从0到1:手把手教你构建MCP应用(下)
本文探讨了MCPServer的进阶优化与安全控制。在性能优化方面,介绍了数据库连接池、缓存机制和批量操作等关键技术;在安全控制层面,详细讲解了认证授权、权限矩阵和审计日志等安全措施。文章还展示了MCP在自动化写作中的具体应用场景,包括素材收集、知识库检索和自动配图等功能。最后分析了MCP当前面临的挑战(认证、权限管理、生态碎片化等)和未来发展趋势,指出MCP有望成为AI时代的标准化交互协议。
进阶:性能优化、安全控制
当你的MCP Server变得更复杂时,需要考虑进阶话题。
性能优化
1. 连接池
对于数据库访问,使用连接池:
from sqlalchemy import create_engine
from sqlalchemy.pool import QueuePool
engine = create_engine(
'sqlite:///database.db',
poolclass=QueuePool,
pool_size=5,
max_overflow=10
)
def get_db_connection():
return engine.connect()2. 缓存
对于频繁调用的工具,添加缓存:
from functools import lru_cache
import time
@lru_cache(maxsize=100)
def get_user_info(user_id: int):
"""缓存用户信息,减少数据库查询"""
return database.query(f"SELECT * FROM users WHERE id={user_id}")
# 或者使用TTL缓存
from cachetools import TTLCache
cache = TTLCache(maxsize=100, ttl=60) # 60秒过期
def get_cached_user(user_id: int):
if user_id in cache:
return cache[user_id]
result = database.query(user_id)
cache[user_id] = result
return result3. 批量操作
支持批量操作,减少网络往返:
@app.tool()
async def batch_insert_users(users: List[Dict[str, Any]]) -> str:
"""
批量插入用户数据
Args:
users: 用户列表,每个元素包含name、email、department
"""
conn = get_db_connection()
cursor = conn.cursor()
cursor.executemany('''
INSERT INTO users (name, email, department, join_date)
VALUES (?, ?, ?, ?)
''', [(u['name'], u['email'], u['department'], datetime.now())
for u in users])
conn.commit()
conn.close()
return f"成功插入 {len(users)} 个用户"安全控制
1. 认证与授权
对于远程MCP Server,实现认证:
from fastapi import FastAPI, Header, HTTPException
from mcp.server.fastmcp import fastmcp
app = FastAPI()
mcp = fastmcp("secure-server")
VALID_TOKENS = {"token123", "token456"}
async def verify_token(x_mcp_token: str = Header(...)):
"""验证访问令牌"""
if x_mcp_token not in VALID_TOKENS:
raise HTTPException(status_code=401, detail="Invalid token")
return x_mcp_token
@app.middleware("http")
async def auth_middleware(request, call_next):
token = request.headers.get("x-mcp-token")
if token not in VALID_TOKENS:
return JSONResponse(
status_code=401,
content={"error": "Unauthorized"}
)
response = await call_next(request)
return response2. 权限控制
实现细粒度权限:
# 权限矩阵
PERMISSIONS = {
"role_admin": ["read", "write", "delete"],
"role_user": ["read"],
"role_guest": []
}
def check_permission(role: str, action: str):
"""检查用户权限"""
allowed_actions = PERMISSIONS.get(role, [])
if action not in allowed_actions:
raise PermissionError(f"角色 {role} 没有权限执行 {action}")
@app.tool()
async def delete_user(user_id: int, role: str = "guest") -> str:
"""删除用户(需要admin权限)"""
check_permission(role, "delete")
database.delete(user_id)
return f"用户 {user_id} 已删除"3. 审计日志
记录所有操作,便于追踪:
import json
from datetime import datetime
def audit_log(action: str, params: dict, result: str, user: str):
"""记录审计日志"""
log_entry = {
"timestamp": datetime.now().isoformat(),
"action": action,
"params": params,
"result": result,
"user": user
}
with open("audit.log", "a") as f:
f.write(json.dumps(log_entry) + "\n")
@app.tool()
async def sensitive_operation(param: str, user: str = "unknown") -> str:
"""敏感操作"""
try:
result = do_operation(param)
audit_log("sensitive_operation", {"param": param}, "success", user)
return result
except Exception as e:
audit_log("sensitive_operation", {"param": param}, f"failed: {e}", user)
raise
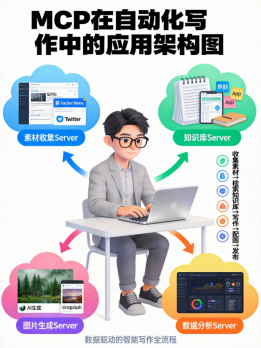
MCP在自动化写作中的应用
作为一个专注自动化写作的内容创作者,我也在思考MCP能带来什么。
场景1:自动素材收集
我写文章经常需要收集素材:GitHub上的热门项目、Hacker News的讨论、 Twitter 的趋势。可以写一个MCP Server,把这些数据源统一暴露给AI:
@app.tool()
async def search_github_repos(query: str, language: str = None) -> str:
"""搜索GitHub仓库"""
# 调用GitHub API
repos = github_api.search_repositories(query, language=language)
return format_repos(repos)
@app.tool()
async def get_hacker_news_stories(limit: int = 10) -> str:
"""获取Hacker News热门故事"""
# 调用HN API
stories = hn_api.top_stories(limit=limit)
return format_stories(stories)
@app.tool()
async def search_tweets(query: str, count: int = 10) -> str:
"""搜索Twitter推文"""
# 调用Twitter API
tweets = twitter_api.search(query, count=count)
return format_tweets(tweets)然后,我只需要对AI说:"帮我收集一下关于MCP的最新资料"。
AI会自动:
1. 调用 search_github_repos 搜索相关项目
2. 调用 get_hacker_news_stories 获取相关讨论
3. 调用 search_tweets 搜索相关推文
4. 把所有信息整理成一份素材报告
场景2:知识库检索
我的写作依赖个人素材库——写过的文章、发过的即刻动态、保存的观点笔记。可以写一个MCP Server,把这些素材库变成可查询的Resources:
@app.resource("knowledge://article/{slug}")
async def get_article(slug: str) -> str:
"""获取指定文章内容"""
return read_file(f"articles/{slug}.md")
@app.resource("knowledge://jiche/{id}")
async def get_jiche_post(id: str) -> str:
"""获取指定即刻动态"""
return database.query(f"SELECT * FROM jiche WHERE id={id}")
@app.tool()
async def search_knowledge(query: str) -> str:
"""搜索知识库"""
# 使用向量搜索
results = vector_db.search(query, top_k=5)
return format_results(results)
这样,AI在写作时可以随时引用我过去的内容。
比如:"我在哪篇文章里提到过MCP?"
AI会搜索知识库,找到相关引用。场景3:自动配图
文章写完,需要配图。MCP Server可以提供图片生成和搜索能力:
@app.tool()
async def generate_image(prompt: str, style: str = "realistic") -> str:
"""生成图片(使用AI图片生成API)"""
# 调用图片生成API
image_url = image_gen_api.generate(prompt, style=style)
return f"图片已生成: {image_url}"
@app.tool()
async def search_unsplash(query: str, count: int = 5) -> str:
"""搜索Unsplash免费图片"""
# 调用Unsplash API
images = unsplash_api.search(query, per_page=count)
return format_images(images)
@app.tool()
async def create_diagram(description: str, type: str = "flowchart") -> str:
"""创建技术图表(使用Mermaid)"""
mermaid_code = generate_mermaid(description, type)
return mermaid_code这样,AI可以根据文章内容自动选择或生成合适的配图。
总结与展望
写到这里,我们已经从0到1完成了一个完整的MCP应用开发流程。
让我总结一下关键要点:
MCP的核心价值
1. 标准化:一套协议,适配所有AI模型
2. 解耦:模型不需要了解底层数据源细节
3. 动态发现:AI可以自动发现和使用新工具
4. 安全性:内置权限控制和审计机制
开发者视角
从开发者的角度,MCP意味着:
• 开发效率:不再需要为每个模型写单独的集成
• 维护成本:统一协议,一次开发,多处使用
• 生态红利:可以使用社区现成的1000+个MCP Server
用户视角
从最终用户的角度,MCP意味着:
• 更强大的AI:AI能访问更多数据和工具
• 更流畅的体验:不需要手动配置各种API
• 更安全的交互:权限透明,操作可追踪
当前的挑战
MCP还面临一些挑战,根据我的研究:
1. 认证难题:2025年11月的一项研究指出,MCP Server存在名称欺骗攻击 风险。恶意开发者可能注册与合法Server高度相似的名称,诱导用户安装。
2. 权限管理粗粒度化:当前MCP仅支持会话级权限(全开或全关),无法实 现"仅允许读取指定目录文件"等细粒度控制。某企业案例显示,因误授权 导致AI助手获取数据库管理员权限,最终造成1.2GB用户数据泄露。
3. 生态碎片化:虽然已有1000+个社区Server,但质量参差不齐,缺乏统一 的认证和评分机制。
4. 企业适配:企业环境需要更完善的身份认证、权限管理、审计追踪,MCP当 前版本在这些方面还不够成熟。
未来展望
尽管有这些挑战,我对MCP的未来还是乐观的。
根据Microsoft的官方博客,MCP在2025年5月已经在Copilot Studio中GA(全 面可用),这标志着主流平台的认可。
Anthropic官方路线图显示,2025年11月将发布的版本会包含:
• 异步操作支持
• 无状态和可扩展性改进
• Server身份认证(.well-known URLs)
• 官方扩展支持
• MCP Registry正式版
这些改进会解决很多当前的问题。
我的个人判断
用了MCP几个月后,我觉得它确实像"AI时代的USB-C",就像USB-C统一了充电、数据传输、视频输出,MCP统一了AI与外部世界的交互方式。但还有一点距离,USB-C的成功不仅在于技术,更在于生态——所有设备都支持它。
MCP要成功,也需要:
• 更多AI平台支持(不仅Claude,GPT、Gemini等也要跟上)
• 更多高质量Server(官方+社区)
• 更完善的安全机制(认证、授权、审计)
• 更好的开发者工具(调试、测试、部署)
这条路可能还要走2-3年。
但方向是对的。
如果你想进一步探索
MCP的官方文档是最好的学习资源:
• https://modelcontextprotocol.io/ - 官方网站,包含文档和教程
• https://github.com/modelcontextprotocol/servers - 官方参考Server 集合
• https://github.com/modelcontextprotocol/inspector - MCP Inspector 调试工具
社区也在快速增长,GitHub上已经有大量优秀的MCP Server实现。
最后的话
你只需要定义好积木(MCP Server),AI模型会自动选择和组合它们来完成复杂任务,这可能就是AI Native时代应该有的开发方式,不写重复代码,不重复造轮子,专注于业务逻辑,把集成的复杂性交给标准协议,这就是MCP的价值。
你已经在用MCP了吗?在开发过程中遇到了什么问题?
欢迎在评论区分享你的经验和思考。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)