Kimi K2.5深度剖析
KimiK2.5是一款开源原生多模态智能体模型,基于Kimi-K2-Base架构,通过15万亿混合视觉与文本token的预训练构建而成。该模型融合了视觉与语言理解能力,具备智能体集群功能,可动态管理100个子代理并行执行1500次工具调用,将任务执行时间缩短高达4.5倍。其核心突破在于采用PARL(并行智能体强化学习)训练方法,通过分阶段奖励机制促使模型掌握任务分解与并行调度能力。在性能表现上,K
一、Kimi K2.5 介绍
Kimi K2.5 是一个开源的原生多模态智能体模型,基于 Kimi-K2-Base,通过在约 15 万亿混合视觉与文本 token 上进行持续预训练构建而成。它无缝融合了视觉与语言理解能力,并具备高级智能体功能,支持即时模式与思考模式,以及对话式和智能体式范式。
核心特性
-
原生多模态:在视觉–语言 token 上进行预训练,K2.5 在视觉知识、跨模态推理以及基于视觉输入的智能体工具使用方面表现出色。
-
结合视觉的编程能力:K2.5 能根据视觉规范(如 UI 设计、视频工作流)生成代码,并自主编排工具以处理视觉数据。
-
智能体集群(Agent Swarm):K2.5 从单智能体扩展转变为一种自导向、协同式的集群执行方案。它能将复杂任务分解为多个并行子任务,并由动态实例化的领域专用智能体协同执行。
| Benchmark | Kimi K2.5 (Thinking) |
GPT-5.2 (xhigh) |
Claude 4.5 Opus (Extended Thinking) |
Gemini 3 Pro (High Thinking Level) |
DeepSeek V3.2 (Thinking) |
Qwen3-VL- 235B-A22B- Thinking |
|
| Reasoning & Knowledge | |||||||
| HLE-Full | 30.1 | 34.5 | 30.8 | 37.5 | 25.1† | - | |
| HLE-Full (w/ tools) |
50.2 | 45.5 | 43.2 | 45.8 | 40.8† | - | |
| AIME 2025 | 96.1 | 100 | 92.8 | 95 | 93.1 | - | |
| HMMT 2025 (Feb) | 95.4 | 99.4 | 92.9* | 97.3* | 92.5 | - | |
| IMO-AnswerBench | 81.8 | 86.3 | 78.5* | 83.1* | 78.3 | - | |
| GPQA-Diamond | 87.6 | 92.4 | 87 | 91.9 | 82.4 | - | |
| MMLU-Pro | 87.1 | 86.7* | 89.3* | 90.1 | 85 | - | |
| Image & Video | |||||||
| MMMU-Pro | 78.5 | 79.5* | 74 | 81 | - | 69.3 | |
| CharXiv (RQ) | 77.5 | 82.1 | 67.2* | 81.4 | - | 66.1 | |
| MathVision | 84.2 | 83 | 77.1* | 86.1* | - | 74.6 | |
| MathVista (mini) | 90.1 | 82.8* | 80.2* | 89.8* | - | 85.8 | |
| ZeroBench | 9 | 9* | 3* | 8* | - | 4* | |
| ZeroBench (w/ tools) |
11 | 7* | 9* | 12* | - | 3* | |
| OCRBench | 92.3 | 80.7* | 86.5* | 90.3* | - | 87.5 | |
| OmniDocBench 1.5 | 88.8 | 85.7 | 87.7* | 88.5 | - | 82.0* | |
| InfoVQA (val) | 92.6 | 84* | 76.9* | 57.2* | - | 89.5 | |
| SimpleVQA | 71.2 | 55.8* | 69.7* | 69.7* | - | 56.8* | |
| WorldVQA | 46.3 | 28 | 36.8 | 47.4 | - | 23.5 | |
| VideoMMMU | 86.6 | 85.9 | 84.4* | 87.6 | - | 80 | |
| MMVU | 80.4 | 80.8* | 77.3 | 77.5 | - | 71.1 | |
| MotionBench | 70.4 | 64.8 | 60.3 | 70.3 | - | - | |
| VideoMME | 87.4 | 86.0* | - | 88.4* | - | 79 | |
| LongVideoBench | 79.8 | 76.5* | 67.2* | 77.7* | - | 65.6* | |
| LVBench | 75.9 | - | - | 73.5* | - | 63.6 | |
| Coding | |||||||
| SWE-Bench Verified | 76.8 | 80 | 80.9 | 76.2 | 73.1 | - | |
| SWE-Bench Pro | 50.7 | 55.6 | 55.4* | - | - | - | |
| SWE-Bench Multilingual | 73 | 72 | 77.5 | 65 | 70.2 | - | |
| Terminal Bench 2.0 | 50.8 | 54 | 59.3 | 54.2 | 46.4 | - | |
| PaperBench | 63.5 | 63.7* | 72.9* | - | 47.1 | - | |
| CyberGym | 41.3 | - | 50.6 | 39.9* | 17.3* | - | |
| SciCode | 48.7 | 52.1 | 49.5 | 56.1 | 38.9 | - | |
| OJBench (cpp) | 57.4 | - | 54.6* | 68.5* | 54.7* | - | |
| LiveCodeBench (v6) | 85 | - | 82.2* | 87.4* | 83.3 | - | |
| Long Context | |||||||
| Longbench v2 | 61 | 54.5* | 64.4* | 68.2* | 59.8* | - | |
| AA-LCR | 70 | 72.3* | 71.3* | 65.3* | 64.3* | - | |
| Agentic Search | |||||||
| BrowseComp | 60.6 | 65.8 | 37 | 37.8 | 51.4 | - | |
| BrowseComp (w/ctx manage) |
74.9 | 57.8 | 59.2 | 67.6 | - | ||
| BrowseComp (Agent Swarm) |
78.4 | - | - | - | - | - | |
| WideSearch (item-f1) |
72.7 | - | 76.2* | 57 | 32.5* | - | |
| WideSearch (item-f1 Agent Swarm) |
79 | - | - | - | - | - | |
| DeepSearchQA | 77.1 | 71.3* | 76.1* | 63.2* | 60.9* | - | |
| FinSearchCompT2&T3 | 67.8 | - | 66.2* | 49.9 | 59.1* | - | |
| Seal-0 | 57.4 | 45 | 47.7* | 45.5* | 49.5* | - | |
模型的评估也是相当出色,接下来我们就来深度拆解一下这个模型。
二、 Kimi K2.5 的设计
Kimi K2.5 在 Kimi K2 的基础上,继续使用约 15T 混合视觉和文本标记进行预训练。K2.5 作为一个原生多模态模型,提供了最先进的编码和视觉功能,以及自主智能体集群范式。
对于复杂任务,Kimi K2.5 可以自主管理一个包含多达 100 个子代理的代理集群,并行执行多达 1500 次工具调用。与单代理配置相比,这可以将执行时间缩短高达 4.5 倍。代理集群由 Kimi K2.5 自动创建和编排,无需任何预定义的子代理或工作流程。
这里可能有人会有疑惑: 这里的k2.5为什么能调用子代理,它不是一个大模型吗?
1. 核心原理:它不仅仅是“模型”,它是“蜂群指挥官”
普通的 LLM(大语言模型)通常是“单兵作战”,即你给一个指令,它按顺序一步步生成答案。 而 Kimi k2.5 引入了 Agent Swarm(智能体蜂群) 架构。
-
身份转变: 在这个模式下,Kimi k2.5 的主模型扮演 Orchestrator(编排者/指挥官) 的角色。
-
能力来源: 它经过了一种特殊的训练,叫做 PARL(Parallel-Agent Reinforcement Learning,并行代理强化学习)。这种训练让模型学会了如何拆解复杂的任务,而不是自己闷头硬干。
2. 它是如何调用子代理的?
这并不是说 Kimi k2.5 内部藏着很多“小人”,而是它具备了**动态实例化(Dynamically Instantiated)**的能力:
-
任务拆解: 当你给出一个复杂任务(比如“帮我调研300个YouTuber的数据”),作为指挥官的 Kimi k2.5 会分析任务,意识到“一个人做太慢了”。
-
召唤分身(子代理): 它会动态地生成(Instantiate)多个“冻结状态的子代理”(frozen sub-agents)。这些子代理本质上可以是模型的轻量化实例或特定功能的执行单元。
-
并行执行: 主模型给这些子代理派发具体的、可并行的子任务。根据博客提到的数据,它可以同时指挥多达 100个子代理,进行 1500次工具调用。
-
结果汇总: 子代理们并行工作(比如同时查几十个网页),最后将结果汇总给主模型。
3. 为什么“大模型”能做到这点?
你之前的认知可能认为大模型就是“输入文本->输出文本”。但现在的趋势是 Agentic Intelligence(代理智能):
-
工具使用(Tool Use): 大模型早就具备了调用计算器、搜索引擎等外部工具的能力(Function Calling)。
-
调用“代理”只是工具使用的一种升级: 对于 K2.5 来说,"启动一个子代理" 本质上就是它调用的一种高级工具。它通过推理(Reasoning)判断出需要帮手,然后通过代码或API指令去唤起这些帮手。
一个真实的例子:
假设场景:你是一个投资人,你对 Kimi k2.5 说:
用户指令: “帮我查一下英伟达(NVIDIA)、特斯拉(Tesla)和 拼多多(PDD)这三家公司过去24小时发生的重大新闻,并分析对股价的潜在影响。”
如果没有子代理,普通大模型会怎么做?它会像一个老实人:先搜英伟达,读完,再搜特斯拉,读完,再搜拼多多,读完……最后总结。这很慢。
下面我们模拟 Kimi k2.5(指挥官模式) 是如何处理的。
🟢 第一阶段:指挥官(Orchestrator)的思考
(这是 Kimi k2.5 主模型的“大脑”内部活动)
Kimi 主模型 (Thinking):
任务分析: 用户需要三家不同公司的即时新闻和分析。
策略判断: 这三家公司的新闻互不干扰,顺序查找太浪费时间。我应该启动“蜂群模式”(Swarm Mode)。
工具检索: 我查看了当前的工具菜单,发现有一个
WebSearch_Agent(联网搜索代理)工具可用。下达指令: 我决定分裂出 3 个子代理,同时去干活。
Kimi 主模型 (输出指令 - 模拟代码):
JSON
// 指挥官发出的系统调用 { "action": "spawn_swarm", "agents": [ { "role": "sub_agent_01", "task": "搜索 'NVIDIA last 24h news',总结关键事件", "tool_access": ["Bing_Search"] }, { "role": "sub_agent_02", "task": "搜索 'Tesla last 24h news',总结关键事件", "tool_access": ["Bing_Search"] }, { "role": "sub_agent_03", "task": "搜索 'PDD last 24h news',总结关键事件", "tool_access": ["Bing_Search"] } ] }
🟡 第二阶段:子代理(Sub-Agents)并行干活
(此时,主模型在“喝茶”等待,3 个子代理同时在后台运行。这对用户是不可见的,但为了演示,我们把它们“显形”。)
注意:这三件事是同时发生的(Parallel Execution)。
🕵️ 子代理 A (负责英伟达):
调用搜索工具 -> 发现新闻:“英伟达发布新一代 Blackwell 芯片发货延迟传闻澄清……”
回传结果: “关键事件:Blackwell 发货正常。股价盘前微涨。”
🕵️ 子代理 B (负责特斯拉):
调用搜索工具 -> 发现新闻:“马斯克宣布 FSD 在中国落地新进展……”
回传结果: “关键事件:FSD 入华预期增强。市场情绪:乐观。”
🕵️ 子代理 C (负责拼多多):
调用搜索工具 -> 发现新闻:“Temu 面临新的关税政策挑战……”
回传结果: “关键事件:跨境电商关税风险。市场情绪:担忧。”
🔴 第三阶段:指挥官汇总与交付
(3 个子代理瞬间把报告交了上来,Kimi 主模型重新接管)
Kimi 主模型 (Thinking): 收到三个子代理的汇报了。现在我要把这些碎片信息整合成用户想要的“股价影响分析”。
Kimi 主模型 (最终回复给用户):
根据对这三家公司过去24小时的新闻监测,以下是详细分析:
英伟达 (NVIDIA):
新闻:针对Blackwell芯片延迟的传闻进行了官方澄清。
影响:消除了市场疑虑,看涨。
特斯拉 (Tesla):
新闻:FSD入华有新进展。
影响:开启新增长曲线预期,看涨。
拼多多 (PDD):
新闻:Temu面临新的关税合规压力。
影响:短期利润率可能承压,看空/震荡。
💡 重点解析:为什么这比以前强?
“调用”的本质: 你看第一阶段的那个
json代码。所谓的“调用子代理”,其实就是主模型写了一张**“派工单”**。系统后台看到这张单子,就自动启动了 3 个小的程序(子代理)去跑。关于你担心的“新工具”: 假设你在后台给 Kimi 增加了一个新工具叫
Stock_Chart_Draw(股价画图工具)。
在第一阶段,Kimi 主模型看“菜单”时,就会发现:“咦,有个画图工具?”
在下指令时,它可能就会多派一个 子代理 D,并在指令里写:
"task": "使用 Stock_Chart_Draw 画出这三家公司的K线图"。主模型不需要重新训练,它只要看到新工具的说明书,把它写进“派工单”里,活儿就干成了。
三、 Kimi K2.5 的前端能力
Kimi K2.5 是迄今为止最强大的开源编码模型,尤其在前端开发方面具有强大的功能。K2.5 可以将简单的对话转化为完整的前端界面,实现交互式布局和丰富的动画效果,例如滚动触发效果。以下是 K2.5 使用图像生成工具,根据单个提示生成的示例:
暂时无法在飞书文档外展示此内容
这种能力源于大规模的视觉-文本联合预训练。规模化之后,视觉和文本处理能力之间的权衡不再存在——它们同步提升。
-
核心架构:视觉与代码的“语义对齐”(Semantic Alignment)
以往的模型(如早期的 LLaVA 或 GPT-4V 的早期版本)处理前端代码时,通常是将视觉信号“翻译”成文本描述,再丢给语言模型生成代码。这种中间转化会有大量信息丢失(比如“红色按钮”丢失了具体的 RGB 值或圆角半径)。
Kimi k2.5 的“视觉-文本联合预训练”意味着:
-
统一的嵌入空间(Embedding Space): 在模型的潜空间里,一段 HTML/CSS 代码
<div class="shadow-lg rounded-xl">和一张“带有阴影的圆角卡片图像”,在向量表示上是高度重叠的。 -
双向映射能力: 模型不仅能“看图写代码”(Vision-to-Code),也能“想代码出图”(Code-to-Vision/Imagination)。
-
前端开发的本质契合: 前端代码本质上是**“用文本描述视觉”**。因此,这种联合训练的模型天生就是“前端专家”,因为它不需要在“逻辑大脑”和“视觉眼睛”之间来回切换,它的“直觉”里代码就是像素。
-
突破“模态税”(Modality Tax):规模化带来的质变
文中提到最关键的一句话是:“规模化之后,视觉和文本处理能力之间的权衡不再存在——它们同步提升。”
这触及了 AI 研究中的一个痛点,通常被称为“模态竞争”或“模态税”:
-
过去的问题: 在模型参数不够大、数据不够多时,引入图像数据往往会“挤占”模型的容量,导致纯文本(如逻辑推理、纯算法代码)的能力下降。就像一个人的脑容量有限,学了画画可能就忘了数学。
-
K2.5 的设计哲学: 只要模型参数量(Scale)突破某个临界点,并使用足够高质量的混合数据(Interleaved Data),不同模态之间会产生协同效应(Synergy):
-
代码增强视觉: 代码有着极强的逻辑结构(嵌套、循环、层级),学习代码能帮助模型更好地理解图像中的“结构关系”(比如理解网页布局的 DOM 树结构)。
-
视觉增强代码: 视觉数据提供了代码运行后的“Ground Truth(真实结果)”,帮助模型修正代码逻辑,使其更符合人类直觉。
-
-
“单提示生成”背后的 Agentic Workflow(代理工作流)
文中提到“根据单个提示...使用图像生成工具”,这暗示 K2.5 在处理前端任务时,可能内置了一个隐式的 闭环反馈机制:
-
Intent Understanding(意图理解): 用户说“做一个像 Spotify 的播放界面”。
-
Visual Planning(视觉规划): 模型内部先构建一个视觉目标(即它想画成什么样)。
-
Code Generation(代码生成): 编写 HTML/CSS/JS。
-
Self-Correction (Implicit): 虽然文中没明说,但能够实现“交互式布局”和“滚动动画”,说明模型在生成时预测了渲染后的动态行为。它不是在写静态文本,而是在构建一个动态的 DOM 对象。
这意味着什么?
这段设计标志着 AI 辅助编程进入了 2.0 阶段:
-
1.0 阶段(Copilot 时代): 你写个函数头,AI 帮你补全剩下的逻辑代码(基于文本预测)。
-
2.0 阶段(Kimi k2.5 时代): 你描述一个产品形态,AI 直接交付一个可交互的界面(基于视觉-代码对齐)。
四、 Kimi K2.5 的训练思想
K2.5 经过并行智能体强化学习 (PARL) 训练,能够自主管理多达 100 个子智能体的智能体群,执行多达 1500 个协调步骤的并行工作流程,而无需预定义角色或手工设计的工作流程。
PARL 使用可训练的协调器代理将任务分解为可并行化的子任务,每个子任务由动态实例化的冻结子代理执行。与顺序执行代理相比,并发运行这些子任务可以显著降低端到端延迟。
由于独立运行的子智能体提供的反馈存在延迟、稀疏和非平稳性,训练一个可靠的并行编排器极具挑战性。常见的故障模式是串行崩溃,即编排器尽管具备并行能力,却默认执行单智能体任务。为了解决这个问题,PARL 采用了分阶段奖励塑造策略,在训练初期鼓励并行性,并逐步将重点转移到任务成功上。
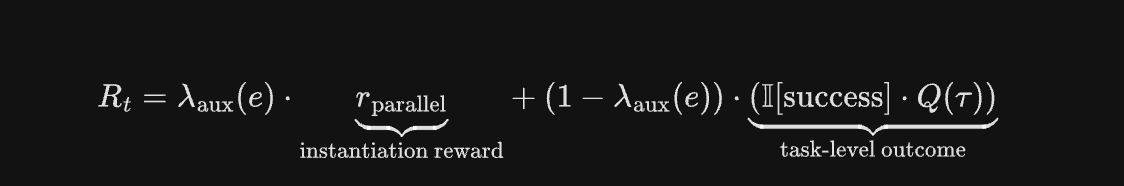
这张图片详细解释了 Kimi k2.5 实现 Agent Swarm(智能体蜂群) 背后的核心技术:PARL(Parallel-Agent Reinforcement Learning,并行智能体强化学习)。
这不仅仅是让模型“能”调用工具,而是训练模型“学会”如何像一个项目经理一样,高效地指挥团队并行工作。
以下是对图片内容的深度技术解读:
-
核心理念:横向扩展 (Scaling Out)
-
概念转变: 传统的提升模型能力是 "Scaling Up"(把模型做大),而 K2.5 提出了 "Scaling Out"(横向扩展)。
-
目标: 从单智能体(Single-agent)进化为 Self-directed Swarm(自驱蜂群)。
-
能力指标: 它可以指挥多达 100 个子智能体,在没有预定义角色或工作流的情况下,协调执行 1500 个步骤。
-
架构设计:指挥官与工人的分离
PARL 架构将智能体分为了两类角色:
-
Trainable Orchestrator Agent(可训练的指挥官): 它是唯一的“大脑”,负责拆解任务、分发工作。只有它是被训练的。
-
Frozen Sub-agents(冻结的子智能体): 它们是被动态实例化出来的“工人”。“Frozen”意味着它们在任务执行中不进行参数更新,它们只是纯粹的执行单元(功能稳定)。
-
优势: 这种架构极大地降低了端到端的延迟(Latency),因为任务是并发处理的,而不是排队处理。
-
训练难点:串行坍缩 (Serial Collapse)
这是多智能体训练中最常见的一个失败模式。
-
现象: 尽管模型有能力并行处理,但在训练初期,模型往往倾向于“稳妥”地一个接一个做任务(Sequential),退化回单智能体模式。
-
原因: 因为并行执行的反馈是延迟的、稀疏的,且子智能体独立运行导致环境不稳定,指挥官很难学到“并行这就比串行好”。
-
解决方案:分阶段奖励重塑 (Staged Reward Shaping)
为了解决“串行坍缩”,Kimi 团队设计了一个精妙的奖励函数(图片中间的公式):
$$R_t = \lambda_{\text{aux}}(e) \cdot \underbrace{r_{\text{parallel}}}_{\text{instantiation reward}} + (1 - \lambda_{\text{aux}}(e)) \cdot (\underbrace{\mathbb{I}[\text{success}] \cdot Q(\tau)}_{\text{task-level outcome}})$$
-
$$r_{\text{parallel}$$ (并行奖励): 这是一个辅助奖励。简单说就是:“只要你敢启动子代理并行干活,我就给你加分。” 这是为了鼓励模型探索并行策略。
-
$$\lambda_{\text{aux}}(e$$ (退火系数): 这个系数从 0.1 逐渐降到 0.0。
-
前期 (0.1): 训练刚开始时,强行鼓励模型“多开分身”,不管干得好不好,先学会分派任务。
-
后期 (0.0): 随着训练进行,这个辅助奖励消失。模型必须靠**“最终任务成功”**(Task-level outcome)来拿分。
-
-
目的: 防止模型为了拿分而“为了并行而并行”(形式主义),确保最终通过并行确实提高了任务质量。
-
强制进化的度量标准:Critical Steps (关键步骤)
为了彻底断绝模型“偷懒”回串行模式的后路,他们修改了计算成本的方式。图片下方的公式引入了一个概念:计算瓶颈 (Computational Bottleneck)。
$$\text{CriticalSteps} = \sum_{t=1}^{T} \left( S_{\text{main}}^{(t)} + \max_i S_{\text{sub},i}^{(t)} \right)$$
-
以前的算法: 通常计算 Total Steps(所有步骤总和)。比如 10 个任务,每个 1 秒,串行做是 10 秒,并行做(算力消耗)也是 10 秒。模型觉得没区别。
-
现在的算法 (Critical Path): 计算 “关键路径时间”。
-
$S_{\text{main}}$:指挥官思考的时间。
-
$\max S_{\text{sub}}$:最慢的那个子智能体花的时间。
-
-
结果: 如果你串行做 10 个任务,这个分数值很高(惩罚大);如果你并行做,这个分数值就很低(奖励大)。这就逼着模型必须学会“怎么快怎么来”,从而涌现出并行策略。
总结
这张图解释了 Kimi k2.5 为什么能“指挥千军万马”。它不是靠硬写规则,而是通过奖励函数的设计(前期给糖吃鼓励并行)和评价指标的倒逼(只看关键路径时间),用强化学习“逼”着模型进化出了项目管理和并行指挥的能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)