AI智能体|扣子(Coze)搭建【爆款人性哲学视频】Agent
什么是他人即地狱!
好久不见!我又更新了,今天给大家带来一个关于 Coze 自动生成火柴人哲学视频工作流。
这类火柴人哲学视频在某音还是挺火的。
在哲学方面的话,我认为有一个观点是我觉得比较的重要的,就是“他人即地狱”,跟“着相”,“我执”还有点相似(这两个观点以后吹)。
如果你对这个观点感兴趣的话,不妨听我吹两句,不感兴趣跳过就行!哈哈。
什么是他人即地狱?期待被谁认可就会被谁奴役,这就是他人即地狱的核心!
我用大学时生活给你解释一下。一开始,大家刚进大学的时候,同学们各玩各的获得随性自在。
然而,当大家开始用 “优秀”“普通” 这类标签给同学贴标签、做区分后,氛围就发生了变化。
同学 A 因颜值高,学习好,总拿高分,被同学与老师夸,同学 B 参加比赛拿奖,也常被夸,唯有同学 C 做什么都被评普通,没亮点。
慢慢地,同学 C 开始向同学 A 学习,去提升成绩,向同学 B 学习,去参与比赛,哪怕自己一点都不开心,一点也不喜欢。
一段时间后,同学 C 取得了一点点成绩,但也已经完全变了,他做任何事都先看别人的反应,生怕在被评普通。
回归日常后,这种后遗症很明显,比如刷到精致同学晒旅游朋友圈,他瞬间觉得自己的周末好无趣。
就像我们,看到同龄人买房买车事业成功时,越看越觉得自己像条咸鱼,明明喜欢独处,看到一对情侣时,却突然觉得自己好孤单,甚至在公共场合做点自己喜欢的事,只要有人注视,立刻觉得害羞想逃。
这就是他人即地狱的本质,不是说别人有多坏,而是你对他人认可的期待会变成奴役你的枷锁,最终亲手摧毁自己的世界。
可为什么会这样呢?明明没干什么伤天害理的事。
当你开始在意别人怎么看,就会从主宰自己的主体,变成被他人定义的客体。
萨特在《禁闭》里说,地狱是他人的注视与评价,把自我定义的权利交给了别人,从而造就了真正的地狱。
但其实,真正的地狱不是他人,而是甘愿放弃自由,屈从于他者目光的自己。
比如有人说你幽默,你便刻意维持这份幽默。久而久之,就真的被这个标签困住了,每个人心中都曾在他人的目光里怀疑自己,束缚自己。
但萨特说,存在先于本质,我们从不是他人评价的附属品,而是自己人生的塑造者。
好了,今天的牛就吹到这里了,我们来看看整个视频的效果是怎么样的。
火柴人哲学
需求分析
需求的话,我个人分析主要集中在两个(有补充可评论区留言)。
第一个就是做哲学 IP 的博主:通过这种动画视频的方式来教学学员以及传播知识点,这种一般来说都是有后端用户的承接能力,比如课程,咨询等。
第二个就是做一些副业:通过这种自动化生产视频的方式,提升生产效率,去批量生产爆款视频获取流量,通过流量以及带货一些哲学相关的书籍来变现。
智能体功能分析
能生成配图提示词同时生成配图。
能生成视频提示词同时生成视频。
能生成文案音频。
能生成动效。
能上传文案或 AI 自动生成。
能上传 BGM,视频拥有字幕。
能进行下载。
流程分析
整体事件流程分析。
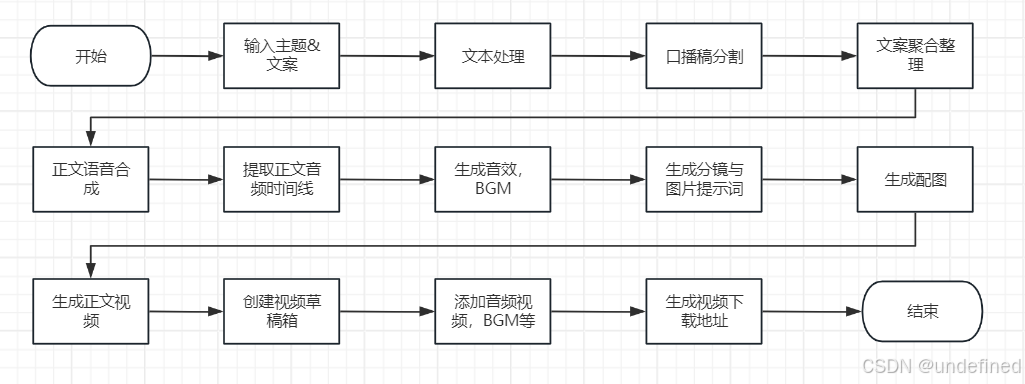
整体 Coze 工作流程分析。
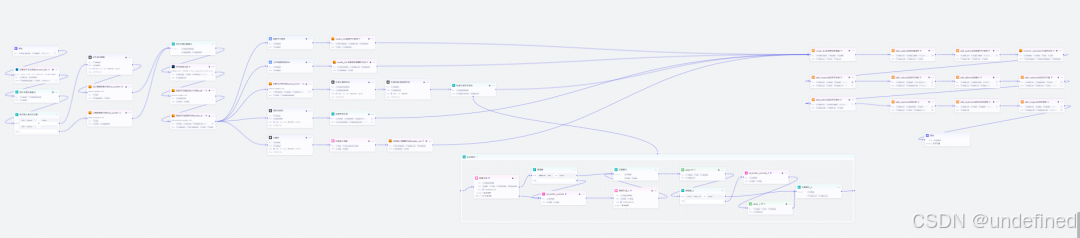
调用视频生成子工作流。
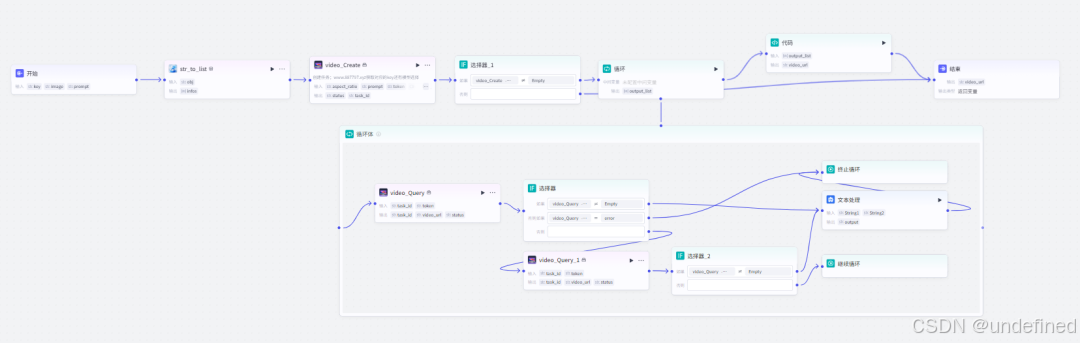
火柴人哲学工作流搭建教程
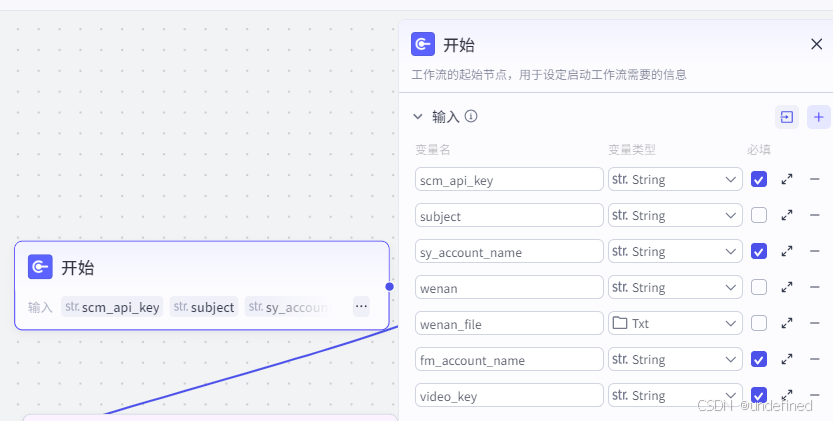
第一步,开始节点
开始节点我们设置参数 scm_api_key ,suject,sy_account_name,wenan,wenan_file,fm_account_name,video_key。
它们分别代表音频时间线插件的 key,选题,视频水印,文案,文案文件,封面标题,视频插件的 key 。
这里的文案文件可以自己上传,也可以自己填写,也可以 AI 生成。
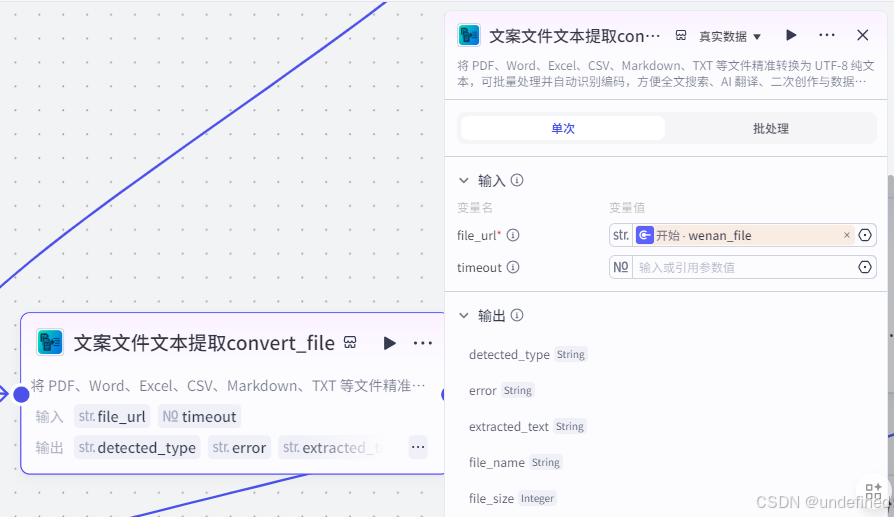
第二步,文档转文本
这一节点的作用主要是对文案文件文本的内容进行提取,注意这一步并非必要的,只有需要上传文案文件的时候需要。
这里我们设置输入参数 file_url 数据来源为开始节点的 wenan_file 。
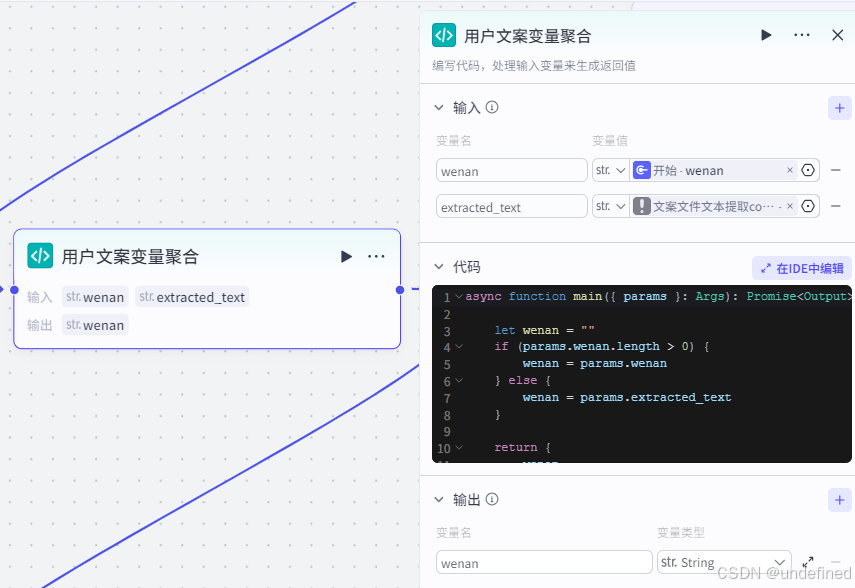
第三步,用户文案聚合
这一步的作用主要是通过代码来实现文案的聚合,为后面来判断我们是那种方式输入的文案(文件还是输入还是 AI )做筛选。
这里我们设置输入参数 wenan ,extracted_text,数据来源为开始节点的 wenan 与 文档转文本节点的 extracted_text。
第四步,判断筛选
这一步的作用主要是做一个文案的筛选,看文案是自己输入还是接下来交给 AI 。
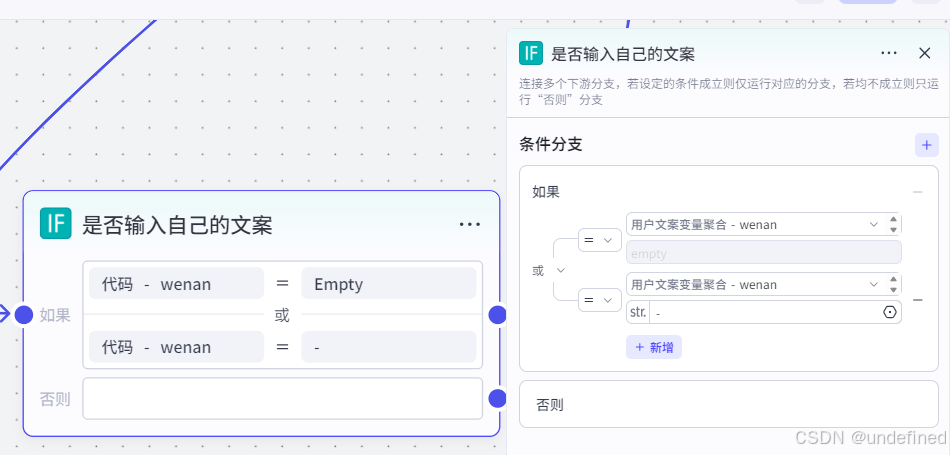
判断为空:
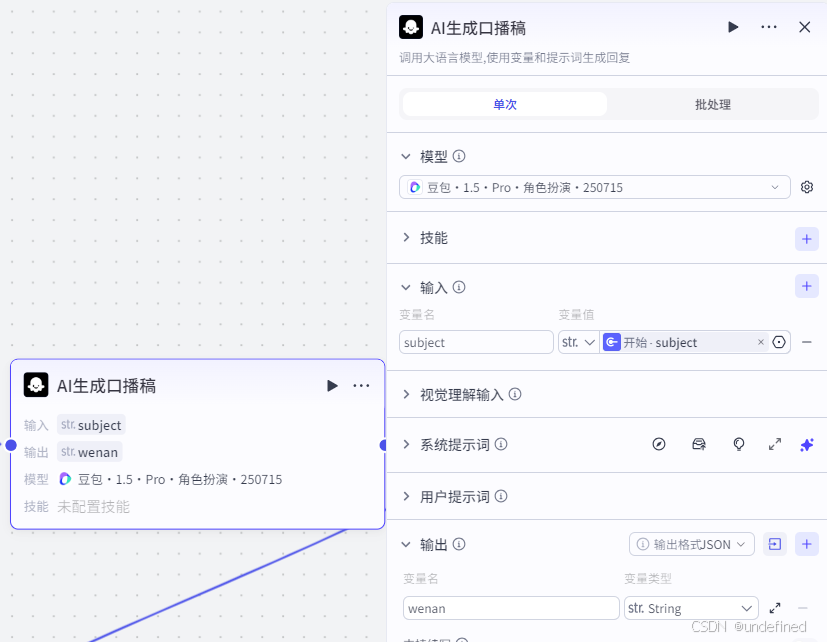
此时 AI 生成口播稿,我们添加 AI 节点,通过 AI 来生成,设置输入参数 subject 数据来源为开始节点的 subject ,设置输出参数 wenan。
注意这里需要提示词的话,找我拿就行。
第五步,口播稿分割
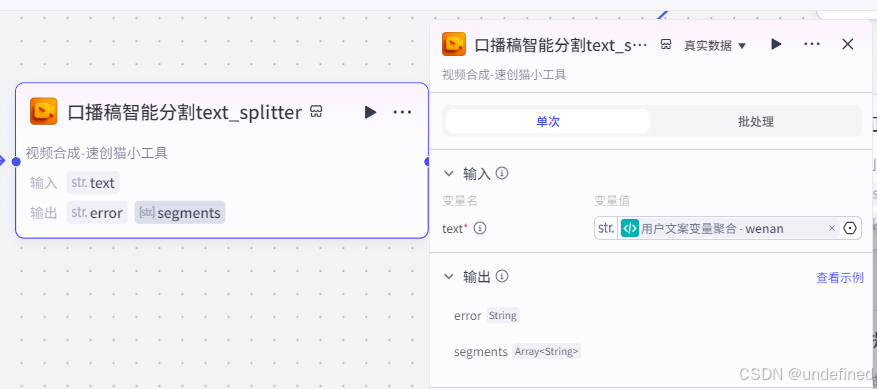
这一步的作用主要是将之前上传/生成的口播稿进行分割,分割成一句句的话,为后面形成视频做准备。
这里我们设置输入参数,如果文案是自己输入的就选择用户文案变量聚合节点的 wenan ,如果是 ai 生成的就选择大模型节点的 wenan 。
第六步,语音合成
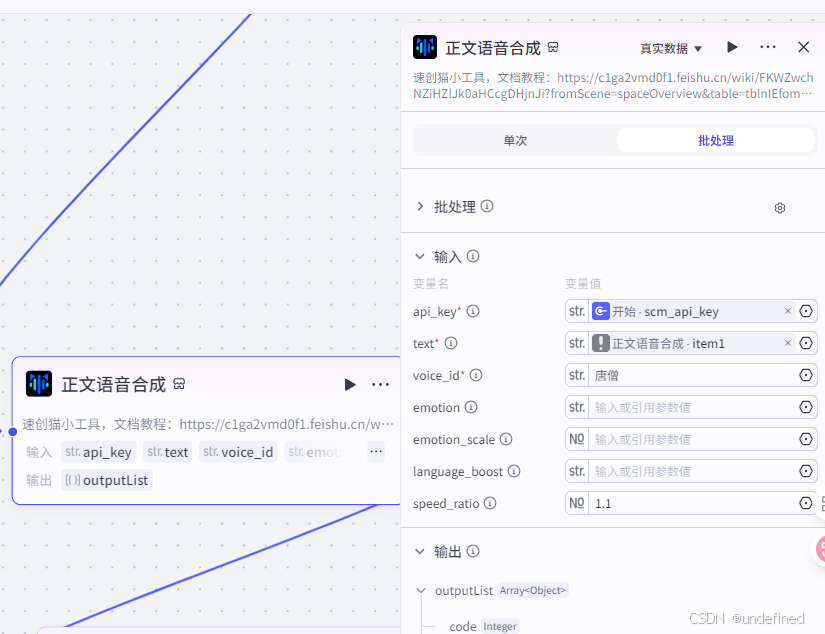
这一步的作用主要是合成我们分割口播稿的语音。
这里我们设置输入参数 api_key,text,voice_id,speed_ratio,它们分别代表插件的 key,文本,音色,语音播放速度。
第七步,转语音url为列表
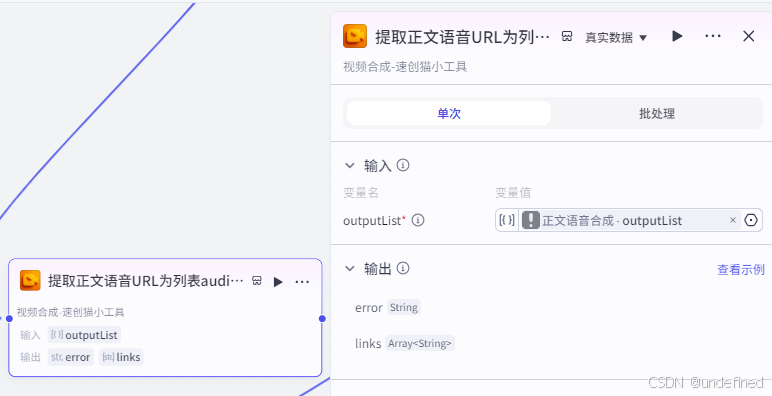
这一步的作用主要是提取正文的语音为 URL 为后面作为提取音频时间线做准备。
这里我们设置输入参数 outputList 数据来源为语音合成的 outputList 。
第八步,提取时间线
这一步的作用主要是确定正文音频的时间线,为后面文案音频放在视频位置做准备。
这里我们设置输入参数 links,api_key,silence_duration,trim_breath,分别代表音频链接组,插件的 key ,静音检测,移气口。
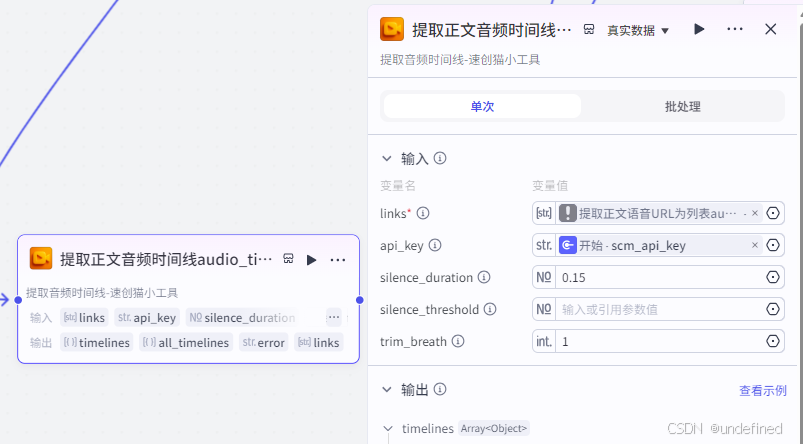
第九步,打字音效
这一步的作用是添加打字音效,这里我们设置输入参数 all_timeline,media_url,数据为:[{"start": 0, "end": 391833}],以及键盘打字音效的 output 。
键盘打字音效这个节点是咱们上传的文件,这里我就不单独解释这个节点了,不懂可以来问俺。
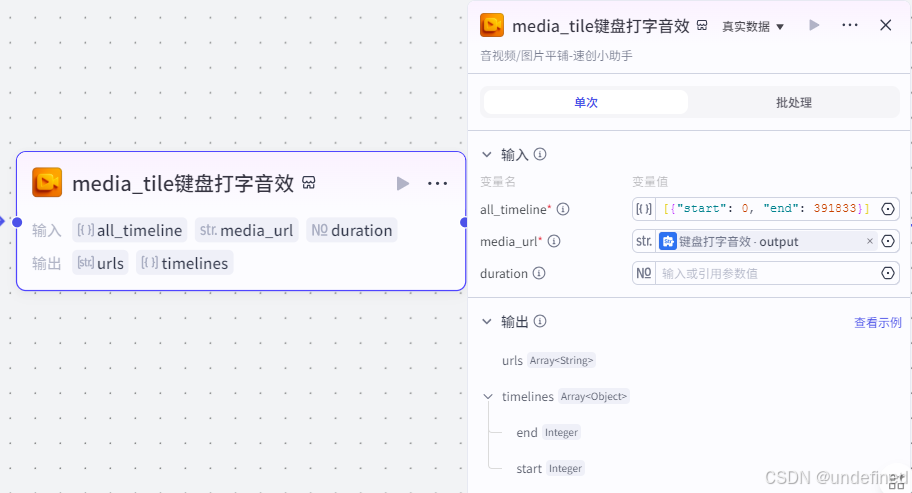
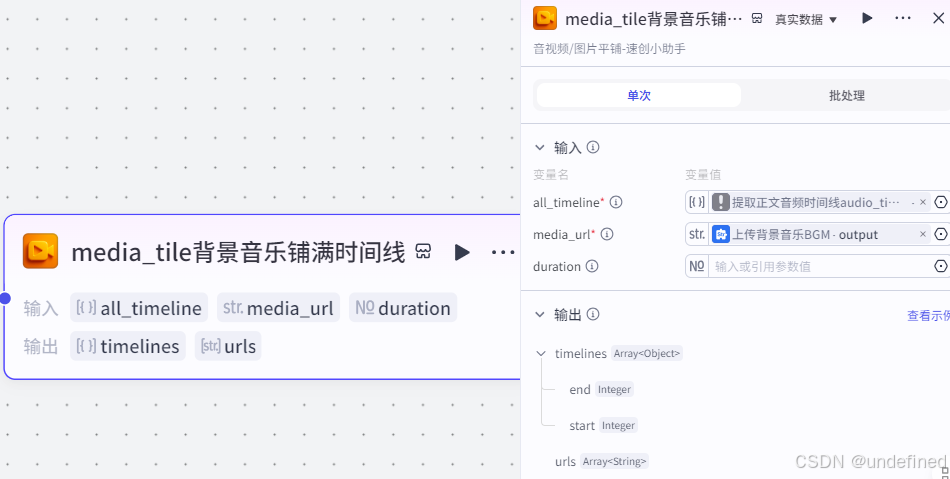
第十步,BGM
这一步的作用是上传背景音乐,并且把背景音乐铺满整条时间线,这里我们设置输入参数 all_timeline,media_url,数据来源如图所示。
注意这个media_url参数来源的这个节点和上一步的一样,是上传 BGM 文件,这个节点我就不单独讲了。
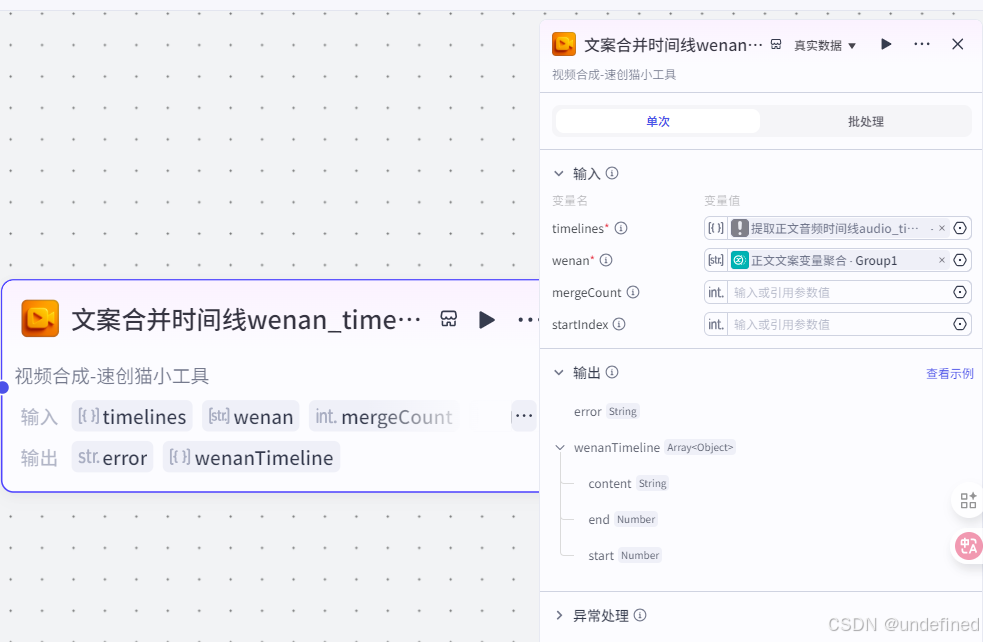
第十一步,文案时间线合并
这一步的作用是将文案的时间线整理起来,合并成一条时间线,为后续生成分镜图片与视频做准备。
这里的参数 wenan 数据来源如果是上传的就选自己上传的,如果是 AI 生成的就选 AI 生成的。
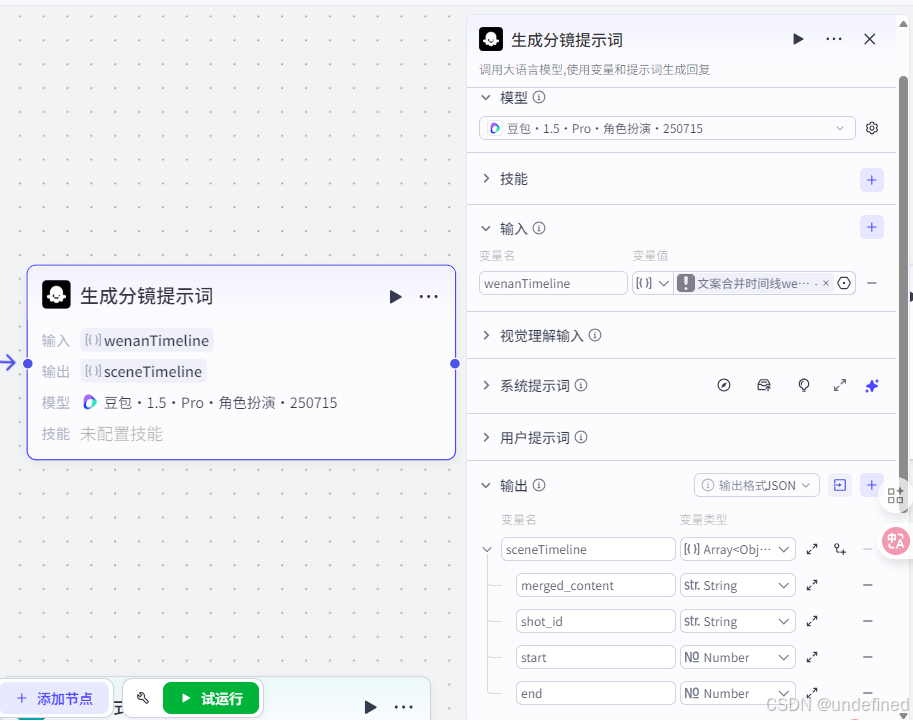
第十二步,分镜提示词
这一步的作用主要是去生成分镜的提示词,为后面生成分镜做准备。
这里我们选择豆包大模型,设置输入参数 wenanTimeline ,输出参数设置 sceneTimeline 数组为一组分镜。
注意这里需要提示词的话,找我拿就行。
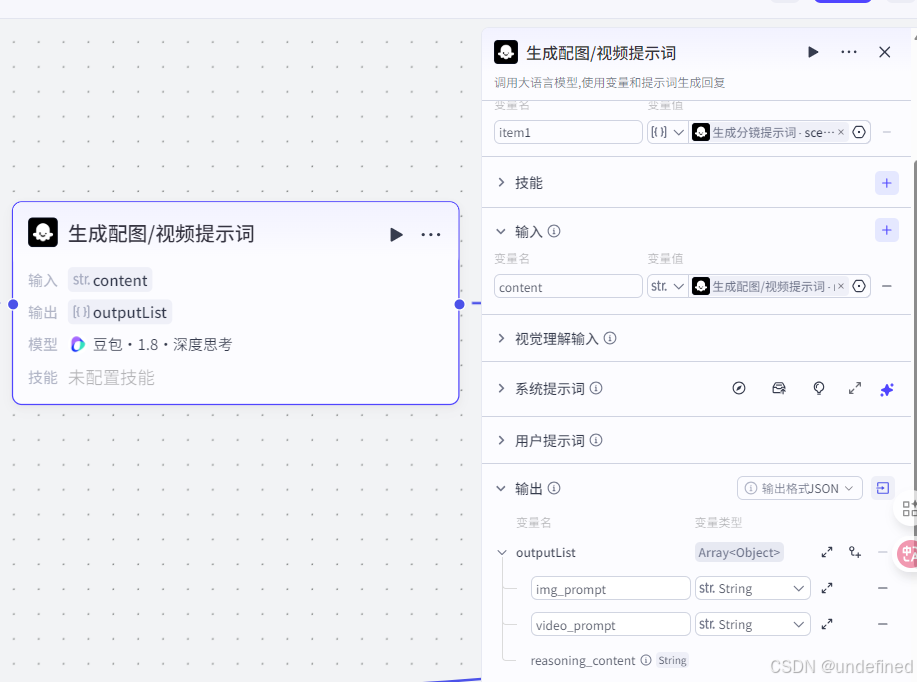
第十三步,配图&视频提示词
这一步的作用是去生成配图和视频的提示词,为后续生成配图与视频做准备,这里我们先批处理分镜数组,确定需要做多少张图,然后再生成提示词。
所以我们设置批处理参数 item1 数据来源为分镜提示词节点,设置输入参数为本节点的 item1 ,设置输出参数数组 outputList 。
注意这里需要提示词的话,找我拿就行。
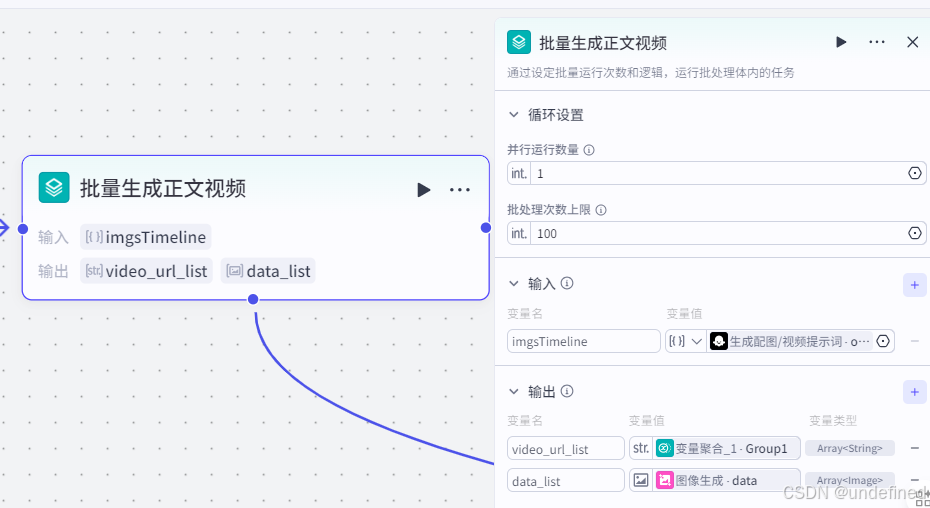
第十四步,生成正文视频
这一步的作用是通过批处理的方式来生成正文视频,需要注意的是我们不能设置过高的并行运行数量,不然的话节点会报错。
这里具体的参数设置我们直接看图片就可以了。
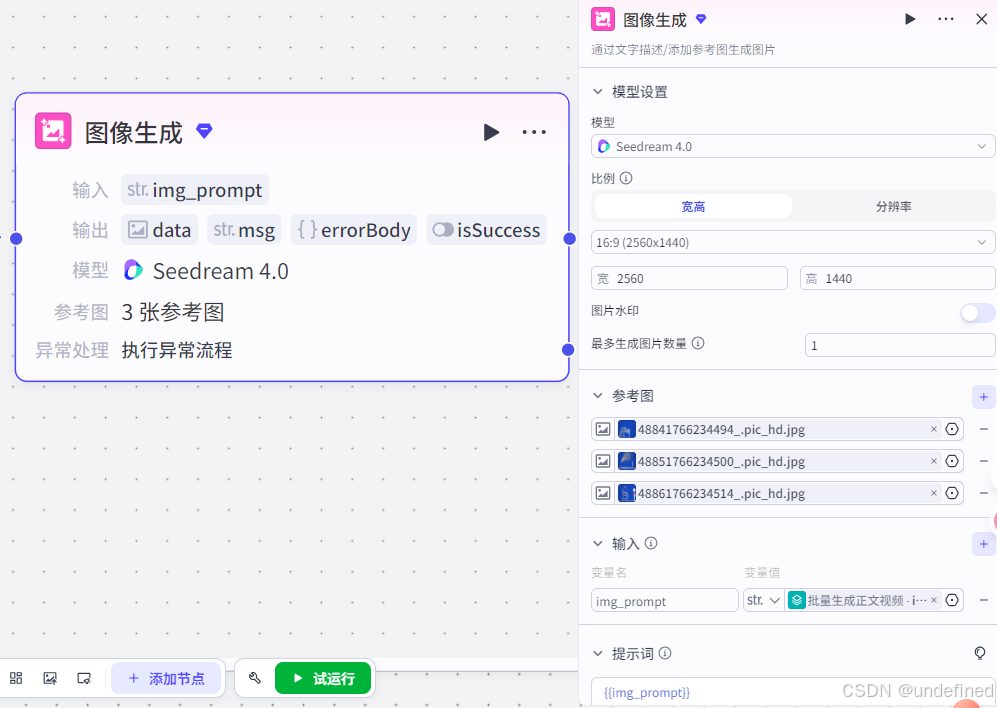
批处理体:图像生成
这一步的作用就是我们去生成对应的图片,由于我们想对标该博主的视频,所以我们这里需要去上传参考图。
这里的模型,比例,以及参数的设置,我们直接看图片就行了,不过这里的参考图我就不提供了,需要的可以自己去找一下。
批处理体:视频生成(子工作流)
这里我们通过调用视频生成的子工作流去根据图片生成视频。
但这里我就不单独讲这个子工作流了,需要子工作流的直接找我就可以了。
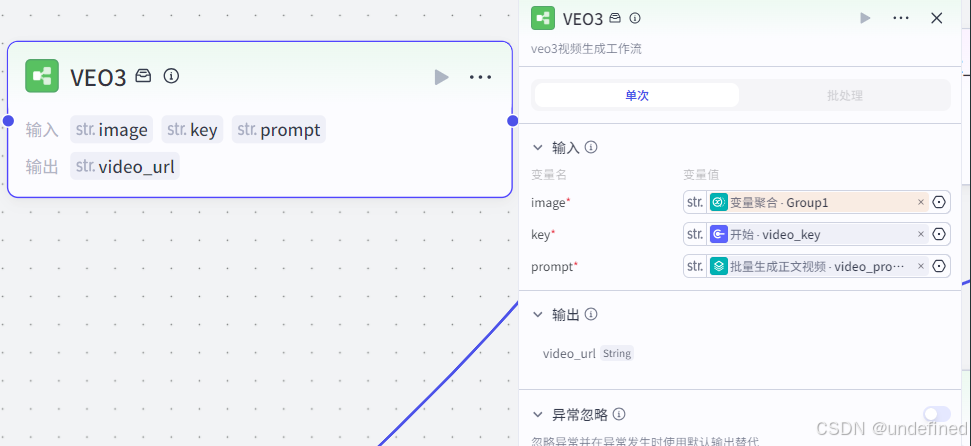
第十五步,提取关键词
这一步的作用主要是对视频的文案内容提取关键词,为形成视频的黄金三秒做准备。
这里我们设置输入参数 wenan 数据来源和刚说的一样,设置输出参数 keywords ,参数为数组格式。
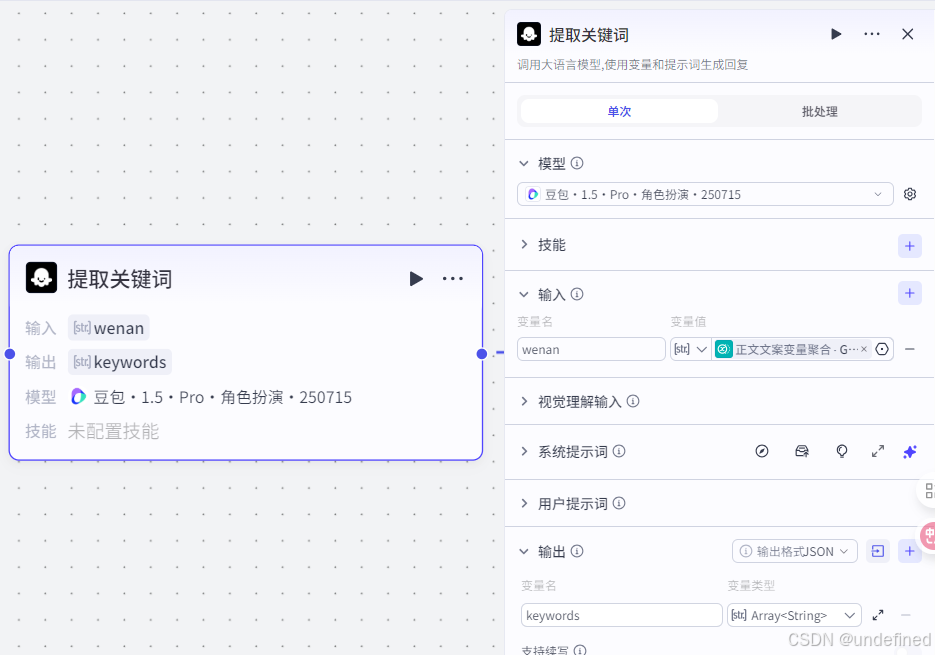
第十六步,动态样式生成
这一步的作用是对刚才关键词用代码的形式去生成一个字体动画的效果,具体的参数设置我们直接看图片就行了。
这里需要代码的话可以来找我拿。
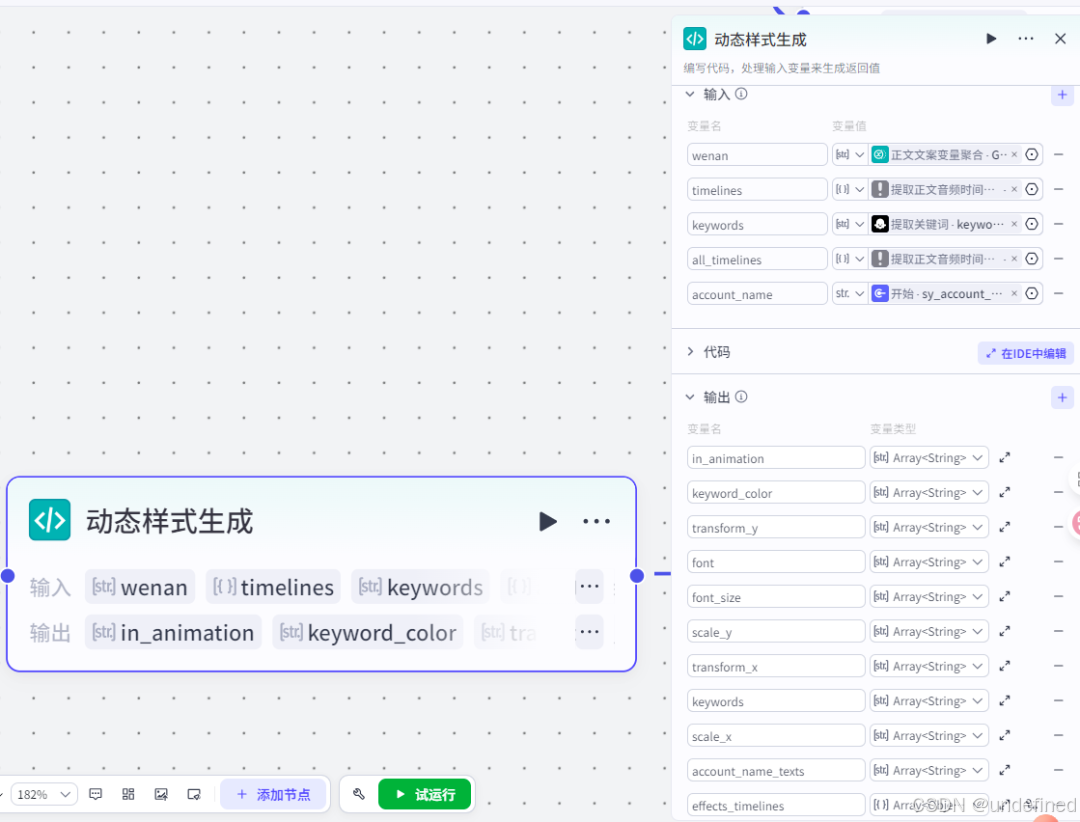
第十七步,视频封面
这一步的作用主要是生成封面图片的关键词,为生成一个封面做准备。
这里我们根据文案来确定关键词,所以输入参数来源文案,输出参数 output 即为关键词。
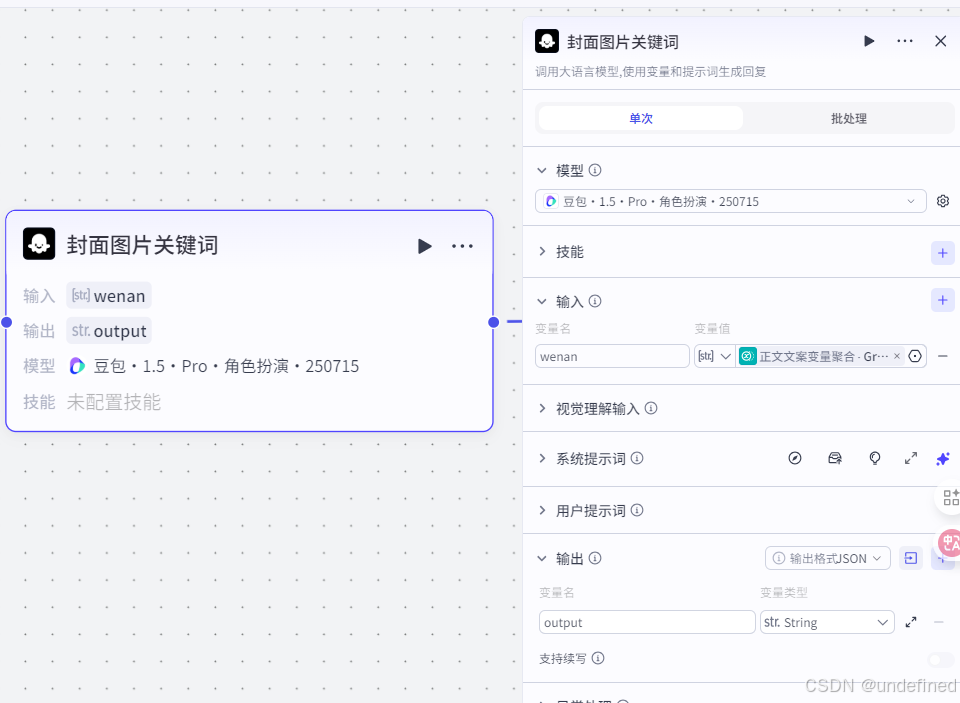
第十八步,封面图片
这一步的作用毫无疑问了,就是生成视频的封面,具体的参数设置我们直接看图片就可以了。
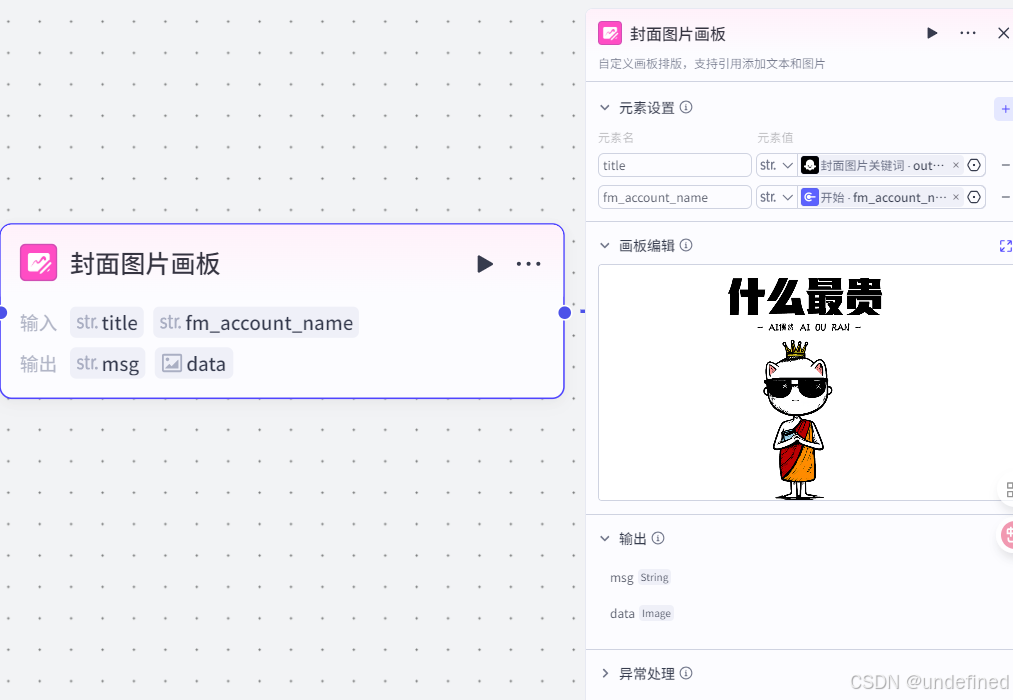
第二十步,封面铺进时间线
这一步的作用是将我们生成的视频,铺到时间线里面,为后面形成视频做准备,我们设置输入参数 all_timeline 为:[{"start": 0, "end": 66666}]
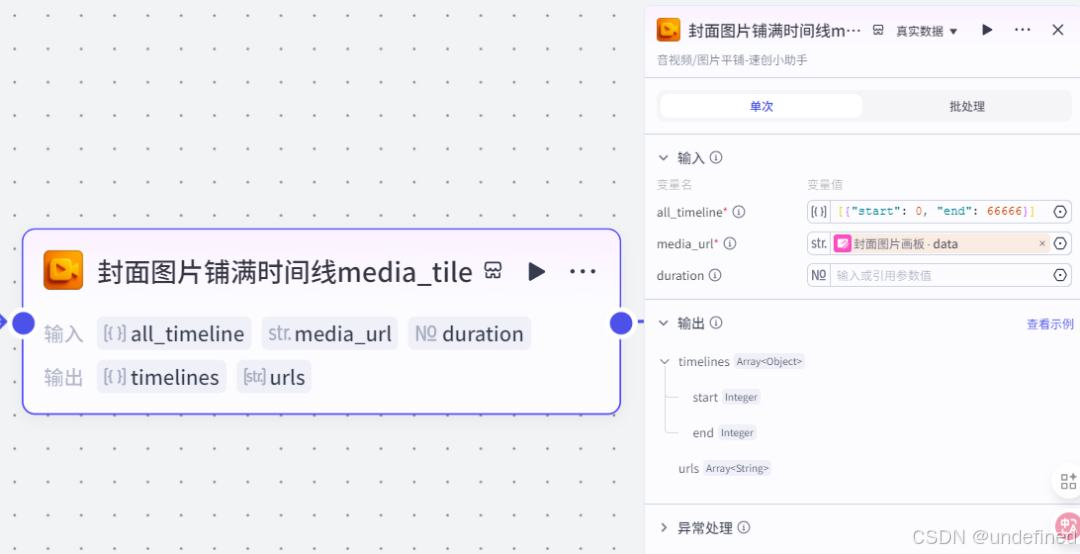
第二十一步,创建视频草稿箱
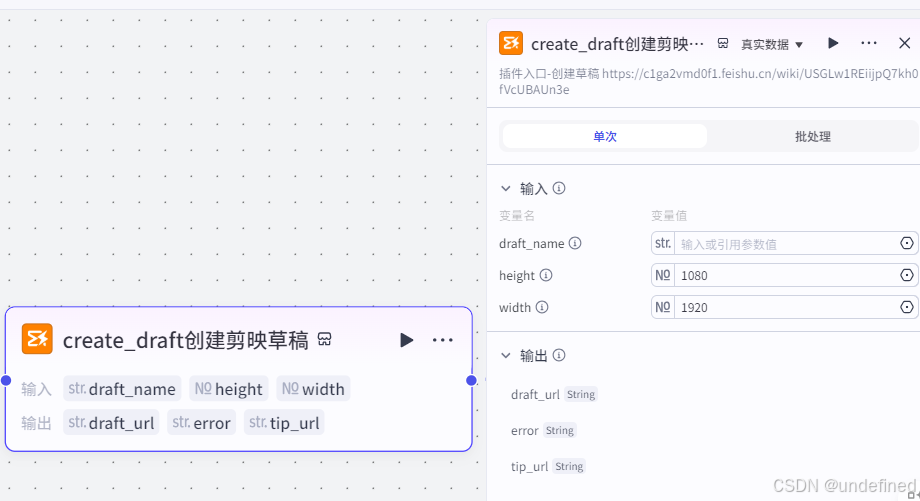
由于前面我们已经生成了图片,视频,文案语音,动效,背景音乐,所以之后我们需要把这些东西打包进一个视频里面,因此我们需要创建一个视频的草稿箱。
具体的参数设置,我们直接看图片就行了。
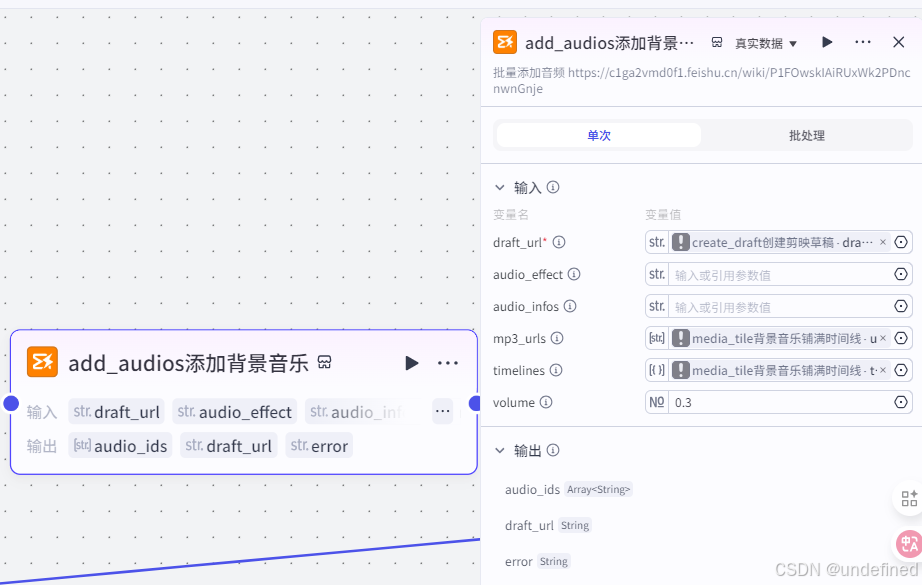
第二十二步,添加 BGM
这一步的作用是将 BGM 添加进视频草稿箱中,具体的参数设置我们直接看图片就可以了。
第二十三步,添加打字音效
这一步的作用是将键盘打字音效添加进视频草稿箱中,具体的参数设置我们直接看图片就可以了。
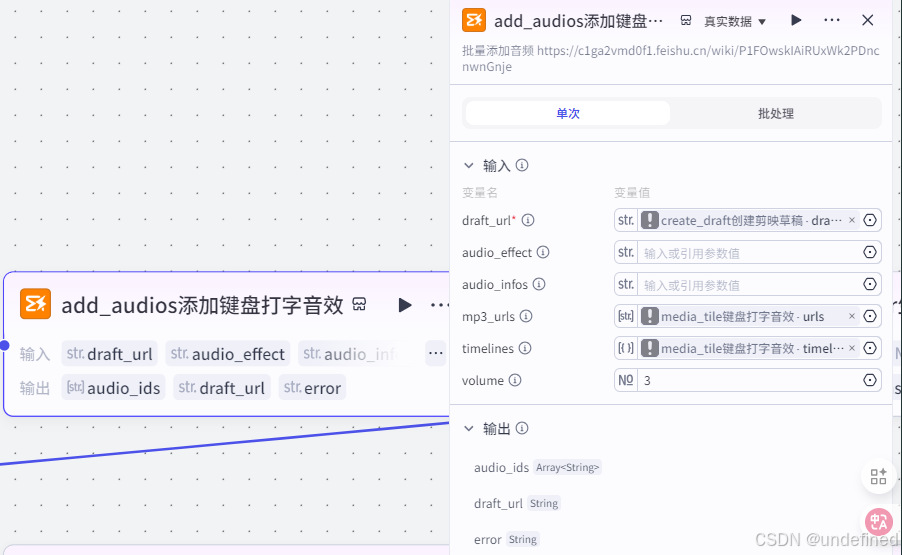
第二十四步,生成时间线
这一步的作用是在视频的草稿箱中去添加时间线,具体的参数设置我们直接看图片就可以了。
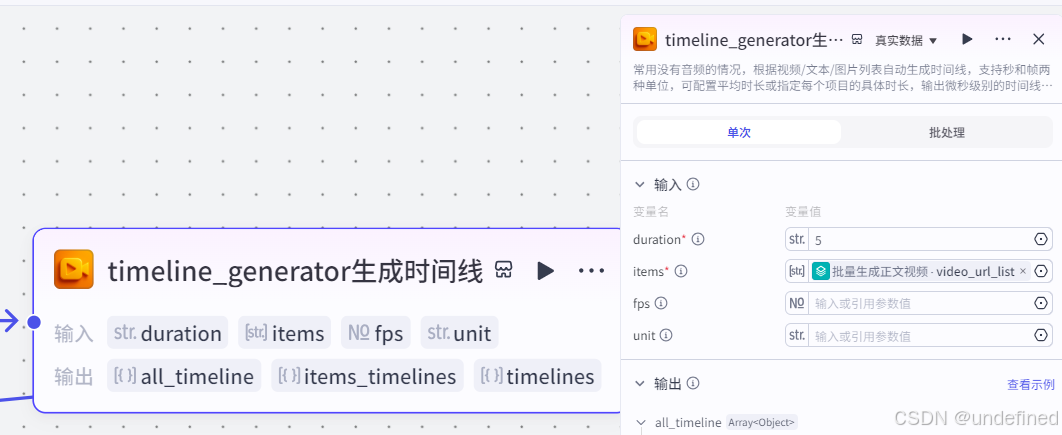
第二十五步,添加正文配图
这一步的作用是将正文的配图添加进视频草稿箱中,具体的参数设置我们直接看图片就可以了。
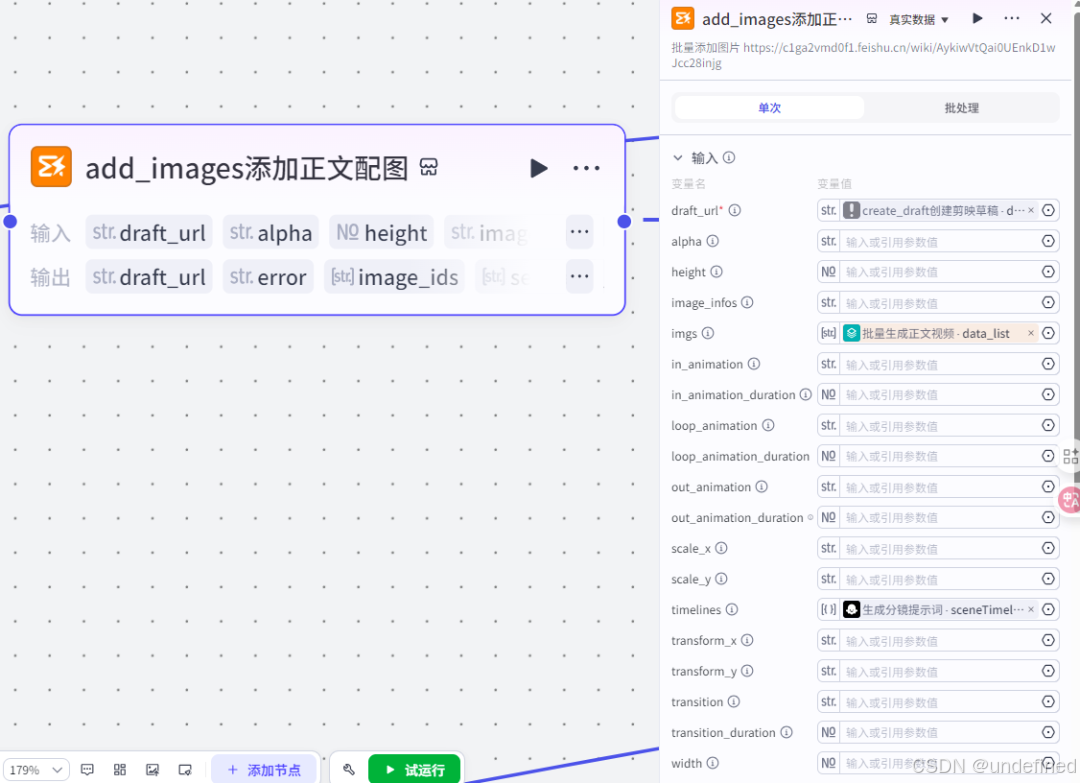
第二十六步,添加正文配图
这一步的作用是将正文的配图添加进视频草稿箱中,具体的参数设置我们直接看图片就可以了。
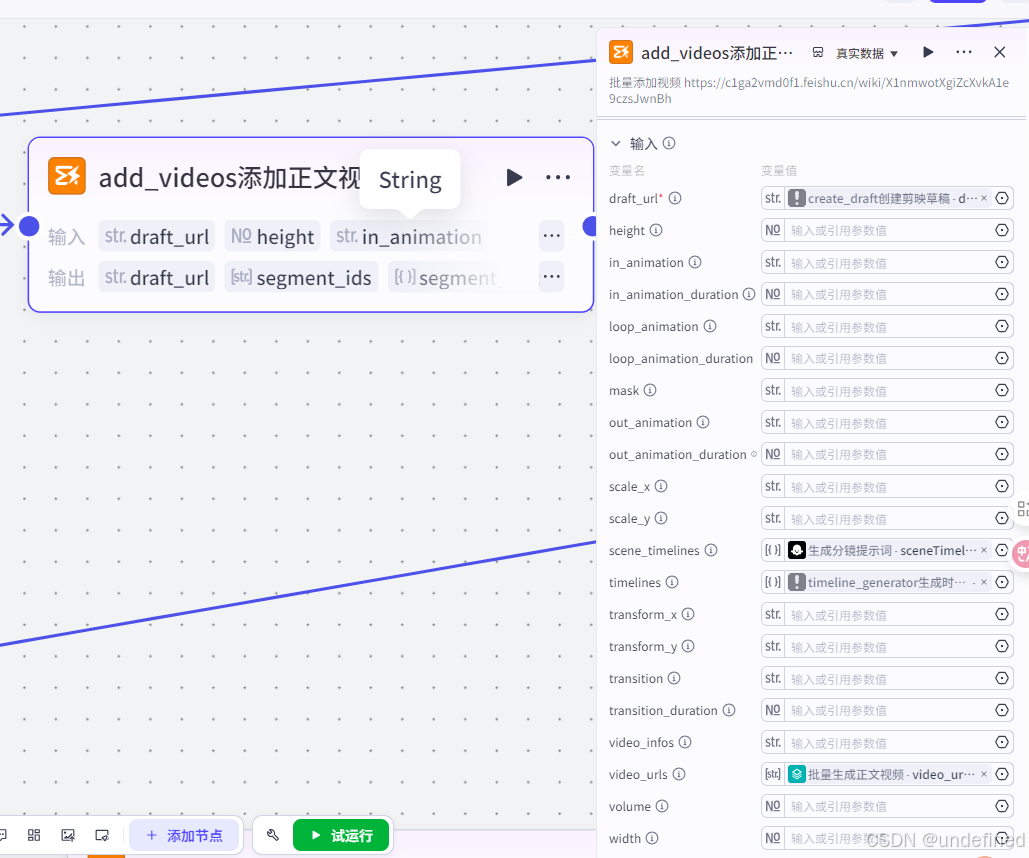
第二十七步,添加噪点
这一步的作用是将噪点添加进视频草稿箱中,具体的参数设置我们直接看图片就可以了。
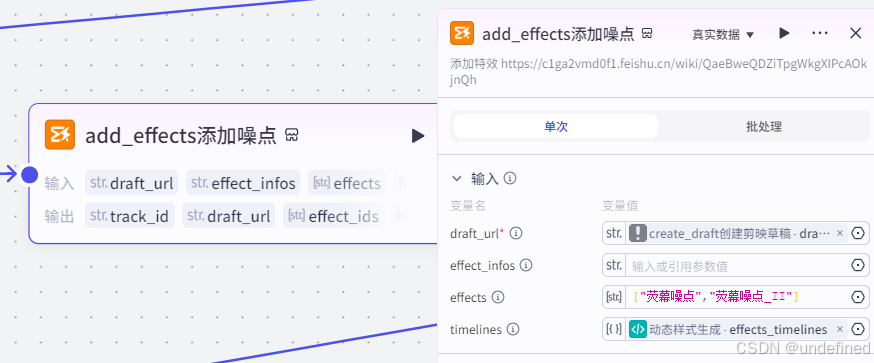
第二十八步,添加字幕
这一步的作用是将正文字幕添加进视频草稿箱中,具体的参数设置我们直接看图片就可以了。
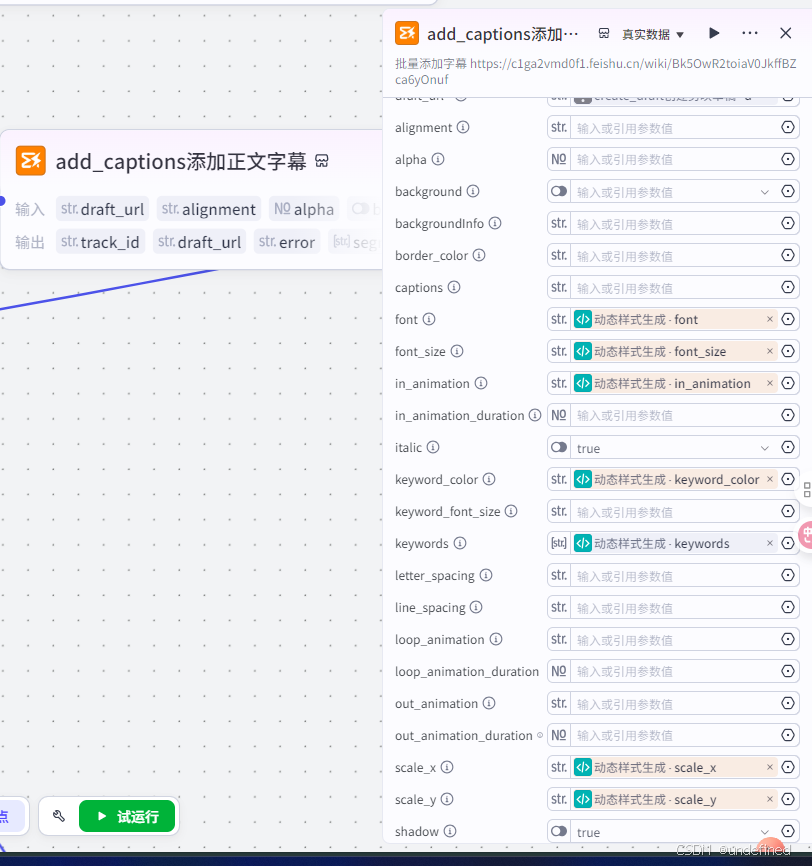
第二十九步,添加音频
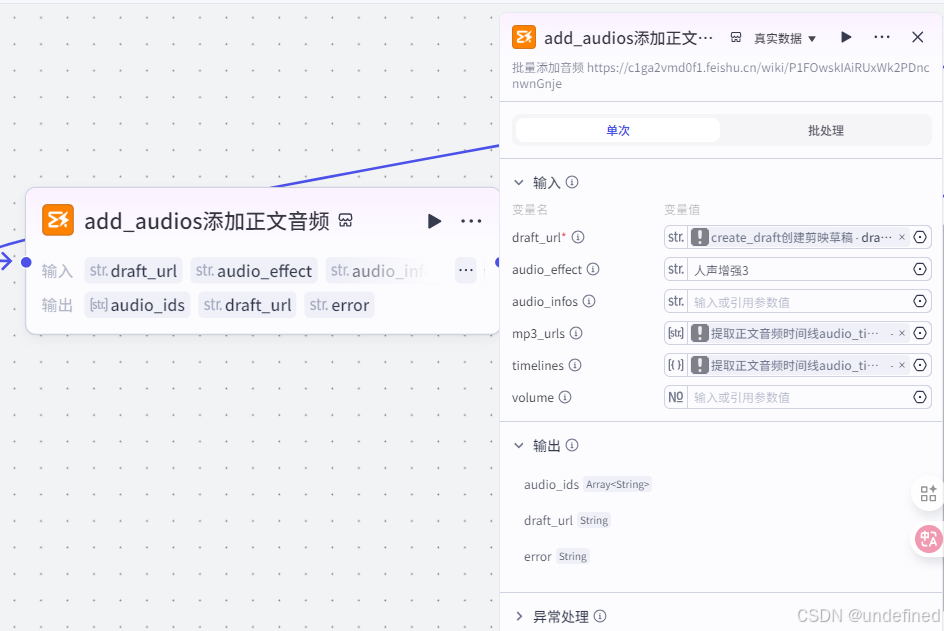
这一步的作用是将正文的音频添加进视频草稿箱中,具体的参数设置我们直接看图片就可以了。
第三十步,添加水印
这一步的作用主要是为视频添加水印,作为一个原创作者的证明,由于大家的各不相同,我这里就不展示对应的参数了,后面大家自己根据情况二改就好了。
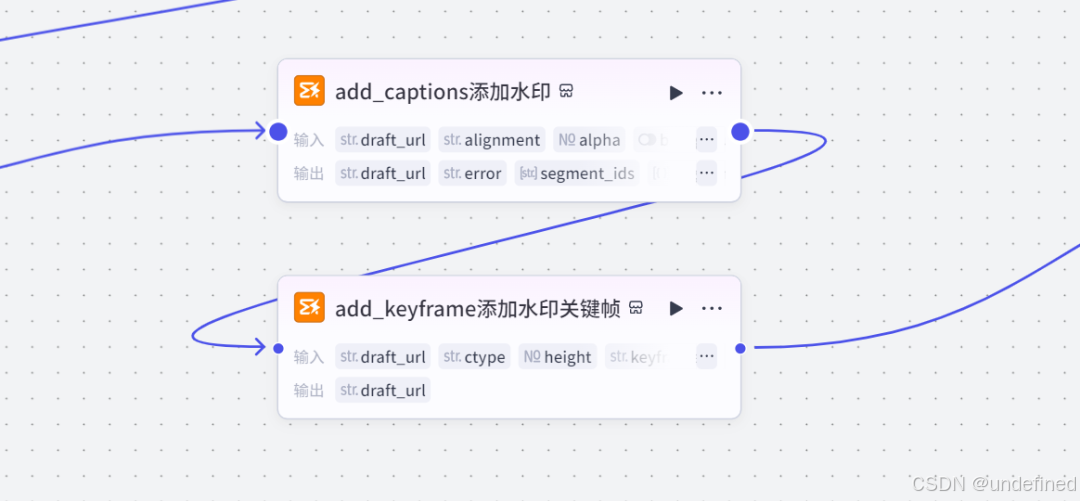
第三十一步,封面帧
这一步的作用就是为视频的封面添加对应的视频帧,然后放进草稿箱中,具体的参数我们直接看图片就可以了。
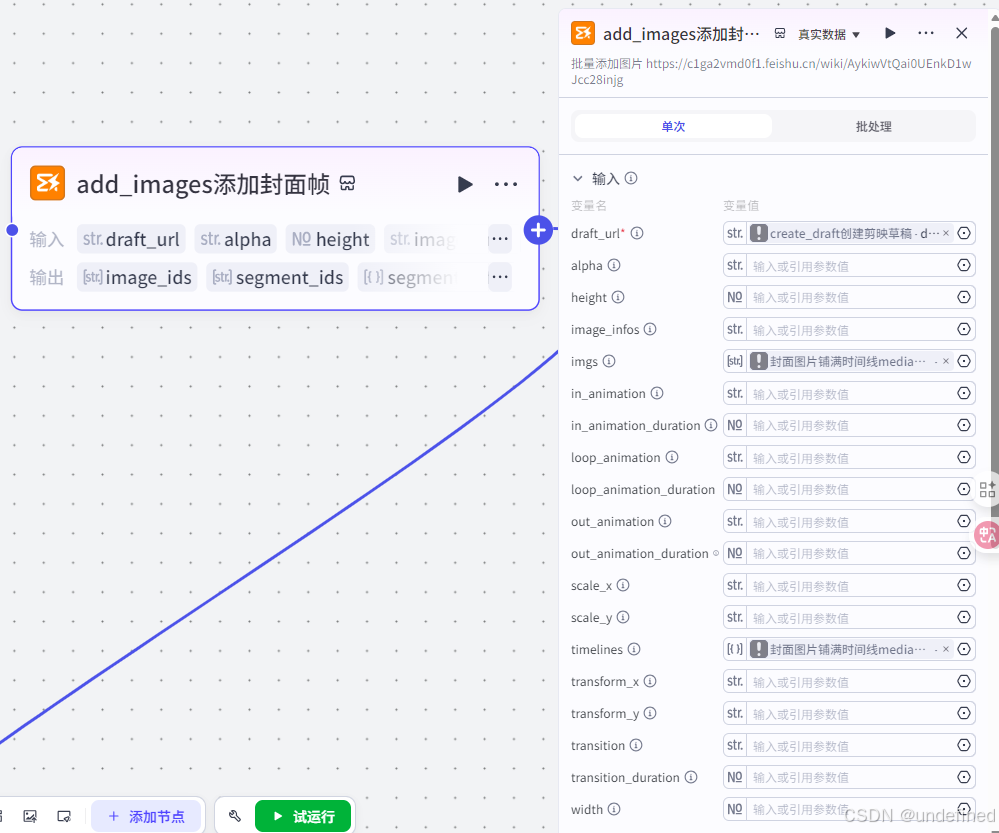
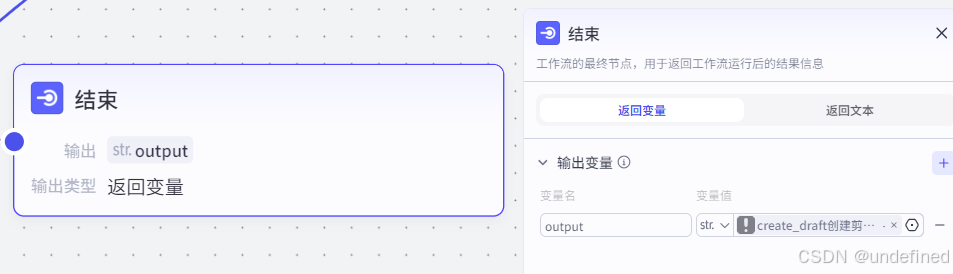
第三十二步,结束
这里的结束节点,我们回传一个视频下载的链接就可以了。
总结
整体的步骤其实远超 32 步,这里我不建议新手直接去做这个工作流,本文这样也只是给大家做一个思路的教学。
如果对本文的工作流感兴趣的,可以随心打赏,我直接发你!
本期的内容就到这里了,感谢你的耐心。
如果看完喜欢,请帮忙转发分享一下,你的点赞转发,就是我更新下去的动力!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)