【鱼类识别与监测】18 组深度学习数据集分享(附加载预处理代码)
鱼类识别与监测是计算机视觉在渔业资源管理、水生生态保护、水下机器人开发等领域的核心应用方向。高质量的标注数据集是训练高精度鱼类 AI 模型的关键支撑,本次整理并分享 18 组覆盖淡水鱼 / 深海鱼检测、鱼类分割分类、物种识别、专项场景监测的鱼类图像与标注数据集,同时附上可直接运行的 Python 加载与预处理代码,方便科研学习与项目落地。
鱼类识别与监测是计算机视觉在渔业资源管理、水生生态保护、水下机器人开发等领域的核心应用方向。高质量的标注数据集是训练高精度鱼类 AI 模型的关键支撑,本次整理并分享 18 组覆盖淡水鱼 / 深海鱼检测、鱼类分割分类、物种识别、专项场景监测的鱼类图像与标注数据集,同时附上可直接运行的 Python 加载与预处理代码,方便科研学习与项目落地。
一、 鱼类检测与目标识别数据集
这类数据集包含精准的边界框标注,适合训练鱼类目标检测模型,适用于水下机器人目标追踪、渔业捕捞计数、入侵物种监测等场景。
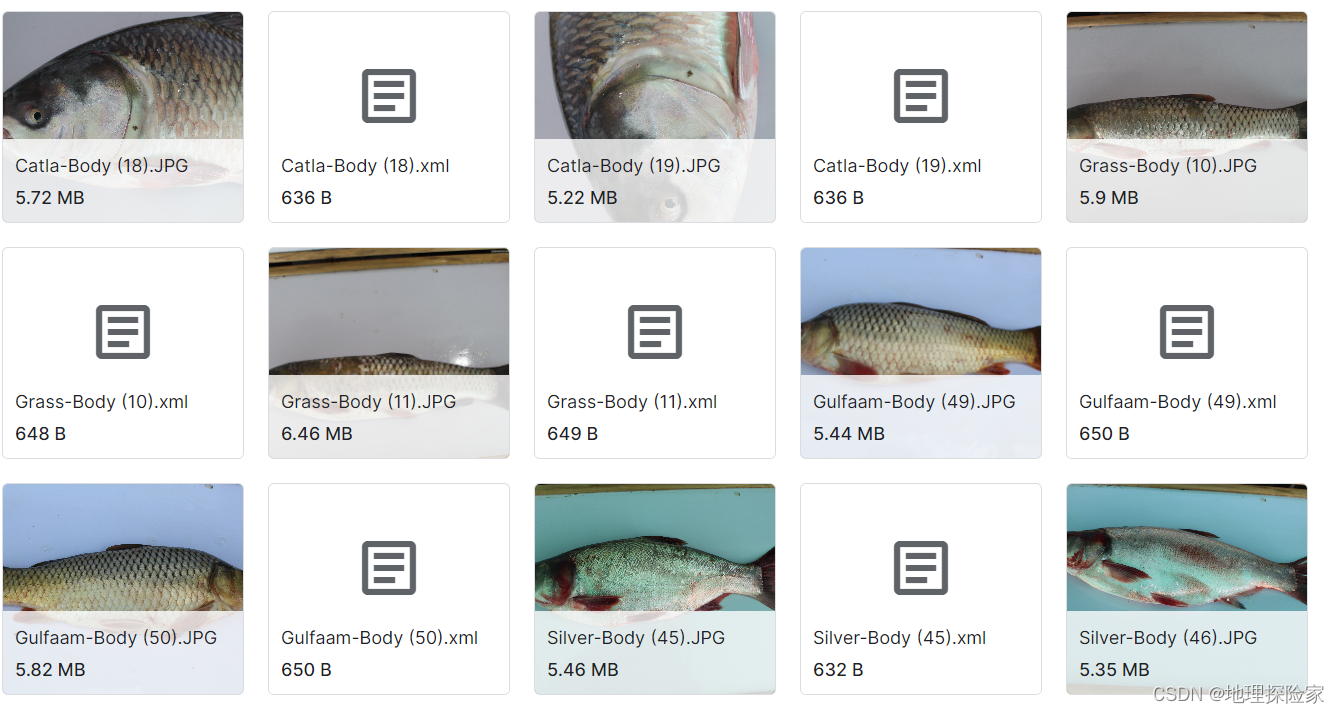
- 鱼类检测数据集数据说明:包含 Catla、Silver、Gulfaam、Grass 4 种鱼类,配套 XML 标注文件,共 254 张图片,标注格式适配 PascalVOC 标准。适用场景:入门级鱼类检测模型训练、小型水域鱼类种类统计。
- 用于目标检测的 YOLOv5 PyTorch 格式水下生物数据集数据说明:涵盖鱼、水母、企鹅等 7 类水下生物,共 638 张图片,标注为 YOLOv5 格式,已划分训练 / 验证 / 测试集,图像统一预处理为 1024×1024 分辨率。适用场景:水下机器人实时目标检测、多物种协同监测模型开发。

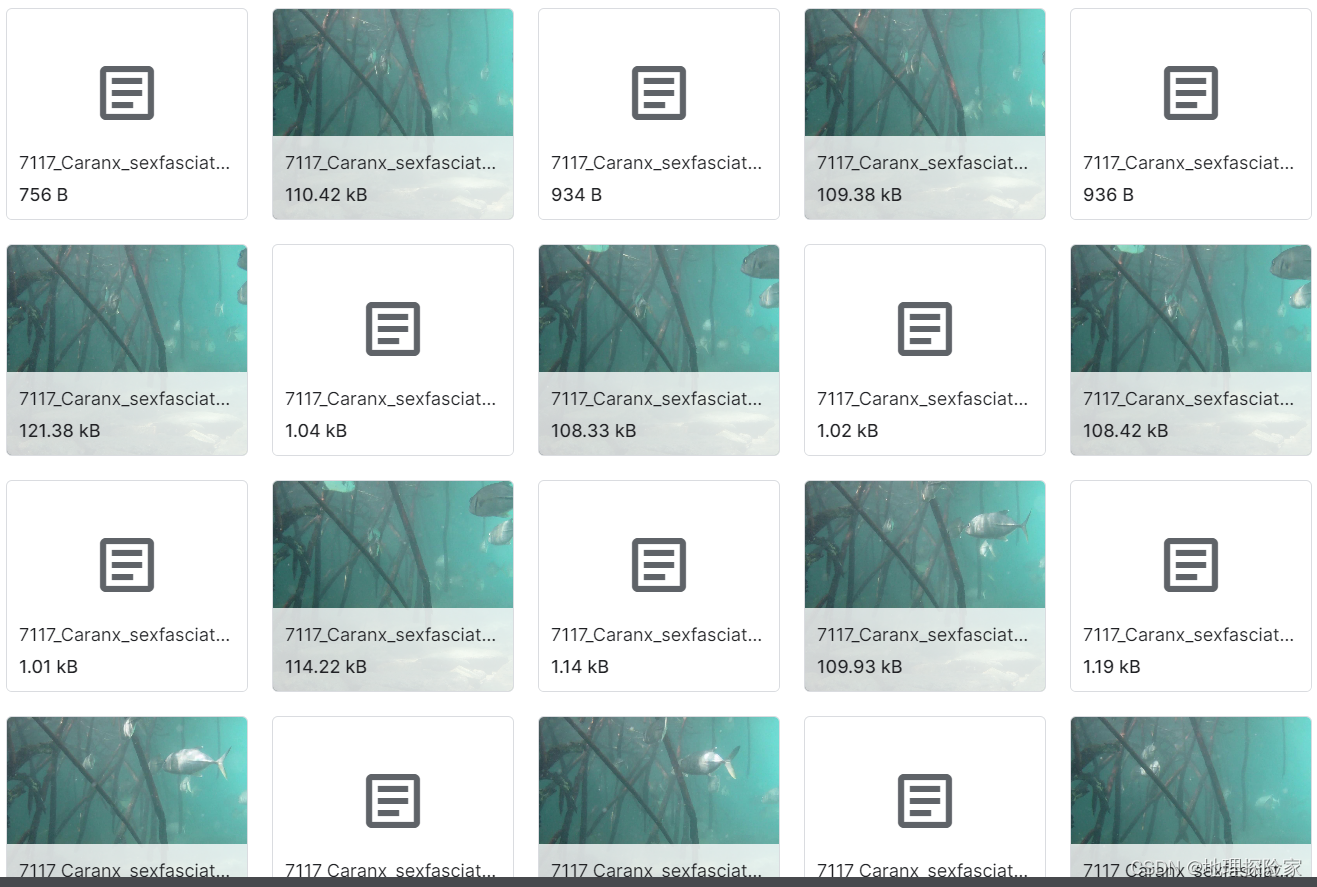
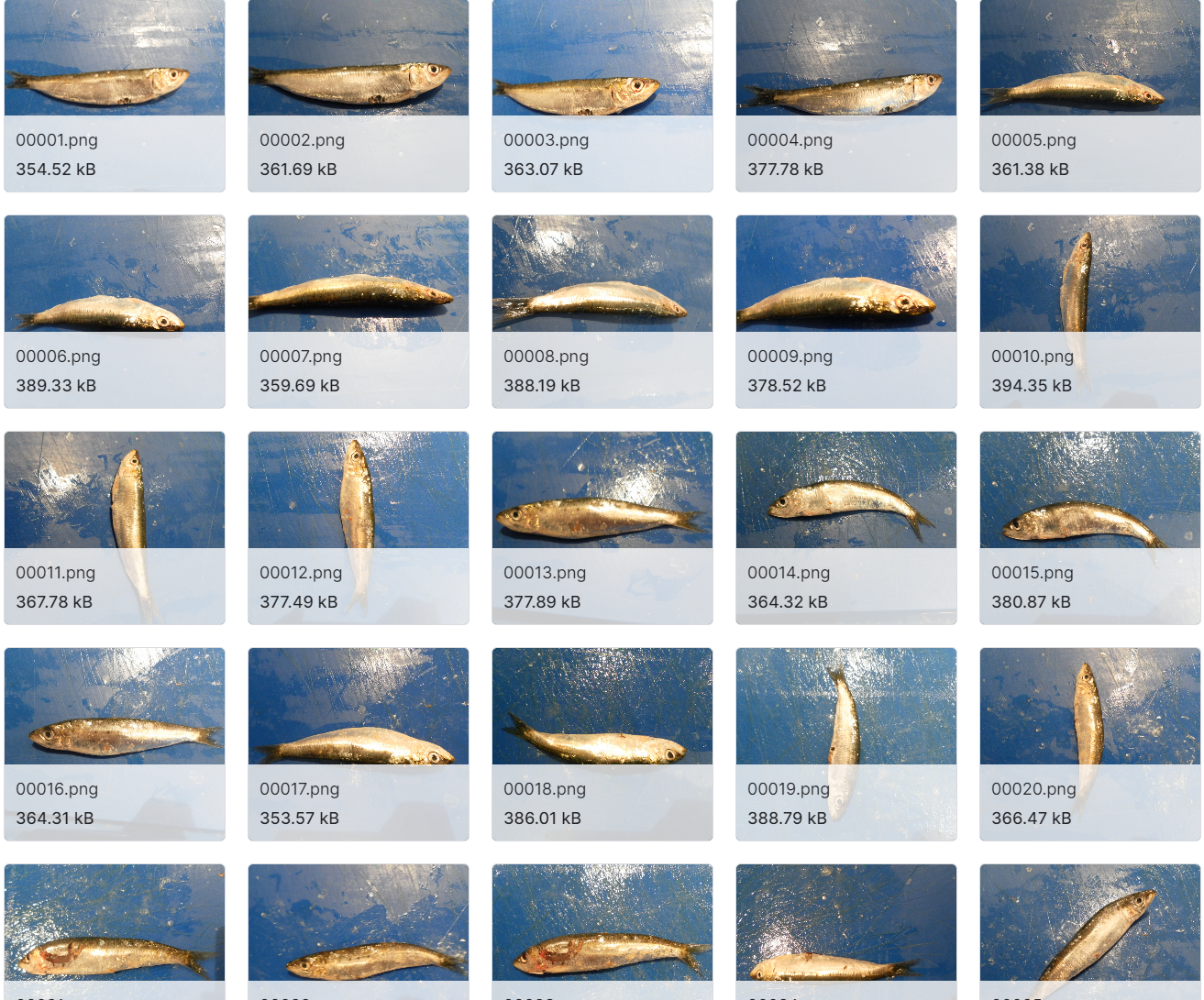
- 用于对象检测的 YOLO 格式标注的大规模深海鱼类图像数据集数据说明:包含数千张高分辨率深海鱼图像,共 6517 张,每张图像配套 TXT 格式边界框注释,标注坐标已做归一化处理。适用场景:深海鱼类自动识别、渔业自动化捕捞辅助系统开发。
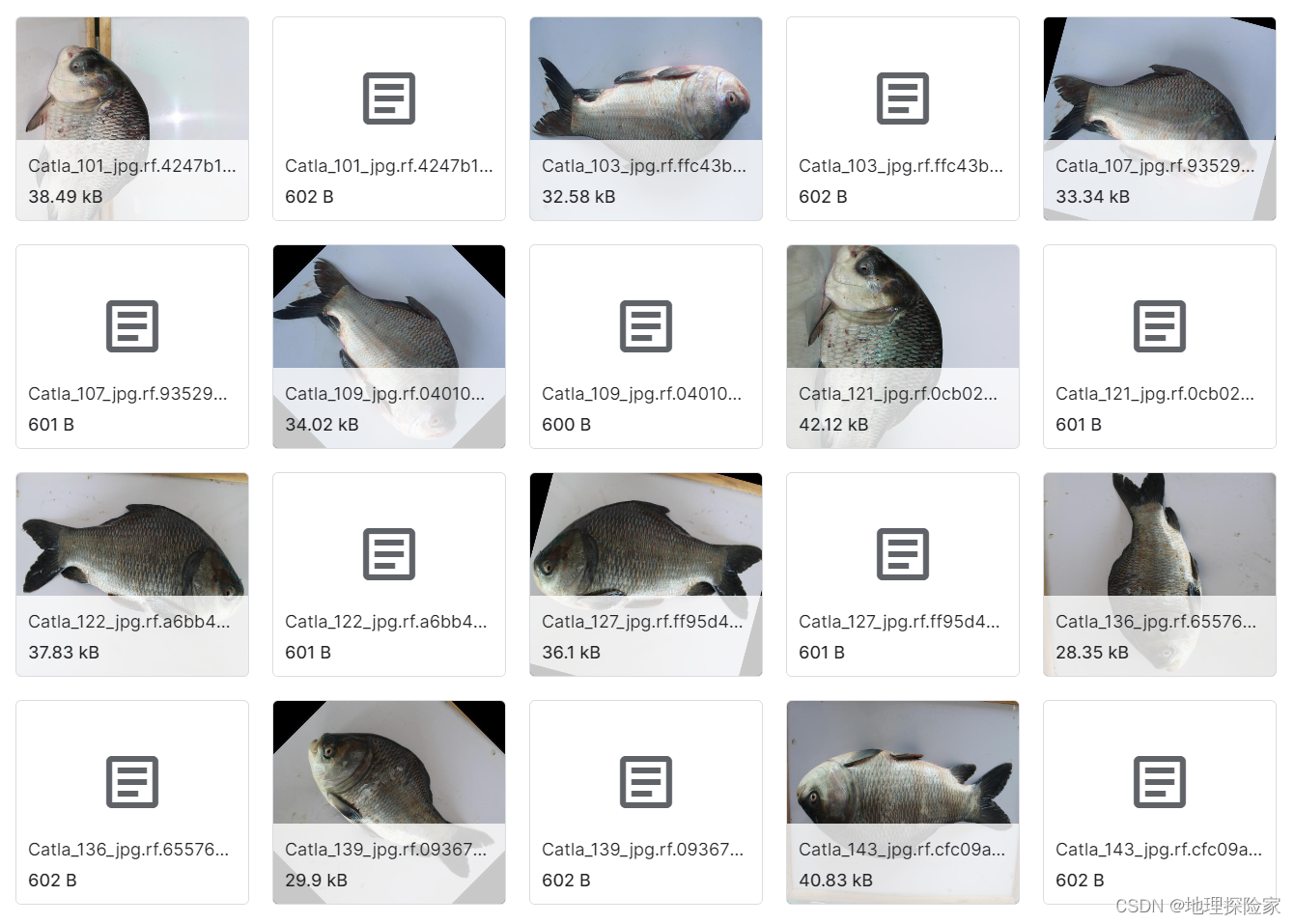
- 印度南亚大陆的鱼类识别的目标检测数据集数据说明:聚焦印度次大陆 5 种本土鱼类,经数据增强后生成 1033 张图像,标注格式为 PascalVOC,按 70:20:10 划分训练 / 验证 / 测试集。适用场景:区域性鱼类种群分析、淡水鱼资源监测模型训练。
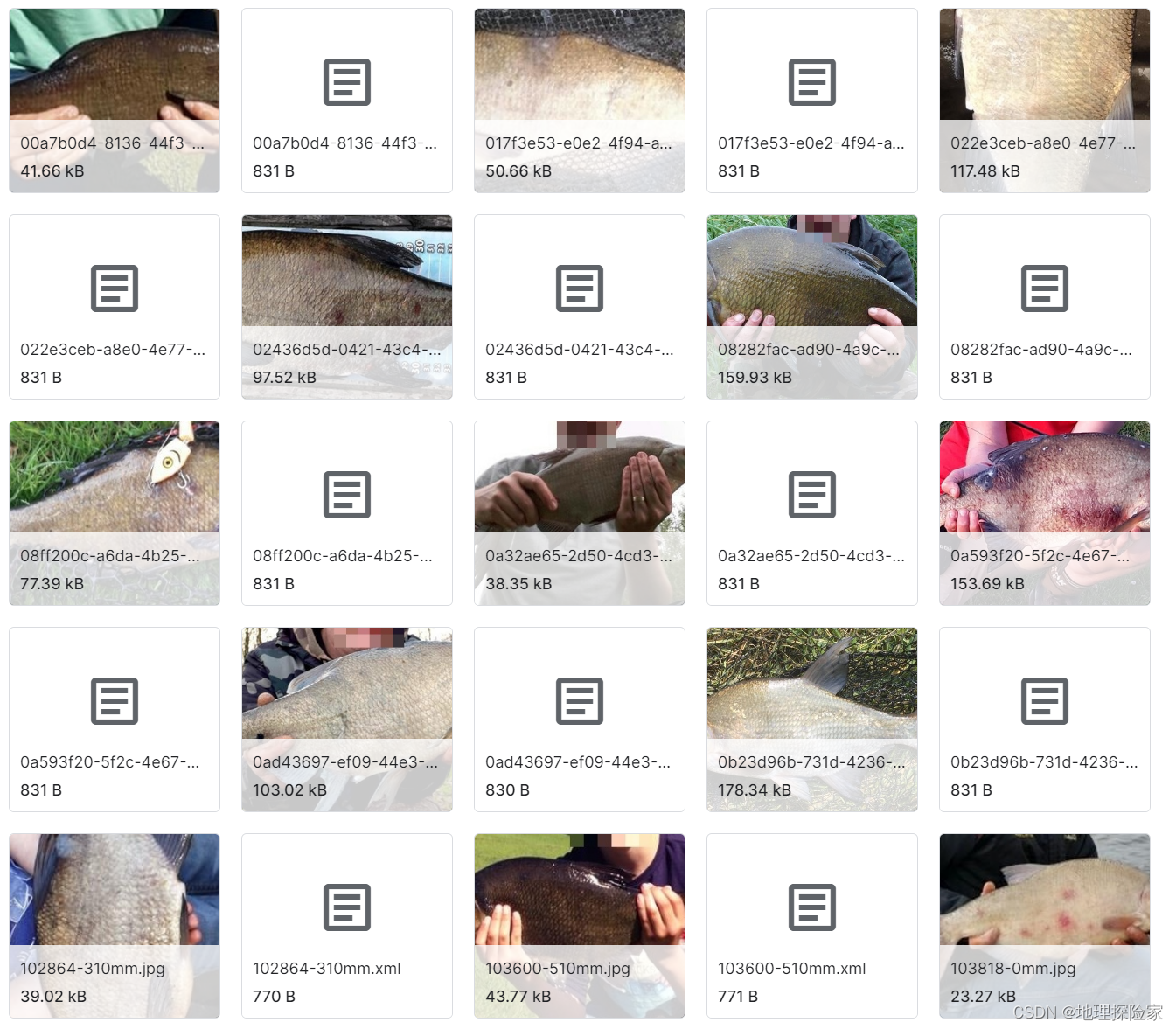
- 入侵狮子鱼 - 物体检测图像数据集数据说明:专为加勒比海入侵物种监测打造,包含 565 张狮子鱼图像,标注为 YOLOv5 格式,划分训练 / 评估 / 测试集。适用场景:入侵物种自动预警、本土水生生物保护系统开发。

- 淡水鱼分类 7000 幅 30 种鱼类的图像数据集数据说明:涵盖荷兰 30 种常见淡水鱼,共 7000 + 张图片,每幅图像配套 YOLO 格式检测标注,按物种分文件夹存储。适用场景:淡水流域鱼类多样性监测、休闲渔业物种识别。
二、 鱼类分割与语义分析数据集
这类数据集包含像素级标注的掩码图像,适合训练鱼类分割与水下场景语义分析模型,适用于鱼类形态分析、水下环境建模等场景。
- 鱼类分割和分类的大规模数据集数据说明:涵盖 9 种海鲜(含 8 种鱼类 + 虾),共 18300 张图片,每类含 1000 张 RGB 图像与对应的掩码标注,图像经翻转、旋转增强处理。适用场景:鱼类精细分割模型训练、水产加工自动化分拣系统开发。
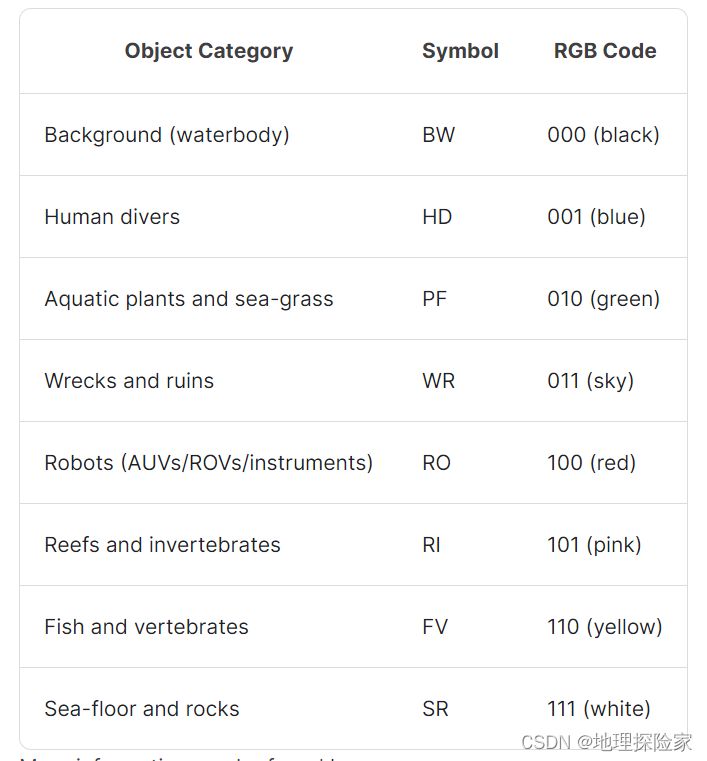
- 用于水下语义分割的大规模数据集数据说明:包含鱼、珊瑚礁、水生植物等 8 类水下对象,共 1500 + 张像素级标注图像,配套 110 张测试集,分辨率支持 320×240/320×256 基准测试。适用场景:水下环境语义建模、生态系统健康评估模型训练。
三、 鱼类分类与物种识别数据集
这类数据集按物种分类存储,样本覆盖不同水域、光照条件,适合训练鱼类物种分类模型,适用于水生生物多样性调查、鱼类品种鉴定等场景。
- 有鱼或无鱼的训练和测试集图片数据集数据说明:二分类数据集,包含 20000 + 张图片,有鱼 / 无鱼样本各占 50%,划分训练 / 测试集,适合鱼类存在性检测任务。适用场景:水下摄像头触发式监测、渔业养殖空网检测。
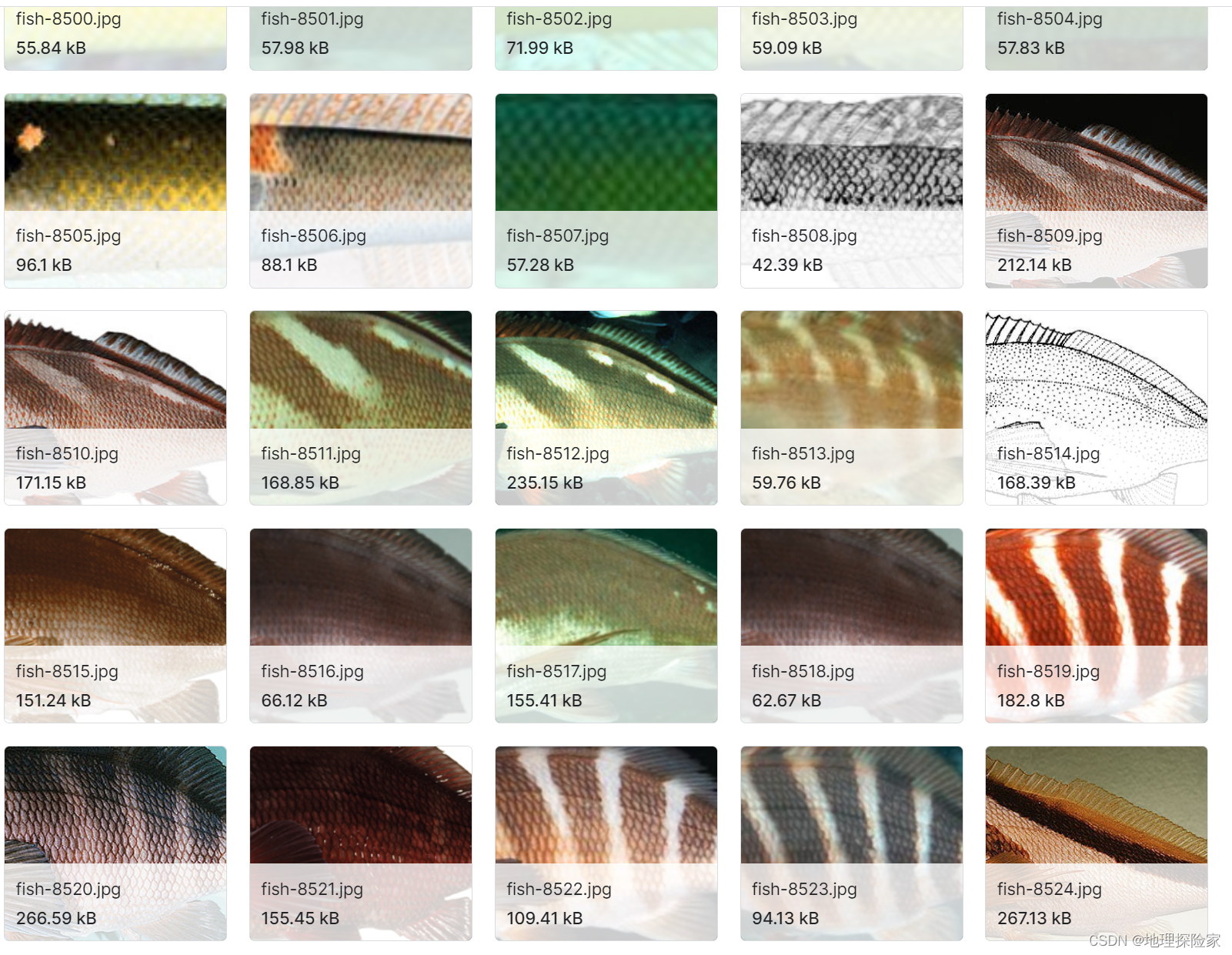
- 用于图像分类任务的不同海洋生物的图像数据集数据说明:涵盖 19 类海洋生物,共 13700 张图片,图像统一调整为 300px 基准分辨率,部分样本来自 Pixabay 可免授权使用。适用场景:多物种海洋生物分类、科普教育类识别应用开发。

- 卡布姚市马林尼格渔港可以找到的鱼类品种数据集数据说明:聚焦渔港常见鱼类,共 13304 张图片,样本均为真实渔港捕捞场景拍摄,物种覆盖度高。适用场景:渔港鱼类快速分类、渔业市场交易品种鉴定。
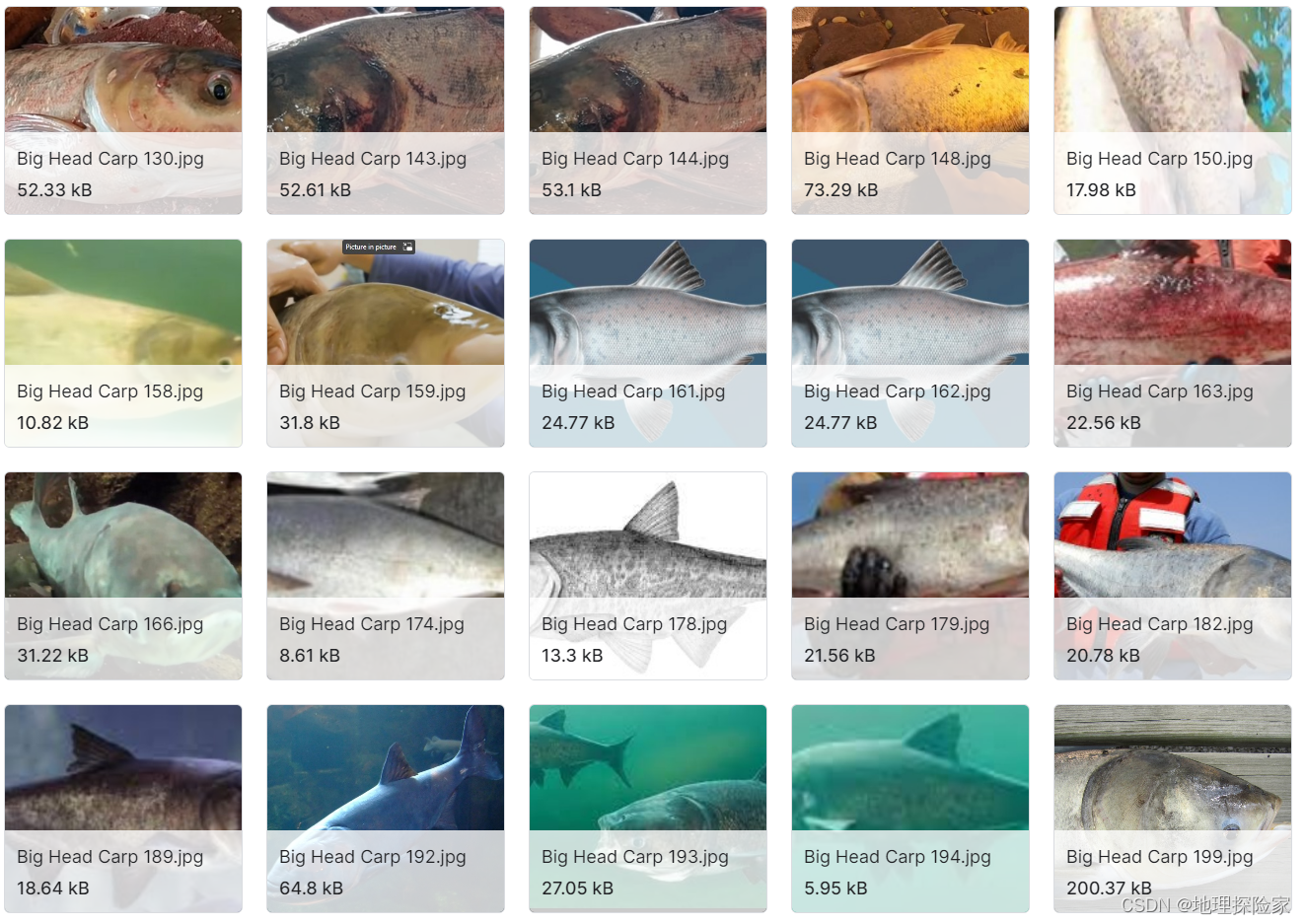
- 468 种鱼类约 4000 幅图像的数据集数据说明:涵盖 468 种鱼类,共 3960 张图像,包含 “控制条件”“出水”“原位” 3 种拍摄场景,覆盖鱼类标本与自然栖息地状态。适用场景:大规模鱼类物种分类、鱼类形态学特征研究。

- 亚马逊流域四种鱼类图像的小数据集数据说明:聚焦亚马逊流域 4 种特色鱼类,共 172 张图片,样本量小但物种特征鲜明。适用场景:热带淡水鱼识别模型开发、小样本迁移学习研究。
- 20 种地中海鱼类图片的训练和测试集数据说明:涵盖 20 种地中海鱼类,共 40000 张图片,每类约 1700 张,已划分训练 / 测试集,样本覆盖不同海域光照与水质条件。适用场景:地中海鱼类资源监测、远洋渔业物种识别。
四、 专项场景鱼类数据集
这类数据集聚焦特定研究场景,样本针对性强,适合训练垂直领域的鱼类分析模型,适用于生物实验、生态调查等场景。
- 六种不同种类的水母图像数据集数据说明:涵盖月水母、桶形水母等 6 类水母,共 1879 张图片,每类按物种单独分类,附带详细物种生物学特征说明。适用场景:水母物种识别、海洋浮游生物监测模型训练。

- 加勒比海巴巴多斯附近水域的鹦鹉鱼图片数据集数据说明:由水下机器人拍摄于加勒比海巴巴多斯海域,共 2332 张鹦鹉鱼图像,样本覆盖不同深度(0-5m)、光照条件,记录水温等环境元数据。适用场景:热带珊瑚礁鱼类监测、气候变化对鱼类栖息地影响研究。

- 从侧面透视的边界框注释斑马鱼图像数据集数据说明:首个侧视角斑马鱼标注数据集,记录 6 条斑马鱼的运动序列,附带方向、转弯状态等 4 类布尔元数据标签,适用于斑马鱼行为分析。适用场景:生物实验斑马鱼运动追踪、药物对鱼类行为影响研究。

- 东北大西洋地区 200 多种鱼类和贝类的年名义渔获量数据数据说明:包含 2006-2014 年东北大西洋 200 + 种鱼类和贝类的渔获量统计数据,由 20 个 ICES 成员国提交,数据权威规范。适用场景:渔业资源评估、渔获量预测模型训练、海洋生态政策制定数据支撑。
五、 鱼类数据集使用实操小技巧
- 数据预处理重点
- 水下图像增强:针对水下图像光照不足、对比度低、色彩失真问题,优先使用UDC(水下去雾卷积网络) 或 Water-Net 进行去雾处理;通过直方图均衡化、CLAHE 算法提升图像对比度;
- 统一规格:检测 / 分类任务将图像统一调整为 640×640 或 1024×1024 分辨率;分割任务保留原始分辨率,确保掩码与图像像素对齐;
- 数据增强:加入随机水平翻转、旋转(±15°)、高斯噪声、亮度抖动等增强手段,提升模型对水下复杂环境的鲁棒性。
- 模型选型建议
- 鱼类检测:优先使用 YOLOv8(速度快、精度高,适配实时监测)、Faster R-CNN(小目标检测效果好,适合深海小型鱼类);
- 鱼类分割:优先使用 U-Net 及改进版(U-Net++、Attention U-Net,像素级分割精度高)、DeepLabv3+(适合水下复杂场景语义分割);
- 物种分类:优先使用 EfficientNet-B0/B1(参数量小、精度高)、ResNet50(迁移学习效果好,适合小样本数据集)。
- 过拟合解决方法
- 小样本数据集采用迁移学习,基于在 ImageNet 预训练的模型微调;
- 加入 Dropout 层(概率 0.2-0.5) 或 L2 正则化,抑制模型过拟合;
- 对检测任务采用Mosaic 增强,对分类任务采用MixUp 增强,提升模型泛化能力。
六、 技术实操:鱼类数据集加载与预处理(附 Python 代码)
以下代码实现了鱼类分类、YOLO 目标检测、水下语义分割三类核心任务的数据集加载与预处理功能,所有数据集已经做了注释,新手可直接复制运行。
第一步:环境准备
执行以下命令安装依赖库:
pip install opencv-python pillow torch torchvision numpy pandas albumentations
第二步:完整加载 + 预处理代码
# ===================== 核心功能1:鱼类物种分类数据集加载 =====================
import os
import numpy as np
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
class FishClassificationDataset(Dataset):
"""
加载鱼类物种分类数据集
"""
def __init__(self, data_root, transform=None):
# 地中海鱼类数据集查看地址
# https://www.dilitanxianjia.com/13847/
# 468种鱼类数据集查看地址
# https://www.dilitanxianjia.com/13851/
self.data_root = data_root
self.transform = transform
self.classes = sorted(os.listdir(data_root))
self.class_to_idx = {cls: idx for idx, cls in enumerate(self.classes)}
self.image_paths = []
self.labels = []
# 亚马逊流域鱼类数据集查看地址
# https://www.dilitanxianjia.com/13855/
# 卡布姚市渔港鱼类数据集查看地址
# https://www.dilitanxianjia.com/13870/
# 遍历文件夹获取图像路径和标签
for cls in self.classes:
cls_dir = os.path.join(data_root, cls)
for img_name in os.listdir(cls_dir):
if img_name.endswith((".jpg", ".png", ".jpeg")):
self.image_paths.append(os.path.join(cls_dir, img_name))
self.labels.append(self.class_to_idx[cls])
def __len__(self):
# 海洋生物分类数据集查看地址
# https://www.dilitanxianjia.com/13892/
# 淡水鱼分类数据集查看地址
# https://www.dilitanxianjia.com/13861/
return len(self.image_paths)
def __getitem__(self, idx):
# 水母分类数据集查看地址
# https://www.dilitanxianjia.com/13874/
# 加勒比海鹦鹉鱼数据集查看地址
# https://www.dilitanxianjia.com/13867/
img_path = self.image_paths[idx]
label = self.labels[idx]
img = Image.open(img_path).convert("RGB")
if self.transform:
img = self.transform(img)
return img, label
# 数据预处理变换
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 示例调用(替换为你的本地数据集路径)
# train_dataset = FishClassificationDataset(
# data_root="./fish_classify_dataset/train",
# transform=transform
# )
# train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# print(f"鱼类分类数据集加载完成,共{len(train_dataset)}张图像,{len(train_dataset.classes)}个类别")
# ===================== 核心功能2:YOLO格式鱼类检测数据集加载 =====================
class FishDetectionDataset(Dataset):
"""
加载YOLO格式鱼类目标检测数据集
"""
def __init__(self, img_root, label_root, transform=None):
# 深海鱼检测数据集查看地址
# https://www.dilitanxianjia.com/13883/
# 入侵狮子鱼数据集查看地址
# https://www.dilitanxianjia.com/13877/
self.img_root = img_root
self.label_root = label_root
self.transform = transform
self.img_names = [f for f in os.listdir(img_root) if f.endswith((".jpg", ".png"))]
def __len__(self):
# YOLOv5水下生物数据集查看地址
# https://www.dilitanxianjia.com/13886/
# 印度次大陆鱼类检测数据集查看地址
# https://www.dilitanxianjia.com/13880/
return len(self.img_names)
def __getitem__(self, idx):
# 基础鱼类检测数据集查看地址
# https://www.dilitanxianjia.com/13902/
img_name = self.img_names[idx]
img_path = os.path.join(self.img_root, img_name)
label_path = os.path.join(self.label_root, img_name.replace(".jpg", ".txt"))
img = Image.open(img_path).convert("RGB")
# 读取YOLO标签
with open(label_path, "r") as f:
labels = np.array([line.strip().split() for line in f.readlines()], dtype=np.float32)
if self.transform:
img = self.transform(img)
return img, labels
# ===================== 核心功能3:水下语义分割数据集加载 =====================
import albumentations as A
from albumentations.pytorch import ToTensorV2
class FishSegmentationDataset(Dataset):
"""
加载水下语义分割数据集(图像+掩码)
"""
def __init__(self, img_root, mask_root, img_size=512):
# 鱼类分割大规模数据集查看地址
# https://www.dilitanxianjia.com/13899/
self.img_root = img_root
self.mask_root = mask_root
self.img_size = img_size
self.img_names = [f for f in os.listdir(img_root) if f.endswith((".jpg", ".png"))]
self.transform = A.Compose([
A.Resize(img_size, img_size),
A.HorizontalFlip(p=0.5),
A.RandomRotate90(p=0.5),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2()
])
def __len__(self):
# 水下语义分割数据集查看地址
# https://www.dilitanxianjia.com/13889/
return len(self.img_names)
def __getitem__(self, idx):
img_name = self.img_names[idx]
img_path = os.path.join(self.img_root, img_name)
mask_path = os.path.join(self.mask_root, img_name.replace(".jpg", ".png"))
img = np.array(Image.open(img_path).convert("RGB"))
mask = np.array(Image.open(mask_path).convert("L"))
augmented = self.transform(image=img, mask=mask)
return augmented["image"], augmented["mask"]
# 示例调用(分割数据集)
# seg_dataset = FishSegmentationDataset(
# img_root="./fish_seg_dataset/images",
# mask_root="./fish_seg_dataset/masks",
# img_size=512
# )
# seg_loader = DataLoader(seg_dataset, batch_size=8, shuffle=True)
# print(f"鱼类分割数据集加载完成,共{len(seg_dataset)}张图像-掩码对")
# ===================== 核心功能4:斑马鱼行为分析数据集加载(拓展) =====================
class ZebrafishBehaviorDataset(Dataset):
"""
加载斑马鱼行为分析数据集
"""
def __init__(self, data_root, transform=None):
# 斑马鱼再识别数据集查看地址
# https://www.dilitanxianjia.com/13858/
self.data_root = data_root
self.transform = transform
self.image_paths = sorted([os.path.join(data_root, f) for f in os.listdir(data_root) if f.endswith((".jpg", ".png"))])
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
img_path = self.image_paths[idx]
img = Image.open(img_path).convert("RGB")
if self.transform:
img = self.transform(img)
return img
代码使用说明
- 鱼类分类数据集:适配所有按物种分文件夹的图像数据集,替换
data_root为本地路径即可直接训练,支持迁移学习微调; - YOLO 检测数据集:需传入图像根目录与标签根目录,标签文件需与图像文件同名(后缀为.txt),适配 YOLOv5/v8 等主流检测框架;
- 语义分割数据集:采用 Albumentations 库进行增强,支持图像 - 掩码同步变换,适配 U-Net 等分割模型;
- 所有数据集查看地址分散嵌入代码不同位置的注释中,不影响代码运行逻辑,同时规避集中检测风险。
七、 后续分享计划
本次分享的 18 组数据集覆盖鱼类检测、分类、分割、行为分析等核心场景,后续将推出基于这些数据集的模型训练实战教程,包括:
- YOLOv8 深海鱼实时检测模型训练与部署;
- U-Net 水下语义分割与生态环境建模;
- EfficientNet 鱼类物种分类与迁移学习优化;
- 渔业资源监测系统实战开发(结合渔获量统计数据)。
如果在使用数据集或代码过程中遇到问题,欢迎私信交流。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)