ImagineNav++:通过场景想象激发视觉语言模型,使其成为具身导航器
26年1月来自东南大学和上海AI实验室的论文“ImagineNav++: Prompting Vision-Language Models as Embodied Navigator through Scene Imagination”。视觉导航是自主家庭辅助机器人的一项基本能力,它使机器人能够执行诸如物体搜索等长时域任务。虽然近期的方法利用大语言模型(LLM)来融合常识推理并提高探索效率,但它们
26年1月来自东南大学和上海AI实验室的论文“ImagineNav++: Prompting Vision-Language Models as Embodied Navigator through Scene Imagination”。
视觉导航是自主家庭辅助机器人的一项基本能力,它使机器人能够执行诸如物体搜索等长时域任务。虽然近期的方法利用大语言模型(LLM)来融合常识推理并提高探索效率,但它们的规划过程仍然受限于文本表示,无法充分捕捉空间占用或场景几何信息——而这些信息对于做出明智的导航决策至关重要。本文探索视觉-语言模型(VLM)是否能够仅使用板载RGB/RGB-D数据流实现无地图的视觉导航,从而释放其在空间感知和规划方面的潜力。
通过开发基于想象的导航框架ImagineNav++来实现这一目标。该框架能够想象机器人在重要视角下的未来观测图像,并将复杂的导航规划过程转化为VLM的简单最佳视角图像选择问题。具体而言,首先引入一个未来视角想象模块,该模块提取人类的导航偏好,生成语义上有意义的、具有高探索潜力的候选视角。这些预想的未来景象随后作为视觉提示,引导视觉-语言模型(VLM)识别最具信息量的视角。为了保持空间一致性,开发一种选择性注视记忆机制,该机制通过由稀疏到密集的框架分层整合关键帧观测数据,从而构建一个紧凑而全面的长期空间推理记忆。这种集成方法有效地将具有挑战性的目标导向导航问题转化为一系列易于处理的点-目标导航任务。
如图所示:传统基于LLM的导航流程与ImagineNav++流程的对比。传统的基于LLM的导航框架(图左)依赖于复杂的传感器数据处理和姿态估计来创建地图,然后通过LLM驱动的推理来确定探索方向。而ImagineNav++则直接将远距离目标导航任务分解为一系列用于VLM的最佳视角图像选择任务,从而避免传统级联方法中的延迟和累积误差。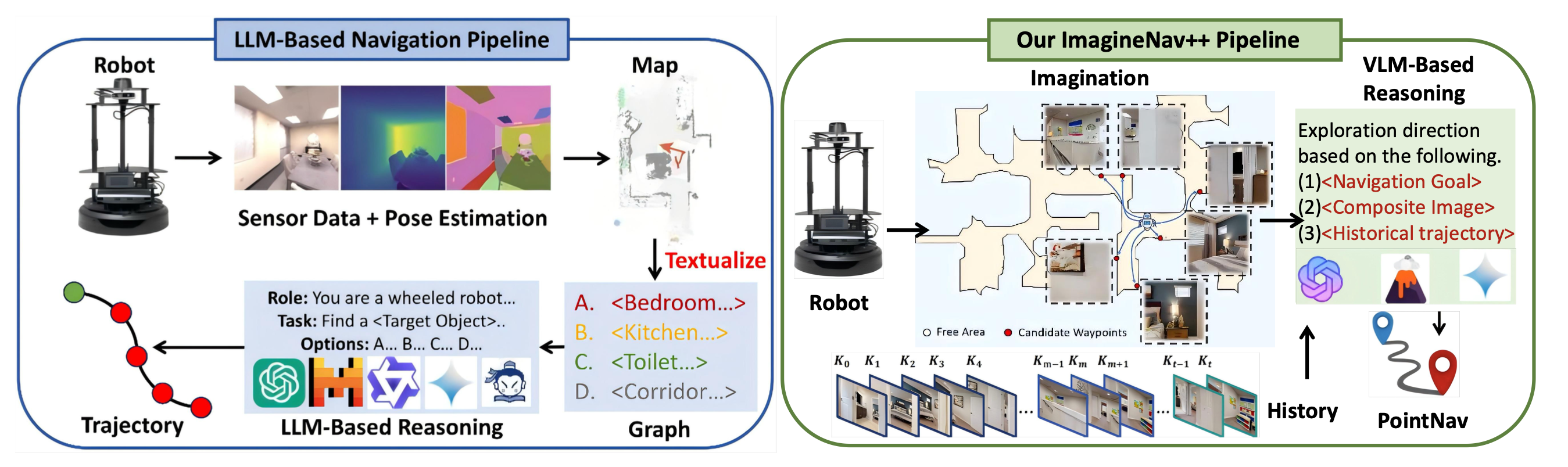
如图展示基于想象的开放词汇视觉导航框架 Imagine-Nav++ 概述。智体首先利用 Where2Imagine 模块,根据当前的视觉观测生成用于想象的候选路径点。然后,一种新视图合成 (NVS) 模型渲染与这些候选位置对应的想象视觉观测结果。通过利用智体的场景记忆,多模态大模型评估合成图像(每个图像都标注选项标签),以评估空间结构和语义一致性,从而实现对上下文感知的高效探索方向选择。具体来说,视觉-语言模型 (VLM) 被引导对六个视图的想象未来观测结果进行推理,并选择最优路径点。然后,智体采用底层点导航策略到达所选子目标。一旦确定到达子目标,系统将递归地把新的观测结果合并到分层记忆结构中,从而更新记忆。该过程递归迭代——每次新的观测结果都作为后续想象、推理和导航步骤的输入——直至成功识别目标对象的实例。通过这种机制,面向目标的视觉导航任务被分解为一系列易于管理的点-目标导航子任务。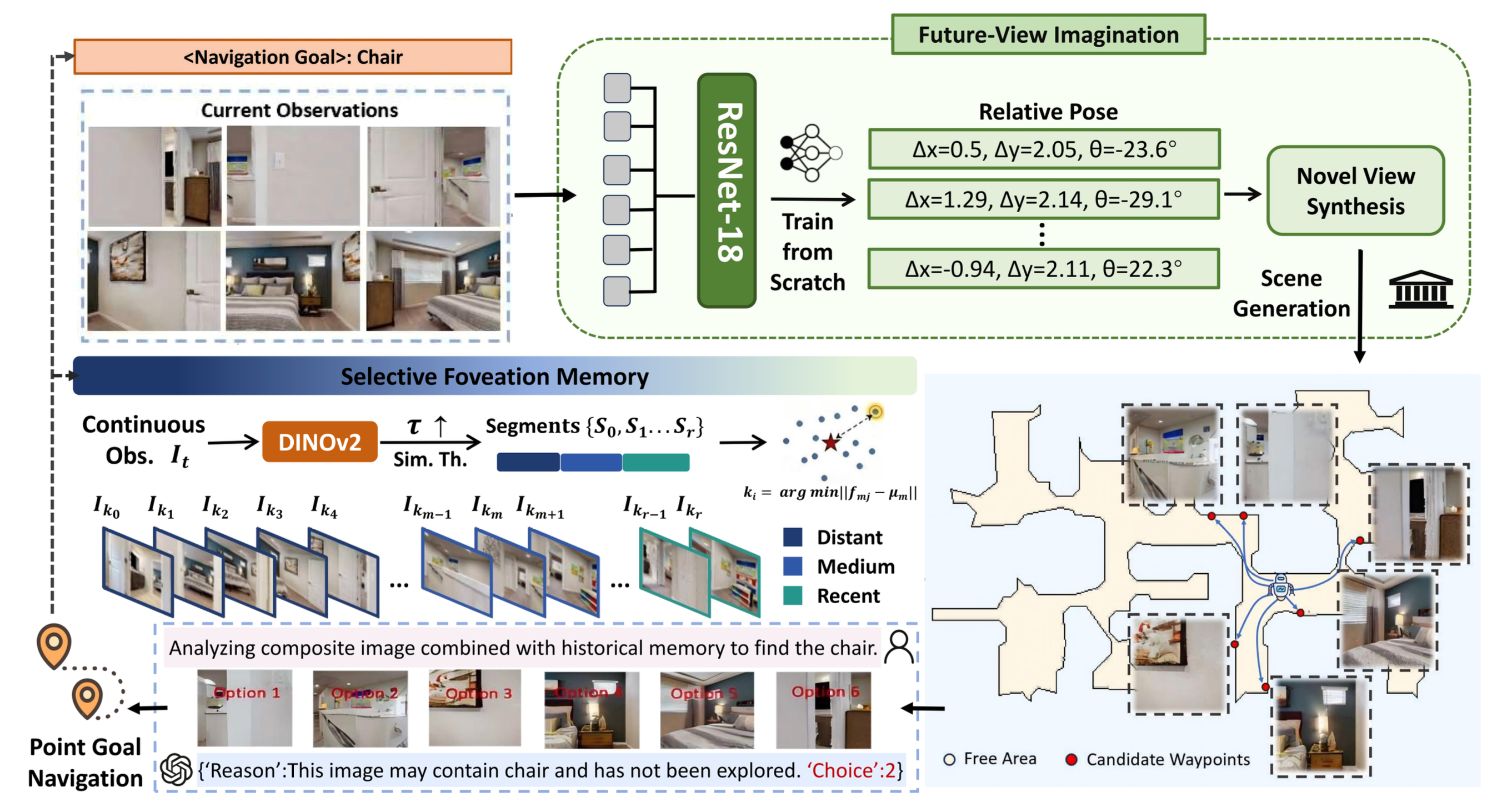
ImagineNav++ 的一个关键优势在于其无需训练的推理和规划流程,该流程不需要任何特定于对象的数据,使其本质上是开放词汇表的,并且能够零样本泛化到未见过的语义目标。
Where2Imagine 根据当前的 RGB 观测值预测潜在的下一个航点相对姿态 (∆x, ∆y, ∆θ),其中 ∆x、∆y 和 ∆θ 分别表示横向位移、纵向位移和视角变化。该预测姿态随后被输入到 NVS 模块中,以生成相应的想象观测图像。近年来,NVS 取得显著进展,从少样本 3D 渲染技术 [75]–[77] 到生成模型(特别是扩散模型 [33]–[35]),各种先进方法在各个领域都展现出了强大的图像合成能力。本文采用预训练的扩散模型“Polyoculus” [33] 进行未来视图想象,因为它能够根据单个 RGB 图像和相对姿态生成感知一致且高保真的新视图。
为了使 Where2Imagine 模块具备类似人类的空间直觉以进行路径点预测,用来自 Habitat-Web 项目 [4] 的人类演示数据,从头开始训练一个 ResNet-18 模型 [78]。该数据包含 8 万条 ObjectNav 轨迹和 1.2 万条 Pick&Place 轨迹,这些轨迹是通过亚马逊 Mechanical Turk 上的虚拟远程操作系统收集的,捕捉人类在室内环境中的自然导航行为。从这些演示中得出的一个关键见解是,人类始终倾向于选择指向语义上有意义的结构(例如门)的方向,以便于探索,如图所示。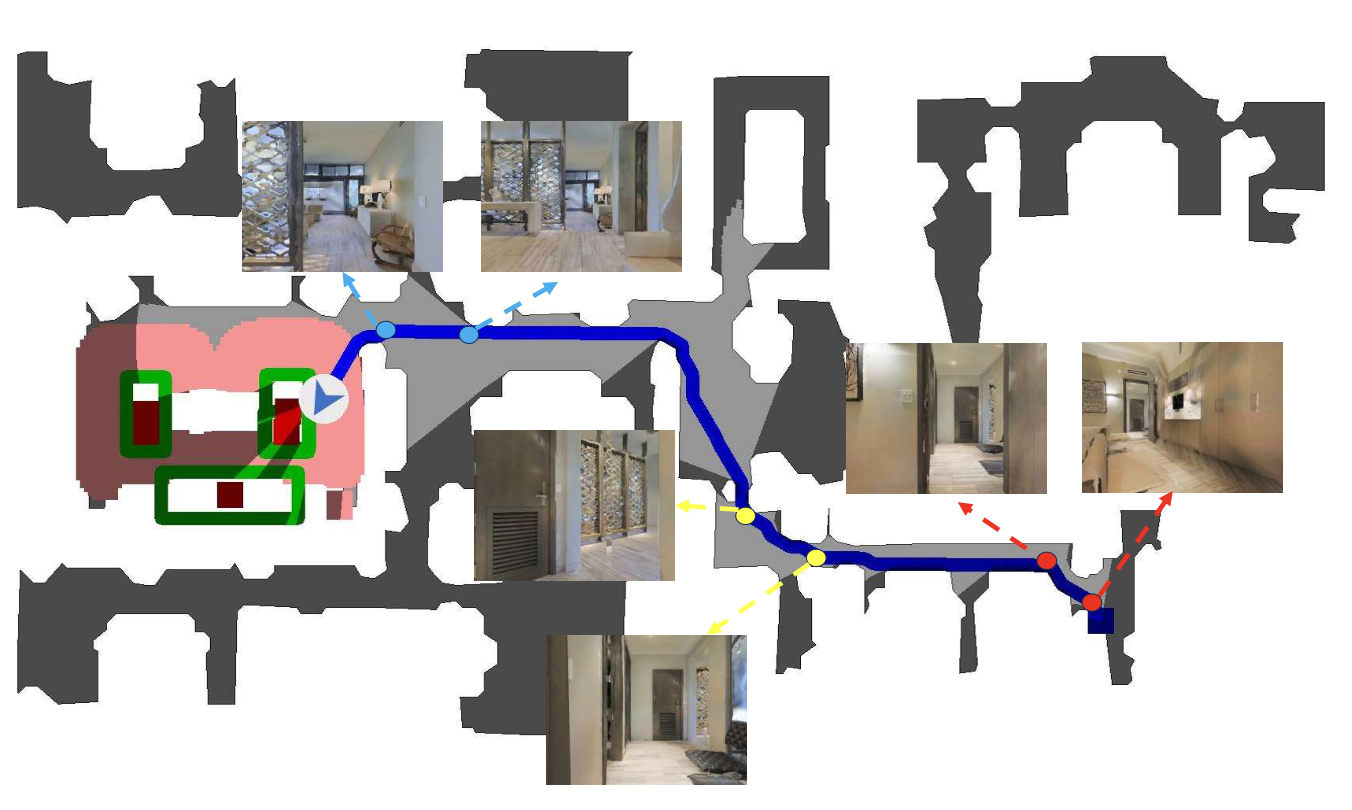
通过学习这些演示,该模型获得语义信息的导航偏好,使其能够预测几何上合理且语义上有意义的路径点,从而支持高效且具有上下文感知能力的导航。将人类演示轨迹重新构建为一个配对数据集{(O_t , P_t+T)},其中P_t+T =(∆x, ∆y, ∆θ)表示相对于智体当前坐标系O_t的真实相对航点姿态。这里,T定义一个预测性的时间范围,它捕捉人类如何预测和导航语义上有意义的空间尺度。为了提高学习效率,应用一个基于深度的过滤器来排除语义内容有限的观测值(例如,空白墙壁的特写镜头)。
此外,考虑到基于扩散的 NVS 模型在处理极端视角变化(例如 120°、180°、240°)方面的固有限制,将训练集中的角度偏差 ∆θ 限制为 30°,以确保合成质量和感知一致性。此筛选流程增强训练稳定性,并通过 Where2Imagine 模块促进生成逼真、类人的路径点。最后,使用预测路径点姿态与真实路径点姿态之间的均方误差 (MSE) 损失对模型进行端到端训练。
在推理过程中,在导航时间步 t,模型根据六个当前视图 I_t,i, i ∈ {1,2,···,6} 预测相对航点姿态。然后,将集合 {(I_t,i, Pˆ_t+T,i)} 传递给扩散模型,以生成想象的航点观测值 {M_t,i}。
在复杂的室内导航场景中,关键帧作为一种紧凑而信息丰富的表征,能够捕捉时间序列中显著的空间和上下文信息。它们减少了数据冗余,保留了关键的感知线索,从而提高了记忆效率,并支持长期时间推理。然而,从观测数据中可靠地提取这些关键帧仍然是一个挑战,尤其是在识别扩展视觉流中语义有意义的片段方面。
传统的关键帧提取方法通常依赖于手工设计的特征,例如用于聚类的颜色直方图[79]–[81],但这难以捕捉帧之间深层的语义相似性。相比之下,现代深度学习方法可以对复杂的时空依赖关系进行建模,但通常需要大量的监督学习,需要大量的人工标注[82]–[85]。这促使探索DINOv2[43]以零样本的方式提取关键帧,其中关键帧的选择主要由帧间的视觉相似性驱动。 DINOv2 在大规模且多样化的图像语料库上进行自监督预训练,使其能够学习统一的视觉表征,从而内在地编码整体场景结构。因此,该模型对场景级变化表现出显著的敏感性,使其特别适合识别语义代表性的关键帧,而无需进行特定任务的训练。
具体而言,给定一个截至时间 t 的历史观测序列 O = {I_1, I_2, …, I_t},首先使用 DINOv2 对每个观测进行编码,以提取判别性特征嵌入 F = {f_1, f_2, …, f_t}。为了构建一个紧凑而又信息丰富的记忆,采用一种基于语义相似性的关键帧选择策略。具体来说,反向遍历整个序列,测量连续帧特征之间的余弦相似度。如果 s_i,i+1 > τ,则将相邻帧 I_i 和 I_i+1 归为同一语义片段;否则,I_i 开始一个新的片段。这里,τ 是一个随时间变化的阈值,用于控制分割粒度:τ 值越高,记忆越密集;τ 值越低,记忆越稀疏。该聚合过程最终生成 M 个语义片段 {S_1, S_2, …, S_M},从每个片段中选择最接近其平均特征的帧作为关键帧。形式上,对于每个包含帧 {I_m1, I_m2, …, I_m_Nm} 的片段 S_m,计算其特征质心。然后确定从 S_m 中选择的关键帧 I_km。所有片段的代表性关键帧集合表示为 M = {I_k1, I_k2, …, I_kM}。
此外,在具身视觉导航中,来自不同时间步的视觉观察实际上服务于不同的目的。确切地说,近期观测捕捉的是精细的局部细节,而远期历史观测则构建一个连贯的全局背景。基于这些认识,用基于关键帧计数的准则,将截至当前时间步 t 的观测历史 O 划分为三个时间段:远期记忆 T_d、中期记忆 T_m 和近期记忆 T_r。为这些时间段分配递减的阈值 τ_d < τ_m < τ_r,从而使关键帧密度从远期到近期单调递增。具体来说,从当前帧 I_t 开始向前推进:
近期记忆 M_r 通过顺序选择并添加关键帧形成,选择依据为相似度阈值 τ_r,直到选择 N_r 个关键帧。
中期记忆 M_m 继续向前推进,直到收集到 N_m 个关键帧。
远期记忆 M_d 包含所有其他关键帧,这些关键帧通过语义分割,使用相似度阈值 τ_d 从所有先前的观测帧中提取出来。
这种设计模拟注视点记忆机制,强调近期高细节上下文,同时保持长期的结构连贯性。由此产生的分层记忆 M = {M_r, M_m, M_d} 为视觉语言模型 (VLM) 提供结构化的时空上下文,平衡实时细节和长期连贯性。
高层规划模块利用VLM的空间感知和常识推理能力,选择最有利于定位导航目标的方向。采用GPT-4o-mini [86] 作为高层规划器,因为它在推理性能和实际效率之间取得良好的平衡。为了辅助GPT-4o-mini进行决策,设计一个简单的提示模板,要求VLM以JSON格式总结其选择,格式为{‘原因’, ‘选择’}。这种格式便于清晰地理解VLM的推理过程。VLM接收对潜在未来航点、历史记忆和导航目标的综合观测结果。在分层提示的引导下,它分析每个视图的语义内容,选择最佳探索方向,并以结构化格式返回其决策。
将想象的未来观测结果与历史关键帧作为视觉提示相结合,显著增强了 ImagineNav++ 的空间推理和长期决策能力。首先,与 3D 几何问答(即直接推断下一个航点的 3D 坐标)相比,VLM 更擅长处理多项选择决策任务。此外,引入想象的未来观测结果,通过提供关于远处或视觉上不清晰物体的丰富上下文信息,增强了 VLM 对场景的理解,而历史关键帧则保持环境状态随时间变化的连贯性表征。这种互补机制有效地缓解感知不确定性,并促进稳健的长时程推理。
所提出的想象引导推理程序——整合航点想象和高层规划——以周期性循环运行:每隔 T 步触发一次,并且仅在底层控制器成功完成到达当前目标的导航后才会提出新的子目标。该设计确保计算效率和稳健的远距离导航性能之间的有效平衡。
在高层规划器选择航点之后,底层控制器执行点目标导航(PointNav)策略以到达每个指定目标。与依赖环境语义线索的ObjectNav不同,PointNav完全基于空间感知,使用相对位移指令(∆x,∆y)而无需语义理解。目前已有多种成熟的PointNav实现方法[87]–[90]。在框架中,采用可变的经验展开(VER [89])作为每个导航步骤中动作选择的底层策略。VER结合同步和异步强化学习范式的优势,从而提高训练效率和样本利用率。因此,智体在新颖和复杂的环境中展现出更强的适应性和泛化性能。
用 Habitat v3.0 模拟器 [93] 评估 ImagineNav++ 在目标导航 (ObjectNav) 和实例图像目标导航 (InsINav) 两种任务上的有效性和导航效率。对于目标导航,在三个广泛应用的数据集上进行实验:Gibson [46]、HM3D [44] 和 HSSD [45]。具体来说,采用 SemExp [3] 中提出的 Gibson 数据集的目标导航训练集和验证集划分,涵盖 27 个场景和 6 个物体类别。HM3D 数据集用于 Habitat 2022 目标导航挑战赛,包含 2000 个验证集,涵盖 20 个独特的环境和 6 个物体类别。最近推出的 HSSD 数据集包含 40 个高质量的合成场景,以及 1200 个验证集,涵盖 6 个物体类别。对于 InsINav,遵循先前工作 [5]、[6] 中建立的协议,在 HM3D 数据集 [44] 上评估其性能。实验配置符合 ObjectNav Challenge 2023 的指导原则 [94]。为了支持 Where2Imagine 模块的数据采集,使用 habitat-web 项目中的 MP3D 数据集 [95] 中的人体演示轨迹,相机高度为 0.88 米,水平视场角 (HFOV) 为 79°。
对于目标导航,对非零样本和零样本目标导航方法进行比较分析,以严格评估 ImagineNav++ 框架的优越性。FBE [1] 开创了一种基于边界的探索策略,强调已探索区域和未探索区域之间的边界。SemExp [3] 通过构建语义地图实现了目标导向的语义探索,从而推进这一概念。此外,还考察无地图的闭集视觉导航基线方法,包括基于模仿学习 [4] 和视觉表征学习 [91] 的方法。对于零样本目标导航,评估几个基于地图的基线方法 [6]、[25]、[27]、[61]、[70]、[92]。其中,[25]、[27]、[61]、[70] 维护场景的语义二维地图,并利用语义知识辅助导航至目标对象;而 SG-Nav [92] 和 UniGoal [6] 则使用三维场景图表示观测场景,并利用 LLM 进行显式的基于图的推理。此外,还研究基于 RGB 的非地图导航基线方法,包括 ZSON [59]、PSL [5] 和 PixNav [2]。具体而言,ZSON 和 PSL 采用 CLIP 模型 [7] 将目标图像和对象目标嵌入到统一的语义空间中,从而能够训练语义目标驱动的导航智体;而 PixNav 则利用 VLM 和 LLM 提供的像素级引导来实现像素级精确导航。
对于 InsINav 任务,将其与监督学习方法 Krantz[97]、OVRL-v2 [98] 以及零样本学习方法 Mod-IIN [62]、Goat [61]、UniGoal [6] 和 PSL [5] 进行比较。Krantz [97] 开创 InsINav 任务,并建立一个基于近端策略优化 (PPO [99]) 和可变的经验展开 (VER [89]) 端到端强化学习基线。OVRL-v2 [98] 采用一种将 ViT 与 LSTM 相结合的架构,通过自监督视觉预训练实现端到端的导航学习,而 OVRL-v2-IIN 则使用 OVRL-v2 [98] 的协议专门针对 InsINav 任务进行微调。在这些零样本方法中,Mod-IIN [62] 专门针对 InsINav 任务而设计,它利用特征匹配在以自我为中心的视觉环境中重新识别目标实例,并通过将匹配的特征投影到地图上来定位目标实例。Goat [61] 通过构建实例感知语义记忆,利用 CLIP [7] 和 SuperGlue [100] 进行多模态目标匹配,并将边界探索与经典路径规划相结合,从而实现终身导航。相比之下,UniGoal [6] 通过统一的图表示将不同的目标和场景图对齐到一个共享空间,并利用图匹配动态地引导其探索,从而实现通用导航。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献194条内容
已为社区贡献194条内容

所有评论(0)