收藏必备!大模型推理性能优化:分形思考框架与实战技巧
MLA(Multi-Head Latent Attention):DeepSeek运用的注意力计算方法,通过双低秩压缩解耦技术(KV 单头的维度压缩至dc=512,Query 的特征维度压缩至dc’=1536),在极速降低 KV Cache 显存带宽压力的同时,通过矩阵吸收的方式保持了 Multi-Head Attention 的计算精度。
本文提出大模型推理优化的分形思考框架,在宏观、中观、微观各层级遵循"看清楚-避免浪费-提升利用率-节约资源"的统一逻辑。通过分析算力、显存、显存带宽、通信带宽四大资源瓶颈,结合DeepSeek等模型实践,展示了如何系统性地优化大模型推理性能,包括PD分离、算子融合、量化压缩等技术,有效提升资源利用率并降低推理成本。
1、引言:推理优化的分形本质与思考框架
在自然界中,分形几何描述了某种结构在不同尺度上表现出自相似性的规律,比如海岸线的曲折、雪花的结晶、植物的枝叶与果实莫不如此。

在计算机科学与AI领域,尤其是大模型推理领域,同样可以观察到分形规律。类似很多领域的性能优化,大模型推理优化也须深入了解所依赖的硬件。我们发现核心矛盾始终是各硬件资源的不足与不均衡,这两个矛盾在不同层级上反复重演。比如:
- 宏观层级(集群): 例如Prefill节点(计算密集)与 Decode节点(访存密集)配比不合理导致的资源闲置;
- 中观层级(单机/卡/推理框架): 典型例子是GPU卡上的MoE 专家负载不均匀,导致在推理过程中某些卡算力闲置;推理框架上并行策略不合理或者CPU调度导致GPU有空泡。
- 微观层级(算子): Decode 阶段单 Token 计算量仅为 Prefill 阶段的 1/(s)(s为输入序列长度),算力需求低,但推理过程中的注意力计算部分需大量 KV Cache 反复参与读写,显存带宽成为数据搬运的核心瓶颈。
说到硬件资源不匹配,就会涉及硬件资源的定义,范围可大可小。以GPU为例子,GPU包含了很多硬件单元,比如英伟达H20里有不少SM,SM里又包括很多的CUDA Core、Tensor Core、Warp(线程束)、寄存器、L1缓存/共享内存、L2缓存、HBM显存、NVLink/NV Switch等,层层拆解,可以很细。
尽管硬件资源五花八门,但问题是类似的,依然是各种硬件资源之间的不足与不均衡, 比如微观一些的Flashattention3,其实会涉及到Warp、寄存器、L1缓存、共享内存、Tensor Core、L2缓存、HBM显存读写带宽等诸多资源,如果某种资源先达到瓶颈,导致其他资源利用率低,就存在优化机会。
本文参考大自然的分形规律,梳理和沉淀了大模型推理优化的分形思考框架,暂时先忽略各种细分的硬件单元,抽象并聚焦以算力、显存、显存带宽、通信带宽四大资源作为分析对象,在各层级分析瓶颈点以及不均衡的情况。因为各层形状(思路)一致,所以不容易遗漏。核心步骤如下:
看清楚:结合模型结构和推理过程,计算或采集与分析资源的需求量和瓶颈点;
避免浪费:比如消除不必要的Kernel Launch、算子冗余、数据重复搬运,让资源聚焦用于核心计算;
提升利用率:通过并行策略调优、负载均衡调度,通信优化等方式,减少四大资源的不匹配程度;
节约资源:在精度几乎无损前提下,通过量化、稀疏化、算子创新等手段减少资源需求量。
下文逐一展开介绍。
2、第一阶段:看清楚——模型架构解析与资源量化
优化的前提是知道问题在哪里,通过建立精确的资源消耗模型,才能分析和识别出瓶颈所在,过往大家更习惯用工具进行 Timeline 分析看问题在哪里,或者局部的理论计算,本文以Deepseek R1/V3为例,尽量呈现较为完整的思路。
2.1 DeepSeek V3/R1 架构解析
2.1.1 关键术语定义
MLA(Multi-Head Latent Attention):DeepSeek运用的注意力计算方法,通过双低秩压缩解耦技术(KV 单头的维度压缩至dc=512,Query 的特征维度压缩至dc’=1536),在极速降低 KV Cache 显存带宽压力的同时,通过矩阵吸收的方式保持了 Multi-Head Attention 的计算精度。
MHA(Multi-Head Attention)是 Transformer 的核心组件,将模型的 Query/Key/Value拆分为多个独立的注意力头,每个头独立计算注意力分数并加权求和,最后拼接所有头的结果,实现更丰富的表征和多视角语义关联。
MoE(Mixture of Experts):是Deepseek的混合专家模型,每个 Transformer 层包含 257 个专家(256 路由专家 + 1 共享专家),单 Token 激活 9 个专家(8 路由 + 1 共享),通过稀疏激活平衡模型容量与计算量。
Prefill 阶段:是自回归 Transformer 模型在推理时,处理整个输入提示词的初始阶段。该阶段位于首次前向传播中,核心任务是并行计算所有输入 Token 的注意力,并将产生的 Key 和 Value 向量写入 KV Cache,为后续的自回归生成( Decode 阶段)做好准备。其核心特征是计算密集、可完全并行、无 Token 间依赖。
Decode 阶段:自回归 Transformer 模型推理时,在 Prefill 之后逐个生成输出 Token 的循环过程。该阶段直接读取并更新 Prefill 所初始化的 KV 缓存,每次前向传播仅计算最新 Token 的注意力与输出,核心特征为内存访问密集、计算量小、具有严格的序列依赖。
并行策略:指大模型部署的时候将模型的计算和存储拆分到多张GPU卡上的方法,主流方法包括TP、EP、DP、SP、CP、PP、CPP等。
TP (Tensor Parallelism):并行策略的一种,将单层内的权重矩阵(张量)切分到多个 GPU 上,通过引入大量的 All-Reduce 通信来换取显存容量和单步计算速度。
EP (Expert Parallelism):并行策略的一种,专门针对 MoE 架构,将不同的专家(Experts)分配到不同GPU卡上,Token 根据路由结果在GPU间进行 All-to-All 交换。
DP (Data Parallelism):并行策略的一种,将不同的输入样本(Batch)分给不同的GPU卡,主要用于扩大吞吐量。
SP (Sequence Parallelism):并行策略的一种,将序列在输入序列维度上切开,常与 TP 结合使用,目的是为了解决长输入带来的显存压力。
CP (Context Parallelism):并行策略的一种,更高级的长文本并行,通常在 Attention 计算层面做跨卡切分。
PP (Pipeline Parallelism):并行策略的一种,按模型的层进行横切,不同层运行在不同GPU卡上,像流水线一样传递中间结果。
CPP:CP与PP的混合并行策略,在流水线并行基础上嵌入上下文并行,多用于超大规模集群下的超长序列训练/推理。
并行度:指某类并行策略下,参与该并行的 GPU 数量,是衡量并行规模的核心指标,比如TP8或者EP8。
四大资源指标:算力(本文例子用FP8峰值算力)、显存(GPU 物理显存容量)、显存带宽(GPU 显存读写速率)、通信带宽(跨卡/ NVLink/IB 传输速率)。
TTFT (Time To First Token):指从用户输入提示(Prompt)开始,到模型生成第一个输出token所需的时间。
TPOT (Time Per Output Token):TPOT 指的是模型在生成阶段,平均每个输出Token所花费的时间。TPOT 衡量的单Token生成的延迟情况,与吞吐量(Tokens Per Second, TPS)成反比(TPS = 1 / TPOT)。
Rank:在分布式并行计算中,唯一标识一个处理单元(通常是GPU)的编号或索引。
MFU:是 Model FLOPs Utilization(模型浮点运算利用率)的缩写。
2.1.2 DeepSeek 模型核心参数与推理流程
模型参数解析
DeepSeek R1/V3 拥有671B 总参数,但通过 MoE(混合专家)架构实现了单 Token 激活仅 37B 参数,激活量并不大。
其核心组件包括:61层 Transformer,前3层为稠密 FFN,后58层为 MoE 结构,核心参数如下表所示:
| 模块 | 关键参数 | 参数规模 |
| 整体架构 | 61层Transformer,前3层稠密层 + 后58层MoE层 | 总参671B,激活37B |
| 嵌入层/输出层 | dmodel=7168,词表V≈129280 | 嵌入层≈0.93B,dmodel是隐藏层维度 |
| MLA注意力层 | 总头数128,dhead=128,低秩压缩(dc=512) | 11.4B(推导过程参见附录C),dhead单注意力头维度,dc是KV压缩维度 |
| 稠密FFN(前3层) | 中间层维度18432(2.57×dmodel),无稀疏激活,3 * [7168, 18432] | ~0.396 B |
| MoE层(后58层) | 257个专家(256路由+1共享),激活专家数k=9,3 * [7168, 2048] * 257 | 单层≈ 11.3 B |
| 专家 | 3 * [7168, 2048] (gate_pro、up_proj、down proj ) | 单个专家:0.044 B |
671B是这么来的:
671 ≈ 0.93*2(嵌入层/输出层)+ 11.4(MLA注意力层)+ 0.396(稠密FFN)+ 11.3*58(MoE)+ Gate/Layernorm(很小)
推理过程解析
推理过程分为 Prefill 与 Decode 两个差异很大的阶段:
Prefill 阶段
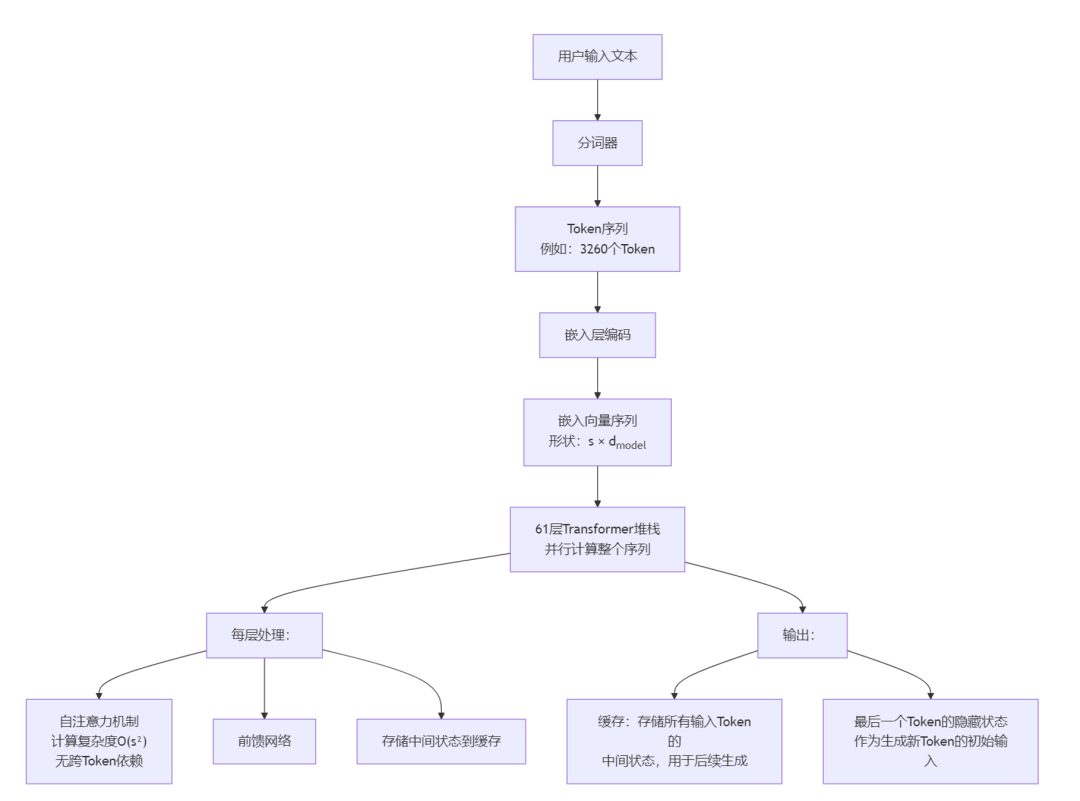
核心任务:一次性计算输入序列(如3260 Tokens)的隐藏状态,初始化KV缓存。
关键特征:批量处理长序列,计算密集,因为Attention为O(n²),无跨 Token 依赖。
输出:KV缓存(存储所有输入 Token 的K/V潜向量)+ 最后一个token的隐藏状态。
流程如下:
用户输入→分词→嵌入层编码→61 层 Transformer 计算(层内并行)→生成 KV Cache + 最后一个 Token 隐藏状态;
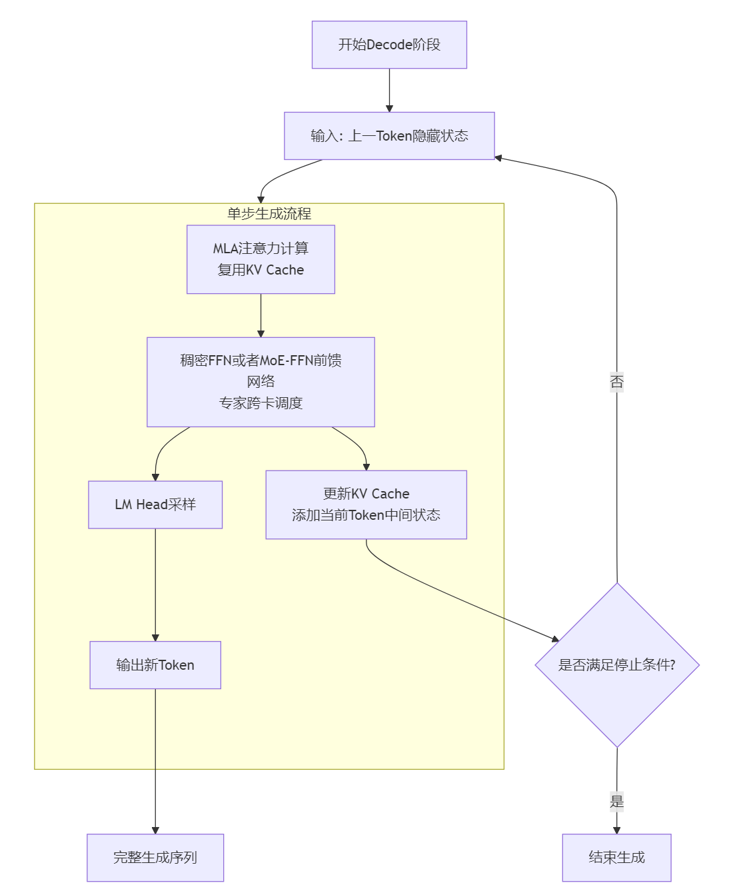
Decode 阶段
核心任务:基于 KV Cache 和上一 Token 输出,迭代生成新 Token。
关键特征:单 Token 串行计算,通信敏感( MoE 专家跨卡调度),依赖KV Cache复用。
输出:新 Token + 更新后的KV Cache。
流程如下:
上一 Token 隐藏状态→ MLA(复用 KV Cache)→MoE-FFN→LM Head 采样→更新 KV Cache→重复至停止条件。
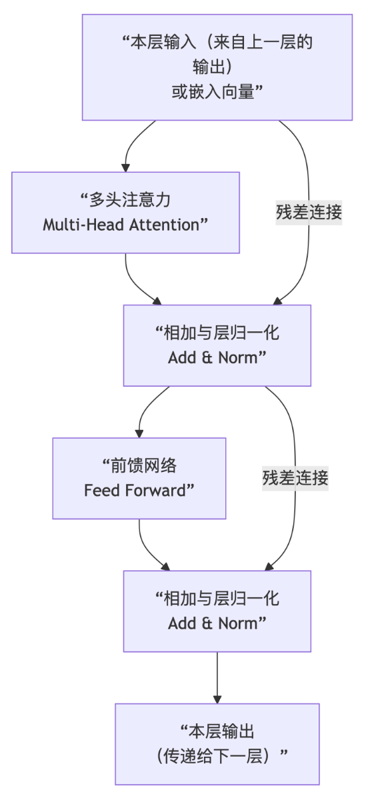
下图对注意力和 FFN 过程做一个展开解读,其实就是一个标准的Transformer 架构的解码器的内部核心计算流程:
2.2 四大资源的选择思路
看清楚模型结构和推理过程之后,我们需要评估哪些硬件资源容易出现瓶颈,但硬件资源类型非常丰富,如何选择呢?
从实践中看,算力、显存、显存带宽、通信带宽的使用情况不论在宏观层面还是微观层面,都会涉及并被仔细考虑,因此本文以四大资源作为核心要分析的部分。另外人们观察分形现象的时候也习惯是从最大最显眼的地方开始然后到更细微的形状。
下表总结了四大资源的单位以及需要观测的指标:
| 资源类型 | 单位 | 相关评估指标举例 | 经验阈值 |
| 算力 | 计算量(TFLOPs) | MFU = 实际算力 / 峰值算力(H20 FP8 峰值算力296 TFLOPs) | MFU<60%,算力未饱和,需提升并行度/BatchSize等 |
| 显存 | 单卡总占用(GB) | 权重 + KV Cache + 激活值 + 系统预留 + cudagraph占用(~10GB / 卡) | >85%,易触发 OOM,需压缩/复用存储 |
| 显存带宽 | GPU 核心访问其自身显存(HBM)所能达到的稳定数据传输速率上限,单位是 GB/秒。 | 显存读写量 / 带宽 ÷ 计算量 / 峰值算力 | >0.5,访存主导延迟,需算子融合、算子流程优化等 |
| 通信带宽 | 这里主要考虑机内或者机间的卡与卡的通信带宽,单位是GB/秒 | 通信量 / 网络带宽 ÷ 计算量 / 峰值算力 | >0.5,通信制约吞吐,需优化并行策略、减少通信量 |
表一:四大资源评估表
2.3 四大资源分析与测算公式
接下来看看具体怎么测算。
2.3.1 算力分析
算力计算公式
根据 Deepseek 的特点,模型推理包括非注意力部分和注意力部分。虽然 MHA 的 KV Cache 压力大,但考虑到要优先缩短首字延迟 (TTFT),所以注意力部分在 Prefill 阶段用计算量更少的 MHA ;Decode 阶段因为显存以及显存带宽更容易成为瓶颈,所以采用MLA。
注:本文的计算评估和选型分析都是基于一个很多团队都使用的3260 Tokens长度的测试集。
MHA(Multi-Head Attention)是 Transformer 的核心组件,将模型的 Query/Key/Value拆分为多个独立的注意力头,每个头独立计算注意力分数并加权求和,最后拼接所有头的结果,实现更丰富的表征和多视角语义关联。
如下是各部分公式的展开介绍:
-
非注意力部分(MoE + 稠密 FFN ):
Flopsnon-Attn ≈ 2×激活参数量×bs/10243 GFlops(公式一)
说明:
1)b=BatchSize;s=序列长度;DeepSeek总激活参数量 37B ,这里只包括非注意力部分,是25.6 B 。
2)大模型推理中的线性层计算(如 FFN、投影层)本质上是矩阵乘法 ,所以可以用上述公式大约测算。
-
MHA注意力计算:
FlopsMHA = NLayer×2bs’nheads(2dh + dR)s/10243 GFlops(公式二)
说明:
1)dh为注意力头维度,Deepseek MHA是128。
2)s’是输入长度的1/2,核心原因 DeepSeek 是一个自回归模型,推理时必须遵守“不能预知未来”的规则,当前Token不能与未来的Token产生相关性,但可以与过去的Token产生相关性。
3)MHA一般用于Prefill阶段(假设已经PD分离),虽然KV Cache占用大,但是计算量比MLA小,有利于缩短TTFT。
-
MLA注意力计算:
MLA的魅力在于通过低秩压缩以及结合律方式,只牺牲一部分算力就可以换取极大的显存与显存带宽的节省。
FlopsMLA = NLayer×2bs’nheads(2dc + dR)s/10243 GFlops(公式三)
说明:
1)s’ = KV Cache 长度,Prefill阶段为平均 KV Cache 长度;dR = 解耦的 RoPE 维度,Deepseek 是64;NLayer = 61
2)MLA 一般用于 Decode 阶段(假设已经PD分离),因为希望显存占用大幅缩小
因为不同阶段注意力采用的计算方式不同,所以 Prefill 阶段和 Decode 阶段的算力测算公式会不同。
-
Prefill 阶段算力:
FlopsPrefill= Flopsnon-Attn + FlopsMHA(公式四)
-
Decode 阶段单Token算力:
FlopsDecode= Flopsnon-Attn + FlopsMLA (公式五)
资源瓶颈分析与典型场景估算
下表以我们经常测评的3260输入为例子,假设权重和计算精度都是FP8,只有1 Batch 情况下的算力测算如下:
| 阶段 | 核心计算模块 | 计算量(GFLOPs) | 占比 | 备注 |
| Prefill | 非注意力部分 | 166912 | 86.3% | 激活参数25.6B |
| 注意力部分(MHA) | 26569 | 13.7% | 11.4B 这里s’=3260/2 | |
| 小计 | 193481 | 100% | ||
| Decode | 非注意力部分 | 51.2 | 44% | s=1 Token |
| 注意力部分(MLA) | 65.1 | 56% | s=1 Token 这里s’=3260+550 | |
| 小计 | 每token | 116.3 | 100% |
表二:3260输入长度场景的算力评估
可以看出:
1)Prefill 阶段非注意力计算量是大头,一张 H20 FP8 算力只有296 TFlops ,一个请求就占了一半以上的算力,几个请求同时进来就会使得 TTFT 明显变长。
2)Decode 阶段,单Token的算力要求不高。
如果业务团队要评估 H20 每卡32并发,平均输入长度在3260,且吐字速率要 50 Tokens/秒是否可行, 算力角度大概可以这么算:116.3/296/1024*50*32 = 0.614秒, 如果算力MFU低于60%,就比较挑战了,要想办法减少单卡上的计算量,比如 EP 或 TP 并行。
2.3.2 显存占用分析
显存占用计算公式
显存一般包括:权重 + KV Cache + 激活值 + 其他(系统预留 + Cudagraph占用,约 10GB / 卡)
-
模型权重显存(Dense部分 FP8 / MoE W4A8 量化):
Memweight-W4A8 ≈ Sizedense/TP + SizeMoE/2/EP GB(公式六)
说明:
1)Sizedense =14GB;SizeMoE =657GB,除以2是因为W4A8
2)TP是张量并行度, EP是专家并行度。
-
KV Cache 显存( FP8 ):
MemKV = b×(sinput + soutput)(dc + dR)/10243(公式七)
说明:
1)sinput = 输入长度,soutput = 输出长度,单Token占用576字节
- dc 是 KV 压缩维度 512,dR 是 RoPE 维度 64
3)除以10243,是为了以 GB 为单位表示。
4)这里KV Cache的维度采用 MLA 的方式,K 与 V 压缩在一起。
-
激活值占用估计:
Memact ≈ Memlinear+Memattention_score+MemFFN(公式八)
-
Memlinear 指 Transformer 层中 Query、Key、Value 的投影层以及输出投影层(O 矩阵)等产生的中间状态显存占用
-
Memattention_score指计算 Attention 时产生的 QKT得分矩阵。
-
MemFFN 指 FFN 层(在 DeepSeek 中包括稠密 FFN 和 MoE 专家层)中间神经元激活产生的显存占用。
-
激活值与算子写法密切相关,情况比较多,这里参考的是过往没有充分优化的情况,不代表现状,另外MLA过程和MHA过程激活值也有差异:
-
MLA过程:
Memact-MLA ≈ ((bsdqc + bs(dc+dR) + bsdmodel ) + 2bnheadss’×s + 2bskdmoe-inter+ bsdmodel)/10243(公式九)
说明:
1)注意力分数一般是BF16,所以2乘以 bnheadss’×s
2)dqc 是 Query 压缩维度 1536。
3)理论上每一层都有Q、K、V、Score、Score@V、O、FFN的gate、Up-projection、Down-projection计算和临时结果。
4)MLA通过矩阵结合律以及低秩操作省掉了一些中间输出,比如K和V压缩在一起,不产生传统高维的Score@V的操作,而是在低秩空间加权混合,再统一上投影还原并输出O。
5)这里假设的是算子融合与优化不充分的情况, 比如H20的L1/共享内存/L2使用不充分等情况。
6)因为每一层算完之后基本不保留,所以显存大小的测算上没有必要乘以 NLayer。
7)前三层稠密FFN的中间维度是18432,MoE 的是2048, 正好是9倍关系,所以就用kdFFN预估峰值情况,k=9,即专家不巧都集中在一张卡上。
8)s’ 是 KV Cache的长度;Decode 阶段,s=1。
9)MLA 过程一般用在Decode阶段
10)除以10243,是为了以G为单位表示。
11)看着复杂,但 Decode 过程激活值显存占用不高,如果3260 KV Cache 长度,1 Batch 情况下,输出1 Token的推理过程,优化不好的情况下,激活值占用大概在0.0008GB,可以忽略不计。
-
MHA过程:
Memact-MHA ≈ (5bsdmodel + 2bnheadss2 + 2bskdmoe-inter + bsdmodel)/10243(公式十)
说明:
1)s是输入 Token 的长度;bnheadss2表示注意力分数的显存占用 。
2)bsdmodel的系数5是估算,主要考虑Q、K、V、Score@V、O的计算
3)前三层稠密FFN的中间维度是18432,MoE 的是2048, 正好是9倍关系,所以就用kdFFN预估峰值情况,k=9,即专家不巧都集中在一张卡上。
4)bsdmodel 指单层计算完成后,为了进行残差相加而保留的那份原始输入状态。
5)MHA 过程一般用在 Prefill 阶段。
6)除以10243,是为了以G为单位表示。
-
单卡总显存:
Memtotal ≈ Sizedense/TP + SizeMoE/2/EP + MemKV + Memact + 10GB(公式十一)
说明:
1)Memact 为激活值占用,如果是MLA过程,就采用Memact-MLA,MHA过程则采用Memact-MHA。
2)假设Dense部分采用TP并行,MoE部分采用EP并行策略。这里 TP 表示张量并行度; EP 表示专家并行度。
显存资源瓶颈分析与典型场景估算
下表以我们经常测评的3260输入为例子,假设 Attention 权重和计算精度都是FP8,MoE 权重做了 INT4 量化,在只有1 Batch 的情况下显存使用测算如下:
| 核心分类 | 估算依据 | 显存占用量(GB) | 备注 |
| 模型权重(FP8) | 671 B 字节 | ~671 | 一张H20放不下 |
| 模型权重 (Attention FP8/MoE W4A8) | (14+657/2) B 字节 | ~342.5 | 权重量化为W4A8,所以657/2; 14B 是 Dense 部分的参数规模,主体是Attention。 |
| KV Cache(MLA) | NLayerbs(dc+dr) | 0.112 | 1 Batch下的数据,s=3260 |
| 激活值(MLA) | 参考公式九 | ~0.0008 | 1 Batch/FP8精度/Decode 1 Token条件下,平均单层的激活数据 |
| 激活值(MHA) | 参考公式十 | ~****2.78 | 1 Batch/FP8精度/Prefill 3260 Tokens条件下,平均单层的激活数据 |
| 其他 | 通信缓冲区、系统预留、内存池管理、框架与运行时开销、Cudagraph占用 | ~10 | 每卡 |
表三:3260输入场景显存使用评估
可以看出:
1)显存中,模型权重占比较大;
2)采用MLA之后,KV Cache的占用比较小,但高Batch长输入情况下、显存也容易成为瓶颈。
2.3.3 显存带宽占用分析
如果显存读写量大,且显存带宽瓶颈出现的时候,其他资源就可能浪费,利用率变低。
显存读写量计算
IOtotal = IOweight + IOKV + IOact(公式十二)
说明:推理阶段显存读写总量,包含权重、KV Cache、激活值的读写开销。
各分项计算:
-
权重读写量 IOweight:
Prefill阶段:IOweight ≈ Sizedense/TP + (SizeMoE/257×k)/2 GB(公式十三)
Decode阶段:IOweight ≈ (Sizedense/TP + (SizeMoE/257×k)/2) ×s GB(公式十四)
说明:
1)(SizeMoE/2)/257×k,除以2是因为W4A8。
2)k分两种情况看,最不均衡和均衡的情况。
最不均衡情况:k = 1 + 8(一个共享专家加上8个路由专家),峰值情况9个专家都在一张卡上;
平均情况:k = 1 + 8/EP。
3)TP是张量并行度,EP表示EP并行度。
4)权重读写量与 Batchsize 没有正相关性,Batchsize 大一些反而划算,一次读取,批量使用。
5)公式中的s是输出Token的长度。
-
KV Cache读写量 IOKV:
IOKV = NLayerbs(dc+dr)/10243 GB(公式十五)
-
激活值读写量 IOact:
显存占用大小和层数关系不大,但是显存读写量和层数关系很大,这里分别看一下Prefill和Decode的显存读写量。
1)Prefill阶段激活值读写量:
IOact ≈ (MemLinear+MemMHA_score+MemFFN) × 2 GB(公式十六)
乘以2是因为读写各一次。
激活值与算子写法与优化程度密切相关,这里估算按某些没有优化的情况进行。
MHA过程:
MemLinear ≈ NLayer×5bsdmodel/10243 GB(公式十七) MemMHA\_score ≈ NLayer×2bnheadss2/10243 GB(公式十八) MemFFN ≈ NLayer×(2bskdmoe-inter + bsdmodel)/10243 GB(公式十九)所以 IOact ≈ NLayer×(5bsdmodel + 2bnheadss2 + 2bskdmoe-inter + bsdmodel)×2/10243 GB(公式二十)
2)Decode阶段激活值读写量
IOact ≈ (Memlinear+MemMLAscore+Memffn)×s×2(公式二十一)
Decode阶段用MLA注意力过程:
MLA过程:
MemLinear ≈ NLayer×(bsdqc + bs(dc+dR) + bsdmodel)/10243 GB(公式二十二) MemMLA\_score ≈ NLayer×2bnheadss's/10243 GB(公式二十三)(注意力分数是BF16) MemFFN ≈ NLayer×(2bskdmoe-inter + bsdmodel)/10243 GB(公式二十四)所以 IOact ≈ NLayer×((bsdqc + bs(dc+dR) + bsdmodel ) + 2bnheadss’s+ (2bskdmoe-inter + bsdmodel))×2/10243 GB(公式二十五)
说明:
1)s=1,s’=KV Cache 长度,dqc=1536
显存读写瓶颈分析与典型场景估算
Decode 比 Prefill 阶段的显存读写耗时占比高,显存带宽瓶颈容易出现,参考下表:
| 场景 | 估算依据 | 显存读写大小 (GB) | 显存读写 耗时 (秒) | 推理计算耗时 (秒) | 显存读写耗时**/** 推理计算耗时 |
| 1 Batch Prefill (TP8+EP8) | 公式十二 | 352.5 14/8+657/2/257*9+0.11+2.78*61*2 | 0.088 | ~0.58 推导一 | 0.15 |
| 1 Batch Decode (DP8/TP1/EP8) | 公式十二 | 25.7 14+657/2/257*9+0.11+0.0008*61*2 | 0.0064 | ~0.000383 推导二 | 16.7 |
| 32 Batches Decode (DP8/TP1/EP8) | 公式十二 | 32.15 14+657/2/257*9+0.11*32+0.0008*61*2*32 | 0.008 | ~0.000383 (理想情况,算力足够并行,不考虑调度和SRAM资源受限等因素) | 20.1 |
表四:3260输入场景显存读写量与耗时评估
推导一:(26.6/8+166.9)/296=0.58
26.6是 Prefill 阶段1 Batch 3260输入条件下 Attention 部分的计算量(单位 TFlops ),可以参考表格二或者通过公式四推导出来,除以8是因为TP8;
166.9是 Prefill 阶段1 Batch 3260输入条件下 FFN(包括稠密和 MoE )的计算量(单位 TFlops ),假设最不均衡的情况,所有 Tokens 都路由到了同一张卡上(当然这是个近似估计, 因为前三层是按 TP8 切分)。166.9可以参考表格二或者通过公式四推导出来。
推导二:(65.1+51.2)/296/1024=0.000382
65.1是 Decode 阶段1 Batch 3260+550 KV Cache 长度下 Decode 1 Token 时 Attention 部分的计算量(单位 GFlops );
51.2是 Decode 阶段1 Batch 3260+550 KV Cache 长度下 Decode 1 Token 时 FFN(包括稠密和MoE)的计算量(单位GFlops)。
为什么3260要加550,是因为我们的评测用例输出平均长度是1100,取一半方便看清楚平均情况。
2.3.4 通信带宽占用分析
这里先假设Prefill的并行策略是TP+EP,Decode的并行策略是DP+TP+EP,其他的并行策略如果要分析,也是类似的方法。
通信量测算公式
-
总通信量:
TrafficTotal = TrafficEP + TrafficTP(公式二十六)
说明:TrafficEP为 EP 并行通信量,TrafficTP为 TP 并行通信量
-
EP 并行通信量:
TrafficEP ≈ NLayer-MoE×2bsdmodel×(k-1)×Precision/10243 GB(公式二十七)
说明:k = 9;Precision = 2(因为BF16);NLayer-MoE = 58;假设都发送到别的卡上
-
TP 并行通信量:
TrafficTP ≈ NLayer×2bsdmodel×Precision×(TP-1)/TP/10243 GB(公式二十八)
说明:TP = 张量并行度;Reduce-Scatter + All-Gather
Reduce-Scatter,每张卡只负责计算一部分(一个分片)的求和结果,每张卡上都只存有一部分完整求和后的数据。
All-Gather,所有的卡把自己负责的那部分求和结果同步给其他所有人,这样每张卡集齐所有分片,拥有了完整的求和结果。
通信耗时测算
以 TP 与 EP 并行为例, 将模型各种静态数据带入:
TrafficEP = 58×2×bs×7168×8×2/10243 ≈ 0.012×bs GB(参考公式二十七)
TrafficTP = 61×2×bs×7168×2×(TP−1)/TP/10243 ≈ 0.00163×bs×(TP−1)/TP GB(参考公式二十八)
TrafficTotal= TrafficEP +TrafficTP ≈ 0.012bs+0.00163bs×(TP−1)/TP GB (参考公式二十六)
1)EP下的一些测算和分析:
EP8并行度下,如果32 Batch,每个Batch传输1个Token,请求的是其他卡上的专家(垮卡不垮机),TimeEP ≈ 0.012bs/900 = 0.0004秒;
EP16并行度下,如果32 Batch,每个Batch传输一个Token,极端情况下全发生了跨机请求,TimeEP ≈ 0.012bs/50 = 0.0077秒;50是机间通信带宽50 GB/秒(假设没有通信损耗);
如果平均分布,一半跨机一半不垮机,TimeEP ≈ 0.012*16/50+0.012*16/900 = 0.004秒;
EP32,均匀分布的情况下,3/4跨机,耗时会比EP16长;TimeEP ≈ 0.012*24/50+0.012*8/900 = 0.0059秒
EP32,如果限制跨机数量不超过2,耗时可能可以缩短到EP16的程度,同时还能节约显存,但因为这种限制,无法选择远端最合适的专家,模型效果上可能会有一些风险,需要验证。
大家普遍认为基于H20用EP32机会不大,原因是跨机通信的概率变大以及H20先天的算力不足。
但是EP32下大Batch的计算效率提升可能可以搬回一些,原因如下:
EP8 32 Batch发送到每张卡,卡里有32个专家, 平均一个专家处理1个Token;
EP16 也是32 Batch发送到每张卡, 卡里16个专家, 平均一个专家可以同时处理2个Tokens;
EP32也是32 Batch发送到每张卡, 卡里8个专家, 平均一个专家可以同时处理4个Tokens;看起来EP32并行度下GPU运算的形状更好,能同时处理更多, 利用率可以上去。当然要看一些核心算子比如Group GEMM利用率提升的空间是否还有,如果已经满了机会就不大。
2)TP下的一些测算:
TP16并行度下,如果32 Batch,每个Batch传输一个 Token ,TimeTP ≈ 0.00163bs×(TP/2−1)/TP/900 + 0.00163bs×(TP/2)/TP/50 = 0.000547秒
通信量瓶颈分析与典型场景测算
Prefill阶段3260输入这个场景下,并行策略的变化,其实是有优化机会,比如:
1)TP8+EP8 相比TP1+EP8的通信耗时增加不多,但是 单卡计算耗时可以下降不少。
2)Prefill阶段的通信计算耗时比偏高(相比 Decode 阶段),如果优化通信耗时或隐藏相当比例,Prefill节点的TTFT与吞吐有提升空间。
参考表五的数据:
| 阶段 | 估算依据 | 通信量(GB) | 通信耗时(秒) | 推理计算耗时(秒) | 通信耗时**/** 计算耗时 |
| 1 Batch Prefill TP1+EP8 | EP:~40.39 公式二十七 | ~40.39 | ~0.045 | ~0.16 推导三 | 0.28 |
| 1 Batch Prefill TP8+EP8 | EP:40.39G 公式二十七 TP:4.65G 公式二十八 | ~45.04 | ~0.05 | ~0.082 推导四 | 0.61 |
| 1 Batch Decode TP1+EP8 | EP:0.012 公式二十七 | ~0.012 | ~0.000013 | ~0.00038 推导二 | 0.034 |
表五:3260输入场景通信量与耗时评估
推导三:(26.6+166.9/8)/296=0.16
26.6是 Prefill 阶段1 Batch 3260输入条件下 Attention 部分的计算量(单位 TFlops );
166.9是 Prefill 阶段1 Batch 3260输入条件下 FFN(包括稠密和 MoE )的计算量(单位 TFlops ),这时要假设比较均匀的情况,看大多数场景下的通信与计算耗时占比,所以除以8近似。
26.6与166.9来自【表二:3260输入长度场景的算力评估】
推导四:(26.6/8+166.9/8)/296=0.082
26.6是 Prefill 阶段1 Batch 3260输入条件下 Attention 部分的计算量(单位 TFlops ),除以8是因为TP8;
166.9是 Prefill 阶段1 Batch 3260输入条件下 FFN(包括稠密和 MoE )的计算量(单位 TFlops ),这时要假设比较均匀的情况,看大多数场景下的通信与计算耗时占比,所以除以8近似。
26.6与166.9来自【表二:3260输入长度场景的算力评估】
2.3.5 小结
通过分析模型结构、梳理清楚推理过程、并估算好四大资源占用情况,对于快速找到资源瓶颈和优化点非常重要。
其实优化点大多来自四大资源不匹配的时候,从宏观一些的PD分离架构到微观层级的算子,均有这个分形特点。
这次完整的设计和沉淀四大资源的测算公式,相当于随手带了一个计算器,有助于优化方向和程度的快速判断,以及对研发结果的快速交叉验证。
看清楚之后,就可以从易到难展开优化,依次是避免浪费、提升利用率、节约资源,类似如下的递进关系:
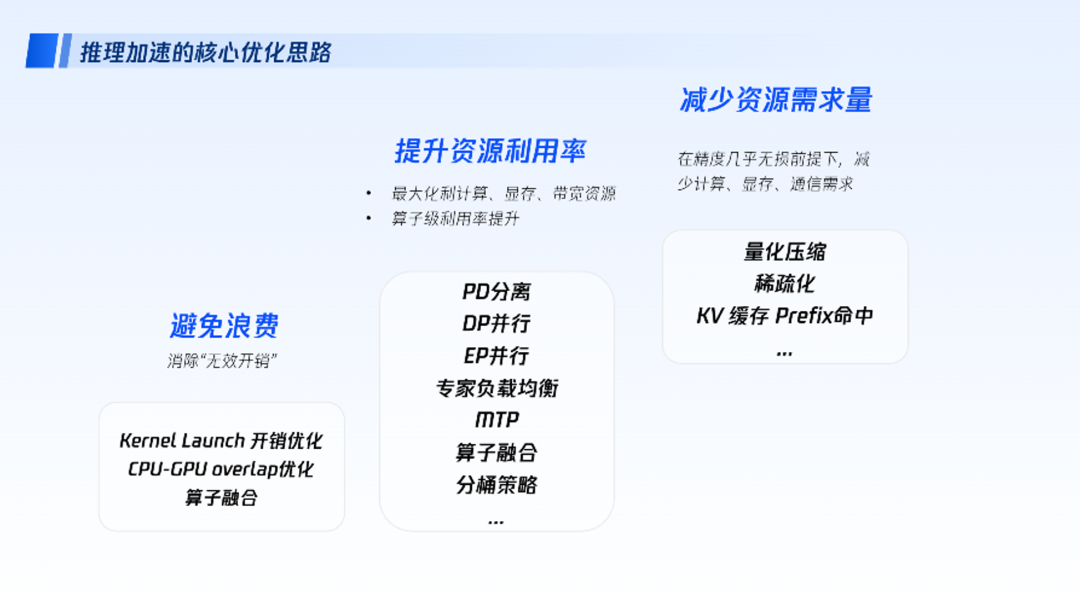
3、第二阶段:避免浪费——消除结构性冗余
看清楚模型结构、推理过程以及所需资源之后,就可以展开各项优化,思路是从易到难展开。所以第二阶段聚焦在如何快速消灭资源明显浪费的问题。比如Prefill阶段对相同的输入重复做Prefill、推理框架上CPU-GPU 同步等待、算子的冗余Launch和重复计算,都属于“识别冗余过程→去重/重叠/融合→减少资源占用”的优化方式。
3.1 减少Prefill(宏观层级)
用户输入如果有不少相同的前缀,就没有必要重复进行 Prefill 。要能大规模减少不必要的Prefill,需建设分布式 KV Cache store。
1)方案概述
基于 vLLM 集成 LMCache 作为缓存引擎,对接 NitroFS 远程存储,支持本地 + 远程混合缓存提升推理性能;核心架构为 vLLM(推理引擎)+ LMCache(KV 存储层)+ 远程存储(持久化 / 分布式访问),支持隐式 / 显式缓存模式,通过多副本 + 动态扩容实现容灾。
2)关键组件作用
LMCache:核心存储后端,负责读写、命中判断、一致性校验,支持NitroFS文件接口;
远程存储:HIFS 挂载,通过预读、聚合写、并发访问提效;
LLM 集成:实现 PD 分离,兼容 LMCache 逻辑(命中统计、缓存开关控制)。
架构示意图如下:
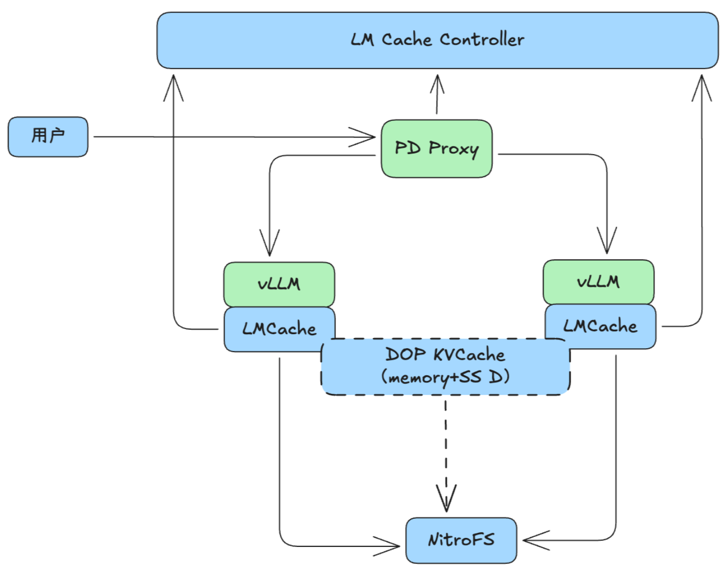
实践效果:通过KV Cache store,某些场景有20%输入重复的情况下,可以减少16%的Prefill计算。
这里的一些反思:Prefill 的重复计算其实是一种比较明显的浪费,但落地的时候反而比较滞后(包括精细化的命中率监控),当新模型和结构出现的时候,这个滞后就会更明显,比如早期Deepseek R1 MLA结构出现的时候以及后来3.2 DSA出现时,KV Cache store的跟进会偏慢。后续可能又有新的KV Cache结构出现,这里的被动不应该再延续。
3.2 消除 CPU-GPU 交互的空隙(中观层级)
我们再从中观层级及推理框架层面看看典型资源浪费的例子,获取举一反三的灵感。
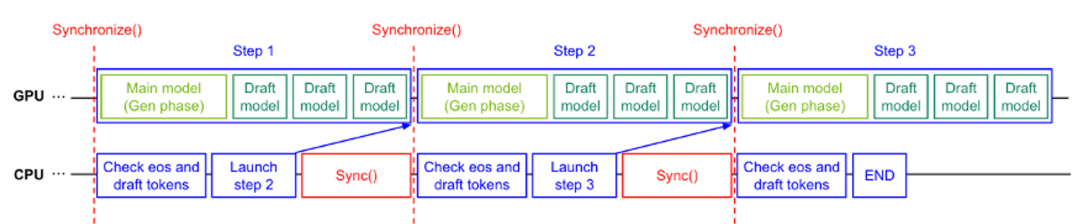
问题: 在 Decode 阶段,GPU 执行 Kernel 的速度极快(微秒级),而 CPU 下发指令(Kernel Launch)的开销相对较大。导致 GPU 在 Kernel 之间出现空闲,如下图:

传统解法: 使用 CUDAGraph 捕获执行流,减少 CPU 介入。开启 CUDAGraph 后 Kernel 间空隙几乎没有,但生成过程中每个 Step 还存在较大的空泡, 显然对 GPU 资源有极大浪费,如下图所示:

进一步优化: 即使开启 CUDAGraph,Step 之间仍有 CPU 处理逻辑(如采样、停止条件判断)。这时候就要考虑CPU-GPU充分的Overlap,比如在当前 Step 的 GPU 计算尚未结束时,CPU 提前预处理下一个 Step 的元数据(Metadata)并发起调度,填补时间空隙,比如下图。之前不合理的做法:CPU处理完再发起下一个step。
实践效果:
- Decode性能10%+
- Continous Batching+负载均衡调度优化,当请求持续打入时, GPU一直处于高负载状态,大部分情况不受CPU任务影响
延伸讨论:
空泡问题很多场景都会有,过去 vLLM的设计上针对性做了不少优化,如果自己写推理框架,很多地方都需要仔细设计,消除相关浪费。下面回顾两个vLLM的设计作为启发。
1)上下文空泡:KV Cache 的管理会成为新的“Step 间空泡”来源。如果在当前 Step 结束发现显存不够才去内存拉取,GPU 会陷入死等。推理引擎会维护一个虚拟内存管理层,在 GPU 还在执行 LayerN 的计算时,后台线程已经通过 PCIe 把 Layer N+1 甚至下一个 Step 需要的 KV Cache 块搬运到了显存边缘。
2)内存碎片空泡:在 PagedAttention 出现之前,显存必须为每个请求预留“最大长度”的连续空间。这导致显存很快被占满,Batch Size 上不去,GPU 算力被闲置。后来 vLLM 做了优化,像操作系统管理虚拟内存一样,将 KV Cache 拆分成物理上不连续的 Blocks(块)。在 GPU 计算当前层时,管理线程可以异步地准备下一组块的物理地址索引,从而消除了因内存重组导致的 Step 延迟。
3.3 算子融合优化(中观 - 微观层级)
算子融合将多个独立算子合并为单个Kernel,消除 Kernel Launch 与数据搬运开销,基本都是 “识别冗余过程→去重/重叠/融合→减少资源占用”的过程 。下面是一些例子。
3.3.1 算子融合优化(中观 - 微观层级)
问题:原 PyTorch 实现中,MoE 专家选择需 18 个独立 Kernel,包括线性层计算(路由层的矩阵乘)、Softmax(路由权重归一化)、Top-K选择(topk)、索引操作gather/scatter/argsort等,Launch 开销比较浪费;
方案:融合为 2 个 Kernel:比如线性层GEMM计算 + Sigmoid;Top-K 选择 + 索引映射 + 专家分配;
效果:算子级加速 10 倍,显存带宽也会节约不少(18次读写变2次)。
3.3.2 Pre-Quant 融合(微观层级)
问题:W4A8 量化中,Pre-Quant与Expand Row为独立算子,需两次数据读写,显存带宽占用增加 50%;
Pre-Quant:指在执行核心计算(比如矩阵乘法)之前,对输入数据(即激活值)进行必要的转换或缩放操作(L1/L2/寄存器->Tensor core)。优化前通常是独立的Kernel。
Expand Row(行扩展):指的是在低比特量化(如 W4A8)推理过程中,对输入激活值X进行的数据准备和对齐操作。
如果Pre-Quant 与 Expand Row 是独立算子,GPU 的执行路径是:
1)从 HBM 读 FP16 激活值 -> 计算量化 -> 写回 HBM(FP8)。
2)从 HBM 读 FP8 激活值 -> 执行行扩展/重排 -> 再次写回 HBM(或直接进 GEMM)。这种“读-写-读-写”的过程产生了大量无效的显存往返。由于 Decode 阶段是Memory-Bound(访存受限) 的,这些多余的 IO 直接拖慢了 Token 的生成速度。
方案:在 GEMM 前融合为单个操作,直接输出量化对齐后的输入数据,避免重复读写,即在加载 X 进入 GPU SRAM(片上缓存) 的过程中,利用读取带宽时间把除以 s 给做了,其实用的是一种微观层级的重叠手段。
优化前:读 X -> 写回 s-1X -> 再读 s-1X 进入 GEMM。
优化后:读 X -> 在寄存器里直接除以 s -> 直接喂给 Tensor Core。这种方式即便不跨算子,也能节省 50% 的 HBM 读写。参考下图:
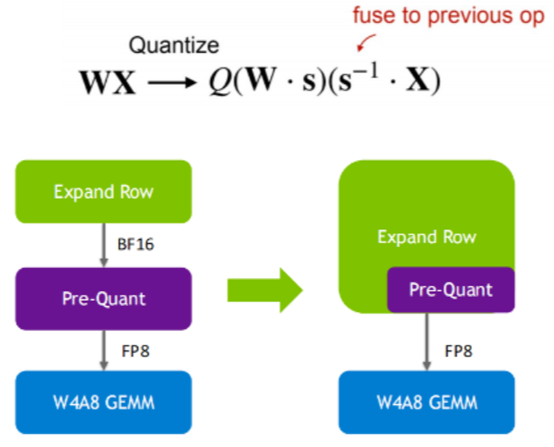
效果:相关算子执行所需的显存带宽节省 50%。
3.3.3 Metadata 融合(中观层级)
问题:Metadata(专家索引、路由权重等)每层均需获取,分布式协调与传输开销占端到端耗时 2%~3%;
方案:全局缓存 Metadata,各层通过哈希映射快速查询,避免重复获取,如下图
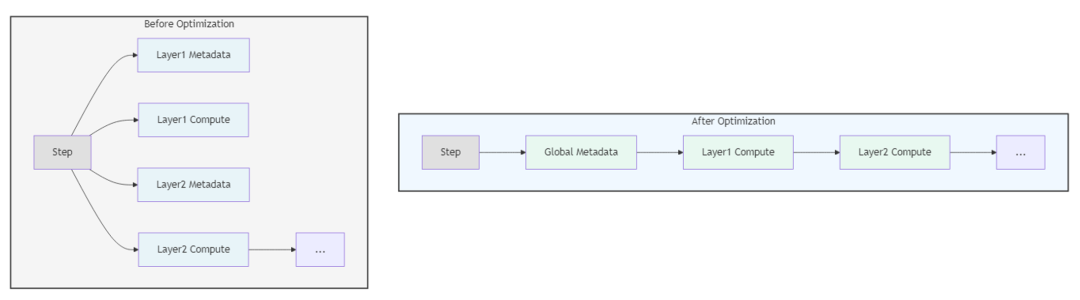
效果:端到端耗时降低 2%~3%。
Metadata是控制分布式计算流程所需的各种协调信息,种类较多,比如:
1)专家索引:每个 Token 被分配到的Top-K专家编号(如K=2),形状通常为 [Batch_size, seq_len, k]的整数张量;
2)路由权重:对应每个被选专家的门控权重,形状为 [Batch_size, seq_len, k]的浮点张量。
3)其他设备拓扑映射、通信模式配置等等。
4、第三阶段:提升利用率——软硬深度协同
在消除了浪费后,可以释放不少资源。但当需求进一步变多之后,总有一种硬件资源会先遇到瓶颈,这时候其他资源大概率是没有达到瓶颈的,这就有了性能优化的机会点,说白了就是如何提升各大资源的利用率。我们以PD分离作为切入点,看看不均衡以及利用率低的情况和优化手段,其实都有“识别资源瓶颈与不均衡的地方→并行策略/调度策略/融合手段/节约手段→提升资源利用率”这样的特点。
4.1 PD 分离(宏观层级)
为什么要有 PD 分离,因为Prefill 和 Decode 的资源需求“形状”不同,应该使用针对性的硬件拓扑和软件策略来承载,以解决非分离架构 MFU 偏低的问题。PD分离的出现就是为了解决算力和显存资源不均衡的问题。
PD 分离流程如下:
用户请求 → 负载均衡器 → Prefill节点集群(m个,大TP+小EP)→ KV Cache RDMA传输 → Decode节点集群(n个,DP+大EP)→ 输出结果
但PD分离本身也会面临不少挑战:
1)Prefill节点:
由于存在算力瓶颈,以及跨机通信开销,导致TTFT降不下来
2)Decode节点:
- 由于KV Cache频繁存取,存在明显的访存瓶颈;
- Decode节点显存墙比较明显,算力用不满
应对方案如下几个小节逐个展开介绍。
4.1.1 Prefill 节点优化(宏观层级)
由于存在算力瓶颈,以及跨机通信开销,导致 TTFT 降不下来,所以策略如下:
采用TP+EP(宏观层级)
通过 TP 并行,缩短首字延迟,参考收益参考下表:
| 并行策略 | 算力 **(****Tflops/**卡) | 推理耗时 (秒) | 通信量 (GB) | 通信耗时 (秒) |
| Attention TP1 + MoE EP8 | 47.5 推导三 | 0.16 | 40.39 公式二十七 | 0.045 |
| Attention TP8 + MoE EP8 | 24 推导四 | 0.082 | 45.04 公式二十七 | 0.05 |
表六:1 Batch/3260 Tokens输入条件下推理和通信资源对比
大致测算可知:相比TP1**,TP8的通信耗时增加了0.005s,但是推理耗时节约了0.08s**
P 节点调度策略(宏观层级)
抓资源不均衡是分形思考框架的核心。PD分离后,一般P和D的性能存在差异,且性能差异受到用户输入长度的影响,因此实践中需要分别考虑调度策略以及分桶策略。
Prefill****节点具体调度策略示例(参考下图):
Chunk调度:同一批到达的请求,按长度排序优先调度短prompt,整体TTFT达到最
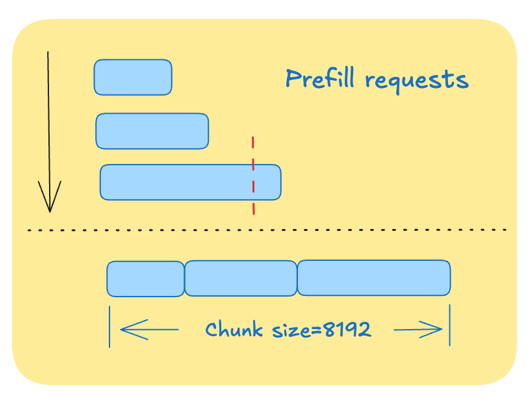
延伸的一些思考:Chunk size是否需要动态调整?
GPU 处理数据时有一个特性:当一次处理的任务量(即 Chunk 大小)太小时,搬运数据的时间远长于计算时间,此时 GPU 在等数据(访存受限);当任务量大到一定程度,计算单元(ALU/Tensor Core)才能满载,开始高效工作(计算受限),GPU任务的形状非常关键,后面还有经典例子。
另外这里延伸对比一下H800与H20:
H800 的特性:算力极高(FP8 下约 4PFLOPS),它需要极大的 Chunk 才能喂饱它的 Tensor Core。如果 Chunk 只有 1024,它可能只发挥了 10% 的算力。
H20 的特性:算力被大幅阉割,但带宽(HBM)依然很高。这意味着它是一个“大水管接小漏斗”。对于 H20 来说,可能 Chunk 只要 2048 就能让它达到算力饱和。
“阶梯状浪费”就在这里: 如果你在 H20 上强制用8192的大Chunk:
排队等待时间长:原本2048就能算完一波开始下一波,现在非要凑够 8192 算一次,导致小请求被无端“堵”在了大块后面,增加了延迟。
吞吐利用率不均:在 Batch Size 波动时,固定的大块会导致 GPU 经常在“等凑单”或“处理多余无效位”,无法灵活利用每一兆带宽。
注:这里2048和8192只是举例子用的数字,具体数字与场景相关
KV Cache传输优化(中观层级)
PD分离过程中,KV Cache 传输的过程很容易引入算力和显存利用率低的问题,所以尽可能优化好。文本介绍计算通信重叠、Layerwise、NIXL等引入、改进和优化。
计算通信重叠(中观层级)
Prefill节点需要将计算得到的 KV Cache 以及 Metadata 传输给Decode节点,如果采用计算->传输->计算模式,将导致GPU利用率降低,这里很容易想到异步传输进行优化,主要采用以下设计实现:
异步传输 KV Cache,与当前iteration forward step overlap,不影响吞吐
RDMA 高效传输,单个forward step 周期内完成,TPOT 有保障
调度层面做好 CPU & GPU Overlap,适配好 PD+投机采样
采用上述方法后,可以看到在整个 Timeline 上,计算与传输能够较好的 Overlap,GPU 利用率持续保持高位。
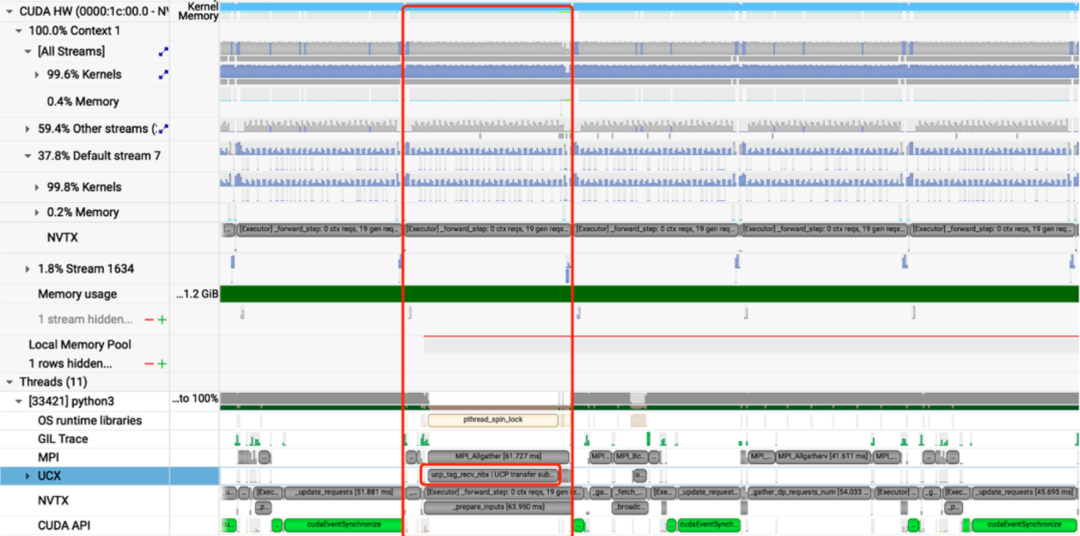
参考来源:ruiqinchen https://mp.weixin.qq.com/s/w_sb_ei-tSGVz9asI9cidQ
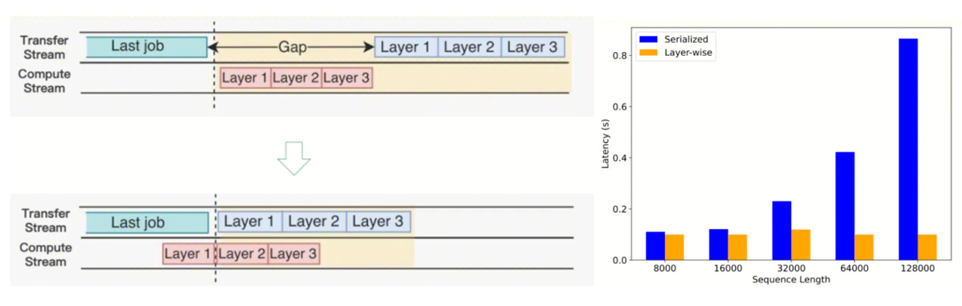
Layerwise(中观层级)
如果等到所有 Layer 算完再进行发送,发送的数据量可能较大,占用较多SM算力,影响下一轮次forward step计算性能,因此根据实际情况设计 Layerwise 传输。
层前向计算与层 KV Cache 传输 Overlap,有效降低长序列场景 KV Cache 传输时耗
长文:ISL>8k 时选择 Layerwise 传输;短文:ISL<8k 时整体传输,避免大量小包,并做小包合并传输。
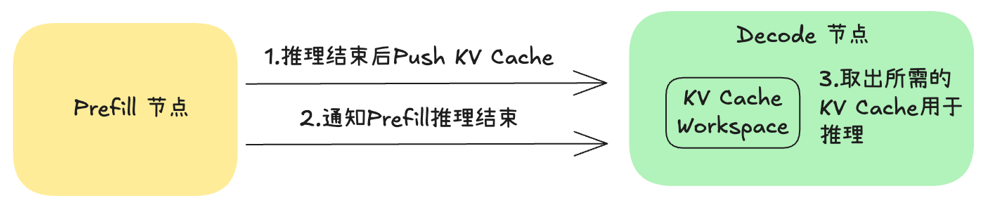
PD分离采用push模式,Prefill 节点生成KV Cache后,主动将数据推送到Decode 节点,无额外协调开销,可与 Layerwise 传输深度配合(推理完一层推一层),掩盖通信延迟。
采用Layerwise传输设计与实现后,可以看到传输的Lantency几乎与ISL无关,保持在较低水准。
参考来源:ruiqinchen https://mp.weixin.qq.com/s/w_sb_ei-tSGVz9asI9cidQ
基于NIXL通信(中观层级)
之前方案采用了NCCL通信,但是NCCL机制上对于算力和显存都有“侵占”,NCCL的步骤大概如下:
1)分块与搬运:GPU 将 Paged 内存(不连续)中的数据拷贝到一块连续的 Shared Buffer(线性缓冲区)。
2)内核态切换:数据从线性 Buffer 经过驱动层准备传输。
3)网络发射:通过 NIC(网卡)发送。
4)接收端对冲:接收端 GPU 收数据到线性 Buffer,再拷贝回最终的 Paged 内存位点。
**上述过程会产生 SM算力消耗、显存带宽消耗,因为数据在 GPU内部的“折返跑”以及显存容量占用。**用昂贵的算力做数据搬运,本身就是一种明显的资源不匹配,但在项目早期我们没有意识到这里。
NIXL直接使用 KVCache 作为传输的源和目的,Prefill节点: GPU(Paged)–>RDMA (GDR)–>Decode节点: GPU(Paged)。基于NIXL能真正做到零拷贝,并且支持UCX等backend,方便扩展为支持异构硬件的PD分离,相比NCCL,实战有3~4%的性能收益。
注:GDR(GPU Direct RDMA)之前,GPU显存 -> 主机内存 -> 网卡 -> 网络-> 对端网卡 -> 对端主机内存 -> 对端GPU显存;GDR可以做到:GPU显存 <-> 网卡 <-> 网络 <-> 对端网卡 <-> 对端GPU显存。
UCX(Unified Communication X ),是一个开源的高性能通信框架,为数据中心和高性能计算(HPC)环境提供统一的通信接口
我们在项目中的主要优化包括:
- 社区NIXL方案兼容内部vLLM的CPU/GPU Overlap、DP等特性
- 支持DP Rank全局负载均衡调度,Prefill主动Push KVCache 模式
- 支持Prefill 节点TP 并行模式到 Decode 节点DP 并行模式的异步传输
下表是各通信方式的对比,帮助选型参考:
| 特性 | MPI | NCCL | Mooncake | NIXL |
| 定位 | 通用并行计算通信标准 | NVIDIA GPU专用集合通信库 | 专用AI推理异构传输引擎 | NVIDIA推出的点对点通信库 |
| 优点 | 标准化高、接口通用、灵活 | NVIDIA生态性能优、集合通信快、易集成 | 专为PD设计、异构支持广、功能完善、与缓存集成 | 与NVIDIA生态深度集成、抽象良好、支持异构硬件 |
| 缺点 | 非专用设计、扩展性差、配置复杂、功能单一 | 有额外拷贝、硬件绑定 | 性能依赖框架集成、可能非零拷贝、生态较新 | 较新 |
| 性能关键 | 依赖UCX配置调优 | 有额外拷贝,以及显存和SM的占用 | 可实现零拷贝(依赖实现) | 设计支持零拷贝 |
| 适用场景 | 快速原型、已有MPI系统、跨平台需求 | NVIDIA多GPU环境、集合通信需求、初期方案 | 生产级异构系统、需灵活拓扑、需集成缓存 | NVIDIA全栈推理平台、需智能路由、看重统一抽象 |
表七:大模型推理各通信方式对比
4.1.2 Decode节点优化(宏观层级)
下表是不同Batch与并行度下Decode 1 Token所需的四大资源情况:
| 并行策略 (MoE W4A8) | 单卡显存占用(GB) | 单卡显存读写(GB) | 单卡通信 (GB) | 单卡算力(Gflops) |
| 1 Batch Attention DP8/TP1+MoE EP8 | 65 推导五 | 16.56 推导五 | ~0.012 | 116 推导五 |
| 32 Batches Attention DP8/TP1+MoE EP8 | 68.5 推导六 | 23.2 推导六 | ~0.383 (0.012*32) | 2288 推导六 |
| 32 Batches Attention DP8/TP1+MoE EP16 | 47.5 推导七 | 22.56 推导七 | ~0.383 (0.012*32) | 2185.6 推导七 |
| 32 Batches Attention DP8/TP1+MoE EP32 | 37.8 推导八 | 22.24 推导八 | ~0.383 (0.012*32) | 2134.4 推导八 |
表八:不同Batch/EP并行度下Decode所需的四大资源情况
推导五:
权重:通过公式六得到55 GB;KV Cache : 0.11 GB;激活:0.0008 GB;系统预留: 10 GB
显存共计:55+0.11+0.0008+10 ≈ 65 GB(参考公式十一)
显存读写:14+657/257/2*2+0.11+0.0008*61*2 ≈ 16.56 GB(参考公式十二,假设均衡的情况)
算力:≈ 65.1+51.2/8 = 71.5 Gflops (假设均衡的情况)
推导六:
权重:通过公式六得到55 GB;KV Cache : 0.11*32 GB;激活:0.0008*32 GB;系统预留: 10 GB
显存占用共计:55 + 0.11*32 + 0.0008*32 + 10 ≈ 68.5 GB (参考公式十一)
显存读写:14+657/257/2*2+0.11*32+0.0008*32*61*2 ≈ 23.2 GB (参考公式十二,假设均衡的情况)
算力:≈ 65.1*32+51.2/8 *32 = 2288 Gflops (假设均衡的情况)
推导七:
权重:通过公式六得到14+657/2/16,34 GB;KV Cache : 0.11*32 GB;激活:0.0008*32 GB;系统预留: 10 GB
显存共计:34 + 0.11*32 + 0.0008*32 + 10 ≈ 47.5 GB
显存读写:14+657/257/2*(1+8/16)+0.11*32+0.0008*32*61*2 ≈ 22.56 GB (参考公式十二,假设均衡的情况)
算力:≈ 65.1*32+51.2/16 *32 = 2185.6 Gflops (假设均衡的情况)
推导八:
权重:通过公式六推导14+657/2/32,得到24.27 GB;KV Cache : 0.11*32 GB;激活:0.0008*32 GB;系统预留: 10 GB
显存共计:24.27+0.11*32+0.0008*32+10 ≈ 37.8 GB
显存读写:14+657/257/2*(1 + 8/32) +0.11*32+0.0008*32*61*2 ≈ 22.24 GB(参考公式十二,假设均衡的情况)
算力:≈ 65.1*32+51.2/32*32 = 2134.4 Gflops (假设均衡的情况)
从表格可以看出,EP并行度加大,吐字速率会下降比较多,原因是跨机通信的概率增加。如果后续跨机通信希望选型TCP,对吐字速率的影响有多大,就要仔细评估了。这里给了粗的框架(表格数据的假设:显存带宽4TB/秒;通信带宽机内900GB/秒,机间50GB/秒;单卡FP8算力296Tflops,参考H20的硬件参数)。
| 32 Batches /Decode 1 Token | 显存读写耗时 (秒) | 通信耗时 (秒) | 计算耗时 (秒) | 总耗时(秒) (假设完全无重叠) |
| EP8 | ~0.0058 | ~0.0004 | ~0.0075 | ~0.0137 |
| EP16 | ~0.00564 | ~0.004 | ~0.0072 | ~0.0168 |
| EP32 | ~0.00556 | ~0.0059 | ~0.007 | ~****0.0185 |
表九:不同EP并行度下Decode阶段显存读写/通信/计算的耗时测算(假设EP Size不同时Kernel性能保持不变)
如果追求50 Tokens/秒的吐字速率,总耗时就不能超过0.02秒, 表格中EP32的方案就非常危险,毕竟这个测算是理想情况,没有考虑算力/显存带宽/通信带宽的实际MFU。
采用DP+EP(宏观层级)
调整并行策略其实就是重新调整各资源的使用量和比例关系,尽量降低触达资源最短板的概率。
如果 Decode 节点显存墙导致算力利用率上不来, 那就想办法利用 EP 将模型的大头 MoE 部分切分到更多卡上,降低单卡显存占用(参考表八显存占用那一列),从而允许开启更大的Batch Size,强行将“访存受限”任务向“计算受限”拉升,提升 QPM。
适配和改造需要注意的地方:
1)运行模式解析
因为在MoE阶段需要做同步,以及CUDA Graph对input tensor shape的要求,一般都需要mock request才能确保Attention的正确性。
2)DP模式正常运行,主要表现为:
- 每个DP Rank在每一次forward step至少包含一条请求
- CUDA Graph模式下,forward step后需all reduce对⻬各DP Rank待处理的request数量
- mock request当Decode请求处理,DP主要应用于Decode
运用DP8之后的收益:单机throughput提升50%以上。
Decode节点负载均衡优化(宏观层级)
即使并行策略优化了,Decode 节点依然有不少利用率不高的情况,体现在负载不均衡。尤其当输入长短变化、输出长短变化的情况下。目前我们还没有非常完整和精细化地监控 Decode 节点负载均衡情况。从业务部署的成本看,已经和实验室压测数据有较大差异。这部分要尽快建设。
当前落地的负载均衡策略是基于请求的round-robin,业界负载均衡策略会有感知更多样和更精细的特点,比如:
1)基于KV Cache 利用率的调度
2)根据滑动统计平均输出长度,优先按剩余槽位调度的策略,参考下图:
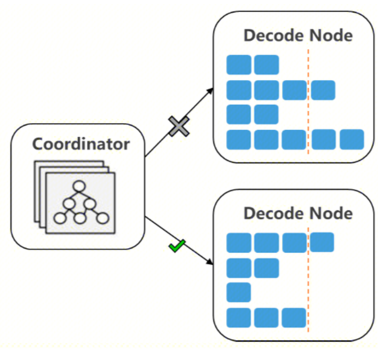
3)基于平均 KV Cache size 的调度
这是 MLA 注意力的算力公式:FlopsMLA = NLayer×2bs’nheads(2dc + dR)s, s’是当前 KV Cache 的长度,s’越长,MLA算力需求量越大,吐字速率和吞吐都会受到影响,另外 Batch 上去后算力可能也是瓶颈,所以需要更多元和更精细化的调度策略。
通信优化(中观层级)
DeepSeek R1/V3 的256个路由专家,通过MoE的稀疏性,每个 Token 仅激活极少数专家,这样容易带来计算气泡:如果负载均衡策略不佳,某些 Rank 上的专家被频繁选中(热点专家),而其他 Rank 闲置,导致整组 EP 必须等待最慢的 Rank 完成,产生算力空转。
还有通信长尾问题:传统的 All-to-All 通信是同步的,如果各 Rank 间发送的数据量因 Token 路由分布不均而产生巨大差异,通信耗时将取决于数据量最大的那个连接。
真是富贵险中求。
问题的本质还是各资源的不均衡问题,解题思路通信优化(减少通信过程对四大资源的消耗)以及负载均衡来缓解,但非常复杂。
具体做法:通过 DeepEP + 腾讯网平团队的 TRMT。
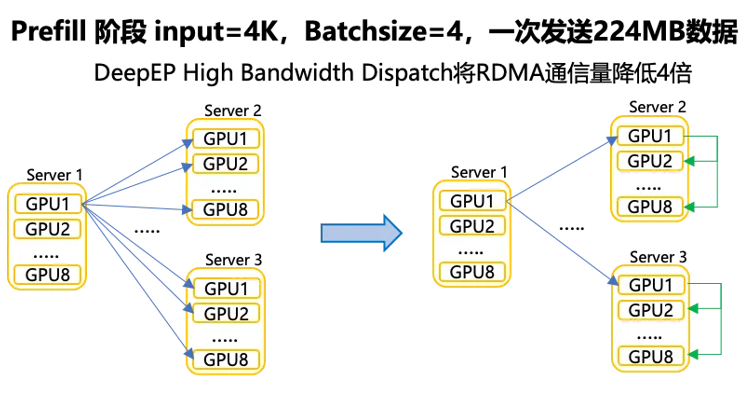
DeepEP 是首个针对 MoE 模型定制的开源通信库,主要应对 MoE 在大规模分布式训练和推理中的通信瓶颈,尤其是由于 NVLink(机内)和 RDMA(机间)带宽极度不对称导致的通信瓶颈。
DeepEP 的流程涉及了:Dispatch(分发) 和 Combine(合并)。
Dispatch的主要步骤:
- Token 路由: 门控网络(Router)计算出每个 Token 应该去往哪个专家。
- 重排与打包: 将发往同一节点的 Token 进行连续存储优化。
- 异构传输与优化: 适配 NVLink→RDMA 非对称带宽,优化跨域数据转发耗时。
Combine(合并阶段):
结果收集: 专家处理完后,数据通过反向路径回传。
加权求和: 根据 Router 给出的权重,将多个专家的输出合并为原始 Token 的表示。
DeepEP 通信三层架构如下:
Intranode 实现:同一节点内的通信,充分利用节点内的NVLink带宽进行传输。
Hybrid Internode 实现:通过机内NVLink转发,降低机间 IB 通信量。此外,通过内存语义实现两阶段通信细粒度Overlap,使机内、机间同时完成传输,从而减少 Token 传输时间。流程参考下图:
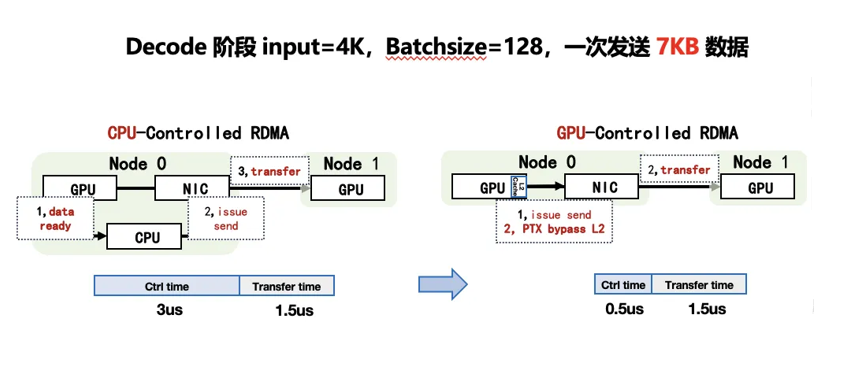
Low Latency Internode 实现:Decode 阶段 MoE 对时延很敏感。低时延模式下跨节点通信直接通过 IB 网络传输,以避免二次转发的时延。并且利用 PTX 优化 IBGDA,减少 CPU 控制绕远路,进一步降低时延。
注:IBGDA(InfiniBand GPUDirect Async)是一项允许GPU绕过CPU,直接通过InfiniBand网络进行远程数据
但是DeepEP最初版本也有不少问题:
比如双端口网卡环境下容易面临负载不均、多任务流量混合时互相影响导致的拥塞以及不均衡,CPU调延迟高、不同厂商的网卡适配不充分等。整体看负载不均衡问题挺严重。
腾讯TRMT在DeepEP基础上又进行了深度优化,具体做法:
1)控制面优化:进一步 Bypass CPU(消除调度延迟)
传统 RDMA 通信依赖 CPU 调度,但在 MoE 推理的 Decode 阶段,比如某长度下 3us 的控制开销远大于 1.5us 的数据传输时间。
TRMT 结合IBGDA ,提供内存语义 API,将计算与通信封装为一个统一的 Kernel,这消除了 Kernel 间的启动开销,还允许在计算执行过程中按需触发。
然后通过灵活的发送时机,实现计算与通信的深度重叠,降低通信耗时对整体计算过程的影响。
效果:控制面时延从 3us 降低至 0.5us,触达硬件性能极限。
2)数据面优化:Bypass L2(精准缓存控制)
由于通信数据频繁读写显存,容易刷掉 GPU L2/L1 缓存中存放的模型权重或 KV Cache,影响命中率从而导致计算性能下降。
TRMT通过 PTX(并行线程执行)指令集,细粒度地控制数据流在 HBM、L1/L2 缓存之间的搬移,减少对缓存的污染,沉淀比较成熟的缓存管理策略。
3)传输层优化:负载均衡与拥塞控制
在大规模集群中,跑满双端口网卡的带宽是提升集群通信效率的关键。
TRMT构建了全互联通信架构,然后通过动态 QP(Queue Pair)端口分配算法,利用积累的 UDP 源端口动态规划技术,引导流量均匀分布,使得服务器上的双端口网卡能够同时跑满带宽,达到了理论峰值,特别是在跨机位通信时性能增益显著, 也弥补了DeepEP只考虑单网卡以及缺乏多网卡适配的不足
优化前通信算子耗时占比高达40%+
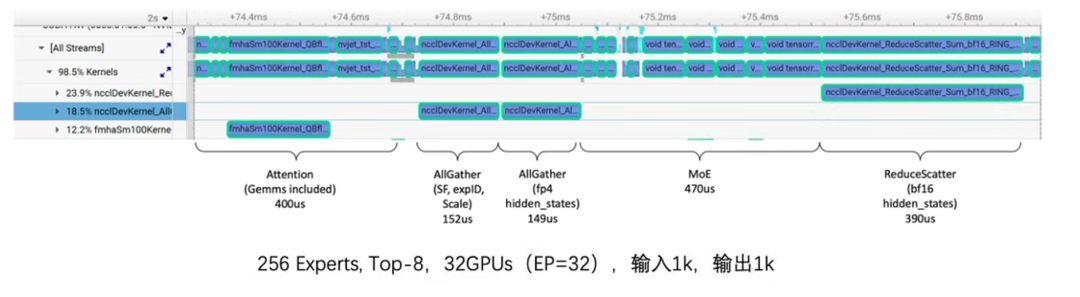
优化后通信算子耗时减少60%,如下图参考:
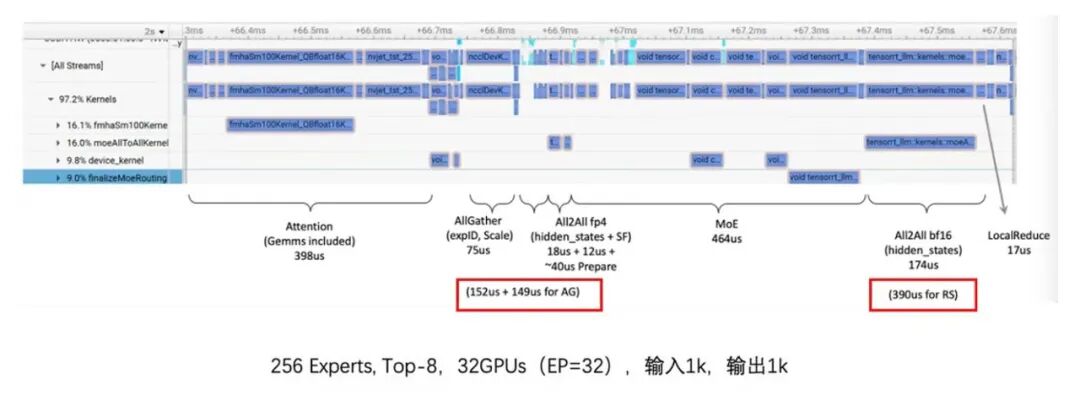
MoE负载均衡优化(中观层级)
负载均衡问题真是大模型推理性能的阿喀琉斯之踵,且无处不在。
通信优化能缓解通信资源的不均衡问题,但不能解决各节点专家负载不均衡的问题,毕竟Token想发给谁,是模型里的Router算出来的,采样分析各Layer各专家激活次数统计分布如下图,表现为:部分Layer存在明显热点专家,热点专家激活的次数可能是非热点专家的5倍以上,导致EP并行存在某个rank上计算耗时较长,其他rank需等待的局面。
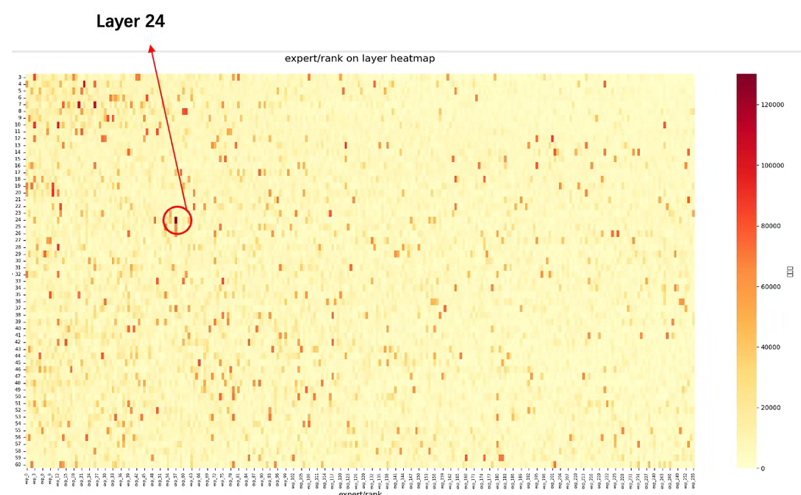
参考来源:ruiqinchen https://mp.weixin.qq.com/s/w_sb_ei-tSGVz9asI9cidQ
既然专家选择暂时无法控制,那就尽量把专家均有摆放,方案如下:
1)通过自研的静态专家放置策略进行均衡。
传统做法(Linear Placement): 简单地按顺序切分,例如前 8 个专家给 GPU 0,后 8 个给 GPU 1。这极易导致负载倾斜,因为某些序列号相邻的专家可能在语义上更相关,经常被同时激活,导致某张卡瞬间过载。
静态专家放置策略采用Round-Robin策略:即 “专家 ID % GPU 数量” 得到物理GPU ID。
计算公式: Physical_GPU_ID = Global_Expert_ID % Number_of_GPUs
这种方式比较简单,但在物理层面上可以达到强制将专家“打散”的效果。即使模型中某一层的多个专家被同时激活,它们大概率也会均匀地分布在所有 GPU 上,从而让所有显卡的计算压力在统计学上保持平衡 。
2)结合DeepEP low-latency算法对vLLM中的MoE执行路径进行适配与调优。
效果:在我们常用的测试集上看,整体请求吞吐率提升约14.03%, TTFT 降低超过50%, TPOT 指标降低约 8.06%,显著改善了生成阶段的稳定性与响应效率。
这个方案也被vLLM社区认可,在vLLM v0.12.0发布的时候被highlight。
参考来源:https://github.com/vllm-project/vllm/pulls?q=28449
4.2 多Token预测(MTP)优化(中观层级)
Multi-Token Prediction(MTP)是一种通过对每一个位置预测多个Token来改进大模型训练性能的技术。MTP用于推理加速可以一次预测多个Token,大幅提升推理性能。
但在高 Batch size下,算力瓶颈突显,MTP的额外计算开销可能导致收益降低。MTP可能适合做调节器:长输入小并发场景,显存快满但算力闲置较多时,MTP帮助提升算力利用率,减少显存与算力之间的不均衡程度。
5、第四阶段:节约资源
最高级的优化是“不做计算”或“少做计算”。
5.1 显存节约:MLA 架构(微观层级)
传统的 MHA(多头注意力)需要缓存巨大的 KV Cache。MLA 通过矩阵低秩分解(Low-Rank Factorization),将 KV Cache 压缩为极其紧凑的 Latent Vector。
效果: 显存占用减少数倍,使得在单卡上支持超大 Batch Size 成为可能。这个趋势还在继续,后续一定可以看到更优秀的注意力机制,更好支持长文的同时进一步节约显存。
5.2 算力与带宽节约:量化与稀疏化(微观层级)
MoE 量化: 采用 W4A8(权重 4bit,激活 8bit)策略。通过 AWQ(Activation-aware Weight Quantization)保护敏感通道,实现精度无损的前提下,显存带宽需求减半。
5.2.1 量化压缩优化(微观层级)
1)敏感度分析:实验阶段发现 DeepSeek 模型前三层 Dense Layer 较为敏感,然后LLM-Head本身通用的形式就是不量化,并且这些层再整个 Deepseek 模型中占比非常小,所以这几层不采取INT4量化。
2)MoE层INT4量化:为了保持INT4下的效果无损,通过AWQ策略使得权重里敏感的channel进行平滑,并且每一层采用per-group的量化方式,group-size=128,这样相比于per-channel能保持更好的精度,并且推理速度不会明显的下降。
3)FP8静态per-tensor量化:通过小批量的高质量校准集进行校准,针对MoE模块中所有Linear都采用了静态per-tensor量化方式,并且经过评测效果无损。
实际效果:
H20单机8卡部署DeepSeek模型,采用了INT4量化节省显存。在DeepGEMM基础上做了深度优化,支持INT4数据类型的高效计算。相较于两机FP8部署,QPM提升50%以上。
量化策略上, 如果精度足够的话,per-tensor应该是最快的,速度上per-tensor>per-channel>per-group。
5.2.2 稀疏注意力优化(微观层级)
长序列(32k 以上)Prefill 阶段中,传统 Attention 计算复杂度为 O (n²),且随序列增长占比显著上升,计算容易成为瓶颈,优化思路是尽量降低计算复杂度,节约资源,O(nk)。
Deepseek给大家立了一个标杆 DSA,值得参考。
DSA 核心步骤:
1.Lightning Indexer(闪电索引器):
这是一个轻量级的头部。它首先对全量 L 个 Token 进行一次极速扫描,为每一个 Query Token 计算它与之前所有 Token 的相关性得分 It,s。
2.Fine-Grained Selection(细粒度筛选):
根据得分,DSA 动态地从 L 个历史 Token 中只选出最关键的 k 个(k << L)。
3.Sparse Attention Calculation(稀疏注意力计算):
Query 只与选出的 k 个 Token 进行 full attention 计算。由于 k 是常数或远小于 L,计算量大幅下降。
四大资源测算:
1)算力消耗(FLOPs):
传统注意力:FLOPs = 2bdmodels2
DSA 稀疏注意力:FLOPsDSA = FLOPsindexer + FLOPssparse
FLOPsindexer:2bHIdIs2(HI=64 头,dI=128 维,FP8)
FLOPssparse:2bdmodelsk(k=2048)
总复杂度:O(Lk) ≈ 2bdmodelsk,相比 O (L²) 降低约s/k 倍(128K 时≈64 倍)
2)显存消耗:相比MLA,索引器需要的额外 KV 存储,用于计算相关性得分相关性得分 It,s。,但这个不大,每个Token存8KB(单个索引Key的大小HI×dI)
3)显存带宽:瓶颈从“读取全量 KV”转变为“扫描索引 + 随机读取稀疏 KV”,传统 Attention 需要在 Decoding 阶段读取所有 KV,而 DSA 只需要读取k个相关性最高的KV,极大地降低了长序列推理时的 HBM 带宽压力。
测算例子:
根据官方配置参数:dI = 128(索引维度),dc = 512(MLA 核心 KV 维度),k = 2048。当 s = 128,000 时:
传统 MLA 读取量:128,000 × 512 = 65.5 单位数据。
DSA 读取量:(128,000 × 128) + (2048 × 512) = 16.3 + 1.0 = 17.3 单位数据。
在 128k 长度下,DSA 的带宽消耗仅为传统 MLA 的约 26.4%,即带宽压力减少了约 73.6%。
4)通信带宽使用量:与之前版本持平,但由于单卡计算和显存效率提升,DSA 允许更大的 Batch Size 或更长的输入,从而提高了单位通信带宽下的有效吞吐量。
5.2.3 mHC计算过程资源分析(微观层级)
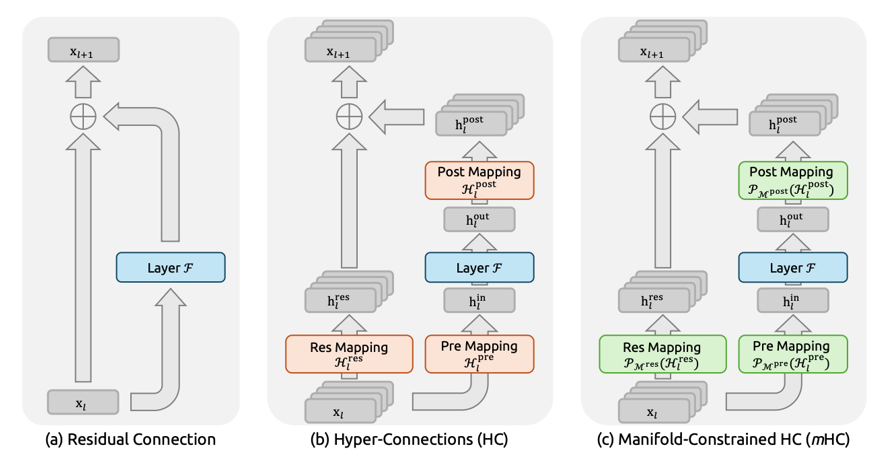
最近Deepseek出了mHC论文[2512.24880] mHC: Manifold-Constrained Hyper-Connections, 旨在把大模型内部残差连接拓宽以增加信息量和表达能力,并给拓宽的连接加上流形约束防止信号不稳定,这个预示着等了10年的Resnet将有新的突破。
mHC架构如下:
如果我们要运用mHC,会遇到那些性能和资源瓶颈?在动手前, 我们其实是可以测算出来的。
算力测算
mHC 的算力开销主要由“映射生成”和“混合操作”组成,展开如下:
| 阶段 | 子阶段 | 算力测算 | 推导 |
| 映射系数生成阶段 | 2ndmodel(n2 + 2n)bs | 1)论文中的投影计算 (公式 14): 输入维度: xl的形状为 [1, ndmodel]。 权重维度: [dmodel, n2 + 2n]。 这是一个标准的矩阵乘法。对于形状为 A×B,FLOPs为2AB,所以公式14的 FLOPs: 2ndmodel(n2 + 2n)bs 2)论文公式16是对公式14拼接后的逐元素乘法和加法,算力是2(n2 + 2n) 3)Sinkhorn 迭代的计算量: Iter×n2,通常Iter=20 所以映射系数生成阶段FLOPs: 2ndmodel(n2 + 2n)bs+2(n2 + 2n) +Iter×n2。 | |
| 映射系数应用阶段 | Pre映射 | 2ndmodelbs | 执行Hlpre · xl,即将 [1, n] 的向量与 [n, dmodel] 的矩阵相乘。 |
| Post 映射 | 2ndmodelbs | 将层输出 F(·) 分发回到各流中,F(·) 里有注意力或者MoE等相关的计算,不属于mHC本身的计算,Post映射的计算形状为 [n, 1] × [1, dmodel]。 | |
| 交叉混合 | 2n2dmodelbs | 执行流之间的交叉混合,即 Hlres · xl,形状为 [n, n] × [n, C]。 | |
| 残差合并 | 2ndmodelbs | 将混合后的流与新生成的流合并,涉及2路 n 条流的加法。 | |
| 汇总 | 2ndmodel(n2+3n+3)bs+2(n2 + 2n) +Iter×n2 |
所以 FlopsmHC≈ 2ndmodel(n2+3n+3)bs+2(n2+ 2n)+Iter×n2,其中n通常为4,Iter为20,相比dmodel,n与Iter都不算大。传统残差的计算量是dmodelbs次加法。
显存占用
公式: MemmHC= 2ndmodel + n2 + 2n
ndmodel:扩展后的残差流状态存储(推理时缓存),考虑收两路的输出(残差主干和分支的输出)。
n2 + 2n:动态映射矩阵生成的参数量
传统残差流宽度为 dmodel,mHC 扩展为 ndmodel。在长文本推理中会有些影响,需要注意。比如128K临时激活需要占3.42GB。
显存带宽占用
参考论文[2512.24880] mHC: Manifold-Constrained Hyper-Connections的Table 2 :
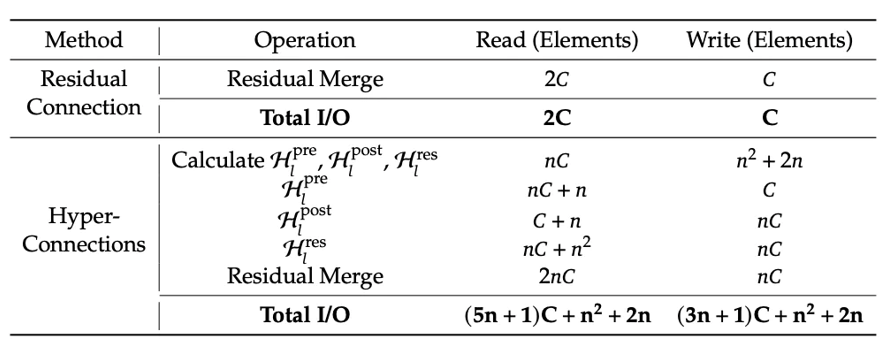
论文中的C就是dmodel
公式: IO = ((8n + 2)dmodel+ 2n2 + 4n)bs。读写放大比较多,传统残差的读写 IO 是 3dmodelbs
通信带宽
TrafficmHC 是之前残差流部分的n倍,对PP并行有影响,mHC残差结构新增的权重规模小, 用TP和EP切分意义不大。
优化方向
针对计算和显存读写的放大,Deepseek给出了如下的性能优化方案:
逻辑降维与参数合并:
1)将 RMSNorm 的“除以范数”操作从 ndmodel 的高维空间移至 n2 低维系数空间执行,消除高维逐元素运算带来的显著延迟。论文中的公式14和16结合在一起已经体现。
2)权重吸收,将 RMSNorm 缩放系数、线性投影及偏置全部预整合进
l 和 bl 中,减少计算步骤。
全流程算子融合,比如:
1)减少扫描:融合公式14~15,一次扫描 xl 同时完成矩阵乘法与范数计算;训练阶段反向传播整合两次矩阵乘法,避免重复加载数据。
2)将公式16~18的系数缩放与激活合并
3)专门做一个Kernel: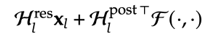 将Hlpost和 Hlres 的计算合并,读取量由 (3n+1)dmodel 降至 (n+1)dmodel,写入量由 3nC 降至 ndmodel。
将Hlpost和 Hlres 的计算合并,读取量由 (3n+1)dmodel 降至 (n+1)dmodel,写入量由 3nC 降至 ndmodel。
精度与流水线优化:
高效混精:数据流采用 bfloat16 保证速度,参数与系数采用 float32 保证精度。
微调流水线:通过“加载-转换-计算-存储”四阶段精细控制,最大化显存带宽利用率。
总结与展望
文本基于分形几何的自相似性原理:在宏观、中观、微观不同层级下,遵循统一的四大资源优化逻辑,化解 DeepSeek等大模型推理优化的复杂性。
6.1 优化闭环
大自然有分形之美,我们的优化工作其实也有异曲同工之处,可以从宏观到微观螺旋式深入。
大模型的推理性能优化,本质上是对硬件物理极限的逼近过程,本文沉淀的分形思考框架,有助于驾驭大模型推理过程以及优化方向,且不受限于具体模型和硬件。
通过分形思考框架,我们在不同层级上反复做两件事情:
- 找到当前各大资源的瓶颈点,以及资源不均衡的情况后展开优化,提升目标资源的利用率,减少不均衡的情况。
- 资源优化,减少对资源的使用
当 1 和 2 完成之后, 在新性能要求的情况下,又会产生新的不均衡与瓶颈,再次进行1和2,直到逼急硬件资源真正的“物理极限”。
6.2 全文十大技术观点总结
| 类别 | 核心观点**/**技术结论 | 具体表现**/**实现手段 | 效果**/**收益 |
| 一、分形思考框架 | 大模型推理优化具有“自相似性”,各层级遵循统一优化逻辑 | “看清楚→避免浪费→提升利用率→节约资源” | 系统性应对复杂优化,不易遗漏重点且能找到优化点 |
| 二、四大资源分析 | 算力、显存、显存带宽、通信带宽是核心瓶颈分析维度 | 建立量化公式模型,识别各阶段资源瓶颈 | 精准定位优化方向,避免盲目优化,也方便快速理解新模型和新硬件 |
| 三、避免浪费 | 消除结构性冗余是快速见效的优化手段 | 1. KV Cache 复用避免重复Prefill 2. CPU-GPU Overlap减少空泡 3. 算子融合减少Kernel Launch | 减少16% Prefill计算、提升10%+ Decode性能、算子加速n倍 |
| 四、提升利用率 | 软硬协同与负载均衡提升资源利用率 | 1. PD分离架构 2. 并行策略调优(TP/EP/DP) 3. 通信优化(DeepEP/TRMT) 4. 专家均衡放置 | 吞吐提升50%+、通信耗时降低60%、负载均衡提升14%吞吐 |
| 五、节约资源 | 算法与架构创新直接减少资源需求 | 1. MLA低秩压缩KV Cache 2. W4A8量化压缩 3. DSA稀疏注意力 4. mHC架构资源预分析 | 显存占用减少数倍、带宽需求减半、长序列计算复杂度从O(n²)降至O(nk) |
| 六、PD分离架构 | Prefill与Decode阶段资源需求差异大,需针对性优化 | 1. Prefill节点:TP+EP+Chunk调度 2. Decode节点:DP+EP+负载均衡 3. KV Cache传输优化(Layerwise/NIXL) | TTFT降低超50%、TPOT降低8.06%、支持更大Batch Size |
| 七、通信优化 | MoE架构通信是性能关键瓶颈 | 1. DeepEP定制通信库 2. TRMT优化(Bypass CPU/L2、负载均衡) 3. NIXL零拷贝传输 | 通信算子耗时降低60%、控制面时延从3us降至0.5us |
| 八、量化与稀疏化 | 精度无损前提下的资源节约 | 1. MoE层INT4量化(AWQ保护) 2. FP8静态per-tensor量化 3. DSA稀疏注意力(k=2048) | QPM提升50%以上、128k长度带宽压力减少73.6% |
| 九、新兴架构预分析 | 新架构(如mHC)可提前测算资源影响 | 算力、显存、带宽、通信四维度公式测算 | 避免盲目实施,针对性设计优化方案 |
| 十、优化闭环 | 持续识别瓶颈→优化→逼近硬件极限 | 从宏观到微观,分形思考框架循环应用 | 系统化、可持续的性能优化 |
6.3 未来展望
本文的分形思考框架,还有不少并行策略、经典算子的资源计算模型没有展开,后续在实践中逐步沉淀下来。
实际工作中我们会遇到各种命题,比如:
1)H20做 Prefill 还有多少空间,成本是否可以对抗友商的白菜价
2)海光BW151做 Decode,是否有机会
3)H20做 Decode 还有多少空间,ROI大概是多少
4)Deepseek或者混元新模型用哪种卡性价比最高,能优化到什么程度。
本文的思考框架与沉淀可以帮忙快速分析上述送命题,并抓住深度优化的方向和薄弱环节。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
为什么要学习大模型?
我国在A大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着AI技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国AI产业的创新步伐。加强人才培养,优化教育体系,国际合作并进是破解困局、推动AI发展的关键。


👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献588条内容
已为社区贡献588条内容

所有评论(0)