【学习笔记】大模型
书,全解深度学习
图解DeepSeek技术
RMSNorm
每个Transformer块
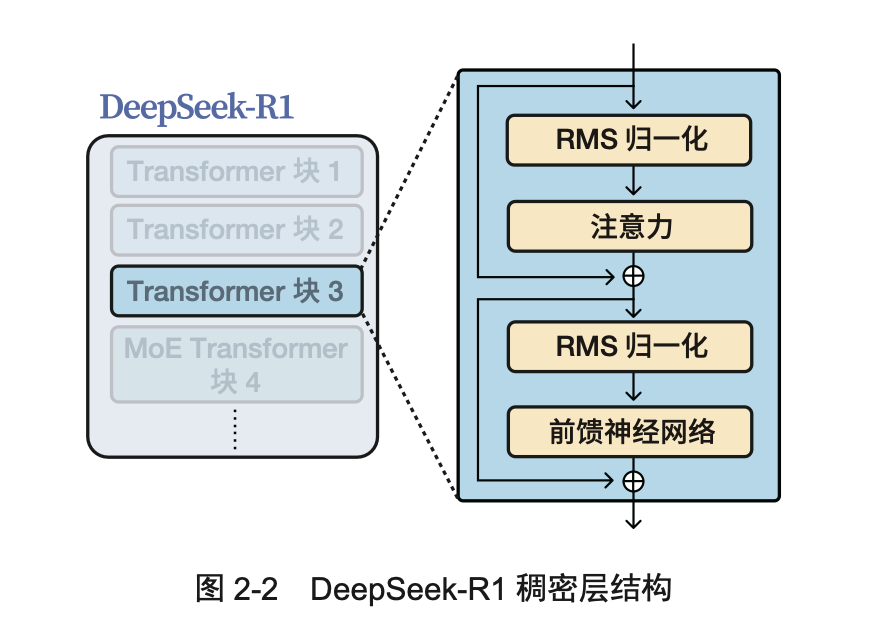
(1)首先对输入采用 均方根 层归一化(root mean square layer normalization, RMSNorm)操作,简称RMS归一化。
(2)完成注意力机制运算后,系统会再次执行归一化操作。
(3)经过这些关键步骤形成的特征表示,最终会送入前馈神经网络(feed forward neural network, FFN)进行深度处理。
RMSNorm,均方根层归一化:先计算输入张量中每个元素的平方的均值,然后取其平方根(RMS),最后用输入除以这个RMS值并乘以一个可学习的缩放因子。均方根层归一化的目的是稳定训练过程,加速模型收敛。
MLA
MLA(multi-head latent attention),多头潜在注意力,通过对K和V值进行低秩联合压缩,有效降低了推理过程中的KV缓存需求。MLA对注意力机制中的QKV向量分别做了低秩投影。例如,DeepSeek-V3中,MLA把7168维的KV分别压缩为512维,把7168维的Q压缩为1536维。
使用低秩 KV 并不简单,主要挑战在于 RoPE(旋转位置嵌入)对位置信息的要求。由于 Q 和 K 都经过 RoPE 处理而变得对位置高度敏感,如果直接对压缩后的 K 应用 RoPE,会导致其同样具备位置敏感性, 从而在推理时必须重新计算所有前缀词元的 K。这意味着无法使用 KV 缓存,严重影响推理效率。
为了 解决这个问题,MLA 引入了一个维度较小的额外位置向量(如图中红框所示),仅对其应用 RoPE 编码, 并采用类似 MQA(多头共享参数)的方式将其与不含位置信息的低秩 K 向量拼接。这种结构既能补充 位置信息,又避免了对整个 K 向量重新编码,从而保留 KV 缓存机制,提升推理效率。在 DeepSeek-V3 中,512 维的低秩 KV 向量中额外添加了 64 维的位置编码向量。
MOE
共享专家(shared expertsa)。在处理所有词元的过程中始终处于激活 状态,因此具备天然的动机去学习通用性更强的知识。它有效地缓解了知识冗余问题,并提升了其他专家专注于特定任务的能力。
- 路由器选择的专家通过细粒度专家分割专注于学习更加专业化的知识,
- 共享专家通过共享专家隔离机制被激励去学习通用性知识
在训练阶段,为了使专家分布更加均匀,DeepSeekMoE 在常规损失函数的基础上引入了两种辅助损失函数(也称为负载均衡损失):
- 其一为专家级损失(expert-level loss),用于鼓励模型持续使用多样化的专家组合,防止路由崩塌现象的发生(然而, 当使用大量 GPU 并行训练时,由于施加了过多约束,这种强制性的均衡可能会导致 性能下降);
- 其二为设备级损失(device-level loss),用以促进不同设备间的负载均衡,从而提高整体效率。
DeepSeek-R1 模型基于 Transformer 解码器模块堆叠架构,共 61 层,前 3 层为稠 密层,后 58 层为 MoE 层。
稠密层:前 3 层 Transformer 块结构与主流大模型类似。每个块先对输入进行 RMS 归一化操作,再经多头潜在注意力机制运算,该机制通过低秩联合压缩键和值来 降低 KV 缓存需求,提高推理效率,最后送入前馈神经网络处理。
MoE 层:后 58 层采用 MoE 机制替代常规的前馈神经网络。MoE 由专家和路由 器组成,专家实际上也是前馈神经网络,而路由器负责将词元分配给特定专家。
混合精度
在DeepSeek-V3中,模型的大部分参数使用FP8格式存储,仅有以下组件因对精度要求较高,仍采用BF16或FP32格式存储:
- 嵌入模块
- 输出头
- MoE层门控模块(即路由器)
- 归一化算子
- 注意力算子
这些组件的计算对精度较为敏感,因此保留高精度。此外,部分组件(如路由 器)规模较小,保留高精度所带来的额外开销可忽略不计。
多头潜在注意力机制MLA、混合精度训练和多词元预测MTP这三大关键技术,共同造就了 DeepSeek-V3 作为基础模型的卓越性能。
全解深度学习
编码器结构
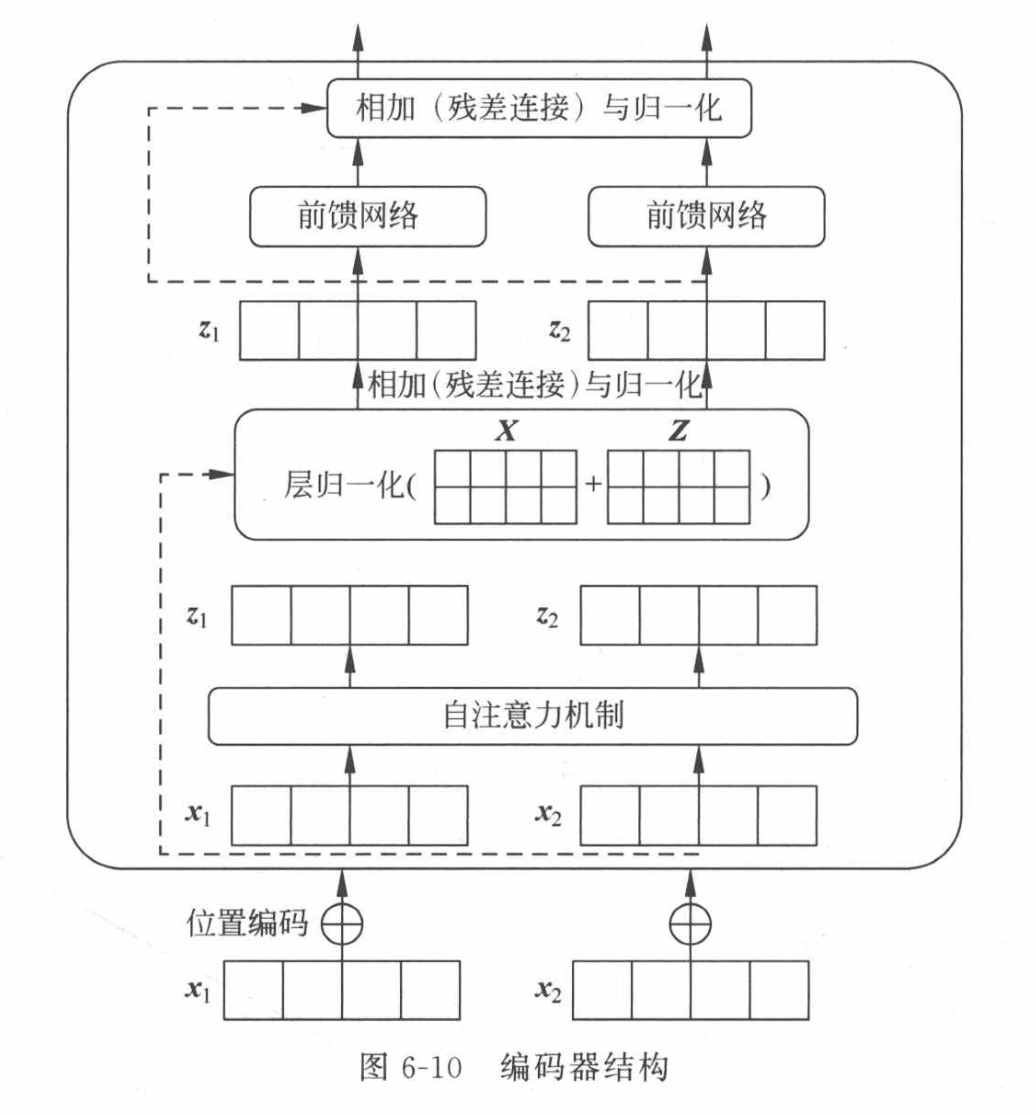
每个编码器中的自注意力层周围都有一个残差连接,然后是层归一化步骤。归一化的输出再通过前馈网络(FeedForward Network,FFN)进行映射,以进行进一步处理。前馈网络本质上就是几层神经网络层,其中间采用ReLU激活函数,两层之间采用残差连接。
- 残差连接可以帮助梯度进行反向传播,让模型更快更好地收敛。
- 层归一化用于稳定网络,减轻深度学 习模型数值传递不稳定的问题。
至于Transformer中的FNN是一个MLP,它在自注意力机制之后对序列中的每个向量单独应用。FNN起到以下两个主要作用。
(1)引人非线性:虽然自注意力机制能捕捉序列中不同位置的向量之间的依赖关系,但它本质上是线性的。通过引人FNN层,Transformer可以学习到输人序列的非线性表示,这有助于模型捕捉更复杂的模式和结构。
(2)局部特征整合:FNN层是一个MLP,对序列中每个位置的向量独立作用。这意味着它可以学习到局部特征并整合这些特征,以形成更丰富的特征表示。这种局部特征整合与自注意力机制中的全局依赖关系形成互补,有助于提高模型性能。换句话说,自注意力机制学习的是向量之间的关系,而FNN学习的是每个向量本身更好的特征表示。

GPT

大模型轻量化
GPU性能指标:核心数(CUDA cores)、显存、内存带宽(Bandwidth)、计算性能(TFLOPS)
算子融合:常见的融合模式包括,卷积与激活函数的融合、卷积与批归一化的融合等。
参数量
import torch
import torch.nn as nn
class modelA(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(20, 16)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(16, 5)
model = modelA()
for name, param in model.named_parameters():
print(name, param.requires_grad, param.numel())前向传播
import torch
import torch.nn as nn
def generate_data(num_samples=100, input_dim=20, num_classes=5):
data = torch.randn(num_samples, input_dim)
labels = torch.randint(low=0, high=num_classes, size=(num_samples,))
return data,labels
class MLPNetwork(nn.Module):
def __init__(self, input_dim=20, hidden_dim1=64, hidden_dim2=32, num_classes=5):
super().__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim1)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(hidden_dim1, hidden_dim2)
self.relu2 = nn.ReLU()
self.fc3 = nn.Linear(hidden_dim2, num_classes)
def forward(self, x):
print(f'x: {x.shape}')
x = self.relu1(self.fc1(x))
x = self.relu2(self.fc2(x))
x = self.fc3(x)
return x
def evaluate_model(model, test_data, test_labels, batch_size=32):
model.eval()
correct = 0
total = 0
num_samples = test_data.size(0)
with torch.no_grad():
for i in range(0, num_samples, batch_size):
batch_x = test_data[i: i+batch_size]
batch_y = test_labels[i: i+batch_size]
outputs = model(batch_x)
_, preds = torch.max(outputs, 1)
correct += (preds == batch_y).sum().item()
total += batch_y.size(0)
break
accuracy = 100.0 * correct / total
return accuracy
if __name__ == '__main__':
test_x, test_y = generate_data(num_samples=200, input_dim=20, num_classes=5)
print(test_x.shape, test_y.shape)
net = MLPNetwork(input_dim=20, hidden_dim1=64, hidden_dim2=32, num_classes=5)
acc = evaluate_model(net, test_x, test_y, batch_size=64)算子
算子库,不仅负责核心操作如 矩阵乘法、卷积运算等的实现,还通过并行计算、内存复用以及硬件加速等技术,最大化地发挥硬件性能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)