Agentic AI 学习笔记(4)
构建Agentic AI的实践技巧
一、评估
先上路
快速原型和迭代是关键。推荐采用快速而粗糙的迭代方法:
-
先构建一个非常简易,但功能完整的原型系统:不要因为觉得评估是一个大型项目,就不敢轻易建立,或者花漫长的时间去做理论调研。
-
试运行并观察输出,找出表现不佳的地方:先用 10-20 个例子开始,快速获得一些指标来辅助人工观察。
-
迭代改进评估:随着系统和评估的成熟,可以增加评估集的规模。如果系统改进了但评估分数没有提高,意味着该改进评估本身了。
-
利用观察结果来确定后续开发工作的优先级和方向,避免脱离实际过度空想:以专业人士的行为为灵感: 对于自动化人类任务的系统,观察系统在哪些方面性能不如人类专家,以此作为下一阶段工作的重点。
二、错误分析和下一步行动任务的优先级
谈问题发现
术语解读
trace:代理在运行过程中,每一步产生的中间输出的整体集合被称为追踪 (trace)。
span:单个步骤的输出有时被称为 span。
错误分析技巧
- 陪看查看trace的习惯
- 进行错误分析确定那个组件表现不佳,导致最终输出质量差。
- 建立电子表格进行量化: 为了更严谨地分析,可以建立一个电子表格,明确地统计每个组件出现“错误”的频率。
- 错误的定义: 某一步的输出明显差于一个人类专家在给定相同输入时会给出的结果。统计示例: 记录在所有被分析的错误案例中,搜索词不佳的比例、搜索结果不佳的比例等。
- 指导决策: 如果发现对搜索结果不满意的频率远高于对搜索词不满意的频率(如 45% vs 5%),那么工作重点就应放在改进网页搜索引擎或调整其参数上,而不是更改搜索词的生成逻辑。
- 利用错误分析输出来决定应集中精力的领域
三、端到端评估与组件级评估
谈问题发现的方法
端到端评估和组件级评估的关系有些类似端到端测试/集成测试与单元测试:
* 端到端评估成本高昂,即使是更换搜索引擎这样的小改动,都需要重新运行整个复杂的工作流程进行端到端评估,时间和金钱成本很高。同时,其他组件的随机性或噪声可能会掩盖被改进组件带来的微小、增量改进。
* 组件级评估更高效, 信号更清晰,避免了整体系统的复杂性带来的噪声。还适用于团队分工: 如果有多个团队分别负责不同组件,每个团队可以自行维护指标。
组件级评估与端到端评估的关系与顺序如下:
-
通过错误分析确定一个问题组件(如网页搜索)。
-
构建和使用组件级评估来高效地进行调优和增量改进。
-
在调优后,运行最终的端到端评估,以验证组件的改进确实提升了整个系统的整体性能。
四、解决识别的问题
对于非 LLM 组件,比如网页搜索、RAG 检索、代码执行、传统 ML 模型来说,改进方式非常多样。
-
调整参数或超参数:
-
网页搜索: 调整结果数量、日期范围等。
-
RAG 检索: 更改相似度阈值、文本分块大小等。
-
人物检测: 调整检测阈值,以权衡误报和漏报。
-
-
替换组件: 尝试更换不同的服务提供商,如不同的 RAG 搜索引擎、不同的 Web 搜索 API找到最适合系统的一个。按笔者经验,在国内查询企业营收报表和财务信息,使用百度搜索的效果就远超Bing或Google,但查询学术资源却完全相反。
对于LLM 组件,改进主要围绕输入、模型本身和工作流程结构展开。
-
改进提示词:增加明确指令(在提示词中指明一些资源和任务应有的规划路径,而不是让LLM自己猜);使用少样本提示 (添加具体的输入和期望输出示例)
-
尝试不同的 LLM: 不要嫌麻烦,多测试几款 LLM,并使用评估 (Evals) 来选择最适合特定应用的最佳模型。
-
任务分解:如果单个步骤的指令过于复杂,导致 LLM 难以准确执行,考虑将任务分解为更小的、更易于管理的步骤,比如拆成生成步骤 + 反思步骤,或连续多次调用。
-
微调模型:这是最复杂、成本最高的选项。只有在穷尽所有其他方法后,仍需要挤出最后几个百分点的性能改进时才考虑。它适用于更成熟且性能要求极高的应用。
拥有对不同 LLM 能力的直觉,能使开发者更高效地选择模型和编写提示词。这样的直觉要如何培养?
-
频繁试用不同模型: 经常测试新的闭源和开源模型,观察它们在不同查询上的表现。
-
建立个人评估集: 使用一套固定的评估任务来校准不同模型的能力。
-
阅读他人的提示词: 大量阅读从业者、专家或开源框架中的提示词,了解不同任务/模型/场景下的最佳实践,提高自己编写提示词的能力。
-
在工作流程中尝试: 实际在Agent工作流程中尝试不同的模型,查看追踪 (Traces) 和组件/端到端评估,观察它们在特定任务中的性能、价格和速度的权衡。

五、延迟缓解和成本削减
在系统输出质量达到要求后,下一个优化重点是:优化工作流程的延迟和成本。
需要强调的是,对于早期团队而言,高质量的输出,比延迟与价格重要得多,不应该首先把时间花在延迟与价格优化上。等系统已经运行良好之后,才应该将精力转向延迟优化;只有当系统有了大量用户,成本成了问题之后,才是开始集中优化成本的理想时机。
-
优化延迟与速度的方法
优化延迟的关键在于进行计时基准测试,找出工作流程中的瓶颈。
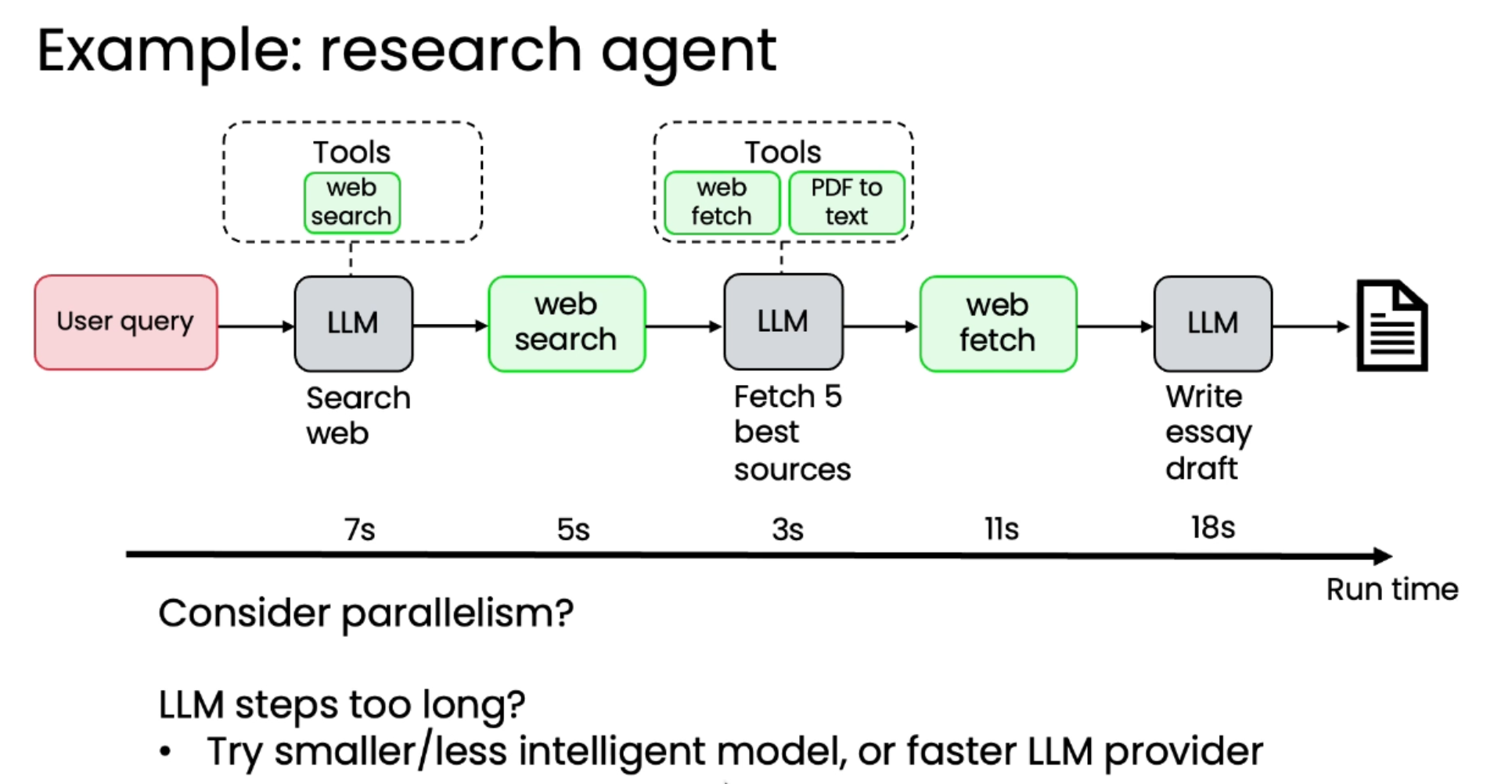
-
计时分析: 详细记录工作流程中每个步骤所花费的时间(例如:LLM 1 耗时 7 秒,LLM 3 耗时 18 秒)。
-
定位瓶颈: 通过时间线分析,确定耗时最长的组件,从而确定最大的提速空间。
-
优化手段:
-
并行化: 考虑将一些像是网页抓取之类的,可以独立进行的步骤并行执行。
-
更换 LLM: 尝试使用更小、更快(尽管可能稍不智能)的模型,或者测试不同的 LLM 提供商,以找到返回 token 最快的服务。
-
-
优化成本的方法
优化成本的关键在于进行成本基准测试,找出最昂贵的步骤。
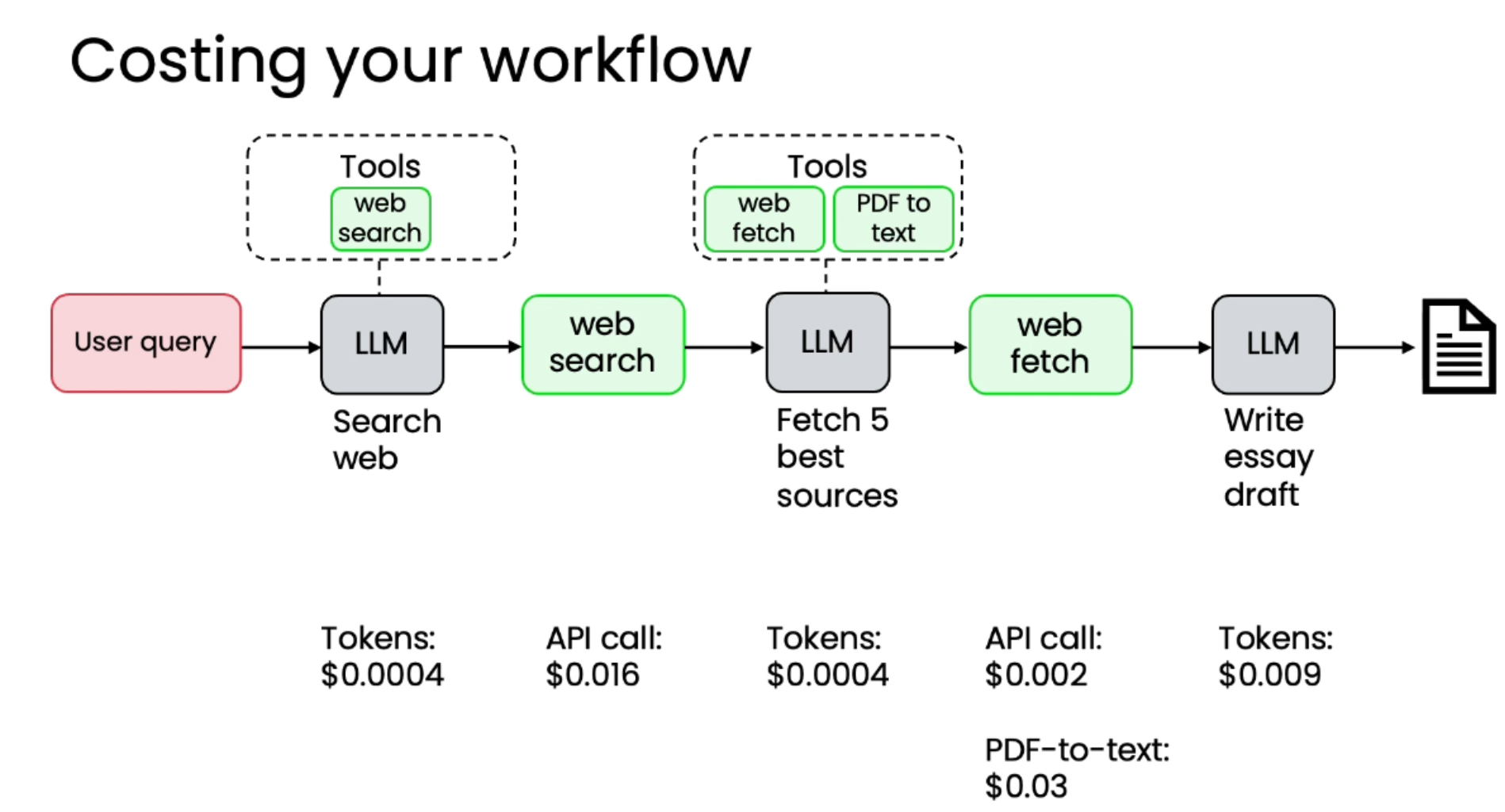
-
成本计算: 计算工作流程中每个步骤的平均成本:
-
LLM: 按输入和输出的 Token 长度收费。
-
API: 按调用次数收费。
-
计算/服务: 根据服务器容量、服务费等计算。
-
-
定位瓶颈: 确定成本贡献最大的组件。
-
优化手段: 寻找更便宜的组件或 LLM 来替代高成本的组件,以最大化成本优化机会。
六、总结
对于我们开发者而言,在开发Agent工作流时,主要精力通常集中在以下两项活动中,并不断来回切换:
-
构建: 编写软件和代码来改进系统。
-
分析: 决定下一步将构建精力集中在哪里的过程,其重要性与构建相当。
而一个Agent系统从初始原型到成熟,分析工作的严谨性也随之提高,通常经历以下迭代阶段:
| 阶段 | 描述 | 主要活动 |
|---|---|---|
| 1. 快速原型 | 快速构建一个端到端系统(所谓的“先做个垃圾出来”)。 | 分析: 手动检查最终输出,通读追踪 (Traces),凭直觉找出性能不佳的组件。 |
| 2. 初步评估 | 系统开始成熟,超越纯手动观察。 | 分析: 构建初步的 端到端评估 (Evals),使用小型数据集(如 10-20 例)计算整体性能指标。 |
| 3. 严谨分析 | 系统需要更精确的改进方向。 | 分析: 进行错误分析,统计和量化各个组件导致次优输出的频率,以做出更集中的决策。 |
| 4. 高效调优 | 系统进一步成熟,需要在组件级别进行高效改进。 | 分析: 构建组件级评估,以便更高效地对单个组件进行调优。 |
显然,开发是一个非线性的过程,需要在调整系统、错误分析、改进组件和调整评估之间反复横跳。
许多经验不足的团队往往花太多时间在构建上,而太少时间在分析上,导致工作重点不集中,效率低下。
在早期,市面上有许多工具可以帮助监控追踪、记录运行时、计算成本等。团队可以尽情使用这些前人造的轮子。但由于大多数Agent工作流程是高度定制化的,所以团队最终仍需要自行构建许多定制化的评估,以准确捕获系统特有的问题。
本模块希望带来的核心认知,就是一套系统化的开发流程(评估,错误分析,改进)。只有这种系统化的开发流程,才能支撑起足够复杂的Agent系统。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)