RAG体系之Query Enhancement 及下属技术:Query Transformations、HyDE、HyPE
基于大模型的轻量改写**,如查询补全、意图明确化、多义消歧(如把模糊的 “产品性能怎么样?: 输入用户原始查询、调用大模型生成贴合 RAG 场景的「假设提示词(Hypothetical Prompt)」,而非无差别的假设文档、将假设提示词通过嵌入模型转化为向量、用该向量在知识库中检索,匹配真实文档块。通过大模型生成「与用户查询匹配的假设性文档」,用「假设文档的向量」替代「原始查询的向量」进行检索,
Query Enhancement(查询增强)是 RAG 体系中聚焦用户提问侧的核心优化技术,其中
Query Transformations(查询转换)、HyDE(假设文档嵌入)、HyPE(假设提示嵌入)是 查询增强的三大核心落地技术;
1、Query Transformations
最基础的查询增强技术,对用户原始查询进行「字面 / 语义层面的规则化 / 标准化改写」,不引入额外生成内容,仅通过调整查询的表达形式,让其更匹配向量数据库的检索逻辑。
核心实现分为两类,可单独使用或者组合使用:
1.1:基础字面转换:关键词提取、同义词替换、句式规整(口语化的 “咋用这个 API?” 规范化 “如何使用该 API 的具体方法”))、否定词转换( “这个功能不能用的原因” 改成 “这个功能无法使用的原因”);
1.2:语义深度转换:基于大模型的轻量改写**,如查询补全、意图明确化、多义消歧(如把模糊的 “产品性能怎么样?” 结合知识库背景补全为 “XX 型号产品的核心性能参数及实际使用表现如何?”)、多轮对话中的上下文融合(如用户前问 “XX 手机的续航”,后问 “能玩多久游戏?”,自动补全为 “XX 手机的游戏续航时间是多少?”)。
整体流程:原始查询 → 转换规则 / 大模型轻量改写 → 生成 1~3 个优化查询 → 用优化查询进行向量检索
解决的 AI 领域问题:
聚焦解决 用户提问的「表达层面缺陷」 导致的检索问题:用户口语化 / 不规范提问导致的检索失配、用户提问简洁 / 模糊导致的关键词缺失、多义词汇导致的检索歧义、多轮对话中的上下文割裂、向量检索的「关键词稀疏」问题
代码落地:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# 定义Query Transformations的提示词模板:明确改写要求(规范化、补全意图、无冗余)
qt_prompt = PromptTemplate(
input_variables=["original_query"],
template="""请你将用户的原始查询改写为**书面化、规范化、意图明确**的检索查询,要求:
1. 保留原始查询的核心意图,不新增无关内容;
2. 若查询模糊/简洁,补全核心主体和关键维度(基于RAG和AI技术背景);
3. 口语化查询改为书面化,去除语气词和无意义词汇;
4. 输出仅保留改写后的查询,无需额外解释。
原始查询:{original_query}
改写后的查询:"""
)
# 构建查询改写链
qt_chain = LLMChain(llm=llm, prompt=qt_prompt)
# 核心查询转换函数
def query_transformations(original_query):
# 调用大模型生成优化查询
optimized_query = qt_chain.run(original_query).strip()
print(f"原始查询:{original_query}")
print(f"优化查询:{optimized_query}\n")
return optimized_query
# 测试
if __name__ == "__main__":
original_query = "咋用自注意力机制?" # 口语化模糊查询
optimized_query = query_transformations(original_query)
# 用优化查询检索知识库
results = retrieve_knowledge(optimized_query)
print("检索结果:")
for doc in results:
print(f"- {doc.page_content}")
关键细节 & 扩展:
(1)多查询生成:若想提升召回率,可修改提示词让大模型生成2~3 个不同角度的优化查询,分别检索 后融合结果(如生成3个不同的优化查询,用换行分隔);
(2)上下文融合:多轮对话场景下,在提示词中加入chat_history输入变量,让改写时融合历史对话(如结合历史对话:{chat_history},改写原始查询:{original_query});
(3)规则式补充:可叠加jieba关键词提取、synonyms同义词替换(如pip install synonyms),实现「规则 + 大模型」的混合改写,降低大模型调用成本
**测试输出示例:**
原始查询:咋用自注意力机制?
优化查询:如何使用Transformer的自注意力机制?
检索结果:
- Transformer的自注意力机制能并行计算,提升模型训练效率,分为多头注意力和单头注意力。
- 多头注意力将特征拆分为多个头,分别计算注意力,能捕捉不同维度的语义信息。
2、HyDE(Hypothetical Document Embedding)实现
通过大模型生成「与用户查询匹配的假设性文档」,用「假设文档的向量」替代「原始查询的向量」进行检索,核心是「以文档级的语义内容,补全用户查询的语义信息」,让检索从「查询向量匹配」升级为「文档级语义匹配」
核心流程:输入用户原始查询(无需复杂改写)、调用大模型生成 1~2 篇与查询高度相关的「假设性文档」、将假设性文档通过嵌入模型转化为向量(而非原始查询)、用该向量在知识库中进行相似性检索,匹配真实的文档块
具体实际应用举例:
案例 3:场景化简单查询 —— 带轻微口语化的短查询
**原始查询**
**咋用Basic RAG解决幻觉(口语化,核心意图是「Basic RAG 解决大模型幻觉的方法」)**
HyDE 生成的假设文档(先规范化意图,再生成事实性内容):
Basic RAG 即基础检索增强生成,是 RAG 技术的基础实现架构,核心用于解决大模型的幻觉问题和知识时效性问题。该技术通过文档向量化入库、用户查询向量化、相似性检索、上下文拼接生成的四步核心流程,让大模型的回答基于真实的知识库内容,而非凭空生成,从而从根源上降低大模型无依据回答的概率,是解决大模型幻觉问题的低成本、 高效的基础方案。
匹配逻辑:
假设文档先将口语化查询规范化为「Basic RAG 解决大模型幻觉的原理」,再覆盖「Basic RAG 的简称、核心 价值、四步流程、解决幻觉的核心逻辑」,和你知识库中1 条核心内容完全匹配,
检索时精准召回:
Basic RAG 的核心流程是文档向量化、查询检索、上下文拼接、大模型生成,解决大模型幻觉问题。
解决的AI领域问题:
(1)短查询 / 抽象查询的语义信息不足导致的检索精度低(如:自注意力机制、大模型幻觉)
(2)传统查询向量检索的「语义鸿沟」 问题:用户查询和知识库文档的文本形式差异大(如查询是 “原理”,知识库是 “具体实现步骤”)
(3)低资源领域的检索召回率低问题:在垂直小众领域(如某专业技术、小众行业),知识库的文档量少,直接用短查询检索容易漏检
(4)补充:间接降低大模型幻觉:由于 HyDE 能让检索到的知识库内容更贴合用户意图,大模型生成回答时的上下文更精准,从而间接减少因 “检索内容不相关” 导致的幻觉
与 Query Transformations 的核心差异
• Query Transformations:改写查询,输出的还是「查询」(短文本),仅优化表达,不扩充新的语义概念;
• HyDE:生成文档,输出的是「文档」(长文本),不仅优化表达,还会基于查询生成相关的语义概念、细节,扩充语义信息。
核心代码实现:
from langchain.retrievers import HyDERetriever
# 核心:初始化HyDE检索器(封装了「生成假设文档+向量化+检索」全流程)
hyde_retriever = HyDERetriever.from_llm(
retriever=retriever, # 基础检索器(复用之前的Chroma检索器)
llm=llm, # 生成假设文档的大模型
prompt=None, # 用默认提示词,也可自定义(见扩展)
document_prompt=None
)
# HyDE核心函数:输入原始查询,返回基于假设文档的检索结果
def hyde_retrieve(original_query):
print(f"HyDE原始查询:{original_query}\n")
# 内部流程:生成假设文档→向量化假设文档→检索→返回结果
results = hyde_retriever.get_relevant_documents(original_query)
return results
# 测试
if __name__ == "__main__":
original_query = "自注意力机制" # 短查询/抽象查询(HyDE的适配场景)
results = hyde_retrieve(original_query)
print("HyDE检索结果:")
for doc in results:
print(f"- {doc.page_content}")
关键细节扩充:
自定义假设文档提示词:若默认提示词不贴合你的业务场景(如金融、法律),可自定义 PromptTemplate,指定假设文档的长度、风格、领域:
from langchain.prompts import PromptTemplate
# 自定义HyDE提示词:生成金融领域的假设文档,长度200字内
hyde_prompt = PromptTemplate(
input_variables=["question"],
template="""请你基于金融领域知识,生成一篇与问题高度相关的假设性文档,要求:
1. 内容贴合问题意图,仅包含相关事实性信息;
2. 长度控制在200字以内,逻辑连贯;
3. 输出仅保留文档内容,无需额外解释。
问题:{question}
假设文档:"""
)
# 初始化时传入自定义prompt
# hyde_retriever = HyDERetriever.from_llm(retriever=retriever, llm=llm, prompt=hyde_prompt)
3、HyPE (Hypothetical Prompt Embedding,假设提示嵌入)实现
HyDE 的进阶优化版本,核心是「将 HyDE 的「假设文档」升级为「假设提示词」,用「假设提示词的向量」进行检索」; 假设提示词的格式为「问题 + 预期的回答框架 / 关键信息维度」
核心流程: 输入用户原始查询、调用大模型生成贴合 RAG 场景的「假设提示词(Hypothetical Prompt)」,而非无差别的假设文档、将假设提示词通过嵌入模型转化为向量、用该向量在知识库中检索,匹配真实文档块
举例说明HyDE→ HyPE的区别:
原始查询:自注意力机制 (短词语/单概念)
HyDE 输出:无结构假设文档(连贯长文本)
自注意力机制是 Transformer 模型的核心组成部分,是实现模型并行计算的关键技术,区别于传统的循环注意力机制。该机制能让模型在处理序列数据时,自主关注输入序列的不同位置信息,捕捉数据之间的语义关联。自注意力机制主要分为单头注意力和多头注意力两种形式,其中多头注意力会将特征拆分为多个头分别计算注意力,能更好地捕捉不同维度的语义信息,提升模型的特征提取能力。
HyPE 输出:结构化假设提示词(问题 + 明确维度)
问题:什么是 Transformer 的自注意力机制?;回答需要包含:1. 自注意力机制的核心定位 2. 自注意力机制的核心作用 3. 自注意力机制的主要分类 4. 不同分类的功能差异
解决的AI领域问题:
在 HyDE 解决「语义信息缺失」的基础上,进一步优化检索结果与「大模型生成环节」的适配性;
解决HyDE 生成的假设文档冗余 / 偏离导致的检索偏差、检索结果与大模型生成需求的「适配鸿沟」、抽象 / 复杂问题的多层语义匹配问题、提升检索的「精准性 - 全面性」平衡
核心代码实现:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# 定义HyPE的提示词模板:生成「问题+结构化回答框架」的假设提示词
hype_prompt = PromptTemplate(
input_variables=["original_query"],
template="""请你基于AI和RAG技术背景,为用户查询生成**假设性提示词**,格式为「问题:XXX;回答需要包 含:1.XXX 2.XXX 3.XXX」,要求:
1. 问题部分保留原始查询的核心意图,书面化表达;
2. 回答框架列出3~5个关键维度,是解答该问题的核心要点,不冗余;
3. 仅输出假设性提示词,无需额外解释。
原始查询:{original_query}
假设性提示词:"""
)
# 构建假设提示词生成链
hype_chain = LLMChain(llm=llm, prompt=hype_prompt)
# HyPE核心函数:生成假设提示词→用提示词检索
def hype_retrieve(original_query):
# 步骤1:生成结构化假设提示词
hypothetical_prompt = hype_chain.run(original_query).strip()
print(f"HyPE原始查询:{original_query}")
print(f"假设性提示词:{hypothetical_prompt}\n")
# 步骤2:用假设提示词做检索(核心:用提示词的向量替代原始查询)
results = retrieve_knowledge(hypothetical_prompt)
return results
# 测试
if __name__ == "__main__":
original_query = "怎么用HyDE优化RAG?" # 复杂问题/方案类问题(HyPE的适配场景)
results = hype_retrieve(original_query)
print("HyPE检索结果:")
for doc in results:
print(f"- {doc.page_content}")
4、实际项目使用时如何选择查询增强技术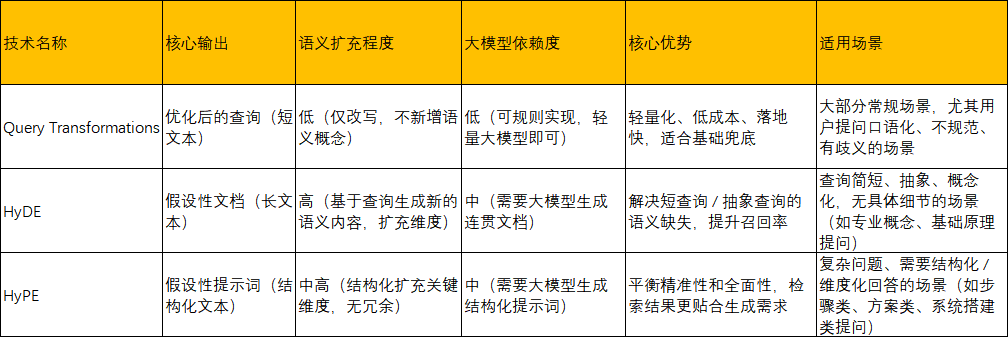
选型原则:
4.1:基础兜底:所有 RAG 系统都应先实现Query Transformations,作为查询增强的基础,低成本解决 80% 的常规检索失配问题;
4.2:进阶优化:在 Query Transformations 的基础上,对短查询 / 抽象查询场景叠加HyDE,对复杂 / 结构化问题场景叠加HyPE;
4.3:混合使用:实际开发中可采用「混合检索策略」—— 同时用 Query Transformations 的优化查询、HyDE/HyPE 的生成内容做向量检索,将所有检索结果融合后重排序,进一步提升效果(成本略有上升,但效果最优)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)