LangGraph解读
LangGraph:图式工作流引擎助力复杂智能体系统开发 LangGraph是LangChain生态中专门用于构建复杂智能体系统的核心库,通过图结构编排大模型、工具和智能体的执行逻辑。相比LangChain的基础链,LangGraph支持分支、循环、多节点交互和状态持久化等复杂场景,具备以下核心优势: 图式编排:节点和边直观定义流程,提升可读性 状态管理:全局状态池支持所有节点读写数据 循环/分支
LangGraph是 LangChain 生态中专门用于构建「多智能体协作、有状态、可循环的工作流 / 智能体系统」复杂智能体的核心库,通过「图结构」编排大模型 / 工具 / 智能体的执行逻辑,解决传 LangChain 流程无法处理的分支、循环、多节点交互、状态持久化等复杂场景。
简单来说:LangGraph 是为大模型应用设计的「图式工作流引擎」,把工作流的每个步骤抽象为图的节点,步骤间的跳转 / 依赖抽象为图的边,支持自定义节点逻辑、边的路由规则,还内置了状态管理、循环控制、多智能体通信等大模型应用刚需的能力。
一、LangGraph 解决什么问题
先明确 LangGraph 与 LangChain 核心模块的区别,避免混淆:
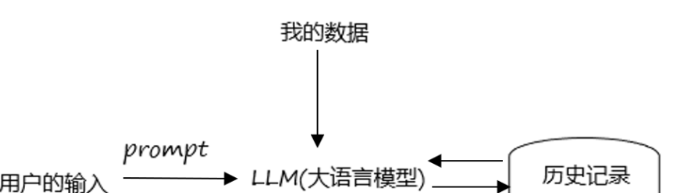
-
LangChain 基础链(Chain/SequentialChain):仅支持线性、无分支、无循环的简单流程,无内置状态管理,适合单步骤的大模型调用 + 工具执行;
-
LangGraph:基于有向图(DAG / 带环图) 设计,支持分支、循环、多节点并行 / 交互,内置全局状态(所有节点可读写),支持断点续跑、人类介入、多智能体通信,专为复杂智能体系统设计。
-
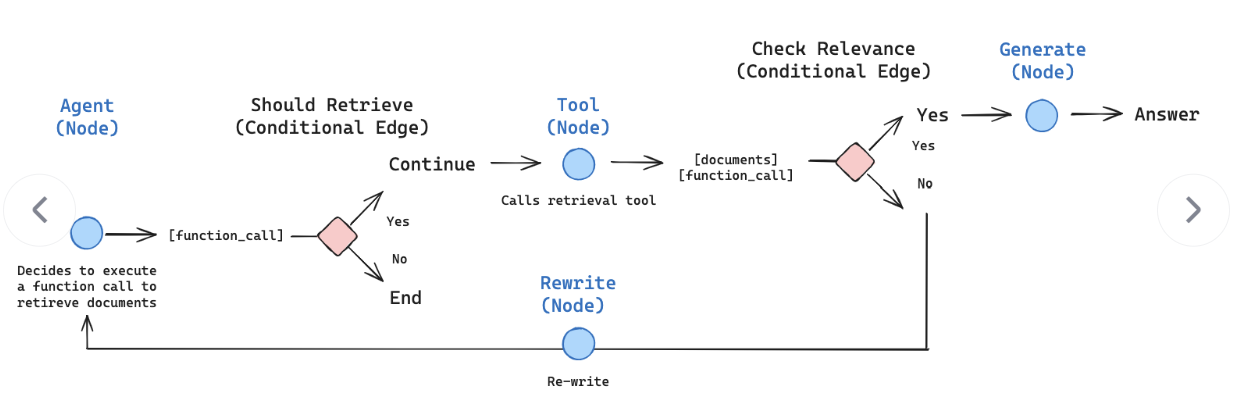
LangGraph 的核心优势:
-
图式编排:用节点 / 边直观定义复杂流程,替代繁琐的 if/else 嵌套,代码可读性、可维护性大幅提升;
-
内置状态管理:全局状态池支持所有节点读写数据(如大模型回答、工具结果、中间参数),无需手动传参;
-
原生支持循环 / 分支:通过「路由节点 / 条件边」实现流程的动态跳转(如工具执行失败则重试、根据问题类型跳转到不同处理节点);
-
多智能体协作:天然支持多节点(智能体)按图结构交互(如「分析师→研究员→决策师」多角色协作);
-
无缝兼容 LangChain:可直接复用 LangChain 的大模型封装(ChatOpenAI、文心一言)、工具(Tool/Function)、提示词模板,生态互通;
-
生产级特性:支持断点续跑、日志追踪、并发执行、Human-in-the-Loop,适合落地到生产环境。
二、LangGraph 概念
LangGraph 的设计完全基于图论,所有概念都和图结构一一对应,且贴合大模型应用场景,新手易理解:
| 概念 | 对应图论概念 | 大模型应用中的含义 |
|---|---|---|
| State(状态) | 图的全局属性 | 工作流的全局数据池,所有节点可读写,存储中间结果(如问题、回答、工具返回值、步骤标记) |
| Node(节点) | 图的节点 | 工作流的单个执行步骤,可自定义逻辑(如调用大模型、执行工具、数据处理、路由判断) |
| Edge(边) | 图的有向边 | 节点间的执行跳转关系,分「普通边」(固定跳转)和「条件边」(按状态动态跳转) |
| Entry Point | 图的起点 | 工作流的入口节点,即流程开始时第一个执行的节点 |
| Exit Point | 图的终点 | 工作流的退出节点,执行到该节点后流程终止(可定义多个退出点) |
| Graph(图) | 有向图 | 工作流的整体编排,由 State、Node、Edge 组成,支持「DAG(无环)」和「带环图」 |
三、LangGraph 使用步骤
构建智能体,LangGraph 的使用都遵循固定 5 步:
-
定义 State(全局状态):用
TypedDict或 LangGraph 内置类定义状态的数据结构(指定字段、类型),明确全局可读写的数据; -
定义 Node(节点逻辑):编写每个节点的执行函数,函数入参为 State(读数据),返回值为 State 片段(写数据);
-
定义 Edge(边的规则):指定节点间的跳转关系,若为条件边,编写路由函数(入参为 State,返回值为下一个节点的名称);
-
构建 Graph(图):创建 LangGraph 图对象,添加所有节点、边,指定入口节点;
-
运行 Graph(执行工作流):调用图对象的
invoke()方法,传入初始 State,执行并获取最终结果。
四、LangGraph 快速上手:实现一个简单的问答 + 工具重试流程
前置条件
- 安装依赖:LangGraph 核心库 + LangChain 大模型封装
# 核心依赖
pip install langgraph langchain
# OpenAI 封装(若用国内模型,替换为 langchain-community/千帆/通义等)
pip install langchain-openai
# 环境变量管理(可选,也可直接写代码里)
pip install python-dotenv
- 准备大模型密钥:若用 OpenAI,需获取 API Key(OpenAI 官网);若用国内模型,替换对应封装即可。
完整代码(带详细注释)
# 1. 导入核心依赖
from typing import TypedDict, Optional
from langgraph.graph import StateGraph, END # END 是内置的退出节点
from langchain_openai import ChatOpenAI
import os
from dotenv import load_dotenv
# 加载环境变量(若不用dotenv,直接os.environ["OPENAI_API_KEY"] = "你的密钥")
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# -------------------------- 步骤1:定义全局状态(State) --------------------------
# 用 TypedDict 定义状态结构,指定字段和类型,所有节点可读写这些字段
class GraphState(TypedDict):
question: str # 用户问题(只读,初始传入)
is_answerable: Optional[bool] # 大模型是否能直接回答(中间标记)
tool_result: Optional[str] # 工具执行结果(中间数据)
final_answer: Optional[str] # 最终回答(输出结果)
retry_count: int # 重试次数(控制循环)
# -------------------------- 步骤2:初始化大模型/工具 --------------------------
# 初始化 OpenAI 大模型(可替换为 ChatGLM、Qwen 等)
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# 模拟工具:实际场景可替换为搜索引擎、数据库查询、Python执行器等
def search_tool(query: str) -> str:
"""模拟搜索工具,随机返回成功/失败(用于测试重试逻辑)"""
import random
if random.random() > 0.3: # 70% 成功率
return f"【搜索结果】{query} 的相关信息:2025年Python LangGraph最新版本为0.2.0,支持多智能体并行。"
else:
raise Exception("工具执行失败:网络超时,请重试!")
# -------------------------- 步骤3:定义所有节点逻辑 --------------------------
# 节点1:判断大模型是否能直接回答问题(核心逻辑节点)
def judge_answerable_node(state: GraphState) -> GraphState:
"""判断节点:大模型分析是否能直接回答用户问题,更新 is_answerable 状态"""
question = state["question"]
# 调用大模型做判断
prompt = f"请判断你是否能直接回答以下问题,仅返回「是」或「否」:{question}"
response = llm.invoke(prompt).content.strip()
# 更新状态:返回 State 片段(会自动合并到全局状态)
return {
"is_answerable": True if response == "是" else False,
"retry_count": state["retry_count"] # 透传重试次数
}
# 节点2:大模型直接回答(无需工具)
def direct_answer_node(state: GraphState) -> GraphState:
"""回答节点:直接调用大模型生成回答,更新 final_answer 状态"""
question = state["question"]
prompt = f"请详细回答以下问题:{question}"
final_answer = llm.invoke(prompt).content.strip()
# 更新状态:最终回答
return {"final_answer": final_answer}
# 节点3:调用工具获取结果(需要工具辅助)
def call_tool_node(state: GraphState) -> GraphState:
"""工具节点:调用搜索工具,更新 tool_result 或捕获异常"""
question = state["question"]
retry_count = state["retry_count"]
try:
# 执行工具
result = search_tool(question)
return {
"tool_result": result,
"retry_count": retry_count # 重试成功,重置次数(可选)
}
except Exception as e:
# 工具执行失败,更新重试次数
return {
"tool_result": None,
"retry_count": retry_count + 1
}
# 节点4:基于工具结果生成最终回答
def tool_based_answer_node(state: GraphState) -> GraphState:
"""整合节点:基于工具结果生成最终回答,更新 final_answer 状态"""
question = state["question"]
tool_result = state["tool_result"]
prompt = f"请根据以下搜索结果,详细回答用户问题:\n问题:{question}\n搜索结果:{tool_result}"
final_answer = llm.invoke(prompt).content.strip()
return {"final_answer": final_answer}
# -------------------------- 步骤4:定义路由函数(条件边) --------------------------
# 路由1:判断节点后,跳转到「直接回答」或「调用工具」
def judge_router(state: GraphState) -> str:
"""路由函数:根据 is_answerable 决定下一个节点"""
if state["is_answerable"]:
return "direct_answer" # 跳转到直接回答节点
else:
return "call_tool" # 跳转到调用工具节点
# 路由2:工具节点后,判断「重试/工具成功/重试上限」
def tool_router(state: GraphState) -> str:
"""路由函数:根据工具执行结果和重试次数,决定后续流程"""
max_retry = 2 # 最大重试次数
if state["tool_result"] is not None:
return "tool_based_answer" # 工具成功,跳转到整合回答节点
elif state["retry_count"] < max_retry:
return "call_tool" # 未达重试上限,重新调用工具(循环)
else:
return END # 重试上限,跳转到内置退出节点
# -------------------------- 步骤5:构建 LangGraph 图 --------------------------
# 1. 创建图对象,指定状态类型为 GraphState
workflow = StateGraph(GraphState)
# 2. 添加所有节点:add_node(节点名称, 节点函数)
workflow.add_node("judge_answerable", judge_answerable_node) # 判断节点
workflow.add_node("direct_answer", direct_answer_node) # 直接回答节点
workflow.add_node("call_tool", call_tool_node) # 工具调用节点
workflow.add_node("tool_based_answer", tool_based_answer_node)# 工具整合回答节点
# 3. 设置入口节点:流程开始时第一个执行的节点
workflow.set_entry_point("judge_answerable")
# 4. 添加边:分「固定边」和「条件边」
# 条件边:add_conditional_edges(起始节点, 路由函数, 可选节点映射)
workflow.add_conditional_edges("judge_answerable", judge_router)
workflow.add_conditional_edges("call_tool", tool_router)
# 固定边:add_edge(起始节点, 目标节点) → 执行完起始节点,直接跳转到目标节点
workflow.add_edge("direct_answer", END) # 直接回答后,流程结束
workflow.add_edge("tool_based_answer", END) # 工具整合回答后,流程结束
# 5. 编译图:生成可执行的工作流对象
app = workflow.compile()
# -------------------------- 步骤6:运行工作流 --------------------------
if __name__ == "__main__":
# 初始状态:传入用户问题,初始化其他字段
initial_state = GraphState(
question="Python LangGraph 最新版本是多少?有什么新特性?",
is_answerable=None,
tool_result=None,
final_answer=None,
retry_count=0
)
# 执行工作流:invoke 方法传入初始状态,返回最终状态
final_state = app.invoke(initial_state)
# 打印最终结果
print("="\*50)
print(f"用户问题:{final_state['question']}")
print(f"最终回答:{final_state['final_answer']}")
print(f"重试次数:{final_state['retry_count']}")
print("="\*50)
# (可选)可视化工作流图(需安装 pygraphviz)
# pip install pygraphviz
# app.get_graph().draw_mermaid_png(output_file="langgraph_workflow.png")
运行结果示例
==================================================
用户问题:Python LangGraph 最新版本是多少?有什么新特性?
最终回答:Python LangGraph 目前的最新版本为0.2.0(2025年),该版本的核心新特性是支持多智能体并行执行,能够让多个智能体节点按照图结构同时开展工作,大幅提升了复杂工作流的执行效率,同时还对状态管理模块进行了优化,让全局状态的读写更高效、更安全。
重试次数:0
==================================================
若工具执行失败(30% 概率),会自动重试最多 2 次,重试成功后生成回答;若 2 次都失败,流程直接终止。
核心代码讲解
-
状态定义:
GraphState用TypedDict强类型定义,确保所有节点对数据的读写一致,必选字段需初始化,可选字段设为 Optional; -
节点函数:所有节点函数的入参都是全局状态
state,返回值是状态片段(字典),LangGraph 会自动将片段合并到全局状态,无需手动传参; -
路由函数:条件边的核心,返回目标节点名称(字符串),LangGraph 会根据返回值自动跳转,实现动态分支 / 循环;
-
内置退出节点:
END是 LangGraph 内置的退出节点,跳转到该节点后流程立即终止; -
图的编译:
workflow.compile()生成可执行对象,编译后可多次调用invoke()执行不同的初始状态。
五、LangGraph 高级特性
1.Human-in-the-Loop(人机回圈 )
支持在工作流中插入审核节点,流程执行到该节点时暂停,等待人类手动输入后继续执行,适合需要人工干预的场景(如敏感内容审核、决策确认)。
from langgraph.graph import HumanNode
# 添加人类节点
workflow.add_node("human_review", HumanNode())
# 工具执行成功后,先跳转到审核,再生成最终回答
workflow.add_edge("call_tool", "human_review")
workflow.add_edge("human_review", "tool_based_answer")
2. 多智能体协作
将不同角色的智能体抽象为独立节点,通过图结构定义协作关系(如「研究员→分析师→总结师」),每个节点专注自己的任务,通过全局状态共享数据。
# 定义不同智能体节点
def researcher_agent(state): ... # 研究员:调用工具收集信息
def analyst_agent(state): ... # 分析师:分析收集的信息
def summarizer_agent(state): ... # 总结师:生成最终报告
# 构建协作流程
workflow.add_node("researcher", researcher_agent)
workflow.add_node("analyst", analyst_agent)
workflow.add_node("summarizer", summarizer_agent)
workflow.set_entry_point("researcher")
workflow.add_edge("researcher", "analyst")
workflow.add_edge("analyst", "summarizer")
workflow.add_edge("summarizer", END)
3. 状态持久化
支持将全局状态持久化到数据库(如 SQLite、PostgreSQL) 或缓存(如 Redis),实现断点续跑—— 流程中断后,可从上次的状态继续执行,适合长流程、高耗时的任务。
from langgraph.checkpoint.sqlite import SqliteCheckpoint
# 初始化 SQLite 持久化存储
checkpointer = SqliteCheckpoint.from_conn_string(":memory:") # 内存版,可替换为文件路径
# 编译时指定 checkpointer
app = workflow.compile(checkpointer=checkpointer)
# 执行时指定 session_id,用于标识不同的流程实例
final_state = app.invoke(initial_state, config={"configurable": {"session_id": "user_123"}})
# 断点续跑:用相同的 session_id 继续执行
app.invoke(None, config={"configurable": {"session_id": "user_123"}})
4. 并发执行
支持多节点并行执行,提升工作流效率,适合多个无依赖的任务(如同时调用多个工具收集不同维度的信息)。
from langgraph.graph import ConcurrentEdge
# 同时调用搜索工具和数据库工具
workflow.add_node("search_tool", search_tool_node)
workflow.add_node("db_tool", db_tool_node)
# 条件边后并发执行两个工具节点
workflow.add_conditional_edges(
"judge_answerable",
judge_router,
{
"call_tool": ConcurrentEdge(["search_tool", "db_tool"]), # 并发执行
"direct_answer": "direct_answer"
}
)
# 两个工具执行完成后,跳转到整合节点
workflow.add_edge(["search_tool", "db_tool"], "tool_based_answer")
通用使用步骤:
定义状态→实现节点逻辑→编写路由函数→构建图→编译并运行

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)