[IJCAI 2025]Enhancing Long-Tail Bundle Recommendations Utilizing Composition Pattern Modelin
计算机-人工智能-尾部调整和原型约束的偏好预测

论文网址:Enhancing Long-Tail Bundle Recommendations Utilizing Composition Pattern Modeling
论文代码:Anonymized Repository - Anonymous GitHub
目录
2.5.1. Composition-aware Long-tail Adapter
2.5.2. Dual-view Prototype Learning
1. 心得
(1)不是我的领域...脑翻英可能会出现很别扭的名词
(2)梦回学注意力的时候,一毛一样的公式但是W不一样就是两个意味
(3)这个原型个数居然是超参数吗...
(4)这个任务本身好绕啊,看力竭了
2. 论文逐段精读
2.1. Abstract
①因为现在捆绑推荐里的东西只有少部分会让人非常感兴趣,而捆绑的其他一堆东西都没啥用
②为了抓住用户的兴趣,作者设计了Composition-Aware Long-tail Bundle Recommendation(CALBRec)
2.2. Introduction
①双视图的两个视角:
| user-bundle view | 建模用户与捆绑物之间的交互,关注用户是否点击、购买或喜欢某个捆绑(如歌单、套餐、图书组合) |
| user-item view | 建模用户与单个物品之间的交互,关注用户对捆绑中具体物品的行为(如歌曲、书籍) |
skew v.歪斜;偏离;歪曲;曲解;影响…的准确性;使不公允 n.斜交;扭曲;斜砌石;歪轮 adj.弯曲的;歪的;曲解的;误用的
②(a)捆绑包中少数物品交互多,多数物品交互少,常用推荐算法在常交互的(头部)物品上性能好,而在尾部物品上性能差;(b)头部物品要和能互补的尾部物品捆绑:
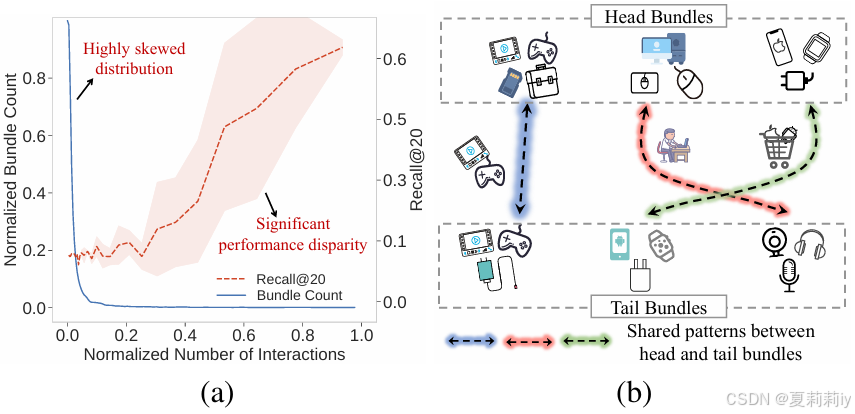
③要解决的问题:复杂的组合和长尾分布
2.3. Related Works
①以前的捆绑推荐都是基于矩阵工程或者图学习
②捆绑推荐任务类型:现有捆绑包精准推荐,个性化捆绑包组合,利用对话方式来推荐,增加多样性,提出新捆绑包
③现有解决问题的办法:数据增强和基于辅助信息的方法,作者说现在的方法都是针对单个物体而没考虑复杂的组合
2.4. Preliminary
2.4.1. Problem Formulation
①用户集,捆绑包集
,物品集
,其中
是用户个数,
是捆绑包个数,
是物品个数
②输入:
| 用户-捆绑包矩阵 | |
| 用户-物品矩阵 | |
| 捆绑包-物品矩阵 |
其中如果某个值等于1就是有关系,0就是没关系
2.4.2. Base Model
①对和
使用LightGCN(似乎节点特征是随机化的?然后用户,捆绑包和物品都会成为节点,邻接矩阵就是这些输入)(下面大图第一列很清楚):
其中是第
层的节点嵌入,
是节点
的邻居集
②用户-捆绑包的更新:
其中和
分别是用户和捆绑包的嵌入
③用户-物品的更新:
其中和
分别是用户和物品的嵌入
④基于以上嵌入得到:
算出来的东西是用户-捆绑包和用户-物品的匹配得分
2.5. Methodology
①CALBRec的框架图:
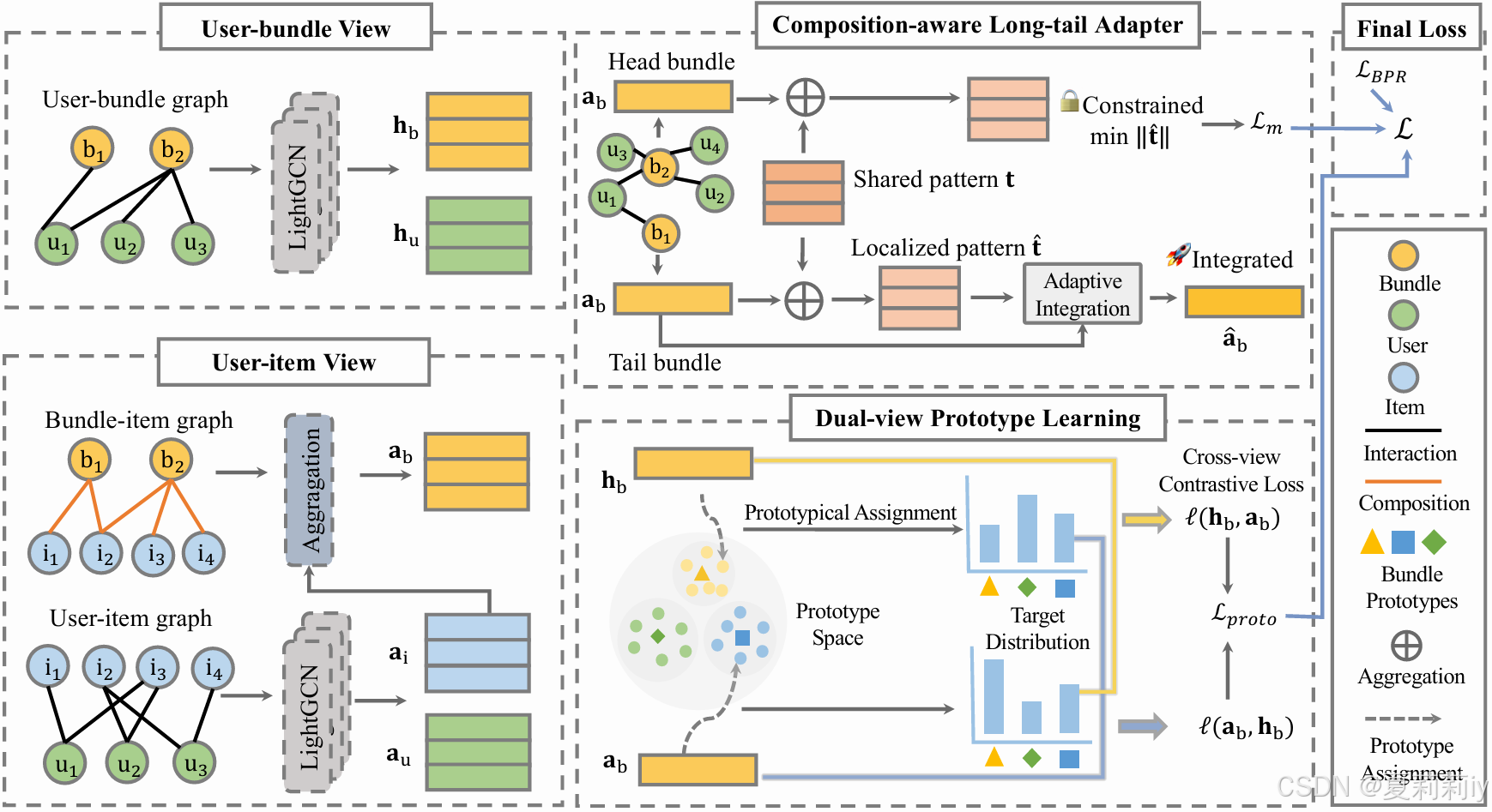
2.5.1. Composition-aware Long-tail Adapter
①建模可学习的且共享的全局特征向量:
其中代表不同的捆绑包,
代表将
转换为局部特征向量
个性化公式,
是捆绑包
在用户-捆绑包在第
层的表示,
是物品
在用户-物品视角中属于捆绑包
的特征
②调整整合的程度:
其中控制了模式缩放重要性,
提供了针对捆绑包的调整。这两个参数分别由以下公式求得:
其中是可学习矩阵
③不是所有的捆绑包都需要补充特征,头部捆绑包已经学到了可靠的表示,但尾部捆绑包没有获得足够的交互(这个是代码里面作者给头部和尾部标签吗?就是按照图上那样头部和尾部直接分开了?)
④对于头部捆绑包,保持学习好的表示,最小化额外模式影响:
⑤对于尾部捆绑包,通过控制的模式整合增强表示:
⑥尾部表示增强后的用户-物品视角得分:
2.5.2. Dual-view Prototype Learning
①为了缓解用户-捆绑包交互中的噪声,作者设计了一个原型学习去把捆绑包表示映射到可学习原型
②构建个原型向量
,分配矩阵
,其中
代表捆绑包
和原型
的分配强度
③定义约束:
约束时为了保证每个原型接收到同等来自捆绑包的分配权重并且每个捆绑包对原型分配了同等的权重(这,我要晕了)
④这个解决办法因为满足Sinkhorn-Knopp algorithm而可以最快收敛:
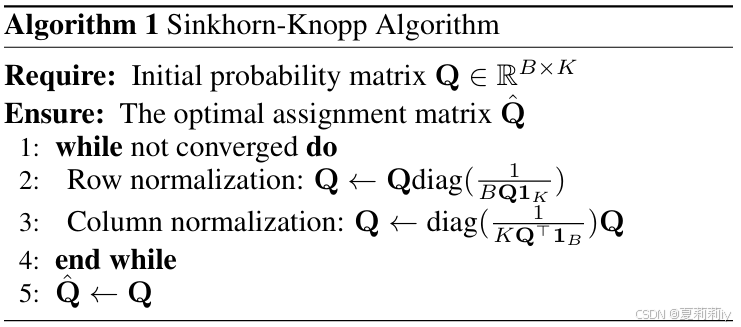
⑤通过Softmax归一化:
其中代表把捆绑包
分配到原型
的概率比
2.5.3. Model Optimization
①推荐目标使用贝叶斯个性化排序损失(Bayesian Personalized Ranking,BPR):
其中是作者给出的偏好分,就是对捆绑包的兴趣程度+对物品的兴趣程度(为什么下标都给了b...我会以为第二个也是用户-捆绑包...oh nono)
②组合优化:
其中是头部捆绑包的指示公式,1表示头部,0表示尾部,
是网络层数。意思是惩罚头部而不惩罚尾部
③将归一化前的概率和归一化后的概率约束到尽量一致:
并且物品视图→捆绑包视图和捆绑包视图→物品视图要协调:
(这个反过来就是把上面损失的上标从换成
)
④总损失:
2.6. Experiments
2.6.1. Experimental Setup
①数据集:书捆绑包Youshu,歌单NetEase,时尚穿搭iFashion:

②数据集划分:7:1:2
③头部和尾部区分:前20% 和后80%
④实验:5次平均
⑤嵌入维度:64
⑥初始化:Xavier
⑦优化器:Adam,学习率为0.001
⑧批量大小:2048
⑨对超参数使用网格搜索
⑩设备:NVIDIA Titan-V GPUs
2.6.2. Overall Performance
①表现比较:
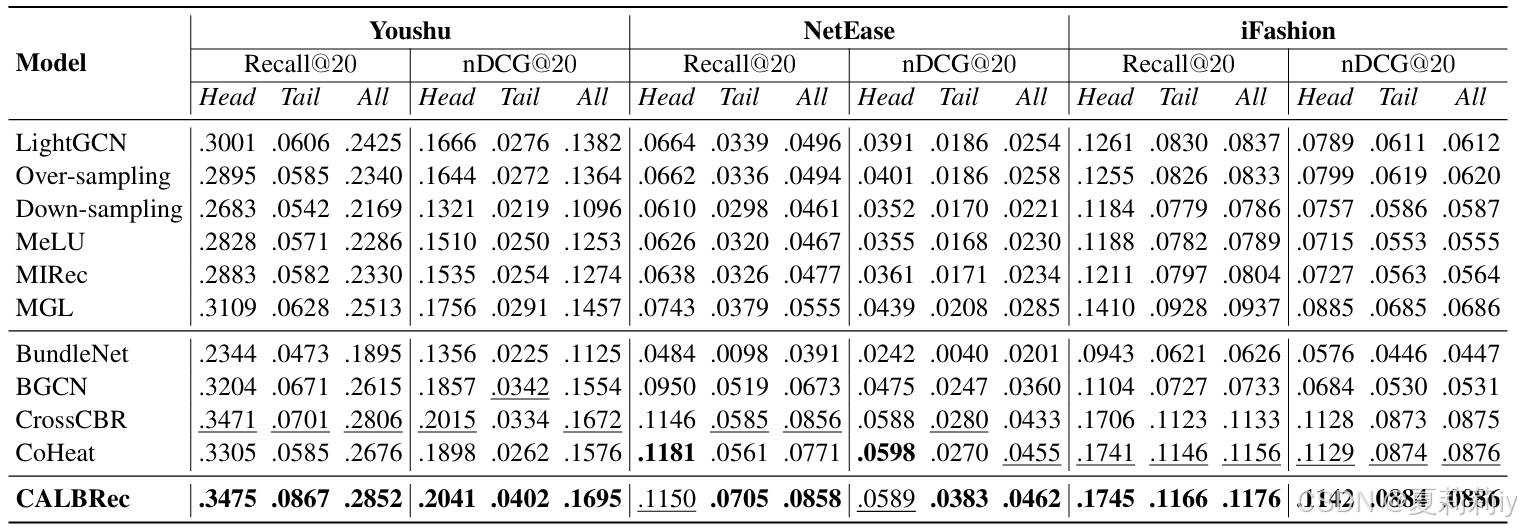
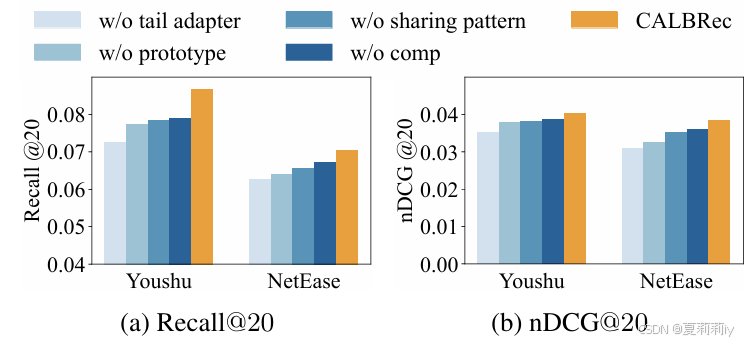
2.6.3. Ablation Study
①消融实验:
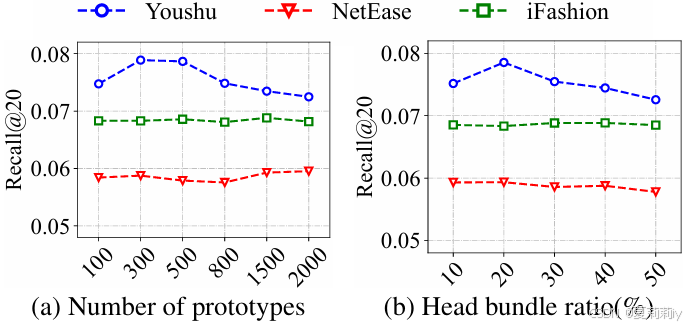
2.6.4. Effectofthe Parameter
①超参数实验:
2.7. Conclusion
~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)