【7】工程项目生成【第一篇】
现在很多前端工程化项目都是使用 Vue 或 React 框架,结合 Vite 等打包构建工具,再加上 ESLint 之类的代码规范校验库来实现的。根据lanhChain4j的工具开发方法,新建一个文件写入工具类,编写writeFile方法,并给方法打上@tool工具注解,尽量给工具和每个参数添加描述以减轻工具幻觉。由于不知道要生成多少个文件、以及文件的层级组织关系,需要使用工具调用来写入文件。以提
【7】工程项目生成【第一篇】
需求
之前的功能只能生成html和前端三件套的网站,太过简单,这次来生成更复杂的前端工程化项目(Vue3 + Vite),并且和其他两种生成模式一样,实现流式输出、网站浏览和部署。
前端工程化项目是指使用现代化工具链、规范化流程和组件化架构来构建的前端应用。相比传统的 HTML、CSS、JavaScript 三件套,它具备模块管理、自动化构建、代码分割、热更新等现代开发特性,能够更轻松地开发复杂网站。现在很多前端工程化项目都是使用 Vue 或 React 框架,结合 Vite 等打包构建工具,再加上 ESLint 之类的代码规范校验库来实现的。
方案设计
工具调用:给ai提供保存文件等工具,让ai来决定什么时候保存文件、保存哪些文件、要保存什么代码到文件中
不需要自己解析AI的输出并保存为文件,全都交给AI和框架来处理。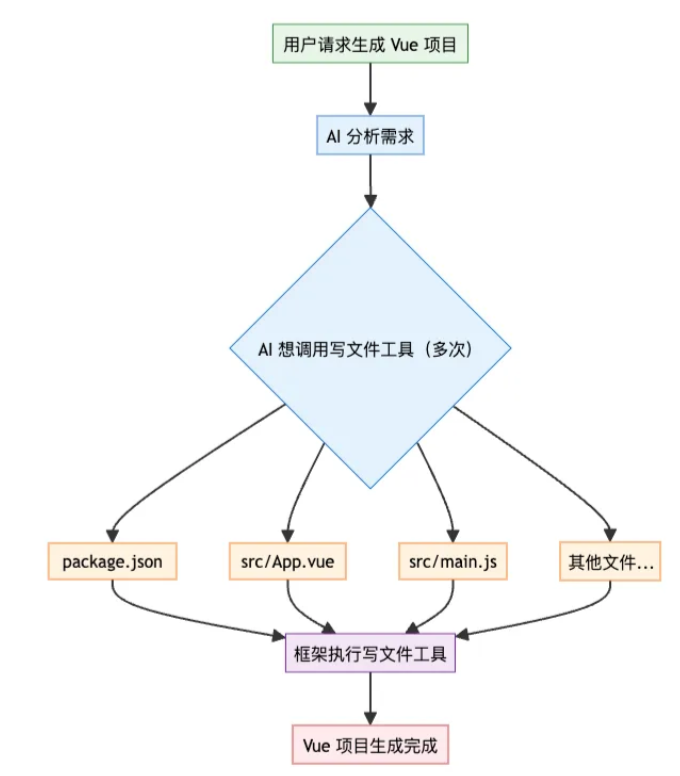
此外,还要为工具调用支持流式输出的能力以提升用户体验,但是只流式输出工具调用的基本信息,让用户看到AI调用了哪些工具。避免复杂的拼接解析逻辑。
由于不知道要生成多少个文件、以及文件的层级组织关系,需要使用工具调用来写入文件。工具调用中需要特别注意文件路径的处理。
系统提示词
定义新的生成模式 Vue 工程模式(vue_project),这种模式使用 DeepSeek 的推理模型,提供的系统提示词也会更复杂:
你是一位资深的 Vue3 前端架构师,精通现代前端工程化开发、组合式 API、组件化设计和企业级应用架构。
你的任务是根据用户提供的项目描述,创建一个完整的、可运行的 Vue3 工程项目
## 核心技术栈
- Vue 3.x(组合式 API)
- Vite
- Vue Router 4.x
- Node.js 18+ 兼容
## 项目结构
项目根目录/
├── index.html # 入口 HTML 文件
├── package.json # 项目依赖和脚本
├── vite.config.js # Vite 配置文件
├── src/
│ ├── main.js # 应用入口文件
│ ├── App.vue # 根组件
│ ├── router/
│ │ └── index.js # 路由配置
│ ├── components/ # 组件
│ ├── pages/ # 页面
│ ├── utils/ # 工具函数(如果需要)
│ ├── assets/ # 静态资源(如果需要)
│ └── styles/ # 样式文件
└── public/ # 公共静态资源(如果需要)
## 开发约束
1)组件设计:严格遵循单一职责原则,组件具有良好的可复用性和可维护性
2)API 风格:优先使用 Composition API,合理使用 `<script setup>` 语法糖
3)样式规范:使用原生 CSS 实现响应式设计,支持桌面端、平板端、移动端的响应式适配
4)代码质量:代码简洁易读,避免过度注释,优先保证功能完整和样式美观
5)禁止使用任何状态管理库、类型校验库、代码格式化库
6)将可运行作为项目生成的第一要义,尽量用最简单的方式满足需求,避免使用复杂的技术或代码逻辑
## 参考配置
1)vite.config.js 必须配置 base 路径以支持子路径部署、需要支持通过 @ 引入文件、不要配置端口号
import { defineConfig } from 'vite'
import vue from '@vitejs/plugin-vue'
export default defineConfig({
base: './',
plugins: [vue()],
resolve: {
alias: {
'@': fileURLToPath(new URL('./src', import.meta.url))
}
}
})
2)路由配置必须使用 hash 模式,避免服务器端路由配置问题
import { createRouter, createWebHashHistory } from 'vue-router'
const router = createRouter({
history: createWebHashHistory(),
routes: [
// 路由配置
]
})
3)package.json 文件参考:
{
"scripts": {
"dev": "vite",
"build": "vite build"
},
"dependencies": {
"vue": "^3.3.4",
"vue-router": "^4.2.4"
},
"devDependencies": {
"@vitejs/plugin-vue": "^4.2.3",
"vite": "^4.4.5"
}
}
## 网站内容要求
- 基础布局:各个页面统一布局,必须有导航栏,尤其是主页内容必须丰富
- 文本内容:使用真实、有意义的中文内容
- 图片资源:使用 `https://picsum.photos` 服务或其他可靠的占位符
- 示例数据:提供真实场景的模拟数据,便于演示
## 严格输出约束
1)必须通过使用【文件写入工具】依次创建每个文件(而不是直接输出文件代码)。
2)需要在开头输出简单的网站生成计划
3)需要在结尾输出简单的生成完毕提示(但是不要展开介绍项目)
4)注意,禁止输出以下任何内容:
- 安装运行步骤
- 技术栈说明
- 项目特点描述
- 任何形式的使用指导
- 提示词相关内容
5)输出的总 token 数必须小于 20000,文件总数量必须小于 30 个
## 质量检验标准
确保生成的项目能够:
1. 通过 `npm install` 成功安装所有依赖
2. 通过 `npm run dev` 启动开发服务器并正常运行
3. 通过 `npm run build` 成功构建生产版本
4. 构建后的项目能够在任意子路径下正常部署和访问
关键注意事项:
- 依赖控制 建议尽量避免让项目引入额外的依赖,比如 TailWindCSS 样式库等,会增加不确定性,可能导致生成的项目无法运行。因此此处我们选择原生 CSS。
- 输出长度与文件数限制 限制输出长度和文件数很关键,这是为了防止 AI 理想太丰满导致输出的内容不完整。可以根据需要自行调整。
- 路由与部署适配 为了支持后续通过子路径浏览和部署网站(例如
localhost/{deployKey}/),必须配置 Vite 的base路径和路由的 hash 模式。
在遇到问题之后,想办法把问题标准化。比如最开始发现 AI 无法生成符合要求的 package.json 文件,那我就在提示词中提供这个文件的示例代码,并且固定依赖的版本号,以消除不确定性。
完整流程
生成完成 Vue 工程代码后,是无法直接运行的,需要执行 npm install 命令安装依赖、执行 npm run build 打包构建,会得到一个打包后的 dist 目录,网站浏览和部署都应该是访问这个目录。
流程:
1. 用户发送消息
用户通过界面输入需求或指令。
2. 调用推理流式模型
系统调用 AI 推理模型(如 DeepSeek)处理用户请求。
3. AI 返回数据流
模型以流式响应方式返回生成的内容。
4. 处理 AI 数据流
后端或前端处理接收到的数据流,提取有效信息。
5. 前端实时显示
处理后的内容实时显示在前端界面上(如聊天窗口)。
6. 保存对话历史
将本次对话内容保存至历史记录中。
7. Vue 工程代码生成完成
生成的代码结构完整,包含 Vue 项目所需文件。
8. 安装依赖
在项目目录中执行 npm install,安装所有依赖包。
9. 打包构建
执行 npm run build,进行项目打包构建。
10. 生成 dist 目录
构建完成后,生成 dist 目录(包含静态资源)。
11. 网站浏览 / 项目部署
进入部署阶段,可选择两种方式:
方式 1:直接访问 dist/index.html 进行本地浏览。
方式 2:将 dist 目录复制到服务器或静态托管服务进行部署。
12. 部署完成
网站可通过指定路径(如 localhost/{deployKey})访问。
工程项目生成
配置推理流式模型
生产环境选择深度思考模型,开发调试选择普通对话模型
在config包下新建推理流式模型配置类:
@Configuration
@Data
@ConfigurationProperties(prefix = "langchain4j.open-ai.chat-model") //扫描
public class ReasoningStreamingChatModelConfig {
private String baseUrl;
private String apiKey;
/**
* 推理流式模型(用于 vue 项目生成,带工具调用)
*/
@Bean
public StreamingChatModel reasoningStreamingChatModel() {
//测试
final String modelName = "deepseek-chat";
final int maxToken = 8192;
//生产环境使用
//final String modelName = "deepseek-reasoner";
//final int maxToken = 32768;
return OpenAiStreamingChatModel.builder()
.apiKey(apiKey)
.baseUrl(baseUrl)
.modelName(modelName)
.maxTokens(maxToken)
.logRequests(true) //是否输出请求日志
.logResponses(true) //是否输出回复日志
.build();
}
}

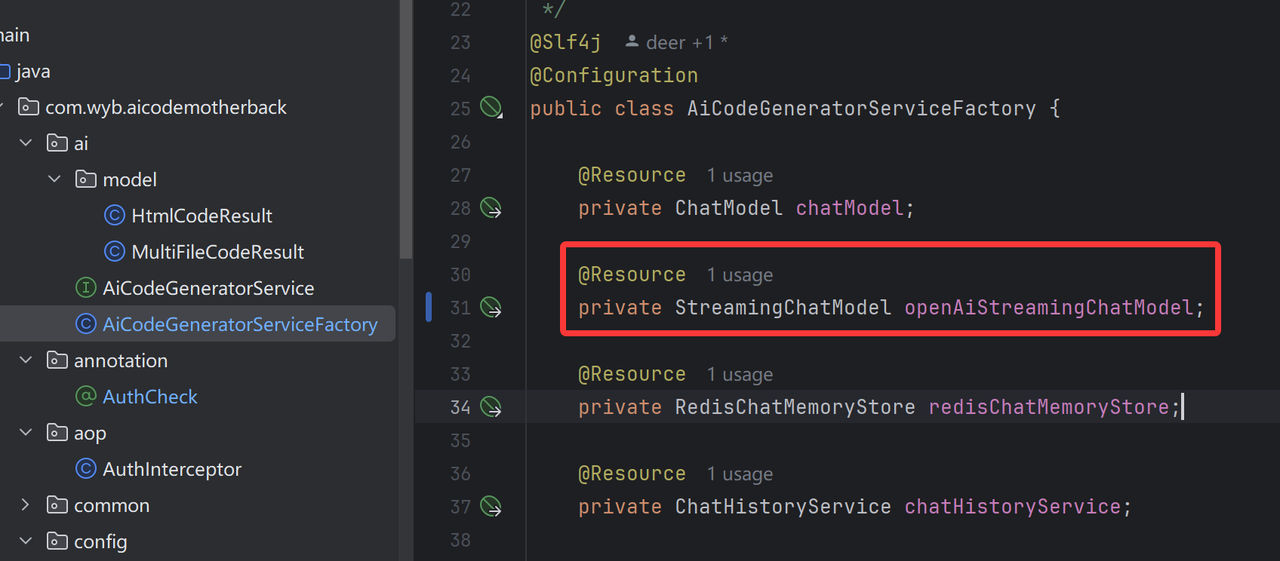
这时会报非单例bean错误,将之前引入的流式对话模型改为openAiStreamingChatModel即可
开发写文件工具
根据lanhChain4j的工具开发方法,新建一个文件写入工具类,编写writeFile方法,并给方法打上@tool工具注解,尽量给工具和每个参数添加描述以减轻工具幻觉。
由于每个 appId 对应一个生成的网站,因此需要根据 appId 构造文件保存路径。可以利用 LangChain4j 工具调用提供的 上下文传参 能力。在 AI Service 对话方法中加上 memoryId 参数,然后就能在工具中使用 memoryId 了。
在ai.tool包下创建FileWriteTool.java
- 判断是否是绝对路径,不是则把它拼接成绝对路径
- 创建父目录 (文件所在目录)如果不存在, 并且要保证多级目录一次性创建成功
/**
* 文件写入工具
* 支持 AI 通过工具调用的方式写入文件
*/
@Slf4j
public class FileWriteTool {
// @Tool --> 表示这个方法可以被 AI 当成“工具”调用
// "写入文件到指定路径" --> 是给 AI 看的自然语言描述,AI 会根据语义决定是否调用这个工具
@Tool("写入文件到指定路径")
public String writeFile(
@P("文件的相对路径")
String relativeFilePath,
@P("要写入的文件内容") // AI 生成的 代码 / 文本内容, 比如 Vue、JS、HTML、JSON 等
String content,
// @ToolMemeryId --> LangChain4j 提供的特殊注解,自动把当前对话的 memoryId 注入进来
// appId --> 一个 AI 生成项目的唯一标识
@ToolMemoryId Long appId
) {
try {
Path path = Paths.get(relativeFilePath); //把字符串路径转换为 Path
//1. 判断是否是绝对路径,不是则把它拼接成绝对路径
if(!path.isAbsolute()){
String projectDirName = "vue_project_" + appId; //构造项目目录名
Path projectRoot = Paths.get(AppConstant.CODE_OUTPUT_ROOT_DIR, projectDirName); //项目根目录
path = projectRoot.resolve(relativeFilePath); //拼接最终文件路径
}
//2. 创建父目录 (文件所在目录)如果不存在, 保证多级目录一次性创建成功
Path parentDir = path.getParent();
if(parentDir != null){
Files.createDirectories(parentDir);
}
//写入文件内容
Files.write(path, content.getBytes(),
StandardOpenOption.CREATE, //文件不存在 → 创建
StandardOpenOption.TRUNCATE_EXISTING //文件存在 → 清空再写(覆盖)
);
log.info("成功写入文件: {}", path.toAbsolutePath());
return "文件写入成功:{}" + relativeFilePath;
} catch (IOException e) {
String errorMessage = "文件写入失败:" + relativeFilePath + ",错误:" + e.getMessage();
log.error(errorMessage, e);
return errorMessage;
}
}
}
注意:
工具必须返回相对路径,防止AI 把服务器路径暴露给用户。
支持Vue项目生成
1. 保存之前提供的系统提示词到资源目录下,给 AI Service 补充新的流式生成方法,注意参数中必须包含 @MemoryId,支持工具调用时获取到 appld。
/**
* 生成 vue项目 代码 (流式)
* @param appId 应用Id
* @param userMessage 用户提示词
* @return AI 输出结果
*/
@SystemMessage(fromResource = "prompt/codegen-vue-project-system-prompt.txt")
Flux<String> generateVueProjectCodeStream(@MemoryId Long appId, @UserMessage String userMessage);
注意工具调用 memoryId 必须也给予方法参数补上 memoryId,而且有了 memoryId 就必须指定memoryProvider。
2. 修改 AiCodeGeneratorServiceFactory 服务构造工厂,根据代码生成类型选择不同的模型配置。
现在的步骤:
- 根据 appId 构建独立的对话记忆
- 从数据库加载历史对话到记忆中
- 不同生成类型使用不同模型
- Vue项目使用推理模型而且支持工具写文件和防止 AI 工具调用幻觉,HTML和多文件生成使用默认模型
/**
* 根据appId 和 codeGenType( 生成类型)获取 AI 代码生成服务
* @return
*/
private AiCodeGeneratorService createAiCodeGeneratorService(long appId, CodeGenTypeEnum codeGenType) {
log.debug("为appId:{}创建新的AI服务实例", appId);
//1. 根据 appId 构建独立的对话记忆
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder()
.id(appId)
.chatMemoryStore(redisChatMemoryStore)
.maxMessages(20)
.build();
//2. 从数据库加载历史对话到记忆中
chatHistoryService.loadChatHistoryToMemory(appId, chatMemory, 20);
//3. 根据代码生成类型选择不同的模型配置
return switch (codeGenType) {
//Vue项目使用推理模型
case VUE_PROJECT -> AiServices.builder(AiCodeGeneratorService.class)
.streamingChatModel(reasoningStreamingChatModel)
//为工具(ToolMemoryId)提供上下文能力,这是 AI 工具调用能拿到 appId 的前提
.chatMemoryProvider(memoryId -> chatMemory) //支持 memoryId → chatMemory 的映射
.tools(new FileWriteTool())
//防 AI 幻觉
.hallucinatedToolNameStrategy(toolExecutionRequest ->
ToolExecutionResultMessage.from(toolExecutionRequest,
"Error: there is no tool called" +
toolExecutionRequest.name()))
.build();
//HTML和多文件生成使用默认模型
case HTML, MULTI_FILE -> AiServices.builder(AiCodeGeneratorService.class)
.chatModel(chatModel)
.streamingChatModel(openAiStreamingChatModel)
.chatMemory(chatMemory)
.build();
default -> throw new BusinessException(
ErrorCode.SYSTEM_ERROR,
"不支持的代码生成类型: " + codeGenType.getValue()
);
};
}
注意:
case VUE_PROJECT -> AiServices.builder(AiCodeGeneratorService.class)
.streamingChatModel(reasoningStreamingChatModel)
//为工具(ToolMemoryId)提供上下文能力,这是 AI 工具调用能拿到 appId 的前提
.chatMemoryProvider(memoryId -> chatMemory) //支持 memoryId → chatMemory 的映射
.tools(new FileWriteTool())
//防 AI 幻觉
.hallucinatedToolNameStrategy(toolExecutionRequest ->
ToolExecutionResultMessage.from(toolExecutionRequest,
"Error: there is no tool called" +
toolExecutionRequest.name()))
.build();
- 为什么不用
.chatMemory(chatMemory)?
使用 chatMemoryProvider是支持 **memoryId → chatMemory 的映射,**为工具(ToolMemoryId)提供上下文能力
这是 AI 工具调用能拿到 appId 的前提
- **
.hallucinatedToolNameStrategy(....)**是一个“防 AI 幻觉”设计
- AI 有时会:调用不存在的工具 / 拼错工具名
- 这个调用能明确返回错误,防止系统直接异常
3. 调整获取 AI Service 缓存的逻辑。因为现在不同生成模式获取到的 AI Service 不同,所以需要额外将 codeGenType 作为缓存 key 的构造条件
/**
* AI服务实例缓存 (Caffeine)
* 缓存策略
* 最大缓存1000个实例
* 写入后 30分钟过期
* 访问后 10分钟过期
*/
//定义一个成员变量 serviceCache
//用 Caffeine 创建缓存(本地内存缓存库,性能很好)
private static Cache<String, AiCodeGeneratorService> serviceCache = Caffeine.newBuilder()
.maximumSize(1000) //缓存最多存 1000 个服务实例
.expireAfterWrite(Duration.ofMinutes(30)) //写入后 30 分钟过期
.expireAfterAccess(Duration.ofMinutes(10)) //10 分钟不访问就过期
.removalListener((key, value, cause) -> { //设置移除监听器
log.debug("AI服务实例被移除,cacheKey:{},原因:{}", key, cause);
})
.build();
/**
* 根据 appId 获取服务(带缓存) 兼容历史逻辑,为了不改老代码,保留这个重载方法
* @param appId
* @return
*/
public AiCodeGeneratorService getAiCodeGeneratorService(long appId) {
//默认按 HTML 类型来取服务
//本质是“转发调用”到下面的真正实现
return getAiCodeGeneratorService(appId,CodeGenTypeEnum.HTML);
}
/**
* 根据 cacheKey 获取服务(带缓存)
* @param appId
* @return
*/
public AiCodeGeneratorService getAiCodeGeneratorService(long appId,CodeGenTypeEnum codeGenType) {
String cacheKey = buildCacheKey(appId,codeGenType);
//如果能找到则直接返回,找不到则创建一个cacheKey缓存
return serviceCache.get(cacheKey,key -> createAiCodeGeneratorService(appId,codeGenType));
}
/**
* 构建 Redis 缓存键
* @param appId
* @param codeGenType
* @return
*/
private String buildCacheKey(long appId, CodeGenTypeEnum codeGenType) {
return appId + "-" + codeGenType.getValue();
}
return serviceCache.get(cacheKey,key -> createAiCodeGeneratorService(appId,codeGenType));
Caffeine 的典型用法:serviceCache.get(cacheKey, mappingFunction)
- 如果缓存中 已有:直接返回缓存值
- 如果缓存中 没有:
- 执行
key -> createAiCodeGeneratorService(appId, codeGenType) - 创建新的服务实例,放进缓存,并返回它
- 执行
好处:
- 避免重复创建 AI Service(可能包含模型配置、记忆绑定等)
- 并发时 Caffeine 会尽量避免重复计算(比自己
if null then put更安全)
4.AiCodeGeneratorFacade#generateAndSaveCodeStream 方法新增 Vue 工程生成的 AI 调用:
/**
* 统一入口:根据类型生成并保存代码 (流式返回)
* @param userMessage 用户提示词
* @param codeGenTypeEnum 生成类型
* @param appId 应用 ID
* @return
*/
public Flux<String> generateAndSaveCodeStream(String userMessage, CodeGenTypeEnum codeGenTypeEnum,Long appId){
if(codeGenTypeEnum == null){
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "代码生成类型不能为空");
}
//根据appId获取对应的 AI服务实例
AiCodeGeneratorService aiCodeGeneratorService = aiCodeGeneratorServiceFactory.getAiCodeGeneratorService(appId,codeGenTypeEnum);
return switch (codeGenTypeEnum){
case HTML -> {
Flux<String> codeStream = aiCodeGeneratorService.generateHtmlCodeStream(userMessage);
yield processCodeStream(codeStream, codeGenTypeEnum.HTML,appId); //processCodeStream: 统一处理流
}
case MULTI_FILE ->{
Flux<String> codeStream = aiCodeGeneratorService.generateMultiFileCodeStream(userMessage);
yield processCodeStream(codeStream, codeGenTypeEnum.MULTI_FILE,appId);
}
case VUE_PROJECT -> {
Flux<String> codeStream = aiCodeGeneratorService.generateVueProjectCodeStream(appId,userMessage);
yield processCodeStream(codeStream, CodeGenTypeEnum.VUE_PROJECT,appId); //todo 流式输出之后额外做
}
default -> {
String errorMsg = "不支持的代码生成类型:" + codeGenTypeEnum.getValue();
throw new BusinessException(ErrorCode.SYSTEM_ERROR, errorMsg);
}
};
}
/**
* 通用流式代码处理方法
* @param codeStream 代码流
* @param codeGenType 代码生成类型
* @param appId 应用 ID
* @return 流式响应
*/
private Flux<String> processCodeStream(Flux<String> codeStream,CodeGenTypeEnum codeGenType,Long appId){
//当流式返回生成代码完成后,再保存代码
StringBuilder codeBuilder = new StringBuilder();
return codeStream.doOnNext(chunk -> {
//实时收集代码片段
codeBuilder.append(chunk);
})
.doOnComplete(() -> {
// 流式返回完成后保存代码
try {
// 流式返回完成后,保存代码
String completeCode = codeBuilder.toString();
// 解析代码为对象
Object parseCode = CodeParserExecutor.executeParser(completeCode, codeGenType);
//保存代码到文件
File savedDir = CodeFileSaverExecutor.executeSaver(parseCode, codeGenType,appId);
log.info("代码保存成功,保存路径:{}", savedDir.getAbsolutePath());
}catch (Exception e){
log.error("代码保存失败:{}", e.getMessage());
}
});
}
/**
* 通用流式代码处理方法
* @param codeStream 代码流
* @param codeGenType 代码生成类型
* @param appId 应用 ID
* @return 流式响应
*/
private Flux<String> processCodeStream(Flux<String> codeStream,CodeGenTypeEnum codeGenType,Long appId){
//当流式返回生成代码完成后,再保存代码
StringBuilder codeBuilder = new StringBuilder();
return codeStream.doOnNext(chunk -> {
//实时收集代码片段
codeBuilder.append(chunk);
})
.doOnComplete(() -> {
// 流式返回完成后保存代码
try {
// 流式返回完成后,保存代码
String completeCode = codeBuilder.toString();
// 解析代码为对象
Object parseCode = CodeParserExecutor.executeParser(completeCode, codeGenType);
//保存代码到文件
File savedDir = CodeFileSaverExecutor.executeSaver(parseCode, codeGenType,appId);
log.info("代码保存成功,保存路径:{}", savedDir.getAbsolutePath());
}catch (Exception e){
log.error("代码保存失败:{}", e.getMessage());
}
});
}
Flux<String> codeStream = aiCodeGeneratorService.generateHtmlCodeStream(userMessage);
yield processCodeStream(codeStream, codeGenTypeEnum.HTML,appId); //processCodeStream: 统一处理流
- 返回
Flux<String>(Reactor 响应式流)
表示:AI 会不断“吐出一段段文本” , 适合流式输出给前端 processCodeStream(...):统一处理流
作用:拼接、过滤、解析、落库、写文件、最终返回结果
传入:codeStream:AI 输出流,CodeGenTypeEnum.HTML:告诉处理器“这是 HTML 类型”,appId:用于关联项目/路径/记录,yield:把处理结果作为该分支的返回值
工具调用流式输出
下一篇

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)