VoiceSculptor——音色设计、风格可控的语音生成模型,技术报告来啦!
在AI语音合成领域,能精准听懂自然语言指令、实现细粒度控制的开源工具一直是行业痛点。近期,西工大音频语音与语言处理研究组(ASLP@NPU)与语图智能技术公司(Yutu Zhineng)、上海灵光乍现技术团队(Shanghai Lingguang Zhaxian Technology)、Wenet社区(WeNet Open Source Community)正式。该模型是一款专为音色设计、风格可控
在AI语音合成领域,能精准听懂自然语言指令、实现细粒度控制的开源工具一直是行业痛点。近期,西工大音频语音与语言处理研究组(ASLP@NPU)与语图智能技术公司(Yutu Zhineng)、上海灵光乍现技术团队(Shanghai Lingguang Zhaxian Technology)、Wenet社区(WeNet Open Source Community)正式开源音色设计模型VoiceSculptor。该模型是一款专为音色设计、风格可控打造的语音生成模型,支持语速、音量、基频等属性可控,可以通过自然语言指令生成成千上万种不同音色的音频。

VoiceSculptor: Your Voice, Designed By You
合作单位:西北工业大学、语图智能、上海玲光乍现科技、Wenet社区
作者列表:胡景斌,陈华康,马林涵,郭大可,詹其瑞,李文豪,张皓宇,夏康翔,张子萸,田文杰,王成有,梁津瑞,郭书翰,杨子航,吴本谷,张彬彬,朱鹏程,谢鹏源,谢川,张强,刘杰,谢磊†
-
Technical Report:
https://arxiv.org/pdf/2601.10629
-
Demo Page:
https://hujingbin1.github.io/VoiceSculptor-Demo/
-
Source Code:
https://github.com/ASLP-lab/VoiceSculptor
-
HuggingFace:
https://huggingface.co/ASLP-lab/VoiceSculptor-VD
-
HuggingFace Space:
https://huggingface.co/spaces/ASLP-lab/VoiceSculptor
⏩一、数据 pipeline :多维度标注,筑牢训练根基
模型性能的上限由数据的质量和多样性决定,VoiceSculptor构建了一套从数据收集到标注的全流程闭环:
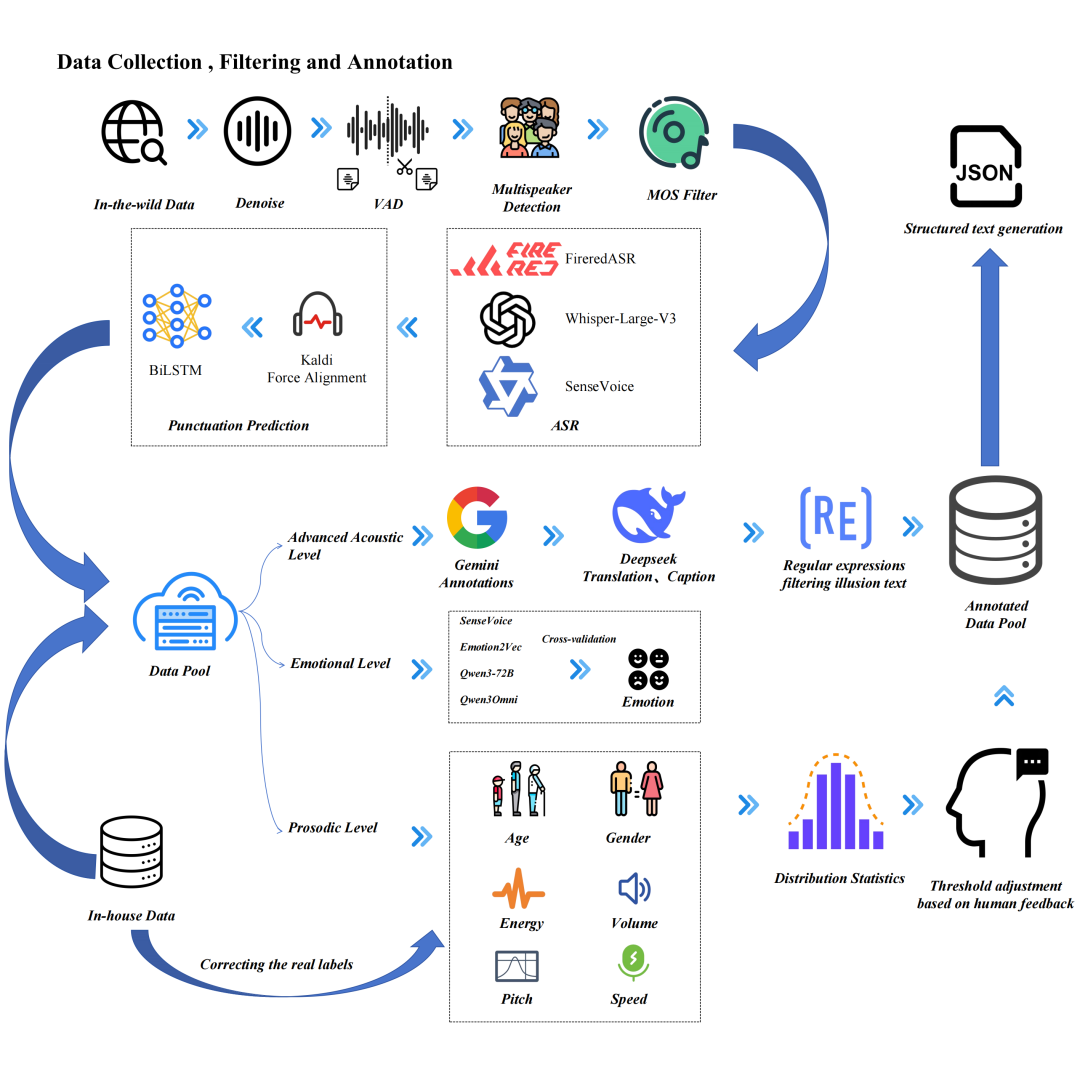
图1 数据处理流程图
1. 数据规模与构成
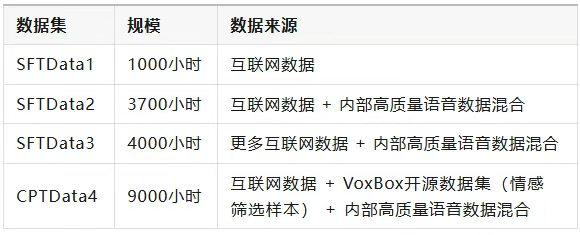
2. 数据预处理四大关键步骤
-
基础处理:使用CleanMel去噪、py-webrtcvad做vad切分、pyannote-audio多说话人检测,使用wvmos进行质量过滤和筛选。
-
ASR校准和标点预测:
-
中文ASR转录:FireRedASR
-
英文ASR转录:Whisper-Large-V3
-
交叉验证:SenseVoice
-
强制对齐:Kaidi工具实现中文字符级/英文词级对齐,生成精准时间戳和停顿时长,并通过标点预测模型对文本增加标点,提升TTS合成的稳定性和韵律。
-
-
多维度标注:
-
声学级:Gemini 2.5 Pro标注音调、语速、音量、年龄、性别、情感等结构化属性,DeepSeek生成自然语言描述,正则过滤LLM幻觉内容。
-
情感级:Emotion2Vec、Qwen3-72B、SenseVoice、Qwen3-Omni四模型交叉验证,解决单一模型标注偏差。
-
韵律级:DataSpeech模型估算基频、能量统计值,VoxProfile标注年龄性别,人工校准属性边界。(如年龄分为儿童/青年/中年/老年4类,韵律属性分5个区间)
-
-
最终校验:结合内部数据真实标签,修正年龄、性别等关键属性标注,形成统一标注数据池。
二、实验核心目标与基准设定
1. 核心评估方向
实验围绕三大核心目标展开:
-
指令跟随能力:能否精准将自然语言描述转化为对应语音属性(音调、语速、年龄、情绪等)
-
细粒度可控性:对单一属性的调节是否精准
-
系统扩展性:模型参数、训练数据规模对性能的影响,以及下游任务适配性
2. 关键基准与对比对象
-
评估基准:采用中文指令TTS权威评测集 InstructTTSEval-Zh,从三大维度打分:
-
APS(Acoustic-Parameter Specification):声学维度(如"性别: 男性.\n\n音高: 男性中高音,情绪激动时显著升高.\n\n语速: 语速急促,句末因恳求略有放缓.\n\n音量: 音量较高,情绪激动时更为响亮.\n\n年龄: 青年至中年男性.\n\n清晰度: 基本清晰,哭腔导致发音略微含混.\n\n流畅度: 整体流畅,偶有因哽咽造成的停顿.\n\n口音: 标准普通话,带有戏剧化哭腔.\n\n音色质感: 略显沙哑,带有明显哭腔的紧张感.\n\n情绪: 极度悲伤,夹杂悔恨与急切恳求.\n\n语调: 哀伤恳求,音高起伏剧烈,充满绝望.\n\n性格: 情感外露,依赖性强,遇事易显慌乱.")
-
DSD(Descriptive-Style Directive):描述性风格指令(如"展现出悲苦沙哑的声音质感,语速偏慢,情绪浓烈且带有哭腔,以标准普通话缓慢诉说,情感强烈,语调哀怨高亢,音高起伏大。")
-
RP(Role-Play):角色扮演(如"模仿5岁儿童讲故事")
-
-
对比模型分为两类:
-
商业模型:Gemini 2.5-Flash、Gemini 2.5-Pro、GPT-4o-Mini-TTS、ElevenLabs
-
开源模型:VoxInstruct、MiMo-Audio-7B-Instruct
-
3. 主观评估设计
-
指标:IMOS(Instruction-following Mean Opinion Score),专门评估语音与指令的契合度。
-
流程:33名听众参与,每人随机评测10个样本,采用MOS标准评分(1-5分),每个样本经多人交叉验证,避免个体偏差。
-
数据:100条精心筛选的测试指令,覆盖复杂属性组合、生僻风格描述等场景。
三、核心组件消融实验:三大创新点的精准验证
为了明确每个核心设计的贡献,VoiceSculptor进行了严格的消融实验。(逐一移除组件对比性能)
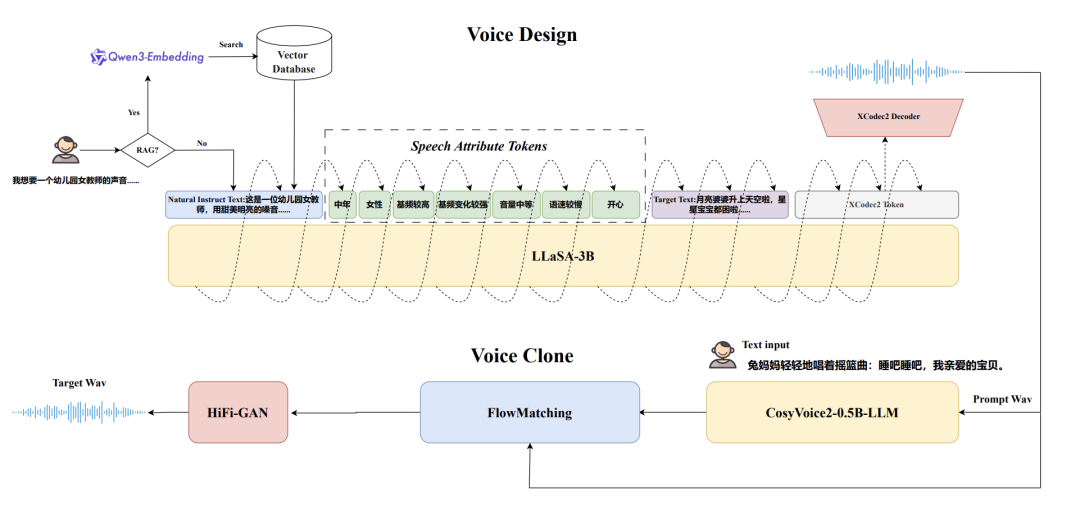
图2 模型结构图
1. CoT(思维链)细粒度属性建模
核心作用:将自然语言指令拆解为结构化属性推理步骤,实现属性解耦控制。
|
实验设置 |
IMOS (±标准差) |
APS (%) |
DSD (%) |
RP (%) |
AVG (%) |
|---|---|---|---|---|---|
|
VoiceSculptor-VD (含CoT) |
3.67±0.17 |
75.7 |
64.7 |
61.5 |
67.6 |
|
移除CoT |
3.59±0.14 |
71.6 |
61.9 |
58.9 |
63.5 |
-
关键发现:
-
CoT使综合得分提升4.1%,APS提升4.1%,证明结构化推理能精准映射语言指令到声学属性。
-
训练中加入0.2概率的属性令牌随机丢弃,不仅未降效反而提升鲁棒性,避免模型过度依赖显式令牌。
-
2. 文本交叉熵(CE)损失监督
核心作用:联合优化文本指令与语音令牌的对齐,增强语义理解。
|
实验设置 |
IMOS (±标准差) |
APS (%) |
DSD (%) |
RP (%) |
AVG (%) |
|---|---|---|---|---|---|
|
VoiceSculptor-VD (含文本CE) |
3.67±0.15 |
75.7 |
64.7 |
61.5 |
67.6 |
|
移除文本CE损失 |
3.42±0.23 |
67.9 |
59.4 |
58.2 |
61.8 |
-
关键发现:
-
文本CE损失使综合得分提升5.8%,IMOS提升0.25分,说明显式监督文本语义能大幅提升指令跟随准确性。
-
模型更能捕捉长距离语境依赖,避免对孤立关键词的片面理解。
-
3. RAG(检索增强生成)机制
核心作用:通过检索相似指令辅助理解,提升对生僻/复杂指令的适配性。
|
实验设置 |
IMOS (±标准差) |
APS (%) |
DSD (%) |
RP (%) |
AVG (%) |
|---|---|---|---|---|---|
|
VoiceSculptor-VD (含RAG) |
3.67±0.27 |
75.7 |
64.7 |
61.5 |
67.6 |
|
移除RAG |
3.39±0.23 |
68.6 |
61.1 |
48.5 |
59.4 |
-
关键细节:
-
RAG基于500K条领域内指令构建向量库(Qwen3-Embedding-0.6B编码),Milvus向量数据库存储,余弦相似度检索。
-
带来最显著提升:RP提升13.0%,APS提升7.1%,证明检索到的同类指令能有效辅助角色扮演和参数控制。
-
暴露模型短板:无RAG时对复杂指令理解能力下降明显,说明外部知识补充的必要性。
-
-
四、规模缩放实验:模型与数据的协同优化规律
为了找到性能与成本的最优平衡点,VoiceSculptor测试了不同模型参数和数据规模的组合:
实验设计
-
模型规格:1B参数(8×L40 GPU训练)、3B参数(8×A100 GPU训练)
-
训练策略:SFT(高质量数据监督微调)、CPT(情感筛选过的数据持续预训练)+ SFT
-
评估指标:IMOS、APS、DSD、RP、综合得分
核心结果
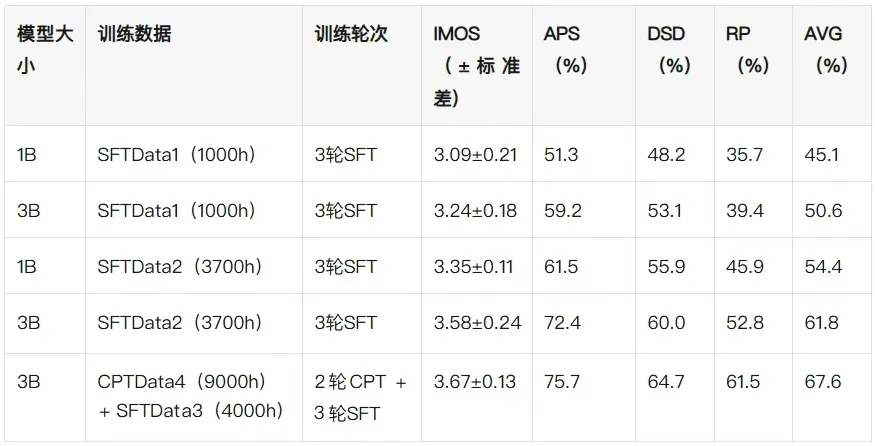
关键结论
-
模型参数提升见效显著:相同数据下,3B比1B模型综合得分高5.5-9.7%,证明大模型更强的语义理解和属性建模能力。
-
数据规模与多样性至关重要:1B模型用3700h数据(SFTData2)比1000h数据(SFTData1)综合得分高9.3%,多源数据能覆盖更多语音场景。
-
预训练+微调范式最优:加入9000h CPT预训练后,3B模型综合得分再提升5.8%,情感感知预训练能提供更优初始化权重。
五、基准测试终极对决:开源模型中文指令控制能力SOTA
完整性能排名
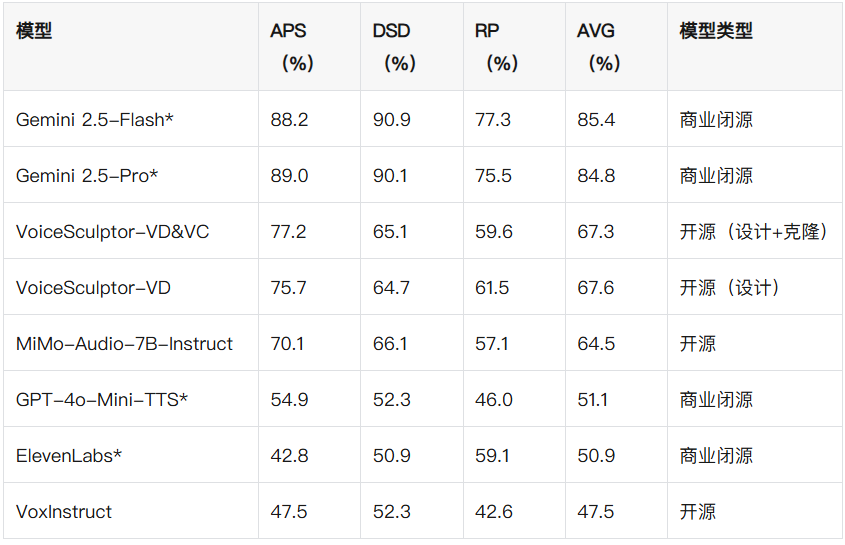
关键亮点解析
-
开源领域领先:VoiceSculptor-VD综合得分67.6%,比第二名MiMo-Audio-7B-Instruct高3.1%,APS(75.7%)和RP(61.5%)两项核心指标领先。
-
风格迁移稳定性强:VoiceSculptor-VD&VC将设计的语音波形输入CosyVoice2克隆后,APS仍达77.2%,证明生成的语音模板可无缝对接下游TTS,风格保留度高。
-
商业模型差距缩小:虽低于Gemini 2.5系列,但大幅超越GPT-4o-Mini-TTS和ElevenLabs,且完全开源可定制,无闭源黑箱限制。
六、实验局限性与未来优化方向
已知短板
-
稳定性不足:相同指令重复合成时,偶尔出现属性控制波动;
-
交互体验:合成过程中可能出现偶发的长时间静默或响应延迟;
-
数据覆盖:儿童和老人语音的自然度、音色一致性有待提升;
-
多语言支持:目前仅重点验证中文性能,英文及多语言能力未充分评估。
未来实验规划
-
增强文本理解:预训练阶段加入大规模文本数据,提升复杂指令语义捕捉能力;
-
数据扩充:收集更多儿童、老人语音样本,增加情感多样性标注;
-
音频编码优化:替换XCodec2为更具语义表达力的音频表征方案;
-
指令增强:通过数据增广,生成更多样化的指令表述,降低对RAG的依赖。
七、伦理规范
-
严禁用于未授权语音克隆、诈骗、深度伪造等非法活动。
-
生成语音为纯合成输出,不对应任何真实个人,无模仿特定个体的意图。
-
使用者需遵守当地法律法规,开发者不对模型滥用承担责任。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)