统质量与效率。相较于对应的单智能体 LLM 基线,EywaAgent 的平均 utility 提升了 6.6%。与此同时,由于大量计算被委托给领域专用基础模型完成,其推理延迟明显下降,token 消耗也减少了接近 30%。
其次,EywaMAS 在科学场景下明显优于传统同构多智能体系统。实验显示,EywaMAS 获得了所有方法中最高的整体 utility。与 Refine 相比,EywaMAS 在性能上具有显著优势;而与 Debate 相比,EywaMAS 不仅 utility 更高,在相同 debate 拓扑下所需 token 数量反而更少。
第三个重要发现是:仅依靠「异构语言模型」并不足以解决科学任务。论文中的异构 LLM-only MAS 方法(例如 MoA 与 X-MAS)并未稳定超越强同构多智能体基线。这说明,对于科学任务而言,真正关键的并不是「多个不同 LLM 的组合」,而是「跨模态异构能力」的引入。换句话说,一个金融时间序列模型、一个生物预测模型,往往比再增加一个语言模型更有价值。
论文还指出,并非所有领域都能从更重型的多智能体协作中受益。在经济与商业等子领域中,单智能体 EywaAgent 已经具有极强竞争力。这意味着,复杂多智能体拓扑并不是始终最优的选择。在某些任务中,过度协作反而可能带来额外开销。
实验还表明,EywaOrchestra 在更低成本与更高自动化程度下,已经能够接近专家设计的 EywaMAS。与需要人工配置的 EywaMAS 不同,EywaOrchestra 完全由 conductor 自动构建系统结构。尽管如此,其 utility 已经接近人工设计系统,甚至在若干子领域中实现反超。同时,动态编排机制还显著降低了推理延迟与 token 消耗。这说明,任务自适应系统编排不仅能提升自动化水平,也能有效优化推理成本。
结语
过去几年,AI 行业的主线几乎始终围绕「大模型」展开——更大的参数量,更长的上下文,更强的推理能力,整个行业都在试图构建「一个能够解决所有问题的通用模型」。
但 Eywa 所代表的方向说明:「模态原生协作(modality-native collaboration)」能够有效增强多智能体系统在科学场景中的能力,并为未来异构基础模型协同推理提供了一条新的发展路径。换言之,未来真正重要的,并不是「一个万能 AI」,而是「一个能够组织异构专家协同工作的 AI 系统」。
参考文献:
https://arxiv.org/abs/2604.27351
https://hyper.ai/cn/papers/2604.27351

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献140条内容
已为社区贡献140条内容

所有评论(0)