大模型选型不用再抽盲盒了,这个平台值得试试
希望AI Ping平台能接入更多垂直领域的模型,像医疗、法律、金融这些专业场景的API。现在平台上主要是通用模型,但实际业务中我们经常需要用到领域专用模型,如果这些也能在平台上对比性能就更方便了。如果能再做个社区功能就更好了,大家可以分享各自的使用经验、路由策略配置、踩坑记录等,互相学习。总的来说,AI Ping确实解决了我在选择MaaS服务时的一些实际痛点。虽然不是完美无缺,但作为一个相对专业的
本文目录:
前言:最近在做项目的时候遇到了一个挺头疼的问题,很多不同的任务需要我们大量调用各种大模型API,但现在市面上的MaaS服务实在太多了,选择起来还是很纠结的。
不知道大家有没有遇到过这样的情况,同样的任务在A平台跑得很快,在B平台可能就卡顿。就好像我昨天用某讯服务跑得飞快,今天再试延迟直接拉满了,有的时候看见便宜的服务,总感觉不是很放心,贵的服务又让我有点舍不得。现在光是主流的MaaS供应商就有二十多家,模型更是数百个,每次选型都像在盲盒里抽奖。更让人头疼的是,不同平台的接口格式都不一样,想测试对比几家服务商,光是适配接口就要花大半天时间.
一、偶然发现的评测神器
前段时间在技术群里看到有人分享了一个叫AI Ping的平台,说是专门做大模型服务性能评测的。当时我的第一反应是:又一个跑分网站?但仔细看了看,发现这个平台有点不太一样。
首先让我眼前一亮的是,这个平台关注的不是模型的精度表现(这方面已经有很多评测机构在做了),而是聚焦在MaaS服务的性能指标上——延迟、吞吐、可靠性等等,这些恰恰是我们开发者在实际业务中最关心的问题。而且据说这个平台是清华系AI基础设施公司清程极智推出的,他们的评测数据还被清华大学和中国软件评测中心用于发布官方榜单,在专业度上还是比较有保障的。
二、实际体验:比想象中有用
1.实时性能排行榜
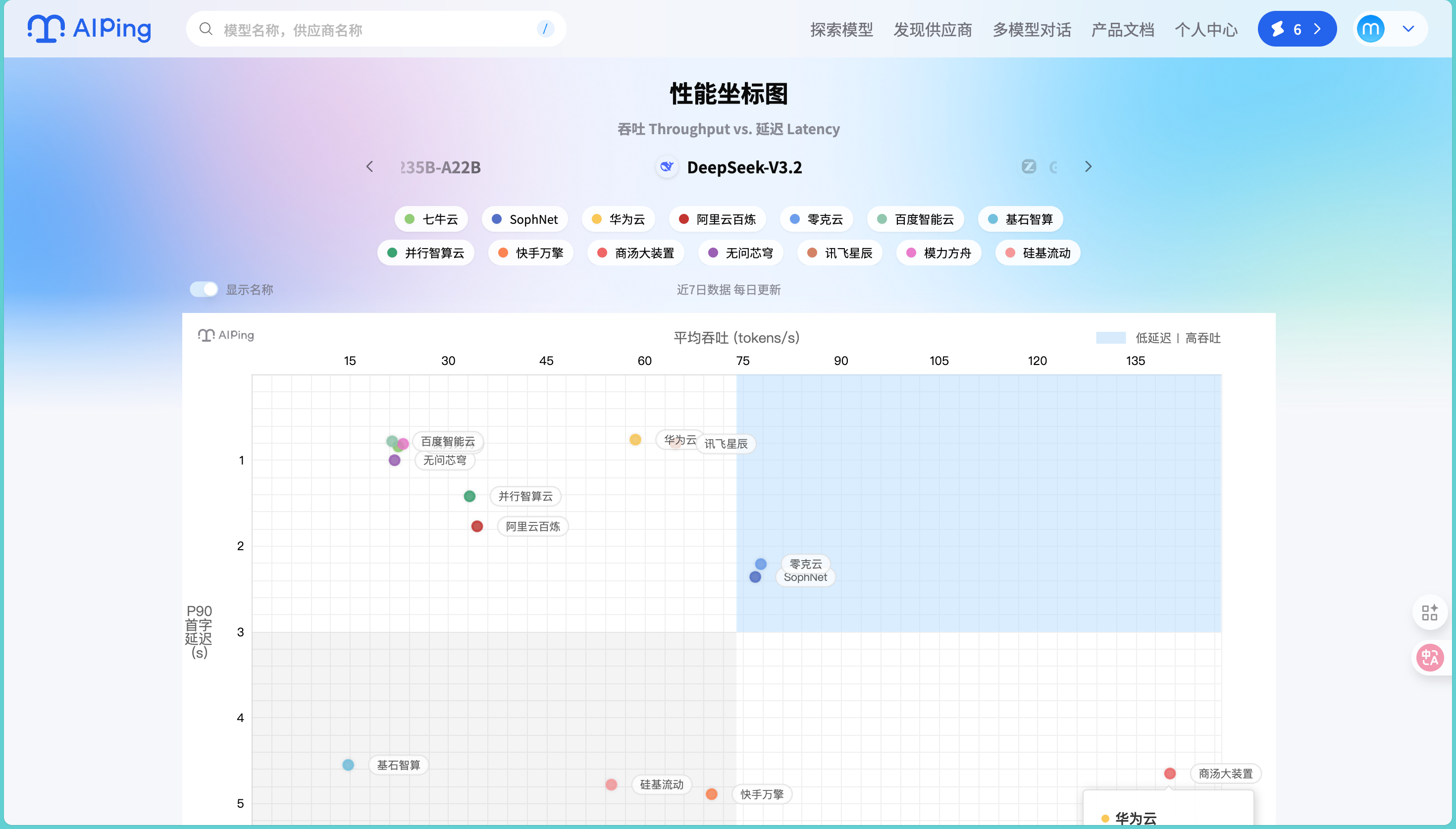
进入AI Ping官网后,最显眼的就是实时更新的性能排行榜:
而且我们可以自己主动选择不同的模型进行不同供应商的表现,比如这个地方我就选用了我平时接触最多的模型——Qwen3-235B-A22B:
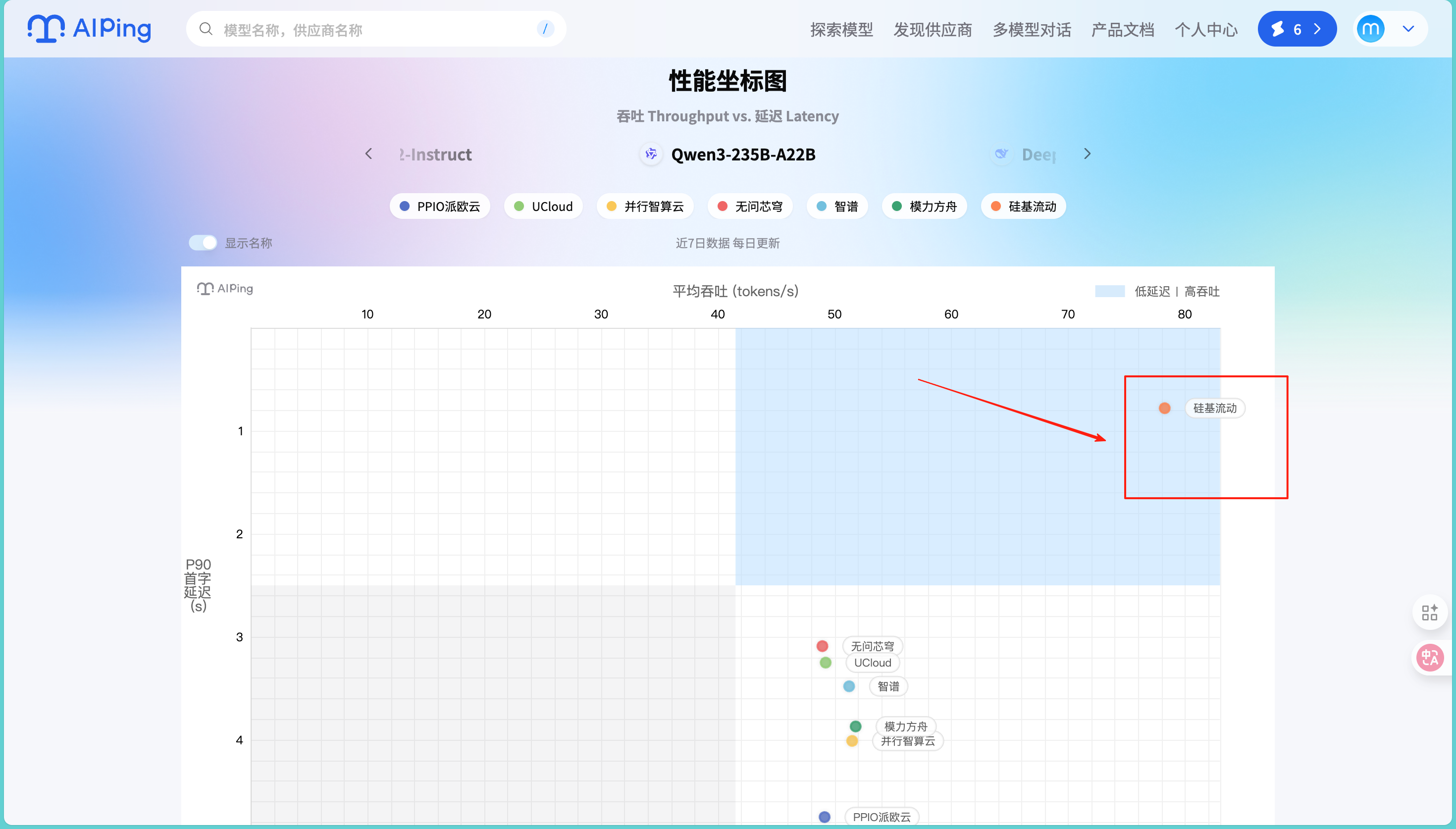
从性能坐标图可以看到,不同供应商在同一个模型上的表现差异还是挺明显的。商汤大装置在吞吐量方面表现突出,而无问芯穹、PPIO派欧云在延迟控制上各有优势。这种直观的对比让我能快速识别出哪家供应商更适合我的具体需求。
让我印象深刻的是,这个榜单不是基于单次"跑分",而是7×24小时持续监测的结果。这就解释了为什么有些服务在某些时段表现很好,但在高峰期就拉胯了。我特地观察了几天不同时段的数据变化,发现确实有些供应商在凌晨时段性能表现优异,但到了白天用户高峰期就明显下降。这种波动性的发现对我们选择服务商还是很有参考价值的。
2.细致的模型筛选与对比体验
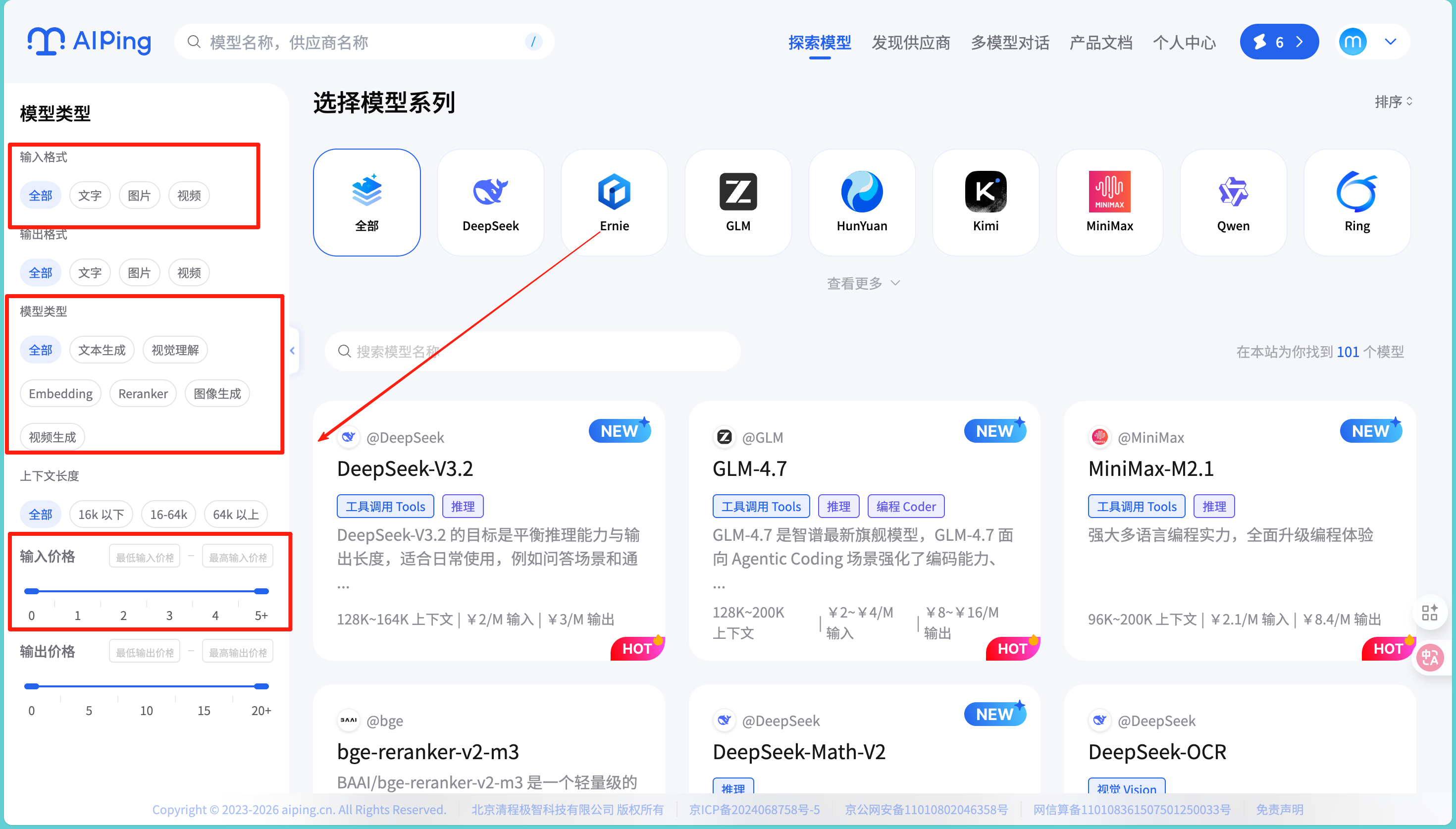
作为一个对模型参数比较敏感的开发者,我特别关注AI Ping的筛选功能。在主页可以按照上下文长度(全部、小于16k、16-64k、大于64k)、输出价格、输入价格等维度进行筛选,这对我这种有明确需求的用户来说非常实用。
我点击进入模型库中发现这里模型十分具体,并且模型上下文长度、输入输出token限制等都已经标注清楚了,使我们可以很方便的去筛选各种所需要的模型:
特别值得一提的是模型详情页的设计,以DeepSeek-R1为例,页面上方有详细的模型介绍,包括技术背景和能力特点。下方的供应商数据表格更是亮点,可以看到阿里云、腾讯云、七牛云等各家供应商的具体表现数据。
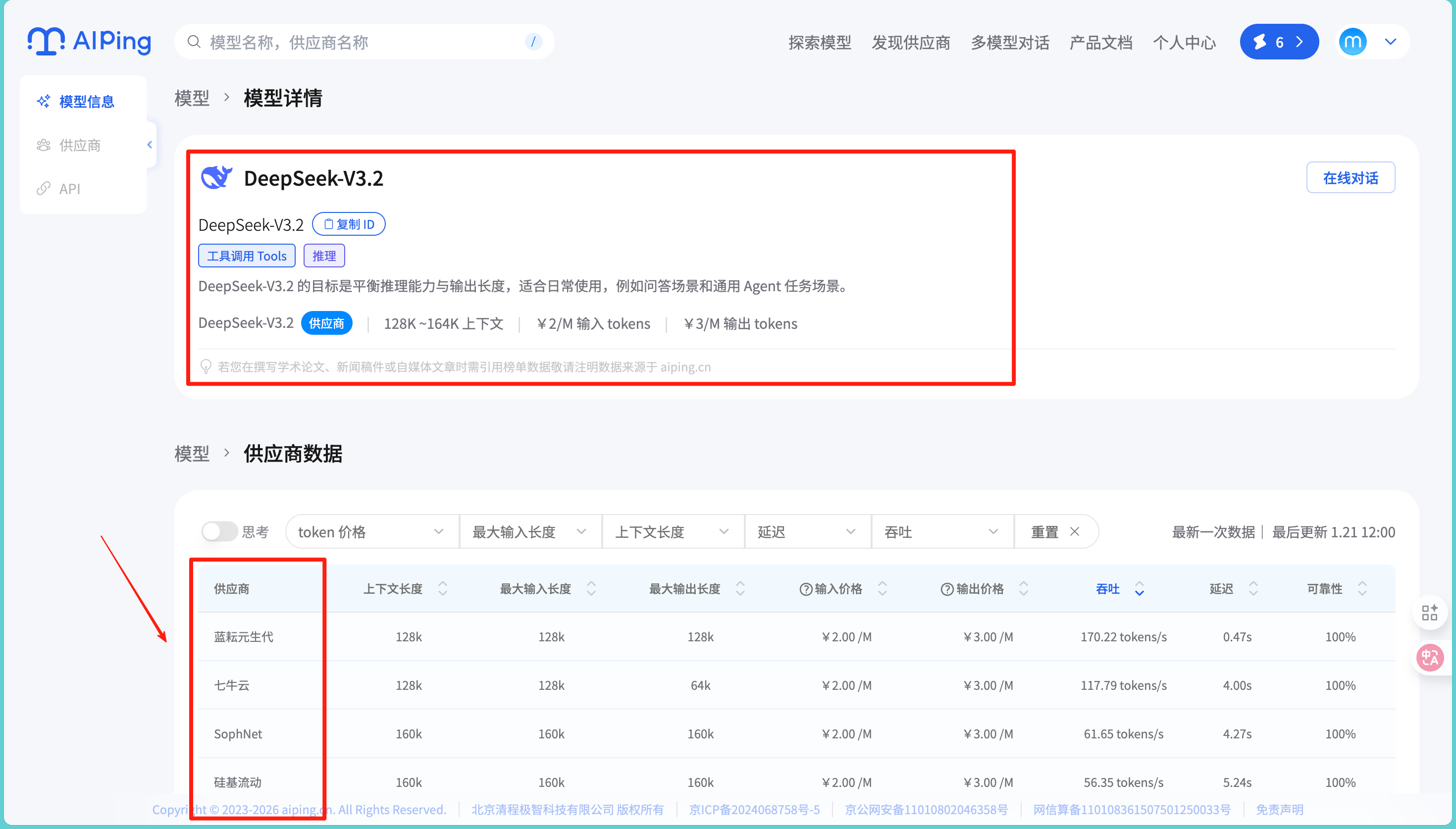
从实际数据来看,同样是DeepSeek-V3.2模型,蓝耘元生代的延迟最低(0.47s),而基石智算的最大输出长度相对较高(164k)。这种横向对比让我能够根据自己的业务场景做出更精准的选择。不过我也注意到,虽然价格都标注为4.00/M输入和16.00/M输出,但实际的性能表现差异还是很明显的。
当我想要访问某个模型的官方页面时,直接就可以点击试用即可,并且在使用界面可以一键切换各种模型,使用起来非常的便捷:
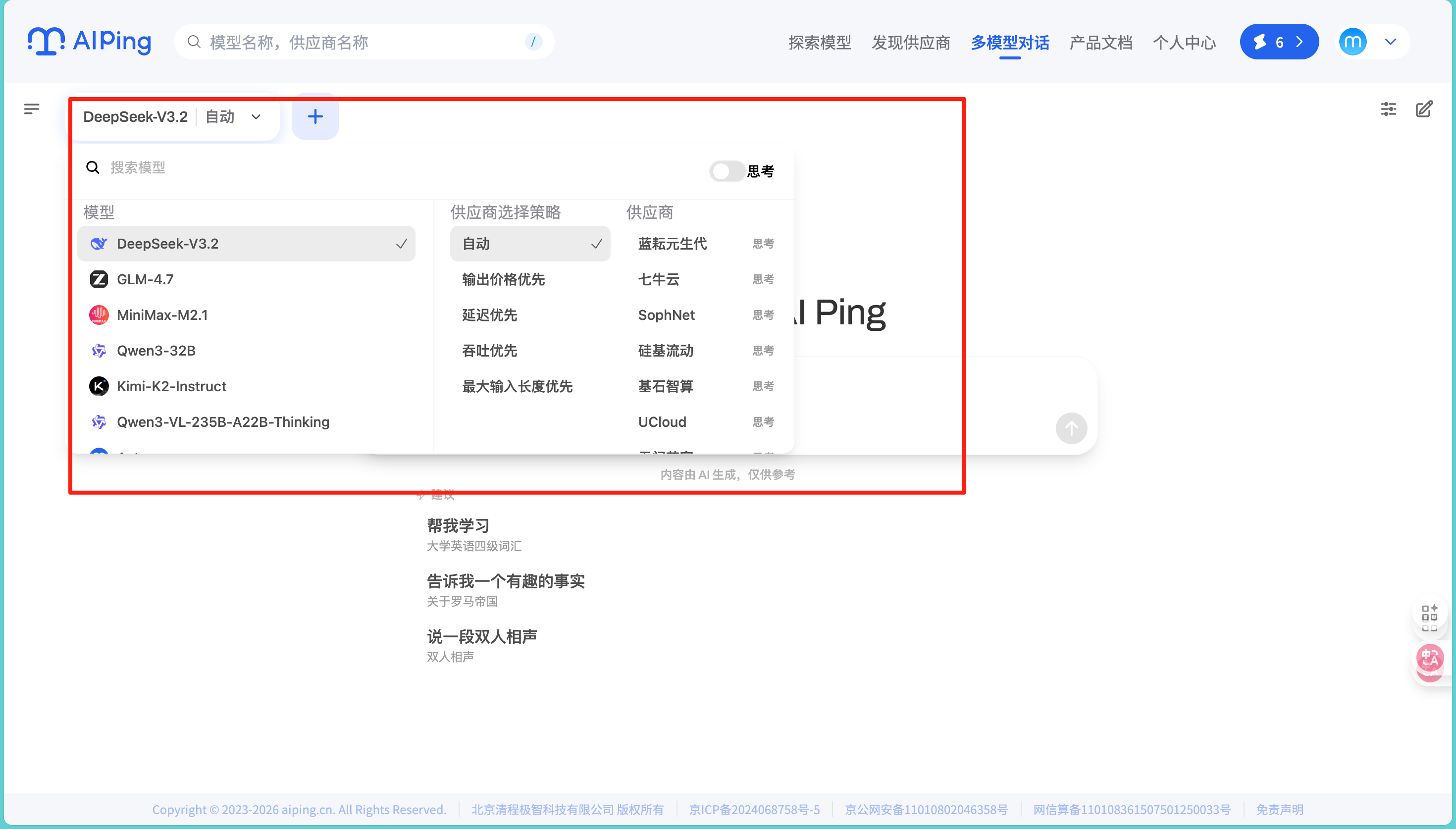
3.统一API接口:解决切换平台的痛点
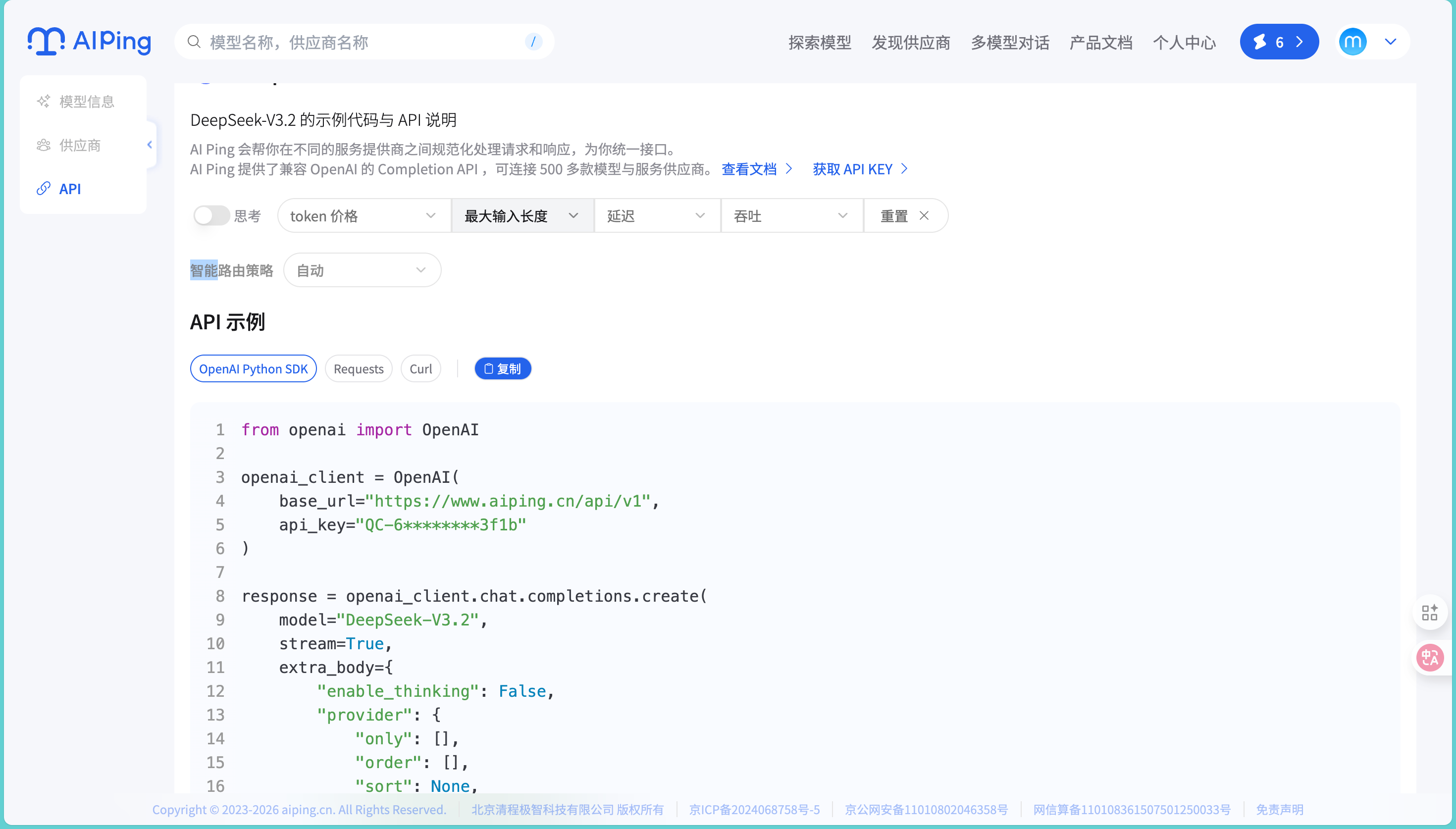
这个功能对我来说真的是个惊喜。以前我测试不同供应商的服务时,最头疼的就是每家的接口格式都不一样,想对比几家的表现,光是改代码适配接口就要花大半天。
AI Ping提供了统一的API接口,我只需要通过一个接口就能调用平台上数十家供应商的服务。实际测试中,我只需要改一个参数指定供应商,其他代码完全不用动,这对于需要频繁测试对比的场景来说省了不少时间。虽然我目前主要还是用它来做选型对比,但这个功能的便利性确实很明显。
4.实用性测试
因为最近的项目需要我需要批量处理客户的合同文档,提取关键信息并生成摘要,大概涉及2000多份文档。这种场景对模型的延迟和稳定性要求比较高,正好用用这个平台看看咋样。
基于AI Ping的数据,我筛选出了几个候选方案:
- 阿里云百炼在开行智算云的表现:延迟1.24s,吞吐43.72tokens/s
- 七牛云的DeepSeek-R1:延迟1.15s,吞吐42.17tokens/s
- 快手万擎的方案:延迟4.3s,但吞吐达到39.92 tokens/s
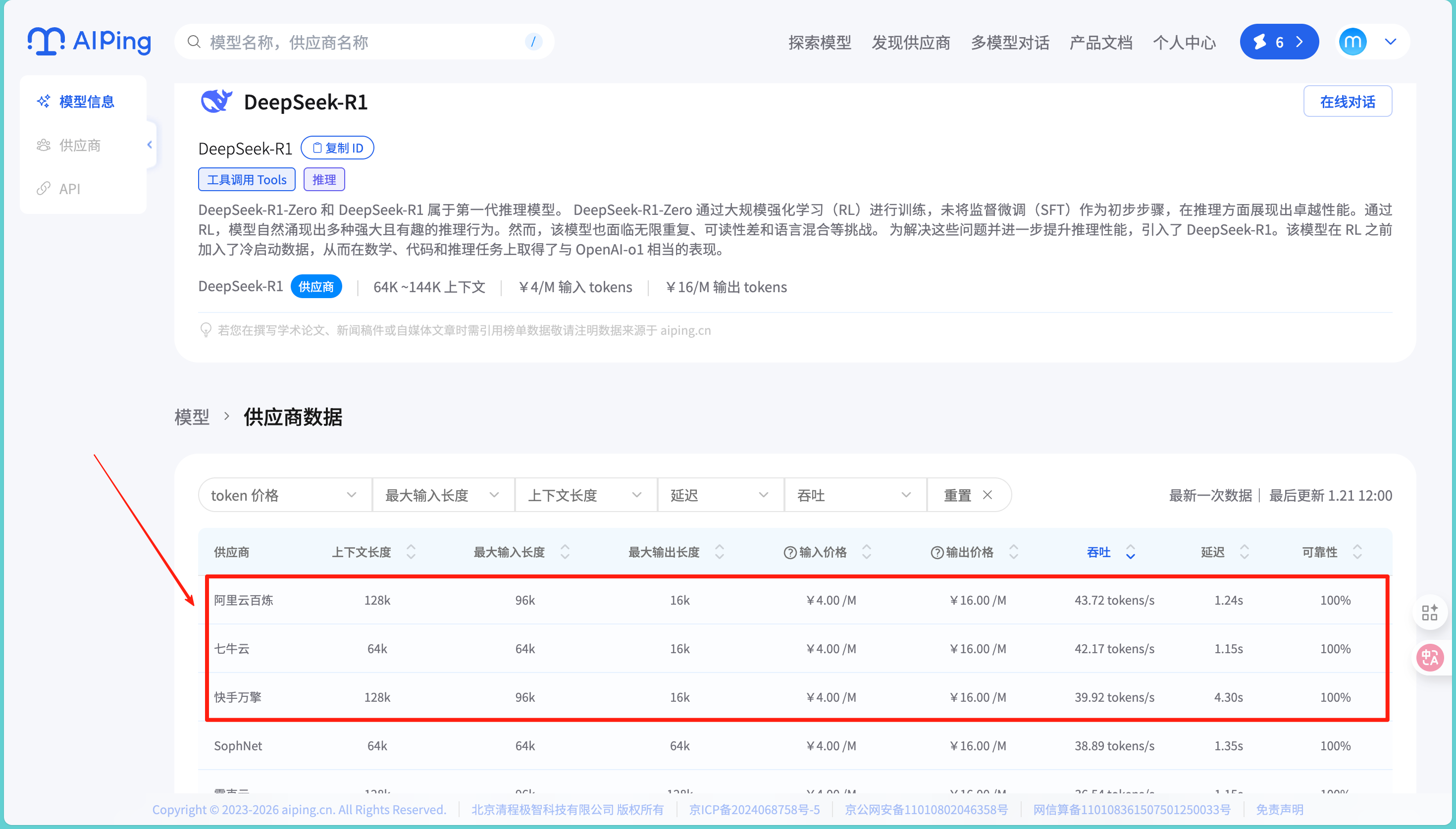
我先用100份文档做了小规模测试。七牛云确实在延迟控制上表现不错,单次调用基本在1秒左右完成。阿里云百炼虽然单次延迟稍高,但在批量处理时的整体吞吐量优势明显,特别是在处理较长文档时。快手万擎的表现比较难以令人满足,在高并发时偶尔会有超时现象。
实际测试中,我还发现了一个平台数据中没有体现的问题:不同时段的性能波动。上午10-12点和下午2-4点这两个时段,所有供应商的响应速度都会明显下降,这可能是因为这些时段用户使用量较大。这个发现让我调整了批量处理的时间安排,避开了高峰期。最终我选择了腾讯云的方案处理紧急文档,阿里云处理大批量任务,AI Ping的数据确实帮我节省了不少试错时间,整个项目比预期提前了半天完成。
另外值得一提的是平台的个人数据中心功能,它会详细记录每次API调用的模型、供应商、Token消耗和产生的费用。我现在会定期看一下这个报表,了解哪些场景花钱比较多,有没有优化空间。对于需要控制成本的项目来说,这个功能还挺有用的。
三、做得不错的地方
- 评测角度实用:从开发者真实需求出发,关注性能而非精度
- 数据相对客观:7×24小时持续监控,避免了单次跑分的偶然性,而且作为第三方评测平台,数据公正性还是有保障的
- 覆盖面广:20多家供应商、200多个模型服务,基本涵盖了主流选择
- 统一接口:一个接口调用多家服务,对于需要频繁测试对比的场景确实方便
- 更新及时:能够跟上各大厂商的最新发布
四、对行业的一些思考
用了AI Ping一段时间后,我觉得这类平台对整个行业还是挺有意义的:
从开发者角度看,AI Ping就像是个技术加速器。现在大模型更新太快了,今天GPT-4好用,可能明天Claude又出新版本,后天国产模型又有突破。以前每次新模型上线,你得重新学接口文档、改适配代码,有时候光是搞清楚一家新平台的鉴权方式就要花半天。现在通过AI Ping的统一接口,新模型上线基本能无缝切换,学习成本确实降低了不少。而且有了性能榜单,我也不用担心踩坑,能更快地尝试新技术。
对整个行业来说,它其实在推动一种标准化和透明化。各家供应商都在一个平台上公开透明地比性能、比价格、比稳定性,这种良性竞争会倒逼大家提升服务质量。我注意到有些供应商看到自己在榜单上排名靠后,很快就会优化服务,这对我们开发者来说是好事。最终受益的还是整个生态——供应商有动力做得更好,开发者能用到更优质的服务。
五、期待与总结
用了一段时间后,我也有一些具体的期待:
希望AI Ping平台能接入更多垂直领域的模型,像医疗、法律、金融这些专业场景的API。现在平台上主要是通用模型,但实际业务中我们经常需要用到领域专用模型,如果这些也能在平台上对比性能就更方便了。如果能再做个社区功能就更好了,大家可以分享各自的使用经验、路由策略配置、踩坑记录等,互相学习。
总的来说,AI Ping确实解决了我在选择MaaS服务时的一些实际痛点。虽然不是完美无缺,但作为一个相对专业的评测平台,已经提供了很多有价值的信息。
特别适合这几类用户:
- 需要频繁调用大模型API的开发者
- 对服务性能指标敏感的业务方
- 想要了解不同供应商表现差异的技术选型人员
- 需要在多家供应商之间对比测试的团队
如果你也在为选择合适的大模型服务而纠结,不妨试试这个平台。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)