多模态-5 BLIP2
BLIP2是一种创新的多模态模型,通过插入QueryFormer(Q-Former)模块实现预训练图像编码器和语言大模型的高效对接。该模型采用两阶段训练:首先进行视觉-文本表示训练,通过ITC、ITM和ITG三种任务学习图像与文本的语义对齐;随后进行视觉-文本生成训练,将提取的视觉特征转换为语言模型的软提示。这种方法避免了从头训练编码器,支持灵活替换不同图像/文本编码器,显著提升了模型效率和灵活性
这篇文章介绍多模态模型-BLIP2
Transformer相关介绍可以看:深度学习基础-5 注意力机制和Transformer
多模态基础知识点可以看:多模态-1 基础理论
BLIP相关介绍可以看:多模态-3 BLIP
语言大模型生成任务的软提示(Prompt tunning)训练可以看:大模型训练-流水线并行/张量并行/ZeRO/Prefix/Prompt tunning/LoRA
BLIP2原论文-《BLIP-2: Bootstrapping Language-Image Pre-training
with Frozen Image Encoders and Large Language Models》
一 模型结构
以往的多模态模型都需要从头训练图像编码器和文本编码器,然后通过精心设计的模态对齐方法,将图像编码结果和文本编码结果映射到同一个语义空间中,再进行下游的多模态任务,这种方法训练耗时且得到的模型体积过大。
BLIP2基于适配器的思想,在已训练完毕的图像编码器和文本编码器之间插入一个Query Former(Q-Former),利用Q-Former对齐图像编码器和文本编码器的编码表示,无需从头训练图像编码器和文本编码器,只训练Q-Former就可以,这样就可以随意更换不同的图像编码器和文本编码器,赋予多模态模型更多的自由,整体如下图所示:
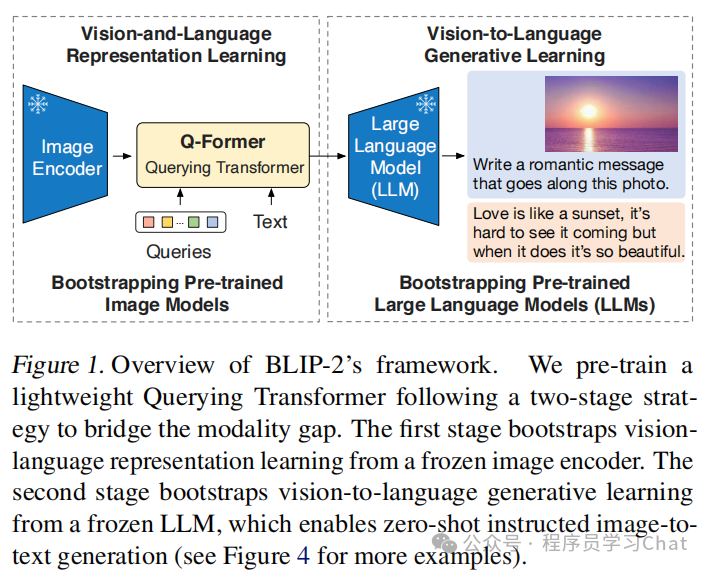
如上图所示,BLIP2将图像输入到已训练完毕的图像编码器(Image Encoder),获取图像对应的编码表示,将图像编码表示、可学习的查询向量(Queries)、用户输入的问题(Text)输入到Q-Former中,Q-Former根据这些输入信息从图像编码表示中获取和当前问题最相关的编码表示向量,作为文本生成任务的一种软提示,将这些软提示和用户输入的问题输入到一个语言大模型(LLM)中,LLM根据这些信息给出问题的回答。





二 训练过程
BLIP2的训练重点是Q-Former,Q-Former的训练分为两个阶段:
1)视觉-文本表示训练:基于BLIP的多任务学习训练方法,BLIP2让Q-Former生成语义对齐的<图像-文本>编码表示,从输入图像中提取出与文本最相关的视觉信息
2)视觉-文本生成训练:让Q-Former输出能够指导语言大模型的特征编码软提示
2.1 视觉-文本表示训练
整体结构如下:
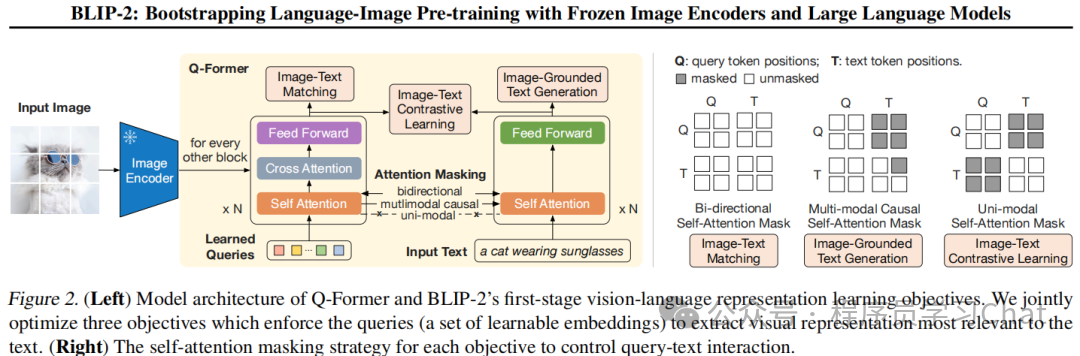
1.从训练数据集中获取一个batch的<图像,图像文本描述>训练数据
2.利用已经训练好的Image Encoder对图像进行特征编码表示
3.将图像文本描述输入到Q-Former中进行文本特征编码表示
4.基于注意力计算,Q-Former融合图像特征编码表示、可学习的查询向量(Learned Queries)、文本特征编码表示的信息,从图像特征编码表示中生成出和文本特征编码表示最相关的特征
5.计算ITC(Image-Text Contrastive)任务的损失

6.计算ITM(Image-Text Matching)任务的损失

7.计算ITG(Image-grounded Text Generation)任务的损失

8.根据三个任务的损失,反向传播训练Q-Former
要注意一些细节:
Q-Former中可学习的查询向量、文本编码表示是同时输入到一个自注意力层(Self Attention)中进行注意力计算的,只不过不同的训练任务注意力掩码mask不同,上图最右侧展示的就是不同任务的具体mask机制,其中灰色表示计算注意力时相关数据被mask掉,白色表示保留,参与自注意力计算:
1)对于ITM任务使用的是Bi-directional Self-Attention Mask,这时所有查询向量、文本编码表示都互相可见,查询向量可以充分融合文本编码表示的信息,最终ITM将融合了文本编码表示信息的查询向量输入到分类层,判断<图像-图像文本描述>是否匹配,通过ITM任务让Q-Former学习到细粒度的语义表示;
2)对于ITG任务使用的是Multi-modal Causal Self-Attention Mask,查询向量不可见文本编码表示的信息,而文本编码表示可见查询向量的信息,文本编码表示利用查询向量从图像编码中提取到的信息进行文本生成解码任务,同时,因为是文本生成解码任务,第i个词语的解码生成应只可见前i-1个文本编码表示的信息,避免解码作弊;
3)对于ITC任务使用的是Uni-modal Self-Attention Mask,查询向量和文本编码表示互不可见,查询向量只利用从图像编码表示中提取到的信息,文本编码表示同理,二者进行对比学习损失计算,通过ITC任务让Q-Former学习到粗粒度的全局<图像-文本>语义表示;
2.2 视觉-文本生成训练
整体结构如下:
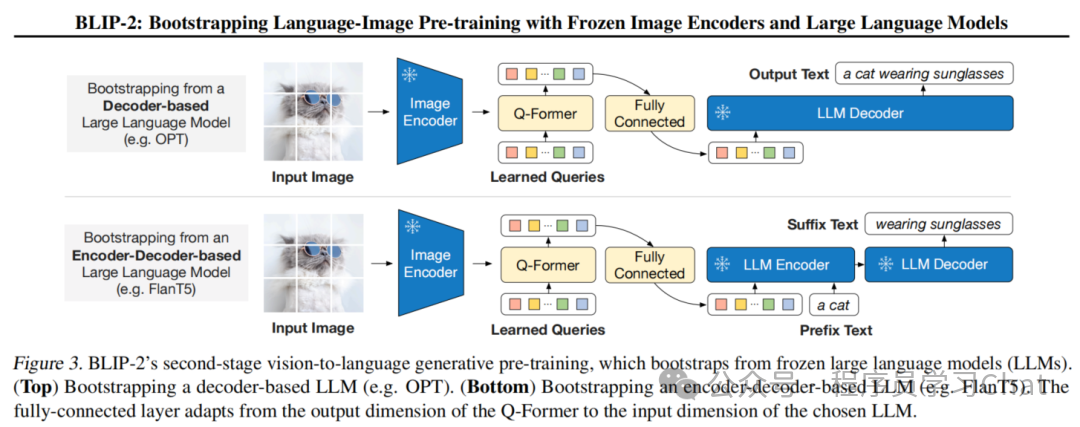
利用已经进行过“视觉-文本表示训练”的Q-Former对输入图像的图像编码表示进行关键特征抽取,将这些抽取到的、能够指导下游语言大模型生成任务的特征输入到一个全连接层(Fully Connected)中进行特征变换,变换为和语言大模型相同的词嵌入维度,然后将这些特征作为一种软提示添加到语言大模型的词嵌入矩阵中,进行模态融合,指导语言大模型的生成任务,计算语言大模型的生成解码损失,反向传播训练Q-Fromer,注意,语言大模型是冻结不参与训练的,可以使用任意的已经训练好的语言大模型。
对于Decoder类型的语言大模型,比如GPT,将软提示添加到词嵌入矩阵中就可以,而对于Encoder-Decoder类型的语言大模型,比如T5,训练时会将文本描述进行随机截取,前半段截取+软提示输入到Encoder中进行特征编码,然后Decoder根据Encoder的输出进行解码。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)