【机器学习与NumPy核心操作详解】
机器学习三个步骤:
1.收集数据
2.建立数学模型
3.预测
机器学习需要准备的库:
numpy,matplotlib,pandas,sklearn
KNN算法:既可以做回归,又可以做分类
回归:找出最近的k个数据,求k个数据的平均值(确定连续的值)
分类:找出最近的k个数据,判断类别,看谁的类别数据最多
全称是k-nearest neighbors,通过寻找k个距离最近的数据,来确定当前数据值的大小或类别。是机器学习中最为简单和经典的一个算法。
距离计算公式:
欧氏距离:点到点之间的直线距离;
曼哈顿距离:是一种在几何度量空间中计算两点之间距离的方法。1

KNN算法-sklearn算法
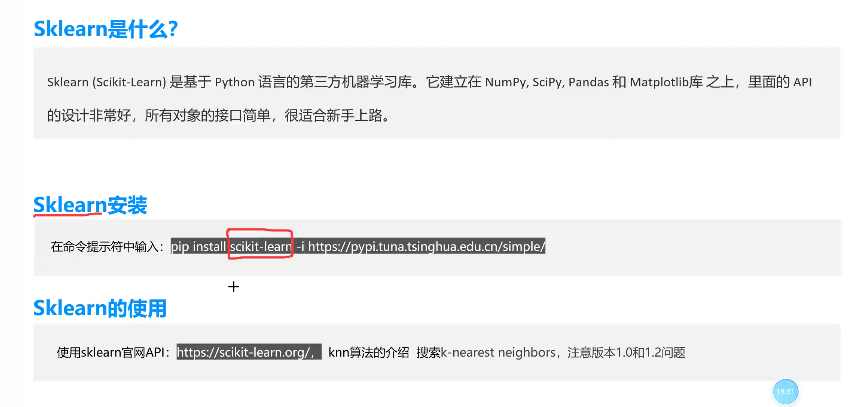
1.认识Numpy和配置环境
NumPy的核心价值在于矩阵运算优化:
并行计算优势:矩阵操作可实现批量数据处理,显著提升AI训练效率
数学基础:支持矩阵求逆、求导等高等数学运算,满足机器学习算法需求
性能对比:相比Python原生列表,NumPy数组计算速度提升10-100倍
Numpy的版本选择与安装
推荐安装numpy==1.26.1,通过pip list命令可查看已安装库的版本,Python第三方库镜像地址与配置,使用镜像地址加速第三方库安装,例如国内清华源或阿里云源。计算机视觉领域需要注意Numpy版本兼容,安装最新版本容易出错,统一安装1.26.1
2.创建array.py
import numpy as np
#一维数组
list1=[1,2,3,4,5]
print(list1)
v=np.array(list1)#将参数变为矩阵
print(v)
#二维数组[多个一维数组组成]
m=np.array([list1,list1,list1])
print(m)
#三维数组[多个二维数组构成]
z=np.array([[list1,list1,list1],[list1,list1,list1],[list1,list1,list1]])
print(z)
z=np.array([m,m,m])
#更高维的
y=np.array([z,z,z])数组的基本属性:
a=v.shape#查询数组的形状
b=v.ndim#查询数组的维度
c=v.size#查询数组中数据个数
print(type(v))
d=v.dtype#查询数组中的元素类型i
nt8,int16,int32,int64:表示不同长度的符号参数
unit8,unit26,unit32,unit64:表示不同长度的无符号参数
floot26,floot32,floot64:表示不同精度的浮点数
complex64, complex128 (complex 是 complex128 的简写):表示复数,其中64和128表示复数的实部和虚部的位数。
bool:布尔类型,可以存储True或False。
str _: 表示定长字符串,可以通过添加数字来指定字符串的长度,如'S10’表示长度为10的字符串。
object:表示Python对象类型,可以用来存储任意Python对象。
3.数组的升维
list1 = [1,2,3,4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8]#
V = np.array(List1)
print(v)一维变二维[-1]表示自己计算【返回一个改变后的矩阵】
a.reshape(newshape, order='C')
a:要重新形状的数组。
newshape:一个整数或者元组,用于定义新的形状。
order:可选参数,指定元素在数组中的读取顺序。‘C'意味着按行,‘F'意味着按列,‘A’意味着原顺序,‘K'意味着元素在内存中的出现顺序。
r1 = v.reshape(4,4)
120
r1=v.reshape(4,-1)#-1表示任意。
print(r1)
r1.ndim
#一维变三维
r2 = v.reshape(1,-1,2)
print(r2)
#二维变三维
r3 = r1.reshape (2, 2,4)
print(r3)
#resize()【不返回计算结果】【直接修改原始数组】
# r4 = v.resize(2,4)
#print(r4)
r4=v.resize(4,4)#直接会修改原始数据到相应的维度
print(v)4.数组的降维
import numpy as np
list1 =[1 2 3 4 5 6,7 8]
v = np.array(list1)
v=v.reshape(2 2,2)
print(v)
v.ndim
#将三维降到二维
r1= v.reshape(1,8)
print(r1)
r1.ndim
#将高维数据转化为一维
#ravel()
r2 = v.ravel()
print(r2)
#flatten()
r3 = v.flatten()#非常重要,
print(r3)
list1 =[1,2,3,4,5,6,7,8]
v= np.array(list1)print(v)
#小补充shape也可以实现降维
v.shape =(2,4)#通过直接对array数据的属性进行修改
print(v)ravel:返回的是视图(view),修改返回的数组会影响原始数组。性能更高,适用于大型数组。
flatten:返回的是副本(copy),修改返回的数组不会影响原始数组。性能稍低,但更安全
5.创建特殊的数组
#创建全为0的数组
a = np.zeros(5)
b=np.zeros((2,2))#(2,2)np.zeros((2,2))#zeros只能接受1个参数,
c = np.zeros((3,2,2))
print(a,'\n',b,'\n',c)
运行结果:
[0. 0. 0. 0. 0.]
[[0. 0.]
[0. 0.]]
[[[0. 0.]
[0. 0.]]
[[0. 0.]
[0. 0.]]
[[0. 0.]
[0. 0.]]]
#创建全为1的数组
d = np.ones(5)
e = np.ones((2,2))
f = np.ones((2,2,2))
运行结果:
[1. 1. 1. 1. 1.]
[[1. 1.]
[1. 1.]]
[[[1. 1.]
[1. 1.]]
[[1. 1.]
[1. 1.]]]
#创建全为2的数组
矩阵中全部填充指定的数据
g = np.full((2,2,2), 5)
print(g)
运行结果
[[[5 5]
[5 5]]
[[5 5]
[5 5]]]
#小补充
h = np.eye(5,7)
print(h)
运行结果
[[1. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0.]]6.numpy中常用的两个函数
import numpy as np
#1.arange(start,end,step)>range(start,end,step)#[左闭右开的区间]一次性产生规律的数据。
r1 = np.arange(0,9,3)
print(r1)
#2.linspace(start,end,nums)
# [左右都是闭区间]
r2 = np.linspace(0,1,21)
print(r2)
运行结果
[0 3 6]
[0. 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 0.55 0.6 0.65
0.7 0.75 0.8 0.85 0.9 0.95 1. ]7.数组元素的选取与修改
import numpy as np
array1 = np.arange(48).reshape(2,4,6)
print(array1)
#np.arange(48)生成0到47的一维数组.reshape(2,4,6)将其转换为2x4x6的三维数组结构分为2个二维矩阵,每个矩阵4行6列
#选取某个元素
#首先确定选取哪一个二维数组
a= array1[1,0,0]
#获取第二个二维数组(索引1)的第0行第0列元素结果值为24
#选取某行元素
b= array1[0,1 :]
#获取第一个二维数组的第1行到最后一行所有元素
#选取某些行元素
c= array1[0,1:3,:]
#获取第一个二维数组的第1到2行(不包括3)的所有列
d= array1[0 ,[1,3],:]
#获取获取第一个二维数组的第1行和第3行的所有列
#选取某列
e = array1[1,:,1]
#选取某些列
#获取第二个二维数组所有行的第1列
f = array1[1,:,1:4]
#获取第二个二维数组所有行的第1到3列
g = array1[1,:[1,4]]
#获取第二个二维数组所有行的第1和第4列
#修改
array1[1,0,0]=100
print(array1)
#将第二个二维数组的第0行第0列元素从24改为100
v= np.array([arrayl,array1,array1,array1])
a=v[2,1,2:,1:3]
print(a)
#创建4个array1副本组成的四维数组
#获取第3个三维数组(索引2)中第2个二维数组的第2行到最后行,第1到2列
8.数组的组合
import numpy as np
#生成基数组
array1 = np.arange(9).reshape(3,3)array2 = 2*array1print(array1)print(array2)
#水平组合
a3 = np.hstack((arrayl,array2))
a4 = np.hstack((array2,array1))
a5 = np.hstack((array1,array2,array1))
a6 = np.concatenate((array1,array2),axis=1)
#axis表示连接的方向
#垂直组合
a7 = np.vstack((array2,array1))
a8 = np.concatenate((array1,array2),axis=0)
print(1)np.hstack()和np.vstack()是专门用于水平和垂直堆叠的便捷函数。
np.concatenate()通过axis参数控制方向:axis=1等价于hstack(),axis=0等价于vstack()
所有组合操作要求数组在非连接轴上的维度一致
9.numpy内敛数组元素的切割
import numpy as np
array1 = np.arange(16).reshape(4,4)
print(array1)
#水平切割
a = np.hsplit(array1,2)#其中第2个参数 2表示将矩阵array1进行2等份切分
b = np.split(array1,2,axis=1)
#垂直切割
c = np.vsplit(array1,2)#
d = np.split(array1,2,axis=0)
#强制切割
#水平切割
e = np.array_split(array1,3 axis=1)
#垂直切割
f = np.array_split(array1,3,axis=0)10.数组的算术运算
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
# 逐元素加法
print(a + b) # [5 7 9]
# 逐元素乘法 (不是矩阵乘法)
print(a * b) # [4 10 18]
# 数组与标量运算 (广播)
print(a * 2) # [2 4 6]11.数组的深拷贝和浅拷贝
-
浅拷贝(View):创建一个新的数组对象,但数据本身是共享的。修改视图会影响原数组,反之亦然。切片操作(如
arr[1:3])默认返回视图。 -
深拷贝(Copy):创建一个全新的数组,包含新的数据内存。修改副本不会影响原数组。
# 原始数组 arr = np.array([1, 2, 3, 4]) # 浅拷贝 (共享内存) view_arr = arr[1:3] # 或 arr.view() view_arr[0] = 99 print(arr) # [1 99 3 4] -> 原数组被改变了! # 深拷贝 (独立内存) copy_arr = arr.copy() copy_arr[0] = 88 print(arr) # [1 99 3 4] -> 原数组不受影响
12.numpy内的随机模块(1)
np.random 是生成随机数的核心模块,常用于数据初始化、模拟实验等。
常用函数
np.random.rand(d0, d1, ...): 生成 [0, 1) 之间均匀分布的随机数,参数指定形状。 np.random.randn(d0, d1, ...): 生成标准正态分布(均值0,标准差1)的随机数。 np.random.randint(low, high, size): 生成指定范围内的随机整数。
np.random.normal(loc, scale, size): 生成指定均值(loc)和标准差(scale)的正态分布随机数。
13.numpy内的随机模块(2)
随机种子
为了保证实验的可重复性,我们需要设置随机种子。只要种子相同,生成的随机序列就完全相同
# 设置种子,确保结果可复现
np.random.seed(42)
# 生成2x3的随机浮点数矩阵 (0到1之间)
a = np.random.rand(2, 3)
# 生成随机整数 (0到10之间)
b = np.random.randint(0, 10, size=5)
# 打乱数组顺序
arr = np.array([1, 2, 3, 4])
np.random.shuffle(arr) # 直接修改原数组14. NumPy内一些函数的使用
这里介绍几个高频实用函数:
np.arange(start, stop, step): 类似Python的range,但返回的是数组。
np.linspace(start, stop, num): 在指定区间内生成等间距的数字(包含端点)。
np.reshape(shape): 改变数组形状。
np.where(condition, x, y): 根据条件从x或y中选择元素。
# 生成0到9的数组
np.arange(10)
# 生成0到1之间的5个等差数
np.linspace(0, 1, 5) # [0, 0.25, 0.5, 0.75, 1.0]
# 条件筛选:如果a>2取a,否则取0
a = np.array([1, 2, 3, 4])
np.where(a > 2, a, 0) # [0, 0, 3, 4]
15.矩阵的运算
虽然NumPy主要使用ndarray,但它支持完整的线性代数运算。
转置:使用 .T 属性。
矩阵乘法:使用 np.dot(A, B) 或 A @ B。
求逆:使用 np.linalg.inv(A)。
行列式:使用 np.linalg.det(A)。
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
# 矩阵乘法
A_trans = A.T
print(A_trans)
#求行列式
D=np.linalg.det(A)
print(D)
#求逆
E=np.linalg.inv(A)
print(E)
# 矩阵乘法
C = np.dot(A, B) # 或 A @ B
print(C)
# 求解线性方程 Ax = B
x = np.linalg.solve(A, B)
print(x)16.读取文件
# numpy.loadtxt():从文本文件中加载数据。这个函数假定文件中的每一行都有相同数量的值,并将这些值分隔开。
# 你可以使用 delimiter 参数指定分隔符,如逗号、制表符等。例如:
import numpy as np
data = np.loadtxt('datingTestSet2.txt',delimiter='\t')
print(data)
#将数组保存到txt 文件中
import numpy as np
array= np.array([[1,2,3],[4,5,6],[7,8,9]])# 创建一个 NumPy 数组
np.savetxt('array.txt',array)# 使用 savetxt()将数组保存到文本文件中"""
读取csv.文件
"""
imoprt pandas as pd
df_1 = pd.read_csv("data1.csv")
df_2 = pd.read _csv("data2.csv",encoding='utf8',header=None)
"""
读取excel文件
"""
df_3 = pd.read excel("data3.xlsx")#
"""
读取txt文件
"""
df_4 = pd.read_table("data4.txt",sep=',',header=None)
#sep=',':指定文件的分隔符为逗号()
"""
导出文件
"""
df_1.to_csv("导出.csv",index=True, header=True)
#index=True:表不号出时包含DataFrame 的系引(行标签),默认信为 True:若设为False,则个导出系引。
df_1.to_excel("导出.xlsx",index=True, header=True)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 57
57 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)