程序员的福音!SWIRL开源AI搜索神器:不折腾向量数据库,Docker一行命令搞定企业级RAG,2.9K星认证!
SWIRL是开源企业级AI搜索和RAG平台,无需迁移数据或搭建向量数据库,Docker一行命令即可部署。支持连接100+企业应用(SharePoint、Confluence等),保留原有权限控制,提供知识库搜索、客服助手、开发助手等功能。后端采用Python+Django,支持联邦搜索和智能排序,帮助团队平均每周节省7.5小时,适合数据分散在多个系统的企业使用。
公司数据散落在Confluence、SharePoint、Google Drive、Jira一堆地方,想搜点资料翻半天找不到。上AI问答吧,又得把数据全导到向量数据库里,搞ETL管道,折腾好几周。
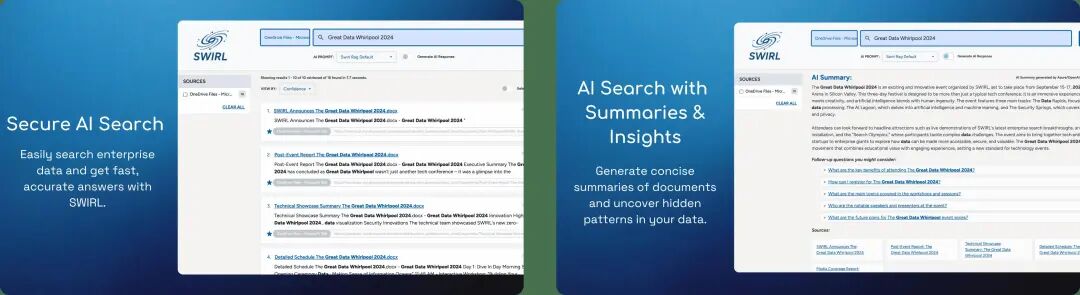
SWIRL这个项目直接把这些破事全省了。GitHub上2.9K星了,数据不用动,不用搞向量数据库,Docker一行命令就能跑起来企业级AI搜索。直接连你现有的系统,搜索、问答全都有,两分钟搞定。
SWIRL是啥
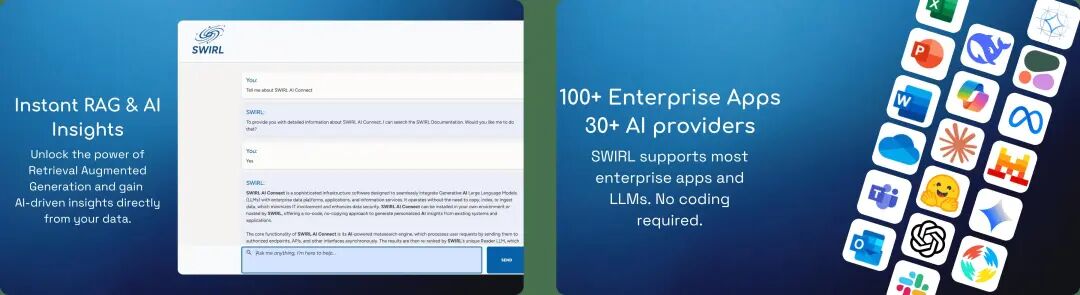
一个专门给企业用的AI搜索和RAG平台。最大的特点是数据不用迁移,直接连接你现有的各种系统(SharePoint、Confluence、Drive、Slack、数据库),在原地搜索,用AI生成答案。
不需要搞向量数据库,不需要写复杂的ETL管道,不需要把敏感数据搬来搬去。支持100多种企业应用连接器,微软365、Google Workspace、Salesforce、Jira、GitHub什么都能接。
而且权限控制保留原样,用户只能搜到自己有权限看的内容,数据安全有保障。
能干啥
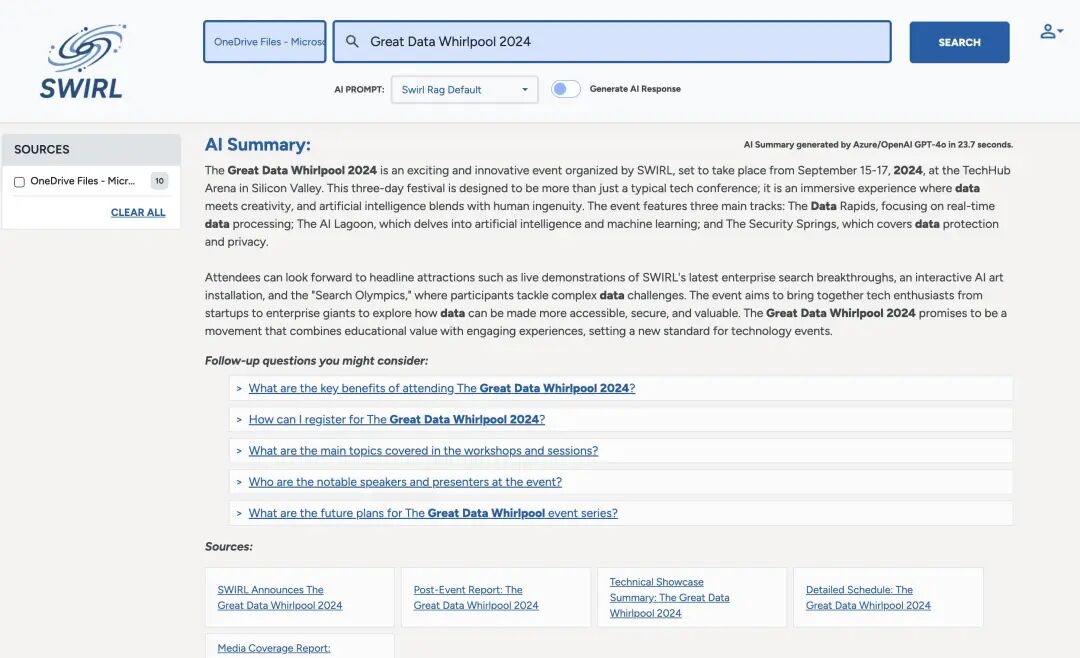
知识库搜索: 连接SharePoint、Confluence、Google Drive,输入问题直接给答案,还附带来源链接。不用再去各个平台翻找文档。
客服助手: 搜索历史工单、帮助文档,AI自动生成回复建议,保持答案的一致性。
开发助手: 搜索GitHub代码、Jira工单、技术文档,快速找到代码示例和解决方案,加速开发。
统一搜索: 一次搜索覆盖所有工具,结果自动按相关性排序,不用在各个系统间切换。
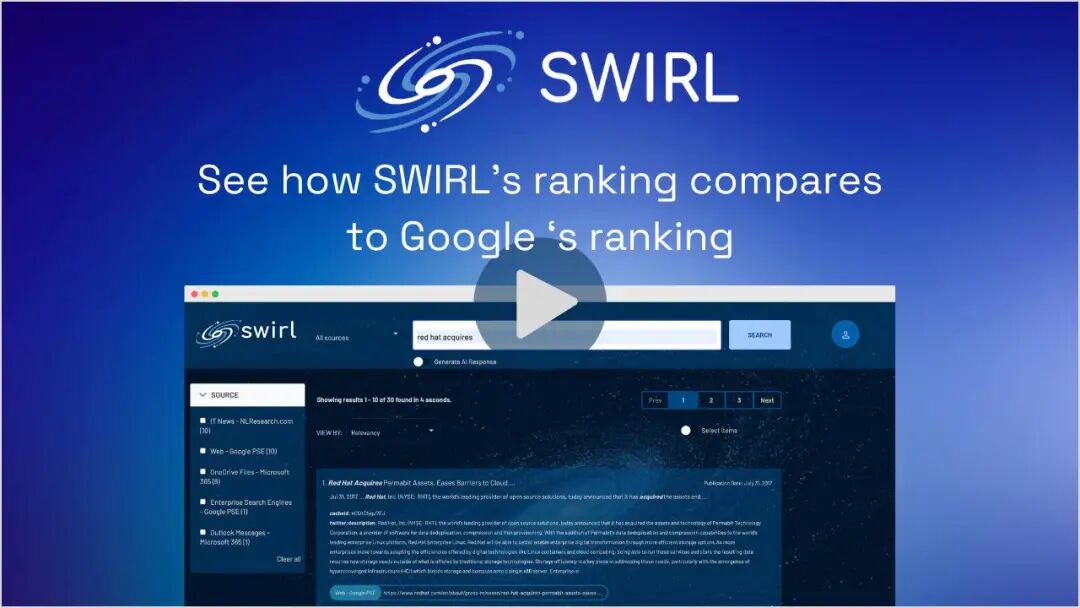
智能排序: 不是简单堆砌结果,会理解公司内部语境,把最相关的结果排在前面。比Google搜公司内部资料准多了。
为啥好用
- • 不折腾基础设施: 不用搭向量数据库,不用写数据管道,Docker一行命令就起来了
- • 数据不用动: 连接现有系统,数据在哪搜哪,不用担心数据迁移和安全问题
- • 权限自动继承: 搜索结果自动过滤,用户只能看到自己有权限的内容
- • 部署快: 官方说是几分钟部署,实测确实快,不像其他企业软件要折腾几周
- • 连接器多: 支持100多种企业应用,主流的工具基本都覆盖了
支持哪些系统
- • 微软生态: Microsoft 365、SharePoint、OneDrive、Teams、Azure
- • Google生态: Google Drive、Gmail、Google Workspace
- • 开发工具: GitHub、GitLab、Jira、Confluence
- • 数据库: PostgreSQL、MySQL、BigQuery、Elasticsearch
- • 其他: Slack、Salesforce、Notion、Zendesk等等
完整列表在官网连接器页面。
怎么装
Docker快速启动:
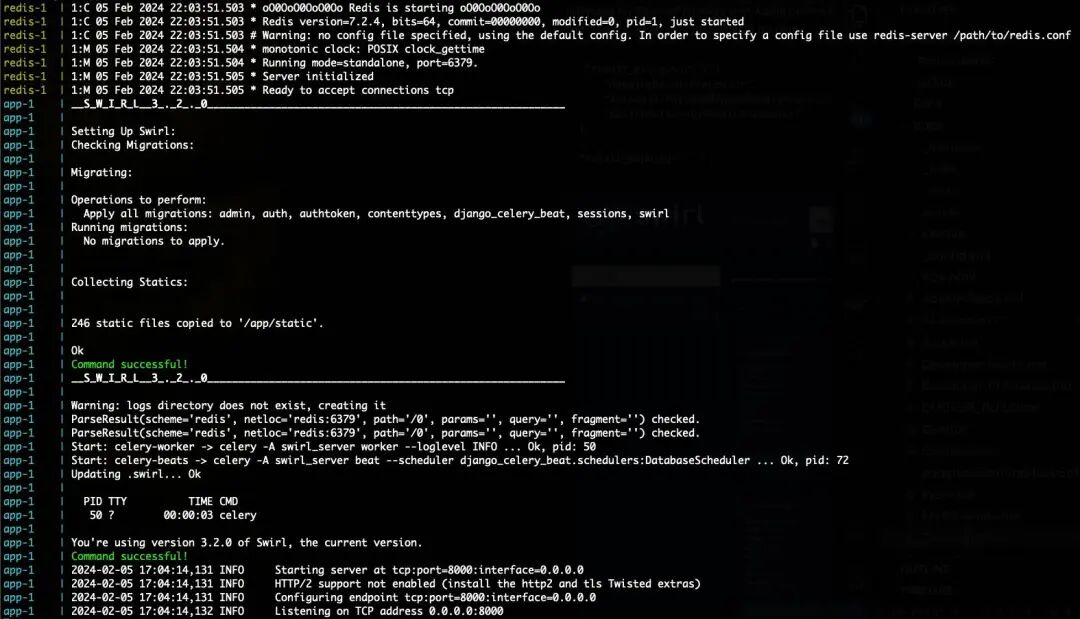
# 下载配置文件curl https://raw.githubusercontent.com/swirlai/swirl-search/main/docker-compose.yaml -o docker-compose.yaml# 启动(需要先装好Docker)docker-compose pull && docker-compose up
启用RAG功能(可选):
# 需要OpenAI API keyexport MSAL_CB_PORT=8000export MSAL_HOST=localhostexport OPENAI_API_KEY='你的OpenAI-API-key'# 然后再启动docker-compose up
启动完成后打开 http://localhost:8000,用户名admin,密码password登录就能用了。
注意: Docker版本关掉就不保存数据,只是用来试用。正式用要本地安装,看官方文档。
使用场景
看个实际案例:连接OneDrive和Microsoft 365,60秒就能搭好一个问答系统。输入问题,AI从你的文档里找答案,还能点进去看原文。
官方数据说用SWIRL的团队平均每周节省7.5小时,这个数据可信,毕竟不用在各个系统间来回找资料了。
项目提供了很多预配置好的SearchProvider(搜索提供者),包括Arxiv、Google News这些,开箱即用。企业应用的连接器要联系官方申请,特别是Microsoft 365需要管理员授权。
技术细节
- • 后端: Python + Django
- • 数据库: SQLite3或PostgreSQL
- • 搜索: 支持同步和异步联邦搜索
- • 排序算法: 用spaCy的大语言模型和NLTK做余弦相似度排序
- • 去重: 可配置的余弦相似度阈值去重
- • 查询转换: 自动适配不同系统的查询语法
项目图片

这个项目适合有一定规模的团队,特别是数据散落在各个系统里,又不想折腾数据迁移的情况。开源版功能已经够用,企业版提供云托管服务和更多连接器支持。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献611条内容
已为社区贡献611条内容

所有评论(0)