【2026最新版】AI聊天助手开发笔记(超详细,含源码)
本文介绍了大语言模型(LLM)的基础知识及其应用开发实践。首先概述了LLM的核心能力,包括语言理解、逻辑推理和生成能力。然后详细讲解了本地部署大模型工具Ollama的使用方法,包括安装配置、模型管理和API调用。接着通过Streamlit框架开发了一个完整的AI聊天助手应用,实现了会话记忆、流式输出、侧边栏交互等功能,并采用JSON格式存储会话历史。最后展示了完整的Python代码实现,包括会话管

一、AI应用-概述
-
全称:大语言模型(Large Language Models, LLM)
-
本质:一种通过代码与算法模拟人脑神经网络的计算机程序
-
参数量级:通常达到数十亿至数千亿级别
-
核心能力:通过大规模数据训练,具备以下能力:
-
理解人类语言
-
进行逻辑思考与推理
-
生成符合语境的语言输出
-
AI应用:是指将AI大模型技术落地到具体的业务场景中,用来解决实际问题的产品或服务。
二、AI应用-基础
1.大模型的部署-本地部署
Ollama是一个在本地运行、管理大语言模型的工具。官网:
https://ollama.com/
默认安装:
下载后双击即可安装,默认是安装在C盘的,具体目录如下:
-
默认安装后目录:C:\Users\用户名\AppData\Local\Programs\Ollama
-
默认安装模型目录:C:\Users\用户名\.ollama
-
默认配置文件目录:C:\Users\用户名\AppData\Local\Ollama
自定义安装:
可以参考本文:Ollama完整部署指南:Win版安装(含路径修改)![]() https://blog.csdn.net/2401_87660168/article/details/159417425deepseek-r1链接:https://ollama.com/library/deepseek-r1
https://blog.csdn.net/2401_87660168/article/details/159417425deepseek-r1链接:https://ollama.com/library/deepseek-r1
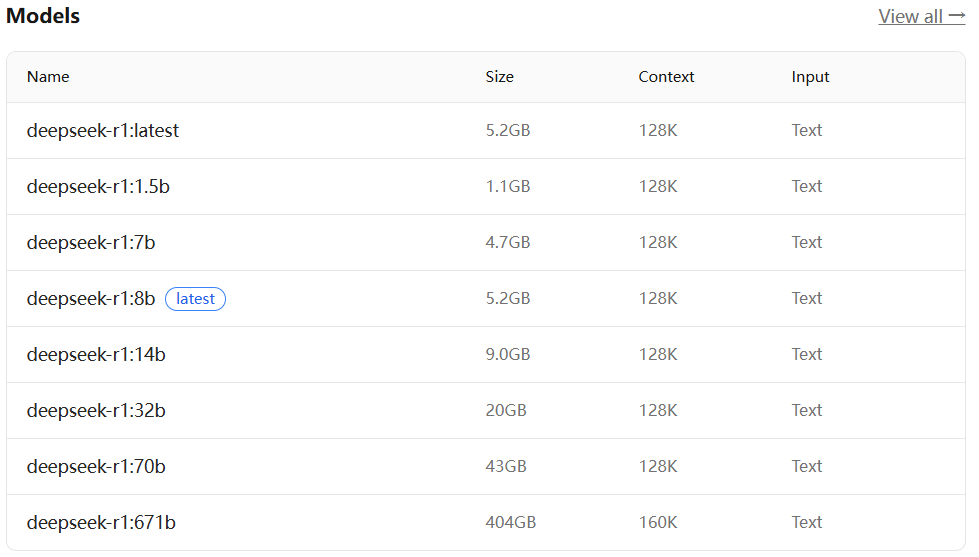
需要几分钟,部署完成。

2.大模型的调用-官方API
1.网络基础知识
1.IP 地址
1. 定义
-
IP地址是联网设备在互联网中的唯一标识,用于定位设备位置。
-
相当于设备的“互联网身份证”。
2. IPv4 地址
-
由 32位二进制数 组成,通常以点分十进制表示。
-
格式:
xxx.xxx.xxx.xxx(每个xxx范围为 0–255)。 -
示例:
-
十进制:
132.12.86.125 -
二进制:
10000100.00001100.01010110.01111101
-
3. IPv6 地址
-
由 128位二进制数 组成,用于解决 IPv4 地址耗尽问题。
-
格式为八组十六进制数,如:
2001:0db8:85a3:0000:0000:8a2e:0370:7334
4. 特殊 IP 地址
-
127.0.0.1:本地回环地址,指向本机,常用于本地测试。
2.域名与 DNS
1. 域名
-
由一串用点分隔的英文字母组成,便于人类记忆。
-
示例:
www.baidu.com
2. DNS(域名解析服务器)
-
作用:将域名转换为对应的 IP 地址。
-
工作流程:
用户输入域名 → DNS 查询 → 返回 IP 地址 → 访问目标服务器
-
示例:
-
域名:
www.baidu.com -
对应 IP:
110.242.69.21
-
3. 多 IP 映射
-
一个域名可对应多个 IP 地址,实现负载均衡与容灾。
示例:百度可能对应多个服务器 IP: 110.242.69.21
103.217.86.45
183.62.66.173
...
3.端口号
1. 定义
-
端口号是 0–65535 之间的整数,用于标识设备中运行的程序(服务)。
-
一个 IP 地址 + 一个端口号 = 一个具体的网络服务。
2. 常见端口
-
80:HTTP(网页浏览) -
443:HTTPS(加密网页) -
22:SSH(安全登录) -
3306:MySQL 数据库
3. 完整访问格式
协议://域名(或IP):端口
4.网络访问流程示例
用户输入:www.baidu.com
↓
DNS 解析为:110.242.69.21
↓
通过端口 443(HTTPS)访问
↓
到达百度服务器,返回网页内容
2.网络模型
1. 为什么需要网络模型
-
互联网连接数十亿设备,需要统一标准确保数据有序传输
-
类似城市交通系统需要交通规则来管理车流
-
ISO国际标准化组织制定了网络通信的统一标准
2. 两种主要网络模型
-
OSI七层模型:理论标准模型,全球网络互连基准
-
TCP/IP四层模型:实际应用模型,OSI的简化实用版本
3.HTTP协议
1. 基本概念
-
全称:Hyper Text Transfer Protocol(超文本传输协议)
-
作用:规定客户端和服务器之间数据传输的规则
-
核心:统一的请求-响应格式,确保通信双方能相互理解
2. HTTP工作模型

3.Apifox测试
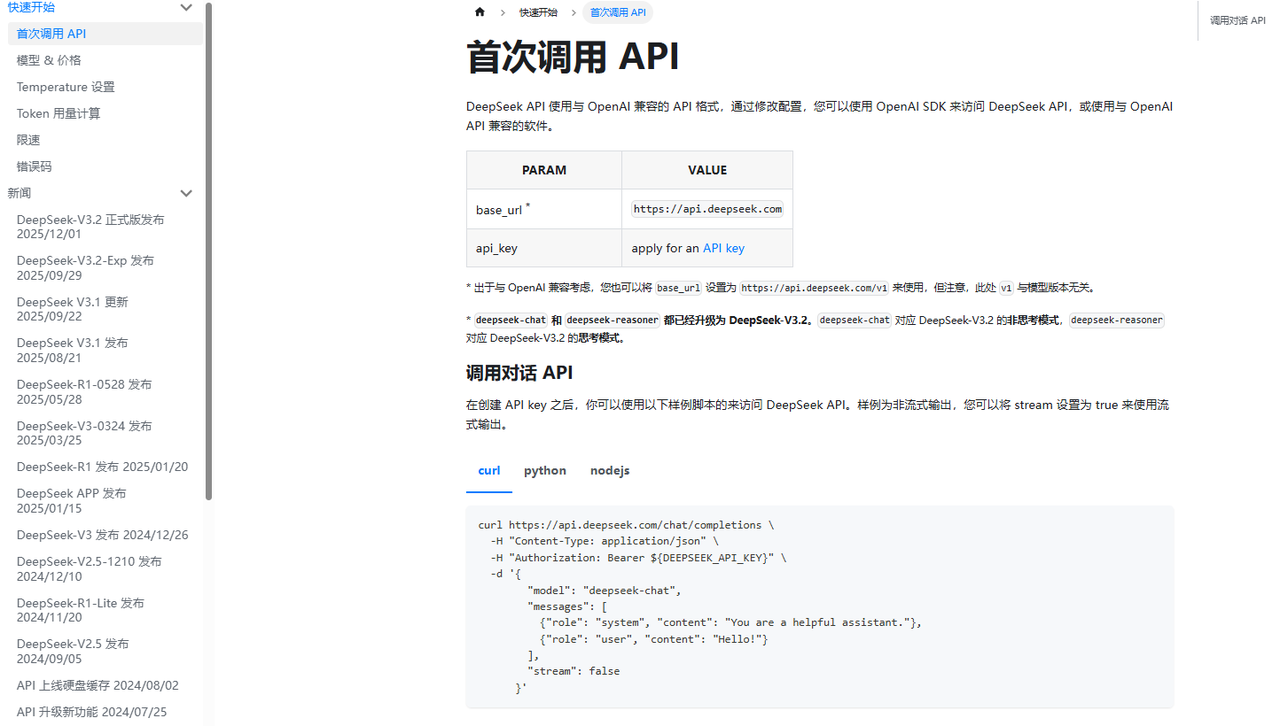
按照以下代码,在Apifox填写测试
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${DEEPSEEK_API_KEY}" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
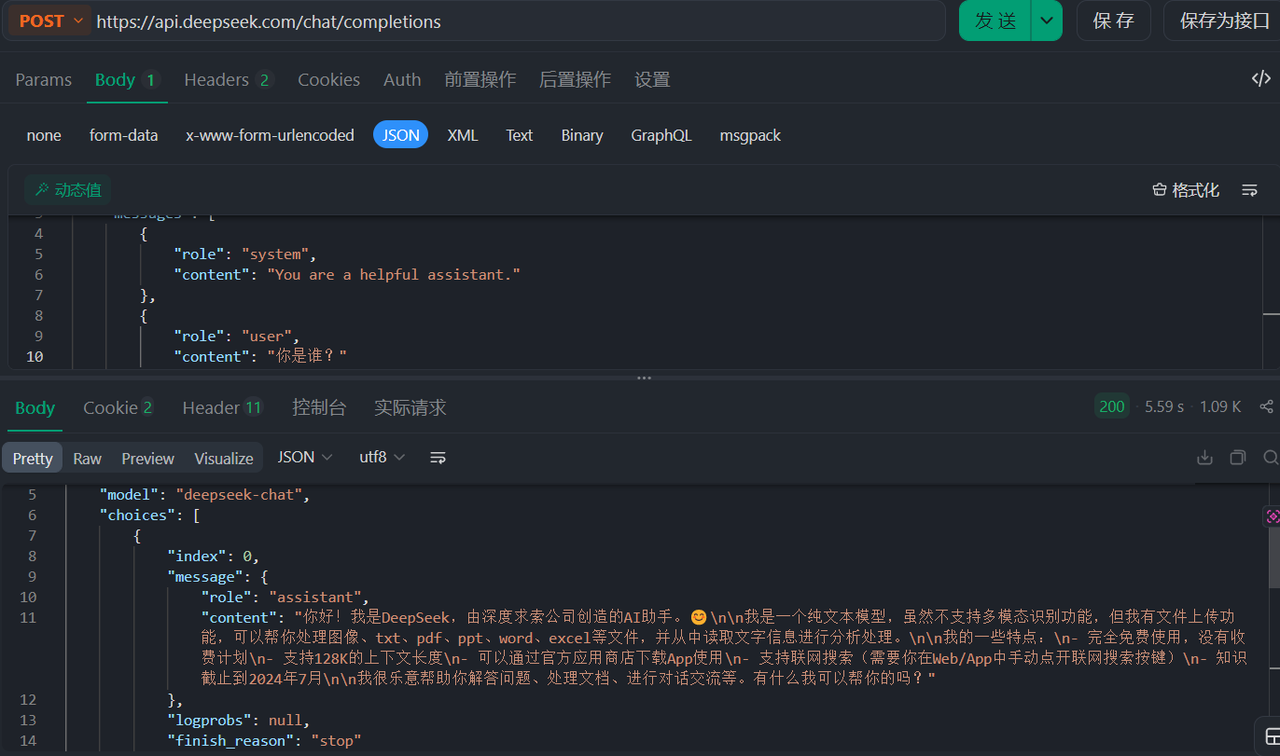
}'
4.会话记忆(会话历史滚雪球)
单次请求是没有记忆的,因此需要会话记忆来衔接之前的对话
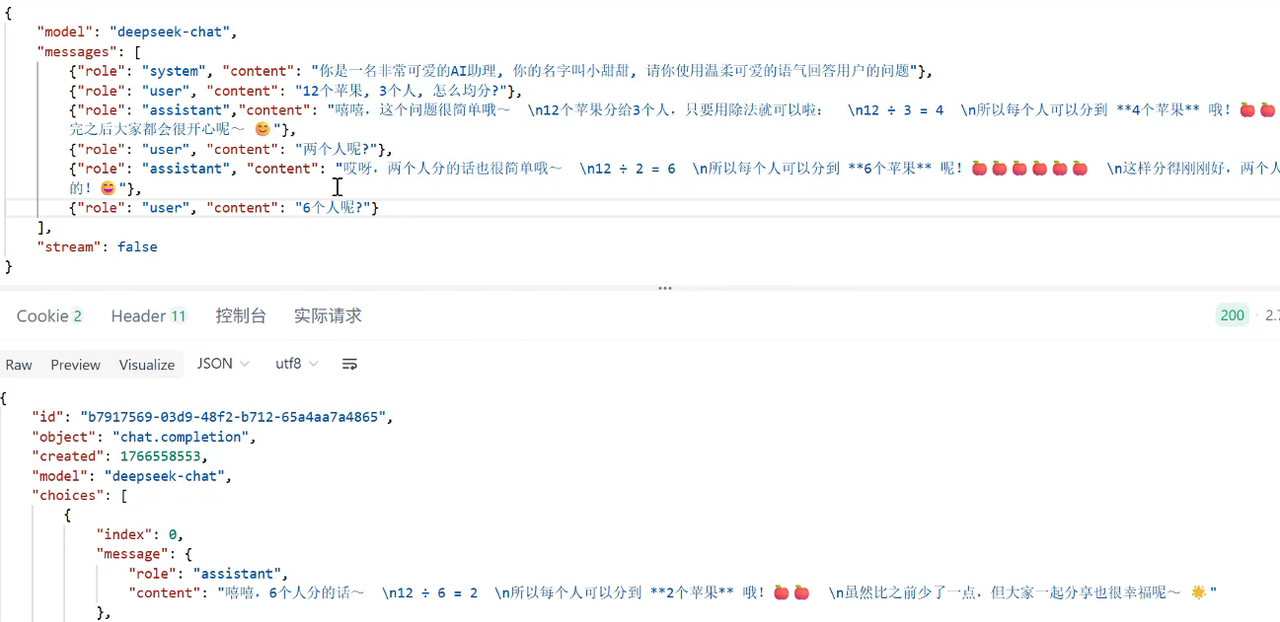

5.调用本地部署的大模型
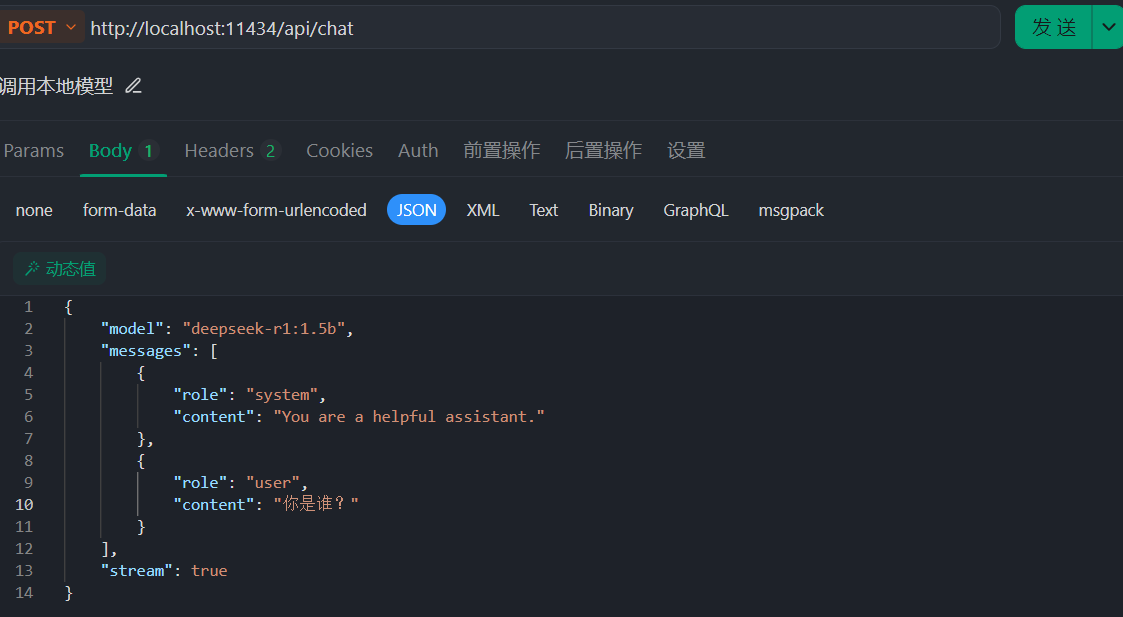
6.代码调用大模型
需要自行配置DEEPSEEK_API_KEY环境变量,另外需要安装openai的包。
如何安装第三方的软件包?
-
安装软件包(最新版):
pip install openai -
安装软件包(指定版本):
pip install openai=2.13.0 -
卸载软件包:
pip uninstall openai -
列出已安装的包:
pip list -
查看包详情:
pip show openai
import os
from openai import OpenAI
# 创建OpenAI客户端
client = OpenAI(api_key=os.environ.get('DEEPSEEK_API_KEY'),
base_url="https://api.deepseek.com")
# 创建聊天
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是一个AI助手,请用专业的语言来回答问题!"},
{"role": "user", "content": "你可以帮我干什么?"},
],
stream=False
)
# 输出聊天结果
print(response.choices[0].message.content)3.提示词工程
提示词工程,简单来说,就是精心设计和优化输入给AI的指令或问题(即“提示词”),以引导AI生成更准确、相关、高质量或符合特定需求的输出的过程。
你可以把它理解为:
-
对用户而言:是与AI高效沟通的艺术和科学。
-
对开发者而言:是开发和优化AI应用的核心技能。
为什么它如此重要?
-
Garbage In, Garbage Out:AI非常强大,但它的输出质量极大地依赖于你输入的质量。模糊的问题会得到模糊的答案,精准的提问才能获得精准的结果。
-
解锁AI的全部潜力:好的提示词能激发模型更深层次的推理、创造和组织能力,而不仅仅是浅层的问答。
-
节省时间和成本:一次到位的提示,可以避免反复修改、重新生成,大大提高工作效率。
-
实现复杂任务:通过特定的提示技巧,可以让AI扮演角色、分步思考、遵循特定格式等,完成写代码、创作剧本、数据分析等复杂工作。
提示词工程的核心原则与技巧
-
清晰具体:避免模糊。明确你想要什么,包括长度、格式、风格、受众等。
例如:不说“总结文章”,而说“用三个要点总结这篇文章的核心论点,每点不超过20字。” -
提供上下文和角色:给AI一个“身份”,能显著改变其回应方式。
例如:“你是一位经验丰富的产品经理...”、“你是一位幽默的脱口秀编剧...” -
使用结构化和分隔符:用“###”、“””、序号等将指令、背景、输入数据分开,帮助AI更好地理解结构。
例如:背景:{这里放背景信息} 问题:{这里放具体问题} 要求:{这里放格式要求} -
分步思考(Chain-of-Thought):对于复杂问题,引导AI一步步推理,而不是直接要答案。例如:“请按以下步骤解答:首先,分析问题中的关键数据;其次,确定适用的公式;最后,计算出结果并检查。”
-
提供示例(Few-Shot Learning):给出1-2个输入输出的例子,让AI快速模仿你想要的格式和风格。
-
迭代优化:很少有提示词能一次完美。根据AI的第一次回复,调整你的提示词,不断优化。
三、AI应用-实战(聊天助手)
1.Streamlit
Streamlit是一个开源Python库,专为数据工程师及机器学习工程师设计,用来快速基于Python代码构建交互式的web网站。
官方网站:
https://streamlit.io/
-
安装streamlit:
pip install streamlit -
在python文件中引入streamlit模块
-
基于streamlit中提供的API构建Web应用
-
运行程序:
streamlit run xxx.py
1.入门示例
import streamlit as st
# 标题
st.title('大标题')
st.header('一级标题')
st.subheader('二级标题')2.基础用法
官方API:
https://docs.streamlit.io/develop/api-reference
import streamlit as st
# 设置页面配置
st.set_page_config(
page_title="streamlit入门",
page_icon="🧊",
# 页面布局
layout="wide",
# 侧边栏状态
initial_sidebar_state="expanded",
menu_items={
'Get Help': 'https://www.extremelycoolapp.com/help',
'Report a bug': "https://www.extremelycoolapp.com/bug",
'About': "# 这是一个页面简介"
}
)
# 标题
st.title('大标题')
st.header('一级标题')
st.subheader('二级标题')
# 段落文字
st.write('段落文字zzzzzzzzzzzzzzzzzzzzzzzzzzzzz')
st.write('段落文字2aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa')
# 图片
st.image('https://docs.streamlit.io/images/api/image.jpg',width=300)
# 音频
st.audio('https://www123.mp3')
# 视频
st.video('https://files.youth.cn/video/zq_video/202601/P020260126366754940955.mp4')
# logo
st.logo('https://static.streamlit.io/examples/cat.jpg')
# 表格
people_data={'name':['张三','李四'],'age':[18,19],'sex':['男','女']}
st.table(people_data)
# 输入框
# https://docs.streamlit.io/develop/api-reference/widgets/st.text_input
name = st.text_input('请输入你的名字:')
st.write('你的名字是:',name)
password = st.text_input('请输入你的密码:',type='password')
st.write('你的密码是:',password)
# 单选按钮
sex = st.radio('请选择你的性别:',('男','女'))2.交互功能
emoji表情包网站:https://emoji8.com/zh-hans/
1.会话记忆
通过session_state来进行缓存,存储方式字典方式。
import streamlit as st
import os
from openai import OpenAI
st.set_page_config(
page_title="AI聊天助手",
page_icon="🎇",
layout="wide",
initial_sidebar_state="expanded",
menu_items={
}
)
# 标题
st.title('AI聊天助手')
# logo
st.logo('aislogo.png')
# 系统提示词
system_prompt = "你是一个AI助手,请用柔和可爱的语气来回答问题!"
# 存储聊天记录
if 'messages' not in st.session_state:
st.session_state.messages = []
# 显示聊天记录
for message in st.session_state['messages']:
# if message['role'] == 'user':
# st.chat_message("user").write(message['content'])
# else:
# st.chat_message("assistant").write(message['content'])
st.chat_message(message['role']).write(message['content'])
# 输入框
prompt = st.chat_input("请输入你的问题:")
if prompt:# 字符串会转为布尔值,如果字符串非空,则返回True
st.chat_message("user").write(prompt)
print("-------->调用AI大模型,prompt:", prompt)
# 添加用户输入
st.session_state['messages'].append({"role": "user", "content": prompt})
#调用AI大模型
client = OpenAI(api_key=os.environ.get('DEEPSEEK_API_KEY'),
base_url="https://api.deepseek.com")
# 创建聊天
print("-------->创建聊天")
print([
{"role": "system", "content": system_prompt},
*st.session_state.messages
])
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
*st.session_state.messages # 解包,对话记录
],
stream=False
)
print("<--------大模型返回消息",response.choices[0].message.content)
st.chat_message("assistant").write(response.choices[0].message.content)
# 添加AI大模型返回
st.session_state['messages'].append({"role": "assistant", "content": response.choices[0].message.content})2.流式输出
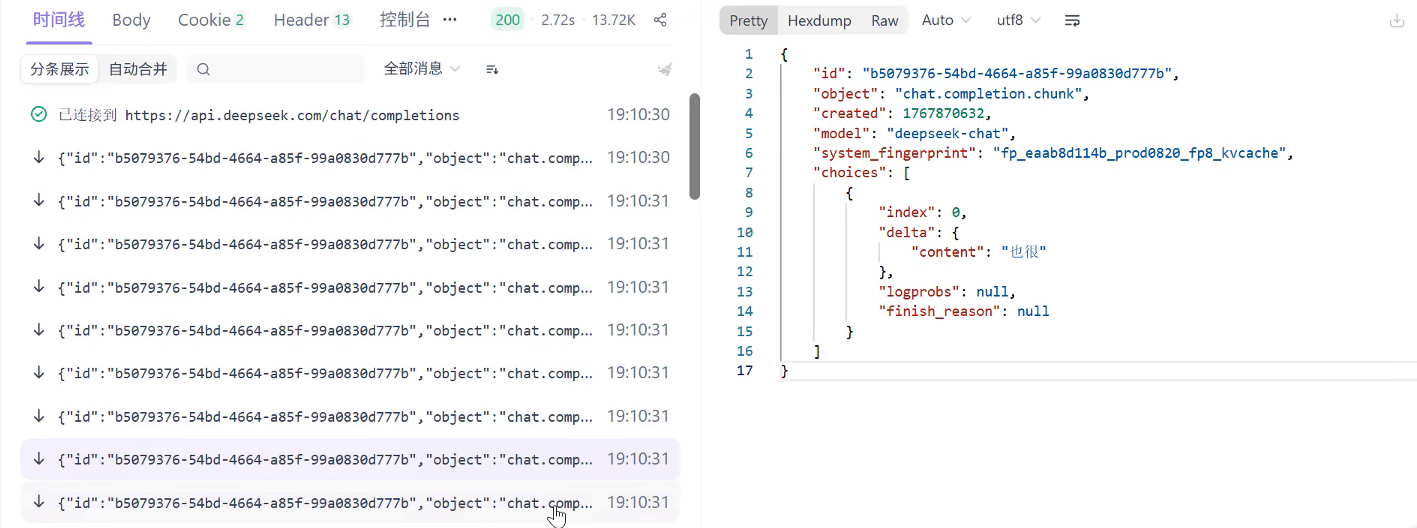
在进行流式输出时,大模型是一次返回几个字,需要进行字符串拼接,通过一个容器response_message来维护这个字符串。
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
*st.session_state.messages # 解包,对话记录
],
stream=True
)
# print("<--------大模型返回消息",response.choices[0].message.content)
# st.chat_message("assistant").write(response.choices[0].message.content)
# # 添加AI大模型返回
# st.session_state['messages'].append({"role": "assistant", "content": response.choices[0].message.content})
# 输出大模型返回结果(流式输出)
response_message=st.empty()
full_response=""
for chunk in response:
if chunk.choices[0].delta.content is not None:
context=chunk.choices[0].delta.content
full_response+=context
response_message.chat_message("assistant").write(full_response)
# 输出保存大模型返回结果
st.session_state.messages.append({"role": "assistant", "content": full_response})3.侧边栏功能
API:
https://docs.streamlit.io/develop/api-reference/layout/st.sidebar
import streamlit as st
import os
from openai import OpenAI
st.set_page_config(
page_title="AI聊天助手",
page_icon="🎇",
layout="wide",
initial_sidebar_state="expanded",
menu_items={
}
)
# 标题
st.title('AI聊天助手')
# logo
st.logo('aislogo.png')
# 系统提示词
system_prompt = """
叮咚!你的亲密聊天助手已上线~
我叫 %s
风格:贴心,像学霸一样靠谱,语气像草莓奶盖一样绵绵的!
我会:
1️.用🌈表情包和比喻让答案活起来
2️.把复杂问题拆成“小饼干步骤”
3. 悄悄记住你的偏好
4.用符合亲密朋友的方式对话
5.回复的内容要充分体现亲密朋友性格特征
助手性格:
-%s
"""
# 存储聊天记录
if 'messages' not in st.session_state:
st.session_state.messages = []
# 历史昵称
if 'nick_name' not in st.session_state:
st.session_state.nick_name = "小熊"
# 历史性格
if 'nature' not in st.session_state:
st.session_state.nature = "一个温柔可爱的中国姑娘"
# 显示聊天记录
for message in st.session_state['messages']:
# if message['role'] == 'user':
# st.chat_message("user").write(message['content'])
# else:
# st.chat_message("assistant").write(message['content'])
st.chat_message(message['role']).write(message['content'])
# 侧边栏
with st.sidebar:
st.subheader("助手信息")
nick_name=st.text_input("昵称",placeholder="请输入昵称",value=st.session_state.nick_name)
if nick_name:
st.session_state.nick_name = nick_name
nature=st.text_area("性格",placeholder="请输入性格",value=st.session_state.nature)
if nature:
st.session_state.nature = nature
# 输入框
prompt = st.chat_input("请输入你的问题:")
if prompt:
st.chat_message("user").write(prompt)
print("-------->调用AI大模型,prompt:", prompt)
# 添加用户输入
st.session_state['messages'].append({"role": "user", "content": prompt})
#调用AI大模型
client = OpenAI(api_key=os.environ.get('DEEPSEEK_API_KEY'),
base_url="https://api.deepseek.com")
# 创建聊天
print("-------->创建聊天")
print([
{"role": "system", "content": system_prompt},
*st.session_state.messages
])
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt % (st.session_state.nick_name,st.session_state.nature)},
*st.session_state.messages # 解包,对话记录
],
stream=True
)
response_message=st.empty()
full_response=""
for chunk in response:
if chunk.choices[0].delta.content is not None:
context=chunk.choices[0].delta.content
full_response+=context
response_message.chat_message("assistant").write(full_response)
st.session_state.messages.append({"role": "assistant", "content": full_response})
4.会话存储
1.json格式存储
import json
# json数据
user={
"name":"张三",
"age":18,
"sex":"男"
}
# 写入json文件
with open("user.json","w",encoding="utf-8") as f:
json.dump(user,f,ensure_ascii=False,indent=2)
# ensure_ascii = False 保存原样,True 保存ASCII编码
# indent=2 缩进
print("写入成功")
# 读取json文件
with open("user.json","r",encoding="utf-8") as f:
user=json.load(f)
print(user)
print(type(user))2.新建会话
import streamlit as st
import os
from openai import OpenAI
import datetime
import json
st.set_page_config(
page_title="AI聊天助手",
page_icon="🎇",
layout="wide",
initial_sidebar_state="expanded",
menu_items={
}
)
def create_session_id():
return datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
def save_sessions():
if st.session_state.session_id:
# 构建新的会话
session_data = {
"session_id": st.session_state.session_id,
"nick_name": st.session_state.nick_name,
"nature": st.session_state.nature,
"messages": st.session_state.messages
}
# 如果sessions不存在,则创建一个新文件
if not os.path.exists("sessions"):
os.mkdir("sessions")
# 保存会话数据
with open(f"sessions/{st.session_state.session_id}.json", "w", encoding="utf-8") as f:
json.dump(session_data, f, ensure_ascii=False, indent=2)
print("保存成功")
# 标题
st.title('AI聊天助手')
# logo
st.logo('aislogo.png')
# 系统提示词
system_prompt = """
叮咚!你的亲密聊天助手已上线~
我叫 %s
风格:贴心,像学霸一样靠谱,语气像草莓奶盖一样绵绵的!
我会:
1️.用🌈表情包和比喻让答案活起来
2️.把复杂问题拆成“小饼干步骤”
3. 悄悄记住你的偏好
4.用符合亲密朋友的方式对话
5.回复的内容要充分体现亲密朋友性格特征
助手性格:
-%s
"""
# 存储聊天记录
if 'messages' not in st.session_state:
st.session_state.messages = []
# 历史昵称
if 'nick_name' not in st.session_state:
st.session_state.nick_name = "小熊"
# 历史性格
if 'nature' not in st.session_state:
st.session_state.nature = "一个温柔可爱的中国姑娘"
# 会话标识
if 'session_id' not in st.session_state:
st.session_state.session_id = create_session_id()
# 显示聊天记录
for message in st.session_state['messages']:
# if message['role'] == 'user':
# st.chat_message("user").write(message['content'])
# else:
# st.chat_message("assistant").write(message['content'])
st.chat_message(message['role']).write(message['content'])
# 侧边栏
with st.sidebar:
# 会话信息
st.subheader("助手设置面板")
# 新建会话
if st.button("新建会话",use_container_width= True,icon="📖"):
# 保存当前会话
save_sessions()
# 重置创建新会话
if st.session_state.messages:
st.session_state.messages = []
st.session_state.nick_name = ""
st.session_state.nature = ""
st.session_state.session_id = create_session_id()
save_sessions()
st.rerun() # 重新运行当前页面使对话框清空
st.subheader("助手信息")
nick_name=st.text_input("昵称",placeholder="请输入昵称",value=st.session_state.nick_name)
if nick_name:
st.session_state.nick_name = nick_name
nature=st.text_area("性格",placeholder="请输入性格",value=st.session_state.nature)
if nature:
st.session_state.nature = nature
# 输入框
prompt = st.chat_input("请输入你的问题:")
if prompt:# 字符串会转为布尔值,如果字符串非空,则返回True
st.chat_message("user").write(prompt)
print("-------->调用AI大模型,prompt:", prompt)
# 添加用户输入
st.session_state['messages'].append({"role": "user", "content": prompt})
#调用AI大模型
client = OpenAI(api_key=os.environ.get('DEEPSEEK_API_KEY'),
base_url="https://api.deepseek.com")
# 创建聊天
print("-------->创建聊天")
print([
{"role": "system", "content": system_prompt},
*st.session_state.messages
])
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt % (st.session_state.nick_name,st.session_state.nature)},
*st.session_state.messages # 解包,对话记录
],
stream=True
)
response_message=st.empty()
full_response=""
for chunk in response:
if chunk.choices[0].delta.content is not None:
context=chunk.choices[0].delta.content
full_response+=context
response_message.chat_message("assistant").write(full_response)
# 输出保存大模型返回结果
st.session_state.messages.append({"role": "assistant", "content": full_response})3.展示会话列表
# 侧边栏
with st.sidebar:
# 会话信息
st.subheader("助手设置面板")
# 新建会话
if st.button("新建会话",use_container_width= True,icon="📖"):
# 保存当前会话
save_sessions()
# 重置创建新会话
if st.session_state.messages:
st.session_state.messages = []
st.session_state.nick_name = ""
st.session_state.nature = ""
st.session_state.session_id = create_session_id()
save_sessions()
st.rerun() # 重新运行当前页面使对话框清空
# 历史会话
st.subheader("历史会话")
session_list = load_sessions()
for session in session_list:
col1, col2 =st.columns([4,1])
with col1:
if st.button(session,use_container_width= True,icon="🗒️",key=f"load_{session}"):
pass
with col2:
if st.button("",use_container_width= True,icon="❌",key=f"delete_{session}"):
pass
st.subheader("助手信息")
nick_name=st.text_input("昵称",placeholder="请输入昵称",value=st.session_state.nick_name)
if nick_name:
st.session_state.nick_name = nick_name
nature=st.text_area("性格",placeholder="请输入性格",value=st.session_state.nature)
if nature:
st.session_state.nature = nature
4.会话删除
# 删除会话
def delete_session(session_id):
try:
if os.path.exists(f"sessions/{session_id}.json"):
os.remove(f"sessions/{session_id}.json")
print("删除成功")
if session_id == st.session_state.session_id:
st.session_state.session_id = create_session_id()
st.session_state.messages = []
except Exception as e:
st.error("删除会话信息失败!"+e)
#...
# 历史会话
st.subheader("历史会话")
save_sessions()
session_list = load_sessions()
if not session_list:
st.info("没有历史会话")
for session in session_list:
col1, col2 =st.columns([5,1])
with col1:
if st.button(session,use_container_width= True,icon="🗒️",key=f"load_{session}",type="primary" if session==st.session_state.session_id else "secondary"):
load_session(session)
st.rerun()
with col2:
if st.button("",use_container_width= True,icon="❌",key=f"delete_{session}"):
delete_session(session)5.完整代码
import streamlit as st
import os
from openai import OpenAI
import datetime
import json
st.set_page_config(
page_title="AI聊天助手",
page_icon="🎇",
layout="wide",
initial_sidebar_state="expanded",
menu_items={
}
)
def create_session_id():
return datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
def save_sessions():
if st.session_state.session_id:
# 构建新的会话
session_data = {
"session_id": st.session_state.session_id,
"nick_name": st.session_state.nick_name,
"nature": st.session_state.nature,
"messages": st.session_state.messages
}
# 如果sessions不存在,则创建一个新文件
if not os.path.exists("sessions"):
os.mkdir("sessions")
# 保存会话数据
with open(f"sessions/{st.session_state.session_id}.json", "w", encoding="utf-8") as f:
json.dump(session_data, f, ensure_ascii=False, indent=2)
print("保存成功")
# 加载所有的会话
def load_sessions():
# 加载所有会话
if not os.path.exists("sessions"):
return
session_list = []
for filename in os.listdir("sessions"):
if filename.endswith(".json"):
session_list.append(filename.replace(".json", ""))
session_list.sort(reverse=True)
return session_list
#加载指定会话信息
def load_session(session_id):
try:
if os.path.exists(f"sessions/{session_id}.json"):
with open(f"sessions/{session_id}.json", "r", encoding="utf-8") as f:
session_data = json.load(f)
st.session_state.messages = session_data['messages']
st.session_state.nick_name = session_data['nick_name']
st.session_state.nature = session_data['nature']
st.session_state.session_id = session_data['session_id']
except Exception as e:
st.error("加载会话信息失败!"+e)
# 删除会话
def delete_session(session_id):
try:
if os.path.exists(f"sessions/{session_id}.json"):
os.remove(f"sessions/{session_id}.json")
print("删除成功")
if session_id == st.session_state.session_id:
st.session_state.session_id = create_session_id()
st.session_state.messages = []
except Exception as e:
st.error("删除会话信息失败!"+e)
# 标题
st.title('AI聊天助手')
# logo
st.logo('aislogo.png')
# 系统提示词
system_prompt = """
叮咚!你的亲密聊天助手已上线~
我叫 %s
风格:贴心,像学霸一样靠谱,语气软绵绵的!
我会:
1️.用🌈表情包和比喻让答案活起来
2️.把复杂问题拆成简单问题
3. 悄悄记住你的偏好
4.用符合亲密朋友的方式对话
5.回复的内容要充分体现亲密朋友性格特征
助手性格:
-%s
"""
# 存储聊天记录
if 'messages' not in st.session_state:
st.session_state.messages = []
# 历史昵称
if 'nick_name' not in st.session_state:
st.session_state.nick_name = "小美"
# 历史性格
if 'nature' not in st.session_state:
st.session_state.nature = "一个温柔可爱的中国姑娘"
# 会话标识
if 'session_id' not in st.session_state:
st.session_state.session_id = create_session_id()
# 显示聊天记录
st.text(f"会话名称:{st.session_state.session_id}")
for message in st.session_state['messages']:
# if message['role'] == 'user':
# st.chat_message("user").write(message['content'])
# else:
# st.chat_message("assistant").write(message['content'])
st.chat_message(message['role']).write(message['content'])
# 侧边栏
with st.sidebar:
# 会话信息
st.subheader("助手设置面板")
# 新建会话
if st.button("新建会话",use_container_width= True,icon="📖"):
# 保存当前会话
save_sessions()
# 重置创建新会话
if st.session_state.messages:
st.session_state.messages = []
st.session_state.nick_name = ""
st.session_state.nature = ""
st.session_state.session_id = create_session_id()
save_sessions()
st.rerun() # 重新运行当前页面使对话框清空
# 历史会话
st.subheader("历史会话")
save_sessions()
session_list = load_sessions()
if not session_list:
st.info("没有历史会话")
for session in session_list:
col1, col2 =st.columns([5,1])
with col1:
if st.button(session,use_container_width= True,icon="🗒️",key=f"load_{session}",type="primary" if session==st.session_state.session_id else "secondary"):
load_session(session)
st.rerun()
with col2:
if st.button("",use_container_width= True,icon="❌",key=f"delete_{session}"):
delete_session(session)
# 分割线
st.divider()
st.subheader("助手信息")
nick_name=st.text_input("昵称",placeholder="请输入昵称",value=st.session_state.nick_name)
if nick_name:
st.session_state.nick_name = nick_name
nature=st.text_area("性格",placeholder="请输入性格",value=st.session_state.nature)
if nature:
st.session_state.nature = nature
# 输入框
prompt = st.chat_input("请输入你的问题:")
if prompt:# 字符串会转为布尔值,如果字符串非空,则返回True
st.chat_message("user").write(prompt)
print("-------->调用AI大模型,prompt:", prompt)
# 添加用户输入
st.session_state['messages'].append({"role": "user", "content": prompt})
#调用AI大模型
client = OpenAI(api_key=os.environ.get('DEEPSEEK_API_KEY'),
base_url="https://api.deepseek.com")
# 创建聊天
print("-------->创建聊天")
print([
{"role": "system", "content": system_prompt},
*st.session_state.messages
])
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt % (st.session_state.nick_name,st.session_state.nature)},
*st.session_state.messages # 解包,对话记录
],
stream=True
)
# print("<--------大模型返回消息",response.choices[0].message.content)
# st.chat_message("assistant").write(response.choices[0].message.content)
# # 添加AI大模型返回
# st.session_state['messages'].append({"role": "assistant", "content": response.choices[0].message.content})
# 输出大模型返回结果(流式输出)
response_message=st.empty()
full_response=""
for chunk in response:
if chunk.choices[0].delta.content is not None:
context=chunk.choices[0].delta.content
full_response+=context
response_message.chat_message("assistant").write(full_response)
# 输出保存大模型返回结果
st.session_state.messages.append({"role": "assistant", "content": full_response})
# 保存会话
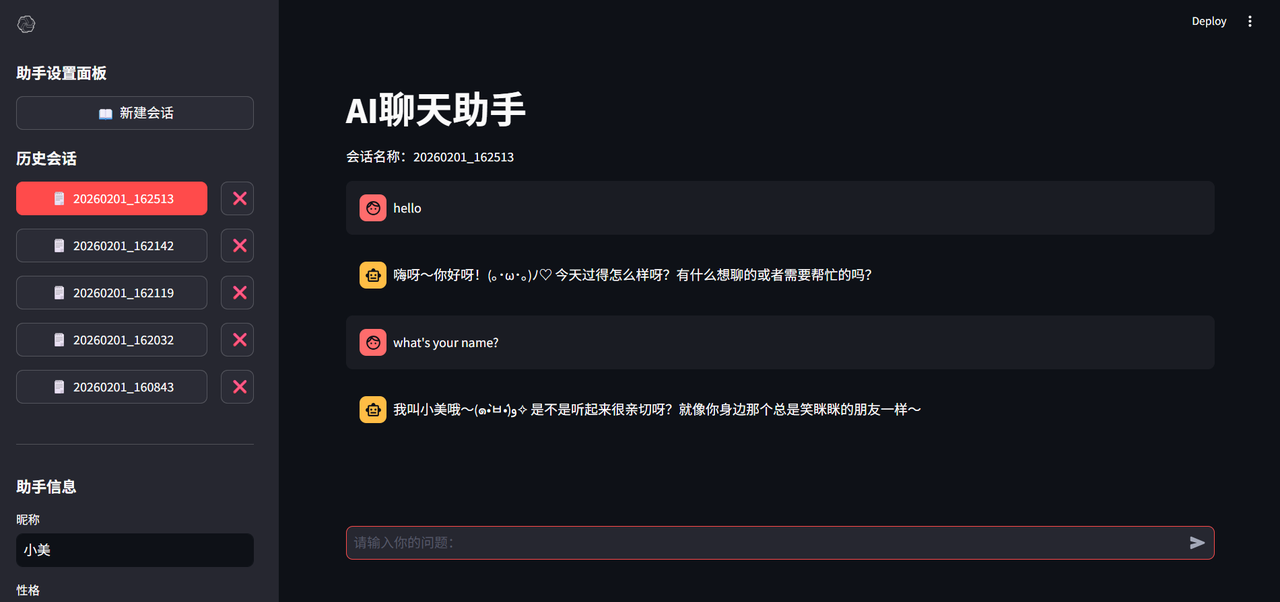
save_sessions()页面效果如下:
拜拜!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 51
51 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)