如何把 MCP 接入到文档 / Issue / CI,形成可复用的工程外脑
data: 结构化 JSON(核心字段可被 Agent 消化)evidence: 可引用证据(URI / doc_id / issue_id / run_id): 下一步建议(可选)这样你可以把外脑迁移到不同宿主时,最大限度不改提示词与规则。发起测试(触发 workflow)读取结果(状态 + 关键失败片段)自动归因(根据错误栈定位代码与 Issue 关联)回写 Issue/PR 评论(让团队看到
工程团队真正的效率瓶颈,往往不在“写代码速度”,而在三个环节反复卡住:
- 找不到正确资料(内部文档、规范、历史决策、依赖版本、接口说明)
- 对不上工作上下文(Issue/需求/缺陷、变更影响、负责人、时间线)
- 执行与验证不闭环(CI 触发、日志定位、回滚判断、发布核对)
Model Context Protocol(MCP) 的价值是:把这些“外部系统”以统一协议暴露为可调用的工具与可读取的资源,让 IDE/终端里的 AI Agent 不再靠猜,而是可检索、可追踪、可执行、可审计。MCP 被定义为连接 LLM 应用与外部数据源/工具的开放协议。
本文给出一套可落地的方法:把 MCP 接入文档 / Issue / CI,组合成可复用的“工程外脑”,并覆盖 Claude Code、Cursor、Kiro、ChatGPT(Developer mode)等常见宿主的配置与工程治理要点。
MCP服务器可前往 Rainyun 低价获取,稳定快速
1. 先统一认知:工程外脑在 MCP 里长什么样
1.1 MCP 的基本结构(决定了你怎么“接”)
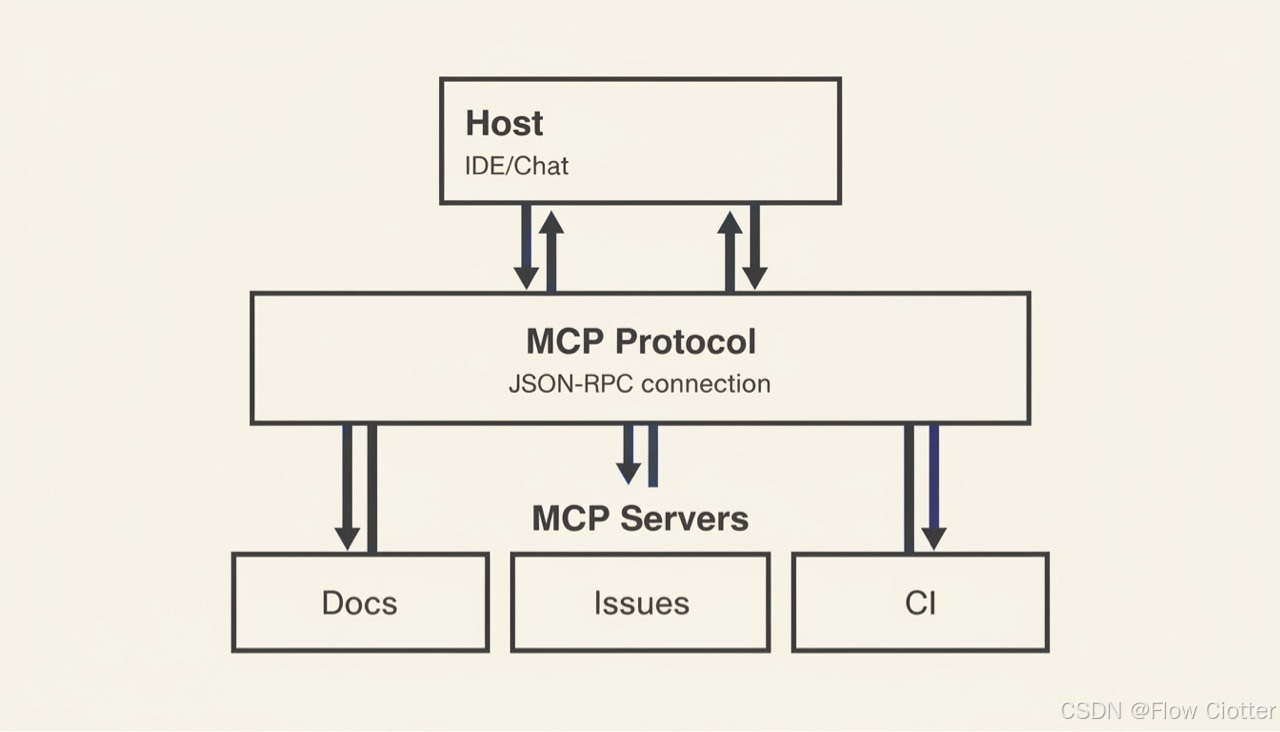
MCP 采用 Host–Client–Server 架构:Host(如 IDE/CLI/Chat 应用)可连接多个 MCP Server;协议基于 JSON-RPC 并维护有状态会话。
你要做的事情,本质上是把组织内的三类系统“包装成 MCP Server”:
- 文档系统(Docs):Confluence/Notion/Drive/内部 Wiki/README/ADR
- 工作系统(Issues):GitHub Issues/Jira/Linear/工单系统
- 执行系统(CI):GitHub Actions/GitLab CI/Jenkins/Argo/自建流水线
1.2 三类 MCP 原语:决定“外脑能力边界”
MCP Server通常通过三类能力对外提供价值:
-
Resources(资源):可读取的上下文(页面、文件、规范、API schema 等),每个资源有 URI。
-
Tools(工具):可被模型调用的动作(搜索、创建 Issue、触发 CI、拉取日志等)。
-
(可选)Prompts:可复用的提示模板/工作流入口(不同宿主支持程度不同)
工程外脑最实用的组合是:
- Docs 以 Resources + search Tool 为主
- Issue 以 Tools(CRUD + comment + query) 为主
- CI 以 Tools(trigger + status + logs) 为主
2. 外脑的目标架构:把“知识、任务、验证”接成闭环
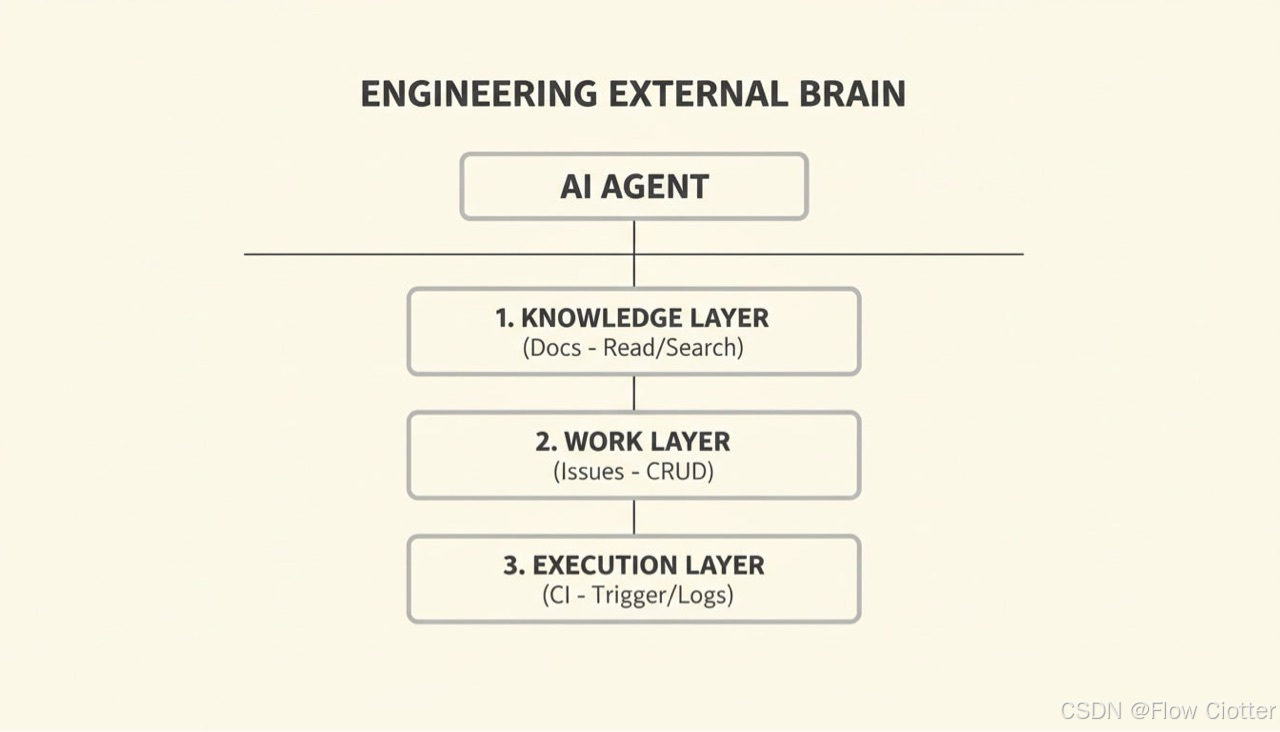
建议把外脑拆成三层,每层都能独立复用、可单独替换:
2.1 知识层(Docs MCP)
目标:让 Agent 能“查得到、读得准、引用可追溯”。
最低工具集(建议):
search_docs(query, filters):全文/向量搜索read_doc(doc_id | uri):读取正文(支持分段)get_doc_meta(doc_id):作者、更新时间、权限、标签list_spaces()/list_collections():空间/知识库枚举(可选)
实现路径两条:
- 直接调用文档系统 API(权限/审计更清楚)
- 或构建“文档索引服务”(向量库 + 元数据),再由 MCP Server 暴露统一工具
Cursor 将 MCP 定位为连接外部系统与数据源的方式,使 Agent 不必反复理解项目结构与外部工具。
实务建议:Docs MCP 应支持 “引用”(返回段落定位、URI、更新时间),否则 Agent 只会“看过”,无法在评审时自证。
2.2 工作层(Issue MCP)
目标:让 Agent 能把“需求/缺陷/讨论”变成可操作对象,而不仅是聊天记录。
最低工具集(建议):
search_issues(query, state, labels, assignee)get_issue(issue_id)create_issue(title, body, labels, assignee)comment_issue(issue_id, comment)link_pr(issue_id, pr_url)(可选)
GitHub 提供了官方 GitHub MCP Server 及使用指南,并讨论了托管/远程形态减少本地维护成本。
实务建议:Issue MCP 要强制输出“变更的来源”:哪个需求、哪个讨论、哪个决策记录(ADR)驱动了代码修改,否则无法形成可审计链路。
2.3 执行层(CI MCP)
目标:把“验证与交付”变成 Agent 可调用的工具,而不是人工点按钮。
最低工具集(建议):
trigger_workflow(repo, workflow, ref, inputs)get_workflow_runs(repo, workflow, ref)get_run_status(run_id)get_run_logs(run_id, filter)(或日志索引)download_artifact(run_id, name)(可选)
如果你在 GitHub 生态里,CI MCP 可以直接封装 GitHub Actions API;也可以通过“GitHub Actions 触发型 MCP Server”这类专用 server 思路来做。
实务建议:CI MCP 必须做权限边界:默认只允许触发“只读/安全流水线”(测试、lint、构建),发布/生产变更必须二次授权或人工确认。
3. 选宿主(Host):IDE/终端/ChatGPT 都能做外脑入口
MCP 的最大优势是“同一套 Server,多宿主复用”。
你可以根据团队习惯选择入口:
-
Claude Code:官方文档说明可通过 MCP 连接大量外部工具与数据源。
-
Kiro:原生支持 MCP,并提供配置与最佳实践文档;支持 workspace 与 user 两级配置(
.kiro/settings/mcp.json/~/.kiro/settings/mcp.json)。 -
Cursor:提供 MCP 文档与目录,并支持在全局或项目内通过
~/.cursor/mcp.json或.cursor/mcp.json配置(示例可见 Context7 的安装说明)。 -
ChatGPT(Developer mode):OpenAI 文档说明 Developer mode 提供完整 MCP 客户端能力(读写工具),但强调风险与安全测试。
4. 落地步骤:从 0 到 1 搭建可复用工程外脑
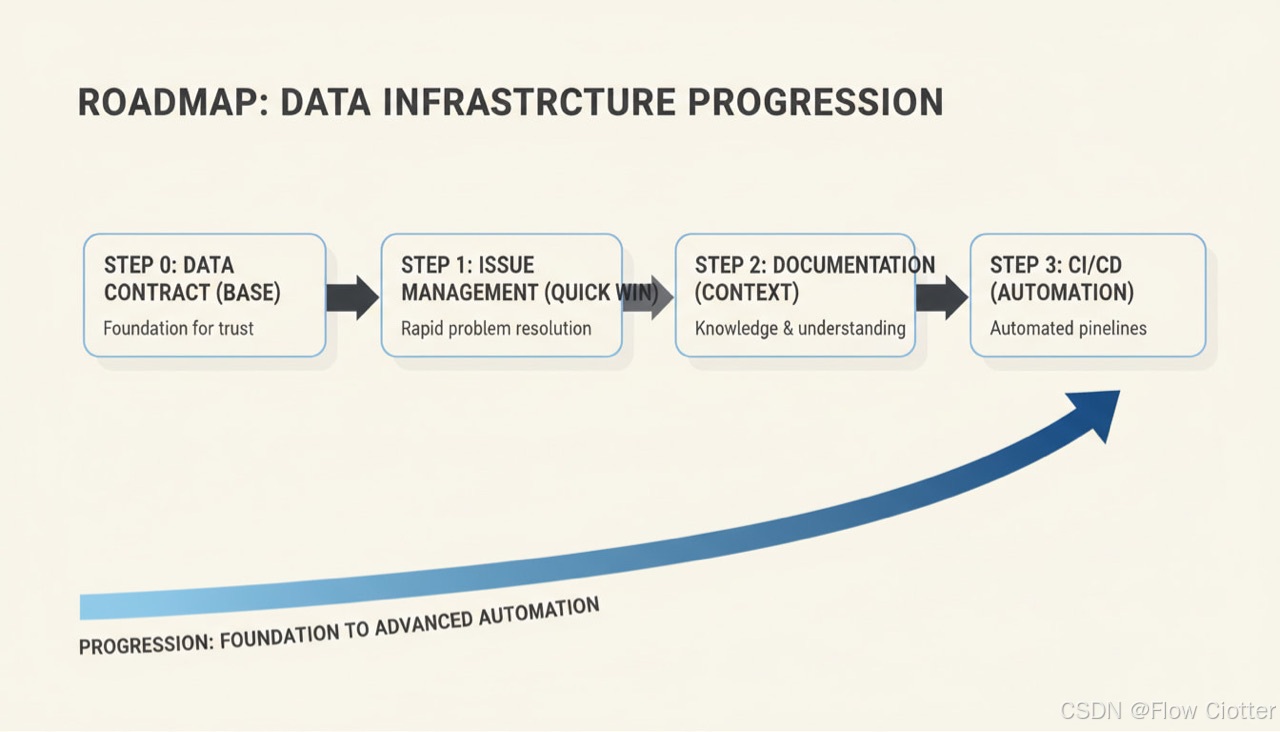
下面给出“最小可用”路线,优先闭环,再扩展能力。
Step 0:先定义“外脑契约”(团队可复用的工具命名与输出格式)
推荐把工具输出统一为:
data: 结构化 JSON(核心字段可被 Agent 消化)evidence: 可引用证据(URI / doc_id / issue_id / run_id)recommendation: 下一步建议(可选)
这样你可以把外脑迁移到不同宿主时,最大限度不改提示词与规则。
Step 1:先接 Issue(最容易产生可见价值)
用 GitHub MCP Server / Jira MCP Server 之类的方式接入,让 Agent 能做到:
- 从 Issue 拉需求与约束
- 生成实施计划(文件列表、风险点、验证点)
- 完成后回写评论(变更摘要、测试结果、PR 链接)
GitHub 官方有 MCP Server 仓库与配置说明,可作为起点。
Step 2:再接 Docs(解决“靠猜”与“错引用”)
Docs 外脑要解决两件事:
- 检索:对“规范/接口/历史决策”做到可搜索
- 引用:返回可审计的出处(URI、段落定位、更新时间)
Cursor 与 MCP 官方文档均提供“构建 MCP server”的指导,可用来快速起步。
一个成熟的 Docs MCP 还应支持:
- 变更检测(文档更新时刷新索引)
- 权限对齐(遵循文档系统权限,不做越权聚合)
- 证据化输出(减少“模型幻觉式引用”)
Step 3:最后接 CI(把“验证”变成工具调用)
CI 外脑的目标是让 Agent 做到:
- 发起测试(触发 workflow)
- 读取结果(状态 + 关键失败片段)
- 自动归因(根据错误栈定位代码与 Issue 关联)
- 回写 Issue/PR 评论(让团队看到证据链)
对远程 MCP Server 的连接与认证,可参考 Claude 平台文档(远程 MCP)与 MCP 规范中的授权思路。
5. 配置范式:把 MCP Server 变成“团队资产”
不同宿主的配置文件格式略有差异,但工程治理思路一致:
5.1 Kiro:分 workspace / user 两级
Kiro 文档与博客明确支持:
- 项目级:
.kiro/settings/mcp.json - 用户级:
~/.kiro/settings/mcp.json
治理建议:
- 团队共享的外脑(Docs/Issue/CI)尽量放在 repo(workspace),保证一致性
- 个人偏好/私人工具放 user scope,避免污染团队
5.2 Cursor:分全局 / 项目两级
Cursor MCP 文档与示例显示可在全局或项目内配置 MCP。
治理建议:
.cursor/mcp.json放在 repo:团队统一外脑入口~/.cursor/mcp.json:个人工具,不参与团队复现
5.3 Claude Code:按 MCP 文档接入外部工具
Claude Code 文档提供 MCP 连接说明,并强调通过 MCP server 扩展到工具、数据库与 API。
治理建议:
- 先接“只读工具”(Docs/检索),再接“写工具”(Issue/CI)
- 写工具必须做权限与审计(见下节安全)
5.4 ChatGPT Developer mode:能力强但风险高
OpenAI 文档说明 Developer mode 提供完整 MCP 客户端能力(读写),并明确提示 prompt injection、写入破坏数据等风险。
治理建议:
- 在团队环境里,将 ChatGPT 作为“分析与检索入口”,写操作尽量走 IDE/CI 的受控通道
- 或把写操作做成“需要二次确认/审批”的工具(工具侧强制)
6. 安全与治理:外脑能不能进生产,取决于这一节
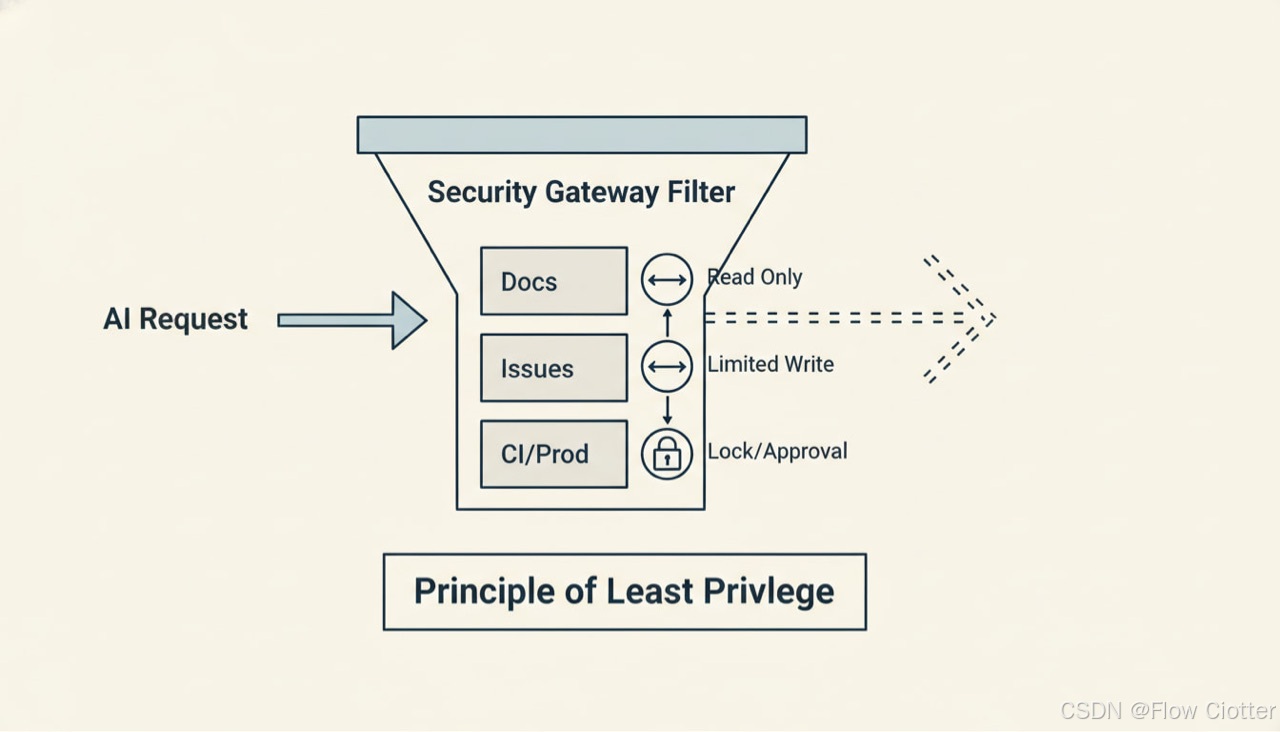
MCP 是“把手伸进系统里”的协议,安全边界必须明确。MCP 生态本身也持续讨论工具执行的威胁建模与边界问题。
建议从四个维度治理:
6.1 最小权限(Least Privilege)
- Docs MCP:尽量只读
- Issue MCP:允许评论/建 Issue,但限制删改、限制跨 repo
- CI MCP:默认只允许“测试/构建”,禁止“生产发布”或需要审批 token
6.2 工具白名单(Tool Allowlist)
在服务端按 toolset 切分:
docs_readonlyissue_write_limitedci_trigger_safe
GitHub MCP Server 也有 toolset/配置相关说明,可借鉴其“能力集”治理方式。
6.3 证据化输出(Evidence-first)
工具返回必须包含:
- 来源 URI / issue_id / run_id
- 时间戳与权限域
- 可复现参数(例如 workflow inputs)
避免“模型看过但无法证明”。
6.4 反提示注入(Prompt Injection)
任何来自外部系统的文本(文档、Issue、日志)都可能携带“诱导指令”。宿主与服务端都应:
- 对工具输出进行分层:数据与自然语言分开
- 对写入操作增加“意图确认”(例如要求明确
confirm=true) - 对高风险工具加人工确认
OpenAI Developer mode 文档也明确强调此类风险。
7. 一套可复用的“工程外脑工作流”模板
你可以把以下流程固化为团队的默认使用方式(配合 Rules/Steering/CLAUDE.md 等规范文件):
- 从 Issue 拉上下文:
get_issue→ 输出约束与验收标准 - 从 Docs 拉证据:
search_docs→read_doc→ 引用关键段落 - 生成实施计划:文件列表、改动范围、风险、测试矩阵
- 执行变更:改代码 + 自测
- 触发 CI:
trigger_workflow→get_run_status→ 失败自动归因 - 回写闭环:Issue 评论写入“变更摘要 + 证据链接 + CI 结果 + PR 链接”
这套流程的关键不是“更聪明的模型”,而是更强的可验证性与可追踪性。
8. 结语:外脑是“协议资产”,不是“工具绑定”
只要你把 Docs / Issues / CI 的 MCP Server 设计成稳定的能力契约,你就能做到:
- 今天用 Kiro / Cursor / Claude Code
- 明天换宿主或换模型
- 外脑不动,团队工作流不动
协议化,才是工程外脑可复用的根本。
附:MCP 免费服务器可前往 魔塔社区 注册
我的稀土掘金账号

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)