概率论下的攻防——为什么 AI 无法实现 100% 的防御?
这也解释了为什么我们在上一篇强调“多级漏斗架构”——必须先用白名单和规则过滤掉 99% 的流量,只把最可疑的 1% 交给 AI,人为地提高“攻击浓度(Base Rate)”,贝叶斯公式才会站在我们这一边。我们将拆解贝叶斯定理在网络安全中的冷酷判决,剖析“误报”与“漏报”之间永恒的零和博弈,并最终推导出 AI 时代的安全终极真理——我们不再追求“无懈可击”,我们追求“风险可控”。但这还只是“天灾”。
概率论下的攻防——为什么 AI 无法实现 100% 的防御?
你好,我是陈涉川,这是《硅基之盾》专栏的第六篇。
如果说前五篇我们是在构建武器、清洗弹药、打磨战术,那么这一篇我们将进入指挥所。我们要探讨的是战争中最底层的哲学问题:确定性(Certainty)的终结。
许多初学者(甚至是企业高管)对 AI 安全抱有一种幻想:只要我买了最贵的 AI 防火墙,只要模型准确率达到 99.99%,我就能实现“绝对安全”。
本篇将用严酷的数学逻辑告诉你:这种想法是危险的。 在概率论的世界里,100% 的防御不仅技术上无法实现,在经济上也是不可接受的。
我们将拆解贝叶斯定理在网络安全中的冷酷判决,剖析“误报”与“漏报”之间永恒的零和博弈,并最终推导出 AI 时代的安全终极真理——我们不再追求“无懈可击”,我们追求“风险可控”。
引言:寻找不存在的“银弹”
在网络安全行业,有一个经久不衰的笑话:
“世界上唯一 100% 安全的计算机,是拔掉网线、灌进水泥、锁在钛合金保险箱里,然后沉入马里亚纳海沟的那一台。”
—— 紧接着,那个笑话的下半句通常是:“即便如此,我也不会把我的社交媒体账号密码告诉它。”
在传统安全时代,我们追求的是一种“布尔式(Boolean)”的安全感。
防火墙规则写着:DENY TCP ANY ANY PORT 445。这是一条铁律。只要规则生效,445 端口就是绝对关闭的。在这种范式下,只要没有 Bug,代码就是法律,结果是确定的(Deterministic)。
然而,AI 的引入打破了这个幻象。当你部署一个深度学习模型来检测 Web 攻击时,模型输出的不再是冷冰冰的布尔值(True/False),而是一个带有温度的置信度(Confidence Score)——比如 0.9823。
它在说:“我认为这有 98.23% 的概率是 SQL 注入。”
这意味着什么?意味着还剩下 1.77% 的概率它不是。
如果你设定阈值为 0.99,你就放过了它(漏报);如果你设定为 0.98,你可能拦截了一个只是名字很怪异的合法用户(误报)。
欢迎来到概率论(Probability Theory)统治的疆域。在这里,没有绝对的好人与坏人,只有分布曲线下的阴影面积。本篇将带你直面这个令安全官(CISO)彻夜难眠的数学真相。
第一章:决定论的崩塌——从“锁”到“免疫系统”
要理解 AI 为什么不能 100% 防御,首先要理解安全防御范式的物理本质转变。
1.1 传统防御:机械宇宙观
传统安全(AV 签名、静态规则)类似于牛顿力学。
- 特征: 线性、可预测、因果分明。
- 逻辑: 只要输入 X 满足条件 C,则执行动作 A。
- 缺陷: 它高度依赖‘已知特征’。面对从未见过的 0-day 漏洞,基于签名的防御往往会彻底失效,防线形同虚设。
- 比喻: 这是一把锁。钥匙对了就能开,不对就开不了。不存在“把门打开 80%”这种状态。
1.2 AI 防御:量子/统计宇宙观
AI 安全(异常检测、行为分析)类似于量子力学或生物免疫系统。
- 特征: 非线性、概率性、模糊性。
- 逻辑: 输入 X 在特征空间中距离恶意聚类中心的距离为 D,计算其归属于恶意的后验概率 P(Y|X)。
- 缺陷: 它永远带有不确定性(Uncertainty)。
- 比喻: 这是一个保安。他看着一个人觉得“鬼鬼祟祟”,于是将其拦下。但他不能 100% 确定这个人就是小偷,也许这个人只是因为肚子痛而弯着腰走路。
1.3 为什么必须接受概率?
既然 AI 不确定,为什么还要用?
因为攻击者变了。现代攻击者使用多态代码、动态域名、拟人化操作。如果你依然坚持使用“确定的规则”去匹配“不断变化的攻击”,你的防御覆盖率将趋近于零。
为了捕捉未知,我们必须牺牲确定性。 这是一个必须支付的本体论代价。
第二章:贝叶斯幽灵——基数谬误(Base Rate Fallacy)
这是本篇最硬核、也是最反直觉的数学章节。
很多厂商宣称:“我们的 AI 模型准确率高达 99%!”
初学者会想:“哇,那我的网络岂不是固若金汤?”
大错特错。 在网络安全场景下,一个准确率 99% 的模型,可能会给你带来一场灾难。
原因是:基数谬误(Base Rate Fallacy)。
2.1 贝叶斯定理的回响
让我们复习一下贝叶斯公式:
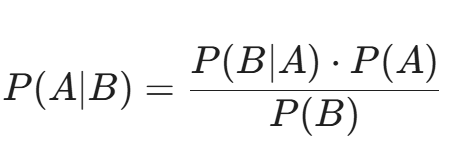
在安全语境下:
- A = 事件是真实的攻击(Attack)。
- B = AI 发出了告警(Alert)。
- P(Attack|Alert) = 我们最关心的指标:当 AI 报警时,这真的是一次攻击的概率是多少?(这也叫精确率 Precision)。
2.2 一个令人震惊的计算
假设你购买了一款高端 AI 防火墙,参数如下:
- 真阳性率 (Recall/TPR): 99%(如果真的有攻击,它 99% 能抓到)。
- 真阴性率 (TNR): 99%(如果是正常流量,它 99% 不会误报)。也就是说,误报率 (FPR) 只有 1%。
看起来非常完美,对吧?
现在,让我们看看真实的网络环境。
- 基数 (Base Rate): 假设你的公司每天处理 1,000,000 个网络请求。其中,真正的恶意攻击非常稀少,假设有 100 个(这已经很高了,占比 0.01%)。
现在,请计算:当 AI 发出“滴滴滴”的警报时,这真的是一次攻击的概率是多少?
直觉告诉你:大概 99%?
让我们算一下:
- 真实的攻击 (True Positives):
100 (攻击总数) X 99% = 99个真告警。
- 虚假的告警 (False Positives):
999,900 (正常请求总数)X 1% (误报率)}= 9,999 个假告警。
- 最终概率 P(Attack|Alert):
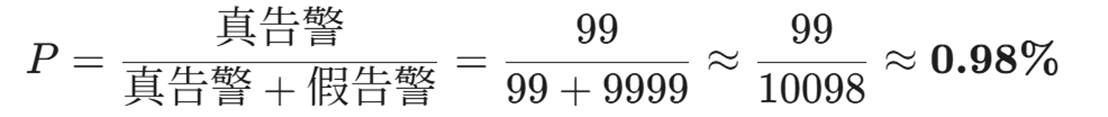
结论:
哪怕你的模型准确率高达 99%,当你看到告警时,它只有不到 1% 的概率是真的攻击,超过 99% 的概率是误报!
这就是“告警疲劳(Alert Fatigue)”的数学根源。如果你每天收到 10,000 个告警,其中 9,900 个都是误报,你的安全运营团队(SOC)会在三天内崩溃,或者直接把这个 AI 系统关掉。
2.3 为什么会这样?
因为正常样本(分母)太大了。哪怕只有 1% 的误报率,乘上海量的正常流量,产生的误报数量也会远远淹没掉那一点点真实的攻击。
给专业人士的启示:
在 AISec 领域,降低误报率(FPR)比提升召回率(Recall)重要一万倍。
一个 99.999% 准确率的模型在很多互联网大厂里都是“不可用”的。我们需要的是 99.99999% 的特异性。这也解释了为什么我们在上一篇强调“多级漏斗架构”——必须先用白名单和规则过滤掉 99% 的流量,只把最可疑的 1% 交给 AI,人为地提高“攻击浓度(Base Rate)”,贝叶斯公式才会站在我们这一边。
第三章:混淆矩阵的经济学——不仅是数学,更是生意
既然 100% 不可能,那我们该如何取舍?
这就要引入混淆矩阵(Confusion Matrix),并将其转化为经济成本矩阵。
3.1 四种结局
对于任何一次检测,只有四种可能:
- TP (True Positive): 有毒,抓住了。(收益:避免了数据泄露的损失)
- TN (True Negative): 无毒,放行了。(收益:业务顺畅运行)
- FP (False Positive): 无毒,却抓住了。(误报,成本:用户被封号、业务中断、客服投诉)
- FN (False Negative): 有毒,却放走了。(漏报,成本:数据库被拖库、勒索软件感染)
3.2 完美的防御是不存在的几何证明
想象在二维平面上,红色点代表攻击,蓝色点代表正常。
在理想世界中,这两堆点离得很远,我们可以画一条直线完美分开它们。
但在现实的高维空间中,由于对抗性伪装和业务复杂性,红色和蓝色是重叠(Overlapping)的。
- 重叠区域: 一个看起来像 SQL 注入的正常查询(比如程序员在搜代码片段);一个看起来像正常图片的恶意 Payload。
- 在这个重叠区域里,无论你把分界线画在哪里,你必然要么错杀好人(FP),要么放过坏人(FN)。
- No Free Lunch Theorem: 你不可能同时最小化 FP 和 FN。这是一个数学上的硬约束。
3.3 CIA 三角的拉锯战
这种数学上的取舍,映射到安全三要素(CIA)上,就是一场永恒的拉锯战:
- 侧重降低漏报(FN)\rightarrow 提升机密性(Confidentiality)
- 策略:宁可错杀一千,不可放过一个。
- 后果:误报率飙升。
- 代价:可用性(Availability)受损。合法用户进不来,业务部门会提刀来见 CISO。
- 场景:核武器发射井、顶级机密数据库。
- 侧重降低误报(FP)\rightarrow 提升可用性(Availability)
- 策略:除非铁证如山,否则不拦截。
- 后果:漏报率增加。
- 代价:机密性/完整性受损。黑客可能混进来。
- 场景:电商大促期间的交易系统(拦截一个订单的损失比放过一次爬虫的损失大)。
专业洞察:
所谓的“AI 模型调优”,本质上不是调整参数,而是调整企业的风险偏好(Risk Appetite)。
你必须问 CEO 一个问题:“如果必须选一个毒药,你是愿意损失 100 万美元的被盗资金,还是愿意损失 1000 万美元的因系统误封导致的订单流失?”
AI 回答不了这个问题,只有商业逻辑能回答。
第四章:阈值的艺术——ROC 曲线与“生死线”
既然必须权衡,那我们在工程上如何操作?这就是阈值(Threshold)的选择。
AI 输出的是一个 0 到 1 之间的概率 P。
我们需要划定一条线τ:
- If P > τ 报警。
- If P≤τ, 放行。
4.1 ROC 曲线 (Receiver Operating Characteristic)
这是一条描述 TPR(纵轴)与 FPR(横轴)关系的曲线。
- 曲线越凸向左上角,模型性能越好。
- AUC (Area Under Curve): 曲线下面积。AUC=0.5 是瞎猜,AUC=1.0 是神。
4.2 阈值滑块的实战演示
让我们移动这个滑块 τ:
- 极度偏执模式 (τ = 0.1)
- 只要有 10% 的嫌疑就报警。
- 结果: 抓住了所有黑客(Recall ≈ 100%),但也把全公司的员工都封号了(FPR 极高)。
- 状态: 系统瘫痪,虽安实亡。
- 极度宽松模式 (τ= 0.99)
- 只有 99% 确定是攻击才报警。
- 结果: 几乎没有误报,业务丝般顺滑。但高明的黑客稍微做点伪装(把概率降到 0.98),就大摇大摆进去了。
- 状态: 门户大开。
- 最佳工作点 (Optimal Operating Point)
- 这是 ROC 曲线切线斜率与代价比(Cost Ratio)相等的点。
- 公式:
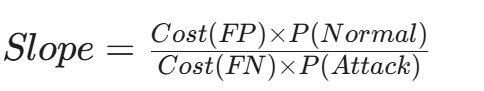
- 解读: 这个公式告诉我们,最佳阈值不仅仅取决于 AI 模型的能力,还取决于如果你犯错,你要赔多少钱。
4.3 动态阈值:AI 的自适应进化
高级的 AISec 系统不会使用固定的阈值。
- 上下文感知: 对于财务系统的访问,τ自动设为 0.3(严格);对于对外公开的官网论坛,τ设为 0.8(宽松)。
- 声誉感知: 对于来自“高信誉 IP”(如合作伙伴办公室)的流量,提高阈值,减少打扰;对于来自 Tor 节点的流量,降低阈值,严防死守。
值得注意的是,AI 输出的 0.99 并不总是代表 99% 的真实概率。在深度学习中,模型往往过度自信(Overconfident)。因此,现代安全系统还需要一个校准层(Calibration Layer),把模型的‘盲目自信’拉回现实。
读到这里,你可能感到一丝绝望。
贝叶斯告诉我们,在攻击稀缺的世界里,误报是宿命。
几何学告诉我们,完美的分类边界不存在。
经济学告诉我们,安全是用可用性换来的昂贵商品。
难道 AI 真的无能为力吗?既然 100% 防御是空想,那我们这就投降吗?
绝不。
认识到局限性,是走向成熟的第一步。正因为无法实现“完美的墙”,我们才需要建立“深度的防御”和“弹性的响应”。
第五章:高维空间的“盲区”——判决边界的几何困境
在第一部分,我们谈到了概率的误判是不可避免的统计现象。但这还只是“天灾”。在网络安全领域,更可怕的是“人祸”——即攻击者利用 AI 的概率特性,进行定向的数学打击。
这就是对抗性攻击(Adversarial Attacks)。要理解它,我们必须跳出二维屏幕,进入高维的几何世界。
5.1 维度的诅咒与“瑞士奶酪”般的边界
人类的直觉是三维的。在我们的想象中,一个训练好的 AI 模型就像一道厚实的墙,将“恶意”和“正常”完美隔开。
但在数学上,一个输入特征向量往往有数百甚至数千个维度(例如,一个 HTTP 请求可以被编码为 1024 维向量)。
根据维度灾难(Curse of Dimensionality)理论,随着维度的增加,数据点在空间中的分布会变得极度稀疏。这意味着,我们以为密不透风的“判决边界(Decision Boundary)”,在高维空间中其实千疮百孔。 它不像是一堵墙,更像是一个极其复杂的、扭曲的、布满孔洞的肥皂泡。
- 专业洞察: 模型在训练集上见过的样本,只是高维空间中极其微小的一个子集。在未见过的区域,模型的决策是外推(Extrapolation)出来的,往往极其脆弱。
5.2 寻找梯度的“幽灵”
攻击者如何穿过这个“肥皂泡”?他们不需要暴力破解,他们利用数学。
如果模型是基于梯度下降(Gradient Descent)训练出来的,那么攻击者就可以利用梯度上升(Gradient Ascent)来攻击它。
假设 x 是恶意样本,y 是“恶意”标签,L 是损失函数。攻击者的目标是找到一个微小的扰动 δ,使得模型将 x+δ 误判为“安全”。
最经典的 FGSM(Fast Gradient Sign Method) 攻击公式极其简单且优雅:
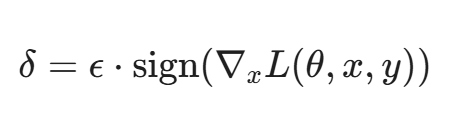
- 直译: 攻击者计算损失函数关于输入 x 的梯度,然后沿着梯度的方向,仅仅移动一小步(\epsilon)。
- 后果: 对于人类肉眼来说,图片还是那张图片,流量还是那个流量(因为 δ 极小);但在 AI 眼中,这个样本的坐标已经跨越了那道脆弱的“肥皂泡边界”,瞬间从“恶意”变成了“安全”。
5.3 现实中的隐形衣
这不仅是实验室的数学游戏,它是真实存在的隐形衣。
- WAF 绕过: 研究人员发现,只需在 SQL 注入 Payload 后添加一段特定的、看似乱码的注释字符,就能让基于 LSTM 的 WAF 认为这是正常文本。这些字符就是经过计算的“对抗扰动”。
- 恶意软件免杀: 在病毒的二进制文件中插入一些无效的“死代码”(Dead Code),这些代码片段是从正常软件中提取的“良性特征”,足以在向量空间中将病毒“拖拽”到安全区域。
结论: 只要 AI 依赖于概率分布,它就天然存在盲区。防御者是在用概率筑墙,而攻击者是在用微积分找缝。
第六章:从“报警”到“决策”——风险量化的金融学
既然 100% 的技术防御被数学证伪,既然对抗样本防不胜防,那 CISO(首席信息安全官)该如何保住饭碗?
答案是:停止扮演“守门员”,开始扮演“精算师”。
我们需要将虚无缥缈的“准确率”,翻译成董事会听得懂的“美元”。
6.1 ALE 模型:给风险定价
不要向 CEO 汇报:“我们的模型 AUC 提升到了 0.98。”
要汇报:“我们通过 AI 将年度预期损失(ALE)降低了 300 万。”
ALE (Annual Loss Expectancy) 模型是安全经济学的核心:
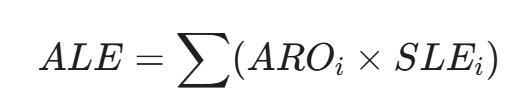
ARO (Annual Rate of Occurrence): 威胁发生的年化频率。
- SLE (Single Loss Expectancy): 单次事件的预期损失。
SLE = Asset Value (资产价值)} X Exposure Factor (暴露因子)
AI 的真实价值不在于消灭威胁,而在于压缩 SLE。
- 传统防御: 勒索软件感染后,平均 48 小时才被人工发现。此时数据已全部加密,SLE = 1000 万(赎金+停产)。
- AI 防御: 勒索软件加密第 10 个文件时,AI 发现异常行为并自动切断进程。响应时间 = 2 秒。SLE = 0.1 万(恢复 10 个文件)。
即使 AI 有漏报,只要它能拦截掉 90% 的高破坏性攻击,从宏观经济账上看,它就是成功的。
6.2 贝叶斯风险决策(Bayesian Risk Decision)
我们在第一部分讨论了阈值 \tau。现在,我们要用钱来重新定义它。
最佳的决策阈值,不是准确率最高的点,而是期望损失最小(Minimum Expected Risk)的点。
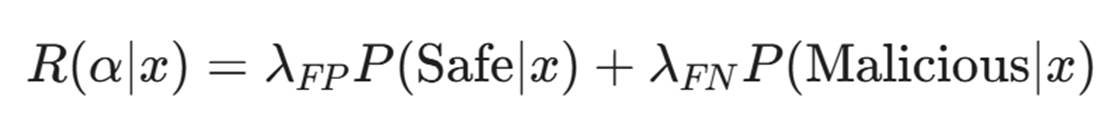
- λFP: 误报带来的成本(如:阻断核心业务 1 分钟损失 5 万)。
- λFN: 漏报带来的成本(如:数据泄露赔偿 200 万)。
场景化调优:
- 场景 A:双十一大促的支付接口。 λ_{FP} 极高(不能拦用户付钱)。此时,我们宁愿接受更高的漏报,也要调低 AI 的阻断阈值。
- 场景 B:核电站的控制内网。 λ_{FN} 是无限大(核泄漏)。此时,任何风吹草动(概率 > 0.1)都要触发最高级警报,哪怕 λ_{FP} 让人工疲于奔命。
专业人士的觉悟: AI 系统的调优,本质上是在调企业的风险偏好(Risk Appetite)。你不是在调参,你是在做生意。
第七章:人机协同(Human-in-the-loop)——最后的 0.01%
技术乐观主义者认为 AI 终将取代人类分析师。但贝叶斯定理告诉我们,当置信度落在 40% - 60% 的模糊地带时,数学是无力的。
这时候,需要引入一种超越统计学的力量:语境(Context)。这正是人类的强项。
7.1 “异常”不等于“恶意”
AI 擅长发现异常(Anomaly)——即统计学上的离群点。
但网络世界充满了“良性的异常”:
- 案例: 某员工在凌晨 3 点突然下载了 5GB 代码。
- AI 视角: 历史行为偏差值 > 3\sigma,报警!概率 0.95!
- 人类视角: 看了眼日历,明天是版本发布日,这哥们在通宵打包上线。这是正常业务。
AI 只能看到相关性(时间、流量大小),人类能理解因果性(发布日、业务逻辑)。这也正是 XAI(可解释性 AI) 致力于解决的问题。我们需要 AI 不仅告诉我们‘这是病毒’,还要告诉我们‘因为它调用了加密函数且修改了引导扇区’,这样人类专家才能高效介入。
7.2 主动学习(Active Learning):人是老师,AI 是学徒
现代 SOC(安全运营中心)不是“AI 报警 -> 人去擦屁股”的单向流动,而是一个闭环。
- 初筛: AI 处理 10 亿级日志,过滤出 1000 条可疑告警。
- 分流:
- 极高置信度(>99%):自动阻断。
- 极低置信度(<10%):自动忽略。
- 模糊地带(40%-60%): 推送给人类专家。
- 标记与反馈: 专家分析那几十条模糊告警,打上标签(Label)。
- “这是误报,原因是新的 CDN 节点上线。”
- 模型更新: 专家将这个 Feedback 喂回给 AI。AI 调整权重,学会了“新 CDN 节点 = 安全”。
在这个体系中,人类不再是低端的监控者,而是AI 的训练师。人类负责处理从未见过的 Zero-day 和复杂的业务逻辑,然后将这些经验“蒸馏”给 AI。
第八章:纵深防御——用不完美构建完美
既然单个模型不可能完美(100%),既然对抗攻击无孔不入,我们该怎么办?
工程学的答案是:冗余(Redundancy)。这就是著名的瑞士奶酪模型(Swiss Cheese Model)。
8.1 异构防御链(Heterogeneous Defense)
不要只叠两层一样的 AI(比如用两个基于 BERT 的模型),那是一样的奶酪,孔洞在同一个位置。对抗样本穿透了一层,就能穿透第二层。
我们要叠加原理完全不同的防御层:
- 第一层:确定性规则(Rule-based)。 拦截已知的、特征明显的攻击。误报率低,速度快。
- 第二层:统计机器学习(Stat-ML)。 基于随机森林或 XGBoost,分析流量统计特征。
- 第三层:深度学习(Deep Learning)。 基于 Transformer 分析 Payload 语义。
- 第四层:图神经网络(GNN)。 分析 IP 关联关系和团伙行为。
概率的乘法效应:
假设每层防御被绕过的概率是 10%(这已经很烂了)。
四层异构防御同时被绕过的概率是:
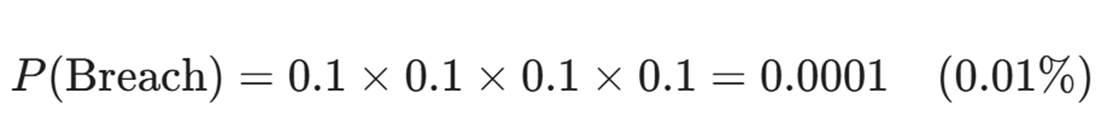
我们用四个二流的模型,构建出了一流的防线。
8.2 动态诱捕:从阻断到欺骗
当 AI 算出攻击概率是 60% 时,与其纠结是放行(可能漏报)还是阻断(可能误报),不如选择第三条路:欺骗。
引入蜜罐(Honeypot)和欺骗技术(Deception Technology)。
- 策略: 将那个 60% 可疑的请求,悄悄重定向到一个高仿真的虚拟环境。
- 收益:
- 如果是正常用户:他依然能访问(虽然是假的),业务未中断,你可以观察他的后续行为来澄清嫌疑。
- 如果是黑客:他在假环境里的每一步操作,都是你免费获得的高质量攻击样本。
- 更重要的是: 你消耗了黑客的时间(Time Cost),这在经济学上是对攻击者最大的打击。
结语:反脆弱的数字生命
至此,我们完成了对 AI 安全底层哲学的重构。
我们从奥本海默的毁灭力量出发,经过图灵的逻辑迷宫,见识了贝叶斯的冷酷判决,最终在工程的堡垒中找到了栖身之所。
核心结论:
- 确定性已死: 没有任何 AI 能提供 100% 的保护。承认这一点,是专业性的开始。
- 对抗永恒: 攻击者会利用高维几何的漏洞。防御必须是动态的、进化的。
- 风险为王: 安全的目标不是“零事故”,而是“风险可控”和“收益最大化”。
- 人机共生: AI 放大算力,人类注入语境。
未来的网络安全系统,不再是一座静止的、坚硬的马奇诺防线,而应该像生物免疫系统一样——
它允许少量的病毒(攻击)进入外围,它会偶尔发烧(误报),但它具备强大的反脆弱性(Antifragility)。每一次攻击,只会让它进化得更强大。
附录:
Ⅰ、给读者的思考题
假设你的 AI 模型检测到了一个勒索软件行为,置信度是 95%。 但是,如果一旦拦截错误,会导致全公司的核心生产数据库停止服务 1 小时,损失 500 万。 如果不拦截,且它真的是勒索软件,会导致数据被加密,赎金加恢复成本是 2000 万。 基于期望损失=概率X损失金额的公式,作为安全负责人,你应该下令拦截吗?如果置信度只有 50% 呢?
Ⅱ、给读者的实战思考(Pre-Article 7)
我们已经理解了概率与统计。但在人类的智慧中,比“统计”更高级的是“逻辑”,比“数据”更重要的是“关系”。
- 如果 AI 知道 IP A 攻击过 IP B,而 IP C 经常登录 IP B,AI 能否推断出 IP C 也可能被入侵?
- 纯粹的深度学习做不到这一点,因为它没有知识。
陈涉川
2026年01月22日

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)