AI AGENT入门
目录
- 核心概念
- 技术栈层次划分
- 开发框架与工具
- 学习路线建议
一、核心概念
1.1 LLM(大语言模型)
LLM 是 Large Language Model 的缩写,指经过大规模文本训练的 AI 模型,如 Claude、GPT、文心一言等。它们能理解自然语言、生成文本、进行推理。
1.2 RAG(检索增强生成)
RAG 是 Retrieval-Augmented Generation 的缩写,核心思路是:让 AI 先检索相关知识,再基于检索结果生成回答。
解决的问题:
- 幻觉问题:LLM 可能编造不存在的内容
- 知识时效性:训练数据有截止日期
- 私有数据:公司内部知识没训练进模型
工作流程:
用户提问 → 检索知识库 → 把相关内容 + 问题一起给 LLM → 生成准确回答
类比:
- 没有 RAG = 闭卷考试(可能记错、瞎编)
- 有 RAG = 开卷考试(查资料回答,更准确)
1.3 KAG(知识增强生成)
KAG 是 Knowledge-Augmented Generation 的缩写,是 RAG 的进阶版本,结合了向量检索 + 知识图谱。
RAG vs KAG:
| 维度 | RAG | KAG |
|---|---|---|
| 知识存储 | 向量数据库 | 向量数据库 + 图数据库 |
| 检索方式 | 语义相似度匹配 | 语义 + 实体关系推理 |
| 适合场景 | 通用问答 | 需要多跳推理的复杂问答 |
1.4 Agent(智能代理)
Agent 是能自主思考、规划、调用工具来完成任务的 AI,而不是简单的一问一答。
普通聊天 vs Agent:
| 模式 | 工作方式 |
|---|---|
| 聊天模式 | 用户问 → AI 直接回答 |
| Agent 模式 | 用户问 → AI 思考用什么工具 → 调用工具 → 根据结果回答 |
Agent 核心循环:
用户提问 → AI 思考 → 调用工具 → 获取结果 → 判断是否继续 → 回复用户
1.5 MCP(模型上下文协议)
MCP 是 Model Context Protocol 的缩写,Anthropic 推出的协议,用于让 AI 模型安全地连接外部工具、数据库和 API。
核心架构:
- Host:运行 AI 模型的环境
- Client:连接 Host 和 Server 的桥梁
- Server:提供工具和数据的服务端
三种能力:
- Tools:让 AI 执行操作(如查询数据库、发送邮件)
- Resources:提供数据给 AI
- Prompts:预定义的提示词模板
二、技术栈层次划分
AI 应用开发可按技术栈从底向上分为四层:

大多数应用开发聚焦在应用层和工具层,模型层和推理层通常由专门的算法团队负责。
2.1 模型层(基础能力)
模型层是 AI 能力的基础,决定了模型"有多聪明"。
| 技术 | 说明 | 谁来做 |
|---|---|---|
| 预训练 | 用海量数据训练基础模型 | 大厂(OpenAI、Anthropic、百度等) |
| 微调 | 用特定数据调整模型行为 | 有数据的企业 |
| RLHF | 人类反馈强化学习,对齐人类偏好 | 大厂为主 |
应用开发者需要了解:
- 不同模型的能力边界(Claude、GPT、文心一言的差异)
- 什么时候需要微调 vs 用 RAG 就够了
什么时候用微调?
| 场景 | 用微调 | 用 RAG |
|---|---|---|
| 改变风格/语气 | ✅ | ❌ |
| 学习特定格式 | ✅ | ❌ |
| 注入新知识 | ❌ | ✅ |
| 知识需要更新 | ❌ | ✅ |
成本对比:
| 方式 | 成本 | 更新速度 |
|---|---|---|
| 全量训练 | 几百万到上亿美元 | 数周到数月 |
| 微调 | 几百到几万美元 | 几小时到几天 |
| RAG | 几乎零成本 | 几分钟 |
2.2 推理层(模型运行)
推理层关注如何高效、低成本地运行模型。
| 技术 | 说明 |
|---|---|
| 推理优化 | 加速模型响应(vLLM、TensorRT) |
| 量化 | 压缩模型体积,降低显存需求 |
| 部署 | 本地部署、云端部署、边缘部署 |
应用开发者需要了解:
- 用 API 还是自己部署模型?
- 响应延迟和成本的权衡
| 方式 | 优点 | 缺点 |
|---|---|---|
| 调用 API | 简单、无需运维 | 成本按量、数据出境 |
| 自己部署 | 数据安全、成本可控 | 需要 GPU、运维复杂 |
2.3 工具层(能力扩展)
工具层让 AI 能调用外部工具,从"只会说"变成"能做事"。
Function Calling
让模型决定调用哪个函数,返回结构化参数:
# 模型返回
{
"function": "get_weather",
"arguments": {"city": "北京"}
}
# 你的代码执行函数,把结果返回给模型
MCP(Model Context Protocol)
Anthropic 推出的标准化协议,比 Function Calling 更规范:
核心架构:
- Host:运行 AI 模型的环境
- Client:连接 Host 和 Server 的桥梁
- Server:提供工具和数据的服务端
三种能力:
- Tools:让 AI 执行操作
- Resources:提供数据给 AI
- Prompts:预定义的提示词模板
FastMCP 快速入门
from fastmcp import FastMCP
mcp = FastMCP("我的服务器")
@mcp.tool()
def add(a: int, b: int) -> int:
"""两数相加"""
return a + b
@mcp.tool()
def search_db(query: str) -> list:
"""搜索数据库"""
return results
if __name__ == "__main__":
mcp.run()
Function Calling vs MCP
| 维度 | Function Calling | MCP |
|---|---|---|
| 标准化 | 各家模型不统一 | 统一协议 |
| 能力 | 只有工具调用 | 工具 + 资源 + 提示词 |
| 生态 | 成熟 | 新兴,潜力大 |
2.4 应用层(产品形态)
应用层是最终用户接触的产品形态,也是大多数开发者聚焦的层次。
2.4.1 RAG(检索增强生成)
核心:让 AI 先检索知识库,再生成回答。
解决的问题:
- 幻觉:模型可能编造内容
- 时效性:训练数据有截止日期
- 私有数据:公司知识没训练进模型
类比:
- 没有 RAG = 闭卷考试(可能记错)
- 有 RAG = 开卷考试(查资料回答)
为什么需要向量数据库?
核心原因:语义搜索。
用户问:"如何申请休假?" 文档标题:"员工请假流程指南"
- 关键词搜索:搜"休假" → 匹配不到"请假" ❌
- 向量搜索:理解两者意思相近 → 找到 ✅
工作原理:
文本 → Embedding 模型 → 向量(一串数字)
常见向量数据库:
| 名称 | 特点 |
|---|---|
| Chroma | 轻量,适合本地开发 |
| Milvus | 开源,生产级,国产 |
| Pinecone | 云服务,开箱即用 |
| FAISS | Meta 出品,纯库 |
RAG 完整流程
建库:文档切片 → Embedding → 存入向量数据库
查询:用户提问 → Embedding → 检索相似内容 → 拼接 prompt → LLM 回答
2.4.2 KAG(知识增强生成)
核心:RAG + 知识图谱,支持多跳推理。
为什么需要知识图谱?
问题:AI 能推理,但只能推理它看到的内容。
场景:10 万篇文档,用户问"张三的部门在哪个城市?"
| 步骤 | 问题 |
|---|---|
| 检索 Top 5 | 可能只找到"张三是技术部工程师" |
| AI 推理 | 看不到"技术部在北京",无法回答 |
知识图谱解决方案:预先抽取实体关系
建库时:
"张三是技术部工程师" → (张三)--[属于]-->(技术部)
"技术部在北京办公" → (技术部)--[位于]-->(北京)
查询时:
图谱推理:张三 → 技术部 → 北京
类比:
- 纯向量 = 在书堆里翻找
- 向量 + 图谱 = 先看目录索引,再翻对应页
KAG 完整架构
建库:
文档 → 抽取实体关系 → 图数据库
→ 切片 Embedding → 向量数据库
查询:
用户问题 → 图数据库查关系 + 向量库查文档 → 合并 → LLM 回答
常见图数据库:
| 名称 | 特点 |
|---|---|
| Neo4j | 最流行,社区版免费 |
| NebulaGraph | 国产,分布式 |
| JanusGraph | 开源,大规模 |
RAG vs KAG 如何选择
| 场景 | 建议 |
|---|---|
| 刚入门 / 简单问答 | 先用 RAG |
| 需要多跳推理 | 上 KAG |
| 数据量小 | RAG 够用 |
建议:先做 RAG,效果不够再加图谱。
2.4.3 Agent(智能代理)
核心:让 AI 自主思考、规划、调用工具完成任务。
普通聊天 vs Agent:
| 模式 | 工作方式 |
|---|---|
| 聊天 | 用户问 → AI 直接回答 |
| Agent | 用户问 → AI 思考 → 调用工具 → 根据结果回答 |
ReAct 模式
ReAct = Reasoning + Acting,让 AI 交替思考和行动:
思考(Thought) → 行动(Action) → 观察(Observation) → ... → 最终答案
示例:用户问"北京今天比上海热多少度?"
Thought 1: 我需要知道两地温度,先查北京
Action 1: 调用天气API(北京)
Observation 1: 北京 28℃
Thought 2: 现在查上海
Action 2: 调用天气API(上海)
Observation 2: 上海 24℃
Thought 3: 相差4℃,可以回答了
Final Answer: 北京比上海热4℃
ReAct vs Function Calling
| 维度 | ReAct | Function Calling |
|---|---|---|
| 思考过程 | 显式,可见 | 隐式 |
| 可控性 | 高,每步能干预 | 低 |
| 速度 | 慢(多轮) | 快 |
| 适合 | 复杂任务 | 简单任务 |
记忆系统
Agent 需要记忆才能更智能:
| 类型 | 说明 | 实现 |
|---|---|---|
| 短期记忆 | 当前对话上下文 | 上下文窗口 |
| 长期记忆 | 历史对话、用户偏好 | 向量数据库 |
2.4.4 工作流编排
把多个 AI 能力串联成复杂流程:
用户输入 → 意图识别 → 路由分发 → RAG/Agent/直接回答 → 输出
Dify 的工作流功能就是做这个的。
各层技术对比
| 层次 | 核心问题 | 代表技术 | 应用开发者需要 |
|---|---|---|---|
| 模型层 | 模型多聪明 | 预训练、微调 | 了解,偶尔微调 |
| 推理层 | 跑得多快 | vLLM、量化 | 了解,按需部署 |
| 工具层 | 能做什么 | MCP、Function Calling | 重点掌握 |
| 应用层 | 解决什么问题 | RAG、Agent | 核心技能 |
技术组合:Agent + RAG + MCP
这三者不是互斥的,而是互补的,实际项目中经常组合使用:
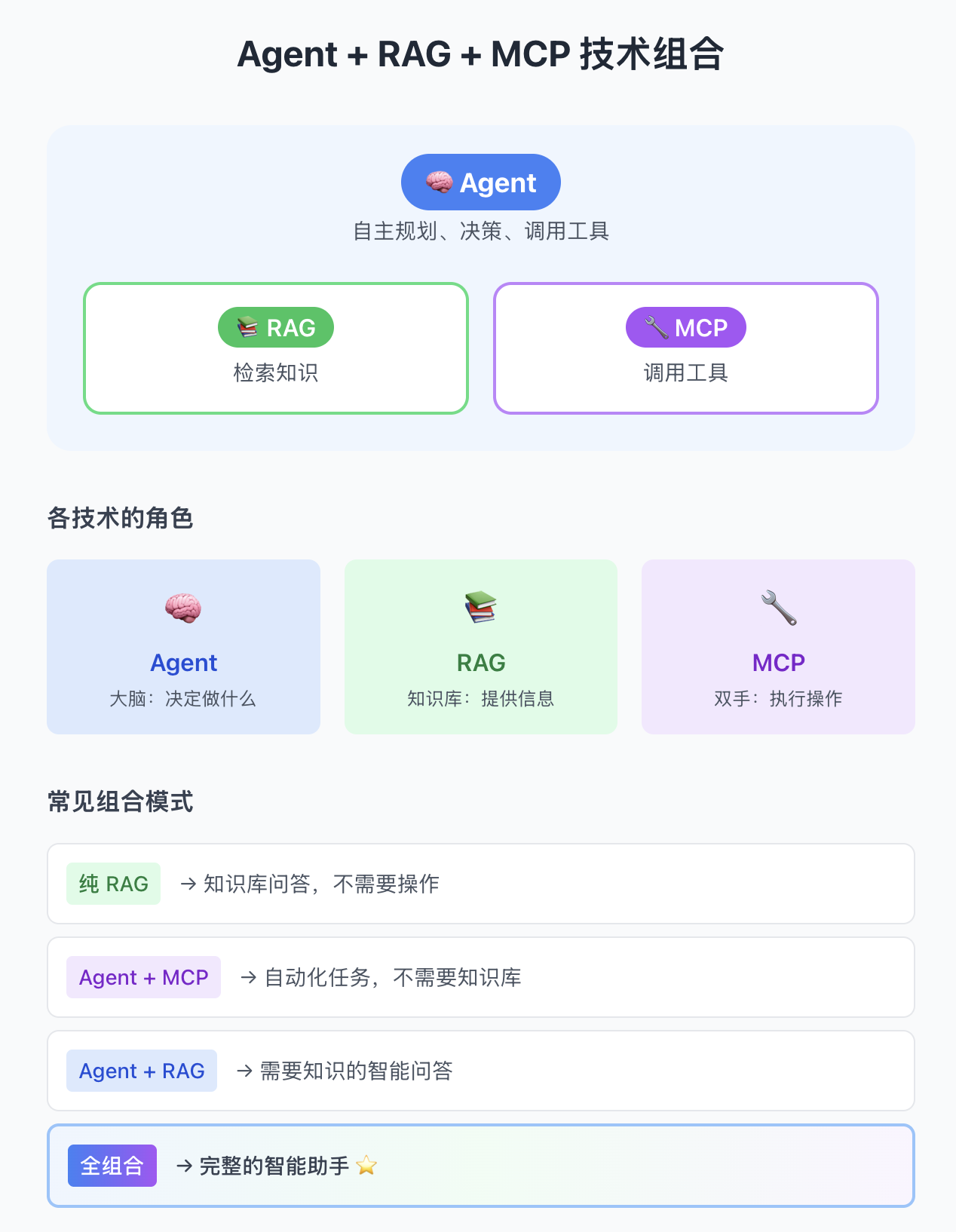
组合示例:用户问"根据我们公司的销售数据,预测下季度业绩"
Agent 思考:这个问题需要先查知识库,再调用计算工具
Step 1: 调用 RAG → 检索公司销售数据和历史趋势
Step 2: 调用 MCP → 连接数据库获取最新数字
Step 3: 调用 MCP → 调用预测模型 API
Step 4: 综合结果,生成回答
学习时可以从单个技术入手,但实际落地往往是组合使用。
三、开发框架与工具
3.1 Dify
Dify 是一个开源的 LLM 应用开发平台,可以快速搭建 AI 应用。
特点:
- 低代码/无代码,拖拽配置
- 内置 Agent、RAG、工作流
- 适合快速验证想法
Dify Agent 两种策略:
- Function Calling:模型自己决定调用哪个工具,速度快
- ReAct:显式思考过程,更可控
3.2 LangChain
LangChain 是用于构建 LLM 应用的 Python 框架,把 LLM 和各种工具"串"起来。
核心组件:
| 组件 | 作用 |
|---|---|
| Models | 统一的 LLM 接口,切换模型只改一行 |
| Prompts | 提示词模板管理 |
| Chains | 把多个步骤串成流程 |
| Agents | 让 LLM 自主决定用什么工具 |
| Memory | 对话记忆 |
| Retrievers | 从向量库检索(RAG) |
简单示例:
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="gpt-4")
prompt = ChatPromptTemplate.from_template("用一句话解释 {topic}")
chain = prompt | llm
result = chain.invoke({"topic": "机器学习"})
RAG 示例:
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever(),
)
answer = qa_chain.run("公司请假流程是什么?")
ReAct Agent 示例:
from langchain.agents import initialize_agent, AgentType
agent = initialize_agent(
tools=[search_tool, calculator_tool],
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True # 打印思考过程
)
agent.run("北京今天比上海热多少度?")
3.3 Dify vs LangChain
| 维度 | Dify | LangChain |
|---|---|---|
| 定位 | 低代码平台 | 代码框架 |
| 使用方式 | 拖拽 + 配置 | 写 Python |
| 灵活性 | 中 | 高 |
| 上手难度 | 低 | 中 |
| 适合 | 快速验证 | 深度定制 |
常见组合:用 Dify 快速验证想法,用 LangChain 做深度定制。
3.4 FastMCP
快速构建 MCP 服务器的 Python 框架,见方向二。
四、学习路线建议
第一阶段:基础(1-2 周)
- 了解 LLM 基本概念
- 注册使用 Dify 平台
- 用 Dify 创建一个简单的聊天机器人
- 了解 RAG、Agent、MCP 的基本原理
第二阶段:单项深入(2-4 周)
依次学习三个核心技术:
RAG:
- 学习向量数据库(推荐 Chroma 入门)
- 理解 Embedding 原理
- 用 Dify 搭建知识库问答
Agent:
- 学习 ReAct 模式
- 学习 LangChain Agent
- 在 Dify 中配置 Agent + 工具
MCP:
- 学习 FastMCP 框架
- 开发一个简单的 MCP Server
- 与 Claude Desktop 集成
第三阶段:组合实战(4+ 周)
把三个技术组合起来,做一个完整项目:
示例项目:企业智能助手
- RAG:接入公司知识库(产品文档、规章制度)
- MCP:连接内部系统(OA、CRM、数据库)
- Agent:自主规划,根据问题决定查知识库还是调系统
这样的项目能覆盖所有核心技术,也是最接近实际落地的形态。
附录:常用资源
数据库选型
| 数据库 | 类型 | 用途 |
|---|---|---|
| Chroma / Milvus | 向量库 | RAG 检索 |
| Neo4j / NebulaGraph | 图数据库 | KAG 知识图谱 |
| Redis | 缓存 | 会话存储 |
学习资源
- Dify 官方文档:https://docs.dify.ai
- LangChain 文档:https://python.langchain.com
- FastMCP 项目:GitHub 搜索 FastMCP
- Anthropic MCP 文档:官方 Claude 文档
文档版本:v2.0 整理日期:2026年1月

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)