AI核心知识73——大语言模型之Shared Vector Space(简洁且通俗易懂版)
共享的向量空间是多模态 AI 能够“看图说话”的根本数学基石。它构建了一个宇宙通用的概念层,将文字、图片、声音等不同形式的数据统一放入同一个坐标系。在这个空间里,核心规则是“含义相同,坐标必近”,不再区分数据形式。这一过程通常通过“对齐”(如 CLIP 模型的训练)实现,让图像特征与文字特征一一对应。正是有了这个 AI 世界的“巴别塔”,才实现了以文搜图、跨语言迁移和 AI 绘画等“魔法”,打破了
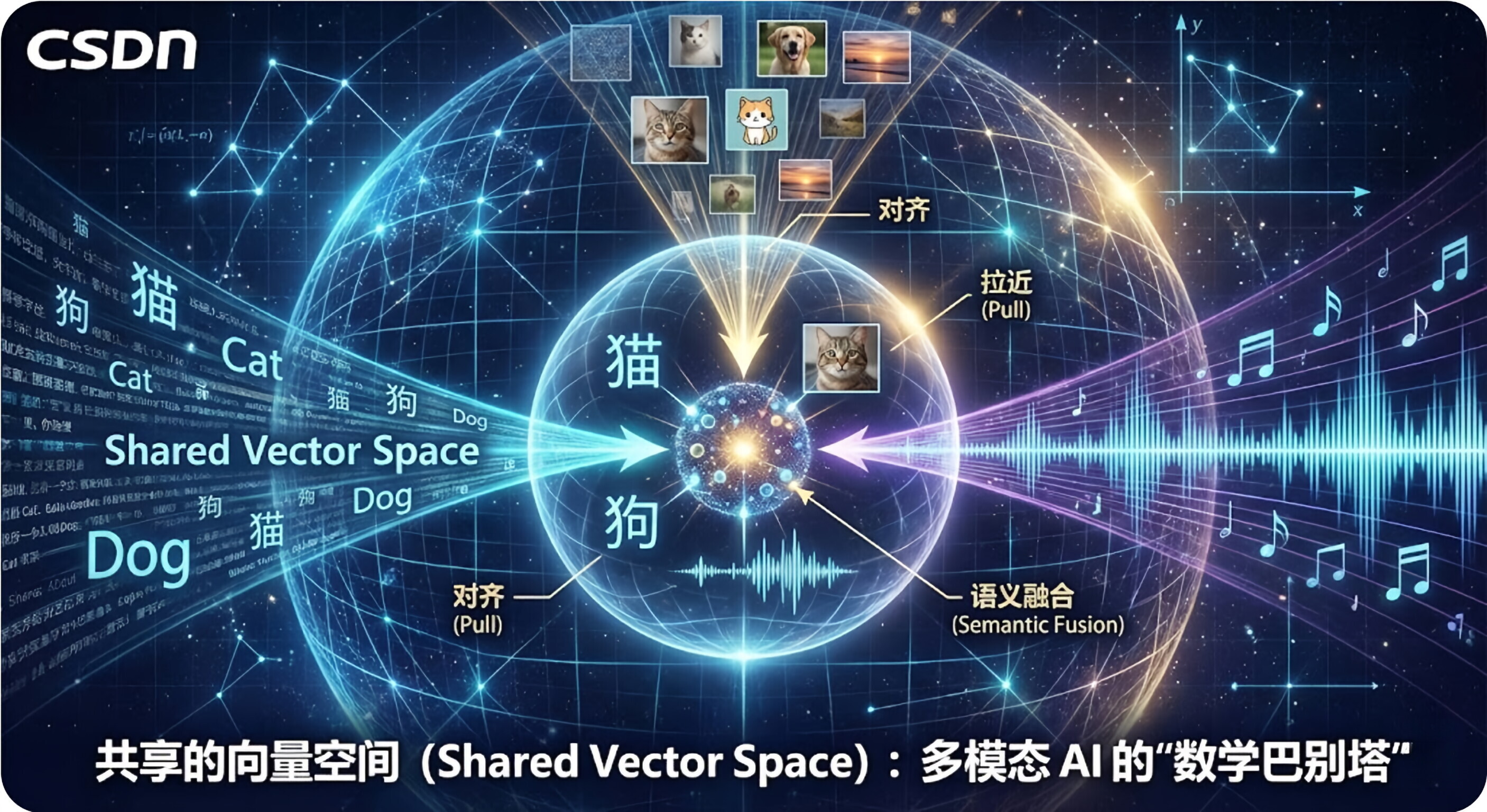
共享的向量空间 (Shared Vector Space) 是多模态大模型能够“看图说话”、“听音画图”或者“跨语言思考”的根本数学基础。
如果说 Embedding 是把一种数据(比如文字)变成了坐标;
那么 共享的向量空间 就是把文字、图片、声音都扔进同一个坐标系里,并且强制要求:意思相同的东西,不管它是什么形式,坐标必须靠在一起。
1.🌌 核心比喻:宇宙通用的概念层
想象一个巨大的“概念宇宙” (这就是向量空间)。
-
以前(独立空间):
-
文字模型有一个自己的宇宙。里面有“猫”字。
-
视觉模型有一个自己的宇宙。里面有“猫的照片”。
-
问题:这两个宇宙是不通的。计算机不知道“猫”这个字和“猫的照片”是同一回事。
-
-
现在(共享空间):
-
我们强行把它们拉到同一个宇宙里。
-
我们定下一条死规矩:只要是代表“毛茸茸、会喵喵叫的动物”,无论是汉字“猫”、英文“Cat”、还是“一张猫的照片”,它们的坐标必须无限接近。
-
结果:在这个空间里,数据不再区分形式,只区分含义 (Semantics)。
-
2.🔗 它是怎么做到的?(对齐/Alignment)
建立这个空间的过程,通常被称为对齐 (Alignment)。最著名的案例是 OpenAI 的 CLIP 模型。
它的训练方法简单而暴力:
-
输入:给模型看几亿对图片和文字(比如一张狗的照片,下面写着“一只可爱的狗”)。
-
拉近 (Pull):告诉模型,“把这张照片的向量和这就话的文字向量,在空间里往一块拉!”
-
推远 (Push):同时,把这张“狗的照片”和文字“香蕉”,在空间里狠狠地推开!
经过亿万次的训练,模型终于悟了:原来图像的特征和文字的特征,是可以一一对应的。
3.🛠️ 共享空间能干什么?
一旦建立了共享向量空间,魔法就发生了:
A. 以文搜图 (Text-to-Image Search)
-
用户搜:“海边的落日”。
-
计算机:先把“海边的落日”变成向量V_text。
-
搜索:在数据库里找哪张图片的向量 V_image 离 V_text 最近。
-
结果:哪怕那张照片没有任何标签,计算机也能把它找出来,因为在空间里,它们挨在一起。
B. 跨语言迁移 (Cross-Lingual Transfer)
-
现象:你用大量的英文数学题训练模型,结果发现它的中文数学能力也变强了。
-
原因:因为在共享空间里,英文的 "Equation" 和中文的 "方程" 指向同一个位置。模型在这个位置学到的解题逻辑,对两种语言都有效。
C. 生成图片 (Midjourney / Stable Diffusion)
-
原理:这些画图 AI 的第一步,就是利用共享空间,把你的文字描述(Prompt)映射到一个具体的数学位置,然后解码器从这个位置“还原”出像素图像。
4.🧬 与“原生多模态”的关系
-
非原生的模型(如早期版本):往往是先把图片映射到共享空间,翻译成近似的文字向量,再喂给语言模型。
-
原生的模型(如 GPT-4o):它的共享空间融合得更彻底。它的内部参数不仅仅是对齐,而是交织 (Interleaved)。
总结
共享的向量空间就是 AI 世界的“巴别塔” 。
它打破了语言、图像、声音之间的隔阂,把世间万物都统一成了数学坐标。
正因为有了这个共享空间,AI 才能看着你的照片写诗,听着你的声音画画。它是连接数字世界与物理世界的通用接口。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)