一站式开发环境配置指南
https://www.jetbrains.com/idea/配置 git克隆项目:下载:https://github.com/redis-windows/redis-windows/releases1 后台启动服务 双击`install_redis_service.bat`后 1填入安装地址 2 填入配置文件 :都支持默认直接回车使用默认启动后任务管理器中后台进程中多了 redis-cli.ex
1 IDEA 下载:
https://www.jetbrains.com/idea/
配置 git 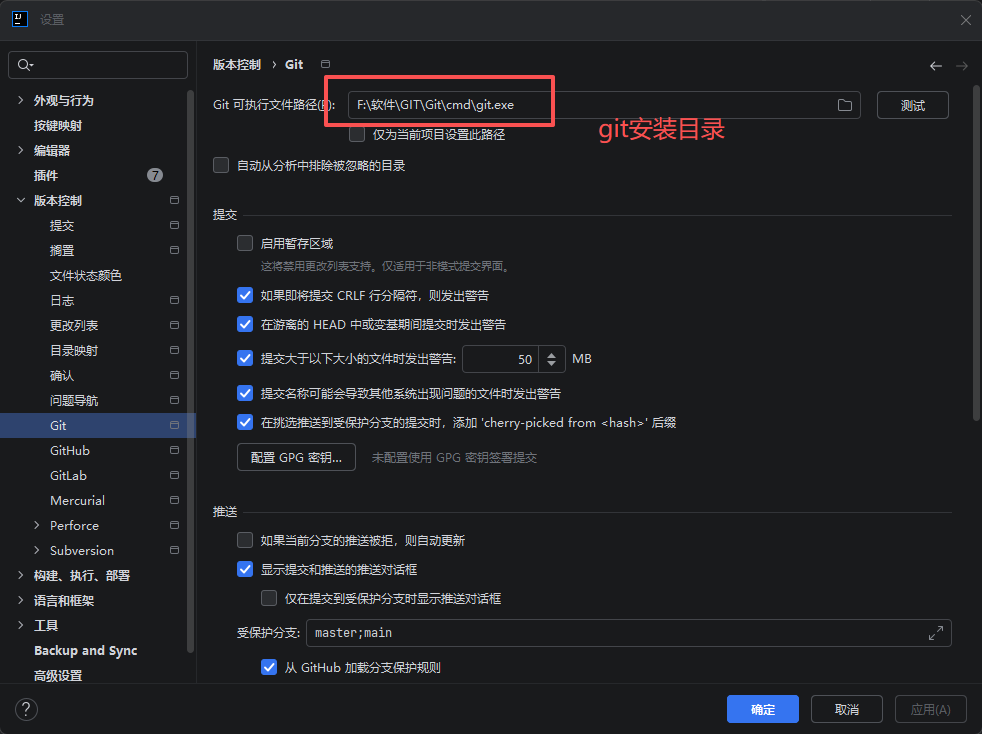
克隆项目: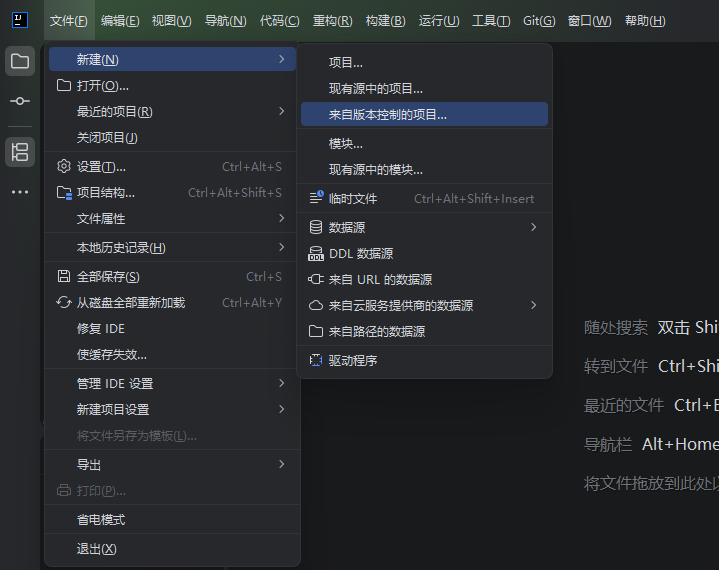
2 Maven :
下载:https://maven.apache.org/download.cgi
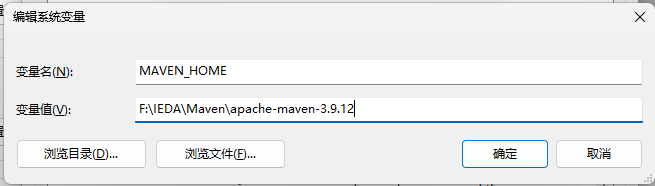
配置 环境:
-
变量名:MAVEN_HOME
-
变量值:D:\Programming\Apache\Maven\apache-maven-3.8.6
path: %MAVEN_HOME%\bin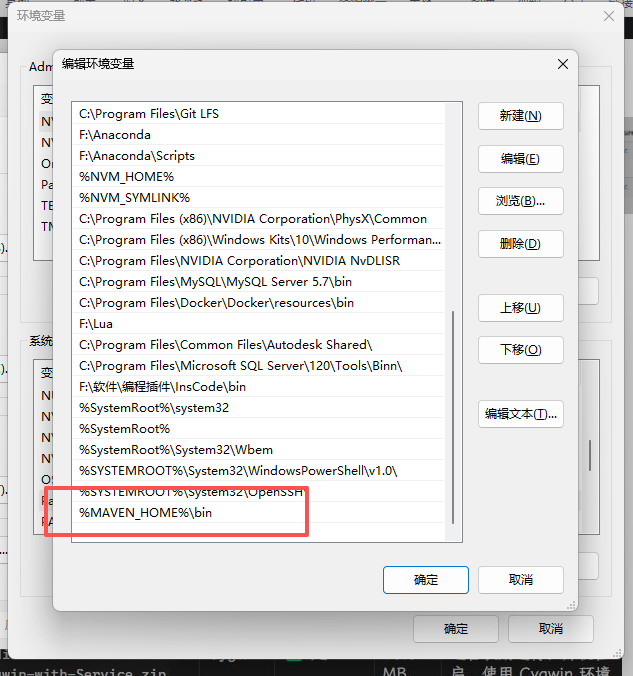
maven配置:
阿里云镜像:
打开后在<mirrors></mirrors>标签中添加 mirror 子节点:
<!-- 阿里云仓库 -->
<mirror>
<id>alimaven</id>
<mirrorOf>central</mirrorOf>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/repositories/central/</url>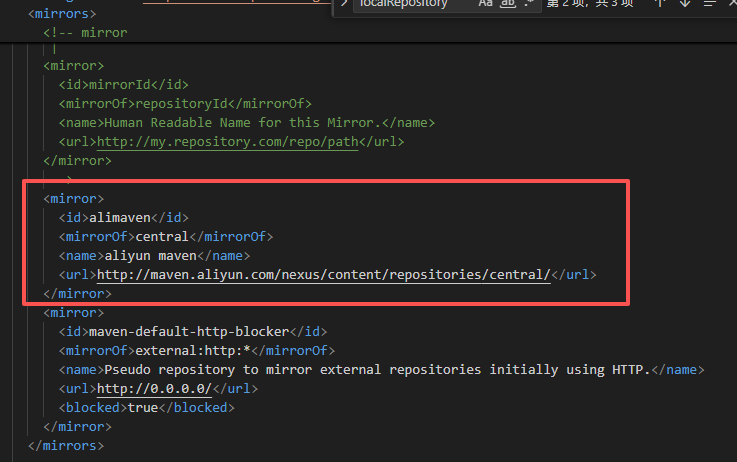
配置 jdk
<!-- java版本 -->
<profile>
<id>jdk-1.8</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>1.8</jdk>
</activation>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
</properties>
</profile>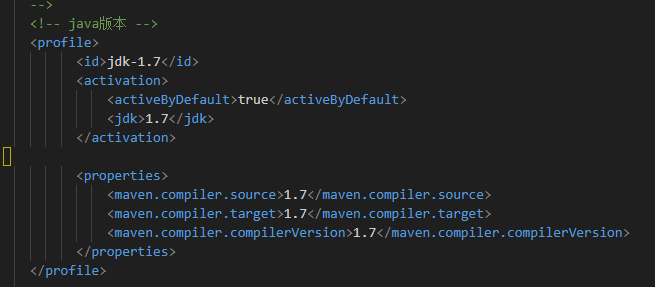
修改 本地仓库位置:
<localRepository>D:\Programming\Apache\Maven\apache-maven-3.8.6\repository</localRepository>
测试 maven :
cmd=> mvn --version--->出现Maven版本信息则表明成功。mvn help:system测试,配置成功则本地仓库
上边设置的路径(D:\Programming\Apache\Maven\apache-maven-3.8.6\repository)中会出现一些文件。
IDEA配置maven: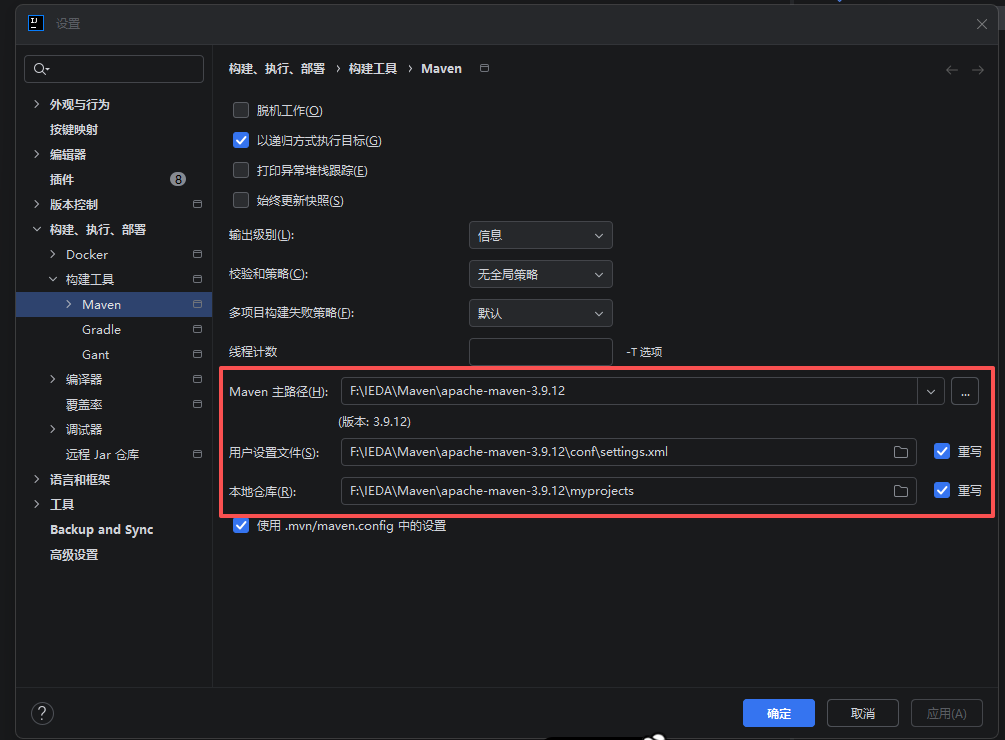
设置Maven在不联网的情况下使用本地插件,一般使用Maven为我们提供好的骨架时,是需要联网的。
-DarchetypeCatalog=internal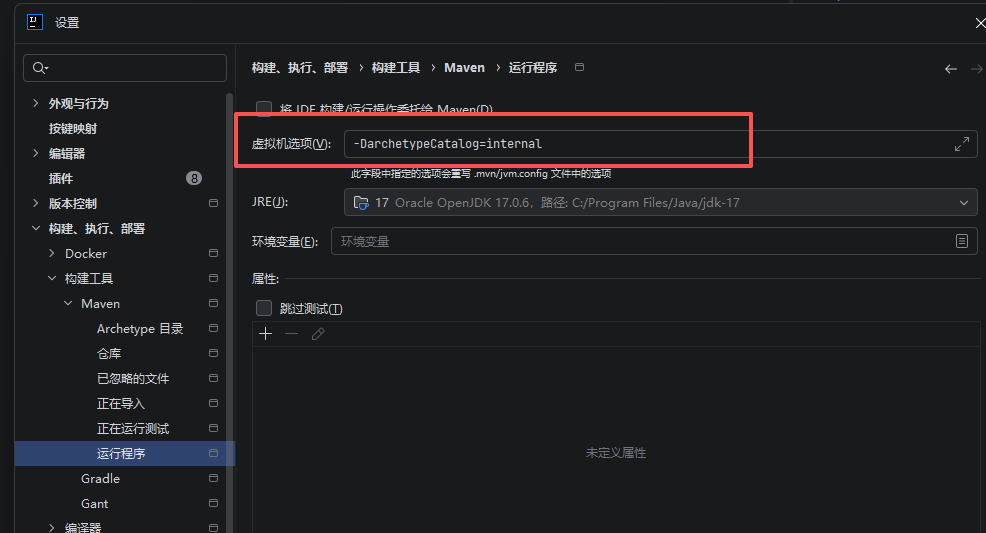
3 Redis
下载:https://github.com/redis-windows/redis-windows/releases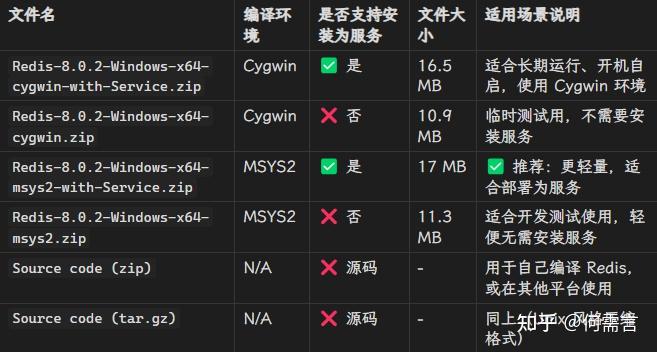
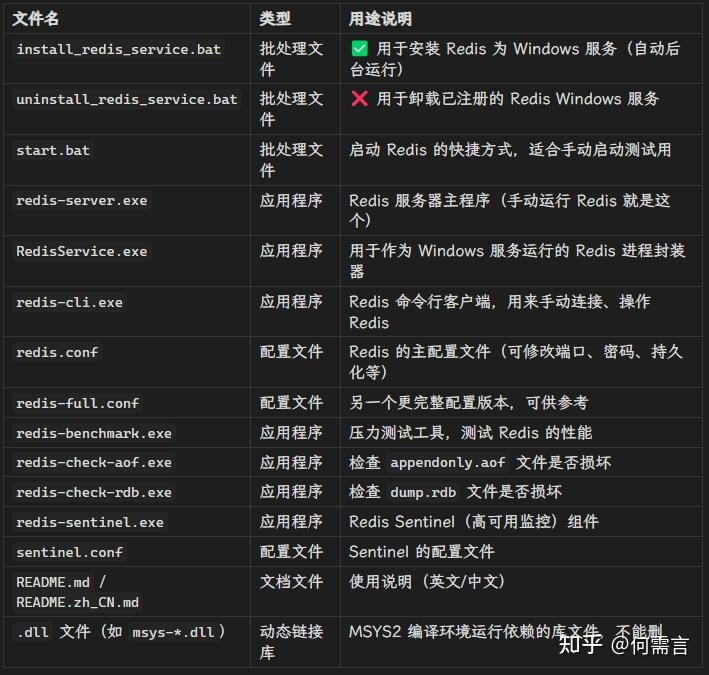
1 后台启动服务 双击`install_redis_service.bat`后 1填入安装地址 2 填入配置文件 :都支持默认直接回车使用默认
启动后 任务管理器中后台进程中多了 redis-cli.exe 和RedisService
同时安装目录会多一个pid文件 是用来记录 唯一进程的
关闭:1 任务管理器手动结束 2 cmd 中
net stop redis
2 临时启动
打开 cmd 窗口 使用 cd 命令切换目录到 C:\redis 运行:
redis-server.exe redis.windows.conf
最新版:redis-server.exe redis.conf
可以把 redis 的路径加到系统的环境变量里,这样就省得再输路径了,后面的那个 redis.windows.conf 可以省略,如果省略,会启用默认的
这时候另启一个 cmd 窗口,原来的不要关闭,不然就无法访问服务端了。
切换到 redis 目录下运行:
redis-cli.exe -h 127.0.0.1 -p 6379
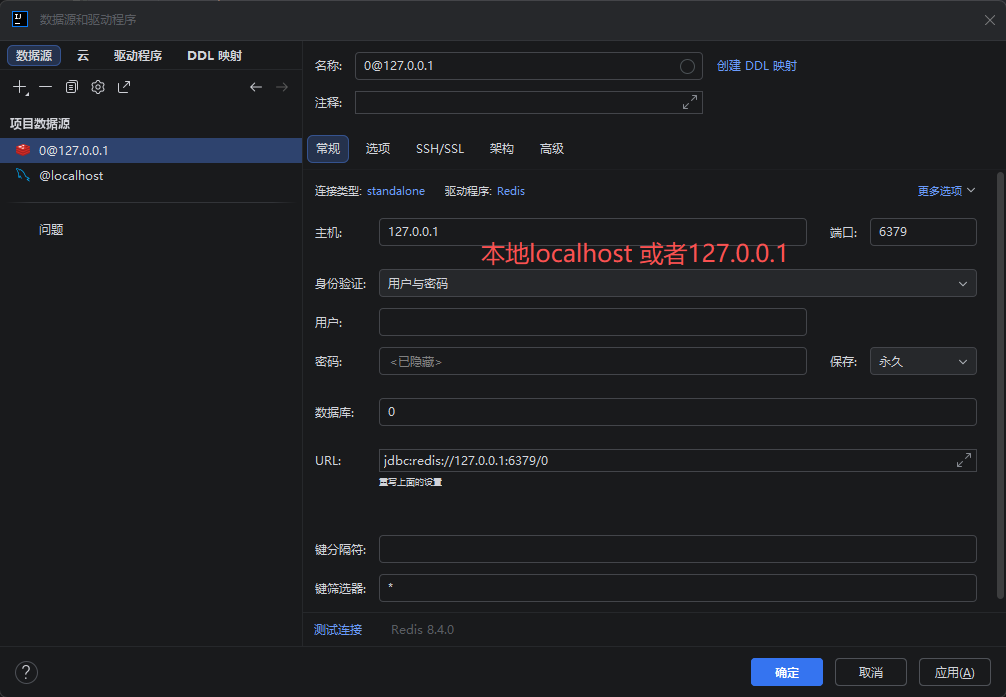
IDEA配置redis: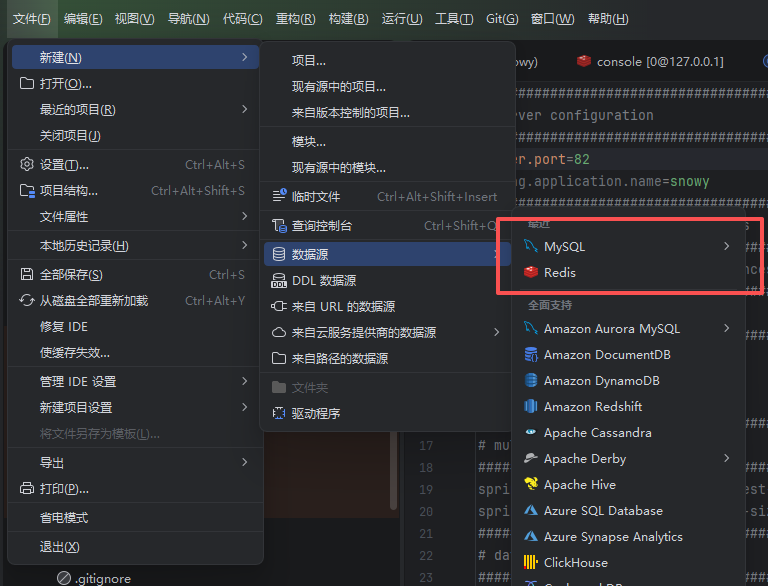
4 MYSQL
配置 环境: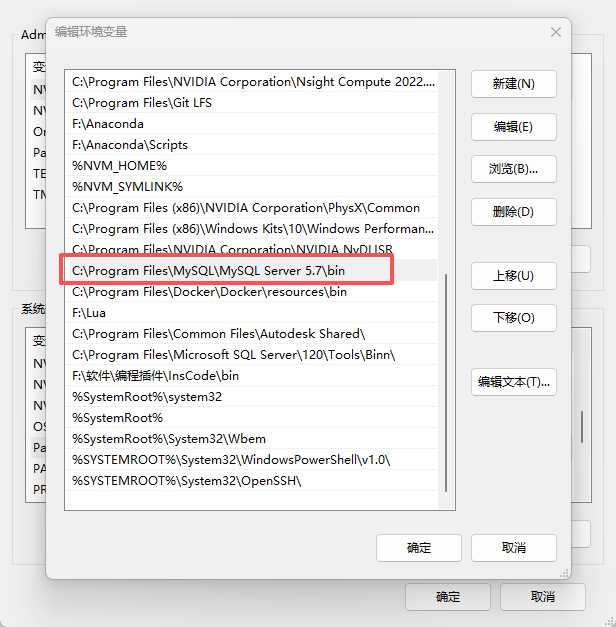
首先确保 开启mysql服务: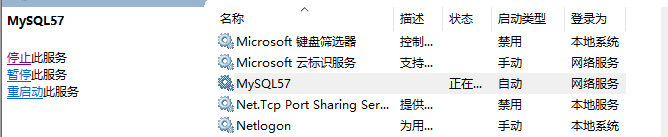
查看 mysql successful安装
命令行查看:mysql -u root -p
或者: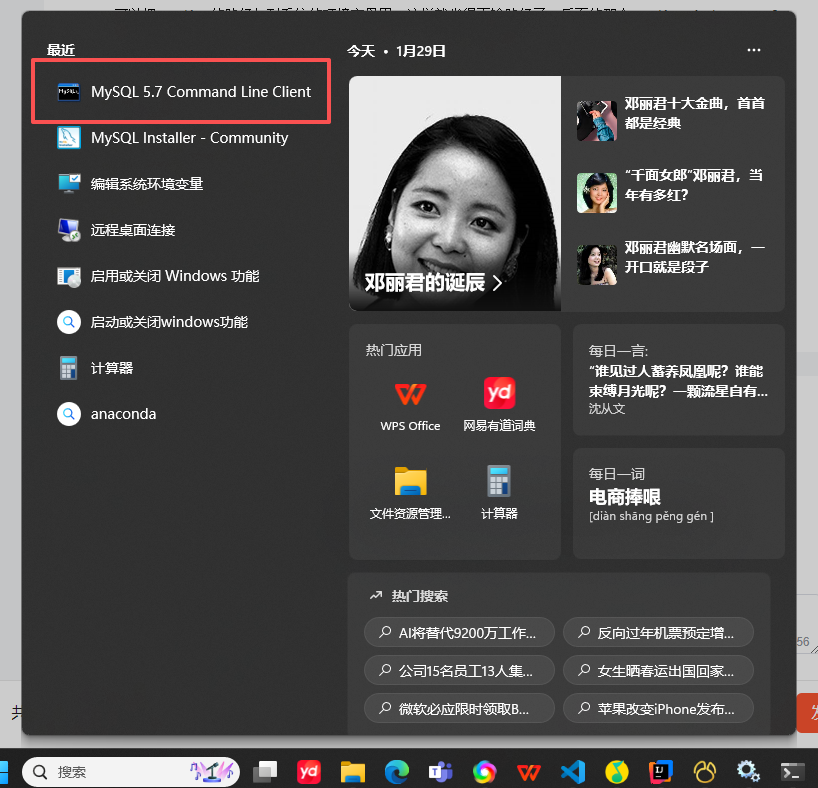
点击输入密码
弹出 :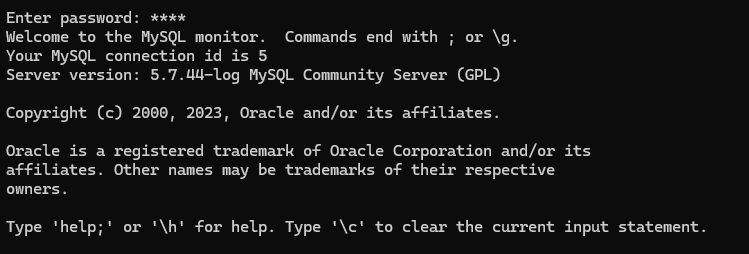
修改密码:
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'your_new_password';
显示:
Query OK, 0 rows affected (0.00 sec)
退出:
mysql> EXIT
5 Navicat
创建 数据库 :
-
选择字符集:
- UTF-8(
utf8或utf8mb4):适用于多语言环境,utf8mb4是推荐选项,因为它支持更全面的Unicode字符集,包括Emoji表情。 - Latin1(
latin1):适用于包含西欧字符的应用。 - 其他专用字符集:如
gbk(简体中文)、cp932(日本语)、euckr(韩语)等,根据特定语言需求选择。
- UTF-8(
-
选择排序规则:
- 排序规则通常与字符集相关联,如
utf8mb4_unicode_ci、utf8mb4_general_ci等。 ci(case-insensitive)表示不区分大小写,cs(case-sensitive)表示区分大小写,bin(binary)表示二进制比较。- 例如,对于多语言文本,
utf8mb4_unicode_ci是一个好的选择,因为它基于Unicode标准进行排序和比较,可以较好地处理多种语言。
- 排序规则通常与字符集相关联,如
导入sql文件 :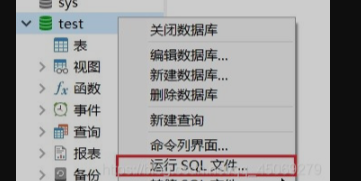
sql查询:
--查询表中所有数据 select * from 表名;
--查询users表中年龄在18~25岁之间的记录
--方式1 between..and..
select * from users where age between 18 and 25;
--方式2 &&
select * from users where age>=18 && age<=25;
--方式3 and
select * from users where age>=18 and age<=25;
--查询users表中年龄为18,20,25岁的记录
--方式1 or
select * from users where age=18 or age=20 or age=25;
--方式2 in
select * from users where age in (18,20,25);
--查询users表中年龄为23,性别为女,名字为小楠的记录
select * from users where age=23 and gender='女' and name='小楠';
--查询users表中序号不为空的记录
select * from users where id is not null;
--查询user表中序号为空的记录
select * form users where id is null;
_:单个任意字符
%:多个任意个字符
--查询users表中姓名第一个字为李的记录
select * from users where name like '李%';
--查询users表中姓名第二个字为李的记录
select * from users where name like '_李%';
--查询users表中姓名含有李字的记录
select * from users where name like '%李%';
--查询users表中姓名是两个字的记录
select * from users where name like '__';
--查询users表中所在城市不相同的记录
--select distinct 字段 from 表名;
select distinct city from users;
排序:
--查询users表中记录,并以年龄升序排序
select * from users order by age;
--查询users表中记录,并以年龄降序排序
select * from users order by age desc;
--查询users表中记录,并体育成绩降序,年龄降序
select * from users order by PE desc, age desc;
计算和、最大值、最小值、平均值、个数:
select sum(字段) (as sumvalue) from 表名;
select max(字段) (as maxvalue) from 表名;
select min(字段) (as minvalue) from 表名;
select avg(字段) (as avgvalue) from 表名;
select count(字段)(as totalcout) from 表名;
分组查询(group by)
--查询users表中的记录,按照性别分组,查询男,女的体育成绩平均分
select gender,avg(PE) from users group by gender;
--查询users表中的记录,按照性别分组,分别查询男、女的体育成绩平均分,人数
select gender,avg(PE),count(id) from users group by gender;
--查询users表中的记录, 按照性别分组,分别查询男、女的体育成绩平均分,人数 要求:分数低于60分的人,不参与分组
select gender,avg(PE),count(id) from users where PE>60 group by gender;
--查询users表中的记录,按照性别分组,分别查询男、女的体育成绩平均分,人数 要求:分数低于60分的人,不参与分组,分组之后,人数要大于2个人
select gender,avg(PE),count(id) from users where PE>60 group by gender having count(id)>2;
分页查询(limit v; n; 限度 限制 极限 )
--查询users表中的前10行条记录
select * from users limit 10;
--查询users表中第2~11条记录 (从第2条记录开始累加10条记录)
select * from users limit 1,10;
--查询users表中第5~17条记录 (从第5条记录开始累加13条记录)
select * from users limit 4,16;
内连接查询:
--语法1 (隐式内连接)
select 字段1,字段2...
from 表1,表2...
where 过滤条件;
--语法2 (显式内连接)
select 字段1,字段2...
from 表1 inner join 表2 ...
on 过滤条件;
外连接查询 :
左外连接:是表1和表2的交集再并上表1的其他数据
右外连接:是表1和表2的交集再并上表2的其他数据
--左外连接
select 字段1,字段2..
from 表1 left outer join 表2 on 过滤条件;
--右外连接
select 字段1,字段2..
from 表1 right outer join 表2 on 过滤条件;
子查询:
select username from user where age =( select avg(age) from userInfo )
例如:要查询工资大于10号部门的平均工资的非10号部门的员工信息
查询10号部门的平均工资
select avg(sal) from emp where deptno = 10;
那么工资大于10号部门的平均工资的非10号部门的员工信息为
select * from emp
where deptno!=10 and sal>(
select avg(sal)
from emp
where deptno = 10;
)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)