别再让你的AI“一本正经地胡说八道“!RAG技术让你模型知识更新快人一步,小白也能秒懂!
文章介绍了RAG(检索增强生成)技术,通过外部知识库检索增强模型回答,解决大模型知识更新慢、易产生幻觉和无法处理私有数据的问题。RAG分为数据准备(文本分割、向量化、存入向量数据库)和检索生成(问题向量化、检索、增强、生成)两个阶段。文章探讨了RAG的优势与挑战,并介绍了高级RAG技术中的摘要索引优化方法。
一、RAG
1.1 简介
RAG (Retrieval-Augmented Generation),即“检索增强生成”,是目前大模型(LLM)落地应用中最主流的技术方案。它解决了大模型知识更新慢、容易产生“幻觉”以及无法掌握私有数据的问题。
大模型虽然聪明,但它的知识停留在他训练的那一刻。如果问它昨天的新闻或公司的内部文件,它就会胡编乱造。RAG 的做法是:在模型回答之前,先去外部知识库里“翻书”查阅资料,把查到的内容喂给模型,让它参考这些资料来写答案。
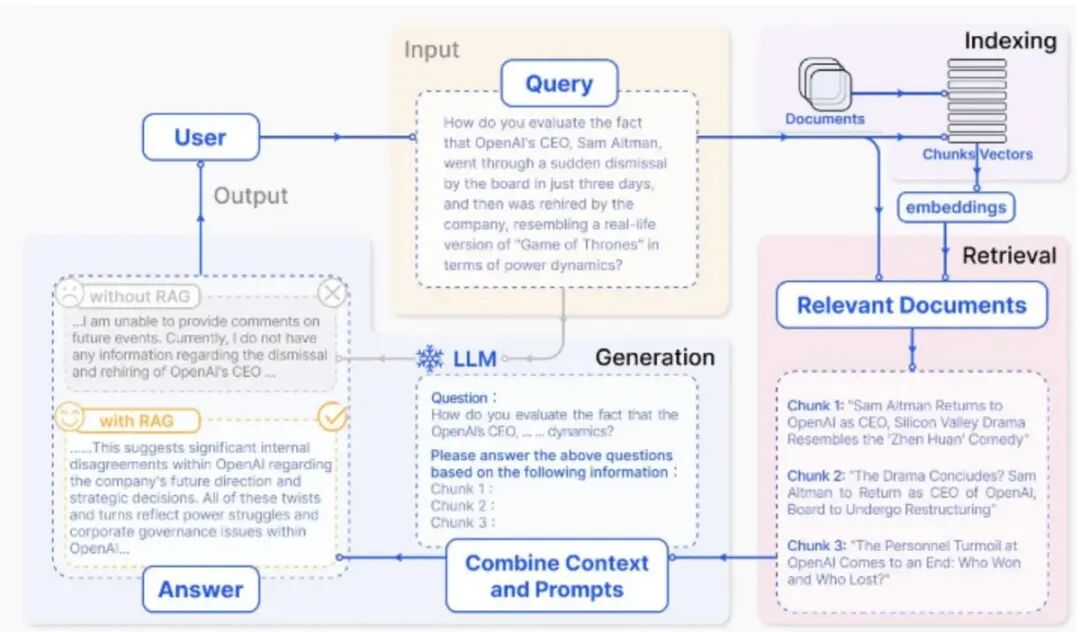
image.png
参考文档:https://datawhalechina.github.io/all-in-rag/#/
1.2 核心思想
RAG 的核心思想可以理解为:“开卷考试”。
- 传统生成: 闭卷考试,全凭记忆,记错或没学过就乱写。
- RAG: 开卷考试,遇到问题先在资料堆里找相关段落,然后根据这些段落组织语言回答。
1.3 实现原理
实现 RAG 通常分为两个阶段:数据准备(离线) 和 检索生成(在线)。
A. 数据准备阶段(把书存进库里)
- 文本分割 (Chunking): 把长文档切成一小段一小段(比如每段 500 字)。
- 向量化 (Embedding): 利用向量模型把这些文本片段向量化。
- 存入向量数据库: 把这些向量存到向量数据库,方便以后进行快速的相似度搜索。
B. 检索生成阶段(查书并回答)
- 问题向量化: 把用户的提问使用相同的向量模型转换成向量。
- 检索 (Retrieve): 在数向量据库里检索和问题向量相似的文本片段(欧氏距离或余弦距离)。
- 增强 (Augment): 把找出来的片段和原始问题拼接在一起,组成一个提示词(Prompt)。
- 生成 (Generate): 把这个提示词发给 LLM,模型根据参考资料输出最终答案。
1.4 优势
- 准确性高: 所有的回答都有据可查,显著降低幻觉。
- 实时性强: 只要更新数据库,模型就能掌握最新信息,无需重新训练模型。
- 成本低: 相比于微调(Fine-tuning)模型,RAG 的部署和维护成本极低。
- 隐私保护: 敏感数据可以留在本地数据库,只在需要时提供给模型参考。
1.5 挑战
虽然原理简单,但在实际应用中仍面临难题:
- 检索不到: 数据库里有,但没搜出来。
- 检索不准: 搜出来很多无关信息。
- 整合能力差: 模型拿到了资料,但没理解好,或者忽略了关键信息。
二、高级RAG
当前RAG所存在的问题,成为很多企业或开发者的痛点,为了解决这些痛点,于是出现了多种方式来优化RAG。在优化的阶段,主要包括:预检索阶段、检索阶段、后检索阶段。
- 预检索优化(Pre-Retrieval)
预检索优化是指在检索之前的环节进行优化,在预检索优化中存在如下方法:
1.1 摘要索引
-
简介:
摘要索引 (Summary Index) 是 RAG 架构中一种旨在优化检索效率和准确性的索引策略。它不直接检索原始文本块,而是通过对文档内容进行预处理,生成“摘要”并以此为核心进行检索。
在标准 RAG 中,如果文档非常长且细节繁琐,直接检索原始切片(Chunks)容易导致信息支离破碎或检索不到位。
摘要索引的做法是:先为每个文档(或文档的大段落)生成一段精炼的摘要,并为摘要建立索引。检索时,系统先匹配摘要,确定相关文档后,再深入该文档获取细节。
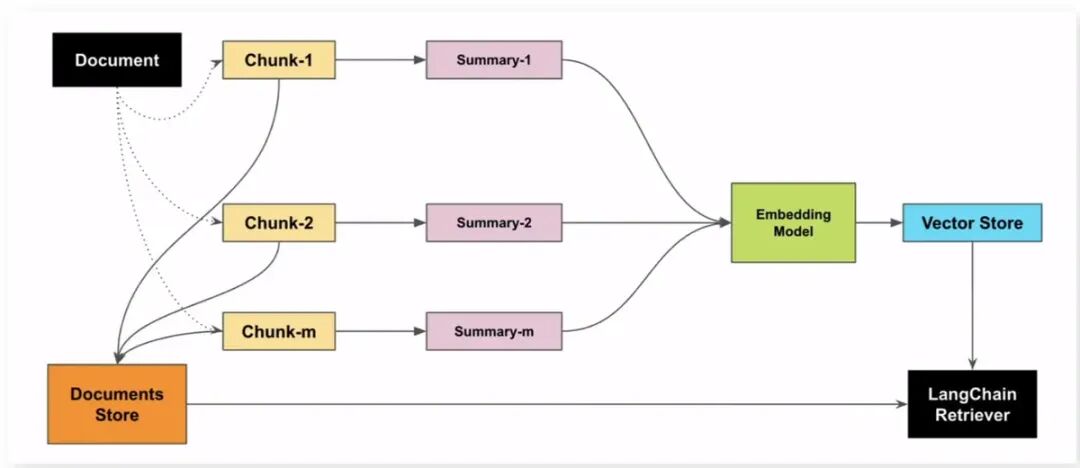
image.png
-
核心思想:
摘要索引的核心思想是 “由简入繁,层级定位”:
- 语义提炼: 原始文本可能包含大量噪音,摘要保留了核心语义,降低了向量检索的干扰。
- 全局映射: 摘要作为一个“锚点”,代表了背后一整块或一整篇文档的含义,解决了“只见树木不见森林”的问题。
- 多层级检索: 通过建立“摘要 -> 原始文本”的映射关系,实现从宏观意图到微观细节的精准导航。
-
实现原理:
实现摘要索引通常分为以下几个步骤:
A. 文档拆分与总结 (Summarization)
B. 构建索引 (Indexing)
C. 检索流程 (Retrieval)
D. 答案生成 (Generation)
LLM 结合这些经过筛选的、高度相关的原始文本片段生成答案。
-
第一阶段(摘要检索): 用户提问后,系统在“摘要库”中寻找最匹配的摘要。
-
第二阶段(上下文提取): 一旦命中某个摘要,系统会自动提取出该摘要关联的所有原始文本片段(或更细小的切片)。
-
向量化摘要: 仅对生成的“摘要文本”进行 Embedding(向量化)并存入向量数据库。
-
建立链接: 在数据库中建立父子关系,即:
摘要 ID -> 原始文本块 IDs。 -
将长文档拆分为较大的语义单元(如章节、页面组)。
-
利用 LLM 为每个语义单元生成一段简短的摘要。
-
关键点: 摘要中通常会保留文档中的核心关键词、实体和主要观点。
-
优势:
摘要索引是构建层级化 RAG 的基础。它像是一本书的“详细目录”,让 AI 能够先看目录确定位置,再翻到具体页面读细节,从而大大提升了处理长文档时的检索成功率,而且信噪比极高。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献611条内容
已为社区贡献611条内容

所有评论(0)