从 OCR 到多模态 VLM Agentic AI:智能文档问答的范式转移全解
传统的 OCR 正在沦为历史。本文将带你深度复盘智能文档处理技术的演进:从 Tesseract 到 PaddleOCR,从布局检测再到基于 VLM 智能体的端到端解析,更附带了基于 AWS Serverless 与 LandingAI ADE API 的生产级代码实现。
目录
阶段一:Tesseract 规则匹配到 PaddleOCR 深度学习
在 OCR 的 1.0 时代,Tesseract 是绝对的主流。它的工作模式非常线性:输入图像,输出纯文本流。开发者面临的最大噩梦是:空间结构丢失。
例如,当面对一张发票时,Tesseract 吐出的是一串没有坐标、没有逻辑顺序的字符。为了提取“Total Amount”,工程师必须编写极度复杂的正则表达式。问题有三:扫描件中的污渍可能导致 $7.95 被识别为 $7.99;简单的正则 Total\s*\$?(\d+) 往往会错误地匹配到 Subtotal 而非最终的 Total,因为在文本流中 Subtotal;对于紧密的表格数据,纯文本流完全丢失了行列对齐信息。
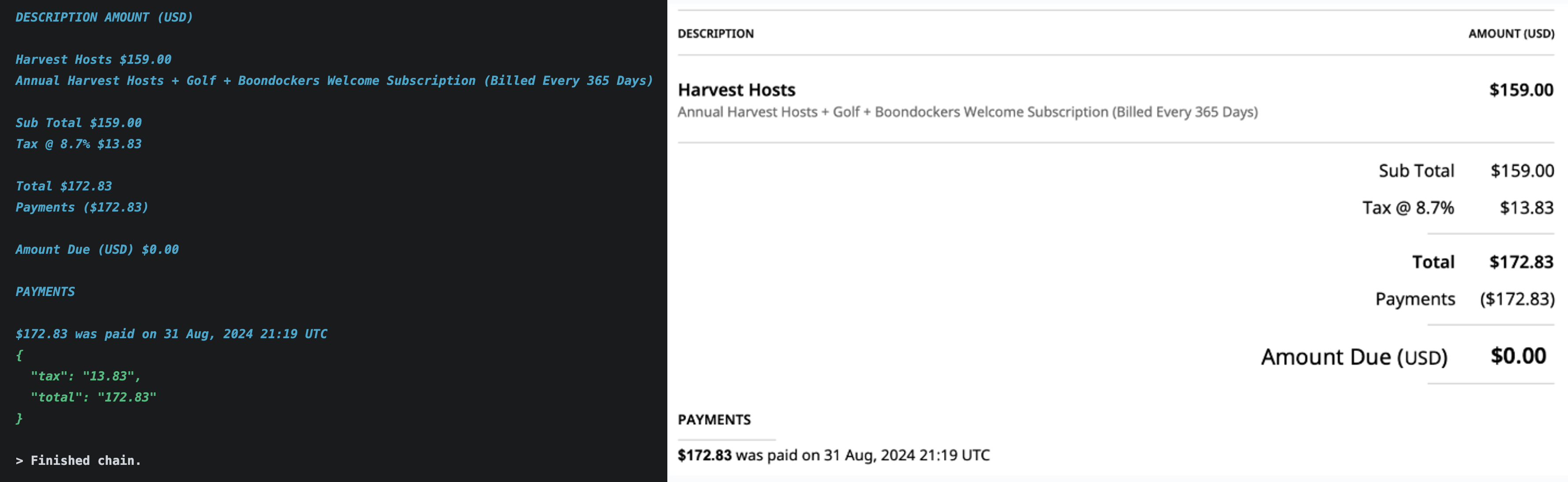
深度学习时代,PaddleOCR 等现代库引入了“检测(Detection)+ 识别(Recognition)”两阶段流程。它不再只是“读字”,而是先用 DBNet 等模型标出文本框,再用 CRNN 等模型识别内容。
from paddleocr import PaddleOCR
ocr = PaddleOCR(lang='en')
# 返回结果包含:文本内容、置信度、以及关键的【坐标框】
result = ocr.predict(image_path)
for line in result[0]:
box, (text, score) = line
# 我们可以根据 box 的 y 坐标判断这是页眉、正文还是页脚
# 我们可以根据 x 坐标判断这是左栏还是右栏
print(f"Text: {text}, Box: {box}, Conf: {score:.2f}")
虽然 PaddleOCR 解决了“看不清”的问题,但它依然不懂“阅读顺序”。例如:
- 学术论文或报纸通常采用双栏排版。PaddleOCR 默认的逻辑是基于图像行的,它会横跨整个页面进行扫描。左栏的句子结尾直接拼上了右栏的句子开头,导致语义崩坏,RAG 系统检索时会检索到错误的上下文。
- 在处理包含技术参数的表格时,PaddleOCR 往往无法理解上下标的视觉含义。例如,表格中的
10^20(10 的 20 次方)识别为1020。在金融或科研领域,这种数据提取错误是不可接受的。 - 面对一张折线图,PaddleOCR 能识别出 X 轴上的年份(2020, 2021)和 Y 轴上的数字。但它只看到了一堆散落的数字和标签。它不知道这是一张“图表”,不知道横轴代表时间,纵轴代表收入。也无法回答“2021年的趋势是上升还是下降?”这类问题,因为对于 OCR 来说,这只是一堆离散的像素点,而不是一个整体的“视觉对象”。

阶段二:Agentic AI 范式
2.1 基于 PaddleOCR 3 的布局检测
首先,在 Agentic AI 的视角下,文档不再是一整块待处理的像素,而是一个由不同语义区域(Semantic Regions)组成的集合。我们的第一步不再是识别文字,而是理解结构。我们需要一个“分拣员”,将文档的不同部分路由给最适合的模型处理:
- 纯文本区域 (Text) → \rightarrow → 交给 OCR 引擎
- 表格区域 (Table) → \rightarrow → 交给表格结构化工具
- 图表/图片区域 (Figure/Chart) → \rightarrow → 交给视觉大语言模型 (VLM)
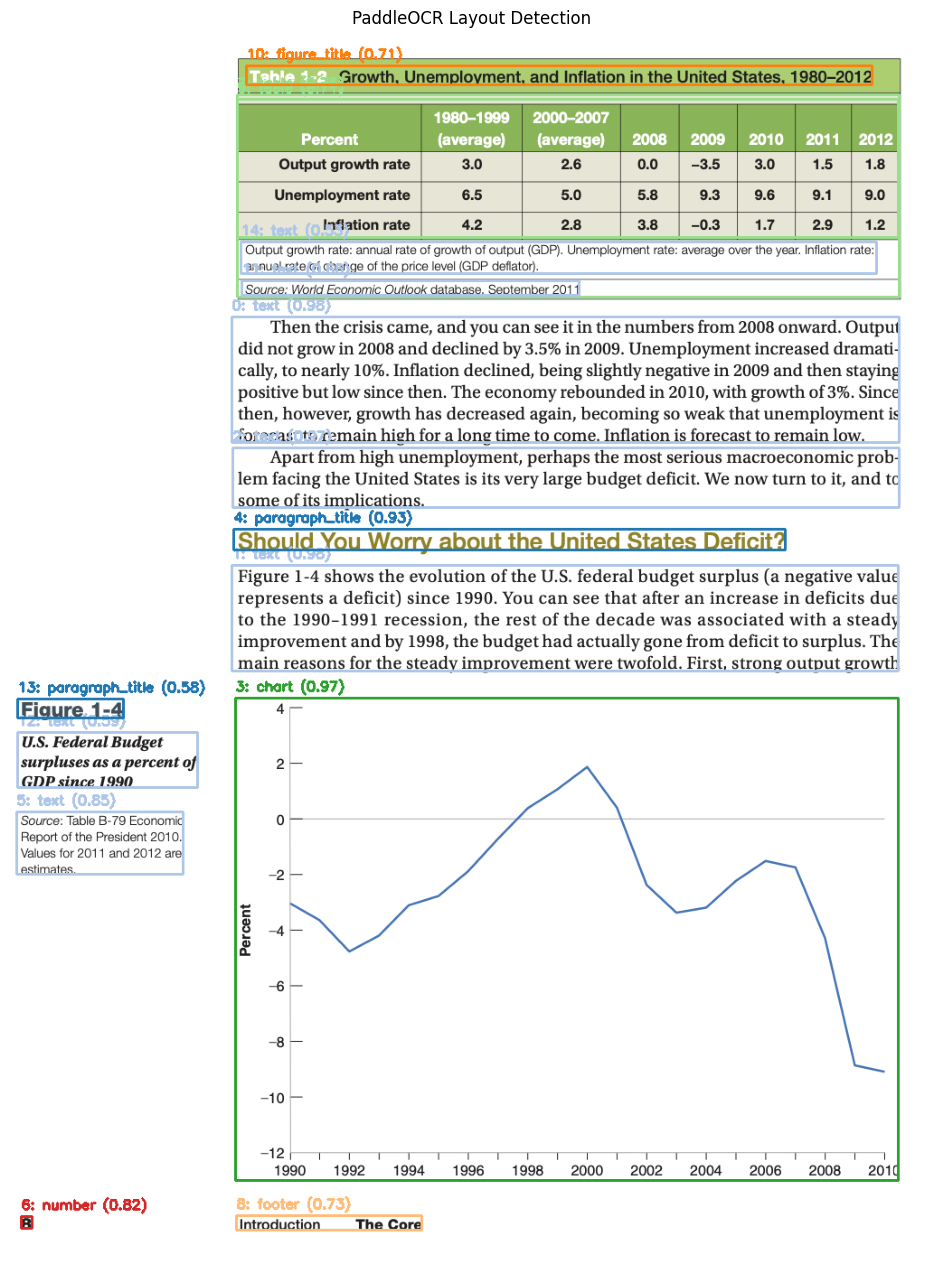
我们使用 PaddleOCR 的 LayoutDetection 模块来实现这一目标。它不仅仅是检测文字,而是对图像中的像素块进行分类。
from paddleocr import LayoutDetection
# 初始化布局检测引擎
layout_engine = LayoutDetection()
def process_document_layout(image_path):
"""
对文档进行布局分析,返回带有分类标签的区域列表。
"""
# 预测布局
layout_result = layout_engine.predict(image_path)
regions = []
# 遍历检测到的每一个框
for box in layout_result[0]['boxes']:
# box['label'] 可能是 'text', 'title', 'table', 'figure', 'footer' 等
regions.append({
'label': box['label'],
'score': box['score'], # 置信度
'bbox': box['coordinate'], # 坐标 [x1, y1, x2, y2]
})
# 按照置信度排序,优先处理高质量区域
regions = sorted(regions, key=lambda x: x['score'], reverse=True)
return regions
2.2 基于 LayoutLM 的阅读逻辑顺序
其次,OCR 最大的痛点之一是阅读顺序(Reading Order)。OCR 引擎通常遵循简单的“从上到下,从左到右”规则。但在双栏排版(Multi-Column)的文档中,这会导致灾难性的后果。为了解决这个问题,需要引入对文档空间结构有理解能力的模型。这里我们使用微软的 LayoutLMv3(通过 LayoutReader 封装)。
def get_reading_order(ocr_regions):
"""
使用 LayoutLMv3 预测人类阅读顺序。
"""
# 1. 计算归一化所需的画布尺寸(基于所有 bbox 的最大边界)
max_x = max_y = 0
for region in ocr_regions:
x1, y1, x2, y2 = region.bbox_xyxy
max_x = max(max_x, x2)
max_y = max(max_y, y2)
# 增加 10% 的 padding 以防止边缘溢出
image_width = max_x * 1.1
image_height = max_y * 1.1
# 2. 坐标归一化 (Normalization)
# 将绝对像素坐标转换为 0-1000 的相对坐标,这是 LayoutLM 的输入标准
boxes = []
for region in ocr_regions:
x1, y1, x2, y2 = region.bbox_xyxy
left = int((x1 / image_width) * 1000)
top = int((y1 / image_height) * 1000)
right = int((x2 / image_width) * 1000)
bottom = int((y2 / image_height) * 1000)
boxes.append([left, top, right, bottom])
# 3. 准备模型输入并推理
inputs = boxes2inputs(boxes)
inputs = prepare_inputs(inputs, layout_model)
# 4. 获取 Logits 并解析排序索引
logits = layout_model(**inputs).logits.cpu().squeeze(0)
reading_order = parse_logits(logits, len(boxes))
return reading_order
拿到 reading_order 索引列表后,我们依据这个逻辑顺序重组 OCR 识别到的文本。这步操作决定了最终喂给 LLM 的 Context 是否通顺。
def get_ordered_text(ocr_regions, reading_order):
"""
根据 LayoutLM 预测的顺序重新排列 OCR 文本块。
"""
# 1. 创建 (reading_position, original_index, region) 元组
indexed_regions = [(reading_order[i], i, ocr_regions[i])
for i in range(len(ocr_regions))]
# 2. 依据 reading_position 进行排序
indexed_regions.sort(key=lambda x: x[0])
# 3. 提取有序文本
ordered_text = []
for position, original_idx, region in indexed_regions:
ordered_text.append({
"position": position,
"text": region.text,
"confidence": region.confidence,
"bbox": region.bbox_xyxy
})
return ordered_text

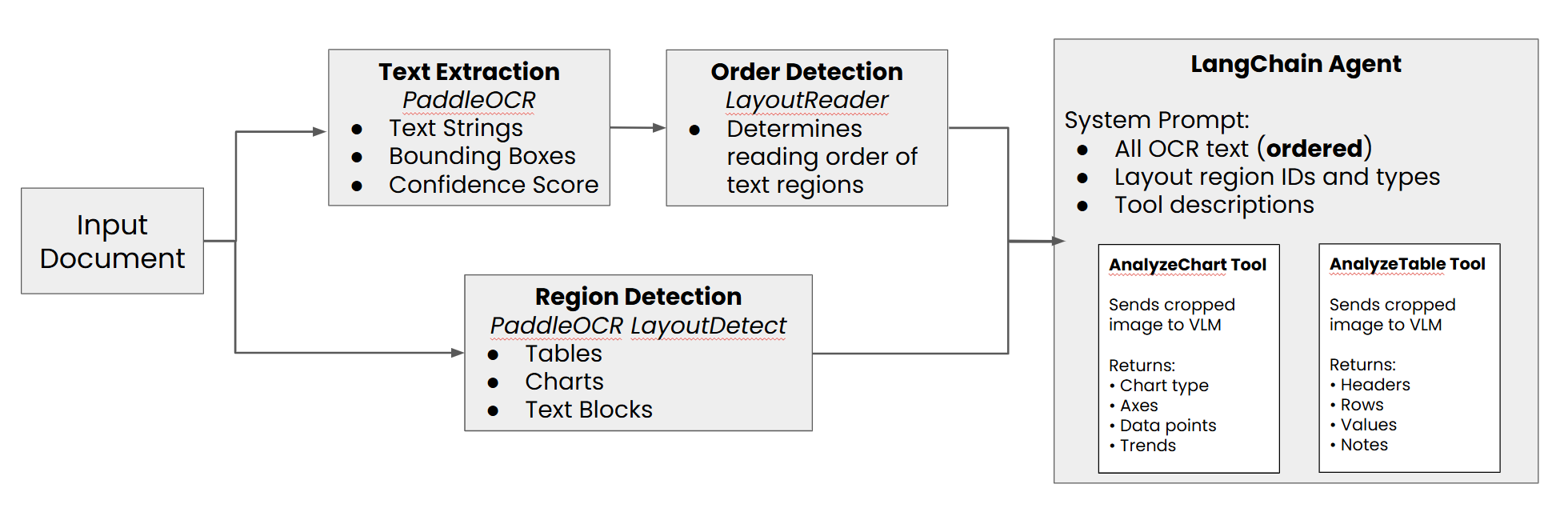
2.3 基于 VLM 工具的 LangChain 智能体
传统 OCR 对非文本信息(如趋势图、饼图、复杂表格)是“盲人摸象”的。因此,需要使 Agent 遇到 Chart 或 Table 类型的区域时触发“视觉感知”能力。
为了让 VLM(如 Qwen-VL 或 GPT-4o)看清楚图表细节,我们不能把整页 PDF 扔进去,那样分辨率会被压缩,且充满干扰。我们必须裁剪出感兴趣的区域(ROI)。

import base64
from io import BytesIO
def crop_region(image, bbox, padding=10):
"""
根据 Bbox 裁剪图像,并添加适当的 Padding 以保留边缘信息。
"""
x1, y1, x2, y2 = bbox
# 确保坐标不越界
x1 = max(0, x1 - padding)
y1 = max(0, y1 - padding)
x2 = min(image.width, x2 + padding)
y2 = min(image.height, y2 + padding)
return image.crop((x1, y1, x2, y2))
我们使用 LangChain 的 @tool 装饰器定义一个工具,我们不仅要求 VLM “描述”图片,更要求它输出结构化的 JSON 数据。
from langchain.tools import tool
@tool
def AnalyzeChart(region_id: int) -> str:
"""
当布局分析标记出 'Chart' 或 'Figure' 区域时调用此工具。
它负责提取趋势、数据点和图例信息。
"""
# 1. 验证区域有效性
if region_id not in region_images:
return f"Error: Region {region_id} not found."
region_data = region_images[region_id]
# 2. 定义结构化 Prompt
# 这里的 Prompt 设计非常关键,明确要求提取哪些维度的信息
CHART_ANALYSIS_PROMPT = """
You are a Chart Analysis specialist. Analyze this chart image and extract:
1. **Chart Type**: (line, bar, scatter, pie, etc.)
2. **Title**: (if visible)
3. **Axes**: X-axis label, Y-axis label, and tick values
4. **Data Points**: Key values (peaks, troughs, endpoints)
5. **Trends**: Overall pattern description (e.g. "steadily increasing")
Return a JSON object with this structure:
```json
{
"chart_type": "...",
"title": "...",
"trends": "...",
"key_data_points": [...]
}
```
"""
# 3. 调用 VLM 进行多模态推理
# 传入 Base64 编码的裁剪图片
result = call_vlm_with_image(region_data['base64'], CHART_ANALYSIS_PROMPT)
return result
这个工具将“非结构化”的像素转换为了“半结构化”的知识。这使得 LLM 可以在后续问答中引用这些数据。
最后,我们将 OCR 文本、布局信息和多模态工具装配到一个 LangChain Agent 中。
# 1. 格式化有序文本 (来自 LayoutLM + OCR)
ordered_text_str = format_ordered_text(ordered_text)
# 2. 格式化布局区域 (来自 LayoutDetection)
layout_regions_str = format_layout_regions(layout_regions)
# 3. 组装 System Prompt
SYSTEM_PROMPT = f"""
You are a Document Intelligence Agent.
You analyze documents by combining OCR text with visual analysis tools.
## Document Text (in reading order)
{ordered_text_str}
## Document Layout Regions
The following regions were detected in the document:
{layout_regions_str}
## Your Tools
- **AnalyzeChart(region_id)**: Use for chart/figure regions...
- **AnalyzeTable(region_id)**: Use for table regions...
## Instructions
1. For TEXT questions, use the extracted text above.
2. For CHART questions, look at the Layout Regions list, find the region_id, and call AnalyzeChart.
"""
当用户提问时,Agent 会进入 ReAct (Reasoning + Acting) 循环:
-
User Input:
"What is the trend of the training cost shown in the chart?" -
Reasoning:
用户问的是图表趋势。我查看 Document Layout Regions,发现 Region #4 是一个 Chart。我应该调用工具。 -
Action:
调用AnalyzeChart(region_id=4)。 -
Observation:
{"chart_type": "bar", "trends": "Training costs have decreased exponentially..."} -
Final Answer:
"According to the chart (Region 4), the training costs show an exponential decrease over time."
2.4 总结
阶段二标志着我们从“数据数字化”迈向了“数据智能化”。通过 PaddleOCR 布局检测,我们把文档切分成了语义块;通过 LayoutLM,我们重建了人类的阅读逻辑;通过 VLM 工具链,我们让 Agent 拥有了“看懂”图表的能力。
阶段三:Agentic Document Extraction
阶段二通过“分治法”(Text/Table/Chart 分类处理)解决了多模态文档的理解问题。然而,这种流水线依然存在割裂感:OCR 负责认字,LayoutLM 负责排序,VLM 负责看图。
LandingAI 的 Agentic Document Extraction (ADE) 代表了文档处理的 3.0 时代。它不再是将多个模型拼凑在一起,而是引入了端到端的 DPT (Document Pre-trained Transformer) 架构。
3.1 核心哲学:Vision-First
传统的文档处理是“自底向上”的:先识别字符,再组词,再组句,最后猜测布局。ADE 采用“自顶向下”的策略。模型 DPT-2 像人类一样,首先看到的是文档的整体视觉语义。
- 例如人力资源流程图,传统的 OCR 会因为空间位置关系(上方的文本未必是逻辑上的前序节点)而导致流程错乱。DPT-2 模型直接理解箭头、连线和框图之间的拓扑关系,将其转化为结构化的 Markdown 描述,而不是单纯的文本流。
- 例如手写医疗表单,勾选框(Checkboxes)、圈选(Circles)以及横跨多栏的手写注释,对于传统 OCR 是噪音,但对于 Vision-First 模型,这些是承载核心语义的视觉元素。
3.2 工程核心:Schema-Driven
我们强类型系统来约束模型的输出,即 Pydantic 库将业务逻辑注入到提取过程中。
假设我们需要处理不同类型的金融单据(W2 税表、银行流水、工资单)。我们不再需要为每种文档训练一个专用模型,而是定义不同的 Schema。
from pydantic import BaseModel, Field
from enum import Enum
from typing import Optional
# 定义文档类型枚举,带有详细的业务描述,帮助模型进行零样本分类
class DocumentType(str, Enum):
W2 = "W2"
PAY_STUB = "pay_stub"
BANK_STATEMENT = "bank_statement"
def describe(self) -> str:
descriptions = {
"W2": "A year-end W-2 form reporting annual taxable wages.",
"PAY_STUB": "A periodic employee earnings statement.",
"BANK_STATEMENT": "A checking or savings account statement."
}
return descriptions[self.value]
# 定义具体的提取结构
class W2Schema(BaseModel):
employee_name: str = Field(..., description="The name of the employee.")
employer_name: str = Field(..., description="The name of the employer.")
# 强制类型转换:直接要求 float,模型会自动处理 "$1,234.56" 这种格式
wages_box_1: float = Field(..., description="Total wages in box 1.")
tax_year: int = Field(..., description="The year of the W2 form.")
# 动态 Schema 生成
from landingai_ade.lib import pydantic_to_json_schema
schema_json = pydantic_to_json_schema(W2Schema)
ADE API 接受 JSON Schema,这意味着我们可以利用 Python 的类型系统来强制执行业务规则。如果模型提取到的年份是 “2023 FY”,Pydantic 验证会失败或者在提示阶段就约束模型只提取整数。
3.3 可解释可信任:Visual Grounding
在 RAG 系统中,最大的痛点是幻觉(Hallucination),用户无法验证真伪。ADE 的 Parse API 并不只返回文本,它返回的是一个包含 Chunk ID 的结构化 Markdown。例如:
- Markdown:
The total revenue was $383 billion [chunk_id: 12-a]. - Chunks Metadata:
{
"id": "12-a",
"text": "$383 billion",
"bbox": [0.45, 0.67, 0.55, 0.69], // 归一化坐标
"page": 12,
"type": "table_cell"
}
这种数据结构允许我们在前端 UI 上实现溯源:用户点击答案,系统直接在原 PDF 的第 12 页高亮显示那个具体的表格单元格。这是建立企业级文档 RAG 信任关键。
AWS Serverless 的事件驱动流水线
在本地跑通 Notebook 是验证原型的第一步,在生产环境中我们还需要处理并发、重试、存储分层和安全性。
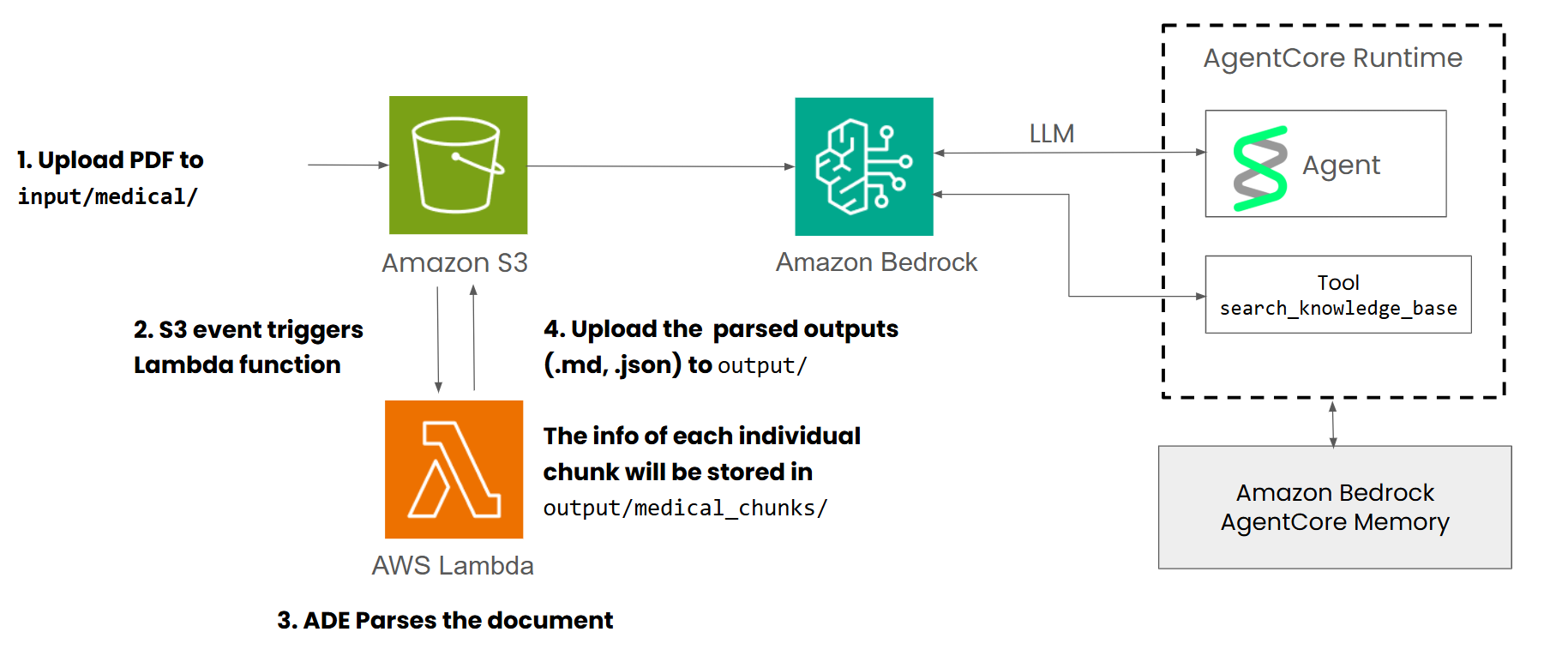
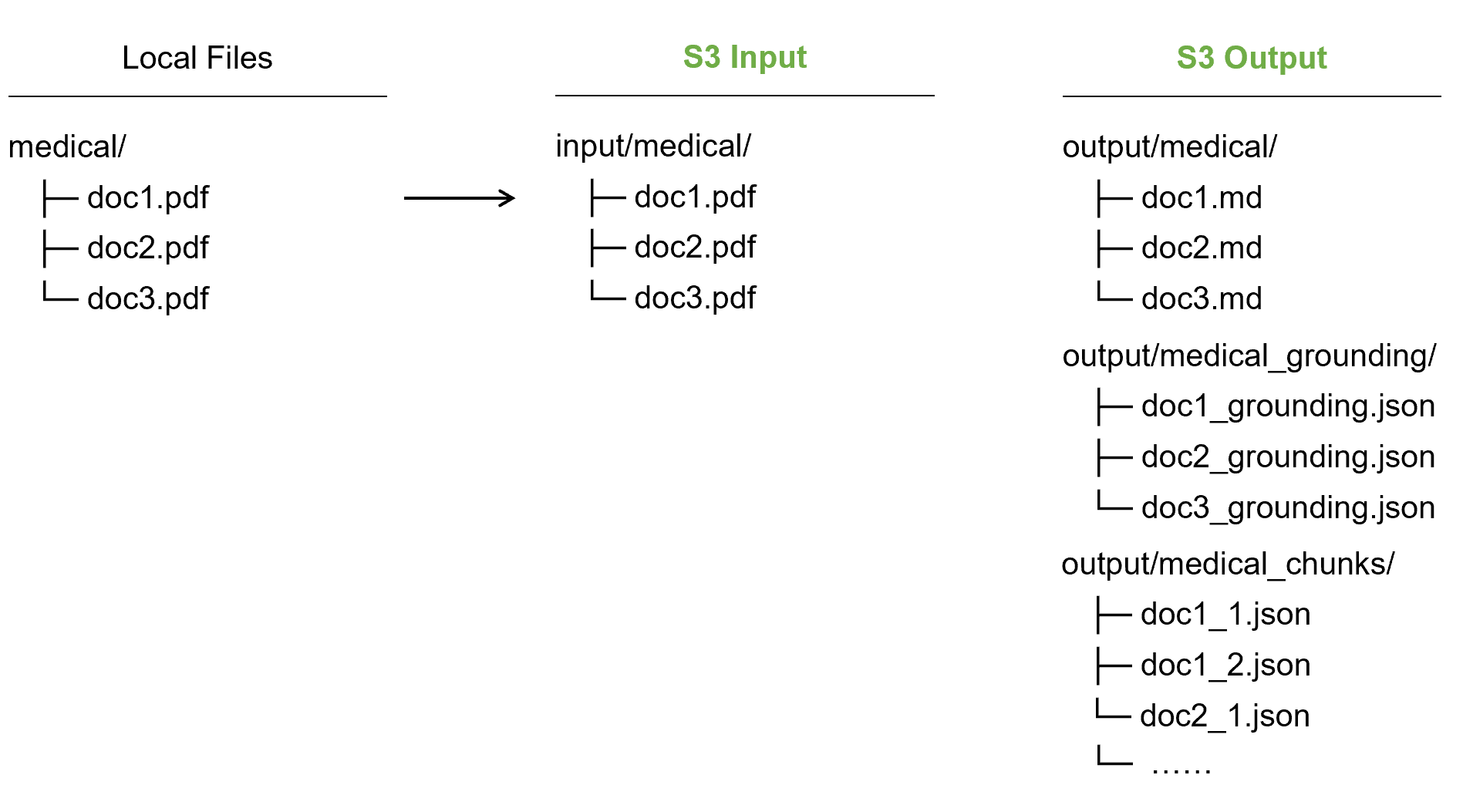
我们采用全托管的 Serverless 架构,以此实现零运维成本和自动扩缩容。数据流向:
- Ingestion (S3 Input): 业务系统将 PDF 上传至 S3。
- Trigger (Lambda): S3 PutObject 事件触发 Lambda 处理函数。
- Processing (ADE + Lambda): Lambda 调用 LandingAI ADE 进行解析。
- Distribution (S3 Output): 产物被分拆为 Markdown(用于阅读)、Chunks(用于索引)和 Grounding Metadata(用于 UI)。
- Indexing (Bedrock KB): AWS Bedrock Knowledge Base 自动监测 S3 变动,将 Chunks 向量化并存入 OpenSearch Serverless。
- Serving (Strands Agent): 最终用户通过 Agent 进行带上下文的对话。
4.1 核心组件:Lambda 处理器
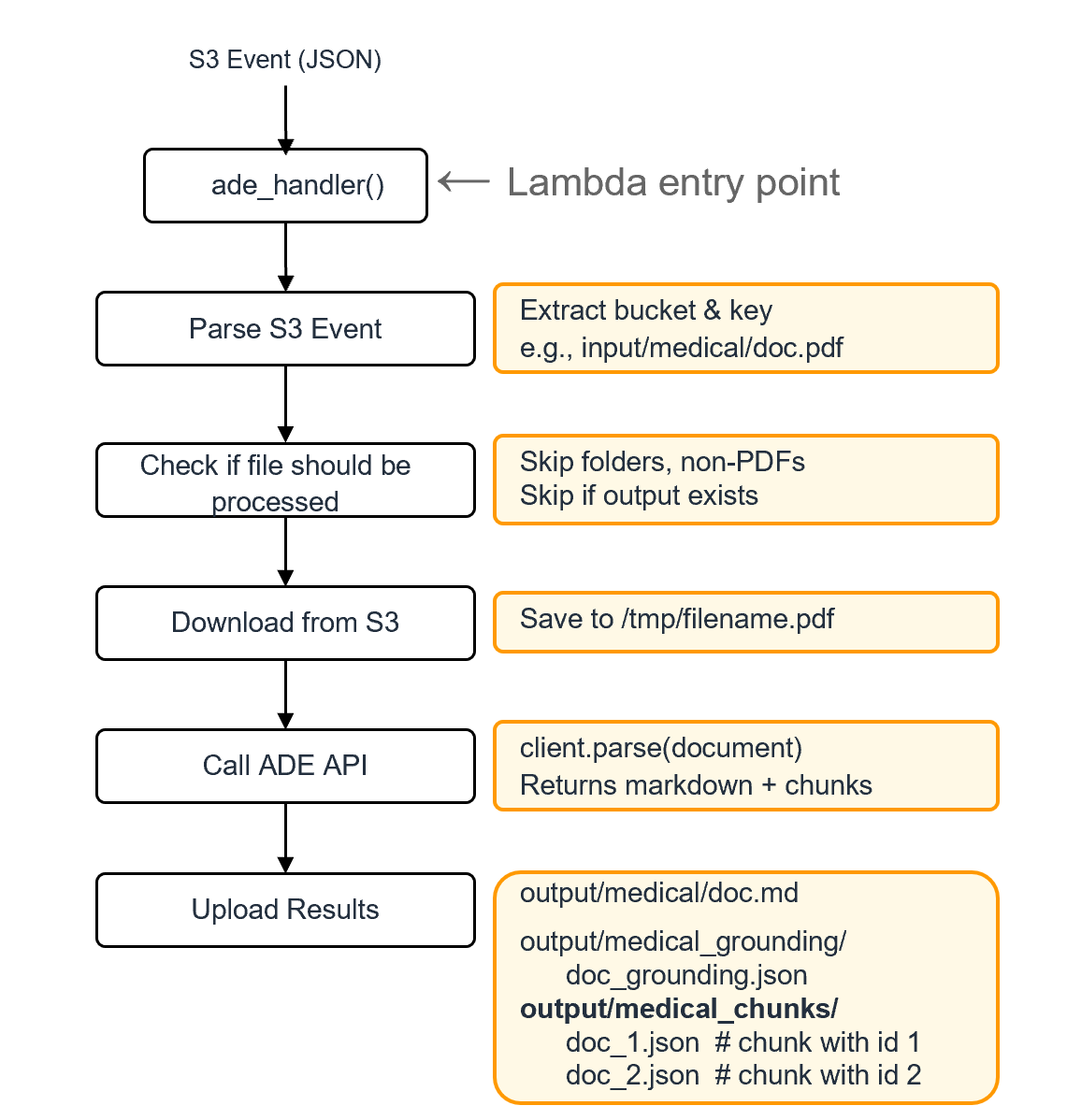
以下是 ade_s3_handler.py 的核心工程逻辑实现 :
import os
import json
import boto3
from landingai_ade import LandingAIADE
s3 = boto3.client("s3")
# 初始化 ADE 客户端,API Key 来自环境变量
client = LandingAIADE(api_key=os.environ.get("VISION_AGENT_API_KEY"))
def ade_handler(event, context):
"""
AWS Lambda 入口函数:处理 S3 事件,调用 ADE,分发产物。
"""
# 1. 解析 S3 事件
record = event['Records'][0]
bucket_name = record['s3']['bucket']['name']
input_key = record['s3']['object']['key']
# 2. 验证与下载
# 生产环境必须防止处理非 PDF 文件或自身产生的 Output 文件造成死循环
if not input_key.lower().endswith(".pdf") or "output/" in input_key:
return {"status": "skipped"}
local_pdf_path = f"/tmp/{os.path.basename(input_key)}"
s3.download_file(bucket_name, input_key, local_pdf_path)
# 3. 调用 ADE Parse API (核心步骤)
# 使用 dpt-2-latest 模型,开启分页解析
print(f"Parsing {input_key}...")
parse_result = client.parse(
document=local_pdf_path,
model="dpt-2-latest"
)
# 4. 产物分发策略 (关键工程设计)
base_name = os.path.splitext(os.path.basename(input_key))[0]
output_prefix = f"output/{base_name}"
# A. 存储完整 Markdown (用于给 LLM 提供全文档上下文)
s3.put_object(
Bucket=bucket_name,
Key=f"{output_prefix}/full_document.md",
Body=parse_result.markdown
)
# B. 存储 Grounding Metadata (用于前端高亮)
# 包含所有 chunk 的 id, type, bbox, page
chunks_meta = [chunk.model_dump() for chunk in parse_result.chunks]
s3.put_object(
Bucket=bucket_name,
Key=f"{output_prefix}/grounding.json",
Body=json.dumps(chunks_meta)
)
# C. 存储独立 Chunks (用于 Bedrock Knowledge Base 索引)
# 这一步至关重要:我们将每个 Chunk 存为单独的 JSON 文件
# Bedrock 会自动读取这些 JSON,将其中的 'text' 向量化,将其他字段作为 metadata
for chunk in parse_result.chunks:
chunk_data = {
"text": chunk.text, # 向量化目标
"chunk_id": chunk.id,
"chunk_type": chunk.type, # text, table, figure
"page": chunk.grounding.page,
"bbox": chunk.grounding.box,
"source_document": base_name
}
# 路径设计为 output/chunks/,方便 Bedrock Data Source配置
s3.put_object(
Bucket=bucket_name,
Key=f"output/chunks/{base_name}_{chunk.id}.json",
Body=json.dumps(chunk_data)
)
return {"status": "success", "chunks_count": len(parse_result.chunks)}
- 独立 Chunk 存储: 每个 Chunk 存为独立的 JSON 文件,这样 Bedrock Knowledge Base 可以为每个 Chunk 生成一个向量,并在检索时精准返回该 Chunk 的元数据(包括 bbox)。
- 元数据保留: 在 JSON 中保留
bbox和page,使得后续的检索不仅能拿回文字,还能拿回坐标。
4.2 核心组件:Bedrock Knowledge Base
为什么选择 Bedrock KB 而不是自己维护 ChromaDB?
在生产环境中,自己维护向量数据库需要处理分片、备份和高可用。Bedrock KB 底层使用 OpenSearch Serverless,不仅处理了这些运维问题,还集成了 AWS 的 IAM 权限体系。索引策略:
- Data Source: 指向 S3 的
output/chunks/目录。 - Embedding Model: Amazon Titan Embeddings v2。
- Chunking Strategy: 选择 “No Chunking”。
注意:因为 ADE 已经通过视觉语义完成了切分(表格是一个 Chunk,段落是一个 Chunk),我们不需要 Bedrock 再进行机械的“每500字规则切分”。
4.3 核心组件:Strands Agent
最后,我们需要一个 Agent 来串联这一切。普通的 RAG 只能回答文本,而我们的 Agent 具备“视觉能力”。
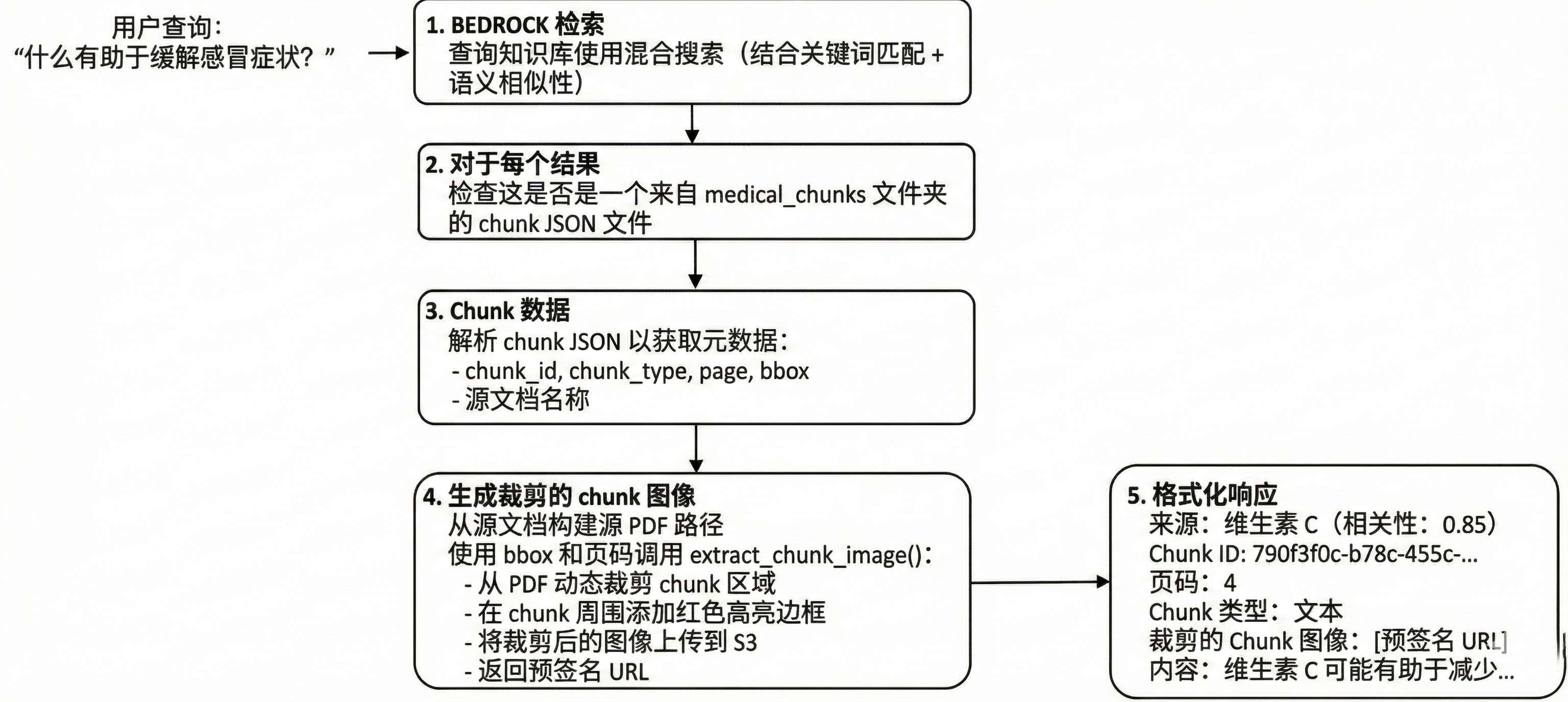
我们需要定义一个自定义工具 search_knowledge_base:
- Hybrid Search: 使用 Bedrock
retrieveAPI 进行混合搜索(关键词+向量)。 - Metadata Extraction: 从搜索结果中提取
chunk_id和bbox。 - Dynamic Cropping (动态裁剪): Agent 会实时去 S3 读取原 PDF,根据
bbox裁剪出图片,并生成预签名 URL。
@strands.tool
def search_knowledge_base(query: str) -> str:
"""
搜索知识库,并返回带有视觉证据(裁剪图片)的结果。
"""
# 1. 检索
results = bedrock_client.retrieve(
knowledgeBaseId=os.environ["KB_ID"],
retrievalQuery={"text": query},
retrievalConfiguration={
"vectorSearchConfiguration": {"overrideSearchType": "HYBRID"}
}
)
formatted_response = []
# 2. 处理每个搜索结果
for res in results['retrievalResults']:
metadata = res['location']['s3Location']['metadata'] # 之前存入的 JSON 字段
chunk_id = metadata.get('chunk_id')
bbox = metadata.get('bbox')
page = metadata.get('page')
source_doc = metadata.get('source_document')
# 3. 动态裁剪图片 (Visual Grounding Helper)
# 调用辅助函数,利用 PyMuPDF (fitz) 在 Lambda 中裁剪 PDF
# 并上传到 S3 临时目录,获取 Presigned URL
image_url = extract_chunk_image(
bucket=os.environ["BUCKET"],
key=f"input/{source_doc}.pdf",
page=page,
bbox=bbox
)
# 4. 构造富文本回复
formatted_response.append(f"""
**Source:** {source_doc} (Page {page})
**Content:** {res['content']['text']}
**Visual Evidence:** 
""")
return "\n\n".join(formatted_response)
4.4 Agent Memory?
- Session Management: 区分
session_id和actor_id。Actor ID 代表用户身份(如 “Dr. Smith”),Session ID 代表当前对话。 - UserPreference: 记住用户偏好(例如“用户喜欢简短的回答”)。
- Summary: 自动总结长对话,防止上下文超出 Token 限制。
# 记忆配置
memory_config = AgentCoreMemoryConfig(
memory_id=MEMORY_ID,
session_id=current_session_id,
actor_id=user_id
)
# 实例化 Agent
medical_agent = Agent(
model="anthropic.claude-3-sonnet", # 强推理模型
tools=[search_knowledge_base],
session_manager=session_manager, # 注入记忆能力
system_prompt="""
You are a medical assistant.
ALWAYS use the search tool to find information.
When you find a result, you MUST display the 'Visual Evidence' image URL provided by the tool.
Do not hallucinate medical facts.
"""
)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)