学习周报三十二
本周通过对两篇论文的研读与实践,深入理解了当前大模型训练与多模态生成中的两个关键优化方向。
摘要
本周聚焦于强化学习探索优化与多模态生成模型的技术细节。深入研究论文《Rewarding the Rare》,其针对强化学习后训练中出现的“探索坍缩”问题,提出基于策略层面唯一性的奖励机制,通过聚类分组对稀缺解题思路进行加权奖励,以提升模型在复杂问题求解中的多样性。同时,学习分析了ThinkDiff模型的代码实现,重点探讨了其如何通过提取并迁移视觉语言模型的中间隐藏状态(hidden states),将多模态推理能力高效传递给扩散解码器,实现理解与生成的深度对齐。
Abstract
This week focused on the technical details of reinforcement learning exploration optimization and multimodal generation models. An in-depth study was conducted on the paper “Rewarding the Rare”, which addresses the “exploration collapse” problem in reinforcement learning post-training by proposing a strategy-level uniqueness reward mechanism. It enhances model diversity in complex problem-solving through cluster grouping and weighted rewards for scarce solution strategies. Additionally, the code implementation of the ThinkDiff model was analyzed, with emphasis on how it efficiently transfers multimodal reasoning capabilities to the diffusion decoder by extracting and migrating the intermediate hidden states of the visual language model, achieving deep alignment between understanding and generation.
1、Rewarding the Rare: Uniqueness-Aware RL for Creative Problem Solving in LLMs
1.1 《探索坍缩》
RL 训练中容易出现探索坍缩(Exploration Collapse)问题——Collapse 这个词,在机器学习里,经常指「多样性的缺失」,本来有很多可能性,结果「坍缩」到了一个或者少数的几个点上。在这篇文章里,主要指的是:如果一道难题只有某种冷门思路能做出来,而模型训练后只会一种主流思路,那么你采样 256 次也可能都采不到那个冷门正确思路。
目前提升 LLM 数学和逻辑推理能力的主流范式是强化学习后训练(Post-training with RL)。
简单说,就是给模型一道题,让它生成很多个答案,如果做对了就给奖励(Reward),做错了就惩罚。但是,现在的 RL 训练有一个很大的问题,叫探索坍缩。
比方说,你要去解一道数学题。通往正确答案可能有三条路:
路径 A:套公式(简单,常见)。
路径 B:画图解法(直观,但写起来麻烦)。
路径 C:利用对称性(巧妙,但很难想到)。
在标准的 RL 训练中,一旦模型发现「路径 A」能拿分,它就会疯狂地通过梯度更新来强化「路径 A」。几轮训练后,模型会变得极其自信,遇到类似的题只会套公式。后果是什么呢?
Pass@1 提高:让你做一次,你做对的概率确实高了。
Pass@k 停滞:如果我不放心,让你做 kkk 次,希望你能给我某种解法是正确的。但因为你只会路径 A,万一这道题路径 A 走不通,你就全军覆没了。模型失去了多样性(Diversity)。
现有的方法试图通过增加「随机性」(Entropy Bonus)来解决这个问题,但它们只是在词元(Token) 层面增加随机性。举个例子:模型可能会生成 设 x 为…… 和 令 x 等于……。这在 Token 上是不同的,但在解题策略上是完全一样的。这某种程度上是「虚假的探索」,我们去年也介绍过很多这类工作。
1.2 策略
这篇论文的核心思想非常简单:我们不应该奖励那些「仅仅是换了种说法」的答案,而应该重奖那些「使用了全新解题思路」的答案。
这就是题目中 Rewarding the Rare(奖励稀缺)的含义。如果 10 个答案里,有 8 个用了「套公式法」,那这 8 个答案即便对了,奖励也要打折,因为它们太普通了。如果有 1 个答案用了「对称性法」,且做对了,那这个答案非常珍贵,我们要给它加倍的奖励。
这引入了一个新的概念:策略层面的唯一性(Strategy-level Uniqueness)。
1.3 方法
作者采用了一套基于 GRPO 的改进算法——GRPO 这种算法是 DeepSeek 提出的一种 PPO 家族的改进算法,在 LLM + RL 后训练领域,几乎成了行业的标配。基于这种算法,变着花样进行「分组」和「加权」,涌现出了一大批微创新的变种。这篇文章采用的方法,也属于这个套路。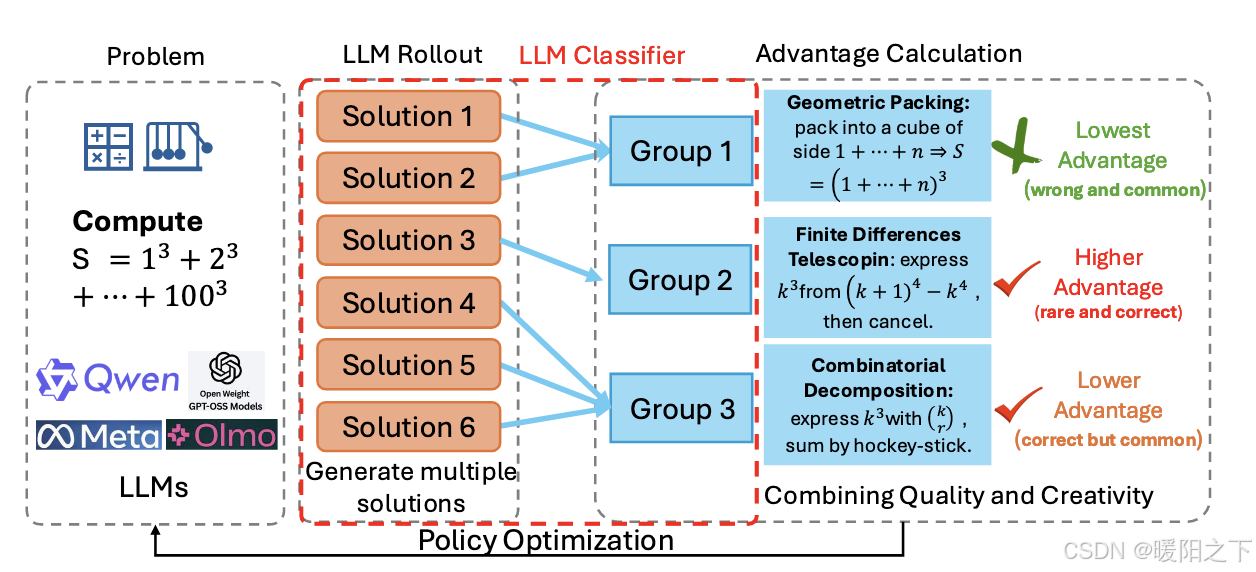
图注:首先让模型针对一个问题生成多个回答(Rollouts);然后引入一个 LLM Judge 作为裁判,把思路一样的回答归为一类;最后根据每一类的数量(Cluster Size)来调整奖励权重——数量越少,唯一性越高,奖励越多。
2 ThinkDiff代码学习
mllama_output_embeddings = {}
mllama_output_embeddings["output_embed"] = [mllama_outputs[i].outputs[0].hidden_states for i in range(batch_size)]
mllama_output_embeddings["input_embed"] = [mllama_outputs[i].prompt_hidden_states for i in range(batch_size)]
mllama_output_embeddings_dict[self.config.vllm_config["embedding_layer_name"]] = mllama_output_embeddings
input_embed:模型“读入 prompt 时”每个输入 token 的表征
output_embed:模型“生成回答时”每个生成 token 的表征(包含生成过程中的推理痕迹)
ThinkDiff 抠 hidden states 的目的不是“为了拿 embedding”,是为了把「多模态推理已经发生过的中间结果」迁移给扩散模型,而不是让扩散模型自己学推理。
总结
本周通过对两篇论文的研读与实践,深入理解了当前大模型训练与多模态生成中的两个关键优化方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)