什么?Agent Skills在“货拉拉”AI应用尝试?
摘要: Anthropic推出的Agent Skills是一种开放标准,通过模块化技能包(指令、脚本和资源)动态扩展智能体能力。与MCP(工具库)和A2A(协作协议)形成互补:Agent Skills专注任务能力,MCP提供统一工具,A2A实现多智能体协作。其核心优势包括: 渐进式披露:按需加载技能内容,避免上下文窗口浪费; 代码协同:确定性任务由传统代码高效处理,LLM专注非确定性决策; 可复用
前言
美国时间 2025 年 12 月 18 日,Anthropic 正式宣布将 Agent Skills 发布为开放标准。去年刚写了篇关于 MCP 的文章,今年 Anthropic 发布了 Agent Skills,迫不及待的试一试,到底有没有宣发的那么强悍。
Agent Skills 是什么
This led us to create Agent Skills: organized folders of instructions, scripts, and resources that agents can discover and load dynamically to perform better at specific tasks.
官网的介绍就是这样,说到 Agent Skills,就一定要和 MCP,A2A 对比,这样才能更好理解 Agent Skills。

首先,抛出结论:Agent Skills 定义“能力”,MCP 提供“工具”,A2A 实现“协作”。
对比

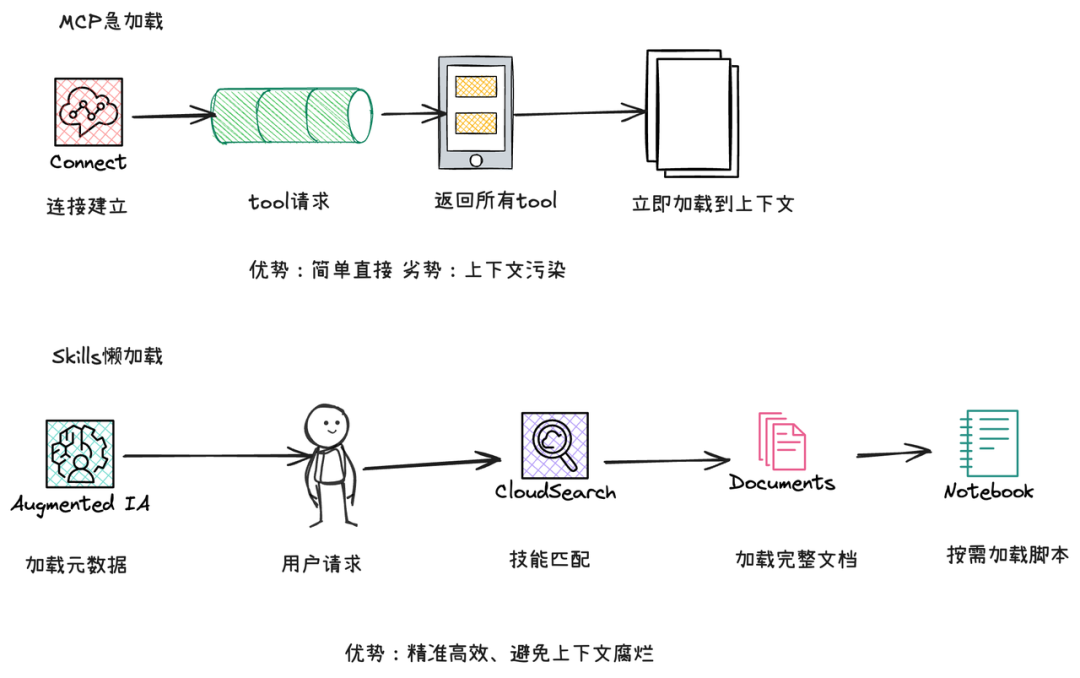
核心关系
你可以将这三者理解为构建一个“智能体公司”的不同部门:
-
• Agent Skills 像是公司的各个专业员工,他们各自掌握了完成特定任务(如写代码、做设计、分析数据)的完整方法和流程。
-
• MCP 像是公司的统一后勤与工具库。无论哪个员工需要工具(如使用数据库、调用某个软件),都通过标准流程从这个库中领取,无需自己再造。
-
• A2A 像是公司内部的协作通讯协议和会议制度。当一项复杂任务需要多个部门的员工(即多个智能体)合作时,他们依据这套规则进行沟通、同步进度和交付成果。
优势
Agent Skill 的思路有别于 MCP 的开发模式,从官网来看,有几个特点可以关注。
特点一:渐进式披露 (Progressive Disclosure)
渐进式披露是Agent技能设计中的核心原则,它让智能体的技能体系既灵活又可扩展。就像一本结构清晰的说明书,先给目录,再分章节,最后附上详细附录——技能的设计也是如此,让Claude只在需要时才加载对应的信息。
当智能体具备文件系统和代码执行工具时,在处理特定任务时,无需一次性将某个技能的全部内容读入上下文窗口。这意味着,一个技能所能涵盖的信息量实际上是没有上限的。这相当于,你可以给一个 Agent 装备 1000 个,甚至无限技能(从写 SQL 到 查数据),只占用极少的上下文(Context),只在执行时才调用相关工具。这完美解决了长期以来困扰开发者的Token 浪费和上下文干扰问题。
特点二:LLM不是万能的
大语言模型虽然擅长处理多种任务,但有些操作还是交给传统代码来执行更合适。比如,让模型通过逐词生成来排序一个列表,远比直接运行排序算法的消耗大得多。除了效率问题,很多实际应用还需要确定性的可靠结果——而这只有代码才能保证。
Agent Skills提出,很多确定性的事情或者输入输出很清晰的事情,是可以拆解为traditional code执行,甚至执行的效果会更好,这也是Agent Skills的优势,它只会在具体执行到的时候触发(Claude can run this script without loading either the script or the PDF into context.)不用像传统Agent方式,全部输入到prompt上下文。

技能会在上下文窗口中通过系统提示符触发
落地
大概的Skill结构,如下
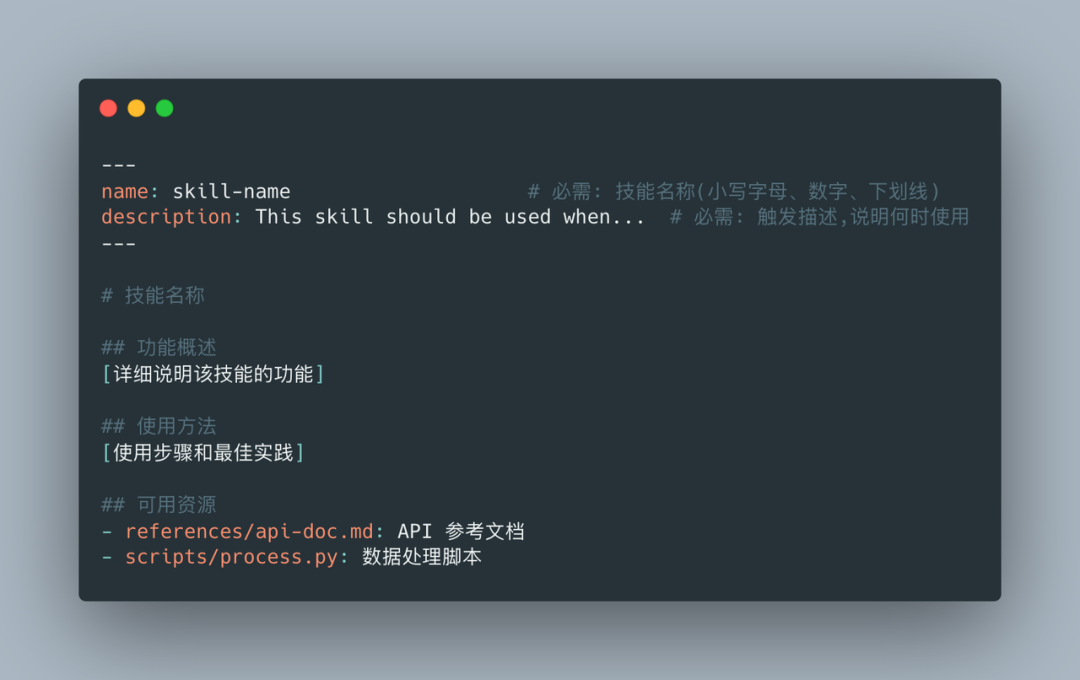
必需字段:
实战一:自然语言查数
背景
大数据存在大量数据分析场景,例如财务、A/B 实验报告等。Agent Skills 可将流程性的知识,打包成可组合、可复用的技能。我们不需要造更多的 Agent,只需动态加载技能,就可以解决特定领域的问题。
案例
我们可以将财务Agent和A/B实验报告Agent的自然语言查数,提炼为如下步骤:
- \1. 理解用户意图:选择合适的数据集信息(财务、A/B实验报告(订单、用户))
- \2. 加载领域知识:读取相关场景的元数据、业务知识等信息
- \3. 加载SQL:生成知识,识别所使用的数据库信息、及相关SQL规范
- \4. 生成并执行 SQL:选取hive.py & doris.py 工具,查询结果
现在,我们将这一套流程打包成技能,其结构如下:

接下来,我们在 Agent 中注册这个技能,就可以快速实现自然语言查数的能力。
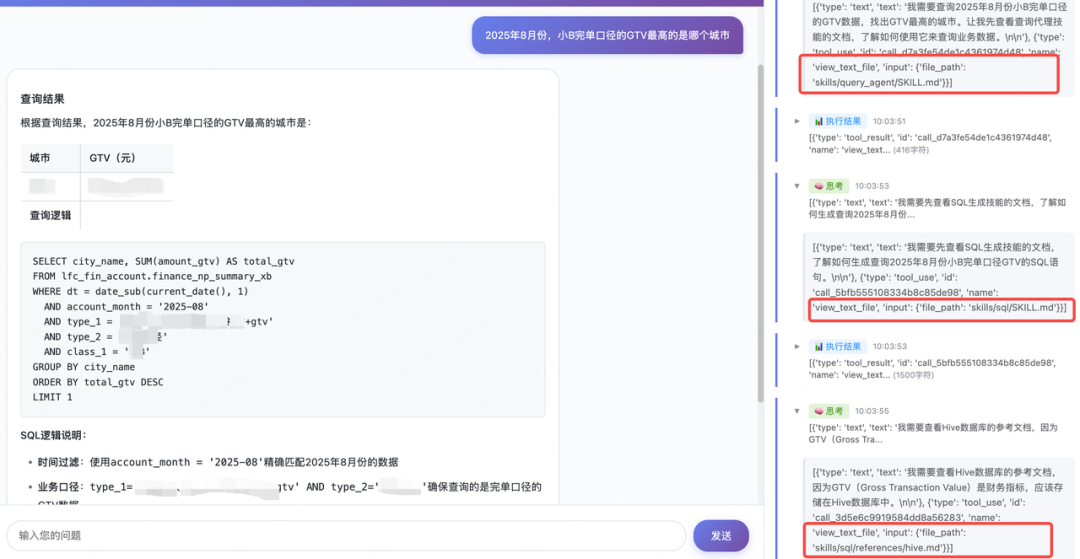 财务
财务
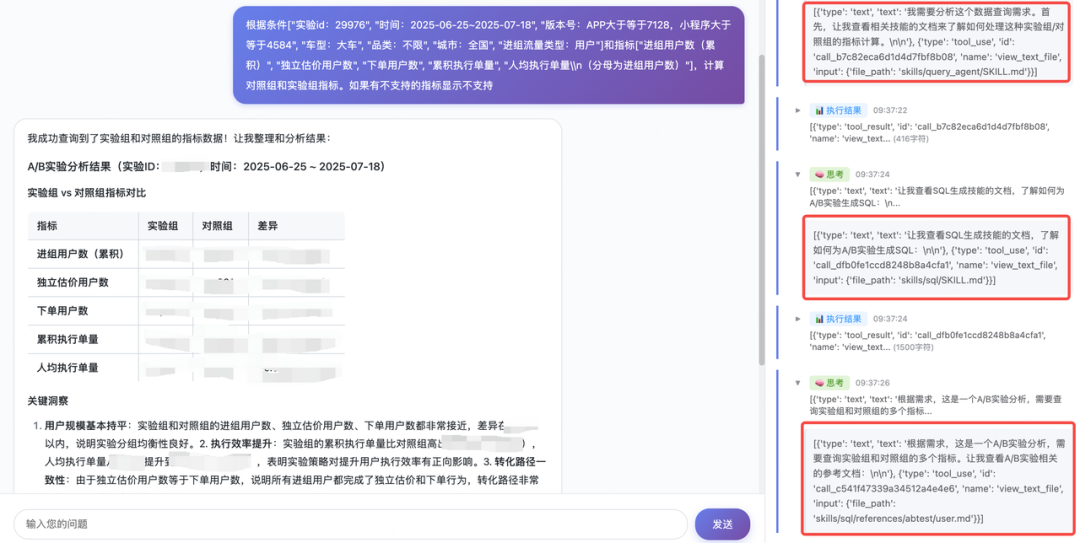 实验报告
实验报告
将自然语言查数打包成技能,后续各业务Agent不再需要定制自然语言查数能力,只需要做好相关领域知识的维护,就能快速解决查数问题,而且,整个流程更容易治理和迭代。
实战二:指标归因分析
背景
大数据存在海量的数据,数据需做一些归因分析,可以进一步发挥数据价值。
skills能力

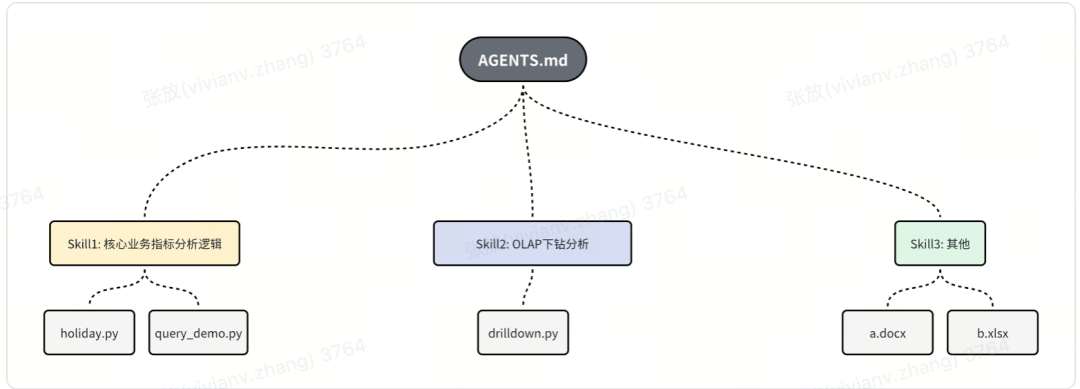
核心流程:
- \1. 理解用户意图:选择合适的SKILL
- \2. 加载领域知识:读取相关场景的元数据、业务知识等信息
- \3. 解析scripts:识别提供的python工具包并使用
- \4. 判断是否继续:判断是否解决问题并调用其他工具
核心结果:
第一阶段分析,分析结束后可衔接其他技能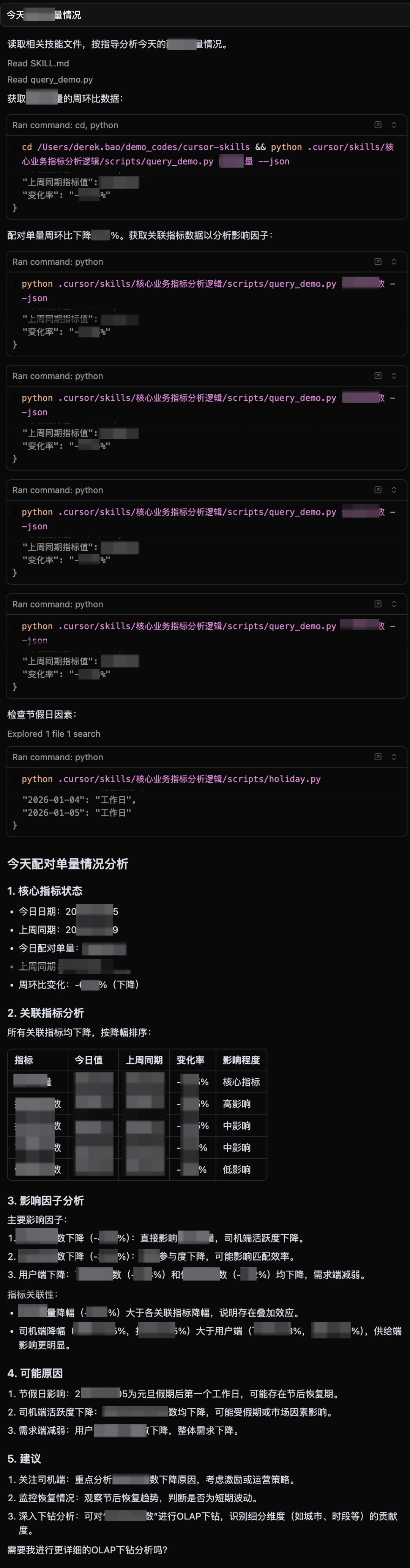 |
第二阶段分析,数据视角更深入 |
|---|---|
注意:*文章内容均为测试环境测试数据*
- \1. 业务经验抽象的质量,决定了Agent能力的上限
- \2. Agent Skills方案,降低了把业务经验注入到大模型的技术复杂度
- \3. scripts是双刃剑,为agent扩展能力边界的同时,也带来较大安全隐患,请谨慎使用外部Skills
核心业务指标分析逻辑 SKILL.md原文件
---
name: 核心业务指标分析逻辑
description: 分析指标1指标及其关联指标的周环比变化,识别影响因子和异常原因。使用场景:当用户需要分析业务指标变化、查找指标下降原因、进行指标根因分析时。
---
# 核心业务指标分析逻辑
分析指标1指标及其关联指标的周环比变化,识别影响因子和可能原因。
## 分析流程
### 1. 获取指标1周环比数据
调用 `scripts/query_demo.py` 获取指标1指标的周环比数据:
python scripts/query_demo.py 指标1 --json
返回数据包含:
- 今日日期、上周同期日期
- 今日指标值、上周同期指标值
- 变化率(周环比)
### 2. 判断是否需要深入分析
**如果指标1环比下降**,继续执行以下步骤:
#### 2.1 获取关联指标数据
调用 `scripts/query_demo.py` 获取以下指标的周环比数据:
- 指标1
- 指标2
- 指标3
- 指标4
- 指标5
python scripts/query_demo.py <指标名称> --json
#### 2.2 分析影响因子
对比各指标的变化率,识别:
- 哪个指标对指标1影响较大(变化率最显著)
- 指标间的关联关系
- 可能的原因分析
### 3. 获取节假日信息(可选)
如需考虑节假日因素,调用 `scripts/holiday.py`:
python scripts/holiday.py
返回指定日期范围内的工作日和节假日信息,用于判断指标变化是否受节假日影响。
### 4. 进行OLAP下钻分析(可选)
对于影响较大的指标,可进行OLAP下钻分析以识别细分维度的贡献度:
参考 `OLAP下钻分析` 技能,使用该技能进行多维度下钻分析。
## 支持的指标
- 指标1(核心指标)
- 指标2
- 指标3
- 指标4
- 指标5
## 分析输出建议
分析结果应包含:
1. **核心指标状态**
- 指标1周环比变化
- 变化趋势(上升/下降/持平)
2. **关联指标分析**(如指标1下降)
- 各关联指标的周环比数据
- 影响因子排序
- 指标关联性分析
3. **可能原因**
- 基于数据变化的可能原因推断
- 节假日因素(如适用)
- 其他外部因素考虑
4. **下钻分析结果**(如适用)
- 细分维度的贡献度分析
- 关键维度识别
## 使用示例
**示例:分析指标1下降原因**
# 1. 获取指标1数据
python scripts/query_demo.py 指标1 --json
# 2. 如果下降,获取关联指标
python scripts/query_demo.py 指标2 --json
python scripts/query_demo.py 指标3 --json
python scripts/query_demo.py 指标4 --json
python scripts/query_demo.py 指标5 --json
# 3. 检查节假日因素
python scripts/holiday.py
# 4. 对影响最大的指标进行下钻分析(如指标2)
展望
Agent Skills 并非一个简单的“新功能”,而是从单体架构到微服务,从过程式脚本到组件化框架这一转型的标准化接口。它的核心价值,在于为“模型智能”的工程化落地,定义了一种可组合、可复用的 “能力单元” 设计范式。
未来的竞争维度将发生根本变化:问题将从 “你的**单体模型(巨石应用)**性能多强?” ,转向 “你的‘包管理器’(Skill 生态)有多丰富、可靠和高效?” 。拥有最强大模型,但缺乏易用、标准化能力接口的公司,可能会像拥有最强单核CPU但缺乏操作系统和软件生态的厂商一样,在真正的应用战场中失势。
Skill 规范,正是在尝试为 AI 世界定义那个至关重要的 “操作系统层”和“包管理协议”。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
人工智能时代最缺的是什么?就是能动手解决问题还会动脑创新的技术牛人!智泊AI为了让学员毕业后快速成为抢手的AI人才,直接把课程升级到了V6.0版本。
这个课程就像搭积木一样,既有机器学习、深度学习这些基本功教学,又教大家玩转大模型开发、处理图片语音等多种数据的新潮技能,把AI技术从基础到前沿全部都包圆了!
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
课程还教大家怎么和AI搭档一起工作,就像程序员带着智能助手写代码、优化方案,效率直接翻倍!
这么练出来的学员确实吃香,83%的应届生都进了大厂搞研发,平均工资比同行高出四成多。
智泊AI还特别注重培养"人无我有"的能力,比如需求分析、创新设计这些AI暂时替代不了的核心竞争力,让学员在AI时代站稳脚跟。
课程优势一:人才库优秀学员参与真实商业项目实训
课程优势二:与大厂深入合作,共建大模型课程

课程优势三:海外高校学历提升

课程优势四:热门岗位全覆盖,匹配企业岗位需求
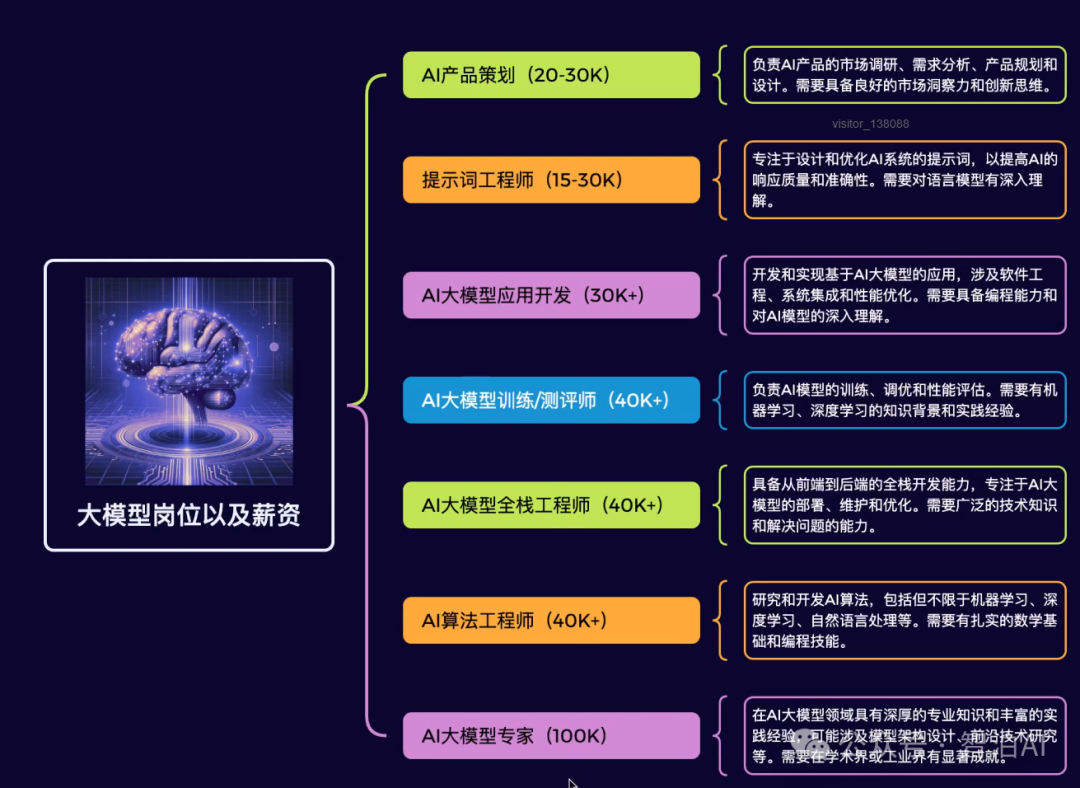
如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
·应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
·零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
·业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
重磅消息
人工智能V6.0升级两大班型:AI大模型全栈班、AI大模型算法班,为学生提供更多选择。

由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【最新最全版】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
来智泊AI,高起点就业
培养企业刚需人才
扫码咨询 抢免费试学
⬇⬇⬇

AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献204条内容
已为社区贡献204条内容

所有评论(0)