ComfyUI基础学习笔记
本文记录AI图形界面工具ComfyUI如何使用,供大家学习参考。写的很基础。
本文记录AI图形界面工具ComfyUI如何使用,供大家学习参考。写的很基础。
ComfyUI是一个AI图形界面工具,是基于节点工作流的图形用户界面。
ComfyUI通过添加节点、连接节点等操作构建的模型工作流来绘制图像。
个人觉得学习ComfyUI要多练习,操作多了就熟练了,由简单的工作流到复杂的工作流逐步进阶。
同时,ComfyUI即拿来主义,复杂的工作流实在不会可以拿别人的来使用。
还可以在别人的工作流基础上进行修改。
目录
(5)GGUF (GPT-Generated Unified Format)
一、ComfyUI安装使用
ComfyUI可以在线下使用,也可以在线上使用。这根据个人需要。
(一)线下安装
线下安装需要一台有独立显卡配置的电脑,官方推荐的是使用显存为6G及以上的英伟达显卡。
ComfyUI安装包推荐使用秋叶整合包。
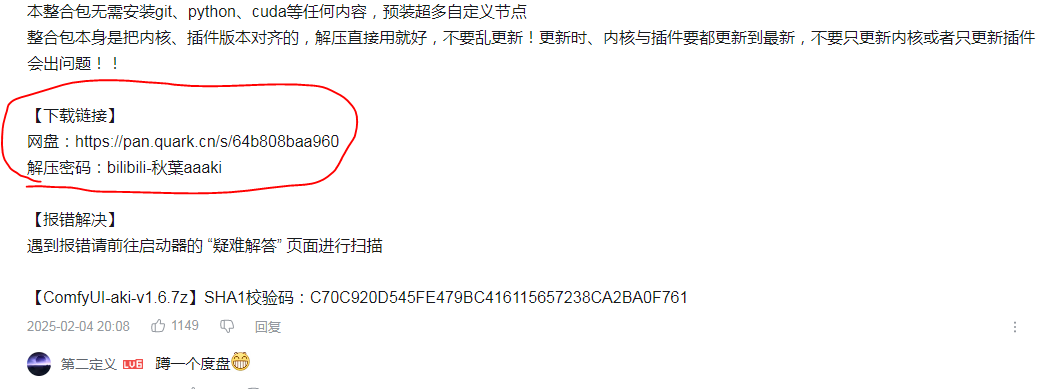
在评论区有个下载链接,点击下载后进行解压,解压后打开运行程序。
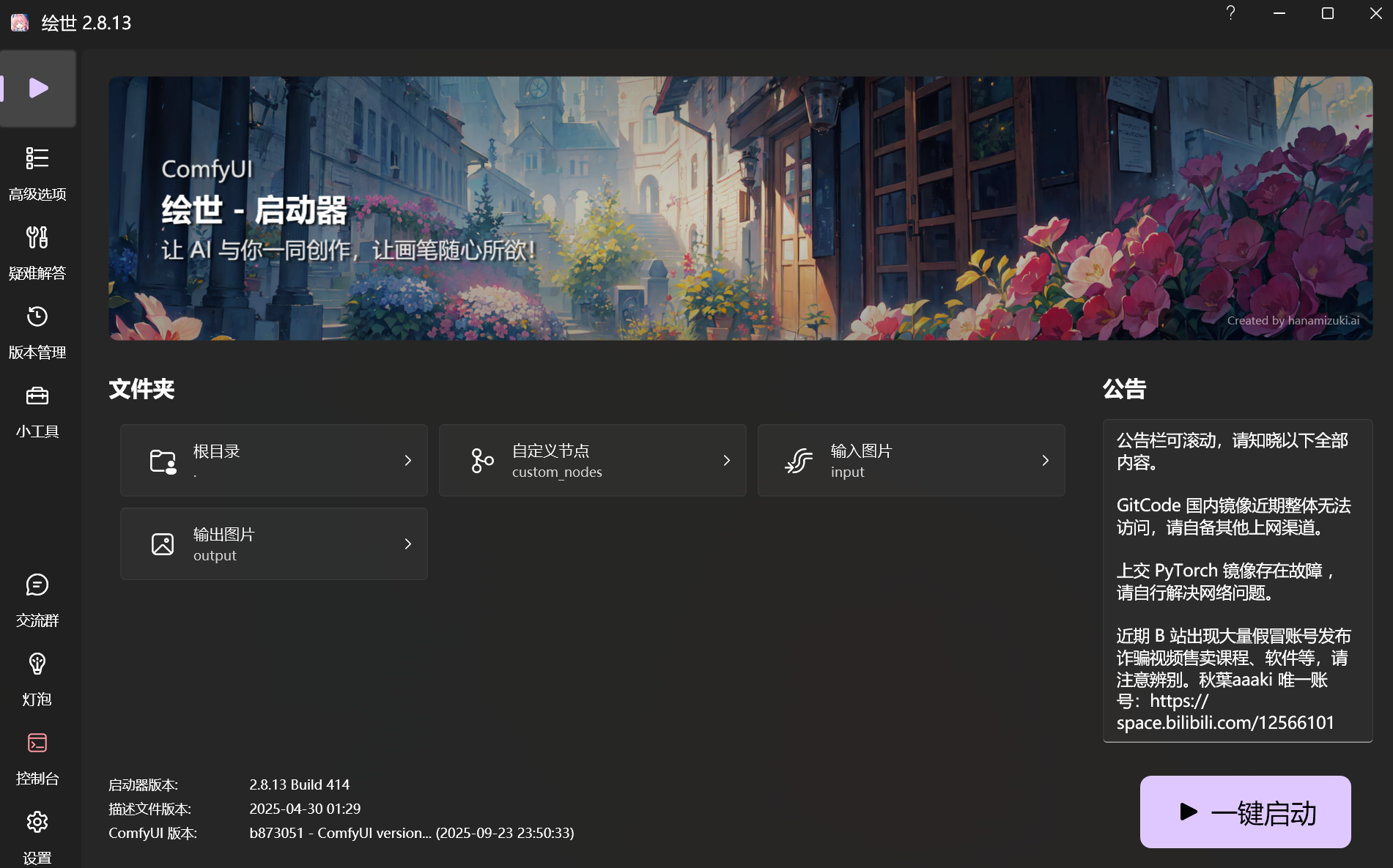
点击一键启动即可使用。
(二)线上使用
如果你的电脑配置不行,可以考虑使用线上的ComfyUI。
线上的ComfyUI推荐两个平台:
1、LiblibAI-哩布哩布AI
https://www.liblib.art/viphome?referralCode=V8aggkw4
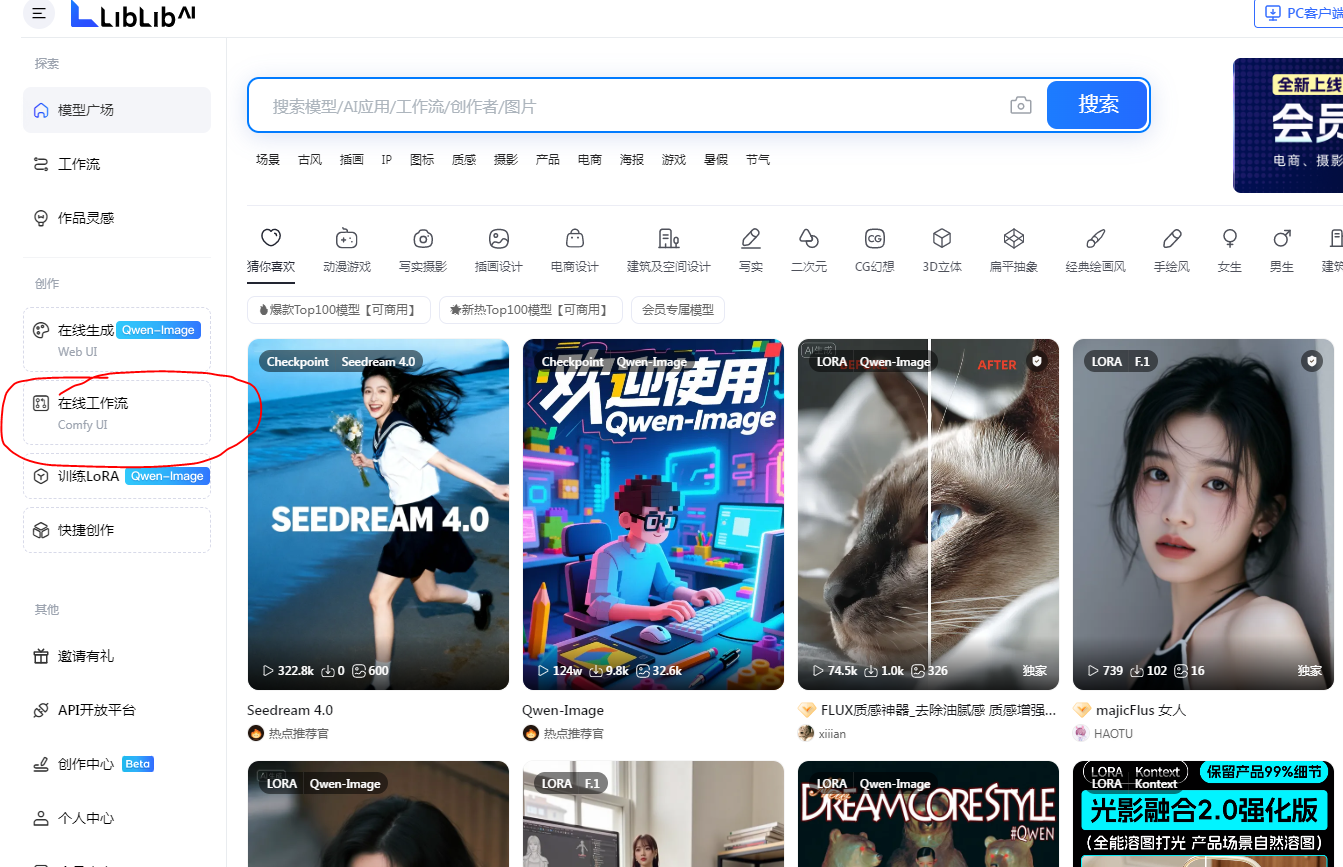
点击注册之后在左手边有个在线工作流,点击进入后即可使用。
2、RunningHub
https://www.runninghub.cn/?inviteCode=58f1cc35
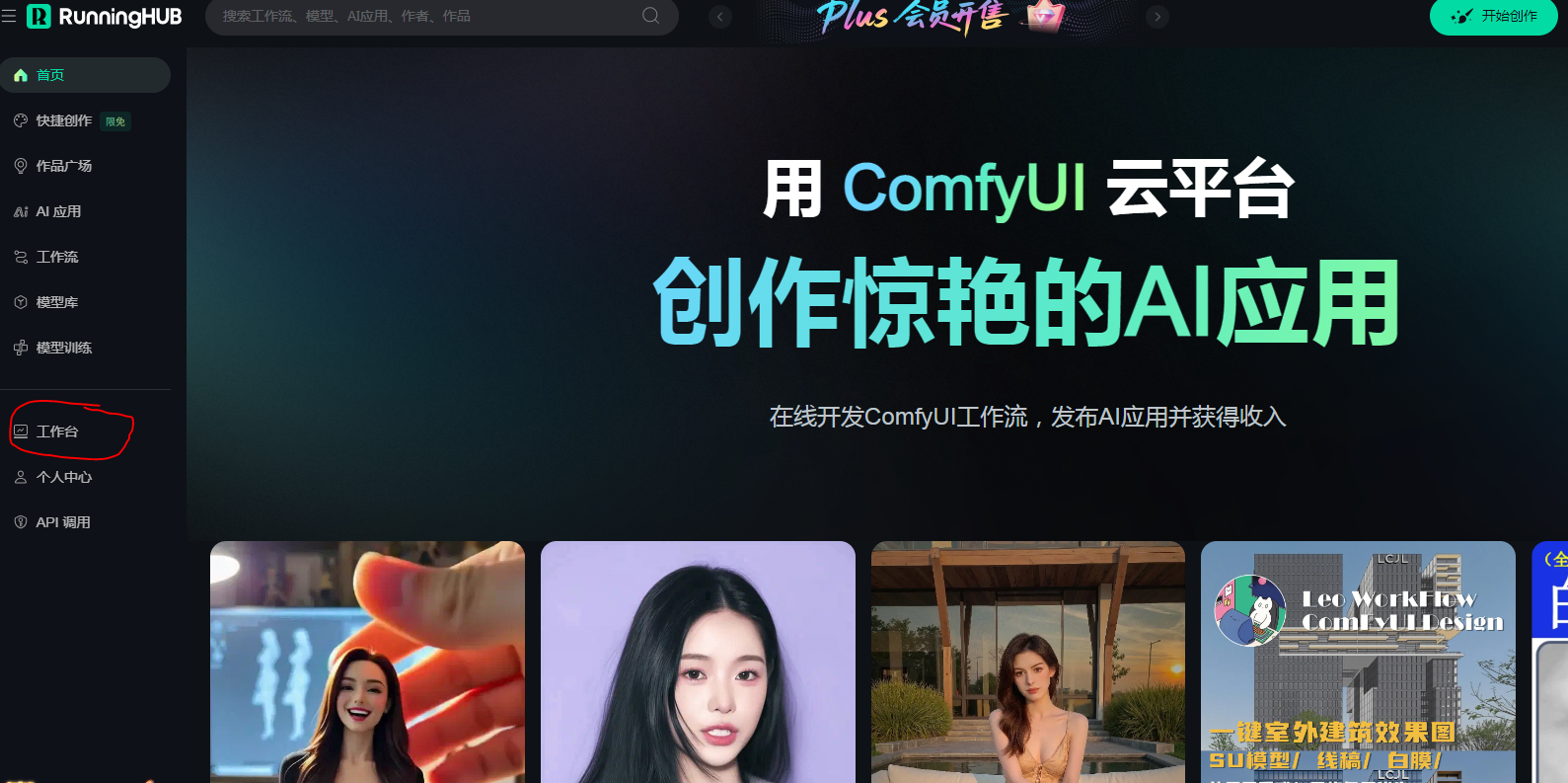
点击注册之后在左手边有个工作台。
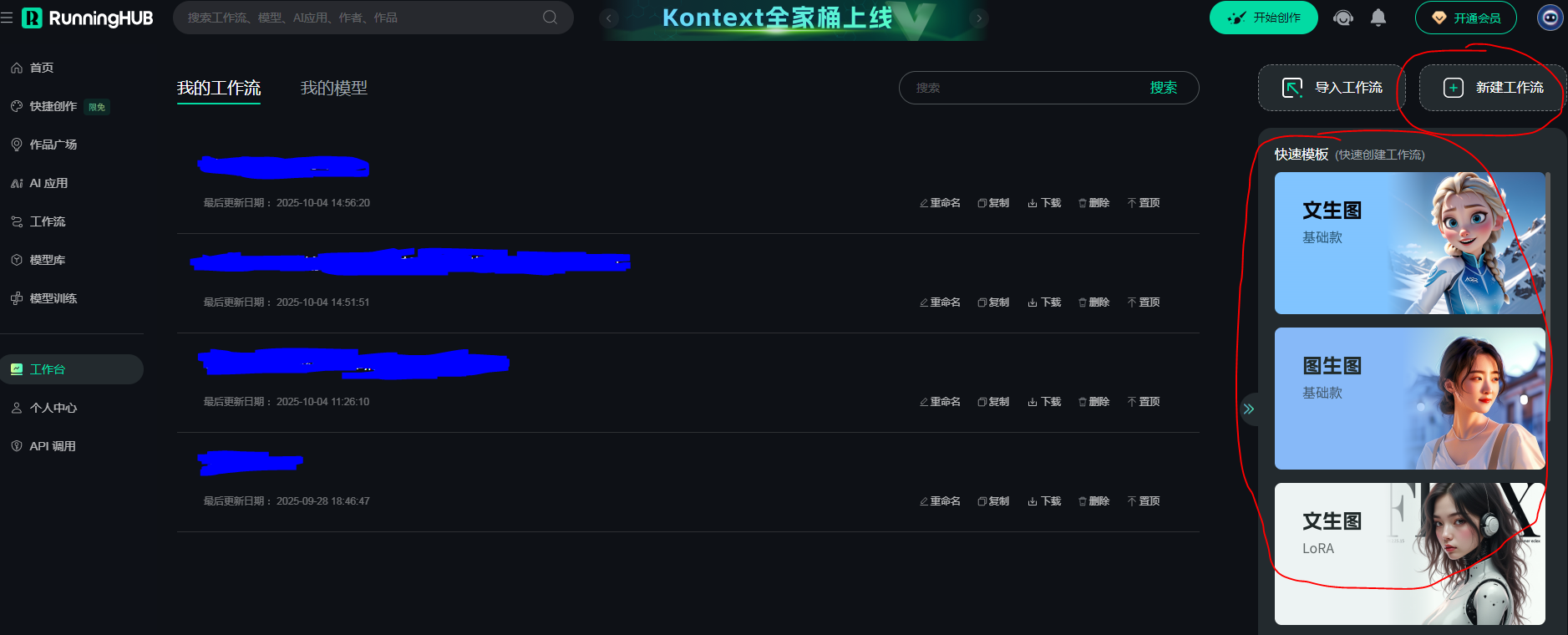
点击进入后在右边有个新建工作流、快速模板,点击进入后即可使用。
二、ComfyUI基本使用操作
这里以线下安装秋叶整合包为例,一键启动进入ComfyUI界面之后,对ComfyUI基本使用操作进行介绍:
(一)界面介绍
进入ComfyUI界面之后,是如图所示的界面:
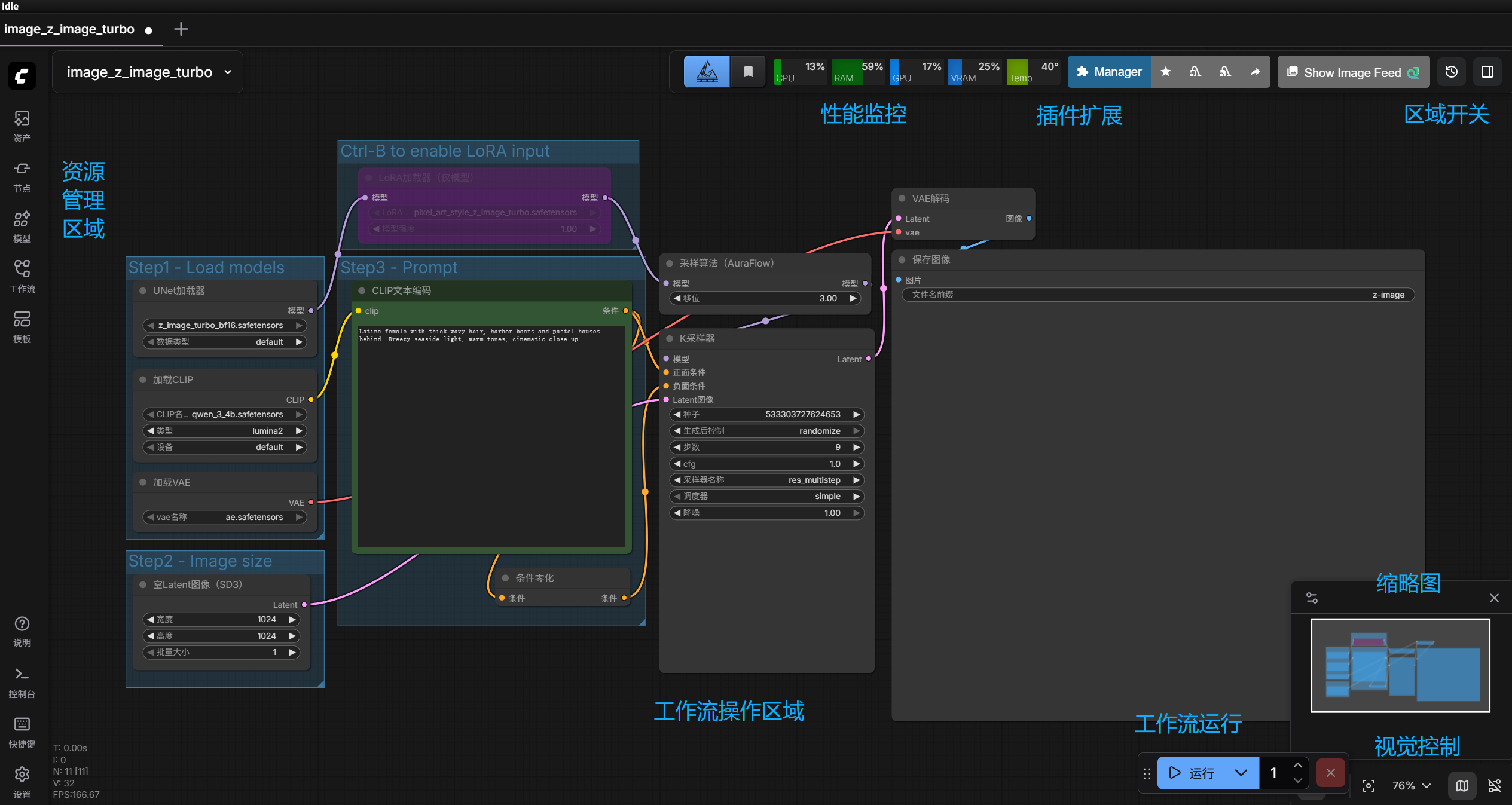
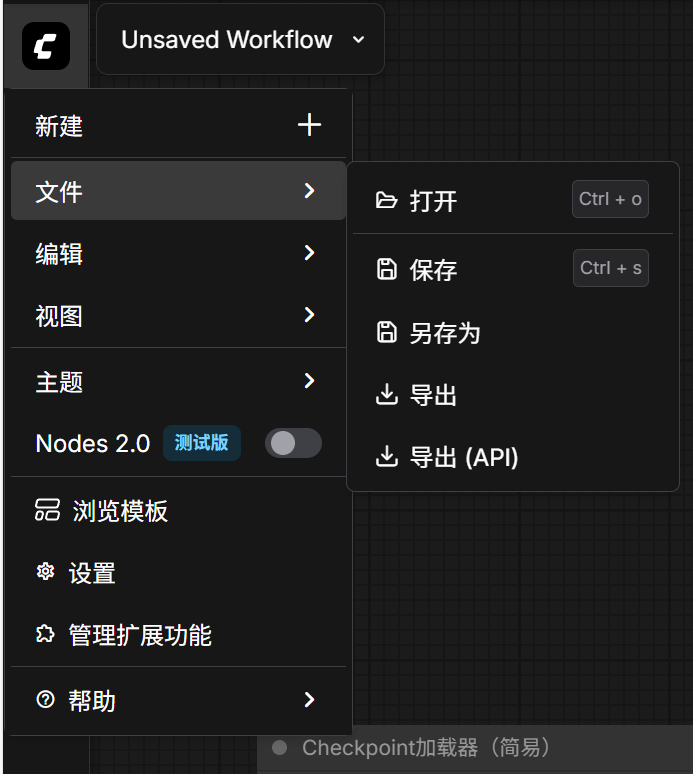
界面左上角有新建、保存、导出、打开工作流,编辑撤销重做,视图等按钮。
然后节点库里可以搜索浏览工作流节点。
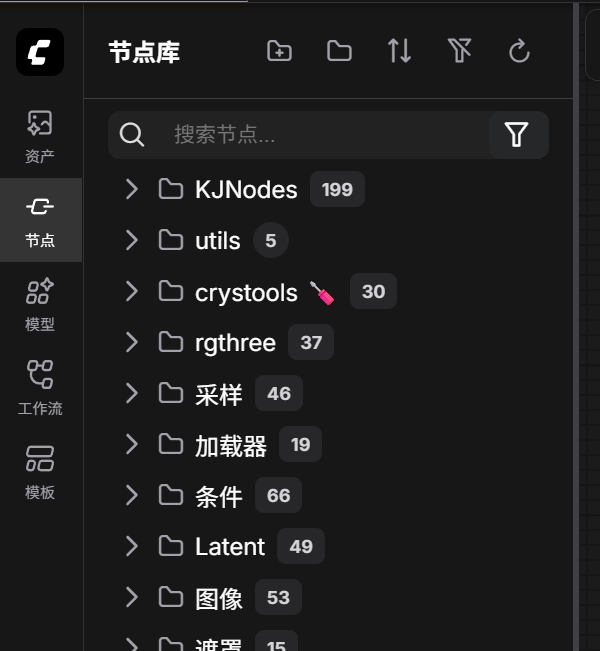
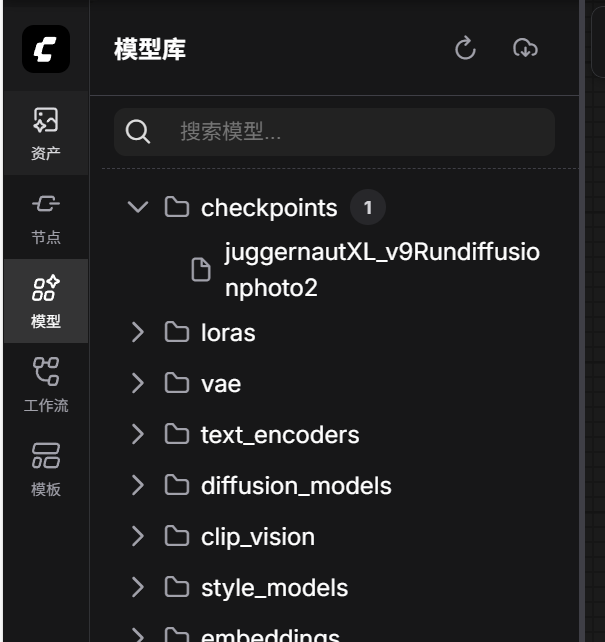
模型库查看你下载好的模型。
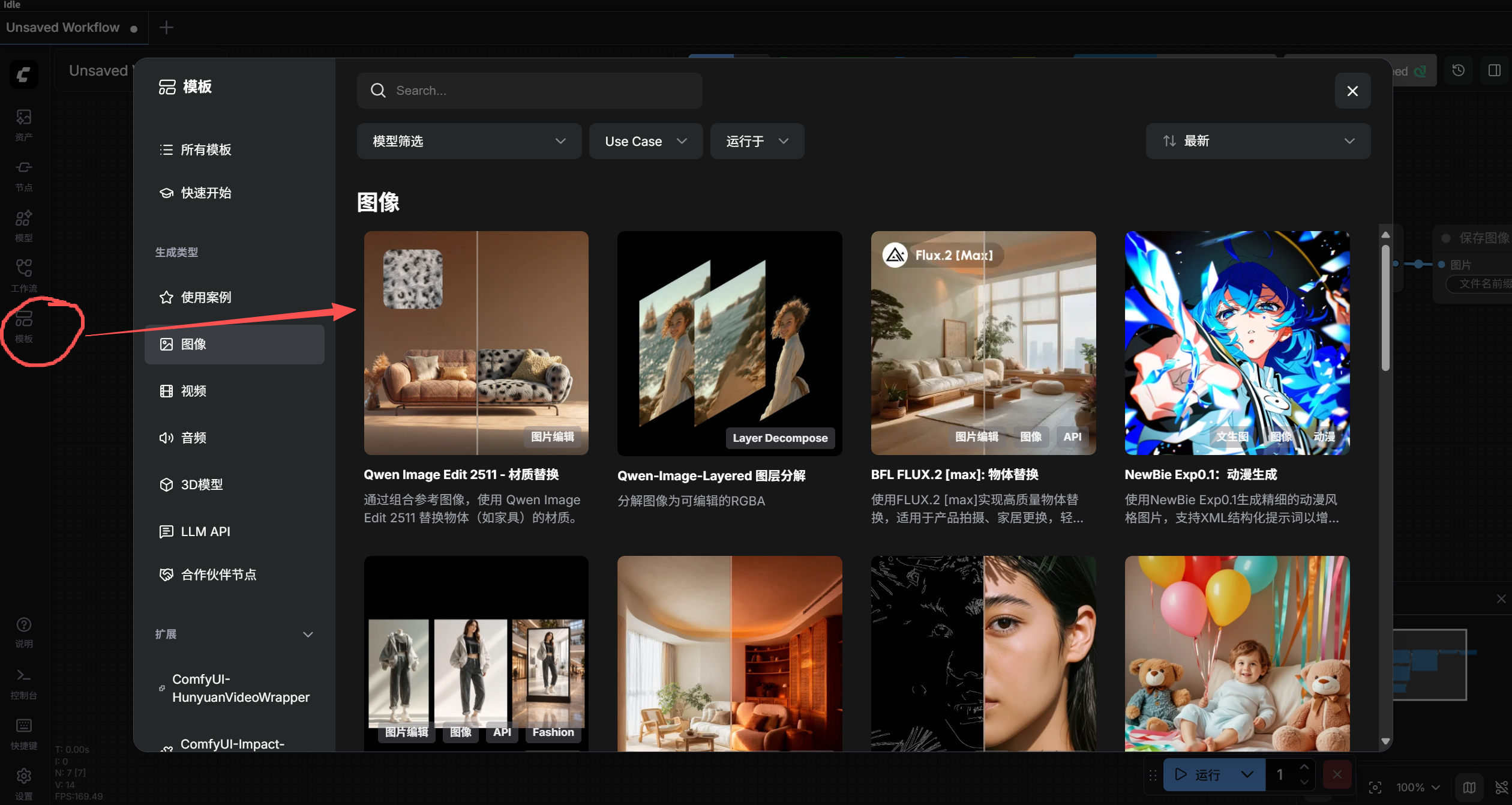
模板里内置了一些基本的工作流,很适合小白新人,直接使用模板,或在模板的基础上改改。
(二)节点操作
常用的节点操作有:
1、添加节点
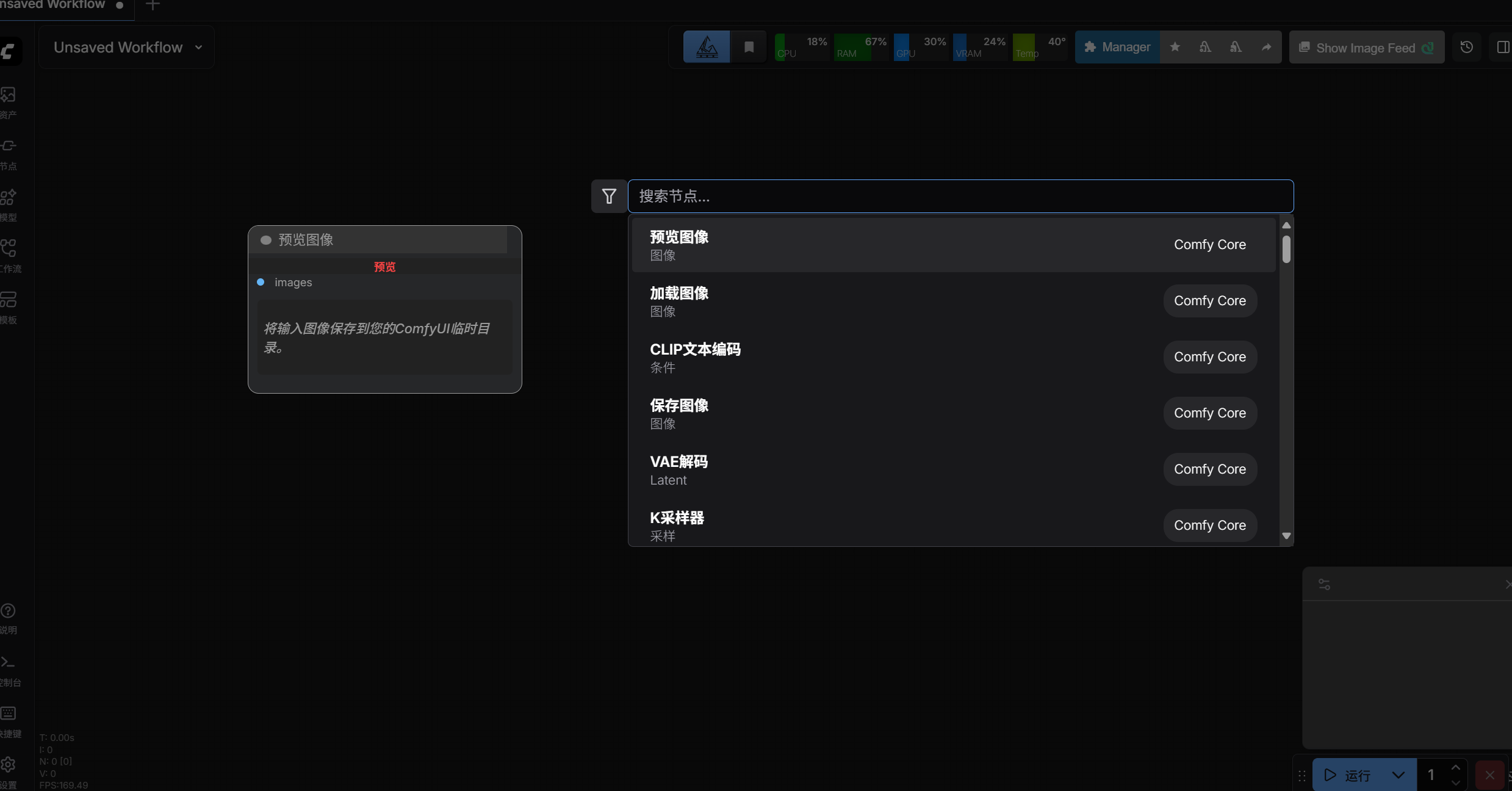
在空白处鼠标双击,就显示节点框,输入想要添加的节点点击即可。
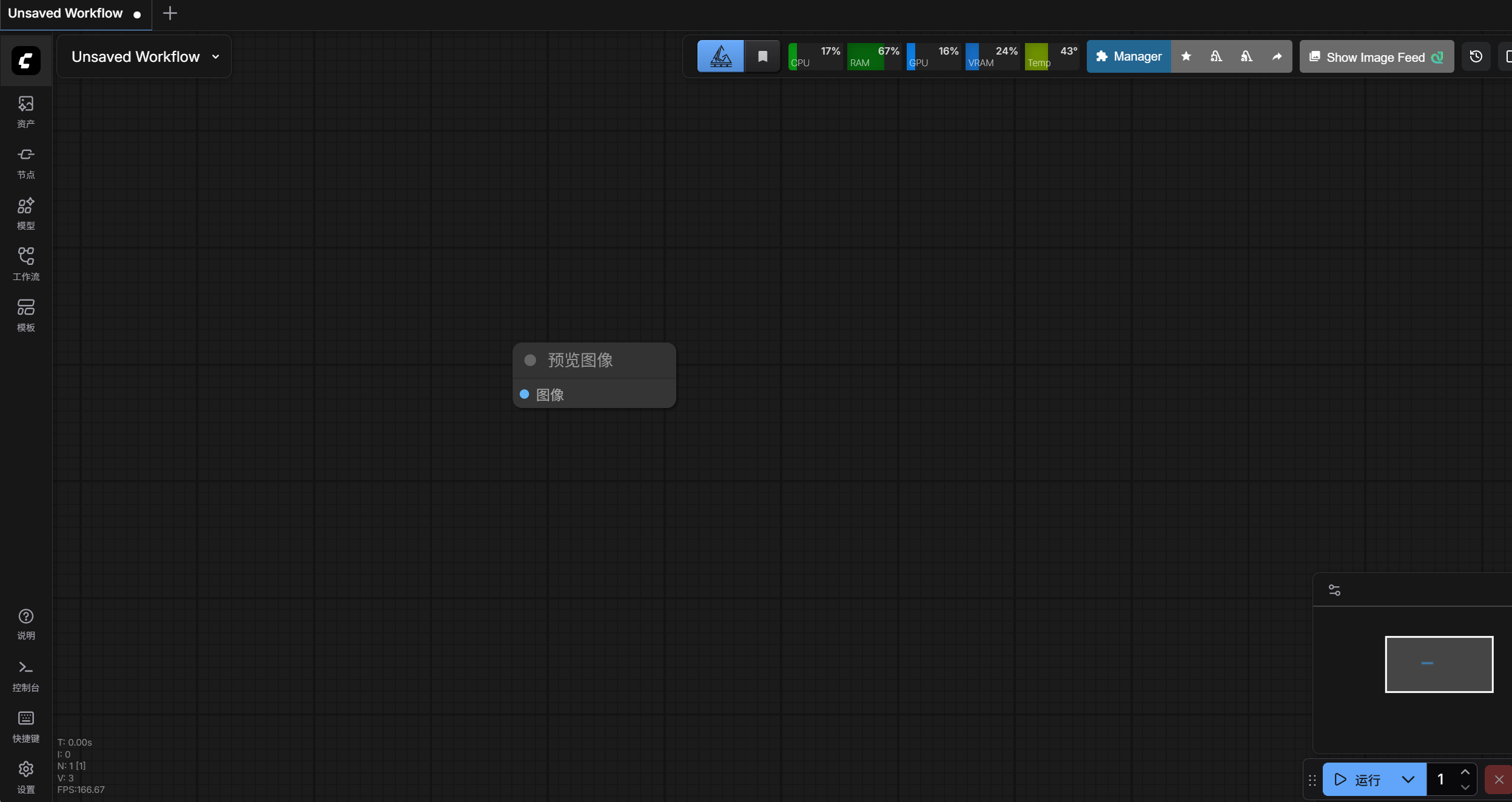
2、节点重命名
双击节点名称处,即可对节点名称进行重命名。
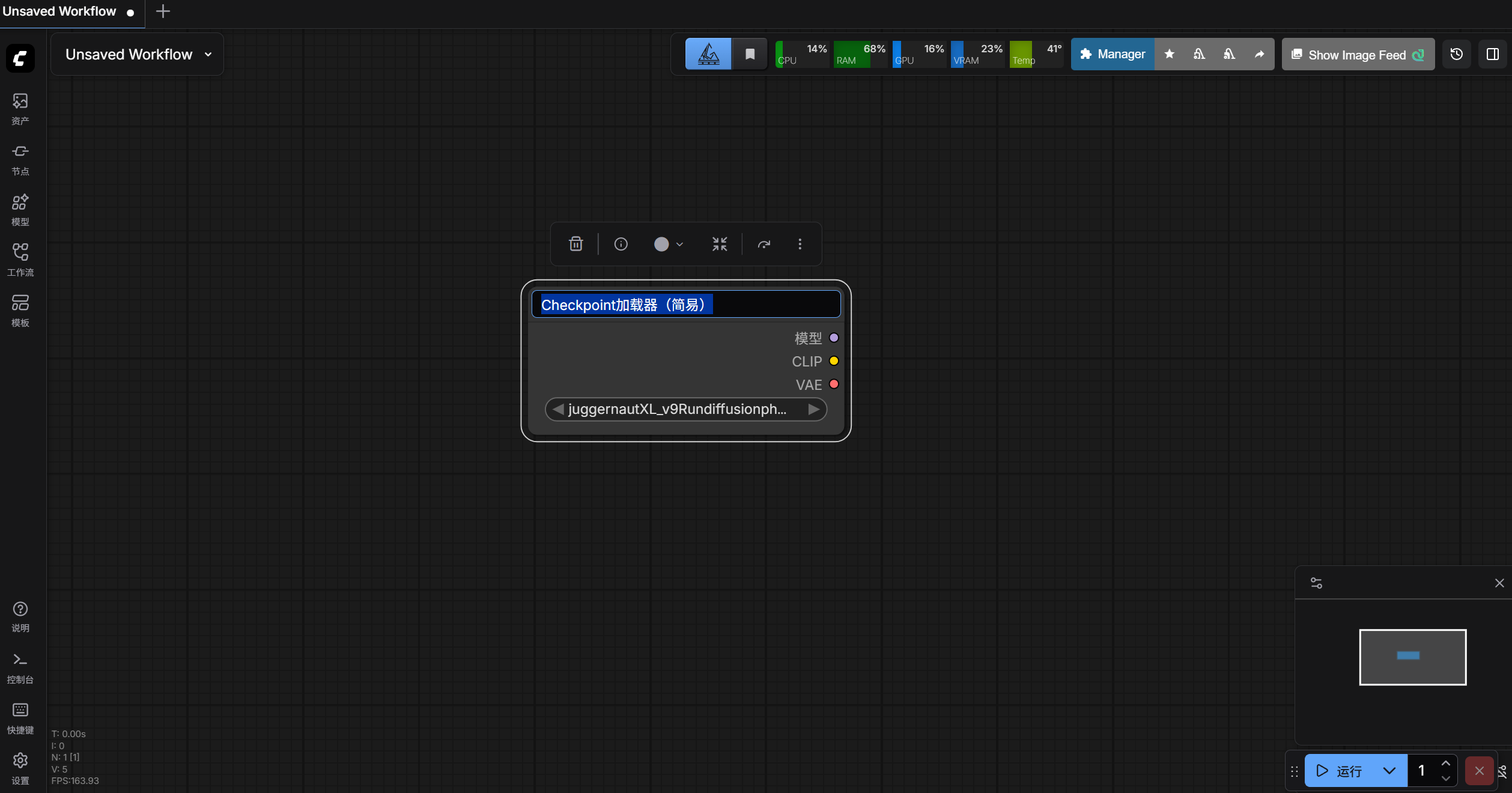
3、节点更换颜色
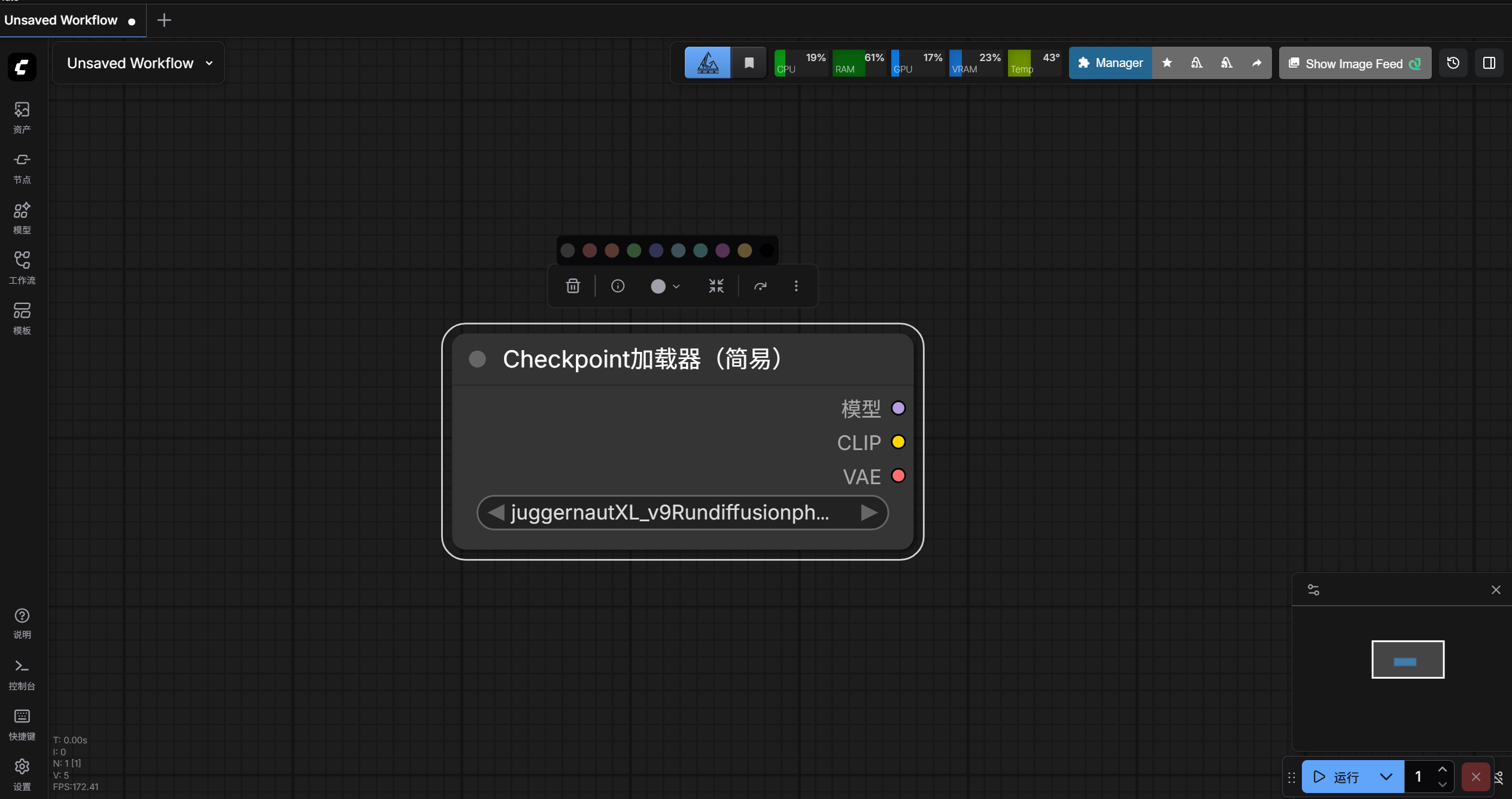
鼠标左键点击节点,有一个圆形图标,点击圆形图标,上方出现各个颜色的圆形图标。
节点要更换成什么颜色,就点颜色对应的图标,例如讲节点颜色换成黄色。
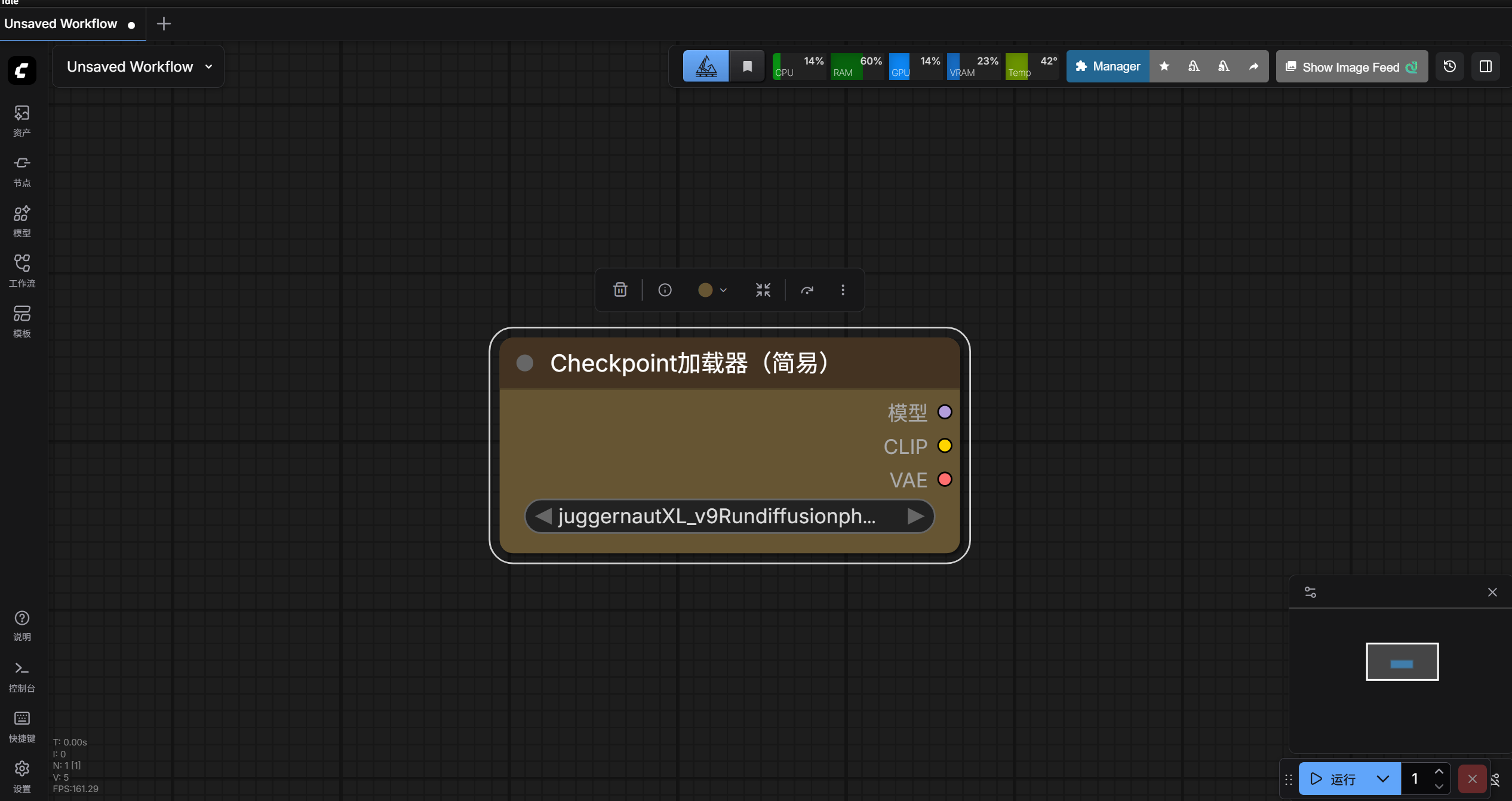
4、节点折叠和固定
想要折叠节点的话,将鼠标放到节点左上角灰色圆点处。
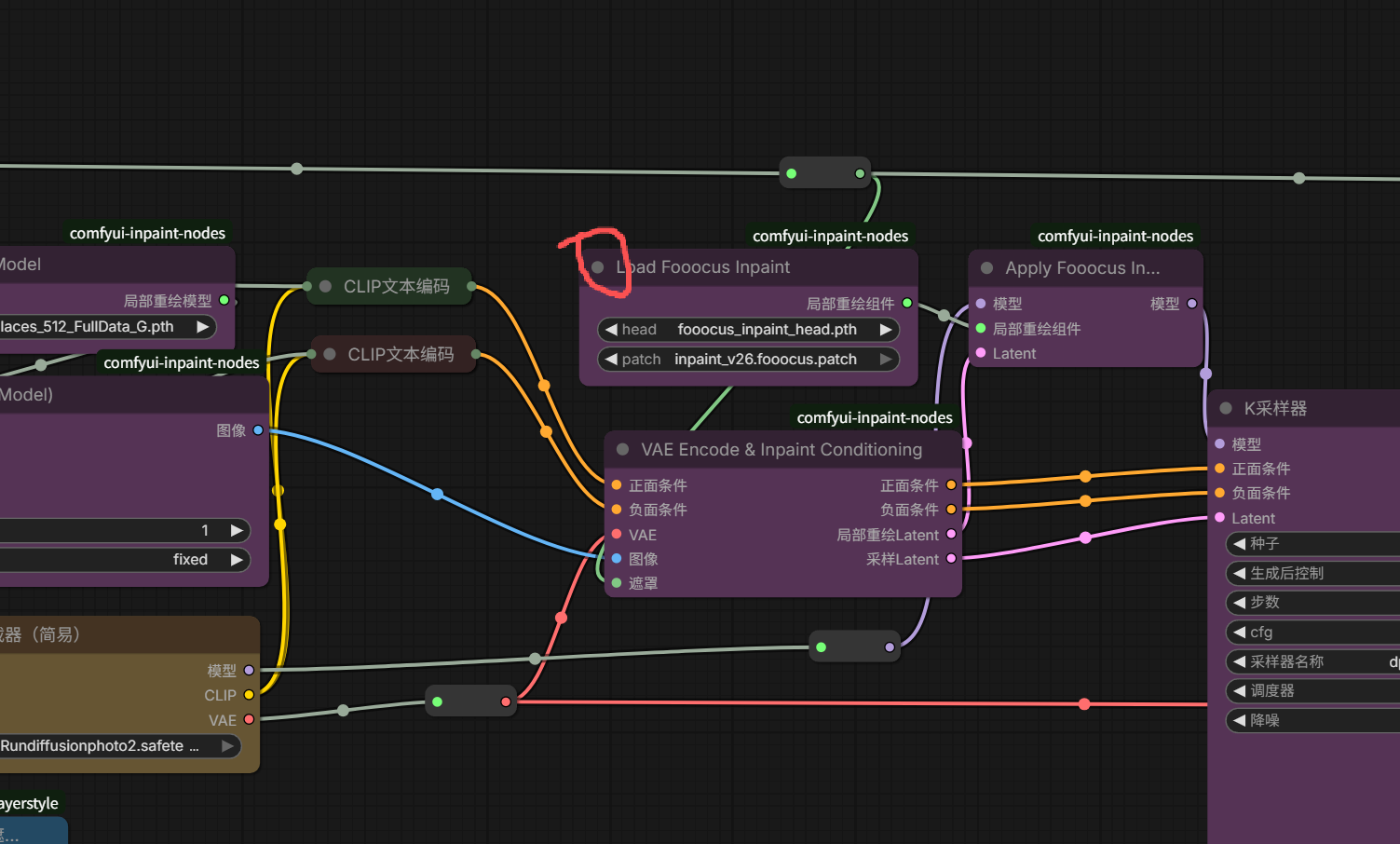
点击灰色圆点,节点就被折叠了。
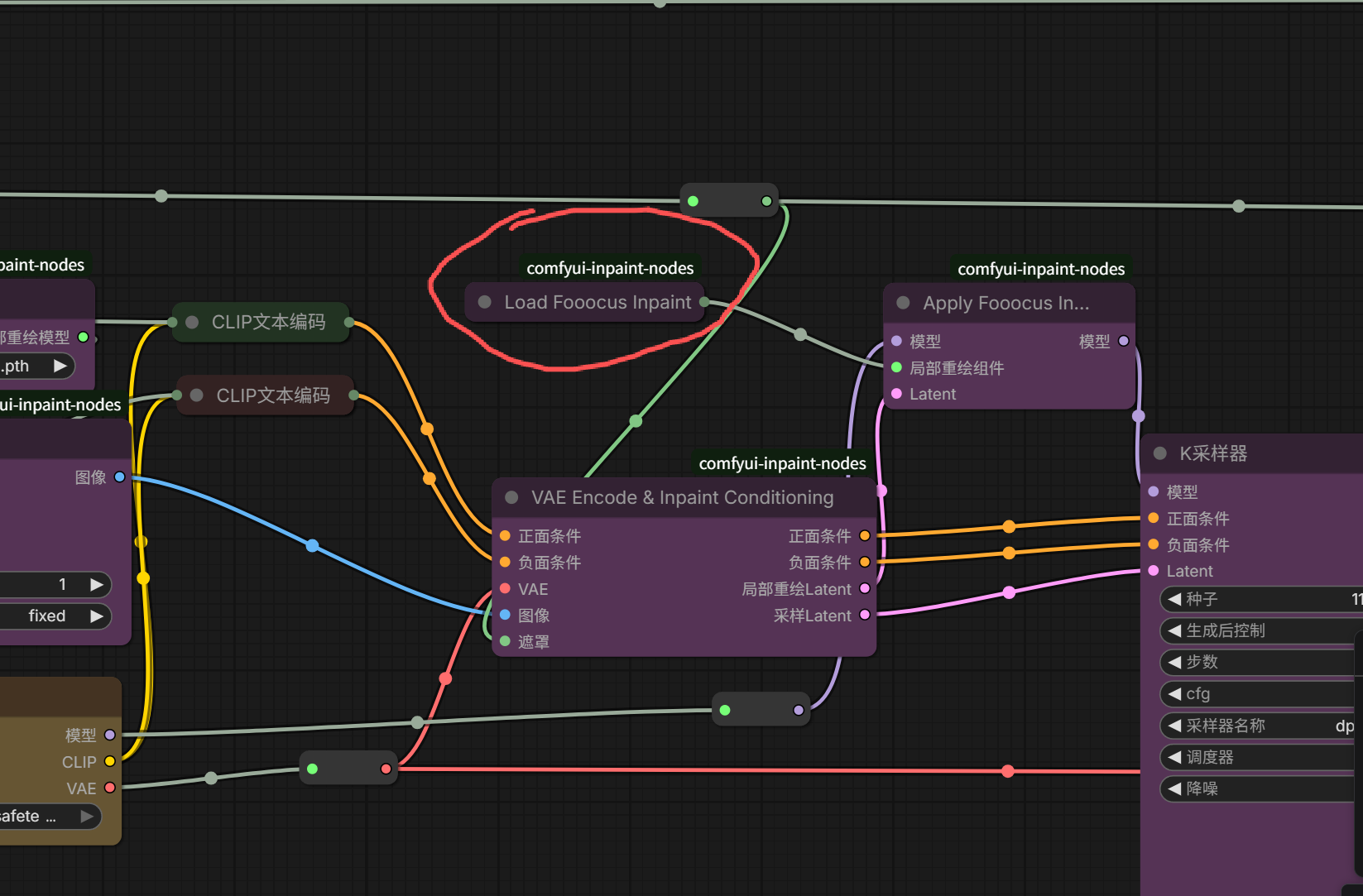
再点击灰色圆点,节点就被展开了。
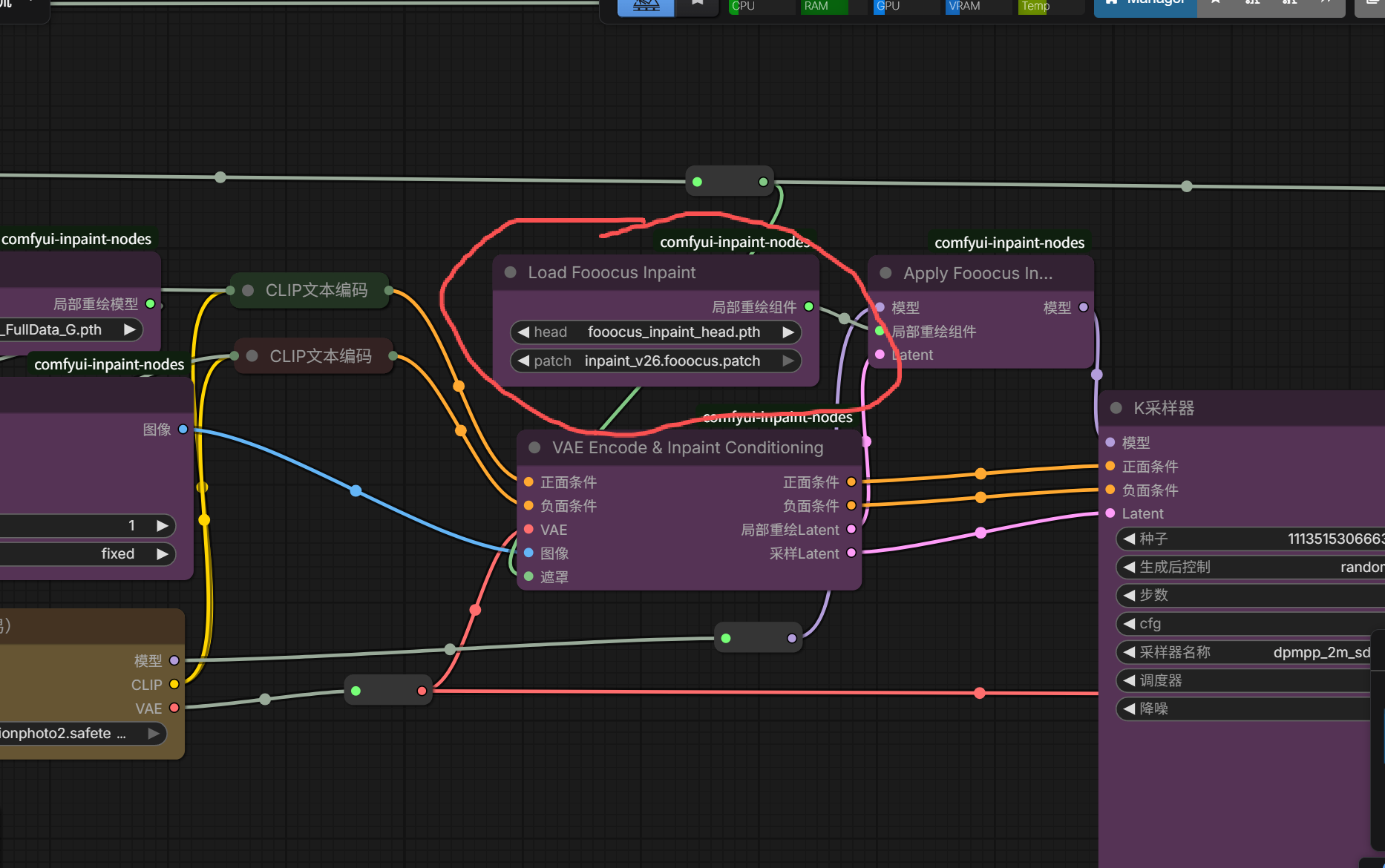
想要将节点固定,鼠标右键点击节点,选择固定。
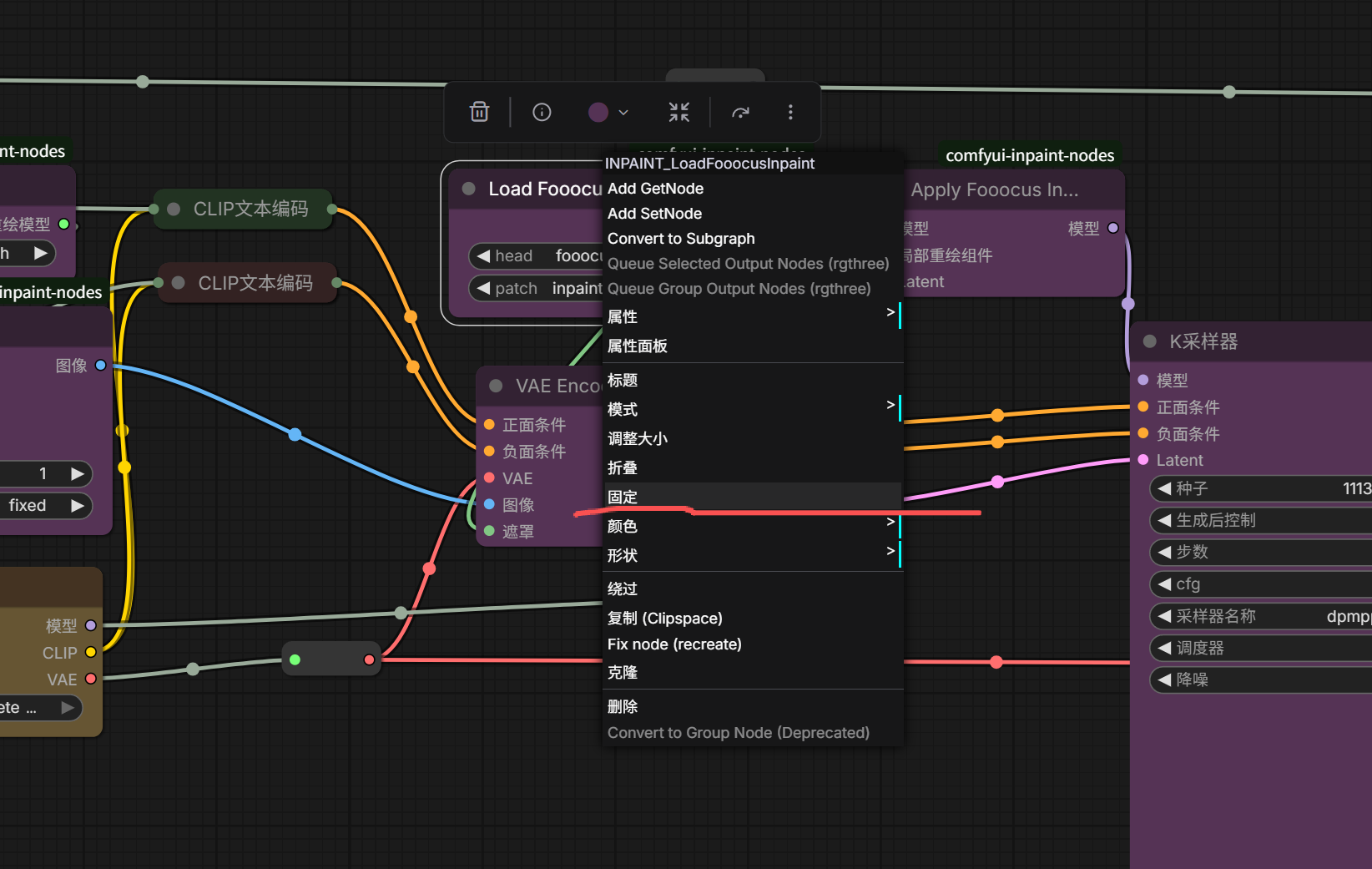
这样节点就被固定了,不能被拖动啦。
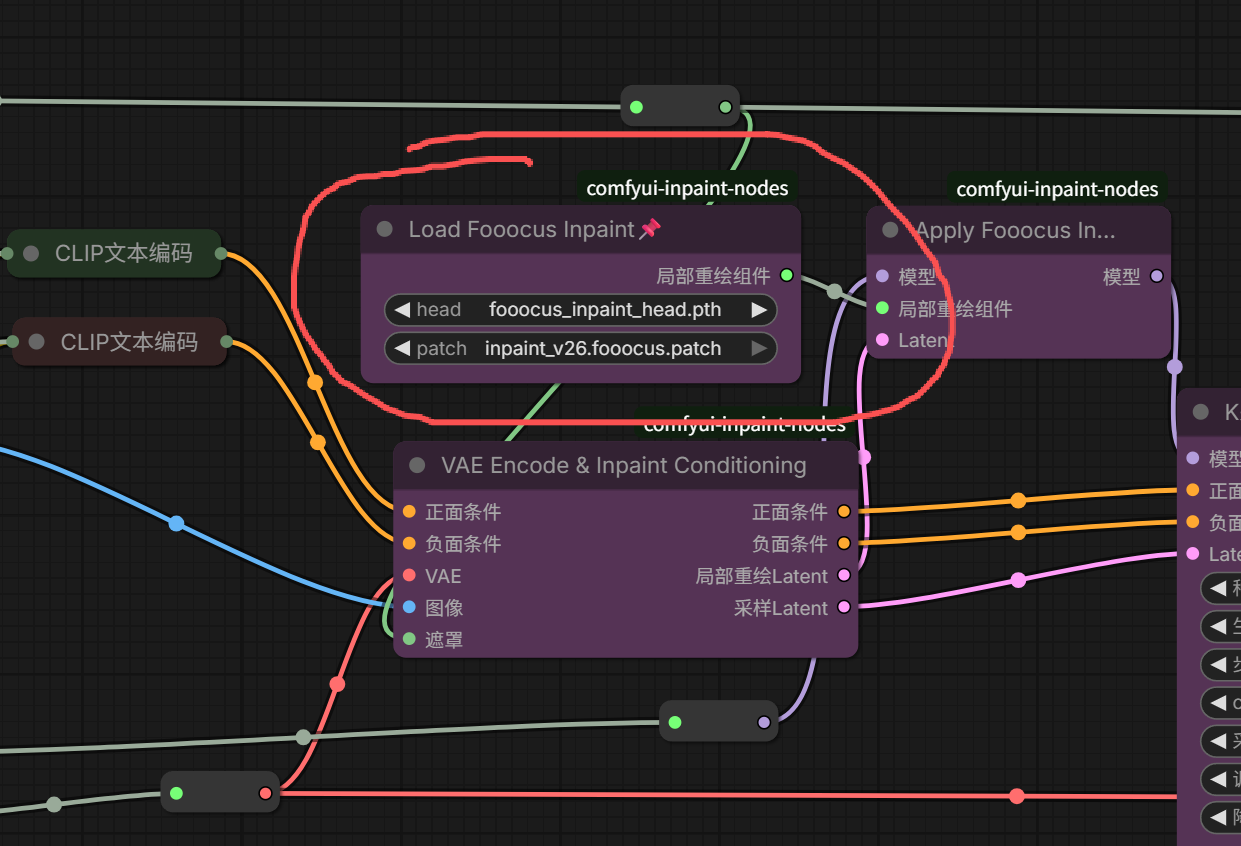
5、节点隐藏绕过
如果你想将不需要的节点隐藏起来,可以鼠标右键点击节点,选择隐藏绕过。
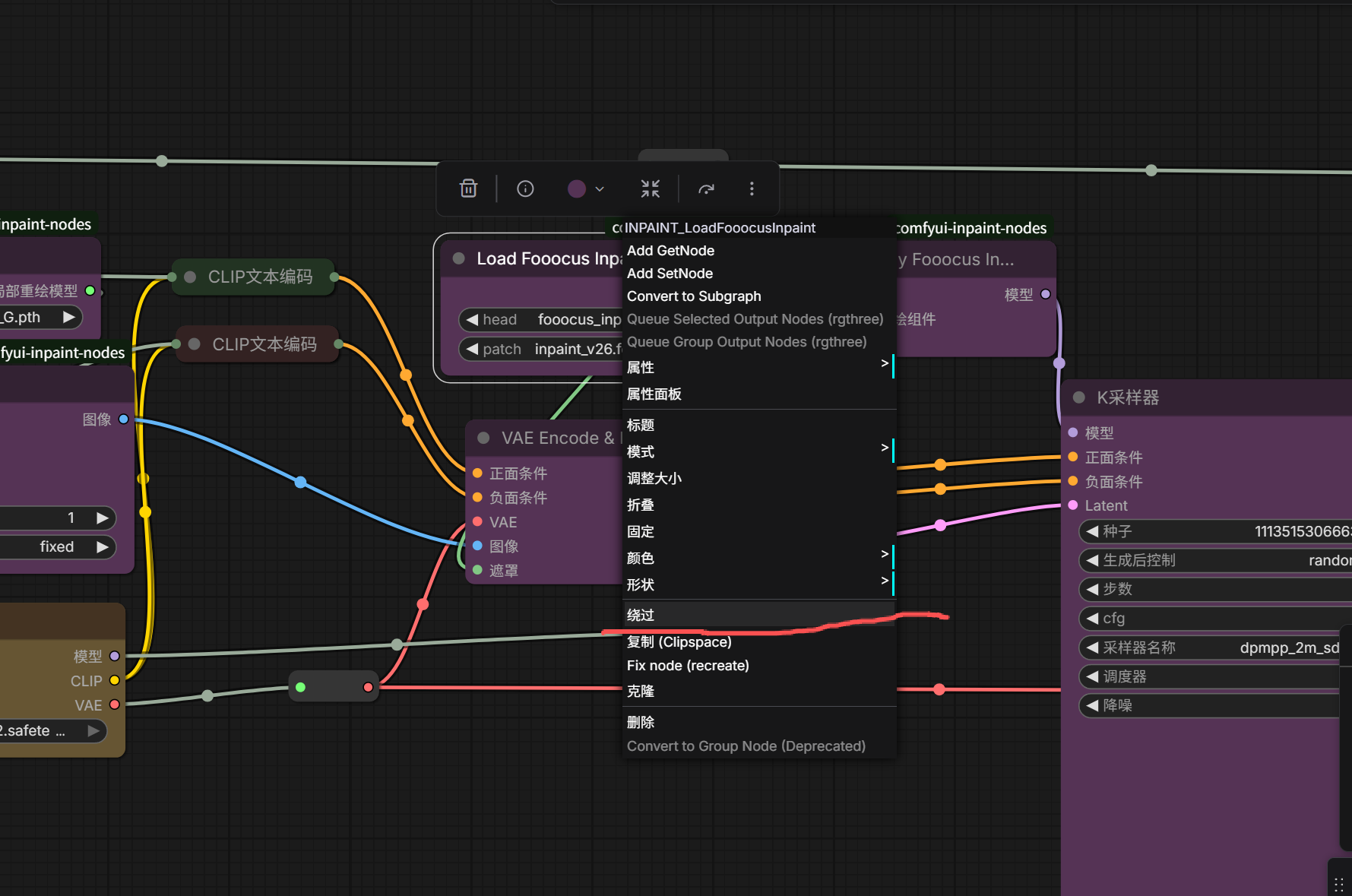
这样节点就被隐藏绕过了,工作流依旧正常运行。
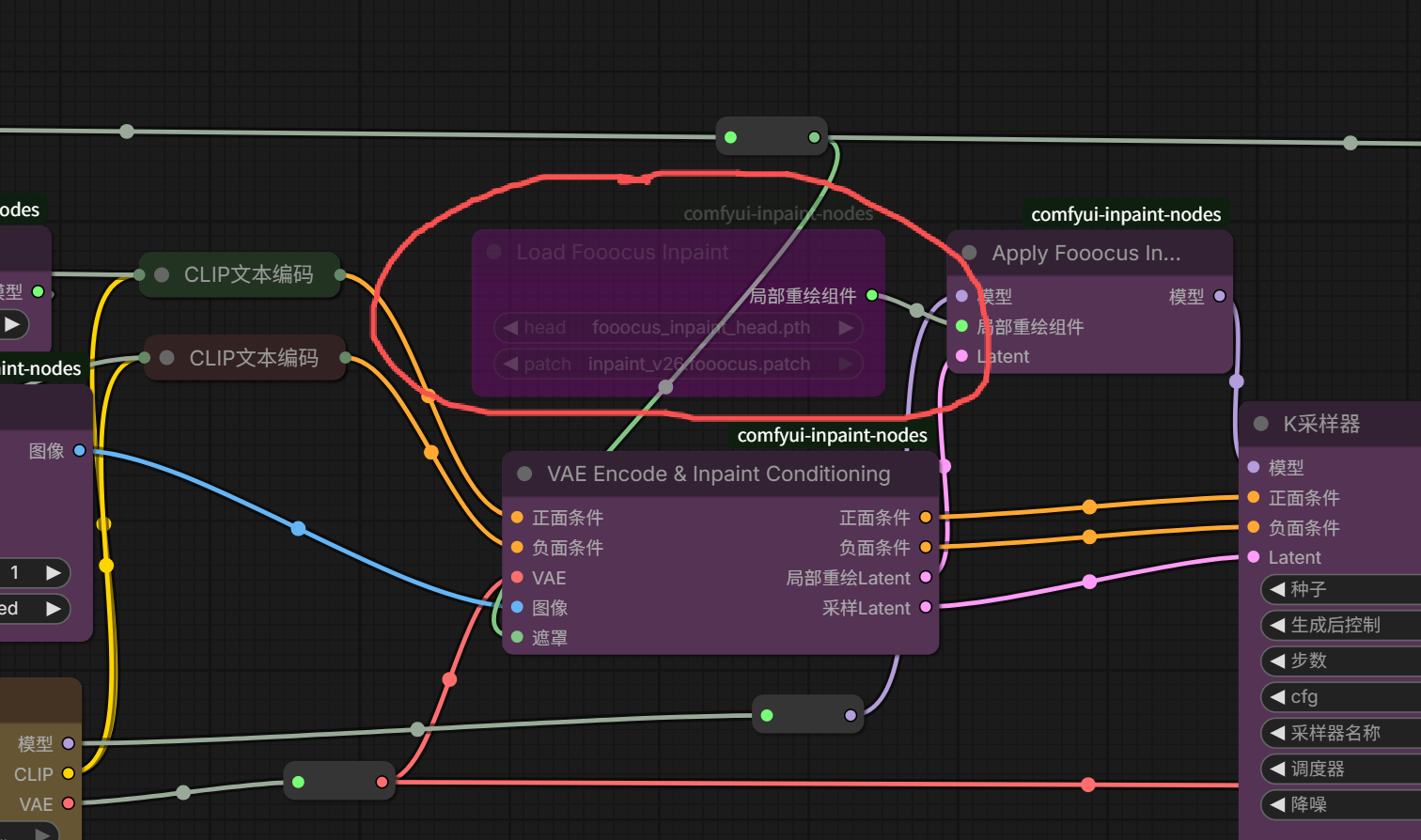
6、节点批量选择拖动
如果想批量移动节点,按住键盘上CTRL键,然后鼠标左键画个框,把批量移动的节点框进去。
然后鼠标左键点住节点,进行拖动即可。
7、节点多端连线
如果有多个节点输入,可以使用 条件合并 节点进行合并然后输出。
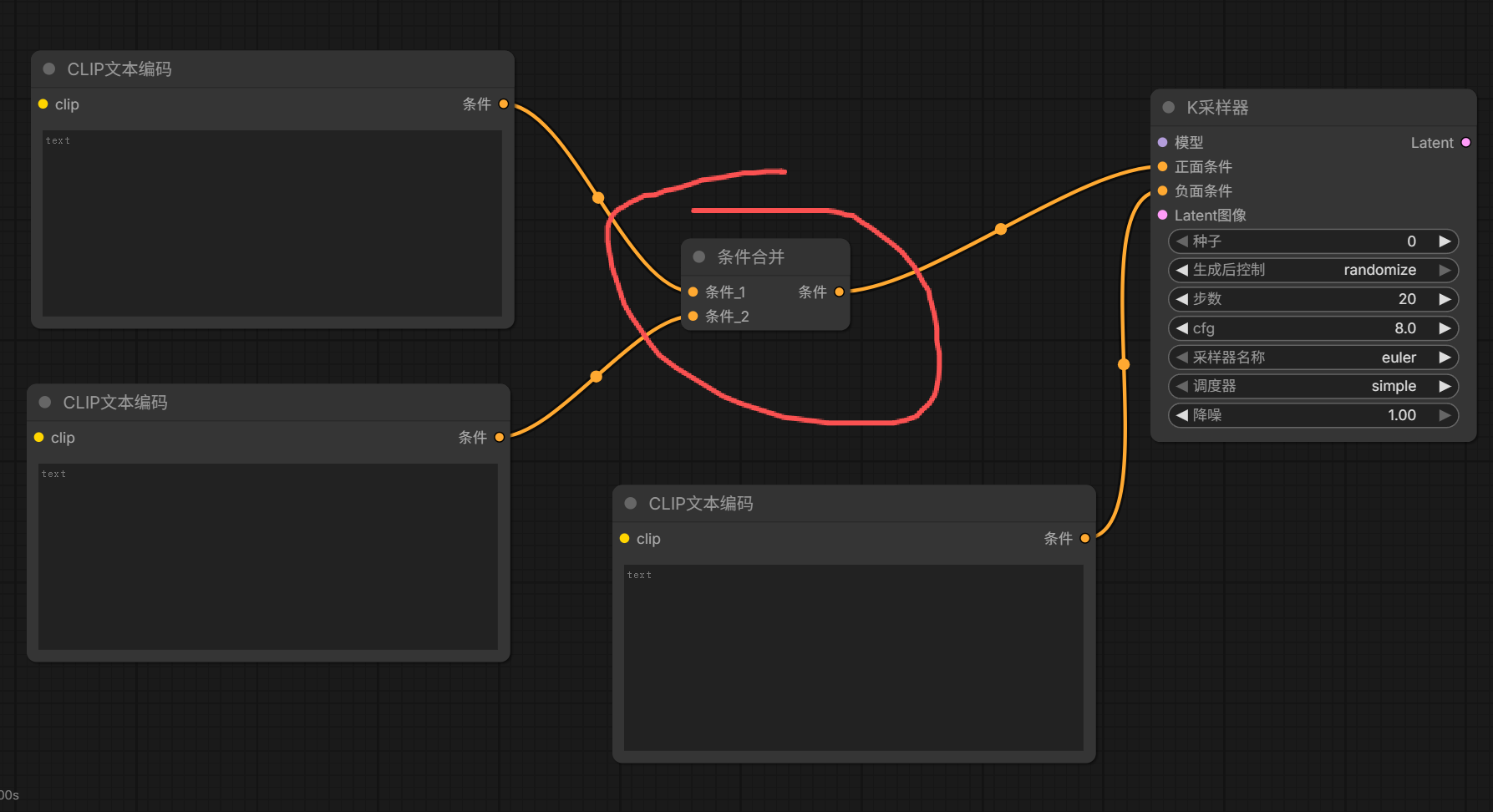
(三)插件扩展安装
插件安装的话可以使用Manager插件功能。
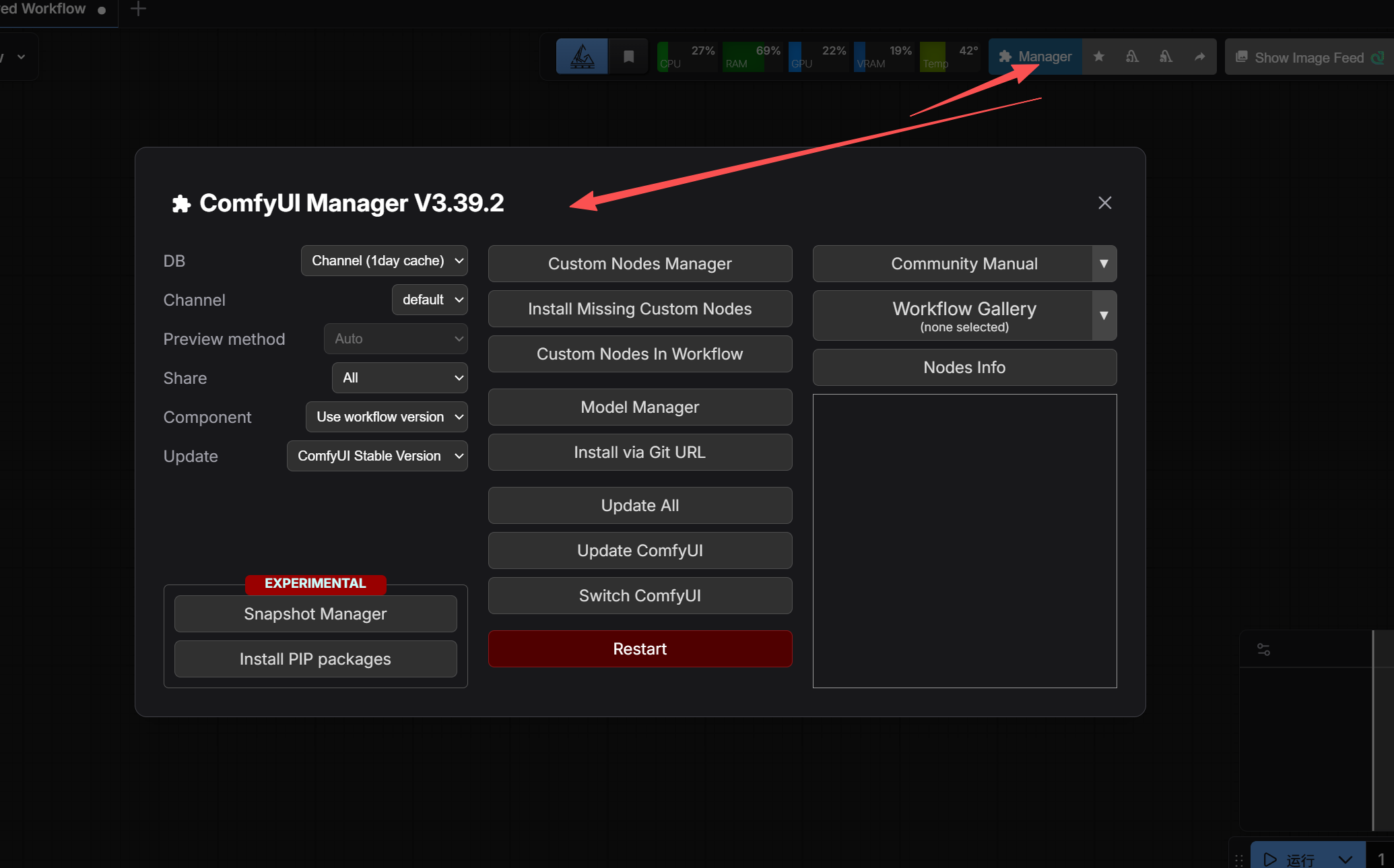
点击Custom Nodes Manager选项,然后要安装的插件可以在搜索框里搜索安装。
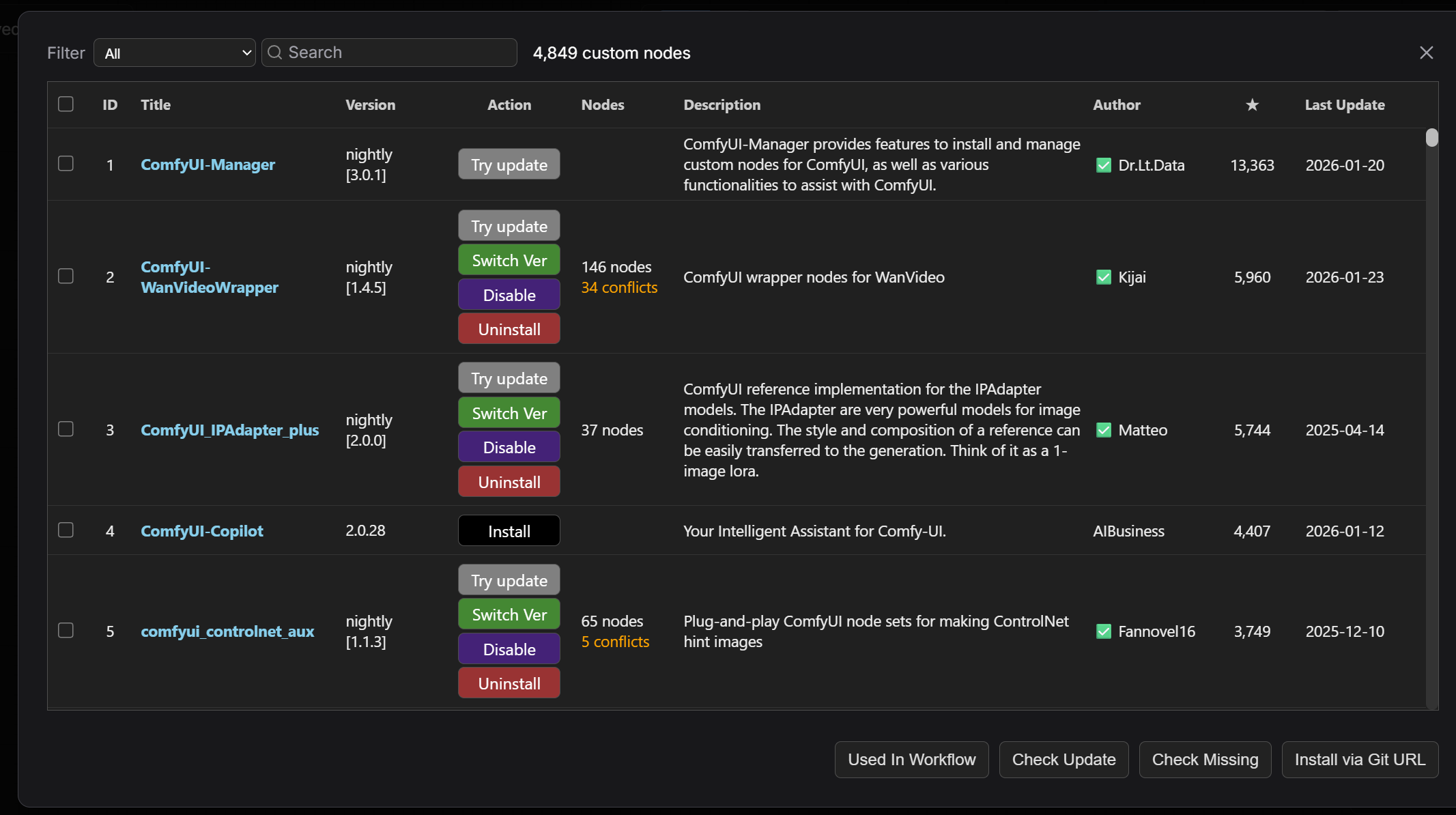
其次,在导入自己找的工作流可能会提示部分插件缺失,可以点击Install Missing Custom Nodes选项,之后安装缺失的插件节点。
安装好节点要重启下ComfyUI才可生效。
最后,插件节点还可以去 Github、huggingface 上下载,下载之后放到对应的文件夹里即可。
(四)ComfyUI报错
有时候使用ComfyUI时会报错,常见的错误有:模型或插件缺失、显存硬件性能报错、环境与依赖库类报错、节点之间线接错了跑不通报错等。
除了显存硬件性能报错,其他报错都可以发给AI,让AI分析解决错误。
例如模型或插件缺失,将报错内容复制给AI。
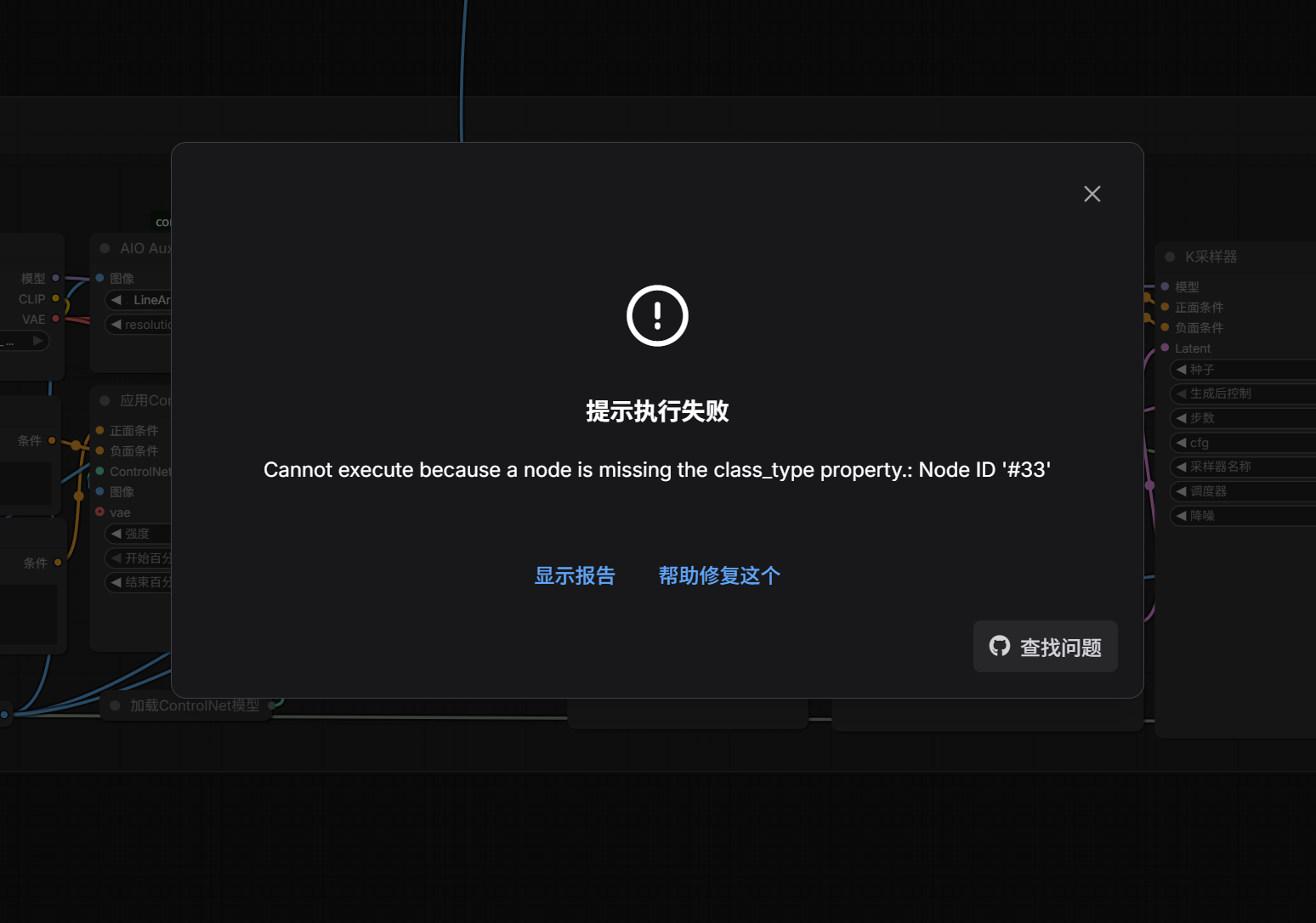
点击图中显示报告,点击右下角复制到剪贴板。
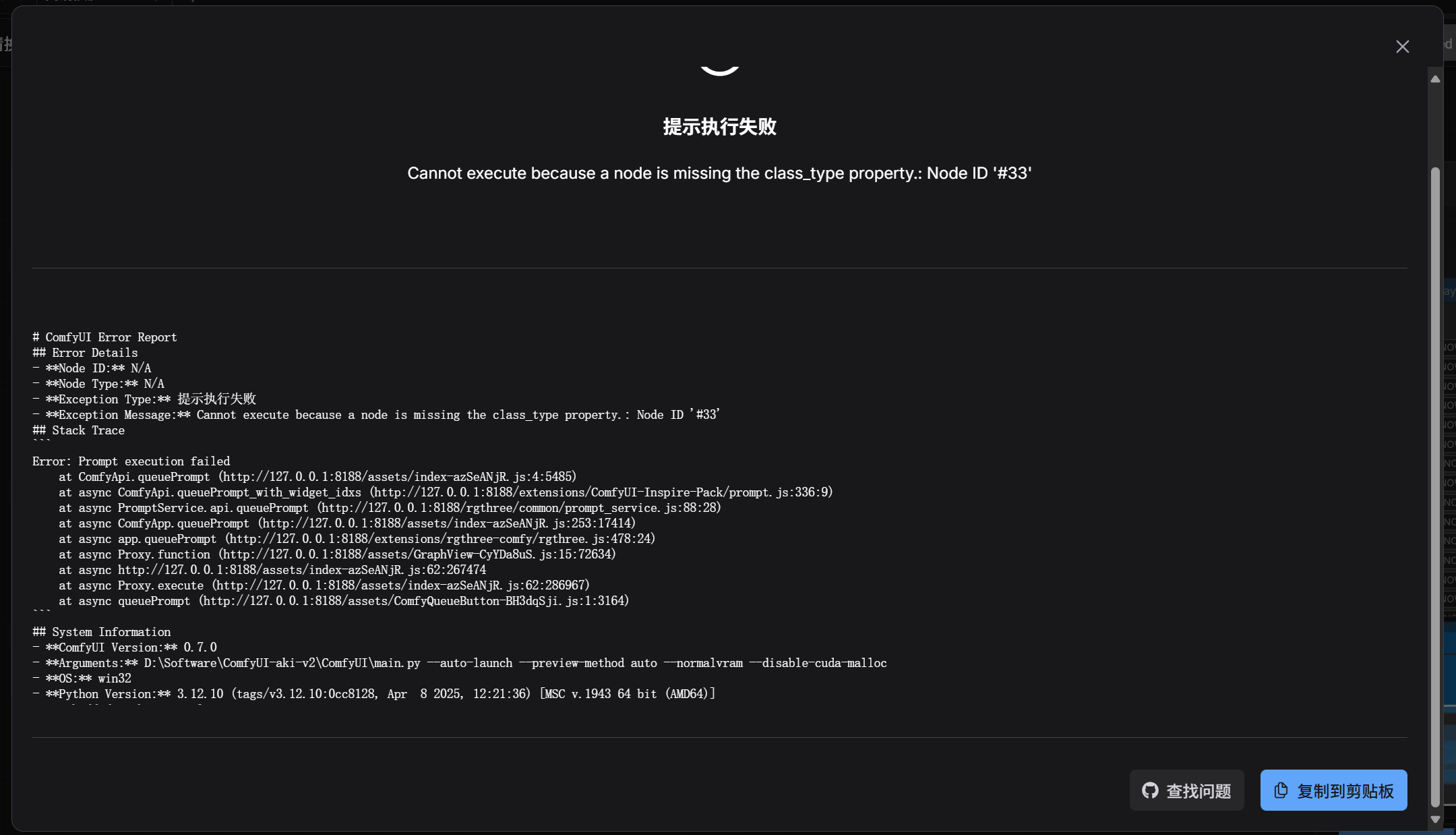
将复制内容发给AI,让AI分析解决错误。
AI会告诉你缺少哪些模型或插件,附上下载链接让你下载,AI还会告诉你下载的模型或插件放到哪个目录下。
我使用过多个AI,对比下来推荐使用Manus来解决报错。

当然你也可以自己来解决报错,不借助AI。
(五)K采样器
K采样器节点我认为很重要,是必须要掌握的,所以单独拎出来说。
其他节点自行了解,不在这说了哈哈。
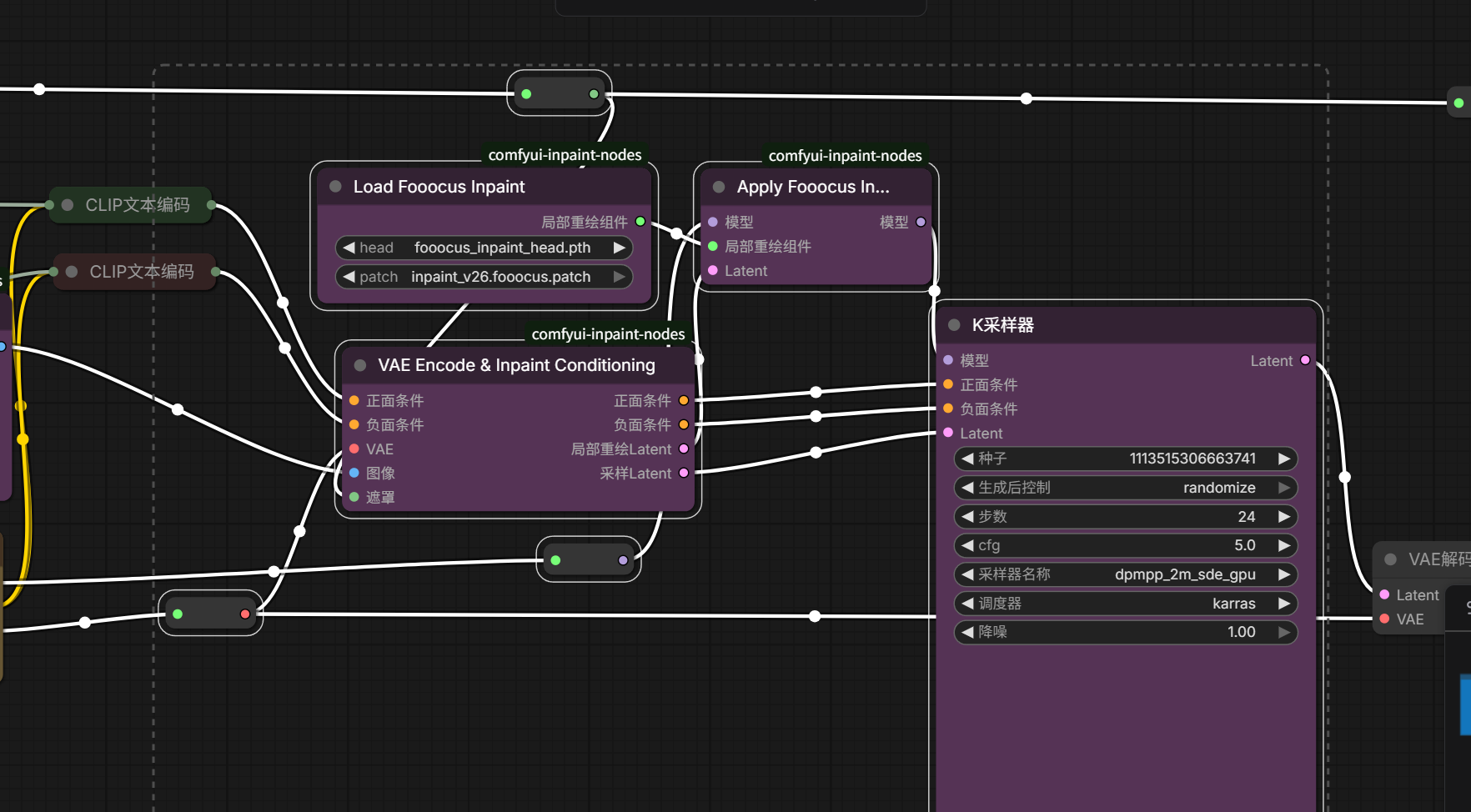
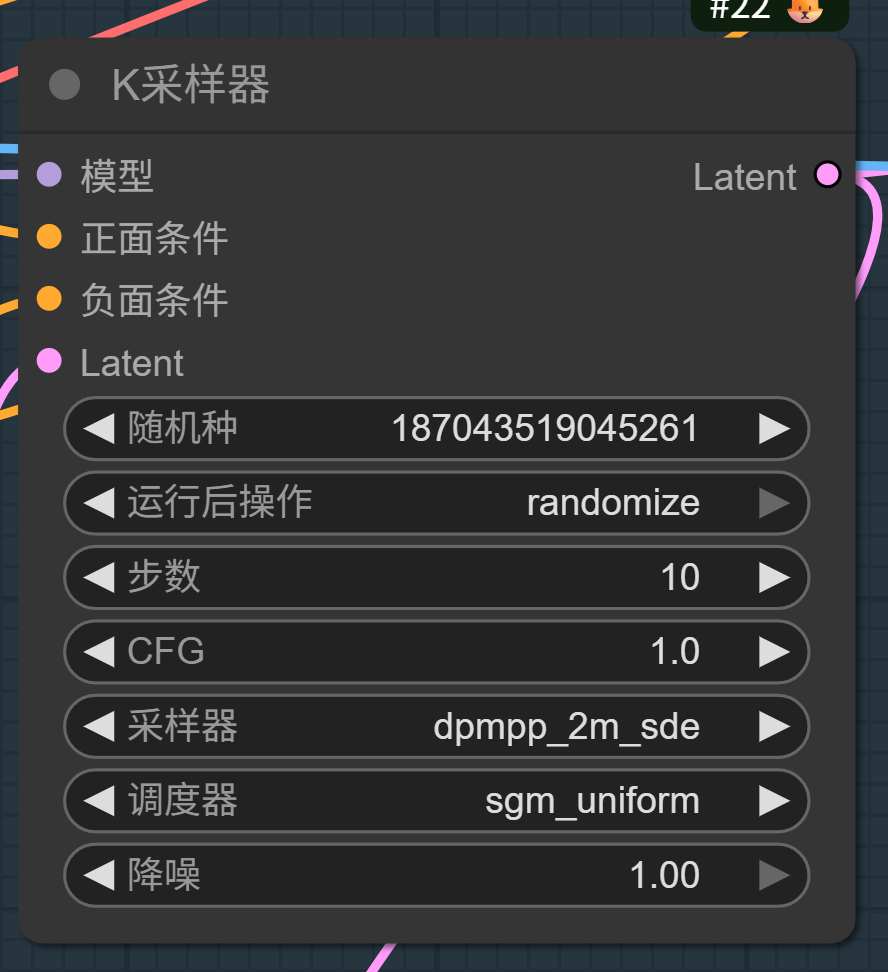
ComfyUI的K采样器如下图所示:
AI 生成图片的过程,其实就是把一张全是噪点的图,通过几十次计算,一步步把噪点去掉,还原出图像。
K采样器的作用是对全是噪点的图进行去噪——它负责把一团乱糟糟的马赛克,变成一张清晰的画。
1、输入
图中输入端左侧连接点,模型一般接收来自Checkpoint大模型输出。
正面条件一般接收CLIP文本编码器正向提示词信息。
负面条件一般接收CLIP文本编码器反向提示词信息。
Latent(latent_image)是接收潜空间图像信息。如果是文生图接收噪点图,如果是图生图接收被压缩后的原图。
2、输出
图中输入端右侧连接点,Latent(latent_image)是输出经过K采样器去噪后、处理好的图像信息,一般需要连接VAE解码器进行解码翻译,当然也可以连接其他。
3、参数
随机种:随机数种子,固定这个种子数字,就能复现出一模一样的画。
运行后操作:产生种子后的控制方式,randomize表示随机种子,increment表示每次增加1,decrement表示每次减少1,fixed表示固定种子。
步数:去噪的次数。例如Turbo/LCM模型可以1-8步,普通模型可以20-40步。但如果超过50步通常边际效益递减,只增加时间不增加画质。
CFG:提示词引导系数。如果是Turbo/Lightning模型建议设为1.0 - 2.0。
采样器:决定去噪的具体数学方法。采样器有很多,常见的采样器如下:
| 采样器名称 (ComfyUI) | 核心描述 | 优点 | 缺点 |
|---|---|---|---|
| dpmpp_2m | 标准算法。一种二阶多步求解器。 | 收敛性极好,画面结构严谨、干净,对 Prompt 还原度高。 | 画面质感有时会显得过于平滑,缺乏微观肌理。 |
| euler | 最基础的一阶求解器,是现代采样器的基石。 | 算法简单,极其稳定,不容易产生坏图。FLUX 模型首选。 | 画面风格偏柔和,细节的锐利度不如 DPM 系列。 |
| euler_ancestral | Euler 的祖先版,每一步都注入随机噪声。 | 画面富有变化和创造力,自带一种朦胧的艺术感。 | 不收敛:随着步数增加画面构图会不断变化,不适合做动画。 |
| dpmpp_2m_sde | 在 dpmpp_2m 基础上引入随机微分方程 (SDE)。 | 质感之王。能生成极真实的皮肤毛孔、布料纹理等细节。 | 引入了随机性,每次生成结果会有微小差异;速度比 2m 慢。 |
| dpmpp_3m_sde | 2m_sde 的高阶版本,专为高步数设计。 | 在极高分辨率下细节表现更细腻。 | 在低步数(<30步)下效果很差,必须配合高步数使用。 |
| lcm | 专为潜在一致性模型 (Latent Consistency Model) 设计。 | 可以在极低步数(4-8步)下生成可用图像。 | 通用性差,配合普通模型使用会导致画面崩坏。 |
| uni_pc | 统一预测校正器,专为扩散模型设计的各种求解器。 | 在低步数(10-15步)下就能达到很高的完成度。 | 在高步数下画质提升不明显,上限不如 DPM++ 系列。 |
| heun | Euler 的改进版(二阶方法)。 | 理论准确度比 Euler 高,画质扎实。 | 同样的步数下,计算量是 Euler 的两倍。 |
| ddim | 早期的确定性采样算法。 | 具有很好的可逆性,适合用于重绘 (Inpainting) 任务。 | 细节丰富程度和结构表现力已不如新一代采样器 |
调度器:决定去噪的节奏。调度器也有很多,常见的调度器如下:
| 调度器名称 (Scheduler) | 核心描述 | 优点 | 缺点 |
|---|---|---|---|
| simple | 简易线性调度器,主要为 FLUX 等新架构模型设计。 | 对FLUX等模型适配性极好,画面干净。 | 在老旧模型SD1.5上效果不佳,容易出现灰度问题。 |
| sgm_uniform | 稳定性生成模型的均匀调度器,专为 SDXL Turbo / LCM 优化。 | 极速生成。对最后几步的降噪处理非常干脆,适合低步数出图。 | 通用性一般,配合普通模型使用时效果不如 Karras 细腻。 |
| karras | 基于 Karras 论文的变速曲线(前期慢后期快)。 | 目前的行业标准。极大地提升了画面细节和清晰度,噪点残留极少。 | 几乎没有短板,是SD1.5 SDXL的首选默认设置。 |
| exponential | 指数型下降曲线,去噪节奏非常激进。 | 对某些特定的2.5D或3D渲染风格模型有奇效,画面锐利。 | 容易导致画面过于锐利甚至出现伪影,对Prompt 的容错率低。 |
| ddim_uniform | DDIM 的均匀调度版本,节奏平稳。 | 在做视频重绘或需要保持画面高度一致性时表现稳定。 | 细节丰富度不如 Karras,画面有时显得略微平淡。 |
| beta | 贝塔分布调度器,也是为新模型(如 FLUX / SD3)设计的。 | 在高分辨率生成时,对结构和光影的控制比 Simple 更好。 | 计算逻辑相对复杂,在某些旧模型上可能导致颜色偏移。 |
| 正常 (normal) | 即 standard / linear,最传统的线性下降策略。 | 兼容性之王,任何模型都能跑,效果中规中矩,最稳妥。 | 上限不高,细节不如 Karras丰富,画面通透感一般。 |
| linear_quadratic | 线性二次方调度器,介于线性与指数之间。 | 试图在平滑过渡和细节保留之间找平衡,适合某些半写实风格。 | 比较冷门,社区验证的黄金组合较少,需要自己摸索步数。 |
| kl_optimal | 基于 KL 散度优化的调度器。 | 理论上能生成数学上更“正确”的概率分布。 | 实际体感提升不明显,且计算速度可能略有影响,极少使用。 |
| capitanZiT | 社区魔改版调度器(通常针对特定微调模型)。 | 在某些特定的二次元或插画模型上可能有独特的滤镜感。 | 极度冷门,通用性未知,缺乏文档支持。 |
| FlowMatchEuler... | 流匹配欧拉离散调度器(Flow Matching)。 | SD3 (Stable Diffusion 3) 的原生调度器。 | 仅适用于 SD3 架构的模型,用在其他模型上会报错或出图崩坏。 |
| bong_tangent | 也是一种社区实验性的调度器。 | 可能在某些极端的步数设置下有特殊效果。 | 属于实验性功能,不建议在正式工作流中使用。 |
| beta57 | Beta 调度器的特定参数变种。 | 针对某些特定训练的 checkpoint 微调过。 | 与标准 Beta 差异极小,普通用户很难肉眼区分区别。 |
常见的采样器和调度器组合如下:
| 采样器 (sampler_name) | 调度器 (scheduler) | 适用场景 | 效果点评 |
|---|---|---|---|
| dpmpp_2m | karras | 【万能标准】 SD1.5 / SDXL 全系列模型 二次元、3D、一般写实通用 |
目前最主流、最稳健的配置。速度快,画面干净,对提示词的还原度高,几乎没有短板。 |
| dpmpp_2m_sde | karras | 【极致写实】 高精度人像摄影、微距摄影 需要丰富纹理材质时 |
牺牲约 50% 的速度换取顶级画质。生成的皮肤毛孔、布料纹理、光影过渡极度真实,拒绝“塑料感”。 |
| euler | simple | 【FLUX 官方】 FLUX.1 [dev] 或 [schnell] FLUX 生态微调模型 |
FLUX 模型的官方推荐配置。能生成最原汁原味、噪点最少、背景最干净的图像。 |
| euler | beta | 【FLUX 增强】 FLUX.1 系列模型 需要更硬朗的画风时 |
同样适用于 FLUX。相比 Simple,它在光影对比度和线条锐利度上会稍微强一点点,立体感稍强。 |
| euler_ancestral | 正常 (normal) | 【艺术创作】 油画、水彩、厚涂插画 寻找构图灵感时 |
即 WebUI 的 Euler a。画面柔和且富有梦幻感,每次生成都有微小的构图变化,适合需要“意外惊喜”的创作。 |
| lcm | sgm_uniform | 【极速闪电】 Lightning / Turbo / Hyper 模型 低显卡或实时生成 |
专为“少步数”设计。配合特定模型,能在极短时间内生成可用的图像,效率极高。 |
| dpmpp_2m | sgm_uniform | 【Turbo 替代】 SDXL Turbo 模型 没有 LCM 采样器时 |
如果找不到 LCM 采样器,这是跑 Turbo 模型的最佳替代方案,出图速度同样极快。 |
| uni_pc | 正常 (normal) | 【低配预览】 显卡性能较差 批量跑图筛选构图 |
“省力”模式。在很低的计算量下就能跑出结构完整的图,适合快速看大概效果。 |
| euler | FlowMatchEuler... | 【SD3 专用】 Stable Diffusion 3 模型 |
SD3 架构的原生算法。请勿用于其他模型,否则可能会报错或生成全黑/全噪点的坏图。 |
降噪:表示重绘幅度,数值越大对图片产生的变化越大。如果是文生图,要设置为1,因为画布全是噪点,必须全改。如果是图生图,可以进行适当调节,例如0.3 是微调,0.7 是大改。
三、绘画模型和ComfyUI画图
AI绘画发展的太快了,当初我刚接触AI绘画的时候,是用的SD1.5模型和Midjourney。
现在SD1.5模型怕是大家都不用了。
现在是2026年1月,当前AI绘画用的主流模型为Zimage、Qwen-image2512、Nano Banana Pro,图片编辑用的主流模型为Flux2 klein。
也许再过几个月这些模型也都不用了,有更厉害的模型出现。
这里以线上RunningHub平台为例,对ComfyUI画图进行介绍:
(一)模型通识
在AI绘画之前,要对模型有个了解。
1、模型分类
常用的模型类别有:CHECKPOINT、LORA、UNET、VAE、GGUF。
(1) Checkpoint (基础模型/底模)
Checkpoint是指经过完整训练的扩散模型权重文件,通常包含Clip Text Encoder、UNet、VAE等核心组件的参数集合。
但凡你要AI画图,你必须选择一个Checkpoint模型才能开始画图。
Checkpoint模型常见格式为.safetensors或 .ckpt。
接下来本文标题(三)到(七)说的都是Checkpoint模型。
(2)LoRA (低秩自适应)
LoRA (Low-Rank Adaptation) 是一种高效的参数微调技术 (Parameter-Efficient Fine-Tuning, PEFT)。
LoRA模型为小模型,作为Checkpoint模型的补充,可以由我们自己训练,也用别人训练好的。
LoRA不改变Checkpoint模型的全量权重,而是在Transformer或UNet的特定层中注入可训练的低秩矩阵 (Low-Rank Matrices)。
大家如果想训练LoRA模型,要下载训练LoRA模型和打标签的软件。
这里推荐赵图图老师的LoRA模型训练器:永久免费!自研无需参数LORA模型训练器:零门槛开箱即用,全模型支持,零环境依赖,图形界面!喂饭教程(胎教级)_哔哩哔哩_bilibili
(3)UNet (核心去噪网络)
UNet是扩散模型中的核心神经网络架构,负责执行具体的去噪推理过程。
如果说Checkpoint是画家的身体,UNet就是他在画画时思考的过程,一步步把模糊的噪点还原成清晰的图像。
UNet 包含编码器 (Encoder)、解码器 (Decoder) 以及中间的跳跃连接 (Skip Connections)。
有的Checkpoint包含了UNet,可以不用额外加载UNet模型。
(4)VAE (变分自编码器)
VAE (Variational Autoencoder) 充当像素空间 (Pixel Space) 与潜在空间 (Latent Space) 之间的编解码桥梁。包括:
- Encoder:将高维的像素图像压缩为低维的潜在特征,供UNet 处理(降低计算量)。
- Decoder:将UNet处理后的低维潜在特征解压还原为可视化的像素图像。
VAE 的质量直接决定了最终图像的色彩饱和度、清晰度以及细节纹理的还原度。错误的 VAE 匹配会导致图像出现“发灰”或严重的色彩偏移。
有的Checkpoint包含了VAE,可以不用额外加载VAE模型。
(5)GGUF (GPT-Generated Unified Format)
GGUF 是一种专为边缘计算与量化推理设计的文件格式,显著降低模型加载所需的VRAM(显存) 和RAM。
对于显卡配置不高的电脑,GGUF是救星。例如它让你能用较小的显存(如 8G)跑动原本需要24G显存才能运行的模型,但画质有细微的损失。
总结:以Checkpoint确立基础生成空间,利用UNet执行去噪计算,通过VAE完成视觉还原,借助LoRA注入特定特征,并最终可通过GGUF格式实现硬件端的量化部署。
2、模型版本
有的时候,你会看到模型带有后缀如SDXL-Lightning、Qwen-Image-2512-FP8、Zero-Image-Turbo等。
这些后缀含义如下:
(1)速度与采样
Lightning:高速版,由字节跳动发布。它采用了改进的蒸馏方法(渐进式对抗蒸馏技术)。
通常采样步数需4-8步,提示词引导系数CFG需设为1.0-2.0,据说画质通常优于Turbo。
Hyper:另一种加速技术,类似于 Lightning,通常针对SDXL模型优化。
Turbo:极速版。它利用对抗性扩散蒸馏技术 (ADD),让模型在极短的步数内成图。
通常采样步数只需1-2步即可出图,提示词引导系数CFG需设为1.0 - 1.5。
| 参数 | 标准模型 (Standard) | Turbo 模型 | Lightning 模型 |
|---|---|---|---|
| 采样步数 (Steps) | 20 - 40 | 1 - 4 | 4 - 8 |
| 提示词引导系数 (CFG Scale) | 7.0 (默认) | 1.0 - 2.0 | 1.0 - 2.0 |
关于采样步数和提示词引导系数CFG的设置还需要参照模型作者写的说明。
PS:蒸馏就是把庞大模型的复杂推理过程,压缩成简单模型的高效推理过程,实现画质不减(或微损),速度翻倍。在蒸馏的过程中,教师信号就是“老师”传授给“学生”的标准答案。老师直接把最终答案或者中间的关键步骤给学生看,训练学生通过直觉一眼看出答案。速度快,省去了中间繁琐的步骤。
(2)精度与修剪类
Pruned:剪枝版。去除了训练过程中产生的冗余数据,体积比全量版小得多(例如从 7GB 减到 2GB),且画质几乎无损。推荐下载此版本。
FP8:只用 8 个位来存储一个数字,相比下面FP16显存需求直接砍半
FP16:半精度浮点数。用 16 个位来存储一个数字,相比下面FP32占地减半,标准的模型精度,体积适中。
FP32:全精度浮点数。用 32 个位来存储一个数字,极其精准,体积巨大,通常只用于继续训练模型,普通人不需要下载。
EMA (Exponential Moving Average):包含平滑权重的版本。通常体积较大,适合用于微调训练;如果只是画图,选不带 EMA 的即可。
(3)功能类
Inpainting:重绘专用。专门用于局部重绘(Inpaint)的模型,能更好地融合背景,修补画面瑕疵。
Instruct / Edit:指令微调版。允许你通过自然语言指令(如“把这朵花变成红色”)来修改图片,而不是重新生成。
看完以上内容,你是否掌握了后缀含义?下面我随便截了个模型名称的图,你看下是什么意思。
(二)模型下载
模型下载一般在 C站、huggingface 上下载。
你也可以把要下载的模型告诉AI,AI会告诉你如何下载,告诉你下载地址或者帮你下载下来。
例如我要下载juggernautXL_v9Rundiffusionphoto2.safetensors这个模型。
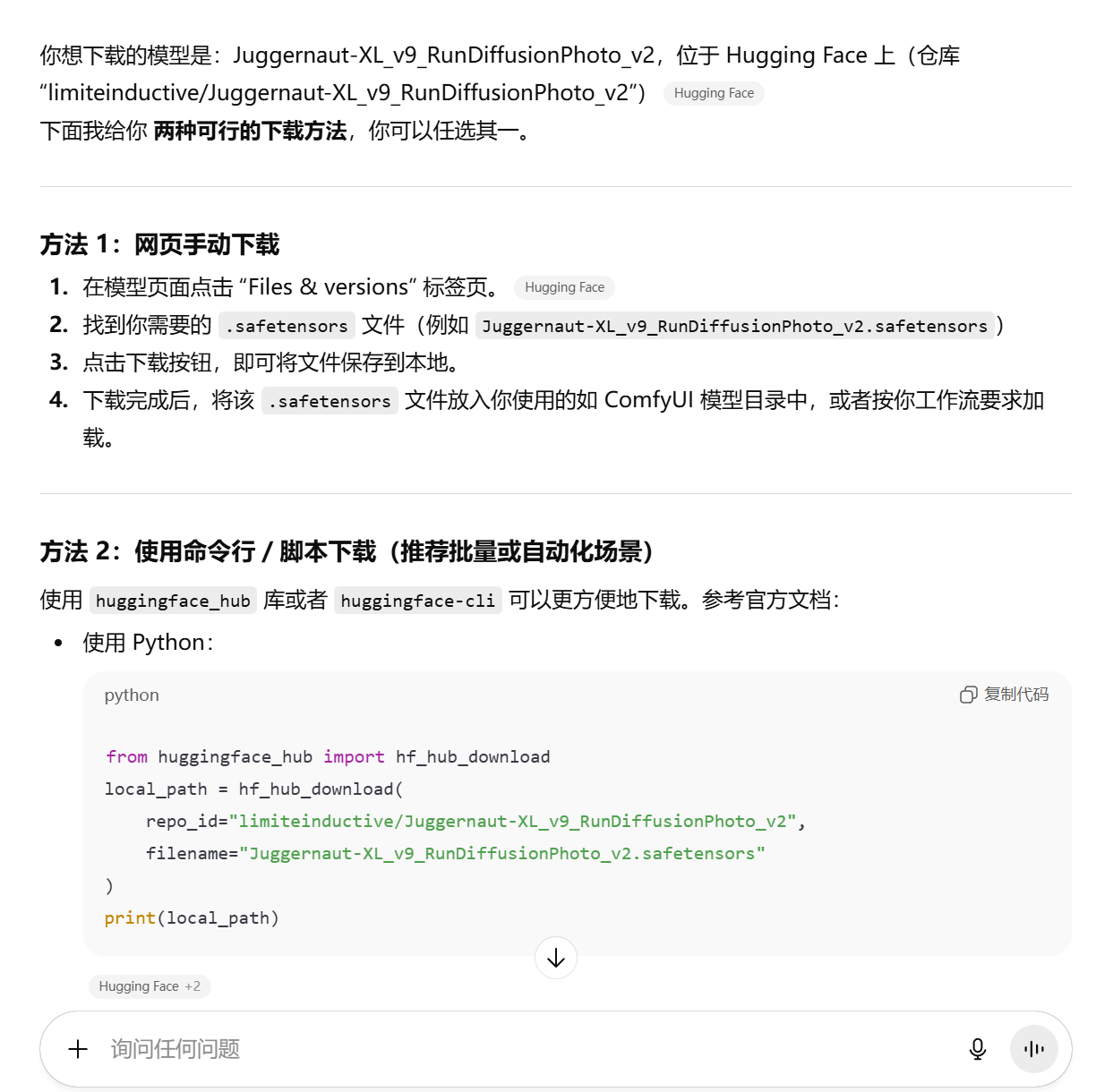
然后我让AI把这个模型下载下来。

(三)SD1.5模型
我刚开始接触AI绘画就使用的SD1.5模型。
SD1.5模型全称Stable Diffusion 1.5版本。
我之前写过两篇文章 AI画图Stable Diffusion web UI学习笔记(上) 和 AI画图Stable Diffusion web UI学习笔记(下)
感叹AI发展的好快,如今Stable Diffusion软件很少人在使用了。
1、文生图
一个基本的SD1.5模型文生图工作流如图所示:
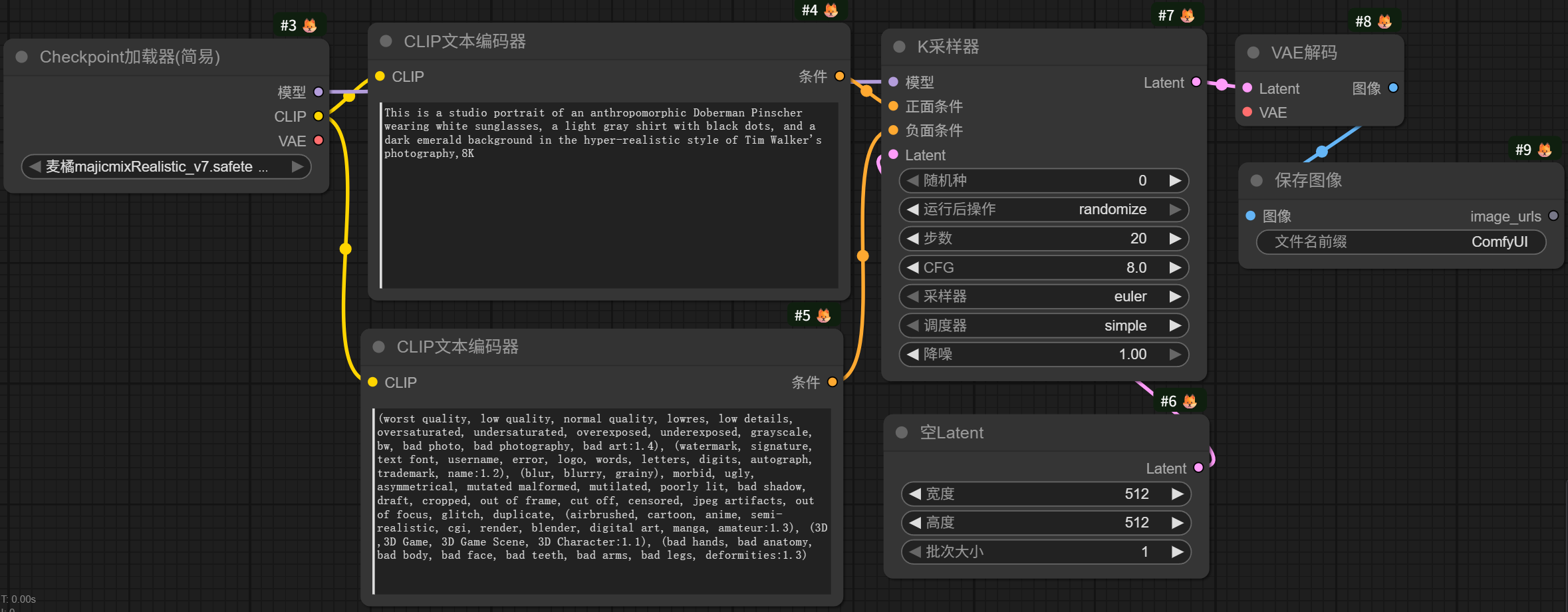
简单理解为:模型——提示词——K采样器——VAE解码——出图像。
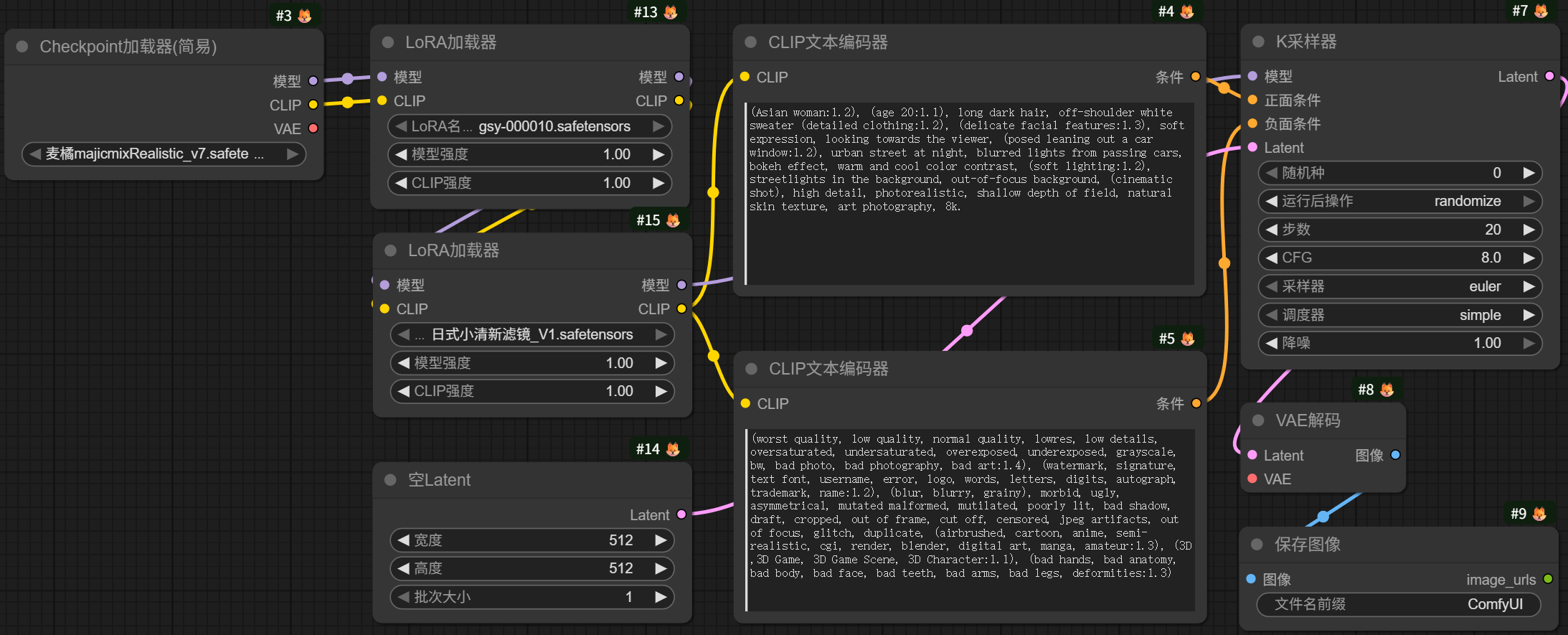
如果想要加载LoRA模型,如图所示:
2、图生图
一个基本的SD1.5模型图生图工作流如图所示:
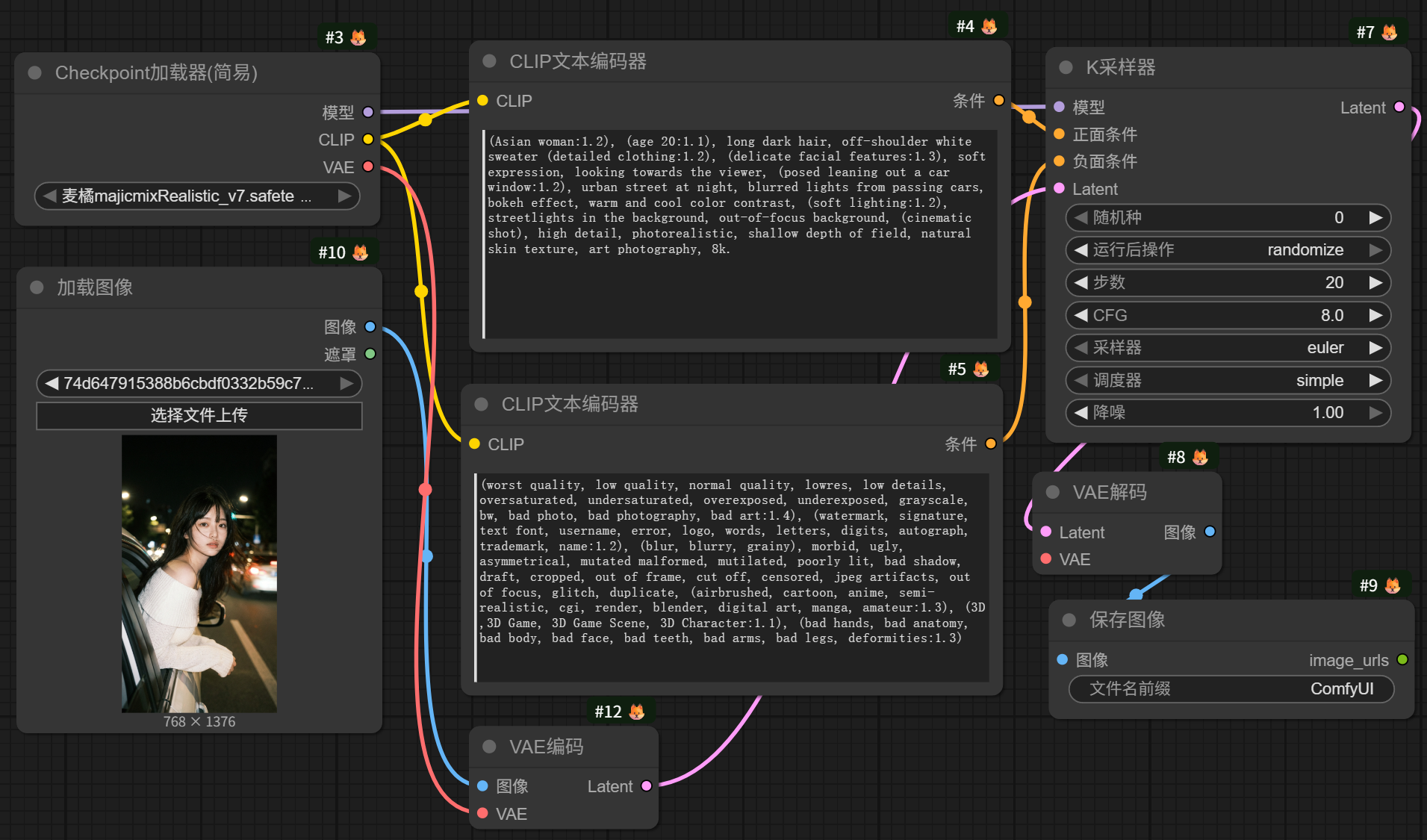
简单理解为:模型——加载图像——VAE编码——提示词——K采样器——VAE解码——出图像。
3、提示词
SD1.5模型的提示词尽量用单词或短句组成。
正向提示词推荐加上:This is a studio portrait of an anthropomorphic Doberman Pinscher wearing white sunglasses, a light gray shirt with black dots, and a dark emerald background in the hyper-realistic style of Tim Walker's photography,8K
反向提示词推荐为:(worst quality, low quality, normal quality, lowres, low details, oversaturated, undersaturated, overexposed, underexposed, grayscale, bw, bad photo, bad photography, bad art:1.4), (watermark, signature, text font, username, error, logo, words, letters, digits, autograph, trademark, name:1.2), (blur, blurry, grainy), morbid, ugly, asymmetrical, mutated malformed, mutilated, poorly lit, bad shadow, draft, cropped, out of frame, cut off, censored, jpeg artifacts, out of focus, glitch, duplicate, (airbrushed, cartoon, anime, semi-realistic, cgi, render, blender, digital art, manga, amateur:1.3), (3D ,3D Game, 3D Game Scene, 3D Character:1.1), (bad hands, bad anatomy, bad body, bad face, bad teeth, bad arms, bad legs, deformities:1.3)
或者:(worst quality, low quality:2), monochrome, zombie,overexposure, watermark,text,bad anatomy,bad hand,extra hands,extra fingers,too many fingers,fused fingers,bad arm,distorted arm,extra arms,fused arms,extra legs,missing leg,disembodied leg,extra nipples, detached arm, liquid hand,inverted hand,disembodied limb, oversized head,extra body,extra navel,easynegative,(hair between eyes),sketch, duplicate, ugly, huge eyes, text, logo, worst face, (bad and mutated hands:1.3), (blurry:2.0), horror, geometry, bad_prompt, (bad hands), (missing fingers), multiple limbs, bad anatomy, (interlocked fingers:1.2), Ugly Fingers, (extra digit and hands and fingers and legs and arms:1.4), (deformed fingers:1.2), (long fingers:1.2),(bad-artist-anime), bad-artist, bad hand, extra legs
4、ControlNet
在大量使用SD1.5模型时代,ControlNet插件是很厉害的,很多时候被用到。
运用场景例如图像风格转换(如真人图像转动漫图像),人物姿势固定生图,图片局部重绘,图片细节修复和高清放大等等。
ControlNet节点一般有三个:ControlNet应用、ControlNet加载器和ControlNet预处理器,例如如图所示:
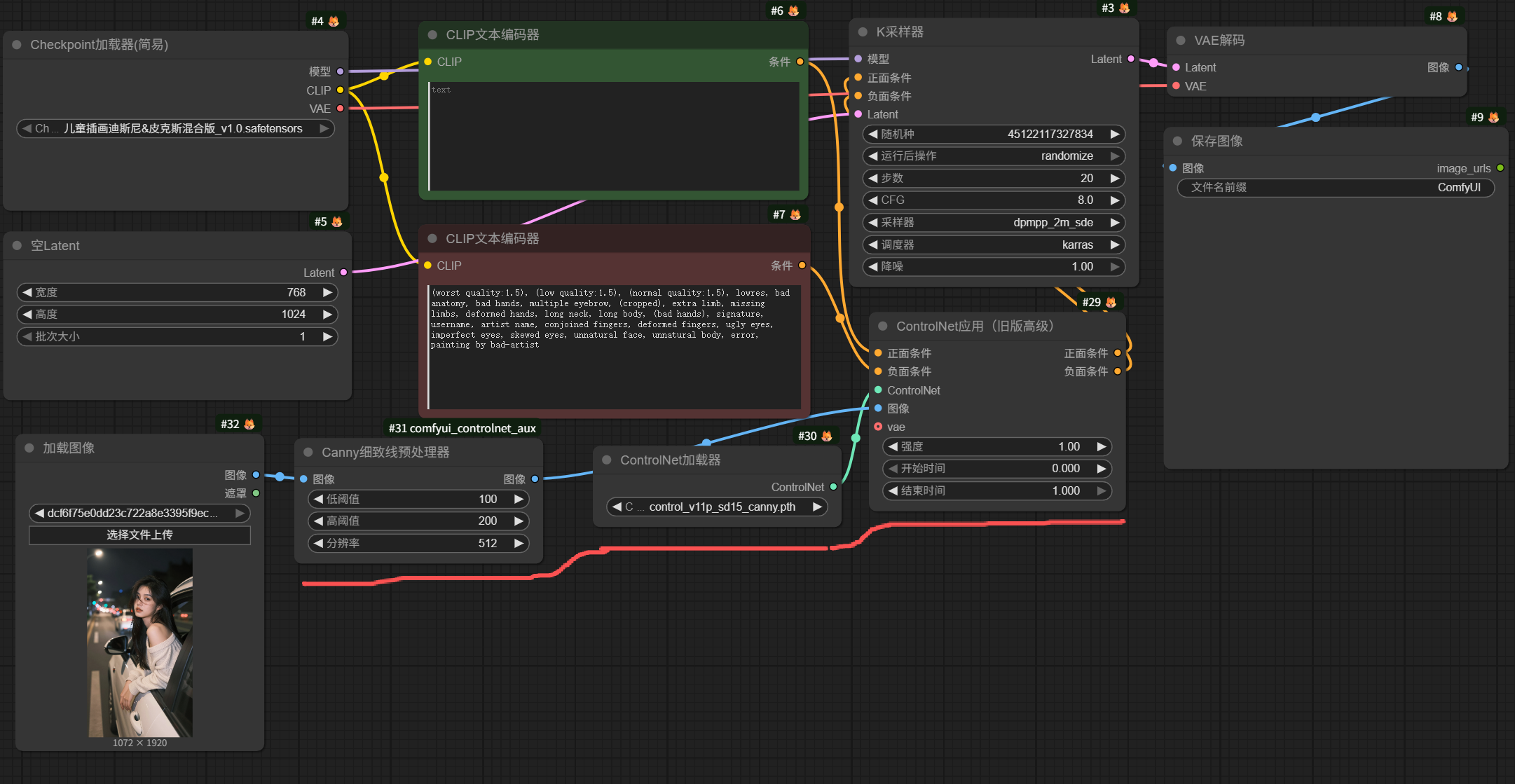
也有合在一起的节点:ControlNet-Union。
ControlNet包括Canny、Softedge、Scribble、Lineart、MLSD、Depth、OpenPose、Inpaint和Tile等节点。
(四)SDXL模型
SDXL模型比SD1.5模型在模型规模、生图质量、对提示词理解等方面更为强大。
SDXL模型包括Base模型和Refiner模型,其中Base模型负责基本的图像生成,Refiner模型负责对生成的图像进行精细化处理。
SDXL模型的提示词引导系数CFG不适合设置过高,会导致细节被过度增强影响图片。
SDXL模型的提示词尽量用句子组成。
1、文生图
一个基本的SDXL模型文生图工作流网上有两种版本。
一种如图所示:
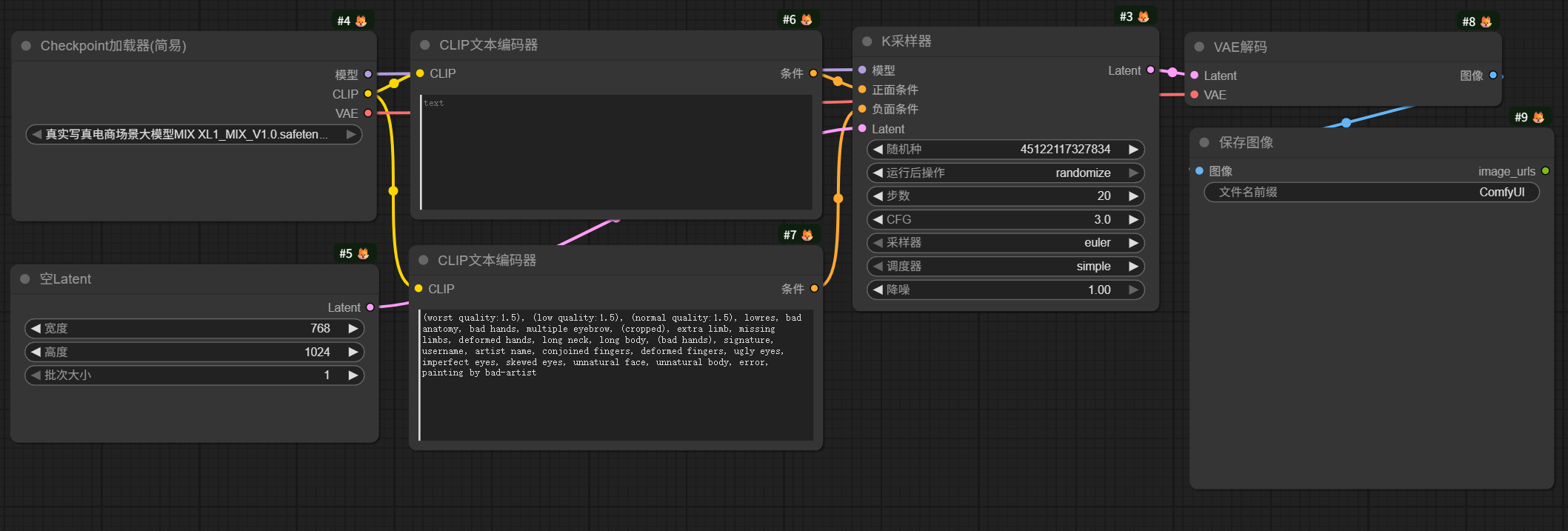
另一种如图所示:
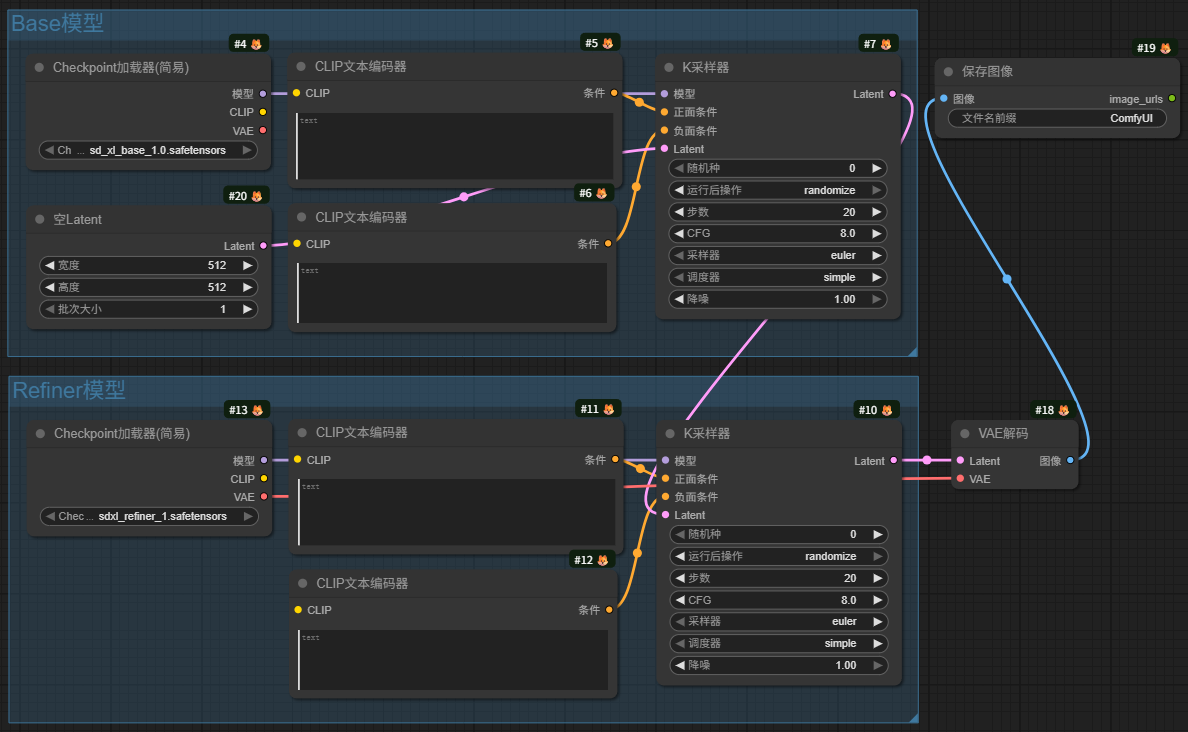
第二种是分别加载了Base模型和Refiner模型。
2、去水印
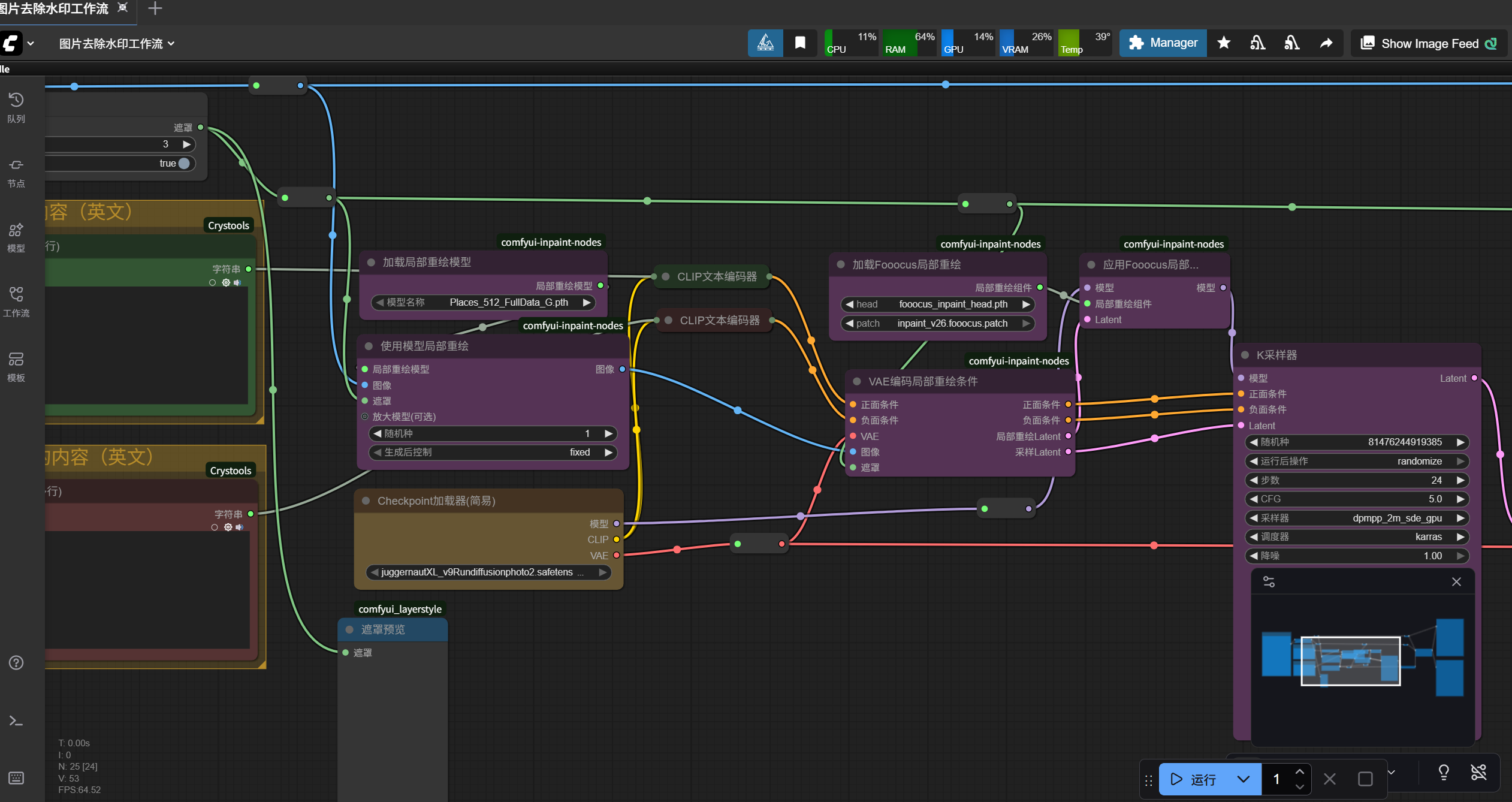
很多工作流、很多模型都可用来去水印,但是这里我推荐使用别人做的这个SDXL模型工作流,如图所示:
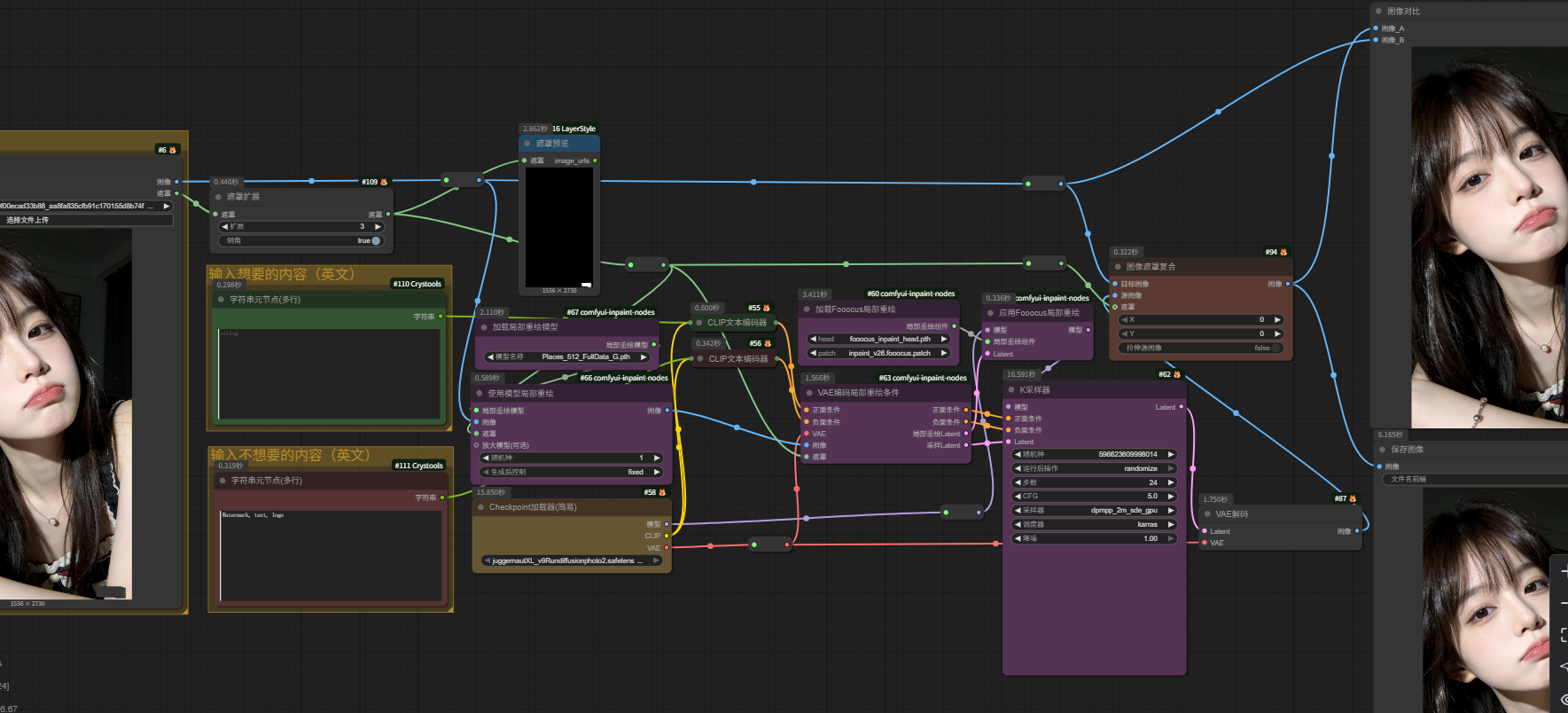
这个SDXL模型工作流是别人做的,去水印效果不错,比有的FLUX模型工作流去水印效果还要好,而且SDXL模型相比于其他模型对显卡要求没那么高,我自己本地电脑4060的N卡就能跑起来,工作流性价比高。
其中,该工作流用到的模型是这几个:
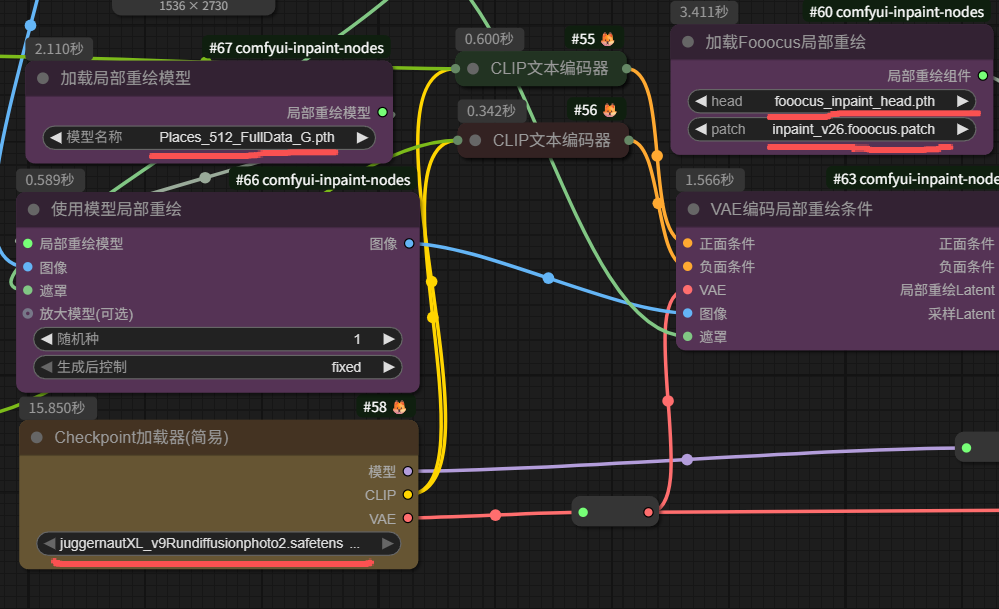
(五)FLUX模型
FLUX模型是黑森林实验室(Black Forest Labs)推出的模型,相比SDXL模型和SD1.5模型更为出色。
1、FLUX.1
首先可以在huggingface上查看FLIX.1信息:FLUX.1 - a black-forest-labs Collection
其次,FLUX.1 大致有这几个版本:Pro、Dev和Schnell。其中,Pro的性能最好,但仅可通过API访问。Dev为开源模型但非商业用途。Schnell是经过蒸馏的4步模型,可个人使用的开源模型。
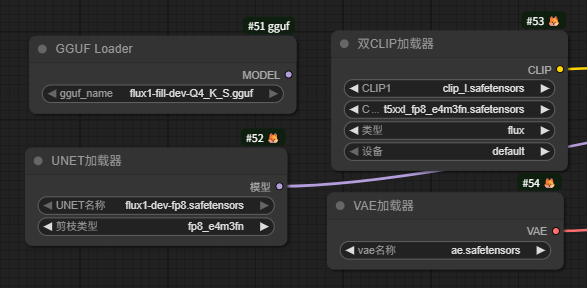
然后,在加载使用FLUX.1模型时,如果使用的是ComfyOrg-dev版本,使用Checkpoint加载器这个节点。
如果使用的是GGUF版的,需要使用GGUF Loader这个节点。
如果使用的是除上述外其他版本的模型,需要使用UNET加载器这个节点。
FLUX系列通常使用 t5xxl 和 clip_l 双重编码。如图所示:
同时,FLUX.1模型不支持反向提示词。
在UNET加载器节点中,有个剪枝类型,选项有default (默认)、fp8_e4m3fn、fp8_e5m2,建议使用fp8_e4m3fn,fp8_e4m3fn能将原本16位的数据压缩到8位,显存占用直接减半。
一个基本的FLUX.1模型文生图工作流如图所示:
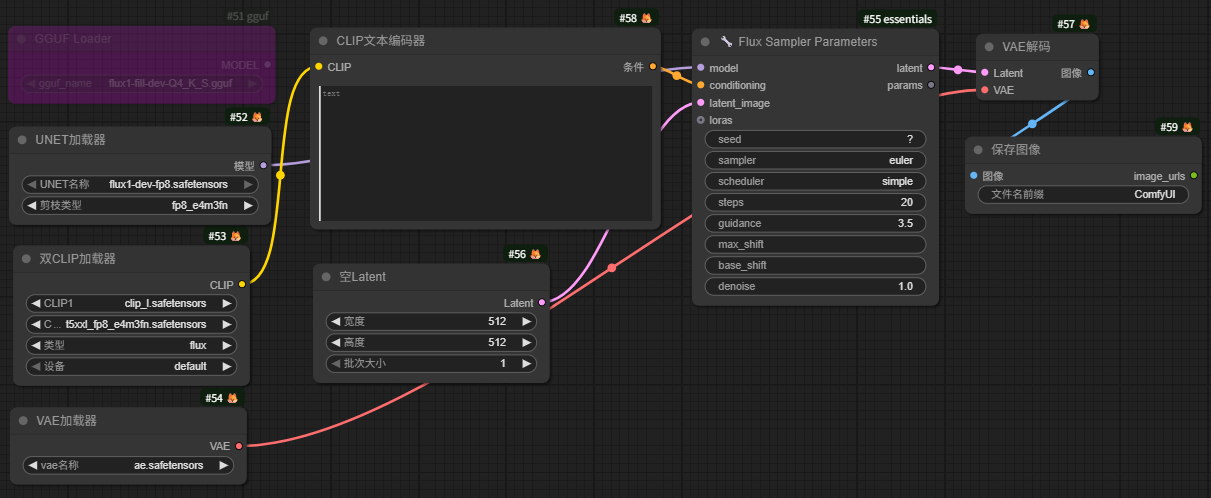
2、FLUX.2
首先可以在huggingface上查看FLIX.2信息:FLUX.2 - a black-forest-labs Collection
FLUX.2 也是大致有这几个版本:Pro、Dev和Schnell。其中,也是一样,Pro仅可通过API访问。Dev为开源模型但非商业用途,生成步数大致 20 - 50 步。Schnell为快速生成、本地低配部署,生成步数大致 4 - 8 步。
同时,和FLUX.1模型一样,FLUX.2模型也是不支持反向提示词。
提示词可以写成:人物主体+动作+图像风格+场景、光照、情绪、季节等。
一个基本的FLUX.2模型文生图工作流如图所示:
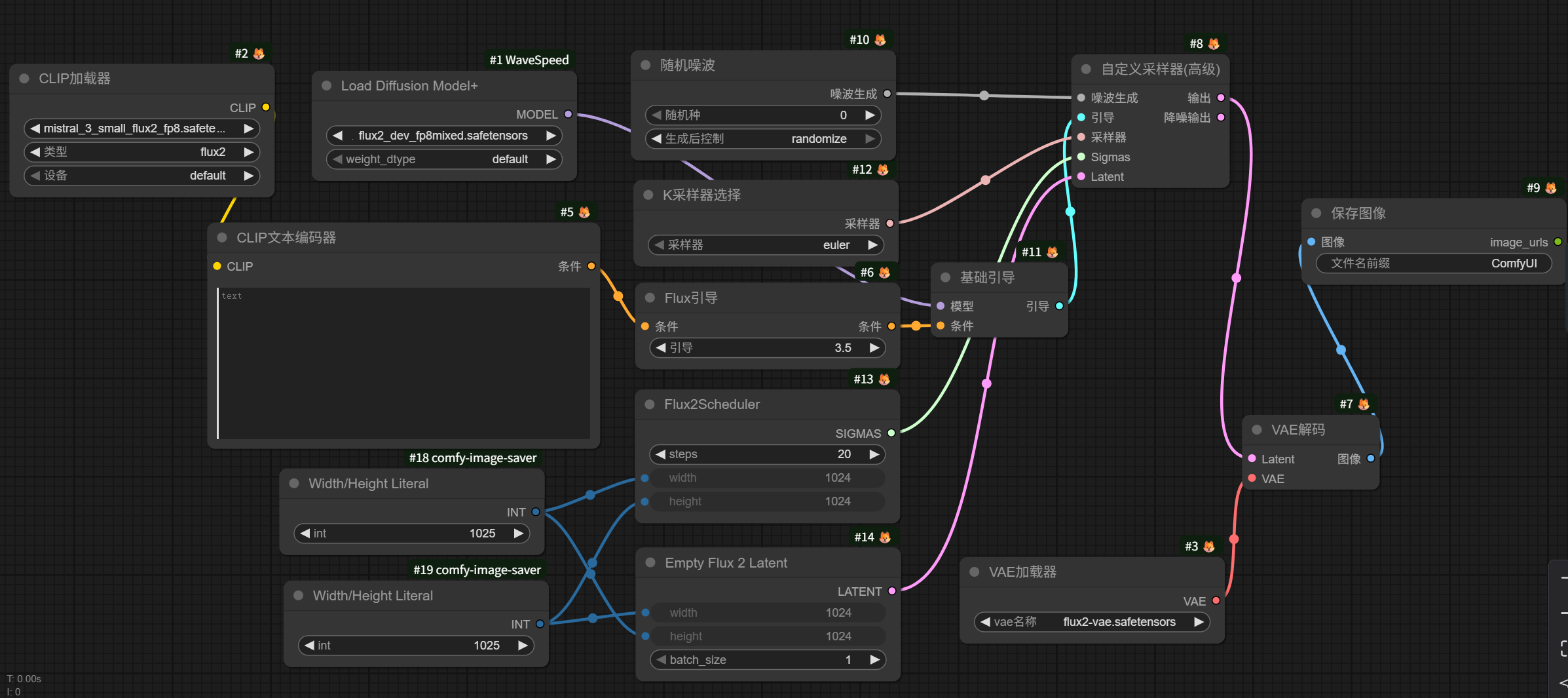
需要注意的是,这里有个 Flux2Scheduler 节点专用调度器,K采样器在选择采样方法时对图片生成影响不大,可以将 Flux2Scheduler 节点改成 BasicScheduler 节点。
3、FLUX.2 Klein
FLUX.2 Klein据说是当前图片编辑最厉害的,但AI发展的较快,可能过几个月就不是最厉害的了。
图片编辑就是修改图片、合成图片,比如公园里摆地摊AI修图的,将图片中的公园里人群给编辑没了。再比如让模特穿上服装,上传模特图、服装图和背景环境图,通过 FLUX.2 Klein模型生成结果。
废话不多说,一个简易图片编辑工作流如图所示:
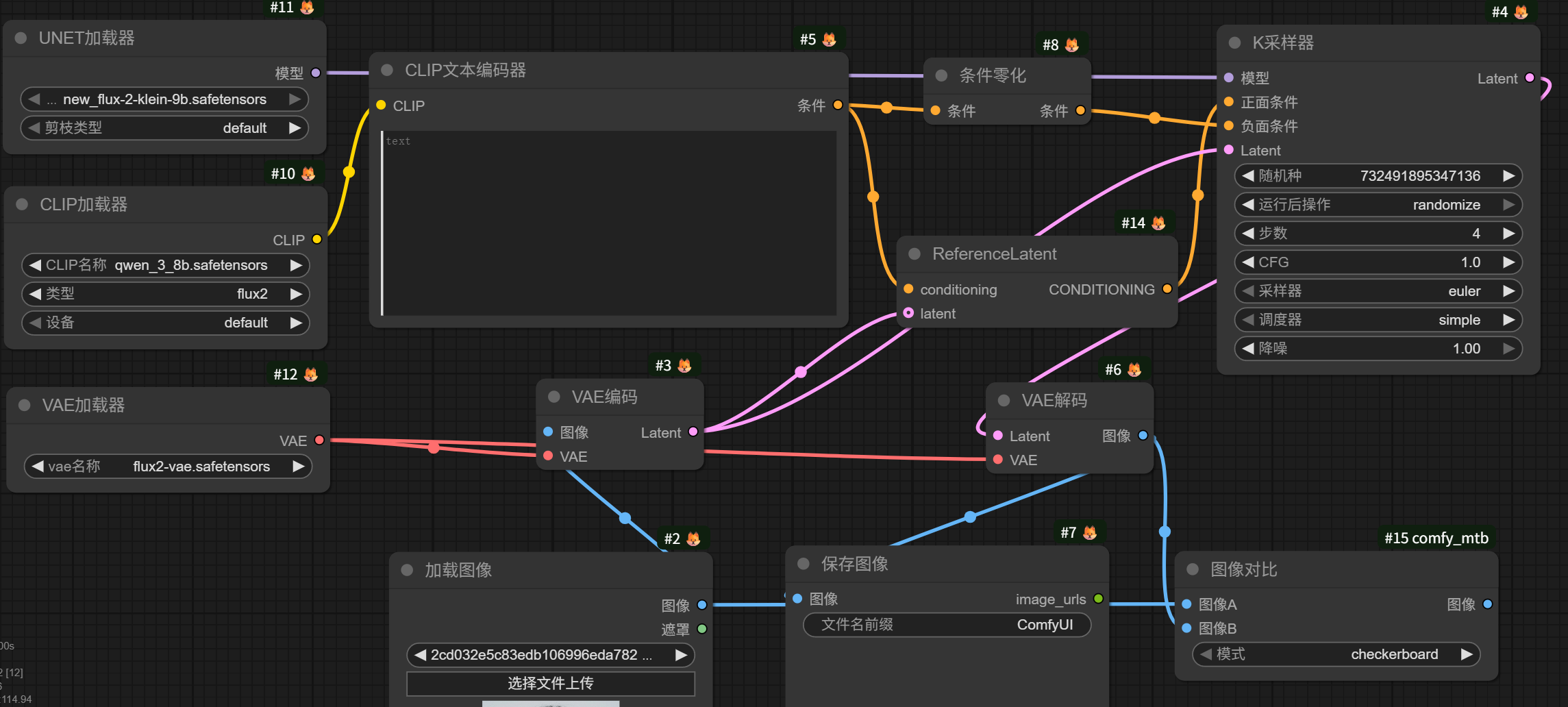
(六)千问模型
千问Qwen-Image模型是阿里巴巴研发的模型,分为图片生成和图片编辑两条线。
Qwen-Image模型相比Z-image模型可能更擅长语义逻辑、文字渲染,偏向设计。
1、图片生成
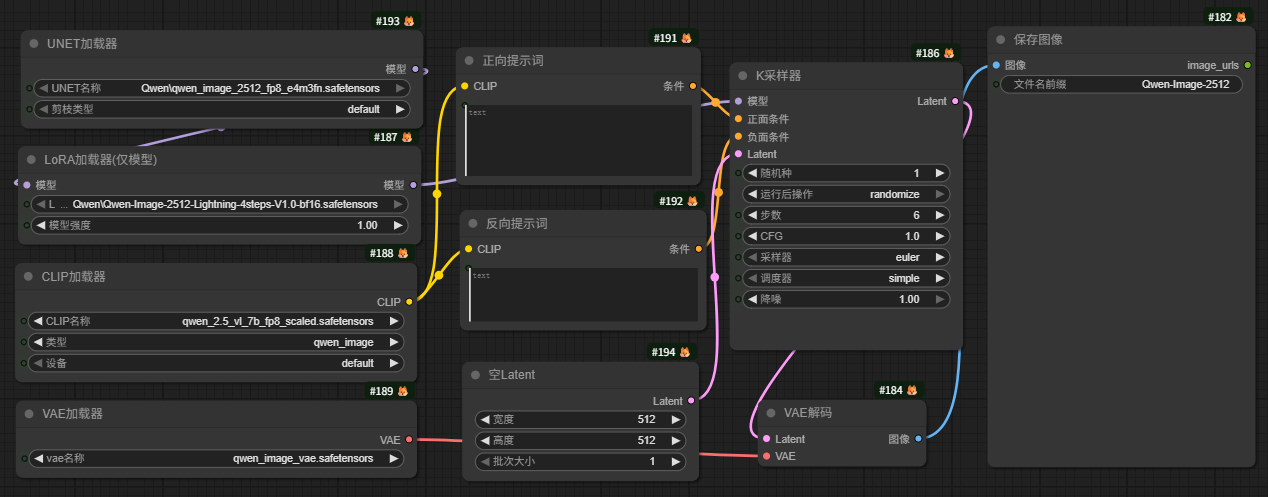
图片生成这条线当前最新版本是Qwen-Image-2512模型。
一个简易的Qwen-Image-2512模型文生图工作流如图所示:
2、图片编辑
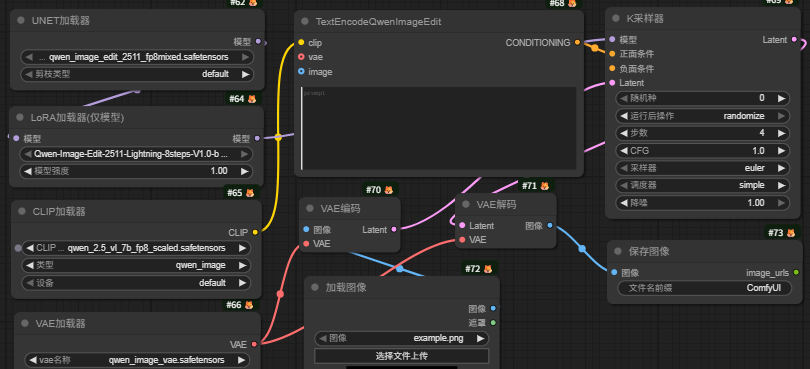
图片编辑这条线当前最新版本是Qwen-image-edit-202511模型。
一个简易的Qwen-image-edit-202511模型图片编辑工作流如图所示:
(七)Z-image模型
Z-image模型是阿里巴巴研发的模型。
目前Z-image模型分为两个版本: Z-Image-Turbo 和 Z-Image-Base。
Z-Image-Turbo是高效精简版,特性8步出图,快速绘画。
Z-Image-Base是未经蒸馏的基础模型,拥有更强的提示词遵循能力和风格可塑性。
Z-image模型相比Qwen-image模型可能更擅长视觉美学、摄影质感,偏向摄影。
作为国产模型,相比于FLUX等国外模型,Z-Image 在处理东亚人像时具有天然优势。
一个基本的Z-image模型文生图工作流如图所示:
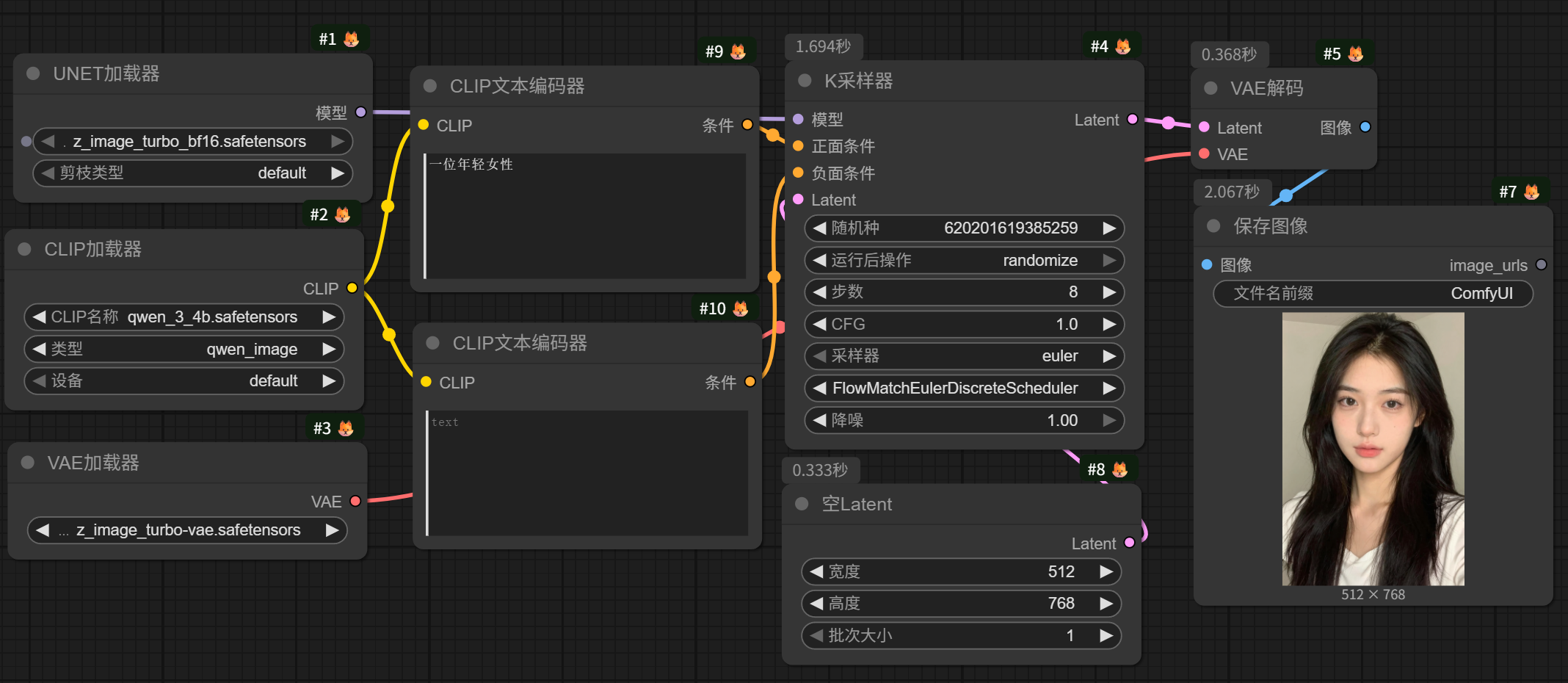
值得注意,Z-image模型有个官方的调度器FlowMatchEulerDiscreteScheduler。
四、ComfyUI生视频
AI绘画发展的太快了,当前技术已经成熟,我认为很厉害了,画的图像接近真实。
众所周知,视频是由一张张图片(帧)组成。AI视频也在快速发展。
按照历史发展经验,在自媒体方面先是以小红书、微信推文、知乎等平台为代表的图文内容爆火起来,之后才是以抖音、快手、微信视频号等平台为代表的视频内容爆火。
AI发展也有这个趋势,从AI绘画爆火到AI视频爆火。
所以将关注重心、学习重心从AI绘画迁移到AI视频是有必要的。
AI视频和AI绘画类似,可以在线上平台上搞,也可以下载开源模型借助ComfyUI在线下本地电脑上搞。
这里以线上RunningHub平台为例,对ComfyUI生视频进行介绍:
(一)Sora2
Sora2在2025年10月爆火,生成视频质量当时也出众。
然后在RunningHub平台上,使用Sora2的API,有每天免费5次文生视频和免费5次图生视频,视频时长10秒。
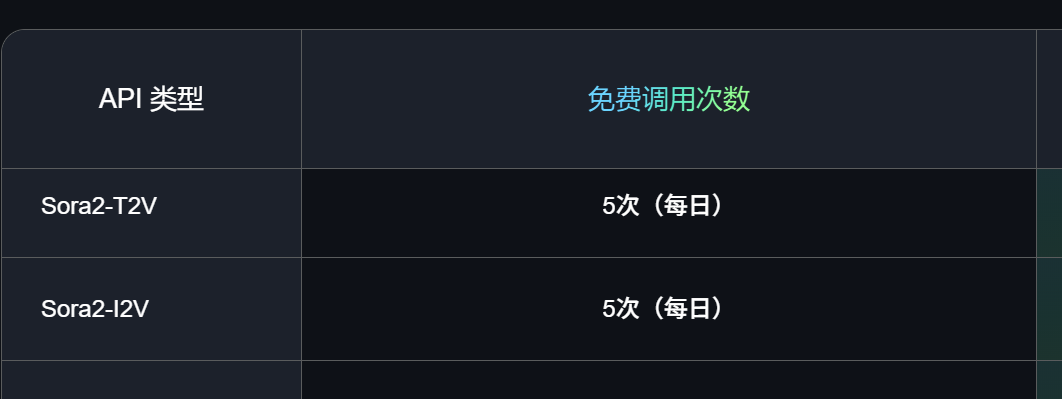
5次免费持续了很长时间,而且生成的视频没有水印。
一个简易Sora2文生视频和图生视频工作流如图所示:
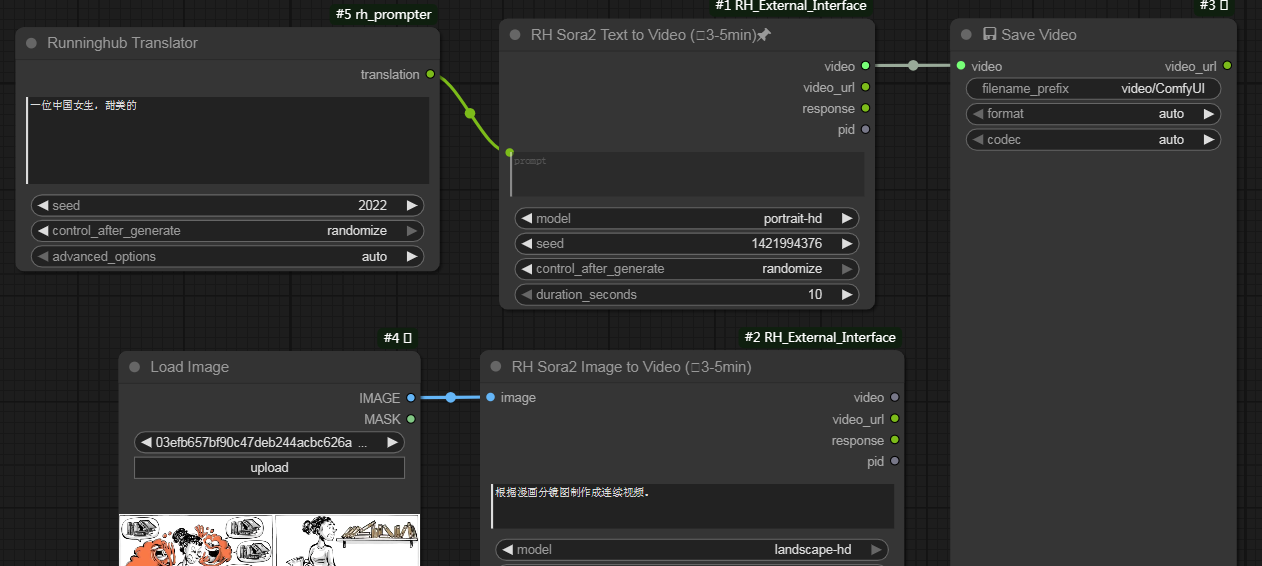
但现在被改了,没有免费,Sora2这个节点好像被改成全能视频S,但还不能用,说是目前第三方路线有问题还未恢复。
就暂时不进行叙述了,等平台问题恢复了再补充。
如果你在Sora2平台上生成视频,也可以使用去水印工作流。
在RunningHub平台上可以搜到很多去水印工作流,注意找11月17日更新之后的去水印工作流,效果才好。
(二)通义万相
通义万相模型是阿里巴巴研发的模型,相比Sora2模型是开源的,可以下载使用。
当前,通义万相模型有三个重要的版本,分别为万相2.2版本、万相2.5版本和万相2.6版本。
通义万相 2.2(Wan 2.2)版本常用来做动作迁移,比如说模仿抖音美女跳舞动作迁移。
动作迁移分为单人(Animate)和多人(Scale)。
RunningHub平台上有很多Wan 2.2 Animate和Wan 2.2 Scale的工作流,而且有换人不换背景、人和背景一起换、不换人换背景的,这里就不展示了。
通义万相 2.5(Wan 2.5)版本相比Wan 2.2补全了视频声音,原生音频同步。
同时Wan 2.5引入了 Fast Mode (极速模式),通过蒸馏技术,它牺牲了微小的细节,换取了极快的生成速度。
RunningHub平台上有很多Wan 2.5的工作流,这里就不展示了。
通义万相 2.6(Wan 2.6)版本解决长叙事和多镜头一致性问题,单指令多镜头和现实绘R2V (Real-to-Video)。
当然除了Sora2和通义万相,还有其他AI视频生成。
结尾碎碎念:
AI发展的太快了,几个月就大变样。
当然,新出的模型需要花时间去研究,在ComfyUI工作流上反复去试验。
使用的同一个模型,为什么别人画的好,你画的不好,你有没有深入研究了。
这是问题所在。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)