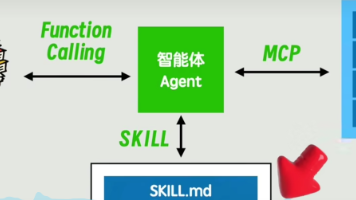
英伟达历代GPU产品的核心架构演进史
英伟达(NVIDIA)的GPU发展史是一部从专用图形处理到通用并行计算,再到如今主导人工智能计算的宏伟史诗。自1999年正式提出“GPU”概念以来,英伟达已推出了十余代核心架构,每一次迭代都深刻地影响了计算机图形学、高性能计算和人工智能的发展轨迹。从最初的图形加速器到如今驱动全球AI革命的计算引擎,英伟达GPU的演进史就是一部不断突破边界、重塑行业的创新史。: 打破图形与计算的边界,通过CUDA平
英伟达(NVIDIA)的GPU发展史是一部从专用图形处理到通用并行计算,再到如今主导人工智能计算的宏伟史诗。自1999年正式提出“GPU”概念以来,英伟达已推出了十余代核心架构,每一次迭代都深刻地影响了计算机图形学、高性能计算和人工智能的发展轨迹。
以下是英伟达历代GPU产品的核心架构演进史,可以将其划分为四个关键阶段:
第一阶段:图形处理时代 (1999-2005)
核心任务: 将图形计算从CPU中解放出来,实现硬件加速,并从固定功能管线迈向可编程渲染。
-
Celsius 架构 (1999年)
- 里程碑产品: GeForce 256 (NV10)
- 历史意义: 全球首款被正式定义为“GPU”的产品。它首次集成了硬件“变换与光照”(T&L)引擎,将原本由CPU承担的几何计算任务接管过来,彻底解放了CPU。
- 关键参数: 220nm制程,约1700-2300万晶体管,4条像素渲染管线(256-bit渲染引擎),支持AGP 4x。其多边形处理能力是当时CPU的5倍。
-
Kelvin 架构 (2001年)
- 里程碑产品: GeForce 3 (NV20)、GeForce 2 GTS
- 历史意义: 开启了GPU的“可编程渲染”时代。引入了可编程顶点着色器和像素着色器,使开发者能通过代码控制渲染流程,而非依赖固定的硬件功能。
- 关键参数: 150nm制程,约5700万晶体管。GeForce 3是全球首款支持DirectX 8.1的消费级GPU。
-
Rankine 架构 (2003年)
- 里程碑产品: GeForce FX 5系列 (NV3x),如FX 5100
- 历史意义: 将可编程渲染技术下沉至入门级市场,普及了DirectX 9.0a。尽管因硬件规格限制成为一款“过渡性”产品,但它为后续架构奠定了基础。
- 关键参数: 150nm/130nm制程,约4500万晶体管,支持顶点和片段程序。
-
Curie 架构 (2004年)
- 里程碑产品: GeForce 6系列 (NV4x),如6800 Ultra
- 历史意义: 全面支持DirectX 9.0c和Shader Model 3.0,实现了“全功能可编程”。同时引入了PureVideo硬件视频解码技术,减轻了CPU在高清视频播放上的负担。
- 关键参数: 130nm制程,约2.22亿晶体管,是当时性能的巅峰。
第二阶段:通用计算探索时代 (2006-2016)
核心任务: 打破图形与计算的边界,通过CUDA平台让GPU成为通用的并行计算引擎(GPGPU)。
-
Tesla 架构 (2006年)
- 里程碑产品: GeForce 8800 GTX (G80)
- 历史意义: 英伟达GPU发展史上的分水岭。它引入了统一渲染架构(Unified Shader Architecture),将顶点、像素、几何着色器合并为通用的流处理器(CUDA核心),解决了资源分配不均的问题。同年,CUDA平台发布,让开发者能用C语言在GPU上进行通用计算。
- 关键参数: 90nm制程,约6.81亿晶体管,支持DirectX 10。
-
Fermi 架构 (2010年)
- 里程碑产品: GeForce GTX 480 (GF100)
- 历史意义: 首个专为通用计算设计的架构,标志着GPU在高性能计算(HPC)领域的正式崛起。引入了L1/L2缓存层次结构、ECC内存纠错和GPUDirect技术。
- 关键参数: 40nm制程,约30亿晶体管,双精度浮点性能达1 TFLOPS,被用于“美洲豹”等超级计算机。
-
Kepler 架构 (2012年)
- 里程碑产品: GeForce GTX 680 (GK104)、Tesla K20/K40/K80
- 历史意义: 专注于提升能效比和并行计算效率。计算能力比Fermi提升3-4倍,使GPU成为科学计算和大数据分析的核心。
- 关键参数: 28nm制程,GK110核心拥有2880个CUDA核心,带宽高达288GB/s。
-
Maxwell 架构 (2014年)
- 里程碑产品: GeForce GTX 980 (GM204)、Tesla M40
- 历史意义: 实现了能效比的革命性突破,在相同功耗下性能是Kepler的两倍。优化了流式多处理器(SMM)设计,为后续架构奠定了基础。
- 关键参数: 28nm制程,GM204核心集成1920个CUDA核心。
-
Pascal 架构 (2016年)
- 里程碑产品: GeForce GTX 1080 (GP102)、Tesla P100
- 历史意义: 采用16nm FinFET工艺,能效比再次飞跃。首次引入NVLink技术,实现了GPU间的高速互联,并率先采用GDDR5X显存,为深度学习训练提供了强大硬件基础。
- 关键参数: GP100核心拥有3840个CUDA核心,显存带宽达732GB/s。
第三阶段:AI加速革命时代 (2017-2022)
核心任务: 专为AI和深度学习优化,引入Tensor Core和RT Core,引领AI算力爆炸式增长。
-
Volta 架构 (2017年)
- 里程碑产品: Tesla V100 (GV100)、Titan V
- 历史意义: AI计算的里程碑。首次引入Tensor Core(张量核心),专门加速深度学习的矩阵运算,使AI训练性能比Pascal提升12倍。
- 关键参数: 12nm制程,集成640个Tensor Core,提供125万亿次张量浮点运算能力(TFLOPS)。
-
Turing 架构 (2018年)
- 里程碑产品: GeForce RTX 2080 Ti (TU102)、Quadro RTX 6000
- 历史意义: 将实时光线追踪带入消费级市场。在Tensor Core基础上,新增了RT Core(光线追踪核心),实现了硬件加速的光线追踪计算。
- 关键参数: 12nm制程,RTX 2080 Ti集成了68个RT Core和576个Tensor Core。
-
Ampere 架构 (2020年)
- 里程碑产品: GeForce RTX 3090 (GA102)、Tesla A100
- 历史意义: AI与图形性能的全面跃升。第二代Tensor Core和RT Core性能大幅提升,A100成为大语言模型训练的“标配”。
- 关键参数: 三星8nm制程,A100拥有6912个CUDA核心和432个第三代Tensor Core,FP16算力达312 TFLOPS(开启稀疏性后达624 TFLOPS)。
第四阶段:生成式AI时代 (2024-至今)
核心任务: 为万亿参数级的大模型提供极致算力、海量显存和超高互联带宽。
-
Hopper 架构 (2022年)
- 里程碑产品: H100 / H800 (GH100)
- 历史意义: 为Transformer模型结构深度优化。第四代Tensor Core和NVLink 4.0的加入,使H100的FP16算力达到1 PFLOPS,成为当时的性能王者。
- 关键参数: 台积电4nm制程,集成800亿晶体管,H100 SXM版本拥有13TB/s的显存带宽。
-
Blackwell 架构 (2024年)
- 里程碑产品: B200 / GB200
- 历史意义: 集十年技术之大成,专为下一代生成式AI设计。通过创新的双芯设计(如GB200将两颗B200和一颗Grace CPU集成),在算力、显存容量和互联带宽上实现指数级增长。
- 关键参数: 采用定制化4nm工艺,B200拥有192GB HBM3e显存,带宽达8TB/s。GB200 NVL72集群的FP16算力高达180 PFLOPS,是前代H100集群的5.6倍。
历代GPU架构演进速览表
| 架构名称 | 发布年份 | 关键制程 | 里程碑产品 | 核心技术创新 | 历史地位 |
|---|---|---|---|---|---|
| Celsius | 1999 | 220nm | GeForce 256 | 硬件T&L,首次提出GPU概念 | 开启GPU时代 |
| Kelvin | 2001 | 150nm | GeForce 3 | 可编程顶点/像素着色器 | 迈向可编程渲染 |
| Rankine | 2003 | 150nm | GeForce FX 5 | DirectX 9.0a支持 | 普及可编程渲染 |
| Curie | 2004 | 130nm | GeForce 6 | Shader Model 3.0, PureVideo | 统一着色器架构前身 |
| Tesla | 2006 | 90nm | GeForce 8800 GTX | 统一渲染架构,CUDA平台 | GPGPU通用计算开端 |
| Fermi | 2010 | 40nm | GeForce GTX 480 | L1/L2缓存,ECC,专为计算设计 | 高性能计算崛起 |
| Kepler | 2012 | 28nm | GeForce GTX 680 | SMX架构,能效比大增 | 成为超算核心 |
| Maxwell | 2014 | 28nm | GeForce GTX 980 | 极致能效比 | 移动端与节能计算 |
| Pascal | 2016 | 16nm | GeForce GTX 1080 | FinFET,NVLink,GDDR5X | 深度学习硬件基础 |
| Volta | 2017 | 12nm | Tesla V100 | 第一代Tensor Core | AI加速革命起点 |
| Turing | 2018 | 12nm | GeForce RTX 2080 Ti | RT Core,实时光线追踪 | 图形技术新突破 |
| Ampere | 2020 | 8nm | GeForce RTX 3090, A100 | 第二/三代Tensor Core,MIG | 大模型训练标配 |
| Hopper | 2022 | 4nm | H100 | 第四代Tensor Core,Transformer引擎 | AI算力新王者 |
| Blackwell | 2024 | 4nm (定制) | B200, GB200 | 双芯设计,192GB HBM3e | 生成式AI新基石 |
从最初的图形加速器到如今驱动全球AI革命的计算引擎,英伟达GPU的演进史就是一部不断突破边界、重塑行业的创新史。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)