AI-大语言模型LLM-Transformer架构6-输出层
本文介绍了Transformer架构中的输出层部分,主要包括Linear层和Softmax层。Linear层是一个简单的单层感知机,负责将解码器输出的语义向量映射回词表空间,与编码器的Embedding层作用相反。Softmax层则将Linear输出的词得分向量转换为概率分布,通过指数归一化处理实现数值稳定性,最终选择概率最大的词作为输出。这两层共同完成了从语义表示到具体词汇的转换过程,是Tran
目的
为避免一学就会、一用就废,这里做下笔记
说明
- 本文内容紧承前文-Transformer架构1-整体介绍、Transformer架构5-残差连接与前馈网络,欲渐进,请循序
- 本文重点介绍Transformer架构中的最后一部分-输出层
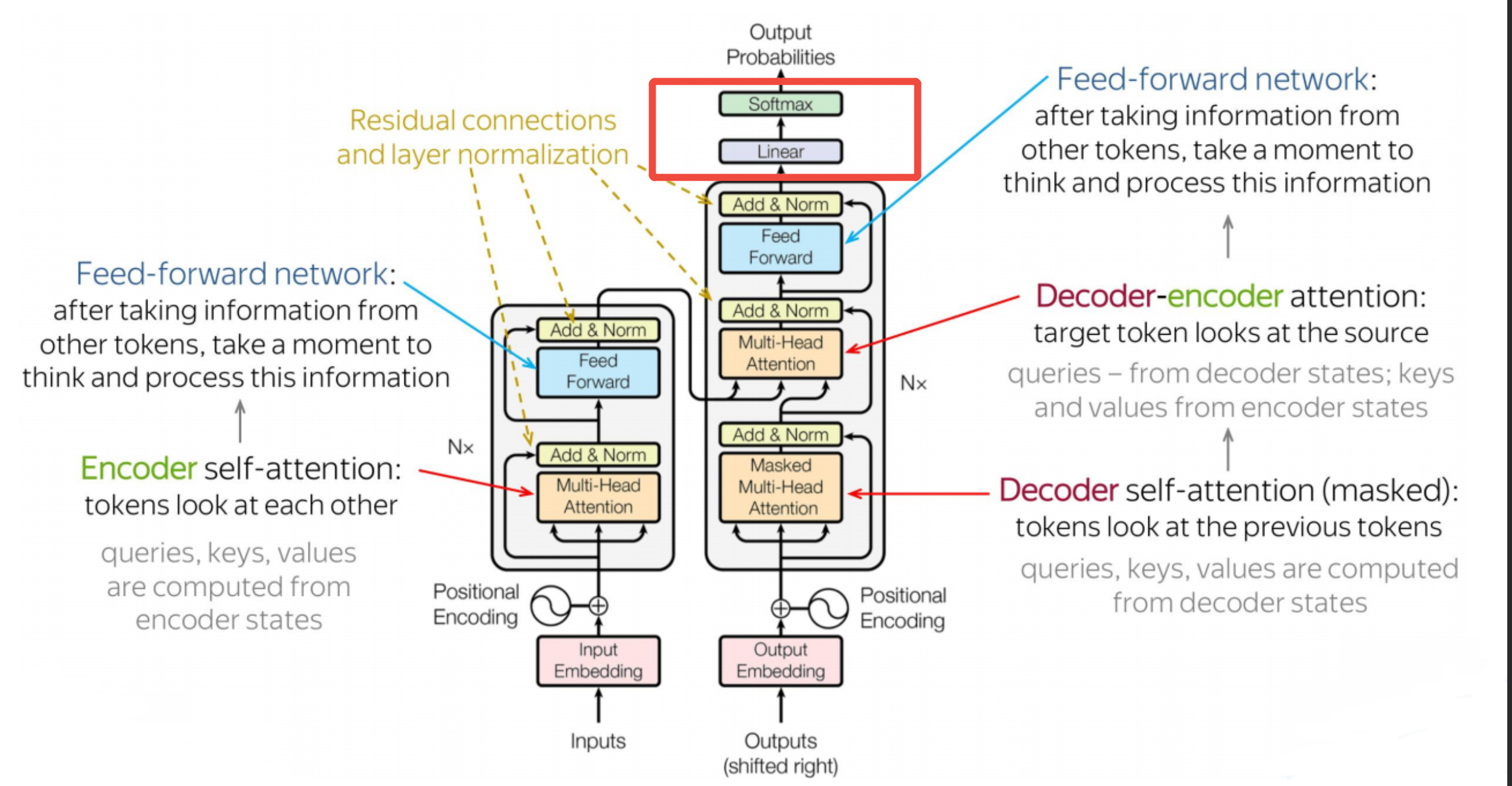
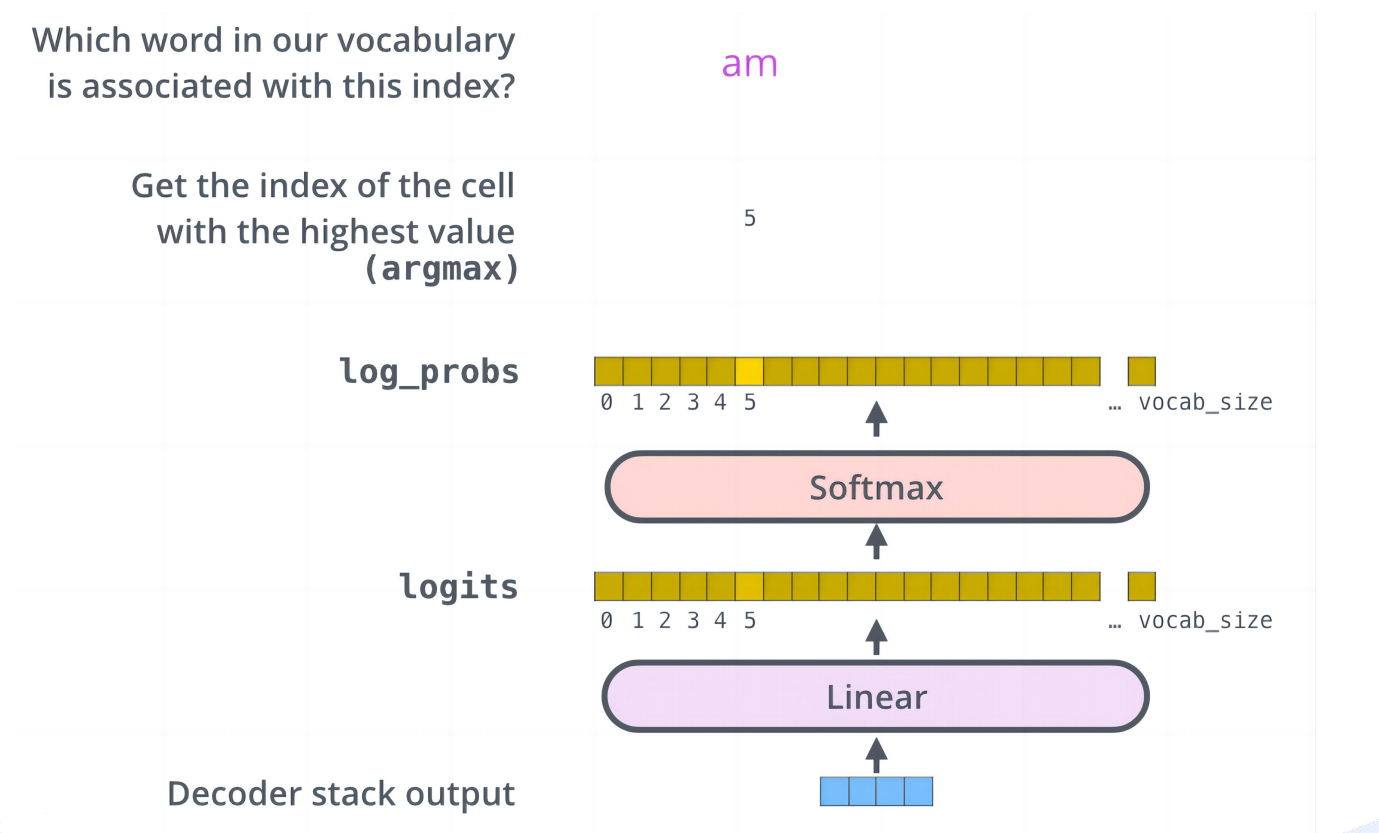
一、输出层1-Linear
是什么
-
Linear也是一种前馈神经网络,但相比Transformer内部的多层非线性神经网络(多层感知机),Linear没有隐藏层和激活函数,是一种简单的线性神经网络(单层感知机)
-
Linear的作用: 将解码器的输出矩阵Z从语义空间映射到词表空间。这和编码器堆栈中Embedding的作用恰好相反:
- Embedding:词表数据 -> 向量数据
- Linear:向量数据 -> 词表数据
为什么
为什么用这种简单的单层感知机?
要实现将解码器的输出矩阵Z从语义空间映射到词表空间,使用点积进行相似度计算: h ⋅ w i h · w_i h⋅wi 已足够。
对照理解,是不是Embedding也是一个单层感知机
是的,Embedding的数学本质
# Embedding 操作:one-hot词向量 → 稠密的语义向量
# 输入:one-hot 向量 e_i = [0,...,1,...,0]
# 操作:v = E^T · e_i (这里的E是嵌入层的参数矩阵)
# 输出:词向量 v = E[i] (第 i 行,v的形状和E相同)
Linear的数学本质
# Linear 操作:稠密的语义向量 → one-hot词得分向量
# 输入:解码器输出的语义向量 x
# 操作:y = W · x + b
# 输出:one-hot词得分向量
二、输出层2-Softmax
什么是Softmax
- Softmax是一种将实数向量转换为概率分布的函数,它是深度学习和机器学习中最重要的激活函数之一,常用于多分类。
- Softmax层就是利用该函数,将Linear层输出的one-hot词得分向量转化为one-hot词概率向量。最后应用层将这个one-hot词概率向量转化成具体的词输出(取概率最大的那个词ID,然后映射成词)
Softmax的数学公式
基础版本(学习理解使用):
对于输入向量 z = [z₁, z₂, …, zₙ],softmax 定义为:
Softmax ( z i ) = e z i ∑ j = 1 n e z j 对 i = 1 , 2 , . . . , n \text{Softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{n} e^{z_j}} \quad \text{对 } i = 1, 2, ..., n Softmax(zi)=∑j=1nezjezi对 i=1,2,...,n
数值稳定版本(实际使用):
Softmax ( z i ) = e z i − max ( z ) ∑ j = 1 n e z j − max ( z ) \text{Softmax}(z_i) = \frac{e^{z_i - \max(z)}}{\sum_{j=1}^{n} e^{z_j - \max(z)}} Softmax(zi)=∑j=1nezj−max(z)ezi−max(z)
输出特性:所有输出值 ∈ [0, 1],且总和为 1,形成概率分布。
为什么用Softmax函数
因为深度学习本质上是学习一个从输入到概率分布的映射,而 softmax 提供了一个可微的、数值稳定的、符合概率公理的方式来做这件事。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)