【论文速读】SEER: 自引导让 Agent 从经验中学习
提出了一种针对复杂工具调用场景的自引导式上下文学习 (Self-Guided ICL)框架。传统的 RAG 方法通常仅依赖语义相似度来检索示例,这在多步推理和工具链规划中往往失效。SEER 的突破在于将检索维度高维化——不仅看 Query 的语义,还考量轨迹相似度工具链覆盖率和意图对齐。更进一步,它引入了在线经验累积 (Online Experience Accumulation)
SEER: 自引导让 Agent 从经验中学习
论文标题: Self-Guided Function Calling in Large Language Models via Stepwise Experience Recall
作者: Sijia Cui 1 , 2 ^{1,2} 1,2, Aiyao He 1 ^{1} 1, Shuai Xu 3 ^{3} 3, Hongming Zhang 1 ^{1} 1, Yanna Wang 1 † ^{1\dagger} 1†, Qingyang Zhang 1 ^{1} 1, Yajing Wang 4 ^{4} 4, Bo Xu 1 † ^{1\dagger} 1†
代码: https://github.com/AI-Research-TeamX/SEER
5. 总结
SEER (Stepwise ExperiencE Recall) 提出了一种针对复杂工具调用场景的自引导式上下文学习 (Self-Guided ICL) 框架。传统的 RAG 方法通常仅依赖语义相似度来检索示例,这在多步推理和工具链规划中往往失效。SEER 的突破在于将检索维度高维化——不仅看 Query 的语义,还考量轨迹相似度、工具链覆盖率和意图对齐。
更进一步,它引入了在线经验累积 (Online Experience Accumulation) 机制,利用 LLM 自我评估将成功的推理轨迹实时写入经验池,实现了无需梯度更新的“测试时训练 (Test-Time Training)”效果。实验表明,SEER 能显著提升开源模型 (Qwen2.5) 的工具调用能力,在 τ \tau τ-bench 上甚至逼近 GPT-4o 的表现。
1. 思想
当前 LLM Agent 在面对需要多步工具调用 (Multi-step Tool Use) 的复杂任务时,经常陷入“知道用什么工具,但不知道怎么组合”的困境。
-
大问题:
- 现有的上下文学习 (In-Context Learning) 检索机制过于粗粒度 (Coarse-grained)。它们通常只基于用户 Query 的语义相似度来检索 Demo。
- 然而,语义相似并不代表解决路径相似。两个语义上看似无关的问题(例如“订机票”和“订酒店”),其底层的工具调用逻辑(查询->筛选->预订)可能高度一致。反之亦然。
- 如何让 Agent 在检索时,能够“透视”到问题背后的程序化逻辑 (Procedural Logic),而不仅仅是表面的语义文本?
-
小问题:
- 静态样本的局限性: 传统的 Few-shot 样本库是手动构建且固定的,无法适应分布外 (OOD) 的新任务。
- 检索维度的单一性: 仅仅匹配 Query Embedding 会忽略 Agent 当前已经执行的步骤 (Interaction History) 和即将需要的工具类型。
- 反馈闭环缺失: Agent 在推理过程中产生的成功经验被浪费了,没有转化为长期记忆。
-
核心思想:
- 多维度的逐步回忆 (Stepwise Experience Recall): 重新定义“相似性”。真正的相似性应该由三部分加权组成:轨迹上下文 (Trajectory Context) + 工具链模式 (ToolChain Pattern) + 用户意图 (User Intent)。
- 自我进化的经验池: 建立一个动态的 Experience Pool。Agent 完成任务后,利用 LLM-as-a-Judge 进行自我评估,若成功则将该轨迹作为新样本存入池中。这使得模型在处理同类任务时能利用最近的成功经验,实现类似强化学习的性能爬升,但无需参数更新。
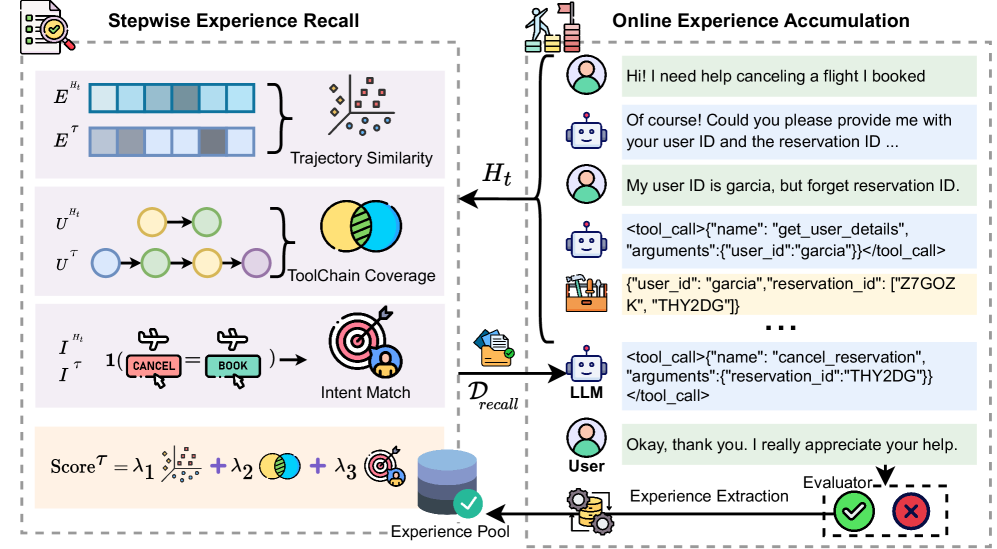
Figure 1: SEER 框架概览。左侧展示了基于三个维度的逐步经验召回机制,右侧展示了基于自我评估的在线经验累积过程。
2. 方法
SEER 的方法论构建在严格的数学定义之上,将非结构化的交互转化为结构化的经验元组,并通过加权评分机制进行精准检索。作者将其形式化为两个核心过程:逐步检索 (Retrieval) 和 在线更新 (Update)。
2.1 轨迹经验提取 (Experience Extraction)
首先,我们需要将一个非结构化的交互历史 H t H_t Ht 形式化。一个完整的交互轨迹 τ \tau τ 被定义为 { o 0 , a 0 , o 1 , a 1 , … } \{o_0, a_0, o_1, a_1, \dots\} {o0,a0,o1,a1,…}。SEER 将其映射为一个结构化的经验表示 d τ d^{\tau} dτ:
d τ = ⟨ E τ , E q , I τ , U τ ⟩ d^{\tau} = \langle E^{\tau}, E^q, I^{\tau}, U^{\tau} \rangle dτ=⟨Eτ,Eq,Iτ,Uτ⟩
其中:
- E τ E^{\tau} Eτ: 轨迹嵌入 (Trajectory Embedding)。对整个交互历史的向量化表示。
- E q E^q Eq: 查询嵌入 (Query Embedding)。仅针对用户初始 Query 的向量表示。
- I τ I^{\tau} Iτ: 推断意图 (Inferred Intent)。通过 LLM 将用户 Query 分类到预定义的离散意图集合 I \mathcal{I} I 中。
- U τ U^{\tau} Uτ: 工具调用序列 (Tool Invocation Sequence)。建模为工具的有向路径 u 1 → u 2 → ⋯ → u n u_1 \to u_2 \to \dots \to u_n u1→u2→⋯→un。
2.2 核心算法流程
SEER 的运行机制由两个算法控制:推理时的检索(Alg. 1)和任务后的累积(Alg. 2)。

算法 1: 逐步经验召回 (Stepwise Experience Recall)
此算法在推理的每一步执行,负责为当前上下文寻找最佳参考。
- 输入: 当前交互历史 H t H_t Ht,经验池 D \mathcal{D} D,权重超参数 λ 1 , λ 2 , λ 3 \lambda_1, \lambda_2, \lambda_3 λ1,λ2,λ3
- 输出: Top- k k k 个相关轨迹 D recall \mathcal{D}_{\text{recall}} Drecall
-
特征提取: 从当前历史 H t H_t Ht 中提取特征元组 ⟨ E H t , E q , I H t , U H t ⟩ \langle E^{H_t}, E^q, I^{H_t}, U^{H_t} \rangle ⟨EHt,Eq,IHt,UHt⟩。
-
遍历评分: 对于经验池 D \mathcal{D} D 中的每一个轨迹 ( τ ′ , d τ ′ ) (\tau', d^{\tau'}) (τ′,dτ′),计算三个维度的子分数:
-
轨迹相似度 ( s 1 s_1 s1): 计算余弦相似度并归一化。
s 1 ← 1 + cos ( E H t , E τ ′ ) 2 s_1 \leftarrow \frac{1 + \cos(E^{H_t}, E^{\tau'})}{2} s1←21+cos(EHt,Eτ′)含义: 衡量当前交互上下文 ( H t H_t Ht) 与候选完整轨迹 ( τ ′ \tau' τ′) 在语义向量空间中的方向一致性。
细节:
- E H t E^{H_t} EHt 和 E τ ′ E^{\tau'} Eτ′ 是通过预训练 Embedding 模型 (如文中的
bge-large-en-v1.5) 获得的向量。 - 标准的余弦相似度 cos ( a , b ) = a ⋅ b ∥ a ∥ ∥ b ∥ \cos(\mathbf{a}, \mathbf{b}) = \frac{\mathbf{a} \cdot \mathbf{b}}{\|\mathbf{a}\| \|\mathbf{b}\|} cos(a,b)=∥a∥∥b∥a⋅b 的取值范围是 [ − 1 , 1 ] [-1, 1] [−1,1]。
- 变换逻辑: 作者使用了 ( 1 + x ) / 2 (1 + x) / 2 (1+x)/2 的线性变换。当两个向量方向完全相反时 ( − 1 -1 −1) 得分为 0 0 0;当完全一致时 ( 1 1 1) 得分为 1 1 1。这不仅将分数归一化到了非负区间,还平滑了负相关带来的惩罚,使其适合作为加权和的一部分。
- E H t E^{H_t} EHt 和 E τ ′ E^{\tau'} Eτ′ 是通过预训练 Embedding 模型 (如文中的
-
工具链覆盖度 ( s 2 s_2 s2): 计算 Jaccard 相似系数的变体(关注当前所需工具是否在历史中出现)。
s 2 ← ∣ U H t ∩ U τ ′ ∣ ∣ U H t ∣ s_2 \leftarrow \frac{|U^{H_t} \cap U^{\tau'}|}{|U^{H_t}|} s2←∣UHt∣∣UHt∩Uτ′∣- 含义: 衡量候选轨迹是否包含了当前任务已经涉及到的工具。
- 细节:
- U H t U^{H_t} UHt 和 U τ ′ U^{\tau'} Uτ′ 被视为无序集合 (Unordered Sets),包含各自轨迹中调用的所有工具名称。
- 分子 ∣ U H t ∩ U τ ′ ∣ |U^{H_t} \cap U^{\tau'}| ∣UHt∩Uτ′∣ 计算两个集合的交集大小。
- 分母 ∣ U H t ∣ |U^{H_t}| ∣UHt∣ 是当前任务已使用的工具数量。
- 设计意图: 注意分母不是并集 (标准 Jaccard),也不是候选集大小。这个公式本质上是在计算 Recall (召回率)。它在问:“我现在用到的工具,在这个历史案例里出现了多少?”
- 边界情况: 如果当前还未调用任何工具 ( ∣ U H t ∣ = 0 |U^{H_t}| = 0 ∣UHt∣=0),通常该项置为 0 或不参与计算(但在实际代码实现中,第一步通常仅依赖 s 1 s_1 s1 和 s 3 s_3 s3)。
-
意图匹配度 ( s 3 s_3 s3): 不使用向量计算得出,而是一个基于 LLM 分类 (Classification) 的离散匹配过程。
s 3 ← 1 ( I H t = I τ ′ ) s_3 \leftarrow \mathbf{1}(I^{H_t} = I^{\tau'}) s3←1(IHt=Iτ′)
其中 1 [ ⋅ ] \mathbf{1}[\cdot] 1[⋅] 是指示函数 (Indicator Function),如果方括号内条件为真,则结果为 1,否则为 0。计算步骤
这一过程依赖于一个预定义的意图分类器 (Intent Recognizer),通常通过 Prompt 让 LLM 扮演。
-
预定义意图集合 ( I \mathcal{I} I):
研究者针对特定领域预先定义好一组意图类别。例如在 ToolQA 数据集中,定义了 8 类意图:Flight Search(航班查询),Hotel Booking(酒店预订),Math Reasoning(数学推理), … 等等。
-
意图推理 (Inference):
- 对于历史轨迹 ( τ ′ \tau' τ′): 在该轨迹存入经验池之前,利用 LLM 分析其初始 Query,输出一个标签 I τ ′ I^{\tau'} Iτ′ (例如
[Hotel Booking]),并存储在 d τ ′ d^{\tau'} dτ′ 元组中。 - 对于当前任务 ( H t H_t Ht): 当用户输入新的 Query 时,实时调用 LLM (使用特定的 Prompt,见论文 Appendix Figure 4),解析出当前意图 I H t I^{H_t} IHt。
Prompt 示例 (简化版):
你是一个意图识别专家。给定用户问题,从以下8个类别中选出一个最可能的意图: [Category A, Category B, ...] 用户问题: "帮我定明天去上海的机票" 输出: [Flight Search] - 对于历史轨迹 ( τ ′ \tau' τ′): 在该轨迹存入经验池之前,利用 LLM 分析其初始 Query,输出一个标签 I τ ′ I^{\tau'} Iτ′ (例如
-
硬匹配 (Hard Matching):
比较两个字符串标签:- 如果 I H t = = I τ ′ I^{H_t} == I^{\tau'} IHt==Iτ′ (例如都是
[Flight Search]),则 s 3 = 1 s_3 = 1 s3=1。 - 如果不同,则 s 3 = 0 s_3 = 0 s3=0。
- 如果 I H t = = I τ ′ I^{H_t} == I^{\tau'} IHt==Iτ′ (例如都是
为什么这么做
向量相似度 ( s 1 s_1 s1) 虽然能捕捉语义,但在高维空间中,"查询某个东西的价格"和"计算某个东西的数量"可能距离很近,但解决逻辑完全不同。 s 3 s_3 s3 作为一个硬约束 (Hard Constraint) 或强特征,强制模型优先关注那些“大方向”一致的案例,避免被语义相似但逻辑迥异的噪声误导。
-
-
-
加权聚合: 计算最终相关性分数。
Score τ ′ ← λ 1 s 1 + λ 2 s 2 + λ 3 s 3 \text{Score}^{\tau'} \leftarrow \lambda_1 s_1 + \lambda_2 s_2 + \lambda_3 s_3 Scoreτ′←λ1s1+λ2s2+λ3s3 -
排序与选择: 根据 Score τ ′ \text{Score}^{\tau'} Scoreτ′ 降序排列,取前 k k k 个轨迹构成 D recall \mathcal{D}_{\text{recall}} Drecall 返回给 LLM 进行 ICL 推理。
算法 2: 在线经验累积 (Continual Experience Accumulation)
此算法在任务结束后执行,负责实现“自我进化”。
- 输入: 刚刚结束的交互历史 H t H_t Ht,LLM 评估器 E \mathcal{E} E,经验池 D \mathcal{D} D
- 输出: 更新后的经验池 D \mathcal{D} D
- 自我评估: 调用评估器 E \mathcal{E} E 判断任务是否成功。
Success ← E . isSuccessful ( H t ) \text{Success} \leftarrow \mathcal{E}.\text{isSuccessful}(H_t) Success←E.isSuccessful(Ht)
(注: 评估器通常对比模型输出与 Ground Truth,或检查任务完成标志) - 条件更新:
- IF Success \text{Success} Success is True:
- 从 H t H_t Ht 中提取特征 E τ , E q , I τ , U τ E^{\tau}, E^q, I^{\tau}, U^{\tau} Eτ,Eq,Iτ,Uτ。
- 构建经验元组 d τ ← ⟨ E τ , E q , I τ , U τ ⟩ d^{\tau} \leftarrow \langle E^{\tau}, E^q, I^{\tau}, U^{\tau} \rangle dτ←⟨Eτ,Eq,Iτ,Uτ⟩。
- 将新经验注入池中: D ← D ∪ { ( τ , d τ ) } \mathcal{D} \leftarrow \mathcal{D} \cup \{(\tau, d^{\tau})\} D←D∪{(τ,dτ)}。
- ELSE:
- 丢弃该轨迹,保持 D \mathcal{D} D 不变。
- IF Success \text{Success} Success is True:
- 返回: 更新后的 D \mathcal{D} D 供下一个任务使用。
3. 优势
- 动态适应性: 相比于 ART (Paranjape et al., 2023) 等仅基于语义检索的方法,SEER 能通过 s 2 s_2 s2 (工具链覆盖) 捕捉到工具使用的结构性模式,对多步复杂任务极其关键。
- 无需微调 (Training-free): 所有的性能提升均来自推理阶段的策略优化和动态 Prompt 构建,无需昂贵的梯度更新。
- 鲁棒的冷启动: 即使初始样本库很小,通过在线累积机制,模型也能迅速通过成功的尝试扩充样本库,提升后续表现。
4. 实验
实验设置
- 基座模型: Qwen2.5-72B-Instruct (主要), Qwen2.5-7B。
- 基准测试:
- ToolQA: 8个领域,分 Easy/Hard 模式。侧重单轮多步推理。
- τ \tau τ-bench: 模拟真实世界的零售和航空场景,包含多轮对话和用户模拟器。侧重动态交互。
- Baselines: Chameleon, ReAct, ART, ExpeL 等。
结论
-
综合性能超越:
在 ToolQA 上,SEER 在 Easy 和 Hard 集合上分别取得了 67.9% 和 31.1% 的平均准确率,显著优于 ExpeL (61.8% / 26.4%)。
在更具挑战性的 τ \tau τ-bench 上,SEER 带来的提升是巨大的。 -
自我进化的有效性:
Figure 2 展示了随着 batch 的推进,SEER 的性能呈现明显的上升趋势。- 关键数据: 准确率从第 1 个 batch 的 37.7% 提升至第 10 个 batch 的 54.9%。这证明了在线经验累积机制能够有效地利用之前的成功经验来指导后续推理。

Figure 2: SEER 的自我提升曲线。随着经验池的扩充,模型准确率稳步上升。
-
消融研究 (Ablation Study):
- s 2 s_2 s2 (工具链覆盖) 的重要性: 去掉 s 2 s_2 s2 后,在 Hard 任务上的性能下降最为明显。这验证了在复杂任务中,匹配“工具使用模式”比匹配“问题语义”更重要。
- s 3 s_3 s3 (意图匹配) 的重要性: 在 Easy 任务上影响较大。对于简单任务,快速定位用户意图可以直接复用标准解法。
- 样本数量 (Top-k): 并非越多越好。实验显示 k = 4 k=4 k=4 左右达到峰值,过多的 Demonstration 会导致 Context 过长,引起注意力分散或过拟合。
-
局限性与改进:
作者坦承,对于初始完全无法解决的困难任务(即没有任何成功轨迹可供存入),SEER 的冷启动可能受阻。通过引入 Reflection (反思) 机制 (SEER+Reflection),可以进一步修正错误,将 ToolQA 的 Hard 准确率从 31.1% 提升至 32.0%。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)