从 Residual 到 Hyper-Connections:再到 mHC——用可控的连乘解决可扩展训练的数值稳定性
本文探讨了大语言模型训练中的稳定性优化方法,从Residual、Dense到HC连接方式的演进,重点分析了mHC(Manifold-Constrained Hyper-Connections)的创新设计。mHC通过将连接矩阵约束到双随机流形,解决了HC在深层网络中易出现的梯度爆炸/坍缩问题。具体采用Sinkhorn-Knopp算法将矩阵投影为近似双随机形式,既保留了可学习性,又确保了连乘稳定性,使
面向大语言模型(多模态/长上下文/超深网络)训练时,稳定可扩展往往比单点精度提升更为关键:一旦训练在万亿 token / 超大 batch / 多机并行下出现梯度爆炸或坍缩,所有工程投入都会被瞬间清零。本文沿着 Residual → Dense → HC → mHC 的脉络,解释 mHC 的直觉、算法与工程落地。
1. Residual connection:为什么它几乎统治了深度网络?
1.1 基本形式与核心性质
最经典的残差连接写成:
y=x+f(x) \mathbf{y} = \mathbf{x} + f(\mathbf{x}) y=x+f(x)
其中 x\mathbf{x}x 是输入特征,F(⋅)F(\cdot)F(⋅) 是一个“残差分支”。
它的关键不只是“相加”,而是把网络变成“在恒等映射 III 附近做小修小补”,从而显著缓解深层网络训练困难。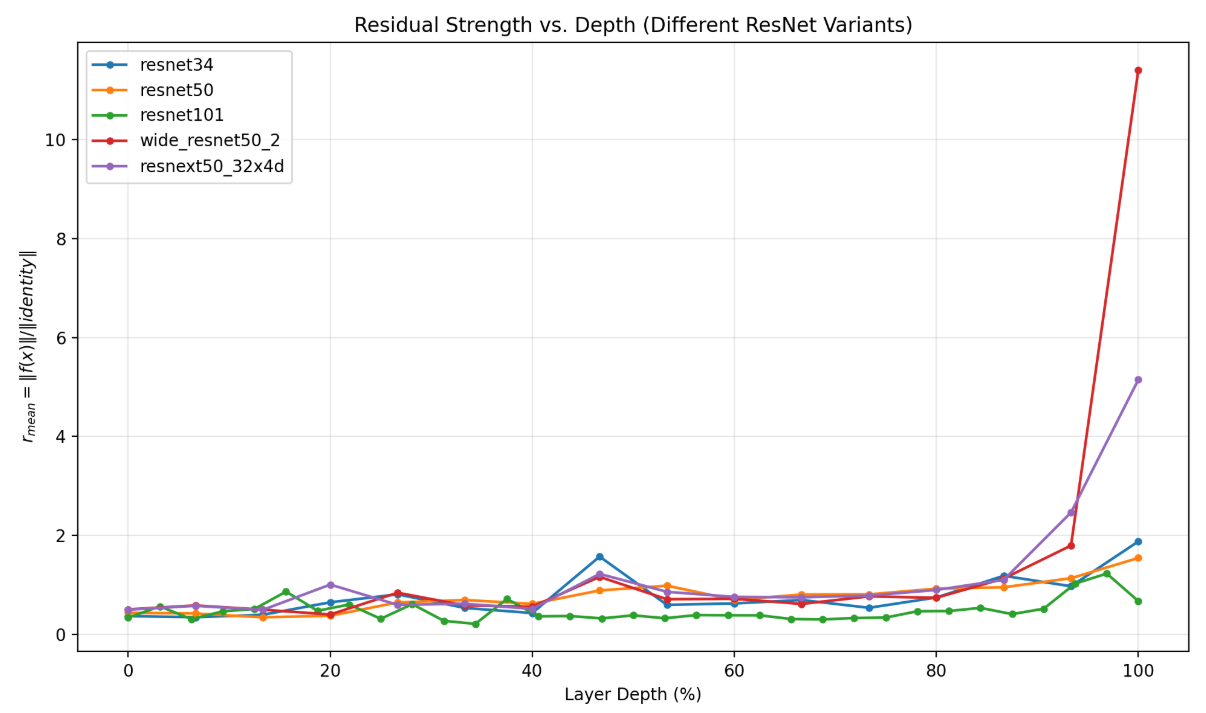
该图对比了不同 ResNet 变体在网络深度上的残差强度变化:横轴为残差块深度百分比(0–100%),纵轴为
rmean=∥f(x)∥/∥identity∥r_{\text{mean}}=\|f(x)\|/\|\text{identity}\| rmean=∥f(x)∥/∥identity∥用于衡量残差分支相对 identityidentityidentity 分支的幅度大小。
整体趋势上,多数模型在 0–90% 深度区间内的 rmeanr_{\text{mean}}rmean 主要分布在 约 0.3–1.0,说明残差项通常与 identityidentityidentity 同量级或略小。在 中段(约 40–55%),部分模型(如 resnet34)出现局部峰值,提示某些 stage 的残差更新更强。
最显著差异出现在 网络末端(接近 100%):wide_resnet50_2 与 resnext50_32x4d 的 rmeanr_{\text{mean}}rmean出现明显陡增(远大于 1),而 resnet50/resnet34 仅温和上升、resnet101 相对更低,表明不同架构在深层是否由残差主导存在明显区别。
1.2 图像领域:ResNet 系列把“可训练深度”推上一个台阶
在视觉里,残差连接最标志性的成功是 ResNet:它把网络深度推到 100+ 层仍然可稳定优化,并成为后续检测/分割/生成等任务的基础积木。
1.3 NLP 领域:Transformer 里“残差 + 归一化”是默认配置
在 Transformer 中,每个子层(自注意力、FFN)外面都包着残差连接,并配合 LayerNorm(原始论文是“Post-LN”写法:先加残差再 LN)。这套组合是训练深层序列模型的关键结构之一。
思考:Residual 的连接强度基本是预先固定的
残差的加法通道很像一条“高速公路”,但它默认只允许本层输入 x\mathbf{x}x与本层变换 F(x)F(\mathbf{x})F(x)做简单融合;当网络更深、更宽、更复杂时,一个自然的问题是:
能不能让网络学会“跨层/跨分支”更丰富的连接方式,而不是只靠固定的与输入做加法?
2. Dense connection:把“跨层信息流”做得更激进
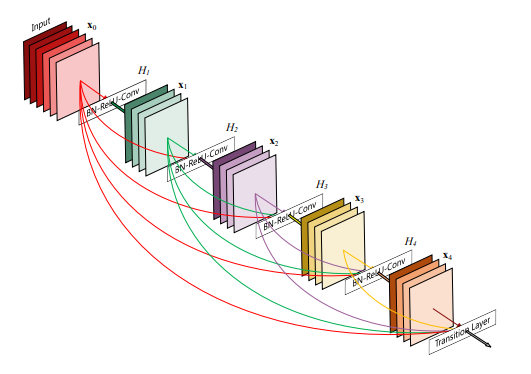
2.1 DenseNet 的连接形式
Dense connection(DenseNet)把同一块内的每一层都连到后续所有层,典型写法是:
xℓ=Hℓ([x0,x1,…,xℓ−1]) \mathbf{x}_\ell = H_\ell([\mathbf{x}_0,\mathbf{x}_1,\dots,\mathbf{x}_{\ell-1}]) xℓ=Hℓ([x0,x1,…,xℓ−1])
这里 [⋅][\cdot][⋅] 是 **拼接(concatenation)**或者add(⋅)add(\cdot)add(⋅),Hℓ(⋅)H_\ell(\cdot)Hℓ(⋅) 是本层变换。DenseNet 强调:更短的梯度路径、更强的特征复用、更好的特征传播。
2.2 图像领域:Dense connection 的典型收益
DenseNet 论文总结的优点包括:
- 缓解梯度消失:dense-connection相当于每一层都直接连接input和loss,因此就可以减轻梯度消失现象,这样更深网络不是问题。
- 加强特征传播:由于密集连接方式,DenseNet提升了梯度的反向传播,使得网络更容易训练。
- 降低参数量:论文中设计了一种类似于深度可分离卷积层,用于降低conv2d的参数量,这里就不过多展开了。
2.3 NLP 领域:Dense 思想更多体现为“跨层特征融合”,主干仍以 residual 为主
相较视觉,NLP 主干架构(Transformer)仍以 residual 为主流;但 DenseNet 的“跨层特征聚合/复用”思想,常以各种 跨层融合 的形式出现(例如把多层隐藏状态拼接/加权用于下游头部),本质上是在“信息流”层面借鉴 Dense。
(这点在工程上很常见,但不同论文实现差异很大,本文不展开具体谱系。)
思考:Dense 连接模式仍然是固定拓扑(预定义谁连谁)
Residual 是“本层短路”,Dense 是“全连式跨层复用”。它们共同点是:连接拓扑/强度都高度结构化且偏固定。
于是下一步就很自然:让连接强度变成可学习的,并且允许网络在“深度流 + 宽度流”上自适应混合——这正是 HC(Hyper-Connections) 的切入点。
3. HC(Hyper-Connections):把 residual 流“扩宽”,并让连接矩阵可学习
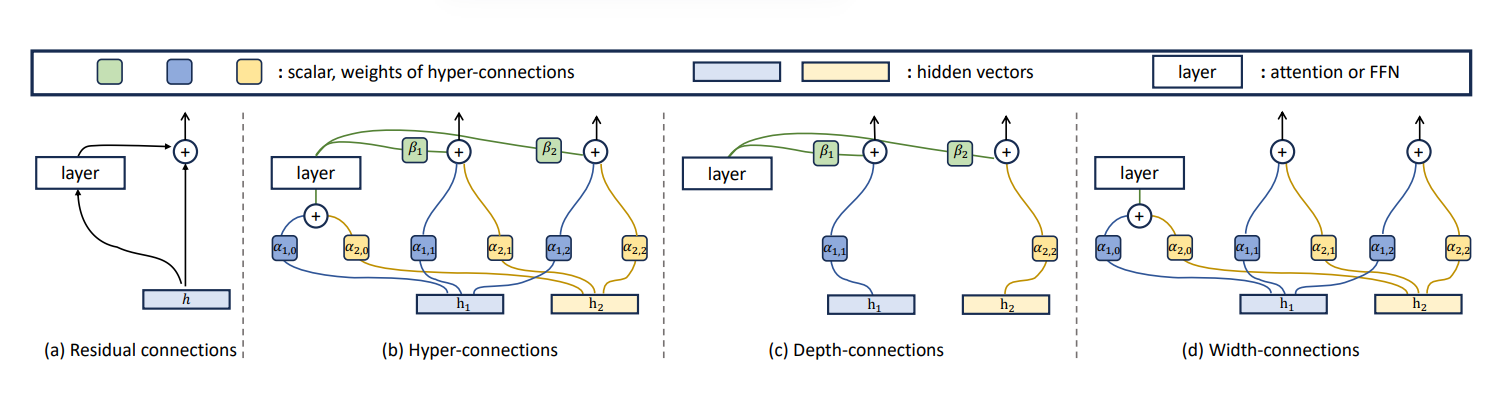
HC 的核心动机是:Residual在“梯度消失 vs 表示坍缩”之间存在权衡(论文称 seesaw trade-off),而根因之一是残差通道的连接强度被预先固定。HC 试图让网络学习连接强度,甚至学习“更像串行还是更像并行”的层组织方式。
3.1 一个直观视角:把“残差”从标量权重推广到“矩阵混合”
你可以把 HC 想象成:
- 不再只有一条 residual stream,而是把 residual stream 扩展成多个并行的“超隐藏向量”;
- 用一个(可学习)矩阵,在这些超隐藏向量之间做混合(width-connections),同时也学习跨深度的连接强度(depth-connections)。
3.2 通过伪代码来更深入的理解HYPER-CONNECTIONS

3.3 具体实现可以参考下面的代码
import torch
from torch import nn
import torch.nn.functional as F
from torch.nn import LayerNorm
# h: hyper hidden matrix (BxLxNxD)
class HyperConnection(nn.Module):
def __init__(self, dim, rate, layer_id, dynamic, device=None):
super(HyperConnection, self).__init__()
self.rate = rate
self.layer_id = layer_id
self.dynamic = dynamic
self.static_beta = nn.Parameter(torch.ones((rate,), device=device))
init_alpha0 = torch.zeros((rate, 1), device=device)
init_alpha0[layer_id % rate, 0] = 1.
self.static_alpha = nn.Parameter(torch.cat([init_alpha0, torch.eye((rate), device=
device)], dim=1))
if self.dynamic:
self.dynamic_alpha_fn = nn.Parameter(torch.zeros((dim, rate+1), device=device))
self.dynamic_alpha_scale = nn.Parameter(torch.ones(1, device=device) * 0.01)
self.dynamic_beta_fn = nn.Parameter(torch.zeros((dim, ), device=device))
self.dynamic_beta_scale = nn.Parameter(torch.ones(1, device=device) * 0.01)
self.layer_norm = LayerNorm(dim)
def width_connection(self, h):
# get alpha and beta
if self.dynamic:
norm_h = self.layer_norm(h)
if self.dynamic:
wc_weight = norm_h @ self.dynamic_alpha_fn
wc_weight = F.tanh(wc_weight)
dynamic_alpha = wc_weight * self.dynamic_alpha_scale
alpha = dynamic_alpha + self.static_alpha[None, None, ...]
else:
alpha = self.static_alpha[None, None, ...]
if self.dynamic:
dc_weight = norm_h @ self.dynamic_beta_fn
dc_weight = F.tanh(dc_weight)
dynamic_beta = dc_weight * self.dynamic_beta_scale
beta = dynamic_beta + self.static_beta[None, None, ...]
else:
beta = self.static_beta[None, None, ...]
# width connection
mix_h = alpha.transpose(-1, -2) @ h
return mix_h, beta
def depth_connection(self, mix_h, h_o, beta):
h = torch.einsum("blh,bln->blnh", h_o, beta) + mix_h[..., 1:, :]
return h
HC 的结果是:在保持额外参数与算力开销相对可控的情况下,带来显著的训练收敛与任务性能收益,并且在 NLP 预训练与部分视觉任务上均有验证。
思考:HC引入了一个“残差从加法变成连乘/混合”的新风险
一旦你把“残差通道的融合”从简单加法,升级为跨层的矩阵混合,那么跨很多层之后,等价变换往往会出现 矩阵连乘。而连乘最怕的就是:
- 稍微大一点就指数爆炸;
- 稍微小一点就指数衰减到 0。
这就是 mHC 专门要解决的核心问题。
4. mHC:把 HC 的连接矩阵“约束到一个流形”,恢复 residual 的恒等映射稳定性
mHC(Manifold-Constrained Hyper-Connections)明确指出:HC 的多样化连接 会破坏 residual connection 的 identity mapping property,从而导致严重训练不稳定与可扩展性受限;此外还会带来额外的系统开销。
4.1 存在的问题:不受约束的“复合映射”偏离恒等,导致爆炸/坍缩
mHC 在“Numerical Instability”里把问题说得很直接:
当 HC 跨多层展开时,残差流中从第 (\ell) 层到第 (L) 层的有效信号传播由某个 复合映射(composite mapping) 控制;由于该映射是可学习但无约束的,它“不可避免地”偏离恒等映射,导致前向与反传中的信号幅值出现 explosion 或 vanishing,从而破坏 residual learning 依赖的顺畅信号流,训练在更深/更大规模时变得不稳定。
4.2 直观的解决方案:让连乘里的矩阵“更接近单位矩阵”以避免爆炸/坍缩
把本质抽象出来,其实就是控制一个连乘:
Meff=ALAL−1⋯A1\mathbf{M}_{\text{eff}} = \mathbf{A}_L \mathbf{A}_{L-1}\cdots \mathbf{A}_1Meff=ALAL−1⋯A1
如果每个 Ai\mathbf{A}_iAi 的“增益”略大于 1,∥Meff∥\|\mathbf{M}_{\text{eff}}\|∥Meff∥ 会指数爆炸;略小于 1 就会指数坍缩。
Residual connection 之所以稳定,很大原因在于它隐含地把“主通道”固定在 单位矩阵III 附近(信息可以不被放大/衰减地穿过很多层)。
因此一个非常朴素但强力的方向是:
把 HC 里参与连乘的那些映射,显式地约束到某种“接近恒等、增益可控”的集合上,让 Meff\mathbf{M}_{\text{eff}}Meff 长链路也不会离谱。
mHC 的选择是:把映射投影到一个特定流形(论文用 doubly stochastic / Birkhoff polytope 相关结构来实现),以恢复恒等映射的属性。
补充:Aℓ\mathbf{A}_\ellAℓ 要具备“接近恒等、增益可控”,通常需要同时满足两类条件
条件1:严格恒正 + 远离 0 的下界,用于避免符号抵消并提升数值鲁棒性
直观上,如果 Aℓ\mathbf{A}_\ellAℓ 中存在大量负值或符号混杂,跨层复合时可能出现“正负抵消”,使某些方向的有效增益异常变小,诱发不稳定。
因此我们希望 Aℓ\mathbf{A}_\ellAℓ 满足严格恒正:
(Aℓ)ij>0(\mathbf{A}_\ell)_{ij} > 0(Aℓ)ij>0
并且最好进一步满足一个“远离 0 的下界”(避免通道被压得过小而近似断路):
(Aℓ)ij≥ϵ, ϵ>0(\mathbf{A}_\ell)_{ij} \ge \epsilon,\ \ \epsilon>0(Aℓ)ij≥ϵ, ϵ>0
需要强调的是:仅“恒正”并不能单独保证连乘后不会坍缩到接近 0(例如各层整体缩放因子都小于 1 时仍会指数衰减),它更多是从“避免抵消/断路”的角度提升鲁棒性;真正抑制爆炸/坍缩还要依赖下面的增益约束。
条件2:范数/谱性质与单位矩阵相似,使得单层近似“单位增益”,从而连乘不爆炸不坍缩
“增益可控”的核心是限制 Aℓ\mathbf{A}_\ellAℓ 的放大与压缩能力。一个常用的表述是让其在某种诱导范数意义下接近单位增益:
∥Aℓ∥2≈1且∥Aℓ−1∥2≈1\|\mathbf{A}_\ell\|_{2} \approx 1 \quad \text{且} \quad \|\mathbf{A}_\ell^{-1}\|_{2} \approx 1∥Aℓ∥2≈1且∥Aℓ−1∥2≈1
等价地,也可以用奇异值来表达“既不放大也不压缩”:
σmax(Aℓ)≈1,σmin(Aℓ)≈1\sigma_{\max}(\mathbf{A}_\ell)\approx 1,\quad \sigma_{\min}(\mathbf{A}_\ell)\approx 1σmax(Aℓ)≈1,σmin(Aℓ)≈1
在更工程化的描述里,也常用 111 范数与 ∞\infty∞ 范数来刻画上界约束(尤其当 Aℓ\mathbf{A}_\ellAℓ 被约束到 doubly stochastic 流形时):
∥Aℓ∥1≈∥I∥1,∥Aℓ∥∞≈∥I∥∞\|\mathbf{A}_\ell\|_{1}\approx \|\mathbf{I}\|_{1},\quad \|\mathbf{A}_\ell\|_{\infty}\approx \|\mathbf{I}\|_{\infty}∥Aℓ∥1≈∥I∥1,∥Aℓ∥∞≈∥I∥∞
总结来说:
- 恒正/有下界主要抑制“符号抵消”和“通道断路”;
- 范数/谱性质受控才是抑制“指数爆炸/指数坍缩”的关键。
mHC 通过将映射投影到 doubly stochastic / Birkhoff polytope 相关结构上,在结构层面为“增益可控”提供了强先验,从而让长链路连乘更稳定。
4.3 Sinkhorn–Knopp 如何解决上面的问题:把矩阵投影成(近似)双随机矩阵
(1) 目标:投影到“双随机矩阵”(doubly stochastic matrices)
双随机矩阵的定义:元素非负,且每行和每列合都为 1。其集合对应著名的 Birkhoff polytope。
(2) Sinkhorn–Knopp:交替行归一化与列归一化
mHC 在“Parameterization and Manifold Projection”里给出的过程是:
先通过指数/正值化让矩阵元素为正,然后做迭代的行、列归一化(交替把行和列缩放到和为 1),并指出该过程会收敛到双随机矩阵;论文也给出实验中选择的迭代次数 (K)。这一思想与经典的 Sinkhorn–Knopp 结果一致:对满足条件的非负矩阵,交替缩放行列可收敛到双随机极限。
(3) 为什么“双随机”对连乘友好?
一个非常关键、且足够“工程友好”的性质是:
双随机矩阵在普通矩阵乘法下构成半群(对乘法封闭)——也就是说若 A,B\mathbf{A},\mathbf{B}A,B 都是双随机,则 AB\mathbf{A}\mathbf{B}AB 仍是双随机。
直觉上,这意味着你把每层的 residual-stream 混合映射都限制在这个集合里,跨层复合后仍不会“跑出边界”,从而显著降低长链路连乘导致的爆炸/坍缩风险(至少在“守恒/归一化”意义上是受控的)。
4.4 工程上如何优化:对应论文 Efficient Infrastructure Design 的关键点
mHC 不是只停留在“数学上更稳”,它专门写了一节 Efficient Infrastructure Design 来压训练开销,并给出“在大规模模型上训练开销仅约 6.7%”的实现结论。
下面按论文结构提炼:
4.4.1 Kernel Fusion:把零散操作合并,降低内存带宽与 launch 开销
论文观察到 mHC 中的 RMSNorm 在高维 hidden state 上会带来显著延迟,于是把“除以范数”的操作重排到矩阵乘之后,并保持数学等价;同时采用混合精度、把共享内存访问的多个算子融合成统一 kernel,以减轻内存带宽瓶颈。
4.4.2 Sinkhorn–Knopp iteration 的单 kernel 化 + 定制 backward
最关键的工程点之一:
mHC 把 Sinkhorn–Knopp 迭代 直接放进单个 kernel 里实现;并且为 backward 推导并实现了定制反向 kernel,通过 on-chip 重计算中间结果并遍历整个迭代,避免把每次迭代的中间态都落到显存,显著减少带宽与存储开销。
4.4.3 Recomputing / 通信重叠(DualPipe)
该部分的核心思想是:用“重计算换显存/带宽”,以及在并行训练中尽量让通信与计算重叠(论文标题明确点名 “Overlapping Communication in DualPipe”)。
结语:mHC 给医疗大模型训练的启发
如果你在做医疗大模型(尤其是多模态、3D 影像、超长序列、超深网络),mHC 这一脉络最值得带走的不是某个 trick,而是一个更一般的设计范式:
- 把“连接拓扑/连接强度”当作可学习对象(HC);
- 但必须同步考虑:长链路复合映射的数值稳定性(mHC 的核心矛盾);
- 用“可证明/可解释的结构约束”(例如双随机流形 + SK 投影)去恢复 residual 的稳定属性;
- 最后用 kernel fusion / 重计算 / 通信重叠 把理论方案变成“可大规模训练的基础设施”。
参考阅读
- ResNet:Deep Residual Learning for Image Recognition
- DenseNet:Densely Connected Convolutional Networks
- Transformer:Attention Is All You Need
- HC:Hyper-Connections(https://arxiv.org/pdf/2409.19606)
- mHC:mHC: Manifold-Constrained Hyper-Connections()
- Sinkhorn–Knopp 原始工作:Concerning nonnegative matrices and doubly stochastic matrices
- 双随机矩阵乘法封闭性(半群):The semigroup of doubly-stochastic matrices :contentReference
笔者邮箱:yikunhuang1995@163.com
有不正确的地方希望您批评指正。
希望天下没有难学的算法

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)