保姆级教程:用微信聊天记录训练一个AI分身
《3分钟:用微信聊天记录训练AI分身》介绍了一个开源项目WeClone,通过微信聊天记录微调大语言模型(如Qwen2.5-7B),快速创建个人数字分身。操作步骤包括:1)申请云服务器(推荐算多多平台);2)使用PyWxDump导出微信聊天记录;3)预处理数据并训练模型(仅需几分钟);4)通过Web服务与AI分身对话。该项目实现了个性化AI的快速部署,适合技术爱好者体验。详细教程和工具链已在GitH
3分钟:用微信聊天记录训练一个AI分身
https://github.com/xming521/WeClone 是一个开源的 AI数字分身 生成项目,它通过用户的微信聊天记录,对大模型行微调,从而创建一个有烟火气的 AI 分身。
ps:Chatgpt 刚火起来的时候,我当时也有类似想法,大部分人的聊天记录都记录在微信上面,如果能直接把聊天记录拿出来训练一个大模型,岂不就能造就一个“我”?我可以用这个模型到处灌水,甚至导入到人形机器人中
只可惜当时没有精力(\能力)做这样的事情,现在看到有同学实现了这样的项目,还是非常开心(\可恶)的!
快速开始
一、下载工程
大家在国内访问 github 可能比较慢,我找了一个 gitee 上的仓库
git clone https://gitee.com/xming521/WeClone.git
为了保证稳定性,将 pip 切换为国内的清华源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
使用 uv 创建虚拟环境
uv venv .venv --python=3.12
source .venv/bin/activate # windows .venv\Scripts\activate
uv pip install --group main -e .
ps:不想自己搭建的直接使用云上镜像:微信聊天记录克隆 AI 分身
二、准备数据:使用 PyWxDump 导出微信聊天记录
1、将手机微信聊天记录迁移到电脑上
详细指南:https://zhuanlan.zhihu.com/p/647727121
2、使用 PyWxDump 导出聊天记录文件
注意,此步骤需要保持电脑上的微信是打开的
PyWxDump 是一个开源的导出电脑上的微信聊天记录的库,主要步骤:
1、下载安装包(目前只支持Windows):Windows下载包
2、解压后,打开应用,会自动在浏览器打开页面
3、解密微信数据
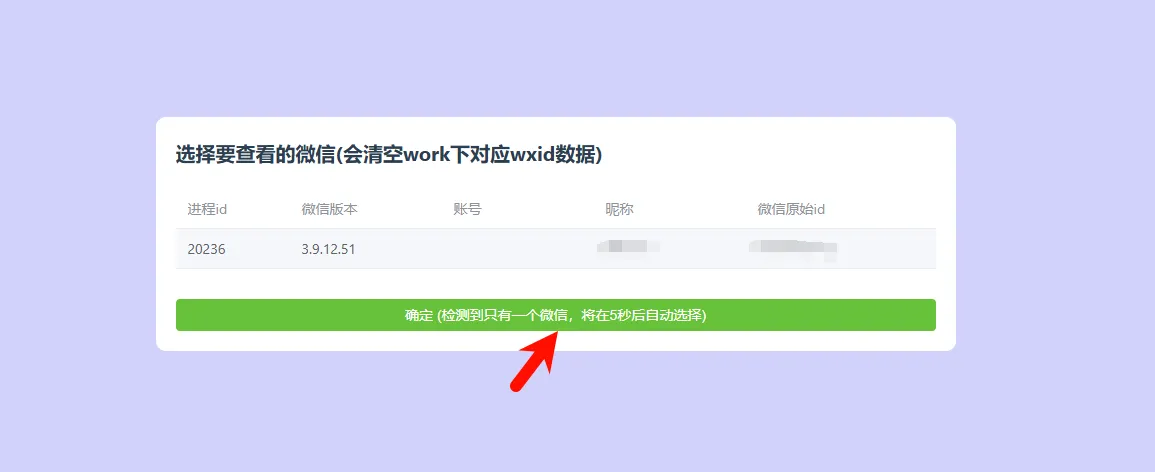
4、导出聊天记录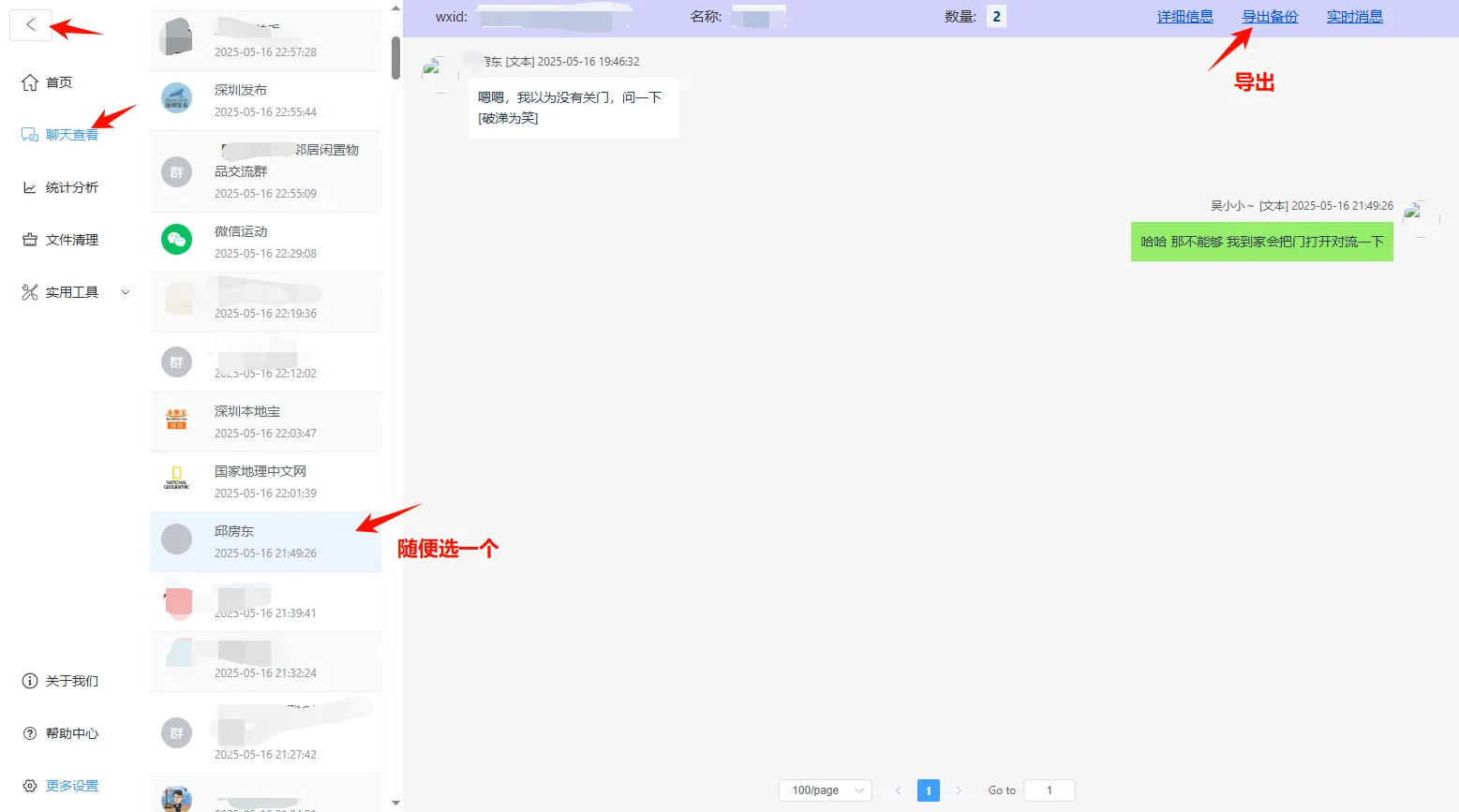
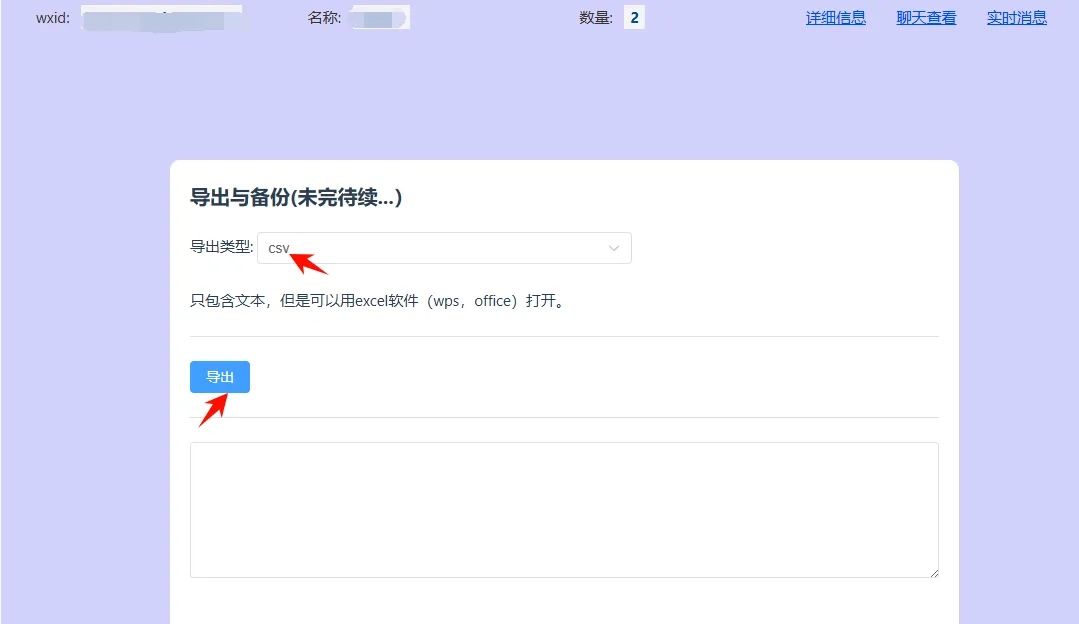
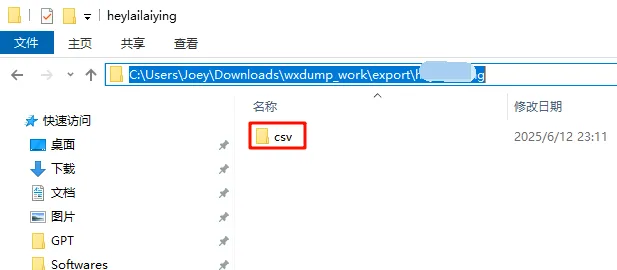
5、查看聊天记录文件夹
复制导出成功后的目录,粘贴到我的电脑地址栏,回车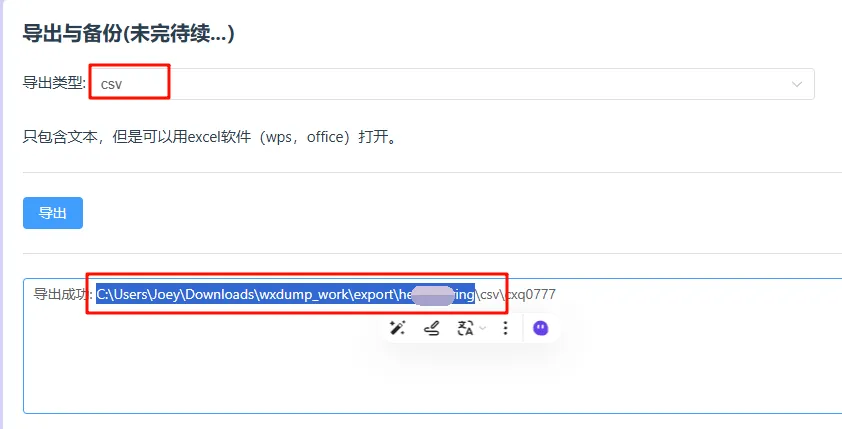
三、预处理数据
1、将本地聊天记录 csv 文件夹复制到云服务器上 Weclone 工程的./dataset目录下
- Windows 用户
scp -P 2222 -r C:\xxx\wxdump_tmp\export\\csv [root@10.114.40.10](mailto:root@10.114.40.10):/root/weclone/WeClone/dataset
将 2222 换成你的实例 ssh 端口号,xxx/csv换成本地聊天记录的文件夹目录,10.114.40.10 换成实例ssh地址
注意:如果提示找不到 scp,请在“应用和功能”里添加“OpenSSH 客户端”。(也可以下载图形客户端 winscp:https://winscp.net/eng/download.php)
- Mac 或 Linux 用户:
scp -P 2222 -r /xxx/csv [root@10.114.40.10](mailto:root@10.114.40.10):/root/weclone/WeClone/dataset
2、对聊天记录进行预处理
原始的聊天记录需要经过预处理才能用于模型训练。
激活 python 虚拟环境
source .venv/bin/activate
预处理数据
weclone-cli make-dataset #在WeClone根目录下执行该命令
成功后,你会看到:
Collecting lengths: 100%|██████████████████████████████████████████| 9/9 [00:00<00:00, 370085.65it/s]
[WeClone] I | 16:07:12 | cutoff_len设置建议:
[WeClone] W | 16:07:12 | 多模态任务请务必配置cutoff_len为数据最大长度
[WeClone] I | 16:07:12 | 9 (100.00%) samples have length < 256.
[WeClone] S | 16:07:13 | 聊天记录处理成功,共9条,保存到 ./dataset/res_csv/sft/sft-my.json
(.venv) (base) root@ins-tcaiohv2xon41mtq510pgpwxu0b42duj:~/weclone/WeClone#
到这里,我们的前置工作都准备好了,可以正式开始训练(微调)大模型了
四、微调大模型
这个镜像里预置了 Qwen2.5-7B-Instruct 模型
如果希望更换模型,可以使用
modelscope下载其他模型,注意要替换一下 settings.jsonc 里的配置
保证当前仍处于虚拟环境下,执行以下命令开始微调
weclone-cli train-sft
注意:工程里已经默认配置好各种参数(./settings.jsonc),我们可以修改相关参数,此处我介绍一些常用的:
| common_args 里的 model_name_or_path | 代表大模型的目录 |
|---|---|
| common_args 里的 template | 代表大模型类型 |
| common_args 里的 use_unsloth | 是否使用 unsloth 优化 LoRA 微调,unsloth 可以提高微调速度,减少微调所需的显存⚠️如果打开这个,那么推理的时候会有报错,目前还没解决 |
更详细的参数设置可参考:https://llamafactory.readthedocs.io/zh-cn/latest/advanced/arguments.html
正常情况下,使用预置的模型,如果只有几十条聊天记录,大概 2-3 分钟就能完成训练,
训练好的模型就保存到 ./model_output 里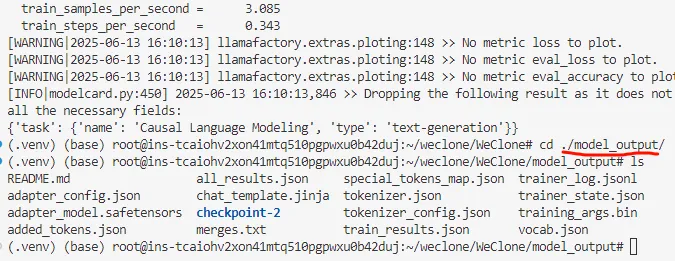
五、与你的数字分身对话(进行模型推理)
微调完成后,你可以通过启动一个 web 服务,与数字分身进行对话交互。
在激活虚拟环境的命令行中,运行:
weclone-cli webchat-demo
脚本会启动一个 Web 服务:
[INFO|2025-06-13 16:43:22] llamafactory.model.model_utils.attention:143 >> Using torch SDPA for faster training and inference.
[INFO|2025-06-13 16:43:22] llamafactory.model.adapter:143 >> Loaded adapter(s): ./model_output
[INFO|2025-06-13 16:43:22] llamafactory.model.loader:143 >> all params: 7,616,878,080
* Running on local URL: http://0.0.0.0:7860
平台已经将这个端口映射到公网了,等 Web 服务成功起来后,在算多多控制台的快捷应用区域打开 Web 页面: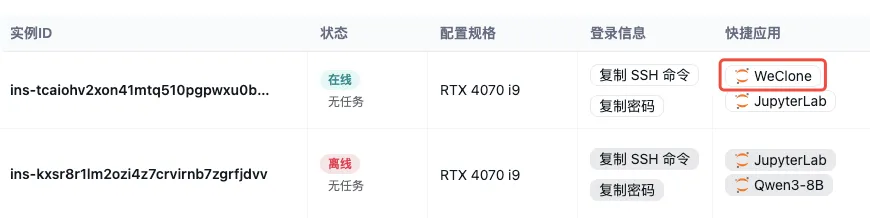
接下来就可以愉快地和你的分身聊天了
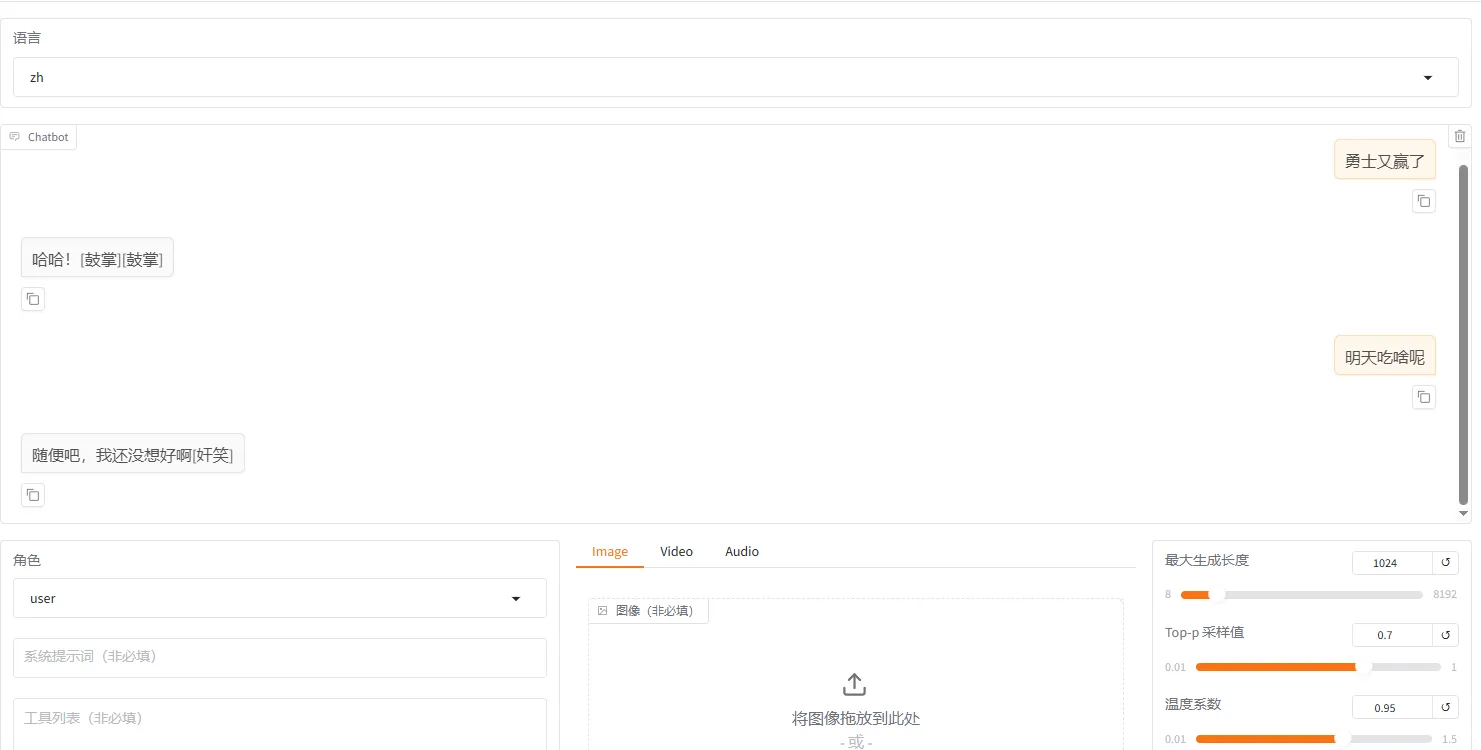
六、其他
你可以考虑将训练好的模型部署到常用的聊天机器人中,比如 AstrBot 本地聊天机器人、Dify工作流等,具体教程可以参考 https://blog.051088.xyz/posts/weclone-linux-tutorial/
我就想马上使用!
对于不想折腾环境的同学,可以直接使用我做好的镜像一键使用:微信聊天记录克隆 AI 分身

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)