RAG技术完全指南:解决大模型三大痛点,从原理到实战代码详解
文章系统介绍RAG技术,解决大模型知识滞后、幻觉生成和专业领域适配不足的痛点。详述技术原理、Embedding模型选型、实战案例及优化技巧,包括知识库构建、检索生成流程、Query改写等。通过浦发银行案例展示DeepSeek+Faiss本地检索系统实现,为开发者提供可直接复用的技术框架与选型思路。
文章系统介绍RAG技术,解决大模型知识滞后、幻觉生成和专业领域适配不足的痛点。详述技术原理、Embedding模型选型、实战案例及优化技巧,包括知识库构建、检索生成流程、Query改写等。通过浦发银行案例展示DeepSeek+Faiss本地检索系统实现,为开发者提供可直接复用的技术框架与选型思路。
在大模型应用落地过程中,“知识滞后”“幻觉生成”“专业领域适配不足”三大痛点始终制约着效果。而检索增强生成(RAG)技术作为连接静态大模型与动态知识库的核心桥梁,凭借实时性、高准确性、低改造成本等优势,已成为企业级AI应用的标配方案。本文将基于技术原理、核心模块、实战案例、优化技巧四大维度,系统化拆解RAG技术,为开发者提供可直接复用的技术框架与选型思路。
一、大模型应用开发的三大模式:选型逻辑与适用场景
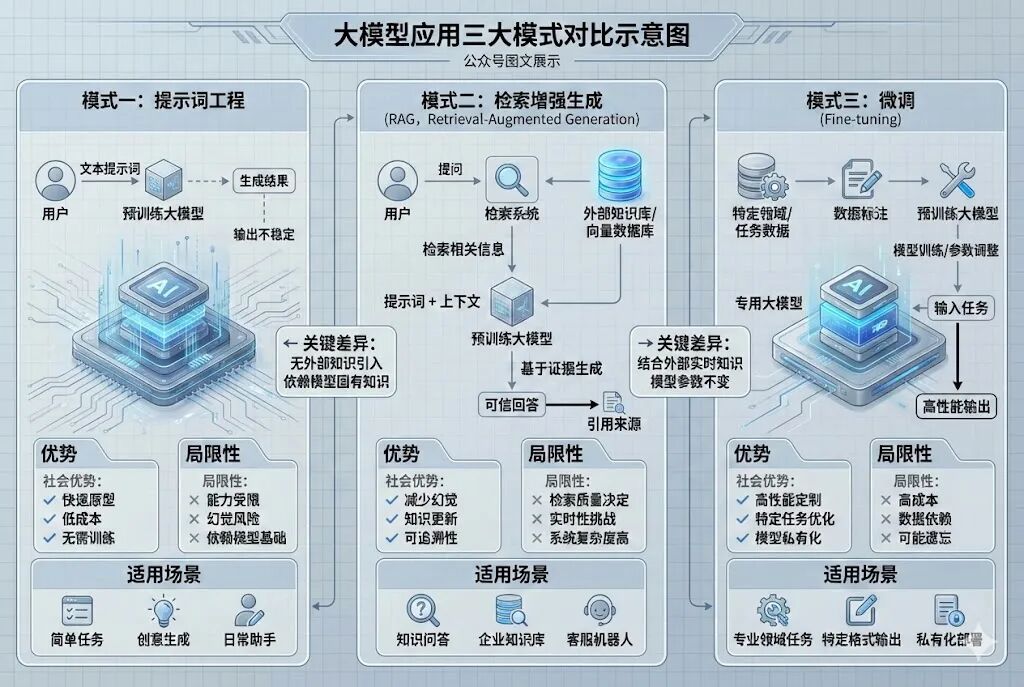
大模型应用开发本质是通过不同手段让模型适配业务需求,目前主流分为提示工程、RAG、微调三种模式,三者无绝对优劣,需根据业务场景动态选择。
**1.**三种模式核心对比
•提示工程(Prompt Engineering):无需修改模型参数,通过优化输入指令引导模型生成结果。核心优势是开发成本极低、迭代速度快,适合简单场景、快速验证需求或模型能力边界探索。局限性在于对指令设计能力要求高,无法解决模型知识盲区问题,且效果易受输入格式影响。
•检索增强生成(RAG):通过实时检索外部知识库补充上下文,让模型基于“既有知识+外部信息”生成答案。优势是知识可动态更新、能溯源答案来源、减少幻觉,适合需要实时信息、专业领域问答(如法律、医疗)、私有知识库交互场景。局限性在于依赖知识库质量与检索精度,需额外搭建检索体系。
•微调(Fine-tuning):基于特定数据集调整模型参数,将知识内化为模型自身能力。适合高频次、高相似度的专业场景(如行业专属话术生成),生成效果更稳定、响应速度更快。局限性在于开发成本高(需标注数据、算力资源)、迭代周期长,且知识更新需重新微调,无法应对动态信息。
**2.**选型决策树
实际开发中可按以下逻辑选择:① 需求是否依赖实时/动态知识?是→RAG;否→② 知识是否高频复用且场景固定?是→微调;否→提示工程。若需兼顾专业度与动态性,可采用“RAG+微调”混合方案(微调模型理解行业术语,RAG补充实时信息)。
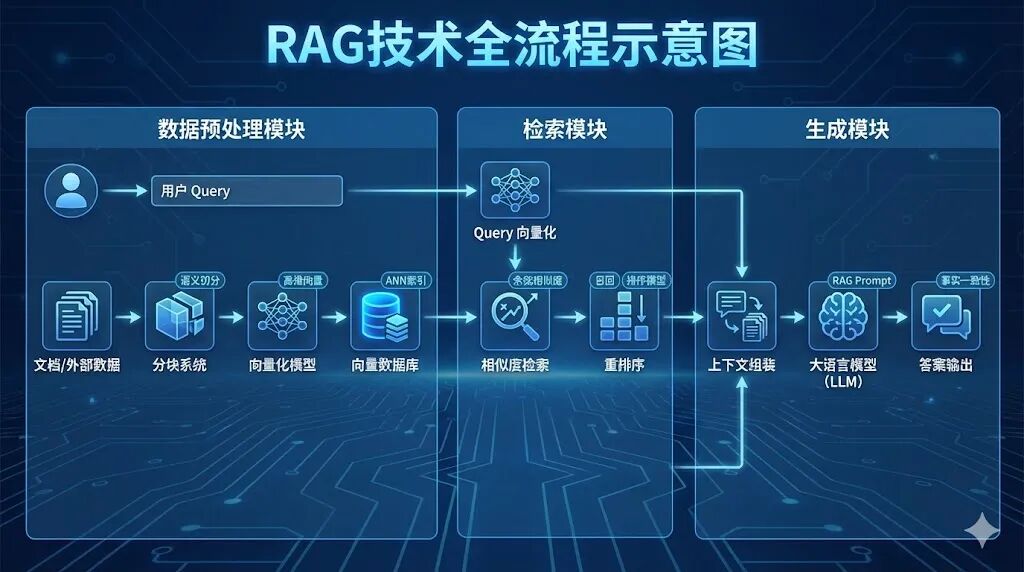
二、RAG核心原理:检索与生成的协同逻辑
RAG的核心思想是“让模型只做擅长的生成任务,将知识存储与检索交给专业体系”,整体流程分为数据预处理、检索、生成三大核心步骤,形成闭环链路。
**1.**完整技术链路拆解
Step 1**:数据预处理****——**知识库构建的基础
原始文档需经过“清洗-分块-向量化”三步转化为可检索的向量数据,直接决定后续检索精度。
•知识库构建:收集PDF、网页、数据库、文档等多源数据,进行去重、去噪(剔除无效格式、冗余内容)、格式标准化处理。例如法律场景需保留法条编号、医疗场景需提取核心症状与诊疗方案。
•文档分块策略:核心是平衡“语义完整性”与“检索效率”,常用三种策略:
○递归字符分割(主流):按段落→句子→空格→字符优先级分割,参数建议chunk_size=500-1000 tokens,chunk_overlap=50-200 tokens(重叠部分避免语义断裂);
○语义分块:基于句子相似度或主题聚类分割,适合长文档(如论文、报告),需依赖语义模型辅助;
○滑动窗口分块:固定窗口大小与步长遍历文本,适合时序类文档(如日志、新闻)。
•向量化处理:通过Embedding模型将文本块转化为高维向量(通常为768/1024/3072维),向量空间中距离越近表示语义越相似。生成的向量需存储在向量数据库中,支持高效相似度检索。
Step 2**:检索阶段****——**精准定位相关知识
接收用户查询后,通过“query向量化→相似度检索→结果重排序”输出Top-K相关文本块(K值通常取3-5,过多易引入冗余信息)。
•相似度计算:主流采用余弦相似度(衡量向量夹角),适用于大部分场景;欧氏距离适合低维向量场景;点积适合归一化后的向量快速计算。
•重排序机制:基础检索结果可能存在语义偏差,需通过重排序模型(如Cross-BERT、Sentence-BERT)优化,结合关键词匹配度、语义相关性综合打分,提升Top结果精度。
Step 3**:生成阶段****——**基于增强上下文输出答案
将检索到的文本块与用户query组合为增强上下文,按固定格式输入大模型,生成兼顾准确性与逻辑性的答案。上下文组装需遵循“query前置+相关文本块按相关性排序+格式标准化”原则,避免模型忽略核心信息。

2. RAG****核心优势与不可替代性
即便大模型支持无限上下文窗口,RAG仍具备不可替代的价值:
•知识时效性:大模型训练数据存在截止日期,RAG可实时对接外部知识库(如新闻、政策、行业动态),无需重新训练模型;
•成本控制:长上下文窗口会大幅增加Token消耗与推理时间,RAG仅输入相关文本块,可降低50%以上推理成本;
•可解释性:生成答案可溯源至具体文本块,解决大模型“黑箱问题”,适合合规要求高的场景(如金融、法律);
•数据隐私:私有知识库可本地部署,无需上传至云端模型,规避敏感数据泄露风险。
三、Native RAG:下一代RAG的优化方向
传统RAG的索引、检索、生成三大环节相互独立,存在语义偏差、检索精度不足等问题。Native RAG通过“全链路协同优化”提升端到端效果,核心是让检索与生成深度耦合,而非简单拼接。
**1.**三大核心优化维度
•索引层优化:突破传统单向量索引限制,采用多向量索引(每个文本块生成多个向量,分别对应核心句、上下文)、混合索引(稠密向量+稀疏向量结合,兼顾语义与关键词匹配),提升模糊查询与长文档检索精度。
•检索层优化:引入自适应检索策略,根据query类型(如事实查询、推理查询)动态调整检索方式与K值;结合用户历史对话上下文,优化检索结果相关性(如上下文依赖型query需关联历史信息)。
•生成层优化:让生成模型反馈检索缺陷,形成闭环优化。例如模型识别到检索文本块信息不足时,自动触发二次检索,补充相关内容;或对检索结果中的冲突信息进行标注,引导模型谨慎生成。
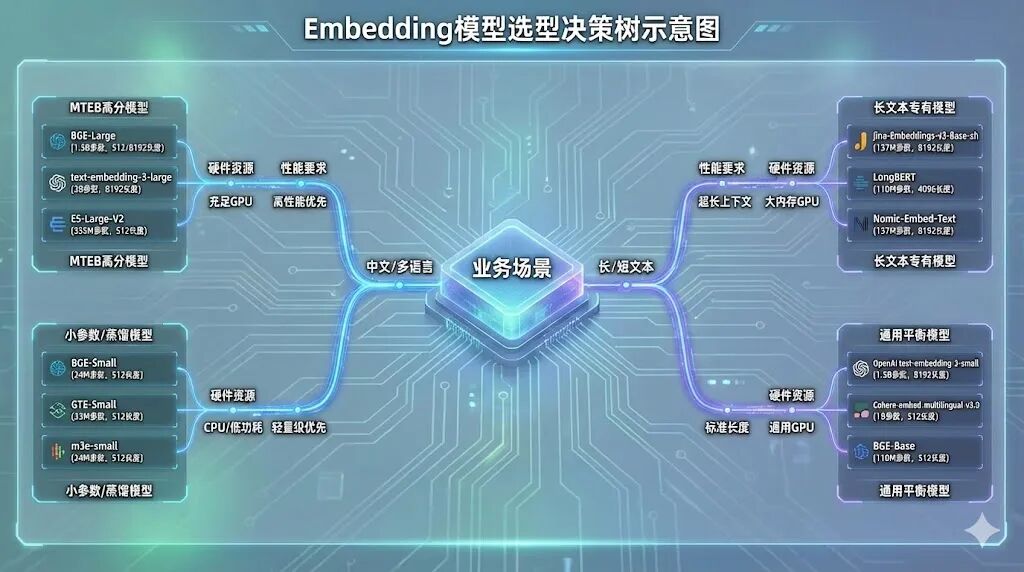
四、Embedding模型选型:从榜单到业务落地
Embedding模型是RAG的“语义基石”,其性能直接决定检索精度。选型需结合业务场景(语言类型、文本长度)、硬件资源(显存、算力)、性能要求综合判断。
**1.**核心评估指标与榜单参考
Embedding模型性能可通过MTEB(Massive Text Embedding Benchmark)榜单评估,核心指标包括:
•检索(Retrieval):衡量文本检索的召回率与精确率,核心指标为MRR(平均倒数排名)、NDCG(归一化折损累积增益);
•STS**(语义文本相似度)**:衡量模型捕捉文本语义相关性的能力,指标为皮尔逊相关系数;
•零样本任务(Zero-shot):衡量模型在未见过的任务上的泛化能力。
主流参考榜单:Hugging Face MTEB Leaderboard(覆盖1000+模型、100+语言),可根据具体任务筛选最优模型。
**2.**分类选型指南与代表模型
| 模型类别 | 代表模型 | 核心特点 | 适用场景 | 硬件要求 |
| 通用文本嵌入(多语言) | BGE-M3、multilingual-e5-large-instruct | 支持100+语言,长文本处理(最长8192 tokens),混合检索能力强 | 跨语言检索、长文档处理、高精度RAG | BGE-M3(2.3G),支持GPU/CPU部署 |
| 通用文本嵌入(轻量) | Jina-embeddings-v2-small、M3E-Base | 参数量小(35M-0.4G),推理速度快(RT<50ms) | 轻量化部署、实时推理、边缘设备应用 | CPU可运行,显存要求<2G |
| 中文优化嵌入 | xiaobu-embedding-v2、stella-mrl-large-zh-v3.5-1792 | 针对中文语义优化,捕捉细微语义差异,适配中文专业术语 | 中文问答、法律/医疗中文检索、中文文本分析 | GPU(4G+显存)或高性能CPU |
| 指令驱动型 | gte-Qwen2-7B-instruct、E5-mistral-7B | 支持复杂指令理解,跨模态检索(文本+代码),零样本表现优异 | 复杂问答系统、指令驱动检索、企业级RAG | GPU(8G+显存),需算力支持 |
| 商业化模型 | text-embedding-3-large(OpenAI)、Cohere-embed-multilingual-v3.0 | 稳定性高,长文本语义捕捉强,API调用便捷 | 全球化应用、英文优先场景、无需本地部署 | 无硬件要求,按调用量计费 |
3.实操代码示例(BGE-M3与gte-Qwen2**)**
示例1:BGE-M3向量生成与相似度计算
| python from FlagEmbedding import BGEM3FlagModel # 加载模型(use_fp16=True加速推理,精度略有下降) model = BGEM3FlagModel(‘BAAI/bge-m3’, use_fp16=True) # 待编码文本 sentences_1 = [“What is BGE M3?”, “Definition of BM25”] sentences_2 = [ “BGE M3 is an embedding model supporting dense retrieval, lexical matching and multi-vector interaction.”, “BM25 is a bag-of-words retrieval function that ranks documents based on query terms frequency.” ] # 生成向量(dense_vecs为稠密向量,sparse_vecs为稀疏向量,可单独或混合使用) embeddings_1 = model.encode(sentences_1, batch_size=12, max_length=8192)[‘dense_vecs’] embeddings_2 = model.encode(sentences_2)[‘dense_vecs’] # 计算余弦相似度矩阵(矩阵乘法实现,shape=[len(sentences_1), len(sentences_2)]) similarity = embeddings_1 @ embeddings_2.T print(similarity) # 输出结果:[[0.626 0.3477] # [0.3499 0.678 ]] |
示例2:gte-Qwen2指令型向量生成
| python from sentence_transformers import SentenceTransformer import torch import torch.nn.functional as F # 加载本地模型(需提前下载,trust_remote_code=True允许加载自定义代码) model_dir = “/root/autodl-tmp/models/gte_Qwen2-1.5B-instruct” model = SentenceTransformer(model_dir, trust_remote_code=True) model.max_seq_length = 8192 # 调整最大输入长度 # 指令型query构建(提升复杂任务检索精度) def get_instruct_query(task, query): return f’Instruct: {task}\nQuery: {query}’ task = ‘Retrieve relevant passages for web search query’ queries = [ get_instruct_query(task, ‘how much protein should a female eat’), get_instruct_query(task, ‘summit define’) ] documents = [ “CDC recommends women aged 19-70 consume 46g protein daily; increase for pregnancy or marathon training.”, “Summit: 1. Top of a mountain; 2. Highest level; 3. Intergovernmental leaders’ meeting.” ] # 生成向量(query需指定prompt_name=“query”,文档用默认设置) query_embeds = model.encode(queries, prompt_name=“query”) doc_embeds = model.encode(documents) # 归一化向量后计算相似度(提升结果稳定性) query_embeds = F.normalize(query_embeds, p=2, dim=1) doc_embeds = F.normalize(doc_embeds, p=2, dim=1) scores = (query_embeds @ doc_embeds.T) * 100 # 转换为百分比分数 print(scores.tolist()) # 输出结果:[[78.4969, 17.0429], [14.9245, 75.3796]] |
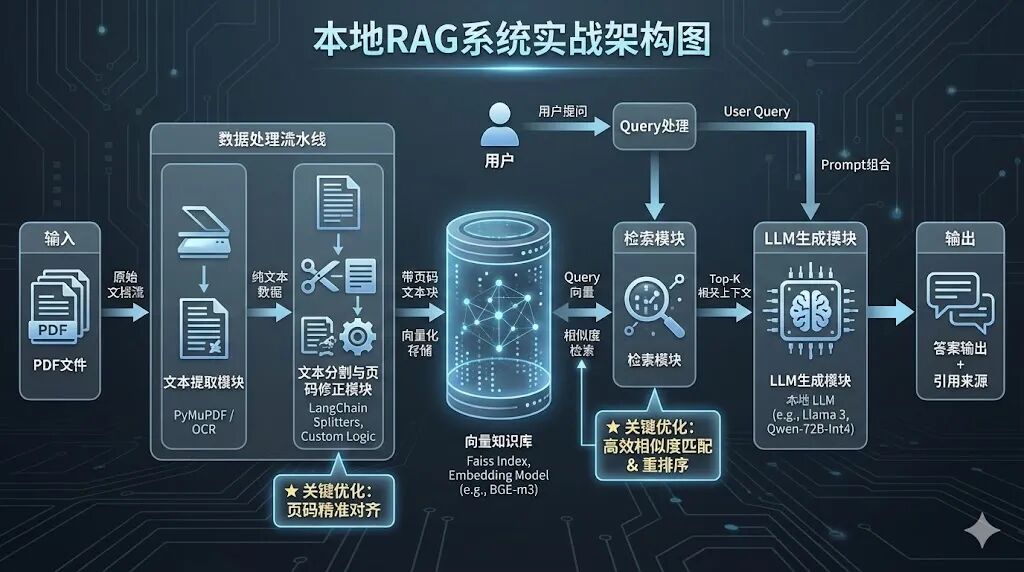
五、实战案例:DeepSeek + Faiss搭建本地知识库检索系统
以“浦发银行个金客户经理考核办法”PDF为例,搭建本地RAG问答系统,实现政策查询、答案溯源功能,技术栈:PyPDF2(文本提取)+ DashScope Embedding(向量化)+ Faiss(向量数据库)+ DeepSeek-v3(生成模型)+ LangChain(流程编排)。
**1.**系统架构与技术选型理由
•Faiss:Facebook开源向量数据库,支持高效近似最近邻检索,适配中小规模知识库(百万级向量以内),本地部署便捷,无需额外服务依赖;
•DashScope text-embedding-v1:阿里云开源嵌入模型,中文语义适配性强,推理速度快,适合金融等专业领域;
•DeepSeek-v3:代码与中文生成能力优异,支持长上下文输入,API调用成本低,适合企业级场景;
•LangChain:简化RAG流程编排,提供现成的问答链、文本分割器,降低开发成本。
**2.**分步实现代码与关键说明
Step 1**:PDF文本提取与页码映射**
核心是提取文本并记录每行对应的页码,为后续答案溯源做准备,解决原始代码中页码映射错误问题。
| python from PyPDF2 import PdfReader from typing import List, Tuple import logging logging.basicConfig(level=logging.INFO) Logger = logging.getLogger(__name__) def extract_text_with_page_numbers(pdf_path: str) -> Tuple[str, List[int]]: “”" 提取PDF文本并记录每行对应的页码 :param pdf_path: PDF文件路径 :return: 提取的文本、每行文本对应的页码列表 “”" pdf_reader = PdfReader(pdf_path) text = “” page_numbers = [] # 索引对应文本每行的页码 for page_idx, page in enumerate(pdf_reader.pages, start=1): extracted_text = page.extract_text() if not extracted_text: Logger.warning(f"No text found on page {page_idx}“) continue # 按换行符分割文本,为每行分配当前页码 lines = extracted_text.split(”\n") text += extracted_text + “\n” page_numbers.extend([page_idx] * len(lines)) return text.strip(), page_numbers |
Step 2**:文本分割与页码修正**
解决原始代码中“文本块与页码不匹配”问题,通过字符位置定位文本块所属页码,采用众数统计确定核心页码。
| python from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.embeddings import DashScopeEmbeddings from langchain_community.vectorstores import FAISS import collections def process_text_and_build_kb(text: str, page_numbers: List[int], api_key: str) -> FAISS: “”" 文本分割、向量化,构建FAISS向量知识库,并修正页码映射 :param text: 提取的PDF文本 :param page_numbers: 每行文本对应的页码列表 :param api_key: DashScope API密钥 :return: FAISS向量知识库对象 “”" # 文本分割器配置 text_splitter = RecursiveCharacterTextSplitter( separators=[“\n\n”, “\n”, “.”, " “, “”], chunk_size=1000, chunk_overlap=200, length_function=len ) chunks = text_splitter.split_text(text) Logger.info(f"Text split into {len(chunks)} chunks”) # 初始化嵌入模型 embeddings = DashScopeEmbeddings( model=“text-embedding-v1”, dashscope_api_key=api_key ) # 构建向量知识库 kb = FAISS.from_texts(chunks, embeddings) # 修正页码映射:为每个文本块找到对应的页码(基于字符位置) chunk_page_map = {} for chunk in chunks: # 找到文本块在原始文本中的起始位置 chunk_start = text.find(chunk) if chunk_start == -1: chunk_page_map[chunk] = “Unknown” continue # 计算文本块包含的行数(基于换行符) chunk_lines = chunk.count(“\n”) + 1 # 找到起始行对应的索引(原始文本前chunk_start字符中的换行符数量) start_line_idx = text[:chunk_start].count(“\n”) # 取该文本块覆盖行数的页码,以众数作为最终页码 chunk_pages = page_numbers[start_line_idx:start_line_idx + chunk_lines] chunk_page_map[chunk] = collections.Counter(chunk_pages).most_common(1)[0][0] # 将页码映射存入知识库 kb.page_info = chunk_page_map return kb |
Step 3**:问答查询与结果展示**
实现相似度检索、问答链调用、成本跟踪与页码溯源功能。
| python from langchain_community.llms import Tongyi from langchain.chains.question_answering import load_qa_chain from langchain_community.callbacks.manager import get_openai_callback def rag_qa(kb: FAISS, query: str, api_key: str) -> dict: “”" RAG问答主函数 :param kb: FAISS向量知识库 :param query: 用户查询 :param api_key: DashScope API密钥 :return: 问答结果(含答案、来源页码、成本) “”" # 相似度检索(Top 3相关文本块) relevant_docs = kb.similarity_search(query, k=3) # 初始化LLM llm = Tongyi( model_name=“deepseek-v3”, dashscope_api_key=api_key ) # 加载问答链(采用stuff策略,适合小批量文档) chain = load_qa_chain(llm, chain_type=“stuff”) # 执行问答并跟踪成本 with get_openai_callback() as cost: response = chain.invoke({ “input_documents”: relevant_docs, “question”: query }) # 提取来源页码 source_pages = set() for doc in relevant_docs: page = kb.page_info.get(doc.page_content.strip(), “Unknown”) source_pages.add(page) return { “answer”: response[“output_text”], “source_pages”: sorted(list(source_pages)), “cost”: cost.total_cost } |
**3.**常见问题与解决方案
•页码映射错误:原始代码直接按索引匹配文本块与页码,忽略分割后上下文断裂问题,解决方案为通过字符位置定位文本块覆盖范围,用众数统计确定页码;
•检索精度低:可优化分块参数(缩小chunk_size、调整overlap)、更换更高性能的Embedding模型、添加重排序机制;
•答案冗余:控制Top-K检索数量(3-5为宜)、优化上下文组装格式(仅保留核心文本块)、调整LLM生成Prompt(要求简洁回答)。
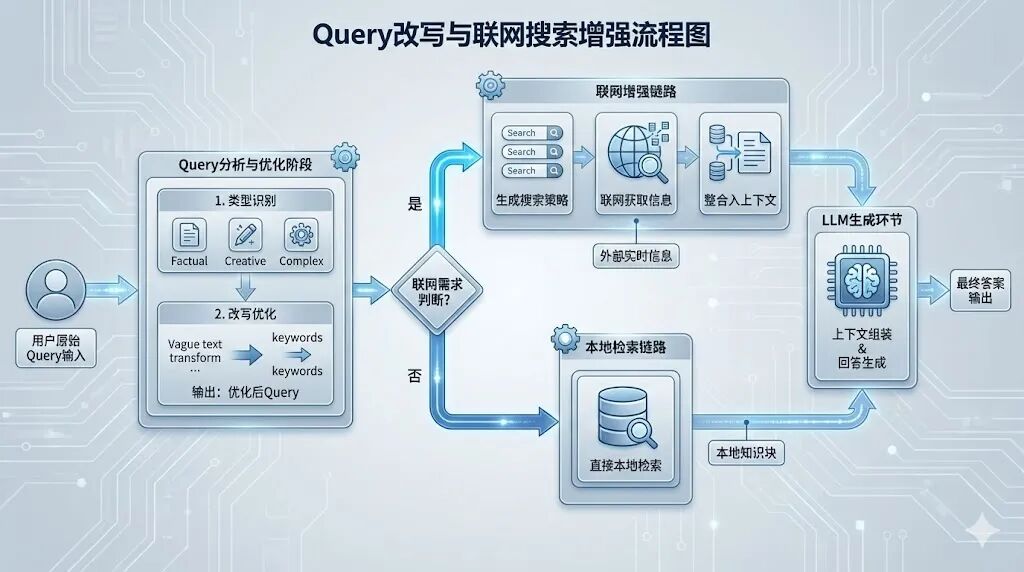
六、RAG优化技巧:Query改写与联网搜索增强
RAG效果的瓶颈往往在“检索”环节,而Query改写与联网搜索能大幅提升检索覆盖度与时效性,解决用户查询模糊、知识滞后问题。
1. Query****改写:让检索更精准
用户查询常存在口语化、模糊化、上下文依赖等问题,需通过改写转化为“书面化、无歧义、高相关性”的检索语句,常见类型与改写策略如下:
(1)五大常见Query类型及改写方法
•上下文依赖型:含“还有”“其他”等词汇,需补充历史上下文。例:用户问“还有其他设施吗?”(上下文提及疯狂动物城园区设施),改写为“除了疯狂动物城警察局、朱迪警官训练营和尼克狐的冰淇淋店之外,疯狂动物城园区还有其他设施吗?”;
•对比型:含“哪个”“更”等比较词汇,需明确对比对象。例:用户问“哪个更好玩?”(上下文提及两个园区),改写为“上海迪士尼乐园的疯狂动物城主题园区和蜘蛛侠主题园区哪个更好玩?”;
•模糊指代型:含“它”“都”等指代词,需替换为明确对象。例:用户问“都什么时候开始?”(上下文提及两地烟花表演),改写为“上海迪士尼乐园和香港迪士尼乐园的烟花表演都什么时候开始?”;
•多意图型:含多个独立问题,需拆分为单意图查询。例:用户问“门票多少钱?需要提前预约吗?”,拆分为“上海迪士尼乐园门票多少钱?”“上海迪士尼乐园门票需要提前预约吗?”;
•反问型:含“不会”“难道”等反问语气,需转化为中立查询。例:用户问“这不会也要提前一个月预订吧?”,改写为“上海迪士尼乐园门票需要提前一个月预订吗?”。
(2)自动意图识别与改写****Prompt
通过LLM自动识别Query类型并改写,提升适配性,核心Prompt如下:
| text ### 指令### 你是智能查询分析专家,需识别用户查询类型并改写,类型包括: 1. 上下文依赖型:含"还有"“其他"等需上下文理解的词汇; 2. 对比型:含"哪个”“比较”“更"等比较词汇; 3. 模糊指代型:含"它”“都”“这个"等指代词; 4. 多意图型:含多个独立问题,用”、“或”?“分隔; 5. 反问型:含"不会”"难道"等反问语气。 优先级:多意图型>模糊指代型,其他类型按语义判断。 返回JSON格式:{“query_type”:“类型”,“rewritten_query”:“改写后查询”,“confidence”:0-1} ### 对话历史### {conversation_history} ### 原始查询### {query} ### 分析结果### |
**2.**联网搜索增强:解决时效性知识需求
对于实时性、动态性知识(如天气、价格、活动),本地知识库无法覆盖,需通过“联网需求识别→Query改写→搜索策略生成→结果整合”增强RAG能力。
(1)联网需求识别条件
当Query包含以下类型信息时,触发联网搜索:
•时效性信息:含“今天”“现在”“最新”等词汇;
•动态数据:价格、营业时间、活动、天气、交通、预订政策、实时人流量;
•外部知识:超出本地知识库覆盖范围的信息(如行业新规、新闻事件)。
(2)联网搜索策略生成
通过LLM生成优化后的搜索Query、关键词、推荐来源与时间范围,示例如下:
原始Query:“下周六上海迪士尼门票多少钱?需要提前多久预订?”
改写后搜索Query:“2026年下周六上海迪士尼乐园门票价格及预订时间要求”
关键词:[“2026年下周六”, “上海迪士尼乐园”, “门票价格”, “预订时间”, “提前预订周期”]
推荐来源:[“迪士尼官方网站”, “携程/飞猪旅游平台”, “官方公众号”]
时间范围:最近7天(确保信息时效性)。
七、总结与展望
RAG技术通过“检索补全知识,生成优化表达”的协同逻辑,有效解决了大模型落地的核心痛点,已成为AI应用开发的必备技术。从技术落地角度,需把握三大核心:一是知识库构建(分块、向量化、向量数据库选型),二是检索精度优化(Embedding模型选型、Query改写、重排序),三是工程化适配(本地部署、成本控制、结果溯源)。
未来RAG技术将向“Native RAG全链路优化”“多模态RAG(文本+图片+音频)”“个性化检索(结合用户画像)”三大方向演进,与微调、提示工程的融合将更紧密。对于开发者而言,掌握RAG技术不仅能提升大模型应用效果,更能拓宽AI落地的业务边界,适配更多专业场景与合规需求。
后续可结合具体业务场景,尝试优化分块策略、自定义Embedding模型、搭建联网RAG系统,逐步提升技术落地能力。
AI大模型从0到精通全套学习大礼包
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以扫描下方链接👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!

01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线


03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的


04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 4
4 0
0- 0



 已为社区贡献635条内容
已为社区贡献635条内容

所有评论(0)